elasticsearch介紹與使用
Elasticsearch全文檢索
1.全文檢索概念
我們生活中的數據分爲結構化數據和非結構化數據:
- 結構化數據:具有固定格式或有限長度的數據,可以用二維表結構來邏輯表達實現的,如數據庫,元數據等。
- 非結構化數據:指不定長或無固定格式的數據,如辦公文件、文字、圖片、XML、HTML、各類報表、影象和音訊/視訊資訊等等。也叫全文數據。
- 對於結構化數據的搜尋:如對數據庫的搜尋,用 SQL 語句。再如對元數據的搜尋,如利用windows 搜尋對檔名,型別,修改時間進行搜尋等。
- 對非結構化數據的搜尋:如利用 windows 的搜尋也可以搜尋檔案內容,Linux 下的 grep命令,再如用 Google 和百度可以搜尋大量內容數據。
對非結構化數據也即對全文數據的搜尋主要有兩種方法:
- 一種是順序掃描法:比如在一個專案中找一個介面名爲 queryTest 的介面,就是在專案裡一個檔案一個檔案的找,對於每個文件從頭到尾的去找,直到掃描專案裏面的所有檔案。window 的搜尋檔案內容,linux 的 grep 命令就是如此的。小數據量的檔案還可以接受,如果對於大量的檔案,方法就很慢了。
- 另一種方法就是通過索引:把非結構化數據重新設計成有一定的結構,利用結構化的數據採取一定的搜尋演算法加快速度。把非結構化數據中提取出的然後重新組織的資訊,稱之爲索引。比如字典,字典的拼音表和部首檢字表就是相當於字典的索引,對每一個字的解釋就是非結構化的,如果字典沒有音節表和部首檢字表,在茫茫辭海中找一個字只能順序掃描。
然而字的某些資訊可以提取出來進行結構化處理,比如讀音,就比較結構化,分聲母和韻母,分別只有幾種可以一一列舉,於是將讀音拿出來按一定的順序排列,每一項讀音都指向此字的詳細解釋的頁數。我們搜尋時按結構化的拼音搜到讀音,然後按其指向的頁數,便可找到我們的非結構化數據——也即對字的解釋。
這種先建立索引,再對索引進行搜尋的過程叫全文檢索。
通俗解釋,全文檢索是指計算機索引程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當使用者查詢時,檢索程式就根據事先建立的索引進行查詢,並將查詢的結果反饋給使用者的檢索方式。
全文檢索大體分兩個過程,索引建立(Indexing)和搜尋索引(Search)。
索引建立:將現實世界中所有的結構化和非結構化數據提取資訊,建立索引的過程。
搜尋索引:通過使用者的查詢請求搜尋建立的索引,然後返回查詢結果的過程。
2.背景與發展
搜尋引擎的發生背景在因特網發展初期,網站相對較少,新聞查詢比較容易。然而隨着新聞技術的飛速發展,特別是因特網應用的迅速普及,網站越來越多,並且每天全球網際網路網頁數目以千萬級的數量增加。要在浩瀚的網路新聞中尋找所需要的材料無異於大海撈針。這時爲滿足人人新聞檢索需求的搜尋網站應運而生。
技術發展:lucene—>solr—>elasticsearch
2.1. lucene
2.1.1 介紹
官網地址:
https://lucene.apache.org/
2.1.2 lucene起源

- 1997 年年末,Doug Cutting (lucene 的原作者) 因爲工作不穩定,產生了把自己的一些軟體商業化的想法。再加上當時 Java 已經是一門炙手可熱的程式語言 , 作者也正好需要一個學習它的理由。因爲作者以前有編寫搜尋軟體的經驗,於是覺得可以用 Java 寫一個搜尋軟體以維持生計。於是 lucene 就此誕生。
- 2000 年 ,作者由於對商業運作並沒有什麼興趣 ,就把 lucene 放到了 SourceForge 上 , 希望通過開源的方式來讓自己保持程式創作的激情。
- 2001 年 , 此時的 lucene 已經吸引了一些人使用 , Apache 希望能夠接收 lucene 專案 。從此 lucene 變得真正活躍起來 , 有一些志願者加入到 lucene 的開發中。不過此時原作者 Doug Cutting 任然是唯一的核心開發者。
- 2010 年 ,原作者已經不再參與 lucene 的日常開發和維護了 , 已經有很多對 lucene 核心有着深入瞭解的開發者參與到專案中。
- lucene 發展出了C++ , C# , Prel , Python 等其他語言的版本。
2.1.3 lucene優點和侷限
優點:
1.穩定,索引效能高
現代磁碟上每小時能夠索引150GB以上的數據;
對記憶體的要求小——只需要1MB的堆記憶體;
增量索引和批次索引一樣快;
索引的大小約爲索引文字大小的20%~30%;
2.高效、準確、高效能的搜尋演算法
搜尋排名——最好的結果顯示在最前面;
許多強大的查詢型別:短語查詢、萬用字元查詢、近似查詢、範圍查詢等;
對欄位級別搜尋(如標題,作者,內容);
可以對任意欄位排序;
支援搜尋多個索引併合並搜尋結果;
支援更新操作和查詢操作同時進行;
靈活的切面、高亮、join和group by功能;
速度快,記憶體效率高,容錯性好;
可選排序模型,包括向量空間模型和BM25模型;
可設定儲存引擎;
3.跨平臺解決方案
作爲 Apache 開源許可,在商業軟體和開放程式中都可以使用 Lucene;
100%純Java編寫;
對多種語言提供介面;
侷限:
只能基於Java語言開發
類庫的介面學習曲線陡峭
原生並不支援水平擴充套件
2.2. solr
2.2.1 介紹
Solr是一個採用Java開發,基於Lucene的全文搜尋伺服器,同時對其進行了擴充套件,提供了比Lucene更爲豐富的查詢語言,同時實現了可設定、可延伸並對查詢效能進行了優化,並且提供了一個完善的功能管理介面,是一款非常優秀的全文搜尋引擎。它對外提供類似於Web-service的API介面。使用者可以通過http請求,向搜尋引擎伺服器提交一定格式的XML檔案,生成索引;也可以通過Http Get操作提出查詢請求,並得到XML格式的返回結果。
官網地址:
https://lucene.apache.org/solr/
2.2.2 solr優點
①高階的全文搜尋功能;
②專爲高通量的網路流量進行的優化;
③基於開放介面(XML和HTTP)的標準;
④綜合的HTML管理介面;
⑤可伸縮性-能夠有效地複製到另外一個Solr搜尋伺服器;
⑥使用XML設定達到靈活性和適配性;
⑦可延伸的外掛體系。
2.3. Elasticsearch
2.3.1介紹
官方網址:https://www.elastic.co/cn/products/elasticsearch
Github :https://github.com/elastic/elasticsearch
總結:
1、elasticsearch是一個基於Lucene的高擴充套件的分佈式搜尋伺服器,支援開箱即用。
2、elasticsearch隱藏了Lucene的複雜性,對外提供Restful 介面來操作索引、搜尋。
突出優點:
- 支援分佈式,擴充套件性好,可部署上百台伺服器叢集,處理PB級數據。
- 近實時的去索引數據、搜尋數據。
- 降低全文檢索的學習曲線,可以被任何程式語言呼叫

2.3.2 ElasticSearch VS Solr
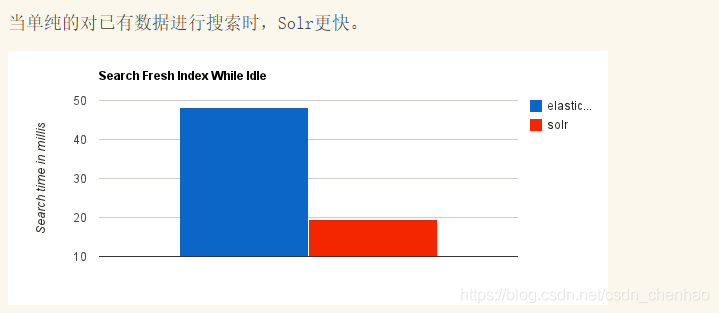
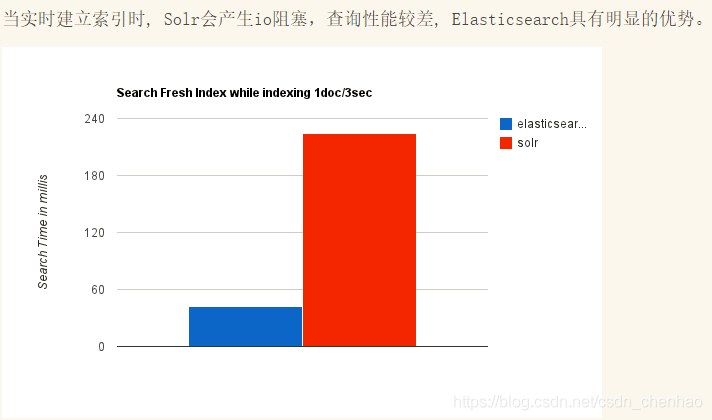
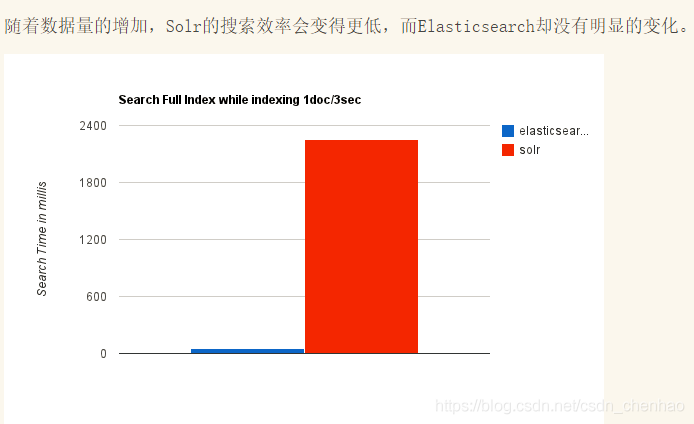
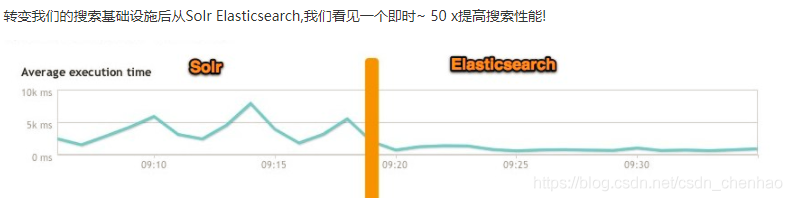
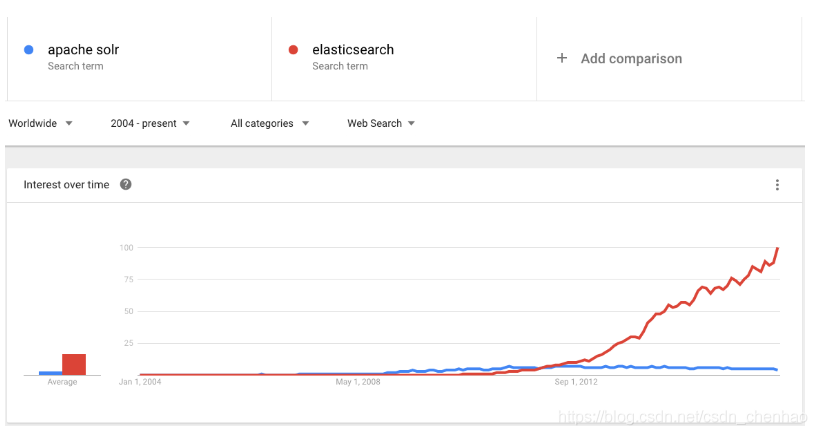
- 近幾年的流行趨勢
我們檢視一下這兩種產品的Google搜尋趨勢。谷歌趨勢表明,與 Solr 相比,Elasticsearch具有很大的吸引力,但這並不意味着Apache Solr已經死亡。雖然有些人可能不這麼認爲,但Solr仍然是最受歡迎的搜尋引擎之一,擁有強大的社羣和開源支援。
總結:
(1)es基本是開箱即用,非常簡單。Solr安裝略微複雜一丟丟,可關注
(2)Solr 利用 Zookeeper 進行分佈式管理,而 Elasticsearch 自身帶有分佈式協調管理功能。
(3)Solr 支援更多格式的數據,比如JSON、XML、CSV,而 Elasticsearch 僅支援json檔案格式。
(4)Solr 官方提供的功能更多,而 Elasticsearch 本身更注重於核心功能,高階功能多有第三方外掛提供,例如圖形化介面需要kibana友好支撐
(5)Solr 查詢快,但更新索引時慢(即插入刪除慢),用於電商等查詢多的應用;ES建立索引快,即實時性查詢快,用於facebook新浪等搜尋。Solr 是傳統搜尋應用的有力解決方案,但 Elasticsearch 更適用於新興的實時搜尋應用。
3.功能和使用場景
3.1功能
第一、分佈式的搜尋引擎和數據分析引擎
搜尋:百度,網站的站內搜尋,IT系統的檢索
數據分析:
電商網站,最近一週手機商品銷量排名前10的商家有哪些;
新聞網站,最近1個月存取量排名前3的新聞版塊是哪些
第二、 全文檢索,結構化檢索,數據分析
全文檢索:我想搜尋商品名稱包含手機的商品,select * from products where product_name like 「%手機%」
結構化檢索:我想搜尋商品分類爲電子數碼的商品都有哪些,select * from products where category_id=‘電子數碼’
部分匹配、自動完成、搜尋糾錯、搜尋推薦
數據分析:我們分析每一個商品分類下有多少個商品,select category_id,count(*) from products group by category_id
第三、對海量數據進行近實時的處理
分佈式:ES自動可以將海量數據分散到多臺伺服器上去儲存和檢索
海量數據的處理:分佈式以後,就可以採用大量的伺服器去儲存和檢索數據,自然而然就可以實現海量數據的處理了
近實時:檢索個數據要花費1小時(這就不要近實時,離線批次處理,batch-processing);在秒級別對數據進行搜尋和分析
跟分佈式/海量數據相反的:lucene,單機應用,只能在單台伺服器上使用,最多隻能處理單台伺服器可以處理的數據量
3.2使用場景
- 非結構化數據查詢(結構化也行)
- 適用於海量數據的快速檢索
- 日誌數據分析,logstash採集日誌,ES進行復雜的數據分析
4.工作原理
4.1 基本概念
-
倒排索引(Inverted Index):
該索引表中的每一項都包括一個屬性值和具有該屬性值的各記錄的地址。由於不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置,因而稱爲倒排索引(inverted index)。Elasticsearch能夠實現快速、高效的搜尋功能,正是基於倒排索引原理。 -
索引(Index):
Elasticsearch 數據管理的頂層單位就叫做 Index(索引),相當於關係型數據庫裡的數據庫的概念。另外,每個Index的名字必須是小寫。 -
型別(Type):
Document 可以分組,比如employee這個 Index 裏面,可以按部門分組,也可以按職級分組。這種分組就叫做 Type,它是虛擬的邏輯分組,用來過濾 Document,類似關係型數據庫中的數據表。 -
文件(Document):
index裏面單條的記錄稱爲 Document(文件)。多條 Document 構成了一個 Index。Document 使用 JSON 格式表示。同一個 Index 裏面的 Document,不要求有相同的結構(scheme),但是最好保持相同,這樣有利於提高搜尋效率。 -
文件元數據(Document metadata):
文件元數據爲_index, _type, _id, 這三者可以唯一表示一個文件,_index表示文件在哪存放,_type表示文件的物件類別,_id爲文件的唯一標識。 -
欄位(Fields):
每個Document都類似一個JSON結構,它包含了許多欄位,每個欄位都有其對應的值,多個欄位組成了一個 Document,可以類比關係型數據庫數據表中的欄位。
在 Elasticsearch 中,文件(Document)歸屬於一種型別(Type),而這些型別存在於索引(Index)中,下圖展示了Elasticsearch與傳統關係型數據庫的類比:

4.2索引結構
下圖是ElasticSearch的索引結構,下邊黑色部分是物理結構,上邊黃色部分是邏輯結構,邏輯結構也是爲了更好的去描述ElasticSearch的工作原理及去使用物理結構中的索引檔案。

邏輯結構部分是一個倒排索引表:
1、將要搜尋的文件內容分詞,所有不重複的詞組成分詞列表。
2、將搜尋的文件最終以Document方式儲存起來。
3、每個詞和docment都有關聯。
例如:
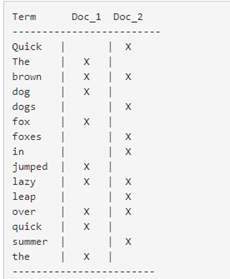
現在,如果我們想搜尋 quick brown ,我們只需要查詢包含每個詞條的文件:

兩個文件都匹配,但是第一個文件比第二個匹配度更高。如果我們使用僅計算匹配詞條數量的簡單 相似性演算法 ,那麼,我們可以說,對於我們查詢的相關性來講,第一個文件比第二個文件更佳。
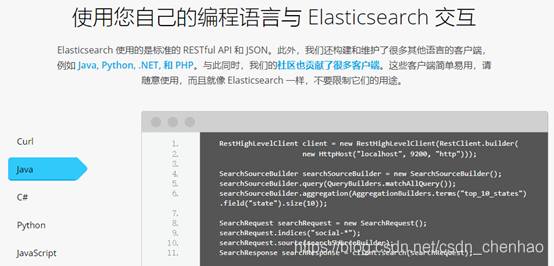
4.3RESTful應用方法
Elasticsearch提供 RESTful Api介面進行索引、搜尋,並且支援多種用戶端。
下圖是es在專案中的應用方式:
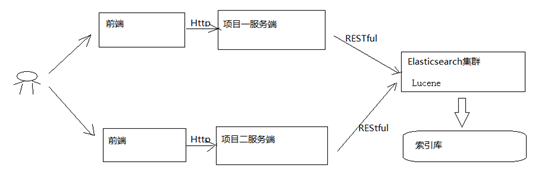
1)使用者在前端搜尋鍵碼
2)專案前端通過http方式請求專案伺服器端
3)專案伺服器端通過Http RESTful方式請求ES叢集進行搜尋
4)ES叢集從索引庫檢索數據。
5. 使用
5.1 ElasticaSearch 安裝
安裝設定:
1、新版本要求至少jdk1.8以上。
2、支援tar、zip、rpm等多種安裝方式。
在windows下開發建議使用ZIP安裝方式。
3、支援docker方式安裝
詳細參見:https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
下載 ES: Elasticsearch 7.8.0
https://www.elastic.co/downloads/past-releases
解壓 elasticsearch-7.8.0.zip
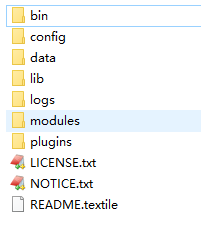
bin:指令碼目錄,包括:啓動、停止等可執行指令碼
config:組態檔目錄
data:索引目錄,存放索引檔案的地方
logs:日誌目錄
modules:模組目錄,包括了es的功能模組
plugins :外掛目錄,es支援外掛機制 機製
5.2組態檔
使用zip、tar安裝,組態檔的地址在安裝目錄的config下,組態檔如下:
- elasticsearch.yml : 用於設定Elasticsearch執行參數
- jvm.options : 用於設定Elasticsearch JVM設定
- log4j2.properties: 用於設定Elasticsearch日誌
elasticsearch.yml:
cluster.name: demo
node.name: demo_node_1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
#discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: false
node.max_local_storage_nodes: 1
path.data: D:\ElasticSearch\elasticsearch‐6.2.1\data
path.logs: D:\ElasticSearch\elasticsearch‐6.2.1\logs
http.cors.enabled: true //允許跨域
http.cors.allow‐origin: /.*/ //允許所有路徑跨域
注意path.data和path.logs路徑設定正確!!!
參數解釋:
cluster.name:
設定elasticsearch的叢集名稱,預設是elasticsearch。建議修改成一個有意義的名稱。
node.name:
節點名,通常一臺物理伺服器就是一個節點,es會預設隨機指定一個名字,建議指定一個有意義的名稱,方便管理一個或多個節點組成一個cluster叢集,叢集是一個邏輯的概念,節點是物理概念
network.host:
設定系結主機的ip地址,設定爲0.0.0.0表示系結任何ip,允許外網存取,生產環境建議設定爲具體的ip。
http.port: 9200
設定對外服務的http埠,預設爲9200。
transport.tcp.port: 9300
叢集結點之間通訊埠
node.master:
指定該節點是否有資格被選舉成爲master結點,預設是true,如果原來的master宕機會重新選舉新的master。
node.data:
指定該節點是否儲存索引數據,預設爲true。
discovery.zen.ping.unicast.hosts: [「host1:port」, 「host2:port」, 「…」]
設定叢集中master節點的初始列表。
discovery.zen.minimum_master_nodes:
主結點數量的最少值 ,此值的公式爲:(master_eligible_nodes / 2) + 1 ,比如:有3個符合要求的主結點,那麼這裏要設定爲2。
bootstrap.memory_lock:
true 設定爲true可以鎖住ES使用的記憶體,避免記憶體與swap分割區交換數據。
node.max_local_storage_nodes:
單機允許的最大儲存結點數,通常單機啓動一個結點建議設定爲1,開發環境如果單機啓動多個節點可設定大於1.
path.conf:
設定組態檔的儲存路徑,tar或zip包安裝預設在es根目錄下的config資料夾,rpm安裝預設在/etc/
elasticsearch path.data:
設定索引數據的儲存路徑,預設是es根目錄下的data資料夾,可以設定多個儲存路徑,
用逗號隔開。
path.logs:
設定日誌檔案的儲存路徑,預設是es根目錄下的logs資料夾 path.plugins: 設定外掛的存
放路徑,預設是es根目錄下的plugins資料夾
discovery.zen.ping.timeout: 3s
設定ES自動發現節點連線超時的時間,預設爲3秒,如果網路延遲高可設定大些。
叢集搭建:copy一份,修改elasticsearch.yml中:node.name,network.host,http.port,transport。tcp.port,path.data,path.logs即可。(注意節點數量設定)
5.3 啓動
進入bin目錄,在cmd下執行:elasticsearch.bat
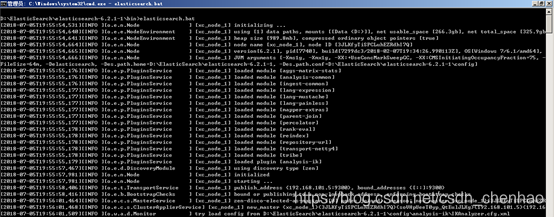
瀏覽器輸入:http://localhost:9200
顯示結果如下(設定不同內容則不同)說明 ES啓動成功:
{
"name" : "demo_node_1",
"cluster_name" : "demo",
"cluster_uuid" : "L0DJsrmCSN-lhQiky7rybw",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
5.4建立索引庫
ES的索引庫是一個邏輯概念,它包括了分詞列表及文件列表,同一個索引庫中儲存了相同類型的文件。它就相當於MySQL中的表,或相當於Mongodb中的集合。
關於索引這個語:
索引(名詞):ES是基於Lucene構建的一個搜尋服務,它要從索引庫搜尋符合條件索引數據。
索引(動詞):索引庫剛建立起來是空的,將數據新增到索引庫的過程稱爲索引。
下邊介紹兩種建立索引庫的方法,它們的工作原理是相同的,都是用戶端向ES服務發送命令。
1)使用postman或curl這樣的工具建立:
put http://localhost:9200/索引庫名稱
{
"settings":{
"index":{
"number_of_shards":1,
"number_of_replicas":0
}
}
}
number_of_shards:設定分片的數量,在叢集中通常設定多個分片,表示一個索引庫將拆分成多片分別儲存不同的結點,提高了ES的處理能力和高可用性,這裏設定爲1。
number_of_replicas:設定副本的數量,設定副本是爲了提高ES的高可靠性,單機環境設定爲0。
2)使用head圖形化外掛建立
5.5建立對映
- 概念說明:
在索引中每個文件都包括了一個或多個field,建立對映就是向索引庫中建立field的過程,下邊是document和field與關係數據庫的概唸的類比:
文件(Document)----------------Row記錄
欄位(Field)-------------------Columns 列
注意:6.0之前的版本有type(型別)概念,type相當於關係數據庫的表,ES官方將在ES9.0版本中徹底刪除type。
上邊講的建立索引庫相當於關係數據庫中的數據庫還是表?
1、如果相當於數據庫就表示一個索引庫可以建立很多不同類型的文件,這在ES中也是允許的。
2、如果相當於表就表示一個索引庫只能儲存相同類型的文件,ES官方建議 在一個索引庫中只儲存相同類型的文件。
5.5.1 ik分詞器
使用IK分詞器可以實現對中文分詞的效果。
下載IK分詞器:(Github地址:https://github.com/medcl/elasticsearch-analysis-ik)
下載zip:
解壓,並將解壓的檔案拷貝到ES安裝目錄的plugins下的ik目錄下
注意:分詞器版本和elasticsearch版本一致
ik分詞器有兩種分詞模式:ik_max_word和ik_smart模式。
ik_max_word
會將文字做最細粒度的拆分
比如會將「中華人民共和國人民大會堂」拆分爲「中華人民共和國、中華人民、中華、
華人、人民共和國、人民、共和國、大會堂、大會、會堂等詞語。
ik_smart
會做最粗粒度的拆分
比如會將「中華人民共和國人民大會堂」拆分爲中華人民共和國、人民大會堂。
- 自定義詞庫
如果要讓分詞器支援一些專有詞語,可以自定義詞庫。
iK分詞器自帶一個main.dic的檔案,此檔案爲詞庫檔案。
在上邊的目錄中新建一個my.dic檔案(注意檔案格式爲utf-8(不要選擇utf-8 BOM))
可以在其中自定義詞彙:
比如定義:
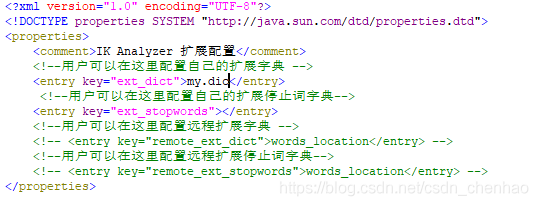
在組態檔IKAnalyzer.cfg.xml中設定自定義my.dic
5.5.2ElasticSearch 常用欄位型別
- 核⼼數據型別
- 複雜數據類
- 專用數據型別

核心的欄位型別:
(1)字串
text ⽤於全⽂索引,搜尋時會自動使用分詞器進⾏分詞再匹配
keyword 不分詞,搜尋時需要匹配完整的值,如:郵政編碼、手機號碼、身份證等。keyword欄位通常用於過慮、排序、聚合等。
{
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"index": true, //預設true
"store": false, //預設false
}
}
- type:型別,這裏爲字串,其它型別見上圖;
- analyzer:通過analyzer屬性指定分詞器。使用ik分詞器的ik_max_word分詞模式,上邊指定了analyzer是指在索引和搜尋都使用ik_max_word,如果單獨想定義搜尋時使用的分詞器則可以通過search_analyzer屬性。分詞顆粒度ik_max_word大於ik_smart。對於ik分詞器建議是索引時使用ik_max_word將搜尋內容進行細粒度分詞,搜尋時使用ik_smart提高搜尋精確性。
- index:通過index屬性指定是否索引。預設爲index=true,即要進行索引,只有進行索引纔可以從索引庫搜尋到。也有一些內容不需要索引,比如:商品圖片地址只被用來展示圖片,不進行搜尋圖片,此時可以將index設定爲false。
- store:是否在source之外儲存,每個文件索引後會在 ES中儲存一份原始文件,存放在"_source"中,一般情況下不需要設定store爲true,因爲在_source中已經有一份原始文件了。
(2)數值型
整型: byte,short,integer,long
浮點型: float, half_float, scaled_float,double
(3)日期型別
date
日期型別不用設定分詞器。通常日期型別的欄位用於排序。通過format設定日期格式
例子:
下邊的設定允許date欄位儲存年月日時分秒、年月日及毫秒三種格式。
"timestamp": {
"type": "date",
"format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd"
}
(4)範圍型
integer_range, long_range, float_range,double_range,date_range
比如招聘要求年齡在[20, 40]上,mapping:
age_limit :{
"type" : "integer_range"
}
"age_limit" : {
"gte" : 20,
"lte" : 40
}
(5)布爾
boolean #true、false
(6)⼆進位制
binary 會把值當做經過 base64 編碼的字串
複雜數據型別:
(1)物件object
定義mapping:
"user" : {
"type":"object"
}
插入數據:
"user" : {
"name":"chy",
"age":12
}
(2)陣列
定義mapping:
"arr" : {
"type":"integer"
}
插入數據:
"arr" : [1,3,4]
專用數據型別:
ip型別
ip型別的欄位用於儲存IPV4或者IPV6的地址
定義mapping:
"ip_address" : {
"type":"ip"
}
插入數據:
"ip_address" : "192.168.1.1"
6.5.3 建立對映
例如:把課程資訊儲存到ES中,這裏我們建立課程資訊的對映:
發送:post http://localhost:9200/索引庫名稱 /型別名稱/_mapping
建立型別爲demo_course的對映
post 請求:http://localhost:9200/demo_course/doc/_mapping
{
"properties":{
"description":{
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart",
"type":"text"
},
"grade":{
"type":"keyword"
},
"id":{
"type":"keyword"
},
"mt":{
"type":"keyword"
},
"name":{
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart",
"type":"text"
},
"users":{
"index":false,
"type":"text"
},
"charge":{
"type":"keyword"
},
"valid":{
"type":"keyword"
},
"pic":{
"index":false,
"type":"keyword"
},
"qq":{
"index":false,
"type":"keyword"
},
"price":{
"type":"float"
},
"price_old":{
"type":"float"
},
"st":{
"type":"keyword"
},
"status":{
"type":"keyword"
},
"studymodel":{
"type":"keyword"
},
"teachmode":{
"type":"keyword"
},
"teachplan":{
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart",
"type":"text"
},
"expires":{
"type":"date",
"format":"yyyy‐MM‐ddHH:mm:ss"
},
"pub_time":{
"type":"date",
"format":"yyyy‐MM‐ddHH:mm:ss"
},
"start_time":{
"type":"date",
"format":"yyyy‐MM‐ddHH:mm:ss"
},
"end_time":{
"type":"date",
"format":"yyyy‐MM‐ddHH:mm:ss"
},
"update_time":{
"type":"date",
"format":"yyyy‐MM‐ddHH:mm:ss"
}
}
}
5.6新增文件
ES中的文件相當於MySQL數據庫表中的記錄。
發送:put 或Post http://localhost:9200/demo_course/doc/id值
(如果不指定id值ES會自動生成ID)
{
"qq":"78698789",
"price_old":168,
"st":"1-3-4",
"charge":"203003",
"mt":"1-3",
"pubTime":"2020-07-13 09:50:00",
"studymodel":"201202",
"description":"水情水調中心",
"pic":"template_overwrite",
"teachplan":"{}",
"users":"asus",
"valid":"204002",
"price":68,
"grade":"200004",
"name":"智慧管理平臺",
"id":"wrweyttwetwrer33343",
"timestamp":1594604940000
}
5.7搜尋文件
1、根據課程id查詢文件
發送:get http://localhost:9200/demo_course/doc/4028e58161bcf7f40161bcf8b77c0000
2、查詢所有記錄
發送 get http://localhost:9200/demo_course/doc/_search
3、查詢名稱中包括spring 關鍵字的的記錄
發送:get http://localhost:9200/ demo_course/doc/_search?q=name:spring
4、查詢學習模式爲201001的記錄
發送 get http://localhost:9200/ demo_course/doc/_search?q=studymodel:201001
分析搜尋結果:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "demo_course",
"_type": "doc",
"_id": "5UJI3HMBW7M_WXPelPnL",
"_score": 1,
"_source": {
"qq": "78698789",
"price_old": 168,
"st": "1-3-4",
"charge": "203003",
"mt": "1-3",
"pubTime": "2020-07-13 09:50:00",
"studymodel": "201202",
"description": "水情水調中心",
"pic": "template_overwrite",
"teachplan": "{}",
"users": "asus",
"valid": "204002",
"price": 68,
"grade": "200004",
"name": "智慧管理平臺",
"id": "wrweyttwetwrer33343",
"timestamp": 1594604940000
}
}
]
}
}
took:本次操作花費的時間,單位爲毫秒。
timed_out:請求是否超時
_shards:說明本次操作共搜尋了哪些分片
hits:搜尋命中的記錄
hits.total : 符合條件的文件總數 hits.hits :匹配度較高的前N個文件
hits.max_score:文件匹配得分,這裏爲最高分
_score:每個文件都有一個匹配度得分,按照降序排列。
_source:顯示了文件的原始內容。
5.7.1查詢語法
葉子查詢
葉子查詢子句在特定欄位中查詢特定值,例如:
- match query 模糊匹配——會將關鍵詞分詞再匹配
- term query 精確匹配——不會將關鍵詞分詞直接匹配
- range query 範圍查詢
複合查詢
複合查詢子句包裝其他葉查詢或複合查詢,並用於以邏輯方式組合多個查詢,例如:
- bool query 布爾查詢
- boosting query 助推查詢(常用於降低文件得分,比如售罄或暫不銷售商品沉底)
- constant_score query 恆定分數查詢,,目的就是返回指定的score,一般都結合filter使用,因爲filter context忽略score。
- dis_max query 分離最大化查詢: 將任何與任一查詢匹配的文件作爲結果返回,但只將最佳匹配的評分作爲查詢的評分結果返回
- function_score query 功能評分查詢:它會在查詢結束後對每一個匹配的文件進行一系列的重打分操作,最後以生成的最終分數進行排序。
查詢方式參考官網:https://www.elastic.co/guide/cn/elasticsearch/guide/current/query-dsl-intro.html
5.7.1.1 match query
- match是標準的全文檢索
- 在匹配之前會先對查詢關鍵字進行分詞
- 可以指定分詞器來覆蓋mapping中設定的搜尋分詞器
{
"query": {
"match": {
"name": {
"query": "es是一個優秀的搜尋引擎",
"analyzer": "ik_smart"
}
}
}
}
5.7.1.2 term query
針對某個屬性的查詢,這裏注意 term 不會進行分詞,比如 在 es 中 存了 「集團」 會被分成 「集/團」 當你用 term 去查詢 「集」時能查到,但是查詢 「集團」 時,就什麼都沒有,而 match 就會將詞語分成 「集/團」去查
{
"query": {
"term": {
"name": {
"query": "集團"
}
}
}
}
5.7.1.3 bool query
可以組合多種葉子查詢,包含如下:
-
must:出現於匹配查詢當中,有助於匹配度(_score)的計算
-
filter:必須滿足才能 纔能出現,屬於過濾,不會影響分值的計算,但是會過濾掉不符合的數據
-
should:該條件下的內容是應該滿足的內容,如果符合會增加分值,不符合降低分值,不會不顯示
-
must_not:滿足的內容不會出現,與filter功能相反,屬於過濾,不會影響分值的計算,但是會過濾掉不符合的數據
{
"query": {
"bool": {
"must": [{
"match": {
"name": "花花公子羽絨服"
}
}],
"must_not": [{
"term": {
"proId": 6
}
}],
"should": [{
"terms": {
"name.keyword": ["花花公子暖心羽絨服", "花花公子外套"]
}
}],
"filter": {
"range": {
"createTime": {
"gte": "2019-12-12 17:56:56",
"lte": "2019-12-19 17:56:56",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
}
}
Filter
其實準確來說,ES中的查詢操作分爲2種:查詢(query)和過濾(filter)。查詢即是之前提到的query查詢,它(查詢)預設會計算每個返迴文件的得分,然後根據得分排序。而過濾(filter)只會篩選出符合的文件,並不計算得分,且它可以快取文件。所以,單從效能考慮,過濾比查詢更快。
換句話說,過濾適合在大範圍篩選數據,而查詢則適合精確匹配數據。一般應用時,應先使用過濾操作過濾數據,然後使用查詢匹配數據。
在Filter context中,查詢子句回答問題「此文件是否與此查詢子句匹配?」答案是簡單的「是」或「否」,即不計算分數。過濾器上下文主要用於過濾結構化數據,例如:
- 該食品的生產日期是否在2018-2019之間
- 該商品的狀態是否爲"已上架"
Ps:常用過濾器將由Elasticsearch自動快取,以提高效能。
5.8修改文件
ES更新文件的順序是:先檢索到文件、將原來的文件標記爲刪除、建立新文件、刪除舊文件,建立新文件就會重建索引。
1、完全替換
Post:http://localhost:9200/demo_course/doc/3
{
"name": "spring cloud實戰",
"description": "本課程主要從四個章節進行講解: 1.微服務架構入門 2.spring cloud 基礎入門 3.實戰SpringBoot 4. 註冊中心eureka。 ",
"studymodel": "201001" ,
"price": 5.6
}
2 、區域性更新
下邊的例子是隻更新price欄位。
post: http://localhost:9200/demo_course/doc/3/_update
{
"doc": {
"price": 66.6
}
}
5.9刪除文件
根據id刪除,格式如下:
DELETE /{index}/{type}/{id}
搜尋匹配刪除,將搜尋出來的記錄刪除,格式如下:
POST /{index}/{type}/_delete_by_query
條件刪除:
{
"query": {
"term": {
"studymodel": "201001"
}
}
}
6.javaApi進行增刪改查
6.1 搭建工程
ES提供多種不同的用戶端:
1、TransportClient
ES提供的傳統用戶端,官方計劃8.0版本刪除此用戶端。
2、RestClient
RestClient是官方推薦使用的,它包括兩種:Java Low Level REST Client和 Java High Level REST Client。
ES在6.0之後提供 Java High Level REST Client, 兩種用戶端官方更推薦使用 Java High Level REST Client,不過當前它還處於完善中,有些功能還沒有。
這裏準備採用 Java High Level REST Client,如果它有不支援的功能,則使用Java Low Level REST Client。
6.1.1新增依賴:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch‐rest‐high‐level‐client</artifactId>
<version>6.2.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.2.1</version>
</dependency>
6.1.2application.yml設定
server.port=40100
spring.application.name=search_service
spring.main.allow-bean-definition-overriding=true
# ----------------------------------------
# elasticsearch config
##------------RestClient設定-----------
demo.hostlist=127.0.0.1:9200
demo.course.index=demo_course
demo.course.type=doc
demo.course.source_field=id,name,grade,mt,st,charge,valid,pic,qq,price,price_old,status,studymodel,teachmode,expires,pub_time,start_time,end_time,update_time
##------------RestClient設定設定-----------
# ----------------------------------------
6.1.3設定類
建立ElasticsearchConfig:
package com.nr.esdemo.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 功能描述:
*
* @author chenhao
* @since 2020/7/12
*/
@Configuration
public class ElasticsearchConfig {
@Value("${demo.hostlist}")
private String hostlist;
@Bean
public RestHighLevelClient restHighLevelClient(){
//解析hostlist設定資訊
String[] split = hostlist.split(",");
//建立HttpHost陣列,其中存放es主機和埠的設定資訊
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
//建立RestHighLevelClient用戶端
return new RestHighLevelClient(RestClient.builder(httpHostArray));
}
//專案主要使用RestHighLevelClient,對於低階的用戶端暫時不用
@Bean
public RestClient restClient(){
//解析hostlist設定資訊
String[] split = hostlist.split(",");
//建立HttpHost陣列,其中存放es主機和埠的設定資訊
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
return RestClient.builder(httpHostArray).build();
}
}
6.1.4啓動類
package com.nr.esdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.domain.EntityScan;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
@SpringBootApplication
public class EsdemoApplication {
public static void main(String[] args) {
SpringApplication.run(EsdemoApplication.class, args);
}
}
6.2增刪改查
6.2.1新增文件
//新增文件
@Test
public void testAddDoc() throws IOException {
//準備json數據
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("name", "spring cloud實戰");
jsonMap.put("description", "主要演示增刪改查");
jsonMap.put("studymodel", "201001");
SimpleDateFormat dateFormat =new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss");
jsonMap.put("timestamp", dateFormat.format(new Date()));
jsonMap.put("price", 5.6f);
//索引請求物件
IndexRequest indexRequest = new IndexRequest("demo_course","doc");
//指定索引文件內容
indexRequest.source(jsonMap);
//索引響應物件
IndexResponse indexResponse = restHighLevelClient.index(indexRequest);
//獲取響應結果
DocWriteResponse.Result result = indexResponse.getResult();
System.out.println(result);
}
6.2.2查詢文件
//根據id查詢文件
@Test
public void getDoc() throws IOException {
GetRequest getRequest = new GetRequest(
"demo_course",
"doc",
"40JF3HMBW7M_WXPesfnU");
GetResponse getResponse = restHighLevelClient.get(getRequest);
boolean exists = getResponse.isExists();
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();
System.out.println(sourceAsMap);
}
6.2.3更新文件
//更新文件
@Test
public void updateDoc() throws IOException {
UpdateRequest updateRequest = new UpdateRequest(index, type, "4028e581617f945f01617f9dabc40000");
Map<String, String> map = new HashMap<>();
map.put("name", "spring cloud實戰");
updateRequest.doc(map);
UpdateResponse update = restHighLevelClient.update(updateRequest);
RestStatus status = update.status();
System.out.println(status);
}
6.2.4刪除文件
//根據id刪除文件
@Test
public void testDelDoc() throws IOException {
//刪除文件id
String id = "40JF3HMBW7M_WXPesfnU";
//刪除索引請求物件
DeleteRequest deleteRequest = new DeleteRequest(index, type, id);
//響應物件
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest);
//獲取響應結果
DocWriteResponse.Result result = deleteResponse.getResult();
System.out.println(result);
}
6.2.5分頁查詢
//分頁查詢
@Test
public void testPageQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//分頁查詢,設定起始下標,從0開始
searchSourceBuilder.from(0);
//每頁顯示個數
searchSourceBuilder.size(10);
//source源欄位過慮
searchSourceBuilder.fetchSource(new String[]{"name", "studymodel"}, new String[]{});
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
}
6.2.6term Query
Term Query爲精確查詢,在搜尋時會整體匹配關鍵字,不再將關鍵字分詞。
//TermQuery
@Test
public void testTermQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("name", "spring"));
//source源欄位過慮
searchSourceBuilder.fetchSource(new String[]{"name", "studymodel"}, new String[]{});
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
System.out.println(searchResponse);
}
6.2.7match Query
1、基本使用
match Query即全文檢索,它的搜尋方式是先將搜尋字串分詞,再使用各各詞條從索引中搜尋。
match query與Term query區別是match query在搜尋前先將搜尋鍵碼分詞,再拿各各詞語去索引中搜尋。
1 、將「spring開發」分詞,分爲spring、開發兩個詞
2、再使用spring和開發兩個詞去匹配索引中搜尋。
3、由於設定了operator爲or,只要有一個詞匹配成功則就返回該文件,operator設定爲and表示每個詞都在文件中出現則才符合條件。
//根據MatchQuery
@Test
public void testMatchQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//source源欄位過慮
searchSourceBuilder.fetchSource(new String[]{"name", "studymodel"}, new String[]{});
//匹配關鍵字
searchSourceBuilder.query(QueryBuilders.matchQuery("description", "spring開發").operator(Operator.OR));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String studymodel = (String) sourceAsMap.get("studymodel");
String description = (String) sourceAsMap.get("description");
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
2、minimum_should_match
上邊使用的operator = or表示只要有一個詞匹配上就得分,如果實現三個詞至少有兩個詞匹配如何實現?
使用minimum_should_match可以指定文件匹配詞的佔比:
比如搜尋語句如下:
//匹配關鍵字
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("description", "spring開發框架")
.minimumShouldMatch("80%");//設定匹配佔比
searchSourceBuilder.query(matchQueryBuilder);
「spring開發框架」會被分爲三個詞:spring、開發、框架
設定"minimum_should_match": "80%"表示,三個詞在文件的匹配佔比爲80%,即3*0.8=2.4,向上取整得2,表示至少有兩個詞在文件中要匹配成功。
6.2.7multi Query
上邊的termQuery和matchQuery一次只能匹配一個Field,multiQuery一次可以匹配多個欄位。
1、基本使用
單項匹配是在一個field中去匹配,多項匹配是拿關鍵字去多個Field中匹配。
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring 框架","name", "description")
.minimumShouldMatch("50%");
2、提升boost
匹配多個欄位時可以提升欄位的 boost(權重)來提高得分
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring 框架",
"name", "description")
.minimumShouldMatch("50%");
multiMatchQueryBuilder.field("name",10);//提升權重10倍
6.2.7過濾器
過慮是針對搜尋的結果進行過慮,過慮器主要判斷的是文件是否匹配,不去計算和判斷文件的匹配度得分,所以過慮器效能比查詢要高,且方便快取,推薦儘量使用過慮器去實現查詢或者過慮器和查詢共同使用。
過慮器在布爾查詢中使用,下邊是在搜尋結果的基礎上進行過慮:
{
"_source": ["name", "studymodel", "description", "price"],
"query": {
"bool": {
"must": [{
"multi_match": {
"query": "spring框架",
"minimum_should_match": "50%",
"fields": ["name^10", "description"]
}
}],
"filter": [{
"term": {
"studymodel": "201001"
}
},
{
"range": {
"price": {
"gte": 60,
"lte": 100
}
}
}
]
}
}
}
range:範圍過慮,保留大於等於60 並且小於等於100的記錄。
term :項匹配過慮,保留studymodel等於"201001"的記錄。
注意:range和term一次只能對一個Field設定範圍過慮。
// 布爾查詢使用過慮器
@Test
public void testFilter() throws IOException {
SearchRequest searchRequest = new SearchRequest("demo_course");
searchRequest.types("doc");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//source源欄位過慮
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","description"},
new String[]{});
searchRequest.source(searchSourceBuilder);
//匹配關鍵字
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架", "name", "description");
//設定匹配佔比
multiMatchQueryBuilder.minimumShouldMatch("50%");
//提升另個欄位的Boost值
multiMatchQueryBuilder.field("name",10);
searchSourceBuilder.query(multiMatchQueryBuilder);
//布爾查詢
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(searchSourceBuilder.query());
//過慮
boolQueryBuilder.filter(QueryBuilders.termQuery("studymodel", "201001"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(60).lte(100));
SearchResponse searchResponse = client.search(searchRequest);
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String studymodel = (String) sourceAsMap.get("studymodel");
String description = (String) sourceAsMap.get("description");
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
6.2.7布爾查詢
布爾查詢對應於Lucene的BooleanQuery查詢,實現將多個查詢組合起來。
三個參數:
must:文件必須匹配must所包括的查詢條件,相當於 「AND」
should:文件應該匹配should所包括的查詢條件其中的一個或多個,相當於 「OR」
must_not:文件不能匹配must_not所包括的該查詢條件,相當於「NOT」
分別使用 must、should、must_not測試下邊的查詢:
發送:POST http://localhost:9200/demo_course/doc/_search
{
"_source": ["name", "studymodel", "description"],
"from": 0,
"size": 1,
"query": {
"bool": {
"must": [{
"multi_match": {
"query": "spring框架",
"minimum_should_match": "50%",
"fields": ["name^10", "description"]
}
},
{
"term": {
"studymodel": "201001"
}
}
]
}
}
}
must:表示必須,多個查詢條件必須都滿足。(通常使用must)
should:表示或者,多個查詢條件只要有一個滿足即可。
must_not:表示非。
//BoolQuery ,將搜尋鍵碼分詞,拿分詞去索引庫搜尋
@Test
public void testBoolQuery() throws IOException {
//建立搜尋請求物件
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
//建立搜尋源設定物件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.fetchSource(new String[]{"name", "pic", "studymodel"}, new String[]{});
//multiQuery
String keyword = "spring開發框架";
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架",
"name", "description")
.minimumShouldMatch("50%");
multiMatchQueryBuilder.field("name", 10);
//TermQuery
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("studymodel", "201001");
// 布爾查詢
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(multiMatchQueryBuilder);
boolQueryBuilder.must(termQueryBuilder);
//設定布爾查詢物件
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);//設定搜尋源設定
SearchResponse searchResponse = client.search(searchRequest);
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
System.out.println(sourceAsMap);
}
}
6.2.7排序查詢
可以在欄位上新增一個或多個排序,支援在keyword、date、float等型別上新增,text型別的欄位上不允許新增排序。
發送 POST http://localhost:9200/demo_course/doc/_search
過慮0–10元價格範圍的文件,並且對結果進行排序,先按studymodel降序,再按價格升序
{
"_source": ["name", "studymodel", "description", "price"],
"query": {
"bool": {
"filter": [{
"range": {
"price": {
"gte": 0,
"lte": 100
}
}
}]
}
},
"sort": [{
"studymodel": "desc"
},
{
"price": "asc"
}
]
}
//排序
@Test
public void testSort() throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//source源欄位過慮
searchSourceBuilder.fetchSource(new String[]{"name", "studymodel", "price", "description"},
new String[]{});
searchRequest.source(searchSourceBuilder);
//布爾查詢
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//過慮
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100));
// 排序
searchSourceBuilder.sort(new FieldSortBuilder("studymodel").order(SortOrder.DESC));
searchSourceBuilder.sort(new FieldSortBuilder("price").order(SortOrder.ASC));
SearchResponse searchResponse = client.search(searchRequest);
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String studymodel = (String) sourceAsMap.get("studymodel");
String description = (String) sourceAsMap.get("description");
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}
6.2.7高亮查詢
高亮顯示可以將搜尋結果一個或多個字突出顯示,以便向使用者展示匹配關鍵字的位置。
在搜尋語句中新增highlight即可實現,如下:
Post: http://127.0.0.1:9200/demo_course/doc/_search
{
"_source": ["name", "studymodel", "description", "price"],
"query": {
"bool": {
"must": [{
"multi_match": {
"query": "開發框架",
"minimum_should_match": "50%",
"fields": ["name^10", "description"],
"type": "best_fields"
}
}],
"filter": [{
"range": {
"price": {
"gte": 0,
"lte": 100
}
}
}]
}
},
"sort": [{
"price": "asc"
}],
"highlight": {
"pre_tags": ["<tag1>"],
"post_tags": ["</tag2>"],
"fields": {
"name": {},
"description": {}
}
}
}
//高亮查詢
@Test
public void testHighlight() throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.types(type);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//source源欄位過慮
searchSourceBuilder.fetchSource(new String[]{"name", "studymodel", "price", "description"},
new String[]{});
searchRequest.source(searchSourceBuilder);
//匹配關鍵字
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("開發",
"name", "description");
searchSourceBuilder.query(multiMatchQueryBuilder);
//布爾查詢
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(searchSourceBuilder.query());
//過慮
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100));
//排序
searchSourceBuilder.sort(new FieldSortBuilder("studymodel").order(SortOrder.DESC));
searchSourceBuilder.sort(new FieldSortBuilder("price").order(SortOrder.ASC));
//高亮設定
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<tag>");//設定字首
highlightBuilder.postTags("</tag>");//設定後綴
// 設定高亮欄位
highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
// highlightBuilder.fields().add(new HighlightBuilder.Field("description"));
searchSourceBuilder.highlighter(highlightBuilder);
SearchResponse searchResponse = client.search(searchRequest);
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
//名稱
String name = (String) sourceAsMap.get("name");
//取出高亮欄位內容
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (highlightFields != null) {
HighlightField nameField = highlightFields.get("name");
if (nameField != null) {
Text[] fragments = nameField.getFragments();
StringBuffer stringBuffer = new StringBuffer();
for (Text str : fragments) {
stringBuffer.append(str.string());
}
name = stringBuffer.toString();
}
}
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
String studymodel = (String) sourceAsMap.get("studymodel");
String description = (String) sourceAsMap.get("description");
System.out.println(name);
System.out.println(studymodel);
System.out.println(description);
}
}