正確使用日誌的十個技巧
轉載至:原文鏈接
做一個苦逼的Java攻城師, 我們除了關心繫統的架構這種high level的問題, 還需要瞭解一些語言的陷阱, 異常的處理, 以及日誌的輸出, 這些"雞毛蒜皮"的細節. 這篇文章是JCP成員, Tomasz Nurkiewicz( 鏈接 )總結的10條如何正確使用日誌的技巧(參見原文). 跟那篇"java程式設計最差實踐"一樣, 也是針對一些細節的, 因爲日誌是我們排查問題, 瞭解系統狀況的重要線索. 我覺得對我們平常coding非常有借鑑意義. 所以轉換成中文, 加深一下印象, 也作爲自己工作的一個參考.
1)選擇正確的Log開源框架
在程式碼中爲了知道程式的行爲的狀態, 我們一般會列印一條日誌:
log.info("Happy and carefree logging");
在所有的日誌框架中, 我認爲最好的是SLF4J. 比如在Log4J中我們會這樣寫
log.debug("Found " + records + " records matching filter: '" + filter + "'");
而在SLF4J中我們會這樣寫:
log.debug("Found {} records matching filter: '{}'", records, filter);
從可讀性和系統效率來說, SLF4J( http://logback.qos.ch/ )比Log4J都要優秀(Log4J涉及到字串連線和toString()方法的呼叫). 這裏的{}帶來的另一個好處, 我們在儘量不損失效能的情況, 不必爲了不同的日誌輸出級別, 而加上類似isDebugEnabled()判斷.
SLF4J只是各種日誌實現的一個介面抽象(facade), 而最佳的實現是Logback, 相對於Log4J的同門兄弟(皆出自Ceki Gülcü之手), 它在開源社羣的活躍度更高.
最後要推薦的是Perf4J( http://perf4j.codehaus.org/ ). 用一句話來概括就是:
如果把log4j看做System.out.println()的話, 那麼Perf4J就是System.currentTimeMillis()
Perf4J可以幫助我們更方便的輸出系統效能的日誌資訊. 然後藉助其他報表工具將日誌以圖表的形式加以展現, 從而方便我們分析系統的效能瓶頸. 關於Perf4J的使用可以參考它的開發者指南(http://perf4j.codehaus.org/devguide.html).
下面 下麪是一份關於日誌jar包依賴的pom.xml參考模板:
<repositories>
<repository>
<id>Version99</id>
<name>Version 99 Does Not Exist Maven repository</name>
<layout>default</layout>
<url>http://no-commons-logging.zapto.org/mvn2</url>
</repository>
</repositories>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.5.11</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>0.9.20</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jul-to-slf4j</artifactId>
<version>1.5.11</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>1.5.11</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>1.5.11</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>99.0-does-not-exist</version>
</dependency>
下面 下麪是測試程式碼:
SLF4JBridgeHandler.install();
org.apache.log4j.Logger.getLogger("A").info("Log4J");
java.util.logging.Logger.getLogger("B").info("java.util.logging");
org.apache.commons.logging.LogFactory.getLog("C").info("commons-logging");
org.slf4j.LoggerFactory.getLogger("D").info("Logback via SLF4J");
上面的程式碼, 無論你採用哪個log框架輸出日誌, 底層採用的都是logback, 至於爲什麼, 可以看這裏(http://www.slf4j.org/legacy.html), 另外這裏爲了在classpath裏面不引入common-logging, 用了一個小技巧, 就是將依賴版本設定爲99.0-does-not-exist, 關於這種用法的說明可以看這裏(http://day-to-day-stuff.blogspot.com/2007/10/announcement-version-99-does-not-exist.html), 不過log4j的作者認爲最簡單的做法就是直接去掉對common-logging的依賴, 相關內容可以看這裏的說明(http://www.slf4j.org/faq.html)
2)理解正確的日誌輸出級別
很多程式設計師都忽略了日誌輸出級別, 甚至不知道如何指定日誌的輸出級別. 相對於System.out來說, 日誌框架有兩個最大的優點就是可以指定輸出類別(category)和級別(level). 對於日誌輸出級別來說, 下面 下麪是我們應該記住的一些原則:
ERROR:系統發生了嚴重的錯誤, 必須馬上進行處理, 否則系統將無法繼續執行. 比如, NPE, 數據庫不可用等.
WARN:系統能繼續執行, 但是必須引起關注. 對於存在的問題一般可以分爲兩類: 一種系統存在明顯的問題(比如, 數據不可用), 另一種就是系統存在潛在的問題, 需要引起注意或者給出一些建議(比如, 系統執行在安全模式或者訪問當前系統的賬號存在安全隱患). 總之就是系統仍然可用, 但是最好進行檢查和調整.
INFO:重要的業務邏輯處理完成. 在理想情況下, INFO的日誌資訊要能讓高階使用者和系統管理員理解, 並從日誌資訊中能知道系統當前的執行狀態. 比如對於一個機票預訂系統來說, 當一個使用者完成一個機票預訂操作之後, 提醒應該給出"誰預訂了從A到B的機票". 另一個需要輸出INFO資訊的地方就是一個系統操作引起系統的狀態發生了重大變化(比如數據庫更新, 過多的系統請求).
DEBUG:主要給開發人員看, 下面 下麪會進一步談到.
TRACE: 系統詳細資訊, 主要給開發人員用, 一般來說, 如果是線上系統的話, 可以認爲是臨時輸出, 而且隨時可以通過開關將其關閉. 有時候我們很難將DEBUG和TRACE區分開, 一般情況下, 如果是一個已經開發測試完成的系統, 再往系統中新增日誌輸出, 那麼應該設爲TRACE級別.
以上只是建議, 你也可以建立一套屬於你自己的規則. 但是一套良好的日誌系統, 應該首先是能根據情況快速靈活的調整日誌內容的輸出.
最後要提到的就是"臭名昭著"的is*Enabled()條件, 比如下面 下麪的寫法:
if(log.isDebugEnabled())
log.debug("Place for your commercial");
這種做法對效能的提高幾乎微乎其微(前面在提到SLF4J的時候已經說明), 而且是一種過度優化的表現. 極少情況下需要這樣寫, 除非構造日誌資訊非常耗效能. 最後必須記住一點: 程式設計師應該專注於日誌內容, 而將日誌的輸出的決定權交給日誌框架去非處理.
3) 你真的知道log輸出的內容嗎?
對於你輸出的每一條log資訊, 請仔細檢查最終輸出的內容是否存在問題, 其中最重要的就是避免NPE, 比如想下面 下麪這樣:
log.debug("Processing request with id: {}", request.getId());
這裏我們能否保證request不爲null? 除了NPE之外, 有時候我們可能還需要考慮, 是否會導致OOM? 越界存取? 執行緒飢餓(log是同步的)? 延遲初始化異常? 日誌打爆磁碟等等. 另外一個問題就是在日誌中輸出集合(collection), 有時候我們輸出的集合內容可能是由Hibernate從數據庫中取出來的, 比如下面 下麪這條日誌資訊:
log.debug("Returning users: {}", users);
這裏最佳的處理方式是僅僅輸出domain物件的id或者集合的大小(size), 而對Java來說, 不得不要吐槽幾句, 要遍歷存取集閤中每一個元素的getId方法非常繁瑣. 這一點Groovy就做的非常簡單(users*.id), 不過我們可以藉助Commons Beanutils工具包來幫我們簡化:
log.debug("Returning user ids: {}", collect(users, "id"));
這裏的collect方法的實現如下:
public static Collection collect(Collection collection, String propertyName) {
return CollectionUtils.collect(collection, new BeanToPropertyValueTransformer(propertyName));
}
過不幸的是, 在給Commons Beanutils提了一個patch(BEANUTILS-375 https://issues.apache.org/jira/browse/BEANUTILS-375)之後, 並沒有被接受:(
最後是關於toString()方法. 爲了讓日誌更容易理解, 最好爲每一個類提供合適的toString()方法. 這裏可以藉助ToStringBuilder工具類. 另外一個就是關於陣列和某些集合型別. 因爲陣列是使用的預設的toString方法. 而某些集合沒有很好的實現toString方法. 對於陣列我們可以使用JDK的Arrays.deepToString()方法(http://docs.oracle.com/javase/6/docs/api/java/util/Arrays.html#deepToString%28java.lang.Object[]%29).
4) 小心日誌的副作用
有時候日誌或多或少的會影響系統的行爲, 比如最近碰到的一個情況就是在某些條件下, Hibernate會拋出LazyInitializationException. 這是因爲某些輸出日誌導致延遲初始化的集合在session建立時被載入. 而在某些場景下當提高日誌輸出級別時, 問題就會消失.
另一個副作用就是日誌導致系統執行越來越慢. 比如不恰當的使用toString方法或者字串連線, 使得系統出現效能問題, 曾經碰到的一個現象, 某個系統每隔15分鐘重新啓動一次, 這個主要是執行log輸出出現執行緒飢餓導致, 一般情況下, 如果一個系統一小時內生成的日誌有幾百MB的時候, 就要小心了.
而如果因爲日誌輸出本身的問題導致正常的業務邏輯被中斷, 那就更嚴重了. 比如下面 下麪這種程式碼, 最好不要這樣寫:
try {
log.trace("Id=" + request.getUser().getId() + " accesses " + manager.getPage().getUrl().toString())
} catch(NullPointerException e) {}
5) 日誌資訊應該簡潔且可描述
一般, 每一條日誌數據會包括描述和上下文兩部分, 比如下面 下麪的日誌:
log.debug("Message processed");
log.debug(message.getJMSMessageID());
log.debug("Message with id '{}' processed", message.getJMSMessageID());
第一條只有描述, 第二條只有上下文, 第三條纔算完整的一條日誌, 還有下面 下麪這種日誌:
if(message instanceof TextMessage)
//...
else
log.warn("Unknown message type");
在上面的警告日誌中沒有包含實際的message type, message id等資訊, 只是表明程式有問題, 那麼是什麼導致了問題呢? 上下文是什麼? 我們什麼都不知道.
另外一個問題就是在日誌中加上一個莫名其妙的內容, 即所謂的"magic log". 比如有些程式設計師會在日誌中隨手敲上"&&&!#"這樣一串字元, 用來幫助他們定位.
一個日誌檔案中的內容應該易讀, 清晰, 可描述. 而不要使用莫名其妙的字元, 日誌要給出當前操作做了什麼, 使用的什麼數據. 好的日誌應該被看成文件註釋的一部分.
最後一點, 切記不要在日誌中包含密碼和個人隱私資訊!
6) 正確的使用輸出模式
log輸出模式可以幫助我們在日誌中增加一些清晰的上下文資訊. 不過對新增的資訊還是要多加小心. 比如說, 如果你是每小時輸出一個檔案, 這樣你的日誌檔名中已經包含了部分日期時間資訊, 因此就沒必要在日誌中再包含這些資訊. 另外在多執行緒環境下也不要在自己在日誌中包含執行緒名稱, 因爲這個也可以在模式中設定.
根據我的經驗, 一個理想的日誌模式將包含下列資訊:
當前時間(不需要包含日誌, 精確到毫秒)
日誌級別(如果你關心這個)
執行緒名稱
簡單的日誌名(非全限定名的那種)
日誌描述資訊
比如像下面 下麪這個logback設定:
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %-5level [%thread][%logger{0}] %m%n</pattern>
</encoder>
</appender>
千萬不要在日誌資訊中包含下列內容:
檔名
類名(我想這個應該是全限定名吧)
程式碼行號
還有下面 下麪這種寫法也是要避免的:
log.info("");
因爲程式設計師知道, 在日誌模式中會指定行號, 因此他就可以根據日誌輸的行號出判斷指定的方法是否被呼叫了(比如這裏可能是authenticate()方法, 進而判斷登錄的使用者已經經過了驗證). 另外, 大家也要清楚一點, 在日誌模式中指定類名, 方法名以及行號會帶來嚴重的效能問題. 下面 下麪是我針對這個做的一個簡單的測試, 設定如下:
<appender name="CLASS_INFO" class="ch.qos.logback.core.OutputStreamAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %-5level [%thread][%class{0}.%method\(\):%line][%logger{0}] %m%n</pattern>
</encoder>
<outputStream class="org.apache.commons.io.output.NullOutputStream"/>
</appender>
<appender name="NO_CLASS_INFO" class="ch.qos.logback.core.OutputStreamAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %-5level [%thread][LoggerTest.testClassInfo\(\):30][%logger{0}] %m%n</pattern>
</encoder>
<outputStream class="org.apache.commons.io.output.NullOutputStream"/>
</appender>
下面 下麪是測試程式碼:
import org.junit.Test;
import org.perf4j.StopWatch;
import org.perf4j.slf4j.Slf4JStopWatch;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class LoggerTest {
private static final Logger log = LoggerFactory.getLogger(LoggerTest.class);
private static final Logger classInfoLog = LoggerFactory.getLogger("CLASS_INFO");
private static final Logger noClassInfoLog = LoggerFactory.getLogger("NO_CLASS_INFO");
private static final int REPETITIONS = 15;
private static final int COUNT = 100000;
@Test
public void testClassInfo() throws Exception {
for (int test = 0; test < REPETITIONS; ++test)
testClassInfo(COUNT);
}
private void testClassInfo(final int count) {
StopWatch watch = new Slf4JStopWatch("Class info");
for (int i = 0; i < count; ++i)
classInfoLog.info("Example message");
printResults(count, watch);
}
@Test
public void testNoClassInfo() throws Exception {
for (int test = 0; test < REPETITIONS; ++test)
testNoClassInfo(COUNT * 20);
}
private void testNoClassInfo(final int count) {
StopWatch watch = new Slf4JStopWatch("No class info");
for (int i = 0; i < count; ++i)
noClassInfoLog.info("Example message");
printResults(count, watch);
}
private void printResults(int count, StopWatch watch) {
log.info("Test {} took {}ms (avg. {} ns/log)", new Object[]{
watch.getTag(),
watch.getElapsedTime(),
watch.getElapsedTime() * 1000 * 1000 / count});
}
}
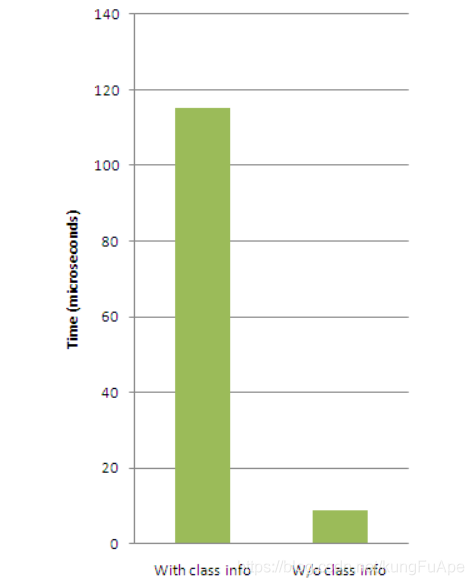
在上面的測試程式碼中, CLASS_INFO日誌輸出了1500萬次, 而NO_CLASS_INFO輸出了3億次. 後者採用一個靜態的文字來取代日誌模式中的動態類資訊.
從下面 下麪的對比圖可以看出, 直接在日誌模式中指定類名的日誌比使用反射動態獲取類名的要快13倍(平均輸出每條日誌耗時:8.8 vs 115微秒). 對於一個java程式設計師來說, 一條日誌耗時100微秒是可以接受的. 這也就是說, 一個後臺應用其中1%的時間消耗在了輸出日誌上. 因此我們有時候也需要權衡一下, 每秒100條日誌輸出是否是合理的.
最後要提到的是日誌框架中比較高階的功能: Mapped Diagnostic Context. MDC(http://www.slf4j.org/api/org/slf4j/MDC.html )主要用來簡化基於thread-local的map參數管理. 你可以往這個map中增加任何key-value內容, 然後在隨後的日誌輸出中作爲模式的一部分, 與當前執行緒一起輸出.
7) 給方法的輸入輸出加上日誌
當我們在開發過程中發現了一個bug, 一般我們會採用debug的方式一步步的跟蹤, 直到定位到最終的問題位置(如果能通過寫一個失敗的單元測試來暴露問題, 那就更帥了_). 但是如果實際情況不允許你debug時, 比如在客戶的系統上幾天前出現的bug. 如果你沒有詳細的日誌的話, 你能找到問題的根源麼?
如果你能根據一些簡單的規則來輸出每個方法的輸入和輸出(參數和返回值). 你基本上可以扔掉偵錯程式了. 當然針對每一個方法加上日誌必須是合理的: 存取外部資源(比如數據庫), 阻塞, 等待等等, 這些地方可以考慮加上日誌. 比如下面 下麪的程式碼:
public String printDocument(Document doc, Mode mode) {
log.debug("Entering printDocument(doc={}, mode={})", doc, mode);
String id = //Lengthy printing operation
log.debug("Leaving printDocument(): {}", id);
return id;
}
因爲在方法呼叫前後加上了日誌, 我們可以非常方便的發現程式碼的效能問題, 甚至找出死鎖和執行緒飢餓(starvation)等嚴重問題:這種情況下都只有輸入(entering)日誌, 不會有輸出(leaving)日誌. 如果方法名類名使用得當, 那麼輸出的日誌資訊也將會非常賞心悅目. 因爲你可以根據日誌完整瞭解系統的執行情況, 因此分析問題的時候, 也將變得更加輕而易舉. 爲了減少日誌程式碼, 也可以採用簡單的AOP來做日誌輸出. 但是也要小心, 這種做法可能產生大量的日誌.
對於這種日誌, 一般採用DEBUG/TRACE級別. 當某些方法的呼叫非常頻繁, 那麼大量的日誌輸出將會影響到系統的效能, 此時我們可以提高相關類的日誌級別或者乾脆去掉日誌輸出. 不過一般情況下, 還是建議大家多輸出一些日誌. 另外也可以將日誌看成一種單元測試. 輸出的日誌將像單元測試一樣, 會覆蓋到整個方法的執行過程. 沒有日誌的系統是不可想象的. 因此通過觀察日誌的輸出將是我們瞭解系統是在正確的執行還是掛了的唯一方式.
8) 用日誌檢查外部系統
這裏是針對前面的一種場景: 如果你的系統需要和其他系統通訊, 那麼需要考慮是否需要用日誌記錄這種互動. 一般情況下, 如果一個應用需要與多個系統進行整合, 那麼診斷和分析問題將非常困難. 比如在最近的一個專案中, 由於我們在Apache CXF web服務上完整的記錄了訊息數據(包括SOAP和HTTP頭資訊), 使得我們在系統整合和測試階段非常happy.
如果通過ESB的方式來多個系統進行整合, 那麼可以在匯流排(bus)上使用日誌來記錄請求和響應. 這裏可以參考Mules(http://www.mulesoft.org/)的(http://www.mulesoft.org/documentation/display/MULE2USER/Configuring+Components).
有時候與外部系統進行通訊產生的大量日誌可能讓我們無法接受. 另一方面, 我們希望開啓日誌臨時進行一下測試, 或者在系統出現問題的時候我們希望開啓短暫的輸出日誌. 這樣我們可以在輸出日誌和保證系統效能之間取得一個平衡. 這裏我們需要藉助日誌日別. 比如像下面 下麪的這樣做:
Collection<Integer> requestIds = //...
if(log.isDebugEnabled())
log.debug("Processing ids: {}", requestIds);
else
log.info("Processing ids size: {}", requestIds.size());
在上面的程式碼中, 如果日誌級別設定爲DEBUG, 那麼將但應所有的requestIds資訊. 但是如果我們設定INFO級別, 那麼只會輸出requestId的數量. 不過就像我們前面提到的日誌的副作用那樣, 如果在INFO級別下requestIds爲null將產生NullPointerException.
9) 正確輸出異常日誌
對於日誌輸出的第一條原則就是不要用日誌輸出異常, 而是讓框架或者容器去處理. 記錄異常本不應該是logger的工作. 而許多程式設計師都會用日誌輸出異常, 然後可能返回一個預設值(null, 0或者空字串). 也可能在將異常包裝一下再拋出. 比如像下面 下麪的程式碼這樣:
log.error("IO exception", e);
throw new MyCustomException(e);
這樣做的結果可能會導致異常資訊列印兩次(拋出的地方打一次, 捕獲處理的地方再打一次).
但是有時候我們確實希望列印異常, 那麼應該如何處理呢? 比如下面 下麪對NPE的處理:
try {
Integer x = null;
++x;
} catch (Exception e) {
log.error(e); //A
log.error(e, e); //B
log.error("" + e); //C
log.error(e.toString()); //D
log.error(e.getMessage()); //E
log.error(null, e); //F
log.error("", e); //G
log.error("{}", e); //H
log.error("{}", e.getMessage()); //I
log.error("Error reading configuration file: " + e); //J
log.error("Error reading configuration file: " + e.getMessage()); //K
log.error("Error reading configuration file", e); //L
}
上面的程式碼, 正確輸出異常資訊的只有G和L, A和B甚至不能在SLF4J中編譯通過, 其他的都會丟失異常堆疊資訊或者列印了不恰當的資訊. 這裏只要記住一條, 在日誌中輸出異常資訊, 第一個參數一定是一個字串, 一般都是對問題的描述資訊, 而不能是異常message(因爲堆疊裏面會有), 第二個參數纔是具體的異常範例.
注: 對於遠端呼叫型別的服務拋出的異常,一定要注意實現序列化, 否則在用戶端將拋出NoClassDefFoundError異常, 而掩蓋了真實的異常資訊
10) 讓日誌易讀,易解析
對日誌感興趣的可以分爲兩類:
人(比如程式設計師)
機器(系統管理員寫的shell指令碼)
日誌的內容必須照顧到這兩個羣體. 參照鮑勃大叔"Clean Code(http://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882)"一書的話來說:日誌應該像程式碼一樣可讀並且容易理解.
另一方面, 如果一個系統每小時要輸出幾百MB甚至上G的日誌, 那麼我們需要藉助grep, sed以及awk來分析日誌. 如果可能, 我們應該讓日誌儘可能的被人和機器理解. 比如, 避免格式化數位, 使用日誌模式則可以方便用正則表達式進行識別. 如果無法兼顧, 那麼可以將數據用兩種格式輸出, 比如像下面 下麪這樣:
log.debug("Request TTL set to: {} ({})", new Date(ttl), ttl);
// Request TTL set to: Wed Apr 28 20:14:12 CEST 2010 (1272478452437)
final String duration = DurationFormatUtils.formatDurationWords(durationMillis, true, true);
log.info("Importing took: {}ms ({})", durationMillis, duration);
//Importing took: 123456789ms (1 day 10 hours 17 minutes 36 seconds)
上面的日誌, 既照顧了計算機("ms after 1970 epoch"這種時間格式), 又能更好的讓人能理解(「1 day 10 hours 17 minutes 36 seconds」) .
如果有所幫助,點個贊吧 ^ .^