Linux進程的管理與排程(四)--- 內核執行緒、輕量級進程、使用者執行緒三種執行緒概念解惑(執行緒≠輕量級進程)
一、執行緒與進程概念
在現代操作系統中,進程支援多執行緒。
- 進程是資源管理的最小單元。
- 執行緒是程式執行的最小單元。
即執行緒作爲排程和分配的基本單位,進程作爲資源分配的單位。
一個進程的組成實體可以分爲兩大部分:執行緒集和資源集。
進程中的執行緒是動態的物件;代表了進程指令的執行。
資源,包括地址空間、開啓的檔案、使用者資訊等,由進程內的執行緒節享。
二、執行緒概唸的產生
2.1 傳統單執行緒進程的缺點
- 現實中有很多需要併發處理的任務,如數據庫的伺服器端、網路伺服器、大容量計算等。
- 傳統的UNIX進程是單執行緒的,單執行緒意味着程式必須是順序執行,不能併發;既在一個時刻只能執行在一個處理器上,因此不能充分利用多處理器框架的計算機。
- 如果採用多進程的方法,則有如下問題:
(1)fork 一個子進程的消耗是很大的,fork 是一個昂貴的系統呼叫,即使使用現代的寫時複製(copy on write)技術。
(2)各個進程擁有自已獨立的地址空間,進程間的共同作業需要複雜的IPC 技術,如訊息傳遞 和共用記憶體等。
2.2 多執行緒的優缺點
多執行緒的優點和缺點實際上是對立和統一的。
支援多執行緒的程式(進程)可以取得直正的並行(parallelism),且由於共用進程的程式碼和全域性數據,幫執行緒間的通訊是最方便的。
它的缺點也是由於執行緒共用進程的地址空間,因此可能會導致競爭,因此對某一塊有多個執行緒要存取的數據南非要一些同步技術。
2.3 執行緒的設計過程演變
在操作系統設計上,從進程演化出線程,最主要的目的就是更好的支援SMP 以及減小(進程/執行緒)上下文切換開銷。
2.4 SMP機器上多執行緒的並行性
無論按照怎樣的方法,一個進程至少需要一個執行緒作爲它的指令執行體,進程管理資源(比如CPU、記憶體、檔案等),而將執行緒分配到某個CPU 上執行。
一個進程當然可以擁有多個執行緒,此時,如果進程執行在SMP 機器上,它就可以同時使用多個CPU 來執行各個執行緒,達到最大程度的並行,以提高效率;
同時,即使是在單CPU 的機器上,採用多執行緒模型來設計程式,正如當年採用多進程模型代替單進程模型一樣,使設計更簡潔、功能更完備,程式的執行效率也更高。
例如採用多個執行緒響應多個輸入,而此時多執行緒模型所實現的功能實際上也可以用多過程模型來實現。
而與後者相比,執行緒的上下文切換開銷就比進程要小很多了,
從語意上來說,同時響應多個輸入這樣的功能,實際上就是共用了除CPU 以外的所有資源的。
2.5 執行緒模型 - 核心級執行緒和使用者級執行緒
針對執行緒模型的兩大意義,分別開發出了核心級執行緒和使用者級執行緒兩種執行緒模型,
分類的標準主要是執行緒的排程者在覈內還是在覈外。
前者更利於併發使用多處理器資源,而後者則更多考慮的是止下文切換開銷。
可以參考:《執行緒的3種實現方式–內核級執行緒, 使用者級執行緒和混合型執行緒》
2.6 目前的實現策略
在止前的商用系統中,通常都將兩者結合起來使用,既提供核心執行緒以滿足SMP系統的需要,
也支援用執行緒庫的方式在使用者態實現另一套執行緒機制 機製,此時一個核以執行緒同時成爲多個使用者態執行緒的排程者。
正如很多技術一樣,」混合「通常都能帶來更高的效率,但同時也帶來更大的實現難度,
出於」簡單「的設計思路,Linux從一開始就沒有實現混合模型的計劃,但它在實現上採用了另一種思路的」混合「。
線上程機制 機製的具體實現上,可以操作系統內核實現執行緒,也可以在覈外實現,後者顯然要求核內至少實現了進程,而前者則一般要求在覈內同時也支援進程。核心執行緒模型顯然要求前者的支援,而使用者級執行緒模型則不一定基於後者實現。這種差異,正如前者所述,是兩種分類方式的標準不同帶來的。
當核內既支援執行緒時,就可以實現執行緒—進程的多對多模型,即一個進程的某個執行緒由核內排程,而同時它可以作爲使用者級執行緒池的排程者,選擇合適的使用者級執行緒在其實間中執行。這就是前面提到的」混合「執行緒模型,既可以滿足多外理器系統的需要,也可以最大限度的減小排程者開銷。
絕大多數商業操作系統(如 Digital Unix,Solaris,Irix)都採用的這種能夠完全實現POSIX 1003.1C 標準的執行緒模型。
在覈外實現的執行緒又可以分爲」一對一「、」多對一「兩種模型,前者用一個核心進程(也許是輕量級進程)對應一個執行緒,將執行緒排程等同於進程排程,交給核心完成,而後者則完全在覈外實現多執行緒,排程也在使用者態完成。後者就是前面提到的單純的使用者執行緒模型的實現方式,顯然這種核外的執行緒排程器實際上只需要完成執行緒執行棧的切換,排程開銷非常小,但同時因爲核心信號(無論是同步的還是非同步的)都是以進程爲單位的,因而無法定位到執行緒,所以這種實現方式不能用於多處理器系統,而這個需求正變得越來越大,因此,在現實中,純使用者執行緒的實現,除演算法研究目的以外,幾乎已經消失了。
Linux 內核只提供了輕量進程的支援,限制了更高效的執行緒模型的實現,但Linux 着重優化了進程的排程開銷,一定程式一也彌補了這一缺陷。
目前,最流行的執行緒機制 機製Linux Threads 所採用的就是執行緒-進程 」一對一「 模型,排程交給核心,而在使用者級實現一個包括信號處理在內的執行緒管理機制 機製。
三、三種執行緒概念——內核執行緒、輕量級進程、使用者執行緒
3.1 內核執行緒
內核執行緒就是內核的分身,一個分身可以處理一件特定事情。這在處理非同步事件如非同步IO時特別有用。
內核執行緒的使用是廉價的,唯一使用的資源就是內核棧和上下文切換時儲存暫存器的空間。支援多執行緒的內核叫做多執行緒內核(Multi-Threads kernel )。
內核執行緒只執行在內核態,不受使用者態上下文的拖累。
- 處理器競爭:可以在全系統範圍內競爭處理器資源;
- 使用資源:唯一使用的資源是內核棧和上下文切換時保持暫存器的空間
- 排程:排程的開銷可能和進程自身差不多昂貴
- 同步效率:資源的同步和數據共用比整個進程的數據同步和共用要低一些。
3.2 輕量級進程
輕量級進程(LWP)是建立在內核之上並由內核支援的使用者執行緒,它是內核執行緒的高度抽象,每一個輕量級進程都與一個特定的內核執行緒關聯。內核執行緒只能由內核管理並像普通進程一樣被排程。
a LWP runs in user space on top of a single kernel thread and shares its address space and system resources with other LWPs within the same process
輕量級進程由clone()系統呼叫建立,參數是CLONE_VM,即與父進程是共用進程地址空間和系統資源。
與普通進程區別:LWP只有一個最小的執行上下文和排程程式所需的統計資訊。
- 處理器競爭:因與特定內核執行緒關聯,因此可以在全系統範圍內競爭處理器資源
- 使用資源:與父進程共用進程地址空間
- 排程:像普通進程一樣排程
輕量級執行緒(LWP)是一種由內核支援的使用者執行緒。
它是基於內核執行緒的高階抽象,因此只有先支援內核執行緒,才能 纔能有LWP。
每一個進程有一個或多個LWPs,每個LWP由一個內核執行緒支援。
這種模型實際上就是恐龍書上所提到的一對一執行緒模型。在這種實現的操作系統中,LWP就是使用者執行緒。
由於每個LWP都與一個特定的內核執行緒關聯,因此每個LWP都是一個獨立的執行緒排程單元。即使有一個LWP在系統呼叫中阻塞,也不會影響整個進程的執行。
輕量級進程具有侷限性。
- 首先,大多數LWP的操作,如建立、解構以及同步,都需要進行系統呼叫。系統呼叫的代價相對較高:需要在user mode和kernel mode中切換。
- 其次,每個LWP都需要有一個內核執行緒支援,因此LWP要消耗內核資源(內核執行緒的棧空間)。因此一個系統不能支援大量的LWP。
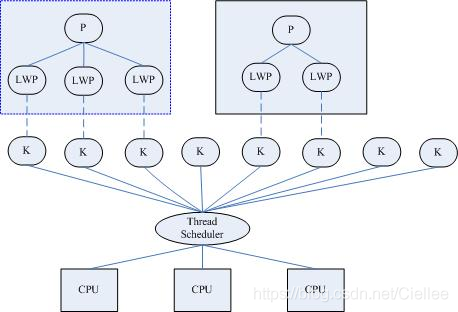
注:
- LWP的術語是借自於SVR4/MP和Solaris 2.x。
- 有些系統將LWP稱爲虛擬處理器。
- 將之稱爲輕量級進程的原因可能是:在內核執行緒的支援下,LWP是獨立的排程單元,就像普通的進程一樣。所以LWP的最大特點還是每個LWP都有一個內核執行緒支援。
3.3 使用者執行緒
使用者執行緒是完全建立在使用者空間的執行緒庫,使用者執行緒的建立、排程、同步和銷燬全又庫函數在使用者空間完成,不需要內核的幫助。因此這種執行緒是極其低消耗和高效的。
- 處理器競爭:單純的使用者執行緒是建立在使用者空間,其對內核是透明的,因此其所屬進程單獨參與處理器的競爭,而進程的所有執行緒參與競爭該進程的資源。
- 使用資源:與所屬的進程共用進程地址空間和系統資源。
- 排程:由在使用者空間實現的執行緒庫,在所屬進程內進行排程
LWP雖然本質上屬於使用者執行緒,但LWP執行緒庫是建立在內核之上的,LWP的許多操作都要進行系統呼叫,因此效率不高。
而這裏的使用者執行緒指的是完全建立在使用者空間的執行緒庫,使用者執行緒的建立,同步,銷燬,排程完全在使用者空間完成,不需要內核的幫助。因此這種執行緒的操作是極其快速的且低消耗的。
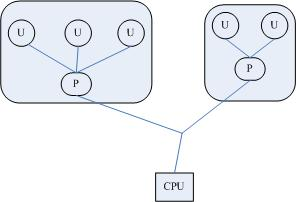
上圖是最初的一個使用者執行緒模型,從中可以看出,進程中包含執行緒,使用者執行緒在使用者空間中實現,內核並沒有直接對使用者執行緒進程排程,內核的排程物件和傳統進程一樣,還是進程本身,內核並不知道使用者執行緒的存在。
使用者執行緒之間的排程由在使用者空間實現的執行緒庫實現。
這種模型對應着恐龍書中提到的多對一執行緒模型,其缺點是一個使用者執行緒如果阻塞在系統呼叫中,則整個進程都將會阻塞。
3.4 加強版的使用者執行緒——使用者執行緒+LWP
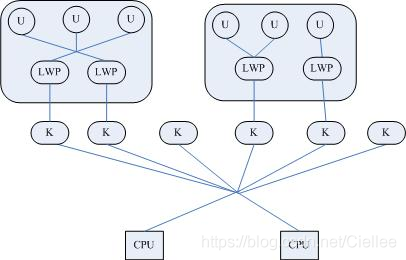
這種模型對應着恐龍書中多對多模型。
使用者執行緒庫還是完全建立在使用者空間中,因此使用者執行緒的操作還是很廉價,因此可以建立任意多需要的使用者執行緒。
操作系統提供了LWP作爲使用者執行緒和內核執行緒之間的橋樑。LWP還是和前面提到的一樣,具有內核執行緒支援,是內核的排程單元,並且使用者執行緒的系統呼叫要通過LWP,因此進程中某個使用者執行緒的阻塞不會影響整個進程的執行。
使用者執行緒庫將建立的使用者執行緒關聯到LWP上,LWP與使用者執行緒的數量不一定一致。當內核排程到某個LWP上時,此時與該LWP關聯的使用者執行緒就被執行。
3.5 Linux使用的執行緒庫
LinuxThreads是使用者空間的執行緒庫,所採用的是執行緒-進程1對1模型(即一個使用者執行緒對應一個輕量級進程,而一個輕量級進程對應一個特定的內核執行緒),將執行緒的排程等同於進程的排程,排程交由內核完成,而執行緒的建立、同步、銷燬由核外執行緒庫完成(LinuxThtreads已系結到 GLIBC中發行)。
在LinuxThreads中,由專門的一個管理執行緒處理所有的執行緒管理工作。
當進程第一次呼叫**pthread_create()建立執行緒時就會先 建立(clone())並啓動管理執行緒。
後續進程pthread_create()建立執行緒時,都是管理執行緒作爲pthread_create()的呼叫者的子執行緒,
通過呼叫clone()**來建立使用者執行緒,並記錄輕量級進程號和執行緒id的對映關係,
因此,使用者執行緒其實是管理執行緒的子執行緒。
LinuxThreads只支援排程範圍爲PTHREAD_SCOPE_SYSTEM的排程,預設的排程策略是SCHED_OTHER。
使用者執行緒排程策略也可修改成SCHED_FIFO或SCHED_RR方式,這兩種方式支援優先順序爲0-99,而SCHED_OTHER只支援0。
- SCHED_OTHER 分時排程策略,
- SCHED_FIFO 實時排程策略,先到先服務
- SCHED_RR 實時排程策略,時間片輪轉
SCHED_OTHER是普通進程的,後兩個是實時進程的(一般的進程都是普通進程,系統中出現實時進程的機會很少)。
SCHED_FIFO、 SCHED_RR優先順序高於所有SCHED_OTHER的進程,所以只要他們能夠執行,
在他們執行完之前,所有SCHED_OTHER的進程的都沒有得到 執行的機會
本文學自:
《內核執行緒、輕量級進程、使用者執行緒三種執行緒概念解惑(執行緒≠輕量級進程)》
《關於進程、執行緒和輕量級進程的一些筆記》
《執行緒的3種實現方式–內核級執行緒, 使用者級執行緒和混合型執行緒》