02數據採集與操作
目錄
•常用格式的本地數據讀寫
•Python的數據庫基本操作
•數據庫多表連線
•爬蟲簡介
•BeautifulSoup解析網頁
•爬蟲框架Scrapy基礎
•Logistic 迴歸
•實戰案例:獲取國內城市空氣品質指數數據
•常用格式的本地數據讀寫
txt
•由字串行組成,每行由EOL (End Of Line) 字元隔開,‘\n’
•開啓檔案 注意編碼
•file_obj= open(filename, access_mode)
•access_mode: ‘r’,‘w’
•讀操作
•file_obj.read() 讀取整個檔案內容
•file_obj.readline() 逐行讀取
•file_obj.readlines() 返回列表,列表中的每個元素是行內容
•寫操作
•file_obj.write() 將內容寫入檔案
•file_obj.writelines() 將字串列表內容逐行寫入檔案
構造字串列表兩種方式:
#構造字串列表
lines=[]
for n in range(100):
line='這是第 %i行\n' %n
lines.append(line)
lines=['這是第 %i行\n' %n for n in range(100)]
開啓檔案兩種方式:
text_filename='./Data_Set_File/python_baidu.txt'
#開啓檔案
file_obj=open(text_filename,'r',encoding='utf-8')
lines=file_obj.readlines()
for i,line in enumerate(lines):
print('{}---{}'.format(i,line))
#關閉檔案
file_obj.close()
enumerate
text_filename='./Data_Set_File/test_write.txt'
#with 語句,包括了例外處理,自動呼叫檔案關閉操作,推薦使用
with open(text_filename,'r',encoding='utf-8') as f_obj:
print(f_obj.readline())
csv
以純文字形式儲存的表格數據(以逗號作爲分隔符),通常第一行爲列名
•讀操作
•df_obj= pd.read_csv(),返回DataFrame型別的數據
•寫操作
•df_obj.to_csv()
Pandas
•基於NumPy構建
•索引在左,數值在右。索引是pandas自動建立的。
•數據結構
•Series,類似於一維陣列的物件。
•DataFram,表格型數據結構,每列可以是不同的數據型別,可表示二維或更高維的數據
JSON (JavaScript Object Notation)
•輕量級的數據交換格式
•語法規則
•數據是鍵值對
•由逗號分隔
•{}儲存物件,如{key1:val1, key2,:val2}
•[]儲存陣列,如[val1, val2, …, valn]
•讀操作
•json.load(file_obj)
•返回值是dict型別
•型別轉換json-> csv
•編碼操作
•json.dumps()
•編碼注意•ensure_ascii=False
#[{'書名': '道德經', '作者': '老子'}, {'書名': '道德經2', '作者': '老子'}]
#上述數據的載入與數據操作分類
import json
filename='./Data_Set_File/json_output.json'
with open (filename,'r',encoding='utf-8') as f_obj:
json_data=json.load(f_obj) #返回值是list型別
print(type(json_data))
print(json_data)
lists1=[]
lists2=[]
for json in json_data:
for i,x in enumerate(json.values()):
if i%2==0:
lists1.append(x)
else:
lists2.append(x)
print(lists1)
print(lists2)
XLS/XLSX (Excel檔案)
•常用的電子表格數據
•檔案操作
•利用pandas處理,快捷方便
•讀操作•df_obj= pd.read_excel(),返回DataFrame型別的數據
•寫操作
•df_obj.to_excel()
•具體操作參考pandas如何處理CSV檔案
(excel先轉爲csv)
•Python的數據庫基本操作
SQLite
一種整合在程式中的嵌入式的輕量級數據庫
•關係型數據庫管理系統
•嵌入式數據庫,適用於嵌入式裝置
•SQLite不是C/S的數據庫引擎
•整合在使用者程式中
•實現了大多數SQL標準
SQLite
•連線數據庫
•conn = sqlite3.connect(db_name
•如果db_name存在,讀取數據庫
•如果db_name不存在,新建數據庫
•獲取遊標
•conn.cursor()
•一段私有的SQL工作區,用於暫時存放受SQL語句影響的數據
CRUD操作
•cursor.execute(sql_str)
•cursor.executemany(sql_str) 批次操作
•fetchone()
•fetchall()
•conn.commit(),提交操作
•關閉連線 conn.close()
SQL基礎
SQL 是用於存取和處理數據庫的標準的計算機語言。
這類數據庫包括:MySQL、SQL Server、Access、Oracle、Sybase、DB2 等等。
SQL 能做什麼?
SQL 面向數據庫執行查詢
SQL 可從數據庫取回數據
SQL 可在數據庫中插入新的記錄
SQL 可更新數據庫中的數據
SQL 可從數據庫刪除記錄
SQL 可建立新數據庫
SQL 可在數據庫中建立新表
SQL 可在數據庫中建立儲存過程
SQL 可在數據庫中建立檢視
SQL 可以設定表、儲存過程和檢視的許可權
SQLite基本操作
•連線數據庫
import sqlite3
db_path='./Data_Set_File/test.sqlite'
conn=sqlite3.connect(db_path)
cur=conn.cursor() #獲取遊標,一段私有的SQL工作區,用於暫時存放受SQL語句影響的數據
conn.text_factory=str #處理中文
cur.execute('SELECT SQLITE_VERSION()')
print('SQLite版本:',str(cur.fetchone()[0]))
•逐條插入數據
# 判斷表是否存在
cur.execute("DROP TABLE IF EXISTS book")
# 新建表
cur.execute("CREATE TABLE book(id INT, name TEXT, price DOUBLE)")
# 逐行插入數據
cur.execute("INSERT INTO book VALUES(1,'肖秀榮考研書系列:肖秀榮(2017)考研政治命題人終極預測4套卷',14.40)")
cur.execute("INSERT INTO book VALUES(2,'法醫秦明作品集:倖存者+清道夫+屍語者+無聲的證詞+第十一根手指(套裝共5冊) (兩種封面隨機發貨)',100.00)")
cur.execute("INSERT INTO book VALUES(3,'活着本來單純:豐子愷散文漫畫精品集(收藏本)',30.90)")
cur.execute("INSERT INTO book VALUES(4,'自在獨行:賈平凹的獨行世界',26.80)")
cur.execute("INSERT INTO book VALUES(5,'當你的才華還撐不起你的夢想時',23.00)")
cur.execute("INSERT INTO book VALUES(6,'巨人的隕落(套裝共3冊)',84.90)")
cur.execute("INSERT INTO book VALUES(7,'孤獨深處(收錄雨果獎獲獎作品《北京摺疊》)',21.90)")
cur.execute("INSERT INTO book VALUES(8,'世界知名企業員工指定培訓教材:所謂情商高,就是會說話',22.00)")
•建表批次插入數據
#建company表,並插入數據
cur.execute("DROP TABLE IF EXISTS company ")
cur.execute("CREATE TABLE company(\
id INT PRIMARY KEY NOT NULL,\
name CHAR(50) NOT NULL,\
age INT NOT NULL,\
address CHAR(50) NOT NULL,\
salary DOUBLE NOT NULL)")
companies=(
(1,'li ming',32,'china',15000.0),
(2,'zhangsan',25,'japan',16000.0),
(3,'lisi',27,'california',17000.0),
(4,'mazi',24,'texas',18000.0),
(5,'little mazi',22,'norway',19000.0),
(6,'middle mazi',23,'country1',20000.0),
(7,'big mazi',26,'country2',21000.0)
)
cur.executemany("INSERT INTO company VALUES(?,?,?,?,?)",companies)
SQL語句:
1>DROP TABLE IF EXISTS book
2>CREATE TABLE book(id INT, name TEXT)
3>INSERT INTO book VALUES()
4>SELECT emp_id,name,dept FROM company CROSS JOIN department
5>SELECT emp_id,name,dept FROM company LEFT OUTER JOIN department ON company.id=department.emp_id
其他常用數據庫的連線
Mysql
MongoDB分佈式數據庫
PostgreSQL(Django推薦與PostgreSQL配合使用)
Oracle適用於各類大、中、小、微機環境。它是一種高效率、可靠性好的適應高吞吐量的數據庫解決方案
•數據庫多表連線
多表連線
•查詢記錄時將多個表中的記錄連線(join)並返回結果
•join方式
•交叉連線(cross join)
•內連線(inner join)
•外連線(outer join)
•cross join
•生成兩張表的笛卡爾積
•返回的記錄數爲兩張表的記錄數的乘積
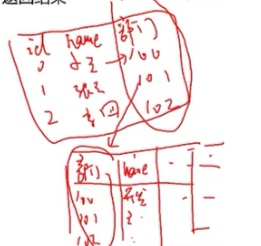
查詢小王所處部門名稱或其他資訊(多錶鏈接:兩張表通過一列聯繫起來)
•inner join
•生成兩張表的交集
•返回的記錄數爲兩張表的交集的記錄數
•outer join
•left join (A,B),返回表A的所有記錄,另外表B中匹配的記錄有值,沒有匹配的記錄返回null
•right join (A,B),返回表B的所有記錄,另外表A中匹配的記錄有值,沒有匹配的記錄返回null
•[注]目前在sqlite3中不支援,可考慮交換A、B表操作
CROSS JOIN交叉連線
cur.execute("SELECT emp_id,name,dept FROM company CROSS JOIN department")
rows=cur.fetchall()
for row in rows:
print(row)
INNER JOIN內連線
cur.execute("SELECT emp_id,name,dept FROM company INNER JOIN department\
ON company.id=department.emp_id;") #做了個交集
rows=cur.fetchall()
for row in rows:
print(row)
OUTER 外連線
#左鏈接left join (A,B)
#返回表A的所有記錄,另外表B中匹配的記錄有值,沒有匹配的記錄返回null
##右鏈接,sqlite3中不支援,可考慮交換A、B表操作
cur.execute("SELECT emp_id,name,dept FROM company LEFT OUTER JOIN department\
ON company.id=department.emp_id;")
rows=cur.fetchall()
for row in rows:
print(row)
•爬蟲簡介
爬蟲
•自動抓取網際網路資訊的程式
•利用網際網路數據進行分析、開發產品
爬蟲基本架構
•URL 管理模組
•對計劃爬取的或已經爬取的URL進行管理
•網頁下載模組
•將URL管理模組中指定的URL進行存取下載
•網頁解析模組
•解析網頁下載模組中的URL,處理或儲存數據
•如果解析到要繼續爬取的URL,返回URL管理模組繼續回圈
URL管理模組
•防止重複爬取或回圈指向
•實現方式
•Python的set數據結構,原因?
•數據庫中的數據表,how?
•快取數據庫Redis,適用於大型網際網路公司
URL下載模組
•將URL對應的網頁下載到本地或讀入記憶體(字串)
•實現方式
•urllib,Python官方基礎模組
•requests或其他第三方的模組
1>通過URL直接下載
#python3.x
import urllib.request
test_url="http://www.google.com"
test_url2="http://www.baidu.com"
#通過url下載
respose=urllib.request.urlopen(test_url2)
print(respose.getcode()) #200表示存取成功
print(respose.read())
2>通過Request存取下載
# 通過Request存取
request = urllib.request.Request(test_url2)
#request.add_header("user-agent", "Mozilla/5.0")
response = urllib.request.urlopen(request)
print(response.getcode()) # 200 表示存取成功
print(response.read())
3>通過Cookie存取下載
# 通過cookie存取
import http.cookiejar
cookie_jar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie_jar))
urllib.request.install_opener(opener)
response = urllib.request.urlopen(test_url2)
print(response.getcode()) # 200 表示存取成功
print(response.read())
print(cookie_jar)
網頁解析模組
從網頁中提取數據有很多方法,概況起來大概有這麼三種方式,首先是正則,然後是流行的Beautiful Soup模組,最後是強大的Lxml模組。
1、正則表達式:最原始的方法,通過編寫一些正則表達式,然後從HTML/XML中提取數據。
2、Beautiful Soup模組:Beautiful Soup 是一個可以從 HTML 或 XML 檔案中提取數據的 Python 庫.它能夠通過你喜歡的轉換器實現慣用的文件導航,查詢,修改文件的方式.Beautiful Soup 會幫你節省數小時甚至數天的工作時間。
3、Lxml模組:lxml是基於libxm12這一XML解析庫的Python封裝,該模組使用C語言編寫,解析速讀比Beautiful Soup模組快,不過安裝更爲複雜。
•從已下載的網頁中爬取數據
•實現方式
•正則表達式,字串的模糊匹配
•html.parser
•BeautifulSoup,結構化的網頁解析
•lxml
結構化解析
•DOM (Document Object Model),樹形結構
•BeautifulSoup解析網頁
BeautifulSoup
•用於解析HTML或XML
•pip install beautifulsoup4
•import bs4
•步驟
- 建立BeautifulSoup物件
- 查詢節點
find,找到第一個滿足條件的節點
find_all, 找到所有滿足條件的節點
建立物件
• 建立BeautifulSoup物件
• bs= BeautifulSoup(
url,
html.parser, 指定解析器
from_enoding 指定編碼格式(確保和網頁編碼格式一致)
)
from bs4 import BeautifulSoup
import urllib.request
html=urllib.request.urlopen("http://www.baidu.com") #開啓網址
bs_obj=BeautifulSoup(html,'html.parser',from_encoding='utf-8') #建立BeautifulSoup物件,返回DOM樹形結構
print(bs_obj.title) #物件的一個屬性
print(bs_obj)
查詢節點
<a href=‘a.html’ class=‘a_link’> next page</a>
•可按節點型別、屬性或內容存取
•按型別查詢節點
•bs.find_all(‘a’)
# 提取所有鏈接
print('1.提取所有鏈接:\n')
link_list=bs_obj.find_all('a')
for link in link_list:
print(link) #<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print(link.name, link['href'], link.get_text()) # #link['href']按照存取鍵值對的方式,把key放進去
#a http://example.com/elsie Elsie
•按屬性查詢節點
•bs.find_all(‘a’, href=‘a.html’)
•bs.find_all(‘a’, href=‘a.html’, string=‘next page’)
•bs.find_all(‘a’, class_=‘a_link’)
•注意:是class_
# 提取一條鏈接
#屬性:id,class_,href,string
print('2.提取一條鏈接:\n')
link1=bs_obj.find('a',id="link1")
print(link1.name,link1['href'],link1.get_text())
link2=bs_obj.find('a',string="Tillie")
print(link2.name,link2['href'],link2.get_text())
print('3.再提取一條鏈接:\n')
links=bs_obj.find_all('a',class_="sister") #注意:是class_
for link in links:
print(link.name,link['href'],link.get_text()) #get_text()獲取節點文字
獲取節點資訊
•node是已查詢到的節點
•node.name 獲取節點標籤名稱
•node[’href’] 獲取節點href屬性
•node.get_text() 獲取節點文字
例外處理
•網路資源或URL是經常變動的
•需要處理異常
# 建立一個完整的函數處理title
def get_html_title(url):
"""
獲取url地址的title
"""
try:
html = urllib.request.urlopen(url)
except Exception as e:
return None
try:
bs_obj = BeautifulSoup(html.read(), 'html.parser')
title = bs_obj.title
except Exception as e:
return None
return title
title = get_html_title("http://www.jd.com")
if title is not None:
print(title)
else:
print("Title獲取失敗!")
BeautifulSoup進階
•使用CSS選擇器方式、正則表達式查詢節點
•儲存解析的內容
•DOM樹形結構
children 只返回「孩子」節點
desecdants返回所有「子孫」節點
next_siblings返回下一個「同輩」節點
previous_siblings返回上一個「同輩」節點
parent 返回「父親」節點
CSS方式查詢節點
import urllib.request
from bs4 import BeautifulSoup
#html = urllib.request.urlopen("https://hao.360.com/?wd_xp1")
html = '''
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
<a href="http://example.com/elsie" class="sister" id="link1">
<span>zhangsan</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">lisi</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">mazi</a>
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
</p>
'''
bs_obj = BeautifulSoup(html, 'html.parser')
bs_obj.prettify() ##prettify實現格式化的輸出
nav = bs_obj.find("p", {"class" : "story"}) #CSS鍵值對方式進行條件篩選
print(nav)
print(nav.get_text())
nav_list = bs_obj.find_all("p", {"class" : "story"})
for nav in nav_list:
print("zz",nav)
print(nav.get_text())
#儲存解析的內容
nav_name_list=[nav.get_text() for nav in nav_list]
print(nav_name_list)
# 儲存到檔案中
with open('./Data_Set_File/output.txt', 'w', encoding='utf-8') as f:
for i,nav_name in enumerate( nav_name_list):
f.write('{}--{}\n\n\n\n\n\n\n\n\n\n'.format(i,nav_name))
樹形結構
# contents:獲取直接子節點,返回list型別
print(bs_obj.p.contents)
# children,返回的是可以迭代的,直接列印輸出None
for i in bs_obj.p.children:
print("xx",i)
#children孩子節點
for i,child in enumerate(bs_obj.find("p", {"class" : "story"}).children):
print(i,child)
#descendants子孫節點
for i,child in enumerate(bs_obj.find("p", {"class" : "story"}).descendants):
print(i,child)
#next_siblings同輩節點
for i,sibling in enumerate(bs_obj.find("p", {"class" : "story"}).next_siblings):
print(i,sibling)
#parent父親節點,previous_siblings同輩節點
#print(bs_obj.find("p", {"class" : "story"}).parent)
for i,sibling in enumerate(bs_obj.find("p", {"class" : "story"}).parent.previous_siblings):
print(i,sibling)
#print(bs_obj.find("p", {"class" : "story"}).parent.get_text())
正則表達式
•簡單的字串匹配可以使用字串方法完成
•複雜、模糊的字串匹配使用正則表達式,如:電子郵箱格式匹配
•通過使用單個字串描述匹配一系列符合某個語法規則的字串
•字串操作的邏輯公式
•常用於處理文字數據
•匹配過程:依次拿出表達式和文字中的字元作比較,如果每個字元都能匹配,則匹配成功;否則失敗
•import re
•pattern = re.compile(‘str’) 返回pattern物件
•推薦使用r’str’ 無需考慮跳脫字元
•pattern.match()
•基本語法
正則表達式語法
file_obj=open("./poem.txt")
lines=file_obj.readlines()
text=""
for i,line in enumerate(lines):
#print('{}---{}'.format(i,line))
text=text+line
file_obj.close()
#print(text)
import re
result=re.findall(" to ",text)
print(len(result))
#查詢以a開頭三個字母的 單詞
result2=re.findall("a..",text) #一個點表示任意一個字元
print(len(result2))
#過濾空格
result3=re.findall("a[a-z][a-z]",text)
print(len(result3))
#print(result3)
#前後空格
result4=re.findall(" a[a-z][a-z] ",text)
print(len(result4))
#print(result4)
#去掉單詞前後的空格
result5=re.findall(" (a[a-z][a-z]) ",text)
print(result5)
#去掉重複的單詞
result6=set(result5)
print(result6) #{'ash', 'air', 'are', 'all', 'and'}
#加上以A開頭的三個字母的單詞
result7=re.findall(" *([Aa][a-z][a-z]) ",text) #空格+*表示可以沒空格,可以是一個空格,兩個空格或多個空格
print(set(result7))
#{'ash', 'any', 'all', 'ars', 'ake', 'ace', 'And', 'ath', 'arp', 'are', 'air', 'ast', 'age', 'ain', 'ade', 'ard', 'ame', 'ant', 'afe', 'ave', 'All', 'ads', 'ags', 'and'}
#不行
result7=re.findall(" (a[a-z][a-z]) |(A[a-z][a-z]) ",text)
print(set(result7))
final_result=set()
for pair in set(result7):
if pair[0] is "":
final_result.add(pair[1])
if pair[1] is "":
final_result.add(pair[0])
#final_result.remove("")
print(final_result)
# \d表示任意一個數字 ,+表示至少有一個
file_obj=open("./poem.txt")
lines=file_obj.readlines()
text=""
for i,line in enumerate(lines):
#print('{}---{}'.format(i,line))
text=text+line
file_obj.close()
#print(text)
result=re.findall("\d+",text)
print(result)
result2=re.findall("\d{2}",text) #剛好匹配兩個數位
print(result2)
result2=re.findall("\d{2,3}",text) #匹配兩個或三個數位
print(result2)
result=re.findall("\w{2,3}",text) #\w表示字母,[A-Za-z]
print(result)
使用正則表達式查詢節點
import urllib.request
from bs4 import BeautifulSoup
import re
html = urllib.request.urlopen("http://www.pythonscraping.com/pages/page3.html")
bs_obj = BeautifulSoup(html, 'html.parser', from_encoding='uf-8')
#print(bs_obj)
images = bs_obj.find_all("img", {"src":re.compile(r"\.\./img/gifts/img.*\.jpg")})
#images = bs_obj.findAll("img", src=re.compile(r"\.\./img/gifts/img.*\.jpg"))
#images = bs_obj.findAll("img", {"src":re.compile(r"\.\./img/gifts/img.*\.jpg")})
for image in images:
print(image["src"])
import urllib.request
from bs4 import BeautifulSoup
import re
html = urllib.request.urlopen("http://baike.baidu.com/item/Python/407313?fr=aladdin")
bs_obj = BeautifulSoup(html, 'html.parser', from_encoding='uf-8')
for link in bs_obj.find("div", {"class":"main-content"}).findAll("a", href=re.compile("^(/view/)((?!:).)*$")):
if 'href' in link.attrs:
print('{}: {}'.format(link.attrs['href'], link.get_text()))
\.\./img/gifts/img.*\.jpg
^(/view/)((?!:).)*$
•爬蟲框架Scrapy基礎
Scrapy簡介
•開源的爬蟲框架
•快速強大,只需編寫少量程式碼即可完成爬取任務
•易擴充套件,新增新的功能模組
Scrapy抓取過程
•使用start_urls作爲初始url生成Request,預設將parse作爲他的回撥函數
•在parse函數中解析目標url
Scrapy高階特性
•內建數據抽取器css/xpath/re
•互動式控制檯用於偵錯
•結果輸出的格式支援,JSON, CSV, XML等
•自動處理編碼
•支援自定義擴充套件
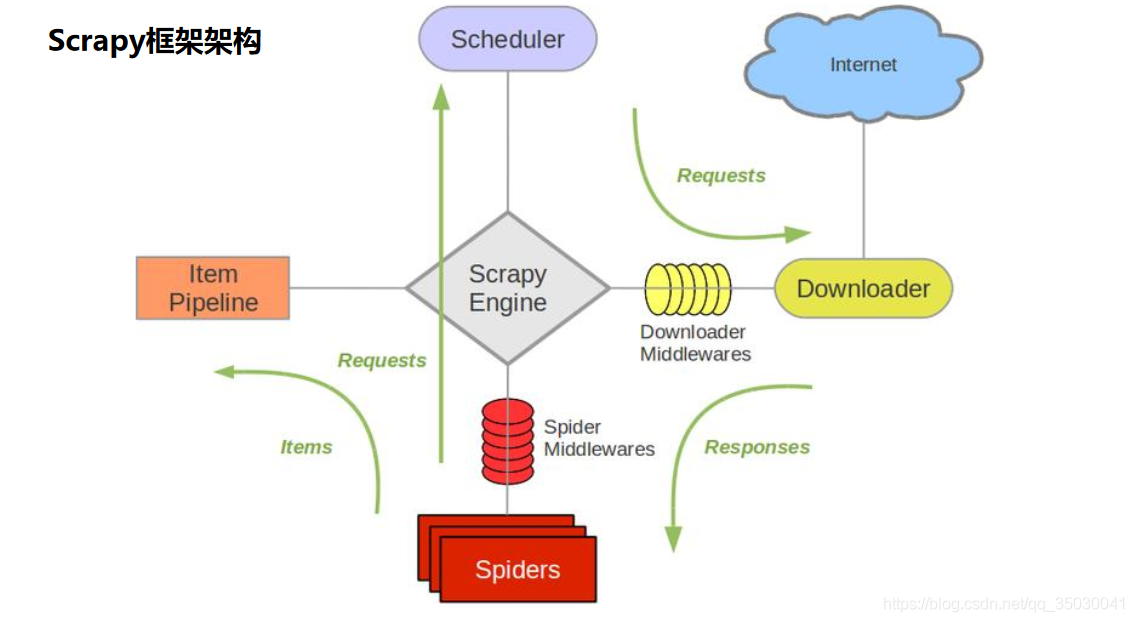
Scrapy使用步驟
•安裝:pip install scrapy(可能需要額外安裝visual c++build tools)
•1. 建立工程
•2. 定義Item,構造爬取的物件(可選)
•3. 編寫Spider,爬蟲主體
•4. 編寫設定和Pipeline,用於處理爬取的結果(可選)
•5. 執行爬蟲
Scrapy使用步驟
- 建立工程
•scrapy startproject air_quality
•目錄結構 - 編寫Spider
. •scrapy genspider aqi_history_spider https://www.aqistudy.cn/historydata/index.php - 執行Spider
•scrapy crawl aqi_history_spider
Scrapy使用步驟
4. 定義Item
•scrapy.Field()
5. 編寫Spider
•呼叫自定義的Item
6. pipelines
•預設return item
7. 執行Spider
•scrapy crawl aqi_history_spider
Scrapy常用命令
•help: 檢視幫助,
scrapy–help
•version: 檢視版本資訊,
•scrapy version, 檢視scrapy版本
•scrapy version –v,檢視相關模組的版本
•新建工程,
scrapy startproject porj_name
•生成spider模板,
scrapy genspider spider_name url
•list,列出所有的spider,
scrapy list
•view, 返回網頁原始碼並在瀏覽器中開啓,
scrapy view url
•有時頁面渲染的結果和檢視結果是不同的
•parse, 呼叫工程spider中的parse解析url,
scrapy parse url
•shell, 進入互動式偵錯模式,
scrapy shell url
•bench, 可以用來檢測scrapy是否安裝成功
•…
新建框架工程和執行都在命令列
如何新建scrapy工程:
1.找到想要建立的目標工程路徑cmd
2.建立工程
scrapy startproject air_quality
3.進入.cfg目錄
cd air_quality
4.生成spider模板
scrapy genspider aqi_history_spider https://www.aqistudy.cn/historydata/index.php
5.執行
scrapy crawl aqi_history_spider
•實戰案例:獲取國內城市空氣品質指數數據
專案任務
1.掌握Scrapy框架的基本操作
2.能夠爬取簡單的頁面數據
3.掌握深度數據的爬取及廣度數據的爬取
偵錯:
根目錄下scrapy shell https://www.aqistudy.cn/historydata/index.php
檢視 response
檢視 response.xpath(’//div[@class=「all」]//div[@class=「bottom」]//a//@href’)
附錄鏈接: