YOLO-V2論文學習(超詳細)
文章目錄
YOLO9000:Better, Faster, Stronger
1.簡單介紹
YOLO9000是一款先進實時的目標檢測系統,可以檢測出超過9000目標種類。基於YOLO-v1的問題,作者採用了很多新奇的方法又借鑑一些之前的工作,提出YOLO-v2,相同的YOLO-v2可以執行在不同尺寸之下,實現一種簡單的速度與精度的權衡。同時作者提出了在目標檢測數據集和分類數據集聯合訓練的方式,並取得了很好的效果。我們接下來的文章主要圍繞這兩個部分展開。
2.設計方案
作者回顧了YOLO-v1的缺點,相對於最先進的檢測系統,YOLO的確存在很多不足,與Fast R-CNN的誤差分析表明,YOLO存在大量的定位錯誤。此外,與基於區域提案的方法相比,YOLO的召回率相對較低。因此YOLO-V2的很多工作也聚焦於提升召回率和定位上。
計算機主流的趨勢是朝着更大更深的網路發展,更好的效能往往依賴於訓練更大的的網路或者同時聚合不同的模型。而YOLO-V2的想法是在獲得更精確模型的同時依舊保持很快的速度,與擴大網路相反,YOLO-v2簡化網路並使特徵更容易去學習。
Batch Normalization
Batch Normalization 在模型收斂方面帶來了顯著的提升,同時可以去除了對其他形式的正則化形式。通過在YOLO中對所有折積層進行批次歸一化,在mAP上得到了超過2%的提升。批次歸一化還有助於規範化模型。通過批次歸一化,可以從模型中去除dropout且不會引起過擬合。
High Resolution Classifier
大多數先進的檢測方法都採用在ImageNet上預先訓練好的分類器。從AlexNet開始,大多數分類器進行的輸入影象都小於256×256。原先YOLO是在224×224的尺寸下訓練分類器網路,將解析度提高到448進行檢測任務。而對於YOLO-V2,首先在448 * 448解析度ImageNet 分類網路中fine turn 10個週期,這使得網路有時間調整折積核,以可以更好地在高解析度影象下工作,然後再將結果網路進行fine turn去做檢測任務。這種方法將最終結果提高了4%的mAP。
Convolutional With Anchor Boxes
YOLO對於邊框的預測是採用最後的全連線層直接預測bounding box的座標,而Faster R-CNN在預測bounding box 的時候採用手工挑選先驗框,僅僅使用RPN的折積層去預測anchor boxes偏移量而不是座標,這大大簡化了問題,也使網路更容易去學習。基於這個思想,作者移除了全連線層使用anchor boxes去預測bounding boxes,也去除一個pooling層來獲得更大的輸出解析度,對於輸入圖片將448 * 448調整到416 * 416。
爲什麼要這樣調整大小呢?作者的回答是YOLO的折積經過了32倍下採樣,我們希望我們特徵圖是奇數個locations,這樣中心網格
就是一個了,這樣好處是什麼呢?一些是大的物體,往往佔據影象的中心,所以最好在中心有一個單獨的位置來預測這些物體,而不是四個位置都在附近。416 * 416的輸入,32倍下採樣就是13 * 13,滿足我們這樣的設計目的。
繼我們前面說的話題,當我們採用anchor boxes的方法時,我們也將類預測機制 機製與空間位置進行瞭解耦,取而代之的是爲每個anchor boxes預測類和物件。遵循YOLO設計,目標預測仍然預測了ground truth與和建議框的IOU;而類預測則預測了該類在有物件的情況下的條件概率。在沒有採用anchor boxes的情況下,模型有着69.5的mAP和81%的召回率。使用該方法之後69.2的mAP和88%的召回率。雖然mAP有所下降,但是召回率的提高意味着模型有着更多的改進空間。
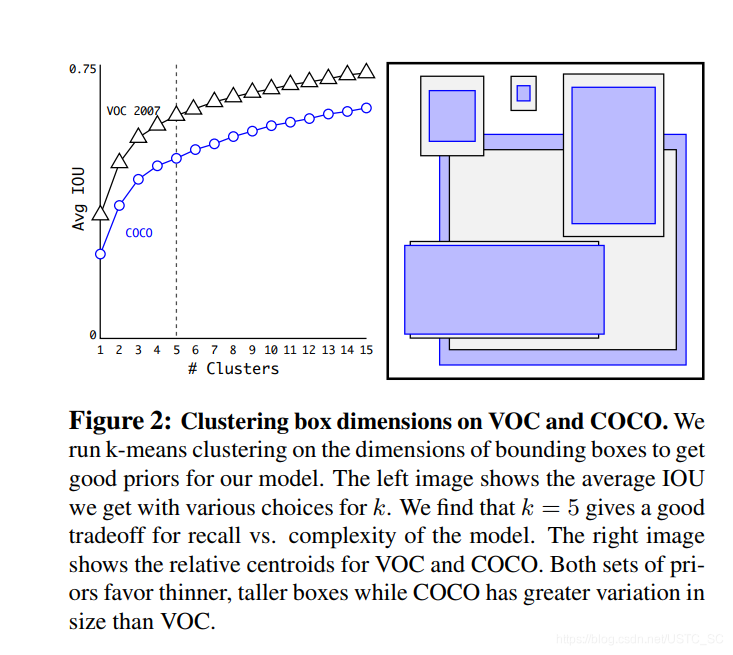
維度聚類
在使用Anchor boxes進行預測時box的尺寸都是手工挑選的,網路可以學會適當地調整盒子,但如果我們爲網路選擇更好的先驗框,就會使更容易的學習獲得更好的預測結果,基於此作者採用K-means的方法去尋找好的先驗框。
既然選擇了K-means,那麼怎麼使用這個方法呢,如果我們採用標準的K-means基於歐式距離,那麼大的框會比小的框產生大的誤差,但是我們真正想要的是選取的框可以有更好的IOU得分,這個和框的尺寸沒有關係,所以我們用下列的公式來表示。
box指真實框 ,centroid指每次迭代的中心框(類似於k-means中心點的意思,k爲幾就有幾個中心框,收斂之後就是我們想要的結果先驗框)
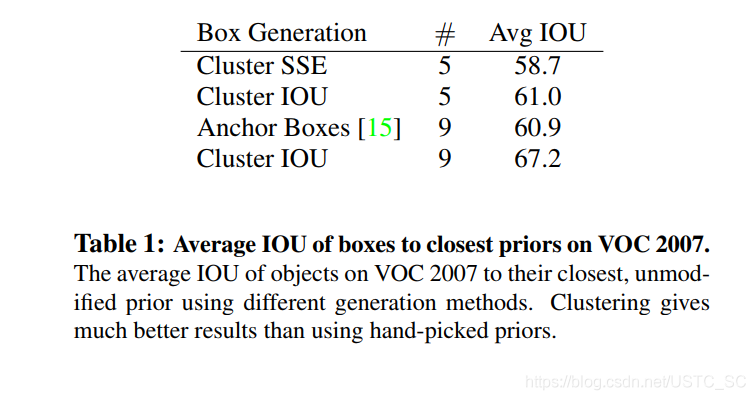
作者採用一系列的K值獲得一系列在不同K值下的框,最後權衡,模型複雜度與召回率,選擇了K等於5,以下圖爲在不同k下的比較以及k=5下的框形狀,在後面一張圖也顯示了維度聚類方法在k =5時 的平均IOU和手工選擇9框效果差不多,而當K=9時,平均IOU超越了很多,也說明了這種方法的可行性,使模型有更好的表徵學習能力。
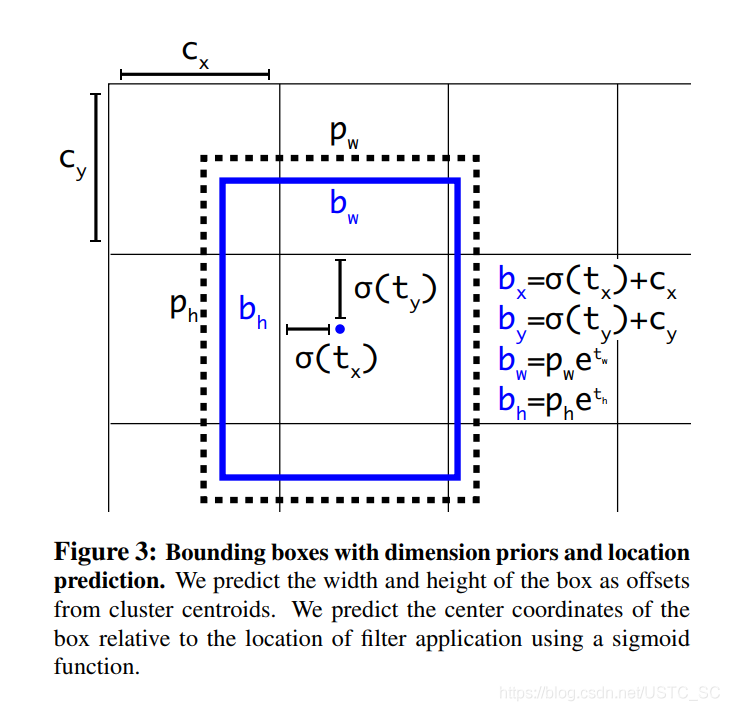
直接位置預測
當YOLO採用anchor boxes的設計時面臨的另一個問題就是在早期迭代過程中不穩定,而這不穩定主要來自於預測box(x,y)座標時,所以YOLO-v2沒有採用Fast-RCNN的預測方式。YOLO-V2位置預測 值 tx , ty 就是預測邊界框中心相對於cell左上角位置的相對偏移值,爲了將邊界框中心點約束在當前cell中,使用sigmoid函數處理偏移值,這樣預測的偏移值在(0,1)範圍內(每個尺度的看做1)。
網格在特徵圖(13*13)的每個cell上預測5個anchor,每個anchor預測5個值: tx , ty tw , th to 。如果這個cell距離影象左上角的邊距爲( cx , cy ),cell 對應的先驗框(anchor)的長和寬分別爲( pw , ph),那麼網格預測框的下圖藍框:
細粒度特徵
改進版本的YOLO最終特徵圖是13 * 13,對於定位大的物體來說已經不錯,但是細粒度特徵對於定位小的物體會很有幫助,,像SSD之類的檢測器就採用結合在不同解析度的特徵圖上去檢測,而YOLO-v2採用一種不同的方法,通過一個passthrough層連線不同層,首先將高解析度相鄰的特徵疊加到不同的通道而不是空間位置,然後再將高解析度特徵與低解析度特徵連線起來,類似於ResNet的操作,舉個例子來說就是將26 * 26 * 512 特徵圖,分成13 * 13 *2048,再連線到最後13 * 13特徵圖(加入通道)。
多尺度訓練
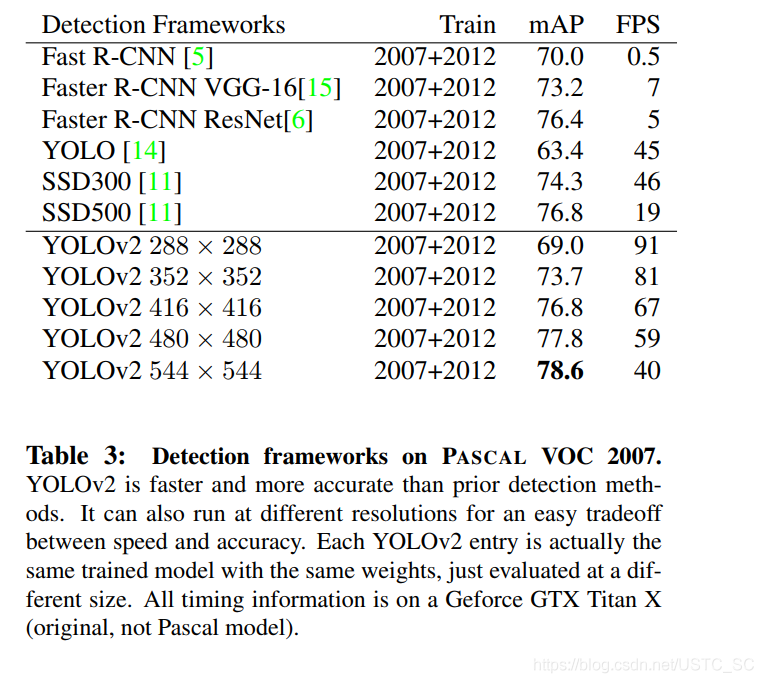
我們改進之後的YOLO-v2,在設計上模型只有折積層和池化層,這也就意味着網路可以動態調整大小,適應不同尺寸的輸入。多尺度訓練作者採用的方法是每10個batches網路隨機選擇圖片大小,由於32倍下採樣,所以輸入尺寸爲32的倍數,大小範圍在{320,352,…,608}這種方法使模型在不同輸入圖片尺寸下都可以預測很好。也就意味着相同的模型可以預測不同尺寸的圖片,這種方法很容易權衡模型精度與速度上的需求,以下圖片顯示了YOLO-v2在不同尺寸下的表現以及其他先進的檢測器。
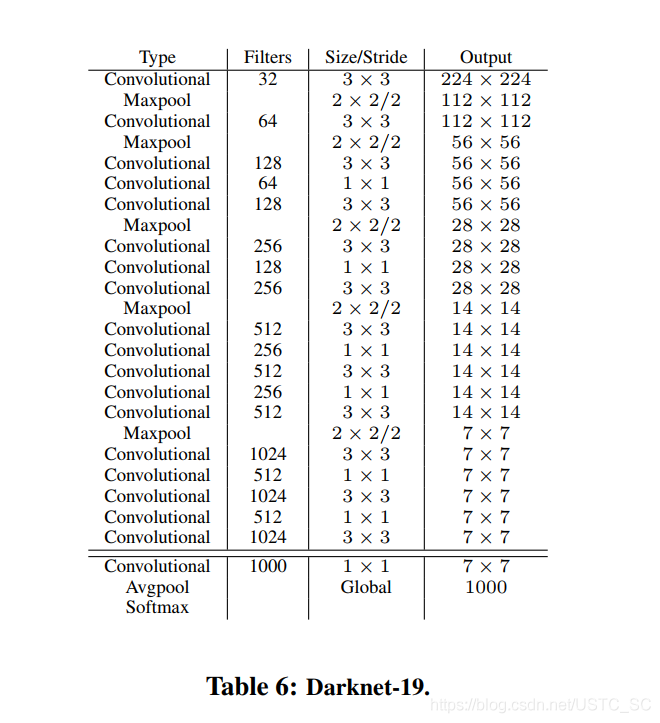
Darknet-19
作者希望YOLO-v2又快又準,大部分檢測框架將VGG16爲基本的特徵提取器,不可否認VGG-16在特徵提取方面的確很強,但是卻也有點複雜,作者結合着VGG-16的和其他網路一些技巧,自定義了Darknet-19網路19個折積層,5個池化層,Darknet-19在精度上有些許落後,但是在參數,複雜度大大低於VGG-16。以下爲Darknet-19的結構圖。
3.WordTree
背景
理想的檢測模型應該又快又準,同時還可以檢測更大範圍的物體,但是實際情況是相對於分類數據集而言目標檢測的數據集很有限。
| 數據集 | 分類數據集 | 檢測數據集 |
|---|---|---|
| 樣本數 | 百萬級 | 成千上萬到幾十萬 |
| 標籤數 | 上萬級 | 幾十到幾百個 |
受限於目標檢測數據集標註成本昂貴,很難將目標檢測數據集規模達到分類數據集的水平,至少短期內不現實,那麼是不是可以通過已有的分類數據集來擴充檢測數據集呢?結合着使用呢?作者就是帶着這樣的想法開始了新方案的探索。
方案
作者的方案就是檢測數據集的圖片學習檢測相關資訊,像bounding box座標預測,目標類別預測,對於只有類別標籤的數據集來擴充可識別的類別。具體就是在訓練過程中混合檢測數據集和分類數據集,當網路發現圖片是檢測數據集時,基於YOLO-v2完整的損失函數進行反向傳播,當遇到圖片是分類數據集,基於模型架構的特定的分類部分進行反向傳播。
這種方案想法很簡單,也很容易理解,那麼也會有一些問題,目標檢測數據集標籤通常是通識物體,比如,貓,狗,而分類數據集通常更加細緻,比如藏獒,哈士奇等等,如果想要合併數據集,必須連貫的合併這些標籤。再者大部分分類使用softmax層計算最後的分佈概率,這其實有一個假設前提類別相互獨立,如果只是簡單合併,不同的數據集類別並不相互獨立,COCO中的某條狗在ImageNet中是哈士奇。
層次分類
ImageNet的命名標籤來自於WordNet,一個用於構建概念和他們相互關係的語言數據庫,WordNet是一種圖形結構而非樹結構,這是因爲語言的複雜性,比如狗既是「犬齒類動物」又是「家養動物」,在這情境下都屬於同義詞,由於WordNet太過於複雜,作者沒有採用全圖結構,而是採用基於ImageNet從WordNet中構建一顆層次樹。爲了構建這棵樹,作者測試ImageNet中的可見物名詞,觀測他們在WordNet圖中到根節點的路徑,這裏簡化根節點爲「客觀實體」。許多同義詞在圖中只有一條路徑,首先將這些路徑加入圖中,然後迭代測試剩下的概念(名詞),把路徑加入樹中使樹的生長儘可能小,打個比方,我們將一個概念加入樹中,他有兩條路徑,一條路徑使樹增加3條邊,另外一條通路只增加一條邊,那麼我們選擇把後一條通路加到樹中。最後構建的就是詞樹,爲了預測累別,計算在每個節點下義詞的條件概率,以下面 下麪「 terrier」節點爲例

如果啊計算一個詞的絕對概率,使用如下公式,我們假定每張圖片包含物體,所以P(physical object)=1

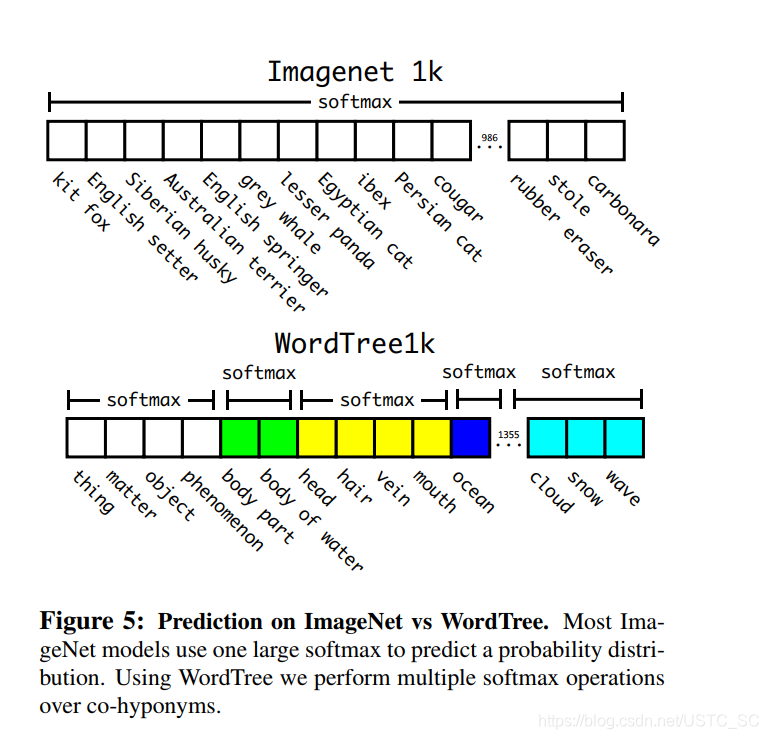
最後基於ImageNet1000構建詞樹,新增中間節點,類別標籤由1000擴充套件到1369,在傳遞過程中真實標籤沿樹向上傳遞,打個比方,一個圖片標籤是「哈士奇」,那麼他也是「狗」,也是 「 哺乳動物 」 等等這些屬於同一概念,在計算時計算屬於同一個概唸的所有下義詞的softmax,就像下圖一樣,一般分類是求一個大的softmax,而使用WordTree,我們執行多個softmax操作的共下位詞.
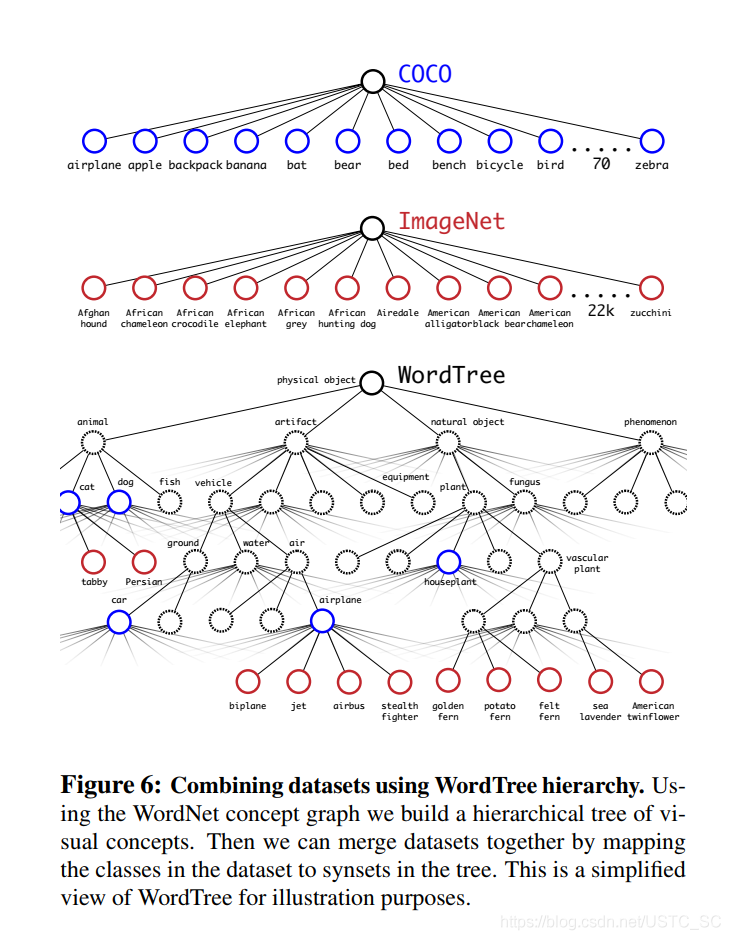
作者使用COCO檢測數據集和ImageNet分類數據集聯合訓練,構建詞樹如下,並且由於ImageNet比COCO數據集大得多,所以對COCO過採樣平衡數據集,使最後ImageNet只比COCO大四倍。
4.小結
YOLO-V2是一個先進的實時檢測系統,提升速度與精度上提出了很多新奇有效的方法,可以執行在不同尺寸大小圖片的上,也使得可以很好地權衡速度與精度。同時YOLO9000使用WordTree來結合來自不同來源的數據,並使用聯合優化技術在ImageNet和COCO上同時進行訓練。YOLO-v2的很多技巧都可以很好地運用在其他場合任務中。