目標檢測論文 R-CNN 論文翻譯
R-CNN 論文翻譯
Rich feature hierarchies for accurate object detection and semantic segmentation
用於精確目標檢測和語意分割的豐富特徵層次結構
摘要:
在經典的PASCAL VOC數據集上測得的目標檢測效能在最近幾年已經達到穩定狀態。表現最佳的方法是複雜的整合系統,通常將多個低階影象特徵與高階上下文結合在一起。在本文中,我們提出了一種簡單且可延伸的檢測演算法,相對於在數據集VOC 2012上已有的最佳結果,該演算法將平均精度均值(mAP)提高了30%以上,達到了53.3%。我們的方法結合了兩個關鍵點:
(1)一是可以將大容量的折積神經網路(CNNs)應用於自下而上的區域建議,以便對目標進行定位和分割;
(2)當缺少有標註的訓練數據時,先對輔助任務進行有監督的預訓練,然後再對特定問題進行微調,這樣可以顯著地提高效能。
因爲我們將區域建議與CNN結合在了一起,所以我們將我們的方法稱爲R-CNN:Regions with CNN features。我們將R-CNN與OverFeat(一種最近提出的基於CNN架構的滑動視窗檢測器)進行了比較。我們發現在200類ILSVRC2013檢測數據集上,R-CNN與OverFeat相比具有很大的優勢。完整系統的原始碼位於http://www.cs.berkeley.edu/~rbg/rcnn。
1.介紹
特徵很重要。在過去的十年中,各種視覺識別任務的進展很大程度上都是基於SIFT [29]和HOG [7]的使用。但是,如果我們關注PASCAL VOC目標檢測[15]這個經典的視覺識別任務的效能,通常會發現,在2010-2012年進展緩慢,通過構建整合系統和採用成功方法的變體獲得的收益很小。
SIFT和HOG是塊方向直方圖,一種大致類似於V1層(靈長類動物視覺通路中的第一個皮質區域)中的複雜細胞的表示方法。但是我們也知道,識別發生在幾個下遊階段,這表明計算特徵可能是分層次,多階段的過程,這些過程對於視覺識別來說甚至更爲有用。
福島的 「神經認知機」 [19],一種受生物學啓發的分層次的平移不變的模式識別模型,是在這方面的早期嘗試。但是,神經認知機缺乏監督訓練演算法。在Rumelhart等人[33]研究的基礎上。 LeCun等人[24]表明,通過反向傳播的隨機梯度下降對於訓練折積神經網路(CNN)是有效的,折積神經網路是將神經感知機進行擴充套件的一類模型。
折積神經網路在上世紀90年代被廣泛使用(例如,[27] ),但後來隨着支援向量機的興起就變得不再流行了。在2012年,Krizhevsky等人[23]在ImageNet大規模視覺識別挑戰賽(ILSVRC)上展示了更高的影象分類準確率,重新引起了人們對CNN的興趣[9,10]。他們的成功來自於在120萬張帶標籤的影象上訓練大型CNN,以及在LeCun的CNN上進行了一些改動(例如,max非線性修正(Relu)和「dropout」正則化)。
在ILSVRC 2012研討會上,人們對ImageNet結果的重要性進行了激烈的辯論。中心問題可以歸結爲:ImageNet上CNN分類結果在多大程度上能夠應用到PASCAL VOC挑戰賽上的目標檢測?
我們通過彌合影象分類和目標檢測之間的差距來回答這個問題。本文首次展示了,與基於簡單類HOG特徵的系統相比,CNN可以大幅提高在PASCAL VOC上目標檢測的效能。爲了獲得此結果,我們關注兩個問題:使用深度網路定位物體和僅使用少量帶標註的檢測數據來訓練大型模型。
與影象分類不同,檢測需要在影象中定位(可能很多)物體。一種方法將定位視爲迴歸問題。但是,Szegedy等人的工作[38],與我們自己的觀點都表明,該策略在實踐中可能效果不佳(他們報告在VOC 2007的mAP爲30.5%,而我們的方法爲58.5%)。另一種方法是構建一個滑動視窗檢測器。CNN已經使用這種方式至少二十年了,通常用於受約束的物件類別,例如人臉[32,40]和行人[35]。爲了維持高空間解析度,這些CNN通常僅採用兩個折積層和池化層。我們也考慮了採用滑動視窗的方法。但是,我們網路中的高層單元具有五個折積層,對於輸入影象,它們有非常大的感受野(195 × 195 畫素)和步長(32 × 32 畫素),這使採用滑動視窗的方法中的精確定位成爲一項開放的技術挑戰。
取而代之的是,我們通過在「使用區域識別」範式[21]中進行操作來解決CNN定位問題,這已成功地用於目標檢測[39]和語意分割[5]。在測試時,我們的方法爲輸入影象生成大約2000個類別獨立的候選區域,使用CNN從每個候選區域中提取固定長度的特徵向量,然後使用多個特定的線性SVM對每個區域進行分類。我們使用一種簡單的技術(仿射影象扭曲)從每個候選區域計算出固定尺寸的特徵向量作爲CNN輸入,而不考慮區域的形狀。圖1概述了我們的方法並突出了我們的一些結果。由於我們的系統將區域建議與CNN結合在了一起,所以我們將此方法稱爲R-CNN:Regions with CNN features。
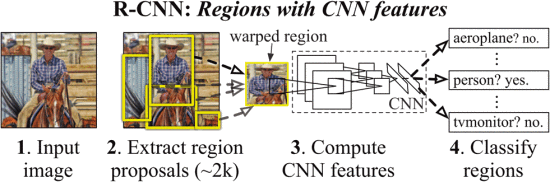
圖1:目標檢測系統概述。我們的系統(1)需要一張輸入影象,(2)提取大約2000個自下而上的候選區域,(3)使用大型折積神經網路(CNN)計算每個區域的特徵,然後(4)使用特定的線性SVMs對每個區域進行分類。R-CNN在pascal voc 2010上的平均精度均值(mAP)爲53.7%。爲進行比較,[39]報告使用了相同的候選區域,但使用空間金字塔和視覺詞袋的方法,mAP爲35.1%。流行的可變形的元件模型(DPM)的效能爲33.4%。在200類的ILSVRC2013 檢測數據集上,R-CNN的mAP爲31.4%,相較於OverFeat有很大的提升,Overfeat以往最好的結果是24.3%
在本文的更新版本中,我們在200類ILSVRC 2013檢測數據集上直接比較了R-CNN和最近提出的OverFeat檢測系統。OverFeat使用滑動視窗CNN進行檢測,是到目前爲止在ILSVRC 2013檢測中表現最好的方法。但我們發現R-CNN的表現明顯優於OverFeat,它們的mAP分別爲31.4%和24.3%。
檢測面臨的第二個挑戰是標記數據稀缺,當前可用的數據數量不足以訓練大型CNN。傳統的解決方法是使用無監督預訓練,然後監督微調(例如,[35] )。本文的第二個主要貢獻是表明在缺少數據時,對大型輔助數據集(ILSVRC)進行監督預訓練,然後對小型數據集(PASCAL)進行特定問題的微調,是學習大容量CNNs的有效範例。在我們的實驗中,對檢測進行微調可將mAP提高8個百分點。經過微調後,我們的系統在VOC 2010上的mAP達到了54%,而經過高度調節的基於HOG的可變形元件模型(DPM)[17,20]僅達到33%。我們還向讀者指出Donahue 等人的同期著作。[12],他們證明了Krizhevsky的CNN可以(無需微調)用作黑盒特徵提取器,在包括場景分類,細粒度次類劃分和自適應域在內的多個識別任務上表現出傑出的效能。
我們的系統也非常有效。唯一的類依賴計算是相當小的矩陣向量乘積和貪婪的非極大值抑制。此計算屬性源自所有類別之間共用的特徵,並且這些特徵的維數也比以前使用的區域特徵低兩個數量級(參見 [39])。
瞭解我們方法的失敗模式對於改進它也是至關重要的,因此我們報告了Hoiem 等人的檢測分析工具的結果。[23]。作爲該分析的直接結果,我們證明了一種簡單的邊界框迴歸方法可以顯着減少錯誤定位,這是主要的錯誤模式。
在開發技術細節之前,我們注意到,由於R-CNN在區域上進行操作,因此很自然地將其擴充套件到語意分割的任務。稍加修改,我們在PASCAL VOC分割任務上也取得了競爭性結果,在VOC 2011測試集上,平均分割精度爲47.9%。
2 使用R-CNN進行目標檢測
我們的物體檢測系統包括三個模組。第一個生成與類別無關的區域建議。這些建議定義了可用於我們的檢測器的候選檢測集。第二個模組是一個大型折積神經網路,它從每個區域提取一個固定長度的特徵向量。第三個模組是一組指定類別的線性SVM。在本節中,我們介紹每個模組的設計決策,描述其在測試階段的用法,詳細瞭解如何學習其參數以及在PASCAL VOC 2010-12上顯示結果。
2.1模組設計
區域建議
各種最新的論文提供了用於生成與類別無關的區域建議的方法。範例包括:objectness(物件狀態), selective search(選擇性搜尋),category-independent object proposals(類別無關的物件建議) , constrained parametric min-cuts (CPMC) 約束參數最小切割 , multi-scale combinatorial grouping多尺度組合,和Cires 等等.他們通過將CNN應用於規則間隔的正方形組來檢測有絲分裂細胞,這是區域建議的特例。因爲R-CNN不關心特定的區域建議方法,我們使用selective search選擇性搜尋,以和原有的檢測工作進行可控的比較。
特徵提取
我們使用Krizhevsky 等人描述的用Caffe 實現的CNN ,從每個建議區域中提取一個4096維的特徵向量。特徵的計算是由正向傳播一張均值相減後227 × 227RGB影象並通過五個折積層和兩個全連線層完成的。我們向讀者介紹[24]和[25]以瞭解更多的網路架構細節。
爲了計算建議區域的特徵,我們必須首先將該區域的影象數據變形爲與CNN相容的形式(其結構要求輸入固定的227 × 227畫素尺寸)。在任意形狀區域的許多可能變換中,我們選擇最簡單的方式。無論候選區域的大小或縱橫比如何,我們都會將其周圍的緊密邊界框中的所有畫素變換爲所需的大小。在變形之前,我們先擴大緊密的邊界框,以便在變形的尺寸處存在精確的p畫素,表示原始框周圍變形影象的上下文資訊(我們使用 p = 16)。圖2顯示了變形訓練區域的隨機採樣。附錄A討論了變形的替代方法。

圖2:VOC 2007訓練集中變形的訓練樣本。
2.2測試階段檢測
在測試時,我們對測試影象進行選擇性搜尋,提取大約2000個建議區域(我們在所有實驗中均使用選擇性搜尋的「快速模式」)。我們對每個建議區域進行變形,然後通過CNN進行前向傳播,獲取特徵。然後,對於每個類別,我們使用針對該類別訓練的SVM對每個提取的特徵向量進行評分。對於給定影象中所有計分的區域,我們應用貪婪的非極大值抑制(對於每個類別都是獨立的),如果該區域的交點重疊(IoU),重疊且評分較高的選定區域大於學習閾值,則拒絕該區域。
執行階段分析
兩個屬性使檢測效率更高。首先,所有CNN參數在所有類別之間共用。其次,與其他常見方法(例如帶有視覺詞袋編碼的空間金字塔)相比,CNN所計算的特徵向量是低維的。例如,UVA檢測系統中使用的特徵比我們的特徵大兩個數量級(360k vs 4k維度)。
這種共用的結果是,計算建議區域和特徵所花費的時間(GPU上的13s /影象或CPU上的53s /影象)將在所有類別上分攤。唯一特定於類別的計算是特徵和SVM權重以及非最大值抑制之間的點積。實際上,一張影象的所有點積都批次處理爲單個矩陣相乘。特徵矩陣通常是2000 × 4096 ,SVM權重矩陣爲 4096 × N,N是類別的總數。
該分析表明,R-CNN可以擴充套件到數千個物件類,而無需求助於雜湊等近似技術。即使有10萬個類,在現代多核CPU上,所得的矩陣乘法也只需10秒。這種效率不僅僅是使用區域建議和共用特徵的結果。由於具有高維特徵,UVA系統的速度要慢兩個數量級,而且其僅儲存100k線性預測器就需要134GB的記憶體,而低維特徵只有1.5GB。
將R-CNN與Dean等人的最新工作進行對比也很有趣。關於使用DPM和雜湊的可伸縮檢測。當引入1萬個幹擾項類別時,他們報告VOC 2007上的mAP約爲16%,每個影象執行5分鐘。使用我們的方法,一萬個檢測器在CPU上執行大約需要一分鐘,並且由於沒有使用近似估計,mAP將保持在59%(第3.2節)。
2.3訓練
監督預訓練
我們在具有影象級標註(即,沒有邊界框標籤)的大型輔助數據集(ILSVRC 2012)上進行有區別的預訓練。使用開源Caffe CNN庫進行了預訓練。簡而言之,我們的CNN幾乎與Krizhevsky 等人的表現相當。比在ILSVRC 2012驗證集上獲得的top-1錯誤率高2.2個百分點。這種差異是由於簡化了訓練過程。
特定領域的微調
爲了使我們的CNN適應新任務(檢測)和新領域(的Win視窗),我們僅使用變形區域建議進行CNN參數的隨機梯度下降(SGD)訓練。除了用隨機初始化的(N+1)類分類層(N個類+1背景)替換CNN的ImageNet特定的1000類分類層之外,CNN架構不變。對於VOC, 原始的N=20,ILSVRC2013, N = 200。我們會將所有的建議區域與ground-truth box進行比較,重疊 ≥ 0.5IoU的作爲該框正例,其餘部分作爲負例。我們設定0.001(初始預訓練速率的1/10)的學習率開始進行SGD,這允許微調在不破壞初始化的情況下取得進展。在每個SGD迭代中,我們對32個正視窗(在所有類中)和96個背景視窗進行統一採樣,以構建大小爲128的微型批次處理。我們將採樣偏向正視窗,因爲與背景相比它們極少見。
目標類別分類器
考慮訓練一個二元分類器來檢測汽車。顯然,緊密包圍汽車的影象區域應該是一個正例。同樣,很明顯,與汽車無關的背景區域應該是負例。還不清楚的問題是如何標記與汽車部分重疊的區域。我們使用IoU重疊閾值解決了此問題,將IoU低於該閾值的區域定義爲負例。通過在驗證集上進行從{ 0 ,0.1 ,… ,0.5 }的網格搜尋選擇了這個重疊閾值爲0.3。我們發現,小心地選擇此閾值很重要。如[39]所述,將其設定爲0.5 會使mAP降低5個點。同樣,將其設定爲0會使mAP降低4個點。正例就是每個類別的真實邊界框。
一旦提取了特徵並應用於訓練標籤,我們將爲每個類優化一個線性SVM。由於訓練數據太大而無法儲存在記憶體中,因此我們採用標準的hard negative mining method難負例挖掘演算法。hard negative mining method能夠快速收斂,並且實際上,僅對所有影象進行一次遍歷(一次訓練)之後,mAP就會停止增加。
在附錄B中,我們討論了爲什麼在微調與SVM訓練中正例和負例的定義不同。我們還將討論爲什麼有必要訓練檢測分類器而不是簡單地使用經過微調的CNN的最後一層softmax層的輸出。
2.4 Pascal Voc 2010-12的結果
按照PASCAL VOC最佳實踐步驟,我們在VOC 2007數據集上驗證了所有的設計決策和超參數。爲了獲得在VOC 2010-12數據集上的最終結果,我們對VOC 2012上的CNN進行了微調,並優化了VOC 2012上的檢測SVM。對於兩種主要演算法變體(帶和不帶邊界框迴歸),我們都將測試結果提交給了評估伺服器一次。
表1顯示了在VOC 2010上的完整結果。我們將我們的方法與四個強大的基準進行了比較,包括SegDPM,它結合了DPM檢測器和語意分割系統的輸出,並使用了其他檢測器間上下文和影象分類器計分。最接近的對比是Uijlings 等人的UVA系統。因爲我們的系統使用了相同的區域建議演算法。爲了對區域進行分類,他們的方法建立了一個四級空間金字塔,並使用密集採樣的SIFT,Extended Opponent SIFT和RGB-SIFT描述符進行填充,每個向量都使用4000字碼本進行了量化。使用直方圖相交核SVM進行分類。與他們的多特徵,非線性內核SVM方法相比,我們在mAP方面實現了很大的提高,從35.1%提高到了53.7%,而且還快得多。我們的方法在VOC 2011/12測試中達到了類似的效能(53.3%mAP)。

表1: VOC 2010測試的檢測平均準確度(%)。R-CNN與UVA和Regionlets最直接可比,因爲所有方法都使用選擇性搜尋區域建議。邊界框迴歸(bb)在3.4節中描述。在發佈時,SegDPM是Pascal VOC排行榜上的佼佼者。DPM和SegDPM使用其他方法未使用的上下文記錄。
2.5. Results on ILSVRC2013 detection
我們在200類的ILSVRC 2013 檢測數據集上執行了R-CNN,使用的系統超參數與在PASCAL VOC上使用的相同。我們執行了相同的步驟,將兩次的測試結果上傳給了ILSVRC 2013 評估伺服器,一次有邊界框迴歸,一次沒有。
圖3 對比了在ILSVRC 2013競賽中R-CNN與其他方法以及OverFeatd的結果。R-CNN達到了31.4%map,大大領先了第二名的OverFeatd,其結果爲24.3%。爲了讓大家瞭解類的AP分佈,在文章最後給出了一個框圖和表來顯示每個類的APs,見表8。大多數的參賽作品(OverFeat, NEC-MU, UvA-Euvision, Toronto A, and UIUC-IFP)都用到了折積神經網路,這表明瞭在如何使用CNN進行目標檢測時,細微差別將會產生不同的結果。
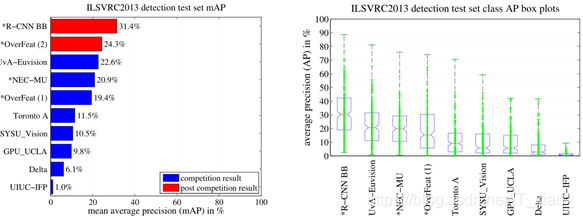
圖3: (左)ILSVRC2013檢測測試集的mAP。*之前的方法使用外部訓練數據(影象和標籤來自於ILSVRC所有案例中的分類數據集)。(右)框圖爲每種方法的200個平均精度值。框圖中沒有顯示比賽後OverFeat的結果,因爲每個類的APs還沒有可用(R-CNN,每個類的APs在表8中,也包含在上傳到arXiv.org的技術報告源中;見R-CNN-ILSVRC2013-APs.txt)。紅色的線標記了AP的中位數,框圖下方和頂部是第25和第75個百分比。每條線代表每種方法的最大值和最小值。每一個AP都被繪製成一個綠點(最好放大觀看)。
在第四節,我們會給出ILSVRC 2013檢測數據集的一個概述和提供一些細節,這些細節關乎我們在ILSVRC 2013數據集上執行R-CNN時做出的選擇。
3 視覺化,消融和錯誤模式
3.1視覺化學習特徵
第一層過濾器可以直接視覺化並且易於理解。它們捕獲定向的邊緣和對應的顏色。理解後續的層更具有挑戰性。Zeiler和Fergus在[42]中提出了一種視覺上有吸引力的反捲積方法。我們提出了一種簡單(且互補)的非參數方法,該方法直接顯示網路學到的知識。
這個想法是在網路中選出來一個特定單元(功能),並像使用一個正確的物件檢測器一樣使用它。就是說,我們根據一大批被提供的區域建議(大約一千萬個)計算這個單元的啓用值,並將建議區域按啓用值從高排到低排序,執行非最大抑制,然後顯示得分最高的區域。我們的方法通過確切地顯示觸發它的輸入,讓選定的單元「爲自己說話」。我們不進行平均操作是爲了檢視不同的視覺模式並深入瞭解由該單元計算出的不變性。
我們視覺化pool5的單元,這是網路中的第5個,也是最後一個折積層的最大池化輸出。pool5的特徵圖是 6 × 6 × 256 = 9216。忽略邊界效應,每個pool5的單元的感受野是 195 × 195 ,輸入層是 227 × 227畫素。pool5的一箇中央單元幾乎具有全域性的視角,而靠近邊緣的單元只有較小的固定支撐。
圖4中的每一行都顯示了一個pool5的單元的前16個啓用值,這個單元來自於我們在VOC 2003訓練集上進行微調過的CNN。這裏只展示了256個功能獨特的單元中的六個(附錄D包括更多)。這些單元作爲代表樣本被選出來用以顯示網路學到了什麼。在第二行中,我們看出一個在狗臉和點陣列上觸發的單元。對應於第三行的單位是紅色斑點檢測器。還有用於人臉和更抽象的圖案的檢測器,例如帶有視窗的文字和三角形結構。該網路似乎正在學習一種表示形式,該表示形式將少量的類調優特徵與形狀,紋理,顏色和材料屬性等分佈式表示形式結合在一起。後續的全連線層FC6 能夠對這些豐富的特徵進行大量的組合以建模。

圖4:pool5前六個單元。接受野和啓用值以白色繪製。有些單位與概念保持一致,例如人(第1行)或文字(第4行)。其他單元捕獲紋理和材料屬性,例如點陣列(2)和鏡面反射(6)。
3.2 消融研究
沒有調優的各層效能
爲了瞭解哪些層對於檢測效能至關重要,我們分析了CNN的最後三層在VOC 2007數據集上的結果。pool5在3.1節中進行了簡要描述。最後兩層總結如下。
FC6 與pool5完全連線。爲了計算特徵,它和pool5的feature map(reshape成一個9216維度的向量)做了一個4096×9216的矩陣乘法,並新增了一個bias向量。中間的向量按分量逐個半波校正(x ← 最大值(0 ,x ))。
FC7是網路的最後一層,將由FC6計算得到的特徵乘以一個 4096 × 4096 加權矩陣,並同樣新增一個偏差向量並進行半波校正。
我們首先看在PASCAL上沒有進行微調的CNN的結果,所有CNN參數僅在ILSVRC 2012上進行了預訓練。逐層分析效能顯示出 FC6的特徵要比FC7要好。這意味着可以刪除29%的CNN參數(約1680萬)而不會降低mAP。更令人驚訝的是,同時刪除 FC7 和 FC6 ,僅僅使用pool5的特徵,也就是隻使用6%的CNN參數,也能有非常好的結果。可見CNN的主要表達力來自於折積層,而不是全連線層。這一發現表明,僅使用CNN的折積層,在HOG上計算任意尺寸影象的稠密特徵圖具有潛在的實用性。這種表示法將可以直接在pool5的特徵上進行滑動視窗檢測器(包括DPM)的實驗.
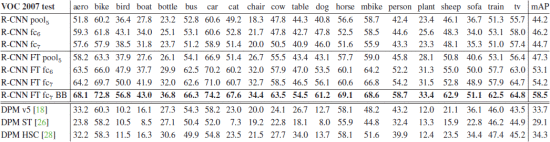
表2: voc 2007測試集的mAP(%)。第1-3行顯示了沒有進行微調的r-cnn效能。第4-6行顯示了在ILSVRC 2012上進行了預訓練,然後在voc 2007 訓練集上進行了微調(ft)的r-cnn的效能。第7行包含一個簡單的邊界框迴歸(bb)階段,可減少定位錯誤(第3.4節)。第8-10行將dpm方法作爲基準。第一個僅使用HOG,而後兩個使用不同的特徵學習方法來增加或替換HOG。
微調後的各層效能
我們看一下在VOC 2007 訓練集上進行參數調優後的CNN的結果。提升是驚人的(表2第 4-6行):微調使mAP增加了8.0個百分點,到了54.2%。對FC6和FC7進行微調要比pool5帶來的改善要大得多, 這表明從ImageNet pool5學習到的特徵通用性較強,並且大多數的改進是通過在它們之上學習特定的非線性分類器獲得的。
與最新特徵學習方法的比較
相當少的特徵學習方法被應用於PASCAL VOC 檢測。我們看一下兩種基於可變形元件模型的最新方法。作爲參考,我們還提供了基於標準HOG的DPM模型的結果。
第一種DPM特徵學習方法DPM ST ,通過「sketch token」概率的直方圖增強了HOG特徵。直觀地,sketch token一個穿過影象中心輪廓的緊密分佈。sketch token概率是通過一個隨機森林在每個畫素上計算得來的,這個隨機森林是被訓練用來將35*35的畫素分類爲150個sketch token中的一個或背景。
第二種方法DPM HSC ,用histograms of sparse codes (HSC)代替HOG。爲了計算HSC,在每個畫素上使用一個學習到的100 7 * 7 畫素(灰度空間)原子求解稀疏碼啓用,啓用結果有三種方式(全波和半波)進行校正,空間池化,l2標準化,然後進行冪運算。
所有R-CNN的變體都大大優於三個DPM方法(表2,第 8-10行),包括使用特徵學習的兩個方法。與僅使用HOG功能的最新版本的DPM相比,我們的mAP高出20個百分點:54.2% vs 33.7%,相對改善了61%。HOG和sketch token的組合比單獨的HOG提高了2.5 mAP點,而HSC比HOG提高了4 mAP點(與內部私有DPM方法進行比較,兩者均使用效能低於開源版本的DPM的非公開版本)。這些方法實現的mAP分別爲29.1%和34.3%。
3.3 網路結構
本文的大部分結果使用的是Krizhevsky等人提出的網路架構。然而,我們發現
結構的選擇對R-CNN的檢測效能有很大的影響。表3顯示了我們使用Simonyan和Zisserman等人最近提出的16層深度網路在VOC 2007上測試的結果。這個網路在最近的ILSVRC 2014級分類挑戰中表現最好。這個網路具有同質結構,由折積核爲3*3的13個折積層,五池化層,最後有三個全連線層。因爲OxfordNet,我們稱這個網路爲" O-Net ",就像它的原型TorontoNet被稱爲「T-Net」。
爲了在R-CNN中使用O-Net,我們從Caffe Model Zoo 上下載了VGG ILSVRC 16 layer 模型預訓練後的公開使用的網路權值。然後我們就像使用T-Net一樣用同樣的協定來微調網路。唯一的區別我們按照要求,使用了更小的批次(24個樣品)以便適合GPU的記憶體。表3的結果表明,使用O-Net的CNN大大超過使用T-Net的R-CNN,mAP從58.5%提升到了66.0%。但是,它有一個相當大的缺點,就是計算時間,使用O-Net的時間大約是使用T-Net的7倍。

表3: 兩種不同的CNN網路結構在VOC2007 測試集上的平均檢測精度 (%)。前兩行是Krizhevsky等人提出的網路結構(T-Net)的結果。第3行和第4行是使用Simonyan和Zisserman等人最近提出的16層網路結構的結果(O-Net)。
3.4 檢測誤差分析
我們應用了Hoiem 等人的優秀的檢測分析工具。揭示我們方法的錯誤模式,瞭解微調是如何改變它們的,並觀察比較我們和DPM的錯誤型別。限於本文的篇幅,分析的完整內容我們無法全部展示出來,請讀者參考[21]來了解一些更詳細的資訊(例如「規範化AP」)。因爲這些分析最好要有關聯圖,因此我們在圖5和圖6的題注中進行討論。
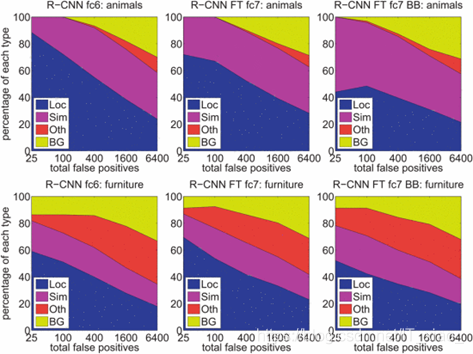
圖5:假正例型別的分佈。每個圖都顯示了假正例的演變分佈,並且按照分數遞減的順序包含了更多的fps。FP共分爲4種類型:loc-定位不良(正確分類並且IoU檢測介於0.1和0.5之間,或者重複);sim-和近似類別混淆;Oth-和不同對象類別混淆;BG-在背景上觸發的FP。與DPM比較(請參閱[21]),那麼我們的大部分錯誤是由於定位不良而引起的,而不是與背景或其他物件類造成的混淆,這表明cnn特徵比HOG具有更大的識別性。不好的定位很可能是由於我們使用了自下而上的區域建議,以及通過對cnn進行全影象分類的預訓練而獲得的位置不變性。第三列顯示了我們的簡單邊界框迴歸方法能夠修復定位錯誤。

圖6:對目標特徵敏感。每個圖均顯示標準化後AP的均值(超過類)(請參閱[21]),以獲取六個不同對象特徵(遮擋,截斷,邊界框區域,長寬比,視點,部分可見性)內效能最高和最低的子集。我們顯示了帶和不帶微調(ft)和邊界框迴歸(bb)以及DPM voc-release5的方法(r-cnn)的圖。總體而言,微調不會降低靈敏度(最大值和最小值之間的差異),但會實質上改善幾乎所有特性的最高和最低效能子集。這表明,微調不僅可以改善縱橫比和邊界框區域中效能最低的子集,還可以根據我們變形網路輸入的方式來推測。同時,微調可以提高所有特性的魯棒性,包括遮擋,截斷,觀察點和零件可見性。
3.4 邊界框迴歸
基於誤差分析,我們實現了一種減少定位誤差的簡單方法。受DPM 中使用的bounding-box迴歸的啓發,我們訓練了一個線性迴歸模型,爲一個通過選擇性搜尋的候選區域的Pool5特徵預測一個檢測視窗。附錄C中提供了完整的詳細資訊。表1,表2,和圖4的結果顯示,這種簡單的方法修復了大量的錯誤定位檢測,mAP提升了3到4個點。
4 語意分割
5 結論
近年來,目標檢測效能停滯不前。表現最佳的檢測系統是複雜的集合體,將來自物件檢測器和場景分類器的多個低層影象特徵與高層上下文結合在一起。本文提出了一種簡單且可延伸的目標檢測演算法,與PASCAL VOC 2012上的最佳以往結果相比,相對改進了30%。
我們能夠取得這個表現主要通過兩個方面。首先是將大容量折積神經網路應用於自下而上的建議區域,以定位和分割物件。第二個是在缺少標記的訓練數據時訓練大型CNN的方法。我們顯示出,對具有豐富數據的輔助任務(影象分類)進行有監督的網路預訓練,然後針對數據稀缺(檢測)的目標任務微調網路是非常有效的。我們推測,「監督的預訓練/特定領域的微調」範例將對多種數據稀缺的視覺問題非常有效。
我們的結論是,通過結合計算機視覺和深度學習(自下而上的區域建議和折積神經網路)的經典工具,我們取得了這些成果,這一點很重要。兩者是自然而不可避免的結合,而不是違背科學探究路線。