MySQL學習之SQL語法-DQL(3)
2020-08-14 11:06:36
目錄
1.基礎查詢
1.1.普通查詢
# 語法
SELECT 列名1,列名2,... FROM 表名
# 查詢常數值
SELECT 100;
SELECT 'HELLO';
# 查詢表達式
SELECT 100*100;
# 查詢函數
SELECT VERSION();
# 查詢別名
SELECT AVG(salary) AS salary_avg FROM t_employee;
# 去重
SELECT DISTINCT department_id FROM t_employee;
# 正常查表
SELECT id, name, department_id, salary, phone_number FROM t_employee;
SELECT * FROM t_employee;
執行結果:

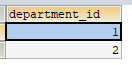

1.2.條件查詢
# 語法
SELECT [查詢列表] FROM 表名 WHERE [條件列表];
SELECT * FROM t_employee WHERE salary > 5000;
SELECT * FROM t_employee WHERE salary > 5000 AND salary < 7000;
SELECT * FROM t_employee WHERE `name` LIKE '%a%';
條件列表結果爲true或false,和Java的條件表達式類似。
執行結果:



1.3.排序查詢
# 語法
SELECT [] FROM [WHERE子句] ORDER BY 欄位1,欄位2,... [排序方式,預設ASC順序,DESC逆序]
SELECT * FROM t_employee ORDER BY salary;
SELECT * FROM t_employee ORDER BY salary DESC;
執行結果:


多個排序欄位則從左向右依次進行排序。
2.常見函數
2.1.單行函數
2.1.1.字元函數
# LENGTH(欄位):長度
SELECT LENGTH(name) FROM t_employee;
# CONCAT(欄位1, 欄位2):拼接字串
SELECT CONCAT(name,'_666') FROM t_employee;
# UPPER(欄位):大寫
SELECT UPPER('ccbbaa');
# LOWER(欄位):小寫
SELECT LOWER('AAABBBCCC');
# SUBSTR(字串, index):擷取字串
SELECT SUBSTR('AABBCC', 4);
# INSTR(字串, 字串):返回字串出現在字串的第一個索引
SELECT INSTR('AABBCC', 'BB');
# TRIM(字串):去除字串前後空格
SELECT TRIM(' AAABBBBBBBAAAAA ');
# 指定去除字串前後內容
SELECT TRIM('A' FROM 'AAABBBBBBBAAAAA');
執行結果:

2.1.2.數位函數
# ROUND(x):四捨五入
SELECT ROUND(1.65);
# CEIL(x);向上取整
SELECT CEIL(-0.5);
# FLOOR(x):向下取整
SELECT FLOOR(2.2);
# TRUNCATE(x,d):截斷
SELECT TRUNCATE(1.69,1);
# MOD(a, b):取餘(a-a/b*b)
SELECT MOD(-10,-3);
執行結果:

2.1.2.日期函數
# NOW():當前時間
SELECT NOW();
# CURDATE():當前日期
SELECT CURDATE();
# CURTIME():當前時間,不包含日期
SELECT CURTIME();
# STR_TO_DATE(str, format):字串轉化爲日期
SELECT STR_TO_DATE('2002-3-4', '%Y-%c-%d');
# DATE_FORMAT(date, format):日期轉化爲字串
SELECT DATE_FORMAT(NOW(), '%Y年%m月%d日');
執行結果:

日期format:
- %Y:四位年份
- %y:兩位年份
- %m:月份兩位
- %c:月份
- %d:日
- %H:24小時制小時
- %h:小時
- %i:分鐘
- %s:秒
2.1.2.流程控制函數
# 語法
# IF(EXPR1, EXPR2, EXPR3)類似於三元運算子
SELECT *, IF(salary > 6000, '有錢人', '窮逼') FROM t_employee;
# CASE case_value
# WHEN when_value THEN ...
# END類似於switch case
SELECT *,
CASE salary
WHEN 5000 THEN '窮逼'
WHEN 6000 THEN '小康'
WHEN 7000 THEN '有錢人'
END
FROM t_employee;
執行結果:


2.2.分組函數
用於統計使用,又稱爲聚合函數或者統計函數或組函數
# 語法
# GROUP BY 欄位
# HAVING 條件表達式
# SUM、AVG、MAX、MIN、COUNT
SELECT SUM(salary), AVG(salary), MAX(salary), MIN(salary), COUNT(salary)
FROM t_employee;
SELECT department_id, MAX(salary)
FROM t_employee
GROUP BY department_id;
SELECT department_id, MAX(salary)
FROM t_employee
GROUP BY department_id
HAVING AVG(salary) > 6000
執行結果:

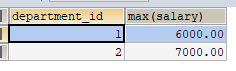
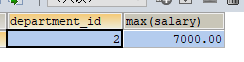
3.連線查詢
在此之前建立一個新表、匯入一些數據:
DROP TABLE IF EXISTS `t_department`;
CREATE TABLE `t_department` (
`id` int(11) NOT NULL COMMENT '部門id',
`name` varchar(20) NOT NULL COMMENT '部門名',
`manager_id` int(11) NOT NULL COMMENT '部門管理者',
`avg_salary` decimal(10,0) NOT NULL COMMENT '部門平均工資',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into `t_department`(`id`,`name`,`manager_id`,`avg_salary`) values (1,'技術部',1,5000),(2,'研發部',3,5000), (3,'銷售部',4,6000);
3.1.內連線或等值連線
# SQL92
SELECT e.name AS employee_name, d.name AS department_name
FROM t_employee e, t_department d
WHERE e.department_id = d.id;
# SQL99寫法
SELECT e.name AS employee_name, d.name AS department_name
FROM t_employee e
INNER JOIN t_department d
ON e.department_id = d.id;
這裏查詢了兩張表,通過部門id進行連線的。
執行結果:
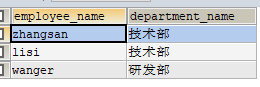
3.2.外連線
外連線有左連線和右連線,一個LEFT JOIN,一個RIGHT JOIN,兩者沒啥區別。
SELECT e.*, d.*
FROM t_employee e
LEFT JOIN t_department d
ON e.department_id = d.id
執行結果:

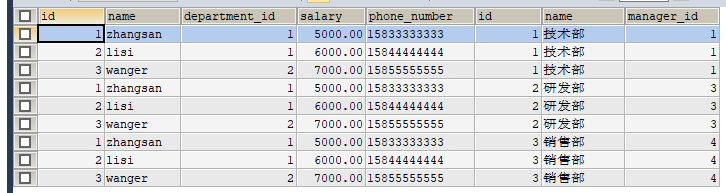
3.3.交叉連線(笛卡爾乘積)
SELECT e.*, d.*
FROM t_employee e
CROSS JOIN t_department d;
返回所有可能的連線方式。
執行結果:
4.子查詢
出現在其他語句中的select語句,稱爲子查詢或內查詢。
4.1.單行子查詢(標量子查詢)
子查詢結果爲一列一行。
# 查詢所有工資大於name=zhangsan工資的所有員工資訊
SELECT *
FROM t_employee
WHERE salary > (
SELECT salary
FROM t_employee
WHERE `name` = 'zhangsan'
);
# 查詢id=1的部門管理者的員工資訊
SELECT *
FROM t_employee
WHERE id = (
SELECT manager_id
FROM t_department
WHERE id = 1
);
執行結果:


4.2.多行子查詢(列子查詢)
子查詢結果爲一列多行。
# 查詢月薪比所有部門平均工資都要大的員工資訊
SELECT *
FROM t_employee
WHERE salary > ALL
(
SELECT avg_salary
FROM t_department
);
執行結果:

4.3.行子查詢
子查詢結果爲一行多列。
# 查詢部門id=1的員工月薪和部門平均月薪相同的員工資訊
SELECT *
FROM t_employee
WHERE (department_id,salary) =
(
SELECT id,avg_salary
FROM t_department
WHERE id = 1
);
執行結果:

5.分頁查詢
# 語法
# LIMIT [OFFSET],SIZE;
# offset要顯示條目的起始索引,從零開始;
# size要顯示的條目個數
# 查詢t_employee和t_department所有組合方式的前5個數據
SELECT e.*, d.*
FROM t_employee e
CROSS JOIN t_department d
LIMIT 5;
執行結果:

分頁查詢可以將大量數據進行程式上的分批次查詢,防止頁面載入大量數據導致的使用者體驗以及效率。
6.聯合查詢
將多條查詢語句的結果合併成一個結果。
# 語法
# UNION [ALL/DISTINCT]
# 查詢員工表和部門表的所有name
(SELECT id,`name`
FROM t_employee e)
UNION
(SELECT `name`,id
FROM t_department d)
執行結果:
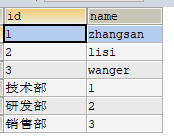
這裏查詢結果的欄位數需要一樣。