MySQL
MySQL
1、初識MySQL
- MySQL是一種開放原始碼的關係型數據庫管理系統(RDBMS),使用最常用的數據庫管理語言–結構化查詢語言(SQL)進行數據庫管理。
- MySQL是開放原始碼的,因此任何人都可以在General Public License的許可下下載並根據個性化的需要對其進行修改。
- MySQL因爲其速度、可靠性和適應性而備受關注。大多數人都認爲在不需要事務化處理的情況下,MySQL是管理內容最好的選擇。
數據庫的介紹
MySQL這個名字,起源不是很明確。一個比較有影響的說法是,基本指南和大量的庫和工具帶有字首「my」已經有10年以上,而且不管怎樣,MySQL AB創始人之一的Monty Widenius的女兒也叫My。這兩個到底是哪一個給出了MySQL這個名字至今依然是個迷,包括開發者在內也不知道。
MySQL的海豚標誌的名字叫「sakila」,它是由MySQL AB的創始人從使用者在「海豚命名」的競賽中建議的大量的名字表中選出的。獲勝的名字是由來自非洲斯威士蘭的開源軟件開發者Ambrose Twebaze提供。根據Ambrose所說,Sakila來自一種叫SiSwati的斯威士蘭方言,也是在Ambrose的家鄉烏幹達附近的坦桑尼亞的Arusha的一個小鎮的名字。
MySQL,雖然功能未必很強大,但因爲它的開源、廣泛傳播,導致很多人都瞭解到這個數據庫。它的歷史也富有傳奇性。

1.1、什麼是數據庫
數據庫(DB,DataBase)
概念: 數據倉庫,軟體,安裝在操作系統之上,可以儲存大量數據
作用: 儲存數據,管理數據
1.2、數據庫分類
關係型數據庫: (SQL)
- MySQL,Oracle,SqlServer,DB2,SQLlite
- 通過表和表之間,行和列之間的關係進行數據的儲存
非關係型數據庫: (NoSQL) Not Only 不僅僅是SQL
- Redis,MongDB
- 非關係型數據庫,物件儲存,通過物件的自身屬性絕對。
DBMS(數據庫管理系統)
DBMS負責執行sql語句,通過執行sql語句來操作DB當中的數據。
DBMS -(執行)-> SQL -(操作)-> DB
數據庫管理系統是一種操縱和管理數據庫的大型軟體,用於建立、使用和維護數據庫,簡稱 DBMS。它對數據庫進行統一的管理和控制,以保證數據庫的安全性和完整性。
數據庫管理系統是一個能夠提供數據錄入、修改、查詢的數據操作軟體,具有數據定義、數據操作、數據儲存與管理、數據維護、通訊等功能,且能夠允許多使用者使用。另外,數據庫管理系統的發展與計算機技術發展密切相關。而且近年來,計算機網路逐漸成爲人們生活的重要組成部分。爲此,若要進一步完善計算機數據庫管理系統,技術人員就應當不斷創新、改革計算機技術,並不斷拓寬計算機數據庫管理系統的應用範圍,從而真正促進計算機數據庫管理系統技術的革新。
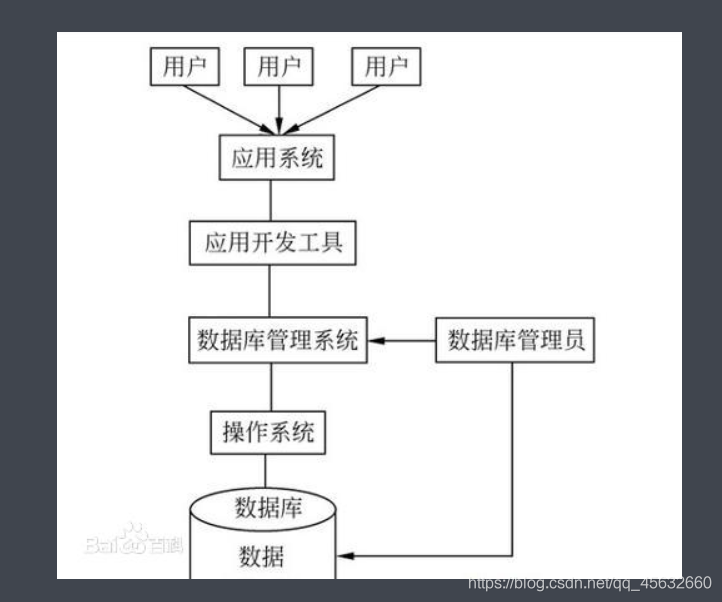
數據庫管理系統概述圖
1.3、MySQL官網下載
https://dev.mysql.com/downloads/mysql/
1.4、安裝MySQL
https://blog.csdn.net/weixin_45764012/article/details/104570795
sc delete mysql, 清空服務/刪除mysql
1.5、連線數據庫
命令列連線
# 連線數據庫
mysql -uroot -p
# 檢視數據庫版本號
select version()
# 所有的語句都用分號結尾
# 檢視所有的數據庫
show databases;
# 使用數據庫
use 數據庫名;
# 檢視所有的表
show tables;
# 顯示錶中得到所有資訊
describe 表名;
# 建立數據庫
create database 數據庫名;
DDL 數據庫定義語言
DML 數據庫操作語言
DQL 數據庫查詢語言
DCL 數據庫控制語言
2、操作數據庫
2.1、簡單操作數據庫
# 建立數據庫
CREATE DATABASE [IF NOT EXISTS] test IF NOT EXISTS 即如果不存在
# 刪除數據庫
DROP DATABASE [IF EXISTS] test IF EXISTS 即如果存在
# 使用數據庫
USE bjpowernode //如果你的表明或者欄位名有特殊符號 需要加上``
2.2、數據庫的列型別
數值
-
tinyint 十分小的數據 1位元組
-
smallint 較小的數據 2位元組
-
mediumint 中等大小的數據 3位元組
-
int 標準的整數 4位元組 常用
-
bigint 較大數據 8位元組
-
float 單精度浮點數 4位元組
-
double 雙精度浮點數 8位元組
-
decimal 字串形式的浮點數 金融計算的時候,一般是使用decimal
字串
- char 字串固定大小的 0~255
- varchar 可變字串 0~65535
- tinytext 微型文字
- text 字串
事件日期
- date 日期格式
- time 事件格式
- datetime 日期格式 常用
- timestamp 時間戳 常用
- year 年份表示
null
- 沒有值,位置
- 注意,不要使用NULL進行運算,結果爲NULL
2.3、數據庫的欄位屬性(重點)
Unsigned:
-
無符號的整數
-
宣告瞭該列不能宣告爲負數
zerofill:
-
0填充的
-
不足的位數,使用0來填充
自增:(auto_increment)
- 通常理解爲自增,自動在上一條記錄的基礎上+1(預設)
- 通常用來設計唯一的主鍵~ index,必須是整數型別
- 可以自定義涉及主鍵自增的起始值和步長
非空: NULL not null
-
假設設定爲not null,如果不給它複製,就會報錯!
-
Null,如果不填寫值,預設就是null!
預設:
- 設定預設的值
2.4、建立數據庫表
# primary key 主鍵
# auto_increment 自增
# not null 非空
# comment 描述
# DEFAULT 預設值
# INNODB 引擎
CREATE DATABASE school
CREATE TABLE IF NOT EXISTS `student` (
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '學號',
`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密碼',
`sex` VARCHAR(2) NOT NULL DEFAULT '男' COMMENT '性別',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '郵箱',
PRIMARY KEY (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
格式
create table 表名(
欄位名 列型別 [屬性][索引][註釋],
欄位名 列型別 [屬性][索引][註釋],
欄位名 列型別 [屬性][索引][註釋],
........
欄位名 列型別 [屬性][索引][註釋]
)[表型別][字元集設定][註釋]
常用命令
show create database 數據庫名 --檢視建立數據庫的語句
show create table 表名 --檢視建立表的語句
desc 表名 --檢視錶的結構
2.5、數據表的型別
--關於數據庫引擎
INNODB 預設使用~
MYISAM 早些年使用
| MYISAM | INNODB | |
|---|---|---|
| 事務支援 | 不支援 | 支援 |
| 數據行鎖定 | 不支援 | 支援 |
| 外來鍵約束 | 不支援 | 支援 |
| 全文索引 | 支援 | 不支援 |
| 表空間大小 | 較小 | 較大越2倍 |
常規使用操作:
- MYISAM 節約空間,速度較快
- INNODB 安全性高,事務的處理,多表多使用者操作
在物理空間存在的位置
所有的數據庫檔案都存在data目錄下,一個資料夾就對應一個數據庫
本質是檔案的儲存!
MySQL引擎在物理檔案上的區別
- InnoDB在數據庫表中只有一個*.frm檔案,以及上級目錄下的ibdata1檔案
- MYISAM對應檔案
- *.frm 表結構的定義檔案
- *.MYD 數據檔案(data)
- *.MYI 索引檔案(index)
設定數據庫表的字元集編碼
charset=utf8
不設定的話,會是mysql預設的字元集編碼 (不支援中文)
MySQL的預設編碼是Latin1,不支援中文
在my.ini中設定預設的編碼(不建議使用)
character-set-server=utf8
2.6、修改刪除表
修改
--修改表名
ALTER TABLE 舊錶名 RENAME AS 新表名
--修改欄位
ALTER TABLE 表名 ADD 欄位 型別
--修改表的欄位(重新命名,修改約束~)
ALTER TABLE 表名 MODIEY 欄位 型別 --修改約束
ALTER TABLE 表名 CHANGE 舊欄位 新欄位 型別 --重新命名
--刪除表的欄位
ALTER TABLE 表名 DROP 欄位
刪除
-- 刪除表(如果表存在再刪除)
DROP TABLE IF EXISTS 表名
3、MySQL數據管理
3.1、外來鍵(瞭解即可)
* 關於外來鍵約束的相關術語:
外來鍵約束: foreign key
外來鍵欄位:新增有外來鍵約束的欄位
外來鍵值:外來鍵欄位中的每一個值。
* 業務背景:
請設計數據庫表,用來維護學生和班級的資訊?
第一種方案:一張表儲存所有數據
no(pk) name classno classname
-------------------------------------------------------------------------------------------
1 zs1 101 北京大興區經濟技術開發區亦莊二中高三1班
2 zs2 101 北京大興區經濟技術開發區亦莊二中高三1班
3 zs3 102 北京大興區經濟技術開發區亦莊二中高三2班
4 zs4 102 北京大興區經濟技術開發區亦莊二中高三2班
5 zs5 102 北京大興區經濟技術開發區亦莊二中高三2班
缺點:冗餘。【不推薦】
第二種方案:兩張表(班級表和學生表)
t_class 班級表
cno(pk) cname
--------------------------------------------------------
101 北京大興區經濟技術開發區亦莊二中高三1班
102 北京大興區經濟技術開發區亦莊二中高三2班
t_student 學生表
sno(pk) sname classno(該欄位新增外來鍵約束fk)
------------------------------------------------------------
1 zs1 101
2 zs2 101
3 zs3 102
4 zs4 102
5 zs5 102
* 將以上表的建表語句寫出來:
t_student中的classno欄位參照t_class表中的cno欄位,此時t_student表叫做子表。t_class表叫做父表。
順序要求:
刪除數據的時候,先刪除子表,再刪除父表。
新增數據的時候,先新增父表,在新增子表。
建立表的時候,先建立父表,再建立子表。
刪除表的時候,先刪除子表,在刪除父表。
drop table if exists t_student;
drop table if exists t_class;
create table t_class(
cno int,
cname varchar(255),
primary key(cno)
);
create table t_student(
sno int,
sname varchar(255),
classno int,
primary key(sno),
foreign key(classno) references t_class(cno)
);
insert into t_class values(101,'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx');
insert into t_class values(102,'yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy');
insert into t_student values(1,'zs1',101);
insert into t_student values(2,'zs2',101);
insert into t_student values(3,'zs3',102);
insert into t_student values(4,'zs4',102);
insert into t_student values(5,'zs5',102);
insert into t_student values(6,'zs6',102);
* 外來鍵值可以爲NULL?
外來鍵可以爲NULL。
* 外來鍵欄位參照其他表的某個欄位的時候,被參照的欄位必須是主鍵嗎?
注意:被參照的欄位不一定是主鍵,但至少具有unique約束。
3.2、DML語言(全部記住)
新增
--第一種方式
insert into 表名(欄位,欄位,欄位) values (值,值,值)
--第二種
insert into 表名(值,值,值..) --注意要對應表的第一個欄位開始寫對應的值
--第三種
insert into 表名(欄位,欄位) values (值,值),(值,值).. --可以爲對應的欄位新增多個值 注意用逗號隔開
修改
update 表 set 欄位 where 條件
--例子:
update teacher set name='哈拉少' where id = 1 --將id等於1的 name欄位裏面的值改爲哈拉少
where 條件:
操作符
| 操作符 | 含義 |
|---|---|
| = | 等於 |
| <>或!= | 不等於 |
| < | 大於 |
| > | 小於 |
| <= | 大於等於 |
| >= | 小於等於 |
| between…and… | 閉合區間/在…之間 |
| and | &&(兩個真,纔可以查詢) |
| or | ||(一個爲真,就可以查詢) |
刪除
# 語法
delete from 表名 where 條件
TRUNCATE 命令
作用:完全清空一個數據庫表,表的結構和索引約束不會變!
# 清空表數據
TRUNCATE 表名
delete 和 TRUNCATE 區別
- 相同點: 都能刪除數據,都不會刪除表結構
- 不同:
- TRUNCATE 重新設定 自增列 計數器會歸零
- TRUNCATE 不會影響事務
4、DQL查詢數據
4.1、DQL
(Data Qyery LANGUAGE :數據查詢語言)
- 所有的查詢操作都用它 select
- 簡單的查詢,複雜的查詢它都能做~
- 數據庫中最核心的語言,最重要的語句
- 使用頻率最高的語句
4.2、指定查詢欄位
# 查詢所有
select * from 表名
# 查詢所有的學生
SELECT * FROM student

# 查詢指定的欄位
select 欄位 from 表名
# 查詢student表裏面學生的姓名
select studentname from student

# 起別名 as
SELECT studentname AS 姓名 FROM student

# 函數
count 計數
sum 求和
avg 平均值
max 最大值
min 最小值
# count就是用來計數
select count(欄位) from 表名
# 學生表裏學生姓名一共有幾個
SELECT COUNT(studentname) 新名字 FROM student

去重 distinct
# 語法
select distinct 欄位 from 表名
數據庫的列(表達式)
-- 學院考試成績+1分檢視
SELECT studentresult + 1 AS 成績 FROM result
數據庫中的表達式: 文字值,列,NULL,函數,計算表達式…
select 表達式 from 表名
4.3、where條件字句
作用:檢索數據中符合條件的值
搜尋的條件由一個或者多個表達式組成! 結果布爾值
邏輯運算子
| 運算子 | 描述 |
|---|---|
| and / && | 邏輯與,倆個都爲真,結果爲真 |
| or / | | 邏輯或,其中一個爲真,則結果爲真 |
| Not / ! | 邏輯非,真爲假,假爲真! |
-- 列子
-- 查詢成績在60到100之間
-- 第一種方法
SELECT * FROM result WHERE studentresult BETWEEN 60 AND 100;
-- 第二種方法
SELECT * FROM result WHERE studentresult>=60 AND studentresult<=100;
-- 第三種方法
SELECT * FROM result WHERE studentresult>=60 && studentresult<=100;
-- 檢視學生編號1000以外的
-- 第一種方法
SELECT * FROM result WHERE studentno != 1000;
-- 第二種方法
SELECT * FROM result WHERE NOT studentno = 1000;
模糊查詢: 比較運算子
| 運算子 | 描述 |
|---|---|
| is null | 結果爲空 |
| is not null | 結果不爲空 |
| between | 閉區間/ 在…之間 |
| like | 匹配對應的數據 |
| in | 查詢in裏面具體數據 |
-- 例子
-- 模糊查詢like
-- like結合 %(代表0到任意個字元) _(一個字元)
-- 查詢學生姓是張的
SELECT * FROM student WHERE studentname LIKE '張%';
-- 查詢學生姓張的同學 名字後面只有一個字
SELECT * FROM student WHERE studentname LIKE '張_';
-- 查詢學生姓名最後一個字是麗
SELECT * FROM student WHERE studentname LIKE '%麗';
-- 查詢學生姓名第二個字是國的
SELECT * FROM student WHERE studentname LIKE '_國%';
-- in(具體的一個或者多個值)
-- 查詢1000,1001學生的資訊
SELECT * FROM student WHERE studentno IN(1000,1001);
4.4、聯表查詢
根據表的連線方式來劃分,包括:
內連線:
等值連線
非等值連線
自連線
外連線:
左外連線(左連線)
右外連線(右連線)
全連線(這個不講,很少用!)
內連線:
內連線之等值連線:最大特點是:條件是等量關係。
內連線之非等值連線:最大的特點是:連線條件中的關係是非等量關係。
自連線:最大的特點是:一張表看做兩張表。自己連線自己。
什麼是外連線,和內連線有什麼區別?
內連線:
假設A和B表進行連線,使用內連線的話,凡是A表和B表能夠匹配上的記錄查詢出來,這就是內連線。
AB兩張表沒有主副之分,兩張表是平等的。
外連線:
假設A和B表進行連線,使用外連線的話,AB兩張表中有一張表是主表,一張表是副表,主要查詢主表中
的數據,捎帶着查詢副表,當副表中的數據沒有和主表中的數據匹配上,副表自動模擬出NULL與之匹配。
外連線的分類?
左外連線(左連線):表示左邊的這張表是主表。
右外連線(右連線):表示右邊的這張表是主表。
左連線有右連線的寫法,右連線也會有對應的左連線的寫法。
| 操作 | 描述 |
|---|---|
| inner join | 如果表中至少有一個匹配,就返回值 |
| left join | 會從左表中返回所有的值.即使右表中沒有匹配 |
| right join | 會從右表中返回所有的值.即使左表中沒有匹配 |
自連線
自連線:最大的特點是:一張表看做兩張表。自己連線自己。
-- 案例:找出每個員工的上級領導,要求顯示員工名和對應的領導名。
SELECT
a.ename AS '員工名',b.ename AS '領導名'
FROM
emp a
INNER JOIN
emp b
ON
a.mgr = b.empno;
4.5、分頁和排序
-- 排序 order by
-- 升序 asc 降序 desc
-- where後面不能直接寫orderby 需要寫 where 條件 orderby
# 對工資進行降序排序
SELECT sal FROM emp ORDER BY sal DESC;
-- 分頁 limit
-- 如果需要排序+分頁,那麼分頁必須要寫在排序的後面
-- limit (查詢起始下標,頁面大小pageSize)
4.6、子查詢
-- select語句當中巢狀select語句,被巢狀的select語句是子查詢。
-- 在where語句中巢狀一個子查詢語句
--例子找出高於平均薪資的員工的資訊
SELECT * FROM emp WHERE sal >(SELECT AVG(sal) FROM emp)
4…7、分組和過濾
-- group by : 按照某個欄位或者某些欄位進行分組。
-- having : having是對分組之後的數據進行再次過濾。
-- 注意:分組函數一般都會和group by聯合使用,這也是爲什麼它被稱爲分組函數的原因。
-- 並且任何一個分組函數(count sum avg max min)都是在group by語句執行結束之後纔會執行的。
-- 當一條sql語句沒有group by的話,整張表的數據會自成一組。
-- where後面不能使用分組函數:
select deptno,avg(sal) from emp where avg(sal) > 2000 group by deptno; // 錯誤了。
這種情況只能使用having過濾。
-- 每個工作崗位的平均薪資?
SELECT AVG(sal),job FROM emp GROUP BY job
-- 找出每個部門的最高薪資,要求顯示薪資大於2900的數據。
SELECT MAX(sal),job FROM emp GROUP BY job HAVING MAX(sal) > 2900
5、函數
5.1、常用函數(不常用)
mysql官方文件: https://dev.mysql.com/doc/refman/5.7/en/sql-function-reference.html
-- ========= 常用函數 =====================
-- 數學運算
SELECT ABS(-20) -- 絕對值
SELECT CEIL(9.5) -- 向上取整
SELECT FLOOR(9.3) -- 向下取整
SELECT RAND() -- 返回一個0~1的亂數
SELECT SIGN(100) -- 判斷一個數的符號 0返回0 負數返回-1 整數返回1
-- 字串
SELECT CHAR_LENGTH('餘香') -- 字串長度
SELECT CONCAT('我','愛','你') -- 拼接字串
SELECT INSERT('我愛你餘香',1,2,'超級愛') -- 從某個位置開始替換某個長度
SELECT LOWER('YUXIANG') -- 將大寫字母轉化爲小寫字母
SELECT UPPER('yuxiang') -- 將小寫字母轉化爲大寫字母
SELECT INSTR('yuxiang','x') -- 返回第一次出現的索引 通過下標1開始
SELECT REPLACE('餘香努力學習','努力','奮鬥') -- 替換指定的字串
SELECT SUBSTR('餘香說即使再小的帆也能遠航',3,5) -- 返回指定的字串(通過下標擷取長度)
SELECT REVERSE('餘香') -- 反轉
-- 時間和日期函數
SELECT CURRENT_DATE() -- 獲取當前的日期
SELECT CURDATE() -- 獲取當前的日期
SELECT NOW() -- 獲取當前的時間
SELECT LOCALTIME() -- 獲取本地時間
SELECT SYSDATE() -- 獲取系統時間
SELECT YEAR(NOW()) -- 獲取當前的年份
SELECT MONTH(NOW()) -- 月份
SELECT DAY(NOW()) -- 日期
SELECT HOUR(NOW()) -- 小時
SELECT MINUTE(NOW()) -- 分鐘
SELECT SECOND(NOW()) -- 秒
-- 系統
SELECT SYSTEM_USER() -- 本機使用者名稱
SELECT USER() -- 使用者名稱
SELECT VERSION() -- 版本號
5.2、聚合函數(常用)
| 函數名稱 | 描述 |
|---|---|
| count() | 計數 |
| sum() | 求和 |
| avg() | 平均值 |
| max() | 最大值 |
| min() | 最小值 |
| … | … |
-- ================聚合函數==================
SELECT COUNT(comm) FROM emp -- count(欄位) 會忽略所有的null值
SELECT COUNT(*) FROM emp -- count(*) 不會忽略null值,
SELECT COUNT(1) FROM emp -- count(1) 不會忽略所有的null值
SELECT SUM(sal) AS '求和' FROM emp
SELECT AVG(sal) AS '平均值' FROM emp
SELECT MAX(sal) AS '最大值' FROM emp
SELECT MIN(sal) AS '最小值' FROM emp
5.3、數據庫界別的MD5加密(擴充套件)3
什麼是MD5
「md5是一種資訊摘要演算法,它可以從一個字串或一個檔案中按照一定的規則生成一個特殊的字串,並且一個檔案所對應的MD5摘要是固定的,當檔案內容變化後,其MD5值也會不一樣,因此,在應用中經常使用MD5值來驗證一段數據有沒有被篡改。」
CREATE TABLE user2(
id INT(4) AUTO_INCREMENT COMMENT 'id',
PASSWORD VARCHAR(100) NOT NULL COMMENT '密碼',
PRIMARY KEY(id)
)ENGINE=INNODB CHARSET=utf8
-- 插入式加密
INSERT INTO user2 VALUE(1,MD5(123456))

6、事務
6.1、什麼是事務?
一個事務是一個完整的業務邏輯單元,不可再分。
比如:銀行賬戶轉賬,從A賬戶向B賬戶轉賬10000.需要執行兩條update語句:
update t_act set balance = balance - 10000 where actno = 'act-001';
update t_act set balance = balance + 10000 where actno = 'act-002';
以上兩條DML語句必須同時成功,或者同時失敗,不允許出現一條成功,一條失敗。
要想保證以上的兩條DML語句同時成功或者同時失敗,那麼就需要使用數據庫的「事務機制 機製」。
6.2、事務的特性
# 事務包括四大特性:ACID
原子性(Atomic)
整個事務中的所有操作,要麼全部完成,要麼全部不完成,不可能停滯在中間某個環節。事務在執行過程中發生錯誤,會被回滾(ROLLBACK)到事務開始前的狀態,就像這個事務從來沒有執行過一樣。
一致性(Consist)
一個事務可以封裝狀態改變(除非它是一個只讀的)。事務必須始終保持系統處於一致的狀態,不管在任何給定的時間併發事務有多少。也就是說:如果事務是併發多個,系統也必須如同序列事務一樣操作。其主要特徵是保護性和不變性(Preserving an Invariant),以轉賬案例爲例,假設有五個賬戶,每個賬戶餘額是100元,那麼五個賬戶總額是500元,如果在這個5個賬戶之間同時發生多個轉賬,無論併發多少個,比如在A與B賬戶之間轉賬5元,在C與D賬戶之間轉賬10元,在B與E之間轉賬15元,五個賬戶總額也應該還是500元,這就是保護性和不變性。
隔離性(Isolated)
隔離狀態執行事務,使它們好像是系統在給定時間內執行的唯一操作。如果有兩個事務,執行在相同的時間內,執行相同的功能,事務的隔離性將確保每一事務在系統中認爲只有該事務在使用系統。這種屬性有時稱爲序列化,爲了防止事務操作間的混淆,必須序列化或序列化請求,使得在同一時間僅有一個請求用於同一數據。
永續性(Durable)
在事務完成以後,該事務對數據庫所作的更改便持久的儲存在數據庫之中,並不會被回滾。
6.3、事務的併發問題
# 事務的併發問題
1、髒讀:事務A讀取了事務B更新的數據,然後B回滾操作,那麼A讀取到的數據是髒數據
2、不可重複讀:事務 A 多次讀取同一數據,事務 B 在事務A多次讀取的過程中,對數據作了更新並提交,導致事務A多次讀取同一數據時,結果 不一致。
3、幻讀:系統管理員A將數據庫中所有學生的成績從具體分數改爲ABCDE等級,但是系統管理員B就在這個時候插入了一條具體分數的記錄,當系統管理員A改結束後發現還有一條記錄沒有改過來,就好像發生了幻覺一樣,這就叫幻讀。
小結:不可重複讀的和幻讀很容易混淆,不可重複讀側重於修改,幻讀側重於新增或刪除。解決不可重複讀的問題只需鎖住滿足條件的行,解決幻讀需要鎖表
6.4、關於事務之間的隔離性
# 事務隔離性存在隔離級別,理論上隔離級別包括4個:
第一級別:讀未提交(read uncommitted)
對方事務還沒有提交,我們當前事務可以讀取到對方未提交的數據。
讀未提交存在髒讀(Dirty Read)現象:表示讀到了髒的數據。
第二級別:讀已提交(read committed)
對方事務提交之後的數據我方可以讀取到。
這種隔離級別解決了: 髒讀現象沒有了。
讀已提交存在的問題是:不可重複讀。
第三級別:可重複讀(repeatable read)
這種隔離級別解決了:不可重複讀問題。
這種隔離級別存在的問題是:讀取到的數據是幻象。
第四級別:序列化讀/序列化讀(serializable)
解決了所有問題。
效率低。需要事務排隊。
oracle數據庫預設的隔離級別是:讀已提交。
mysql數據庫預設的隔離級別是:可重複讀。
6.5、執行事務
-- ============================事務===========================
-- mysql是預設開啓事務自動提交的
SET autocommit = 0 // 關閉
SET autocommit = 1 //開啓
-- 手動處理事務
SET autocommit = 0
-- 事務開啓
START TRANSACTION
INSERT xxxx
-- 提交 持久化(成功)
COMMIT
-- 回滾 回到原來的樣子(失敗)
ROLLBACK
-- 事務結束
SET autocommit = 1
7、索引
MySQL官方對索引的定義爲: 索引(Index) 是幫助MySQL高效獲取數據的數據結構
7.1、索引的分類
- 主鍵索引(primary key)
- 唯一的標識,主鍵不可重複,不能爲NULL,只能有一個列作爲主鍵
- 唯一索引(unique)
- 不可以出現相同的值,可以有NULL值
- 常規索引(key/index)
- 預設的,index,key關鍵字來設定
- 全文索引(fulltext index)
- 在特定的數據庫引擎下纔有,MyISAM
- 快速定位數據
基礎語法
-- 索引的使用
-- 1、在建立表的時候給欄位增加索引
-- 2、建立完畢後,增加索引
-- 顯示索引的所有資訊
SHOW INDEX FROM student
-- 增加一個全文索引(索引名) 列名
-- 第二種方式
ALTER TABLE 表名 ADD 索引型別 (unique,PRIMARY KEY,FULLTEXT,index)[索引名](欄位名)
ALTER TABLE student ADD UNIQUE address(address)
-- explain 分析sql執行的狀況
EXPLAIN SELECT * FROM student
-- 第三種方式
建立索引物件:
create index 索引名稱 on 表名(欄位名);
刪除索引物件:
drop index 索引名稱 on 表名;
例如 create index emp_sal_index on emp(sal)
7.2、什麼時候考慮給欄位新增索引
* 數據量龐大。(根據客戶的需求,根據線上的環境)
* 該欄位很少的DML操作。(因爲欄位進行修改操作,索引也需要維護)
* 該欄位經常出現在where子句中。(經常根據哪個欄位查詢)
注意: 主鍵和具有unique約束的欄位自動會新增索引。
根據主鍵查詢效率較高。儘量根據主鍵檢索。
7.3、索引原則
- 索引不是越多越好
- 不要對進程變動數據加索引
- 小數據量的表不需要加索引
- 索引一般都載入常用查詢的欄位上!
7.4、索引的實現原理
# 通過B Tree縮小掃描範圍,底層索引進行了排序,分割區,索引會攜帶數據在表中的「實體地址」,最終通過索引檢索到數據之後,獲取到關聯的實體地址,通過實體地址定位表中的數據,效率是最高的。
select ename from emp where ename = 'SMITH';
通過索引轉換爲:
select ename from emp where 實體地址 = 0x3;
8、許可權管理和備份
8.1、使用者管理
SQL yog 視覺化管理
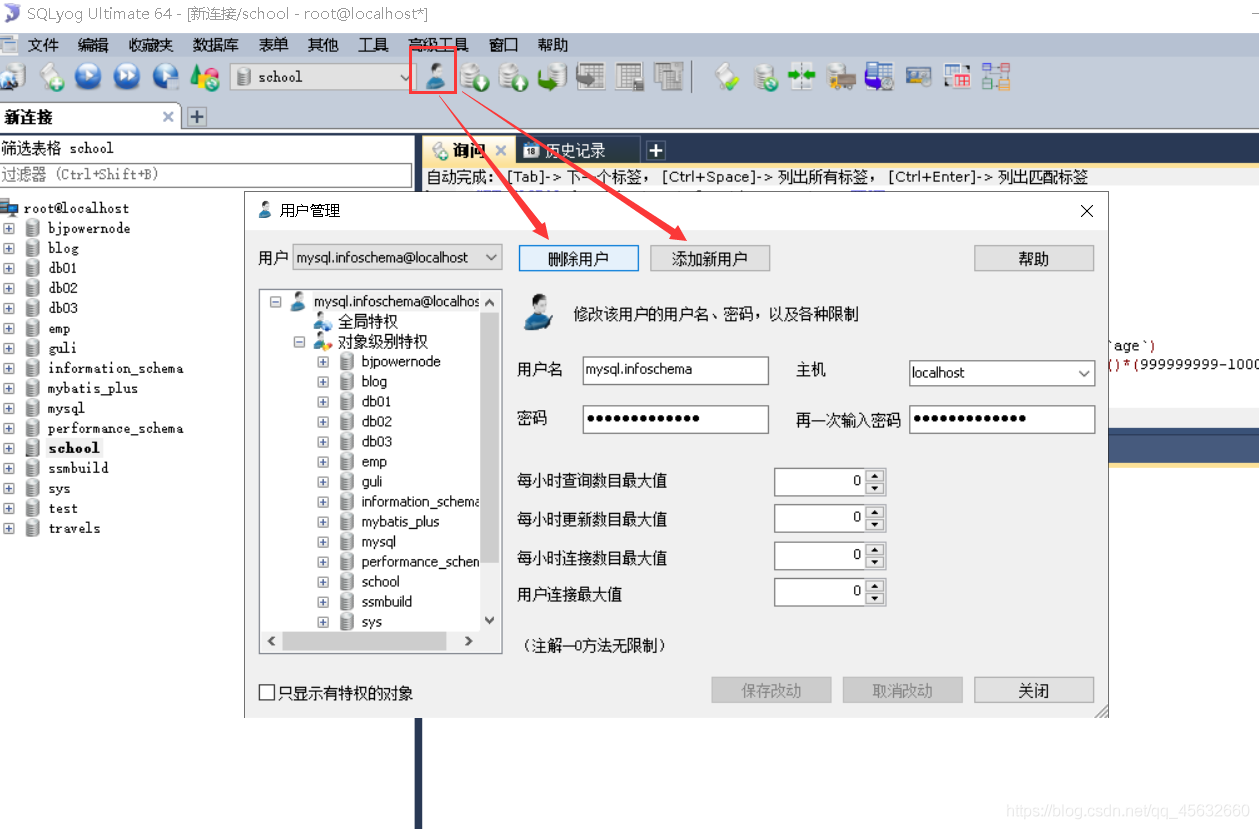
SQL命令
使用者表: mysql.user
本質: 讀這張表進行增刪改查
-- 建立使用者 CREATE USER 使用者名稱 IDENTIFIED BY '密碼'
CREATE USER kuangshen IDENTIFIED BY '123456'
-- 修改密碼(修改當前使用者密碼)
SET PASSWORD = PASSWORD('密碼')
-- 修改密碼(修改指定使用者密碼)
SET PASSWORD FOR 使用者名稱 = PASSWORD('密碼')
-- 重新命名
RENAME USER 舊名 TO 新名
-- 使用者授權 全部的許可權表
-- ALL PRIVILEGES 除了給別人授權,其它都可以幹
GRANT ALL PRIVILEGES ON *.* TO 使用者名稱
-- 檢視許可權
SHOW GRANTS FOR 使用者名稱 -- 檢視使用者許可權
SHOW GRANTS FOR root@localhost -- 檢視主使用者許可權
-- 復原許可權
REVOKE ALL PRIVILEGES ON *.* FROM 使用者名稱
-- 刪除使用者
DROP USER 使用者名稱
8.2、MySQL備份
爲什麼要備份:
- 保證重要的數據不丟失
- 數據轉移
MySQL數據庫備份的方式
-
直接拷貝物理檔案 data
-
在Sqlyog這種視覺化工具中手動導出
- 在想要導出的表或者庫中,右鍵,選擇備份或導出
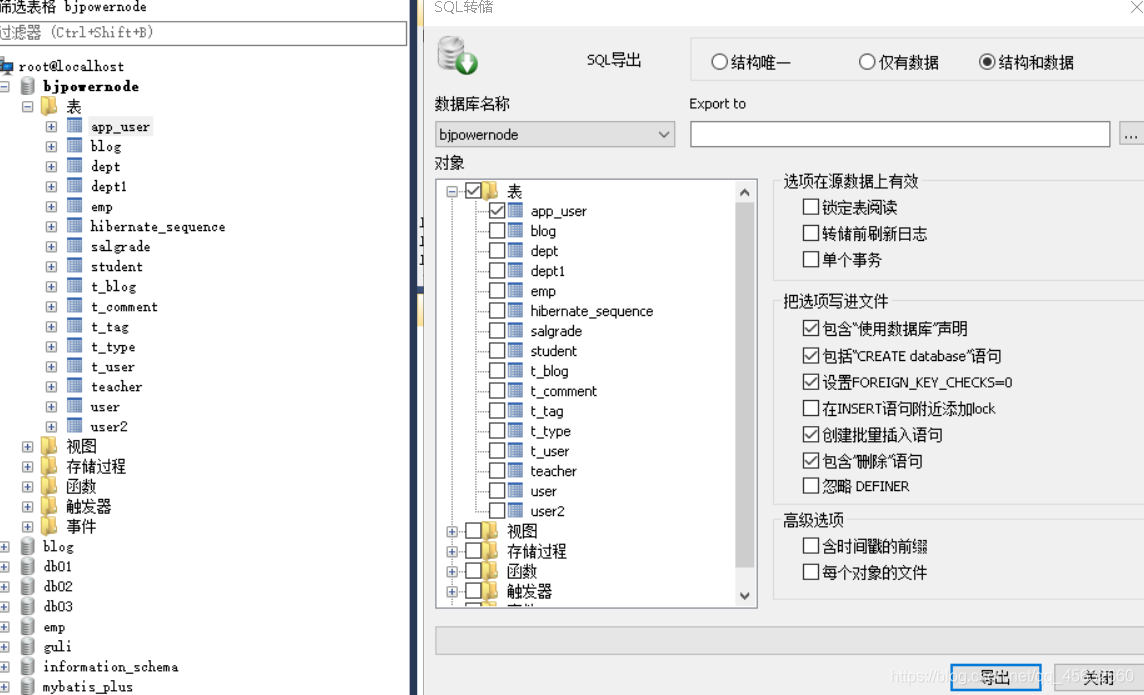
- 在想要導出的表或者庫中,右鍵,選擇備份或導出
-
使用命令導出mysqldump 命令列使用
-- 不用登錄mysql 直接導出
-- mysqldump -h 主機 -u 使用者名稱 -p 密碼 數據庫 表名 > 物理磁碟位置/檔名
-- 多張表
-- mysqldump -h 主機 -u 使用者名稱 -p 密碼 數據庫 表1 表2 表3 > 物理磁碟位置/檔名
-- 選擇一個數據庫
-- mysqldump -h 主機 -u 使用者名稱 -p 密碼 數據庫 > 物理磁碟位置/檔名
-- 匯入數據庫 需要登錄mysql
-- source 物理磁碟位置/檔名
9、規範數據庫設定
9.1、爲什麼需要設計
當數據庫比較複雜的時候,我們就需要設計了
糟糕的數據庫設計
- 數據冗餘,浪費空間
- 數據庫插入和刪除都會麻煩、異常【遮蔽使用物理外來鍵】
- 程式的效能差
良好的數據庫設計
- 節省記憶體空間
- 保證數據庫的完整性
- 方便我們開發系統
軟件開發中,關於數據庫的設計
- 分析需求: 分析業務和需求處理的數據庫的需要
- 概要設計: 設計關係圖 E-R 圖
9.2、三大規範
爲什麼需要數據規範化?
- 資訊重複
- 更新異常
- 插入異常
- 無法正常顯示資訊
- 刪除異常
- 丟失有效的資訊
三大範式
部落格介紹: https://www.jianshu.com/p/08d123026438
第一範式
原則性: 保證沒一列不可再分
第二範式
前提: 滿足第一範式
每張表只描述一件事情
第三範式
前提: 滿足第一範式 和 第二範式
第三範式需要確保數據表中的每一列數據都和主鍵直接相關,而不能間接相關