數據庫中介軟體詳解
1 數據庫拆分過程及挑戰
網際網路當下的數據庫拆分過程基本遵循的順序是:垂直拆分、讀寫分離、分庫分表(水平拆分)。每個拆分過程都能解決業務上的一些問題,但同時也面臨了一些挑戰。
1.1 垂直拆分
對於一個剛上線的網際網路專案來說,由於前期活躍使用者數量並不多,併發量也相對較小,所以此時企業一般都會選擇將所有數據存放在一個數據庫 中進行存取操作。舉例來說,對於一個電商系統,其使用者模組和產品模組的表剛開始都是位於一個庫中。 其中:user、useraccount表屬於使用者模組,productcategory、product表屬於產品模組
其中:user、useraccount表屬於使用者模組,productcategory、product表屬於產品模組
剛開始,可能公司的技術團隊規模比較小,所有的數據都位於一個庫中。隨着公司業務的發展,技術團隊人員也得到了擴張,劃分爲不同的技術小組,不同的小組負責不同的業務模組。例如A小組負責使用者模組,B小組負責產品模組。此時數據庫也迎來了第一次拆分:垂直拆分。
這裏的垂直拆分,指的是將一個包含了很多表的數據庫,根據表的功能的不同,拆分爲多個小的數據庫,每個庫包含部分表。下圖演示將上面提到的db_eshop庫,拆分爲db_user庫和db_product庫。
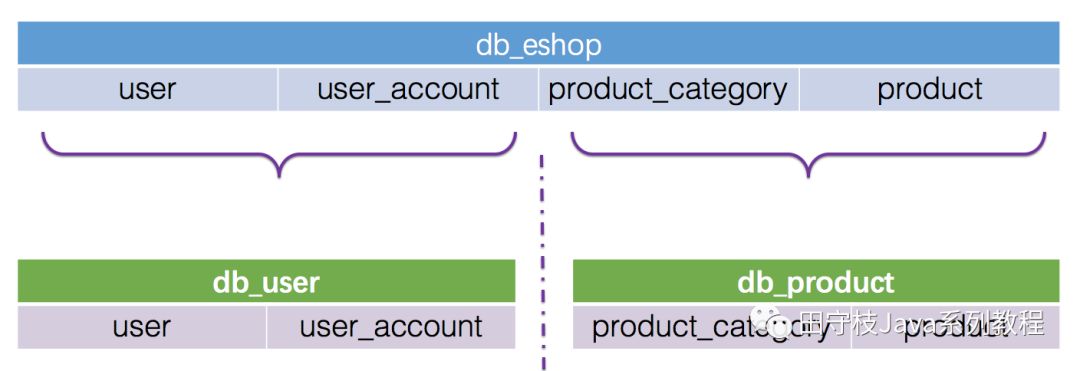
通常來說,垂直拆分,都是根據業務來對一個庫中的表進行拆分的。關於垂直拆分,還有另一種說法,將一個包含了很多欄位的大表拆分爲多個小表,每個表包含部分欄位,這種情況在實際開發中基本很少遇到。
垂直拆分的另一個典型應用場景是服務化(SOA)改造。在服務化的背景下,除了業務上需要進行拆分,底層的儲存也需要進行隔離。 垂直拆分會使得單個使用者請求的響應時間變長,原因在於,在單體應用的場景下,所有的業務都可以在一個節點內部完成,而垂直拆分之後,通常會需要進行RPC呼叫。然後雖然單個請求的響應時間增加了,但是整個服務的吞吐量確會大大的增加。
1.2 讀寫分離
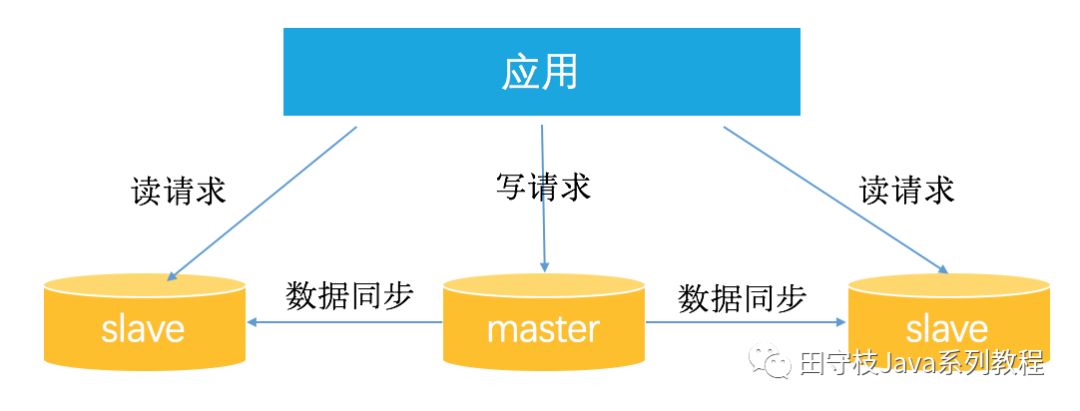
隨着業務的不斷髮展,使用者數量和併發量不斷上升。這時如果僅靠單個數據庫範例來支撐所有存取壓力,幾乎是在 自尋死路 。以產品庫爲例,可能庫中包含了幾萬種商品,並且每天新增幾十種,而產品庫每天的訪問了可能有幾億甚至幾十億次。數據庫讀的壓力太大,單台mysql範例扛不住,此時大部分 Mysql DBA 就會將數據庫設定成 讀寫分離狀態 。也就是一個 Master 節點(主庫)對應多個 Salve 節點(從庫)。可以將slave節點的數據理解爲master節點數據的全量備份。
![]()
master節點接收使用者的寫請求,並寫入到本地二進制檔案(binary log)中。slave通過一個I/O執行緒與Master建立連線,發送binlog dump指令。Master會將binlog數據推播給slave,slave將接收到的binlog儲存到原生的中繼日誌(relay log)中,最後,slave通過另一個執行緒SQL thread應用原生的relay log,將數據同步到slave庫中。
關於mysql主從複製,內部包含很多細節。例如binlog 格式分爲statement、row和mixed,binlog同步方式又可以劃分爲:非同步、半同步和同步。複製可以基於binlogFile+position,也可以基於GTID。通常,這些都是DBA負責維護的,業務RD無感知。
在DBA將mysql設定成主從複製叢集的背景下,開發同學所需要做的工作是:當更新數據時,應用將數據寫入master主庫,主庫將數據同步給多個slave從庫。當查詢數據時,應用選擇某個slave節點讀取數據。
1.2.1 讀寫分離的優點
這樣通過設定多個slave節點,可以有效的避免過大的存取量對單個庫造成的壓力。
1.2.1 讀寫分離的挑戰
1 對於DBA而言,多了很多叢集運維工作
例如叢集搭建、主從切換、從庫擴容、縮容等。例如master設定了多個slave節點,如果其中某個slave節點掛了,那麼之後的讀請求,我們應用將其轉發到正常工作的slave節點上。另外,如果新增了slave節點,應用也應該感知到,可以將讀請求轉發到新的slave節點上。
2 對於開發人員而言
-
基本讀寫分離功能:對sql型別進行判斷,如果是select等讀請求,就走從庫,如果是insert、update、delete等寫請求,就走主庫。
-
主從數據同步延遲問題:因爲數據是從master節點通過網路同步給多個slave節點,因此必然存在延遲。因此有可能出現我們在master節點中已經插入了數據,但是從slave節點卻讀取不到的問題。對於一些強一致性的業務場景,要求插入後必須能讀取到,因此對於這種情況,我們需要提供一種方式,讓讀請求也可以走主庫,而主庫上的數據必然是最新的。
-
事務問題:如果一個事務中同時包含了讀請求(如select)和寫請求(如insert),如果讀請求走從庫,寫請求走主庫,由於跨了多個庫,那麼本地事務已經無法控制,屬於分佈式事務的範疇。而分佈式事務非常複雜且效率較低。因此對於讀寫分離,目前主流的做法是,事務中的所有sql統一都走主庫,由於只涉及到一個庫,本地事務就可以搞定。
-
感知叢集資訊變更:如果存取的數據庫叢集資訊變更了,例如主從切換了,寫流量就要到新的主庫上;又例如增加了從庫數量,流量需要可以打到新的從庫上;又或者某個從庫延遲或者失敗率比較高,應該將這個從庫進行隔離,讀流量儘量打到正常的從庫上
1.3 分庫分表
經過垂直分割區後的 Master/Salve 模式完全可以承受住難以想象的高併發存取操作,但是否可以永遠 高枕無憂 了?答案是否定的,一旦業務表中的數據量大了,從維護和效能角度來看,無論是任何的 CRUD 操作,對於數據庫而言都是一件極其耗費資源的事情。即便設定了索引, 仍然無法掩蓋因爲數據量過大從而導致的數據庫效能下降的事實 ,因此這個時候 Mysql DBA 或許就該對數據庫進行 水平分割區 (sharding,即分庫分表 )。經過水平分割區設定後的業務表,必然能夠將原本一張表維護的海量數據分配給 N 個子表進行儲存和維護。
水平分表從具體實現上又可以分爲3種:只分表、只分庫、分庫分表,下圖展示了這三種情況:
![]()
只分表:
將db庫中的user表拆分爲2個分表,user_0和user_1,這兩個表還位於同一個庫中。適用場景:如果庫中的多個表中只有某張表或者少數表數據量過大,那麼只需要針對這些表進行拆分,其他表保持不變。
只分庫:
將db庫拆分爲db_0和db_1兩個庫,同時在db_0和db_1庫中各自新建一個user表,db_0.user表和db_1.user表中各自只存原來的db.user表中的部分數據。
分庫分表:
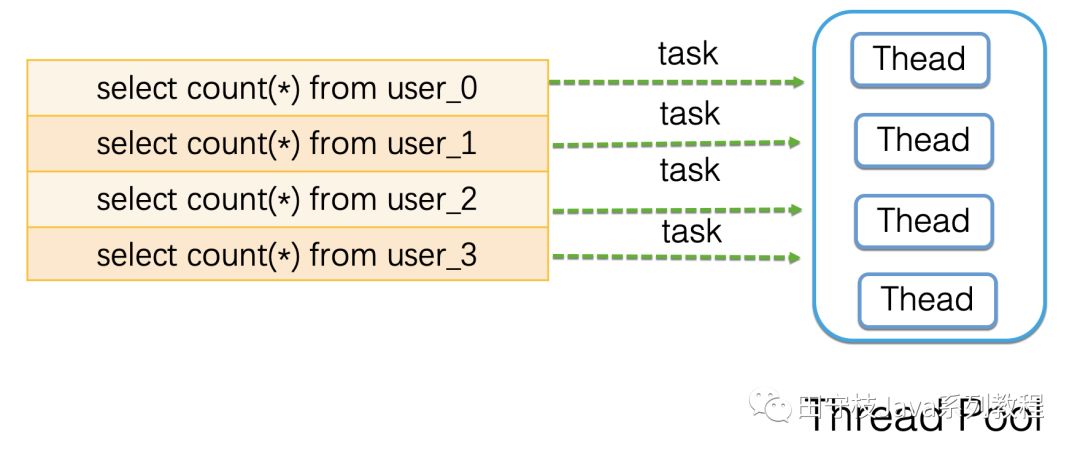
將db庫拆分爲db_0和db_1兩個庫,db_0中包含user_0、user_1兩個分表,db_1中包含user_2、user_3兩個分表。下圖演示了在分庫分表的情況下,數據是如何拆分的:假設db庫的user表中原來有4000W條數據,現在將db庫拆分爲2個分庫db_0和db_1,user表拆分爲user_0、user_1、user_2、user_3四個分表,每個分表儲存1000W條數據。
![]()
1.3.1 分庫分表的好處
如果說讀寫分離實現了數據庫讀能力的水平擴充套件,那麼分庫分表就是實現了寫能力的水平擴充套件。
1 儲存能力的水平擴充套件
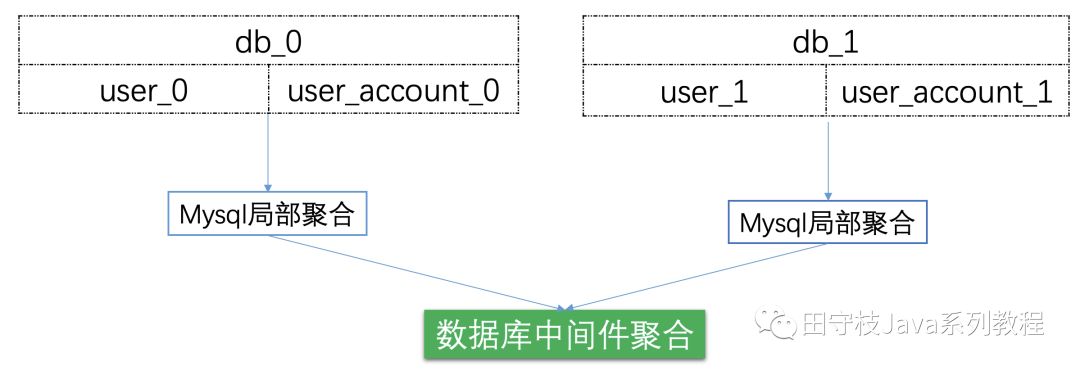
在讀寫分離的情況下,每個叢集中的master和slave基本上數據是完全一致的,從儲存能力來說,在存在海量數據的情況下,可能由於磁碟空間的限制,無法儲存所有的數據。而在分庫分表的情況下,我們可以搭建多個mysql主從複製叢集,每個叢集只儲存部分分片的數據,實現儲存能力的水平擴充套件。
2 寫能力的水平擴充套件
在讀寫分離的情況下,由於每個叢集只有一個master,所有的寫操作壓力都集中在這一個節點上,在寫入併發非常高的情況下,這裏會成爲整個系統的瓶頸。
而在分庫分表的情況下,每個分片所屬的叢集都有一個master節點,都可以執行寫入操作,實現寫能力的水平擴充套件。此外減小建立索引開銷,降低寫操作的鎖操作耗時等,都會帶來很多顯然的好處。
1.3.2 分庫分表的挑戰
分庫分表的挑戰主要體現在4個方面:基本的數據庫增刪改功能,分佈式id,分佈式事務,動態擴容,下面 下麪逐一進行講述。
挑戰1:基本的數據庫增刪改功能
對於開發人員而言,雖然分庫分表的,但是其還是希望能和單庫單表那樣的去操作數據庫。例如我們要批次插入四條使用者記錄,並且希望根據使用者的id欄位,確定這條記錄插入哪個庫的哪張表。例如1號記錄插入user1表,2號記錄插入user2表,3號記錄插入user3表,4號記錄插入user0表,以此類推。sql如下所示:
insert into user(id,name) values (1,」tianshouzhi」),(2,」huhuamin」), (3,」wanghanao」),(4,」luyang」)
這樣的sql明顯是無法執行的,因爲我們已經對庫和表進行了拆分,這種sql語法只能操作mysql的單個庫和單個表。所以必須將sql改成4條如下所示,然後分別到每個庫上去執行。
insert into user0(id,name) values (4,」luyang」)
insert into user1(id,name) values (1,」tianshouzhi」)
insert into user2(id,name) values (2,」huhuamin」)
insert into user3(id,name) values (3,」wanghanao」)
具體流程可以用下圖進行描述:
![]()
解釋如下:
sql解析:首先對sql進行解析,得到需要插入的四條記錄的id欄位的值分別爲1,2,3,4
sql路由:sql路由包括庫路由和表路由。庫路由用於確定這條記錄應該插入哪個庫,表路由用於確定這條記錄應該插入哪個表。
sql改寫:因爲一條記錄只能插入到一個庫中,而上述批次插入的語法將會在 每個庫中都插入四條記錄,明顯是不合適的,因此需要對sql進行改寫,每個庫只插入一條記錄。
sql執行:一條sql經過改寫後變成了多條sql,爲了提升效率應該併發的到不同的庫上去執行,而不是按照順序逐一執行
結果集合併:每個sql執行之後,都會有一個執行結果,我們需要對分庫分表的結果集進行合併,從而得到一個完整的結果。
挑戰2:分佈式id
在分庫分表後,我們不能再使用mysql的自增主鍵。因爲在插入記錄的時候,不同的庫生成的記錄的自增id可能會出現衝突。因此需要有一個全域性的id生成器。目前分佈式id有很多中方案,其中一個比較輕量級的方案是twitter的snowflake演算法。
挑戰3:分佈式事務
分佈式事務是分庫分表繞不過去的一個坎,因爲涉及到了同時更新多個分片數據。例如上面的批次插入記錄到四個不同的庫,如何保證要麼同時成功,要麼同時失敗。關於分佈式事務,mysql支援XA事務,但是效率較低。柔性事務是目前比較主流的方案,柔性事務包括:最大努力通知型、可靠訊息最終一致性方案以及TCC兩階段提交。但是無論XA事務還是柔性事務,實現起來都是非常複雜的。
挑戰4:動態擴容
動態擴容指的是增加分庫分表的數量。例如原來的user表拆分到2個庫的四張表上。現在我們希望將分庫的數量變爲4個,分表的數量變爲8個。這種情況下一般要伴隨着數據遷移。例如在4張表的情況下,id爲7的記錄,7%4=3,因此這條記錄位於user3這張表上。但是現在分表的數量變爲了8個,而7%8=0,而user0這張表上根本就沒有id=7的這條記錄,因此如果不進行數據遷移的話,就會出現記錄找不到的情況。本教學後面將會介紹一種在動態擴容時不需要進行數據遷移的方案。
1.4 小結
在上面我們已經看到了,讀寫分離和分庫分錶帶來的好處,但是也面臨了極大的挑戰。如果由業務開發人員來完成這些工作,難度比較大。因此就有一些公司專門來做一些數據庫中介軟體,對業務開發人員遮蔽底層的繁瑣細節,開發人員使用了這些中介軟體後,不論是讀寫分離還是分庫分表,都可以像操作單庫單表那樣去操作。
下面 下麪,我們將介紹 主流的數據庫中介軟體設計方案和實現。
2 主流數據庫中介軟體設計方案
數據庫中介軟體的主要作用是嚮應用程式開發人員遮蔽讀寫分離和分庫分表面臨的挑戰,並隱藏底層實現細節,使得開發人員可以像操作單庫單表那樣去操作數據。在介紹分庫分表的主流設計方案前,我們首先回顧一下在單個庫的情況下,應用的架構,可以用下圖進行描述:

可以看到在操作單庫單表的情況下,我們是直接在應用中通過數據連線池(connection pool)與數據庫建立連線,進行讀寫操作。 而對於讀寫分離和分庫分表,應用都要操作多個數據庫範例,在這種情況下,我們就需要使用到數據庫中介軟體。
2.1 設計方案
典型的數據庫中介軟體設計方案有2種:proxy、smart-client。下圖演示了這兩種方案的架構:
![]()
可以看到不論是proxy還是smart-client,底層都操作了多個數據庫範例。不論是分庫分表,還是讀寫分離,都是在數據庫中介軟體層面對業務開發同學進行遮蔽。
2.1.1 proxy模式
我們獨立部署一個代理服務,這個代理服務背後管理多個數據庫範例。而在應用中,我們通過一個普通的數據源(c3p0、druid、dbcp等)與代理伺服器建立連線,所有的sql操作語句都是發送給這個代理,由這個代理去操作底層數據庫,得到結果並返回給應用。在這種方案下,分庫分表和讀寫分離的邏輯對開發人員是完全透明的。
優點:
1 多語言支援。也就是說,不論你用的php、java或是其他語言,都可以支援。以mysql數據庫爲例,如果proxy本身實現了mysql的通訊協定,那麼你可以就將其看成一個mysql 伺服器。mysql官方團隊爲不同語言提供了不同的用戶端卻動,如java語言的mysql-connector-java,python語言的mysql-connector-python等等。因此不同語言的開發者都可以使用mysql官方提供的對應的驅動來與這個代理伺服器建通訊。
2 對業務開發同學透明。由於可以把proxy當成mysql伺服器,理論上業務同學不需要進行太多程式碼改造,既可以完成接入。
缺點:
1 實現複雜。因爲proxy需要實現被代理的數據庫server端的通訊協定,實現難度較大。通常我們看到一些proxy模式的數據庫中介軟體,實際上只能代理某一種數據庫,如mysql。幾乎沒有數據庫中介軟體,可以同時代理多種數據庫(sqlserver、PostgreSQL、Oracle)。
2 proxy本身需要保證高可用。由於應用本來是直接存取數據庫,現在改成了存取proxy,意味着proxy必須保證高可用。否則,數據庫沒有宕機,proxy掛了,導致數據庫無法正常存取,就尷尬了。
3 租戶隔離。可能有多個應用存取proxy代理的底層數據庫,必然會對proxy自身的記憶體、網路、cpu等產生資源競爭,proxy需要需要具備隔離的能力。
2.1.2 smart-client模式
業務程式碼需要進行一些改造,引入支援讀寫分離或者分庫分表的功能的sdk,這個就是我們的smart-client。通常smart-client是在連線池或者driver的基礎上進行了一層封裝,smart-client內部與不同的庫建立連線。應用程式產生的sql交給smart-client進行處理,其內部對sql進行必要的操作,例如在讀寫分離情況下,選擇走從庫還是主庫;在分庫分表的情況下,進行sql解析、sql改寫等操作,然後路由到不同的分庫,將得到的結果進行合併,返回給應用。
優點:
1 實現簡單。proxy需要實現數據庫的伺服器端協定,但是smart-client不需要實現用戶端通訊協定。原因在於,大多數據數據庫廠商已經針對不同的語言提供了相應的數據庫驅動driver,例如mysql針對java語言提供了mysql-connector-java驅動,針對python提供了mysql-connector-python驅動,用戶端的通訊協定已經在driver層面做過了。因此smart-client模式的中介軟體,通常只需要在此基礎上進行封裝即可。
2 天然去中心化。smart-client的方式,由於本身以sdk的方式,被應用直接引入,隨着應用部署到不同的節點上,且直連數據庫,中間不需要有代理層。因此相較於proxy而言,除了網路資源之外,基本上不存在任何其他資源的競爭,也不需要考慮高可用的問題。只要應用的節點沒有全部宕機,就可以存取數據庫。(這裏的高可用是相比proxy而言,數據庫本身的高可用還是需要保證的)
缺點:
1 通常僅支援某一種語言。例如tddl、zebra、sharding-jdbc都是使用java語言開發,因此對於使用其他語言的使用者,就無法使用這些中介軟體。如果其他語言要使用,那麼就要開發多語言用戶端。
2 版本升級困難。因爲應用使用數據源代理就是引入一個jar包的依賴,在有多個應用都對某個版本的jar包產生依賴時,一旦這個版本有bug,所有的應用都需要升級。而數據庫代理升級則相對容易,因爲服務是單獨部署的,只要升級這個代理伺服器,所有連線到這個代理的應用自然也就相當於都升級了。
2.2 業界產品
無論是proxy,還是smart-client,二者的作用都是類似的。以下列出了這兩種方案目前已有的實現以及各自的優缺點:
![]()
proxy實現
目前的已有的實現方案有:
-
阿裡巴巴開源的cobar
-
阿裡雲上的drds
-
mycat團隊在cobar基礎上開發的mycat
-
mysql官方提供的mysql-proxy
-
奇虎360在mysql-proxy基礎開發的atlas(只支援分表,不支援分庫)
-
噹噹網開源的sharing-sphere
目前除了mycat、sharing-sphere,其他幾個開源專案基本已經沒有維護,sharing-sphere前一段時間已經進去了Apache 軟體基金會孵化器。
smart-client實現
目前的實現方案有:
-
阿裡巴巴開源的tddl,已很久沒維護
-
大衆點評開源的zebra,大衆點評的zebra開源版本程式碼已經很久沒有更新,不過最近美團上市,重新開源大量內部新的功能特性,並計劃長期維持。
-
噹噹網開源的sharding-jdbc,目前算是做的比較好的,文件資料比較全。和sharding-sphere一起進入了Apache孵化器。
-
螞蟻金服的zal
-
等等
3 讀寫分離核心要點
3.1 基本路由功能
基本路由路功能主要是解決,在讀寫分離的情況下,如何實現一些基本的路由功能,這個過程通常可以通過下圖進行描述:
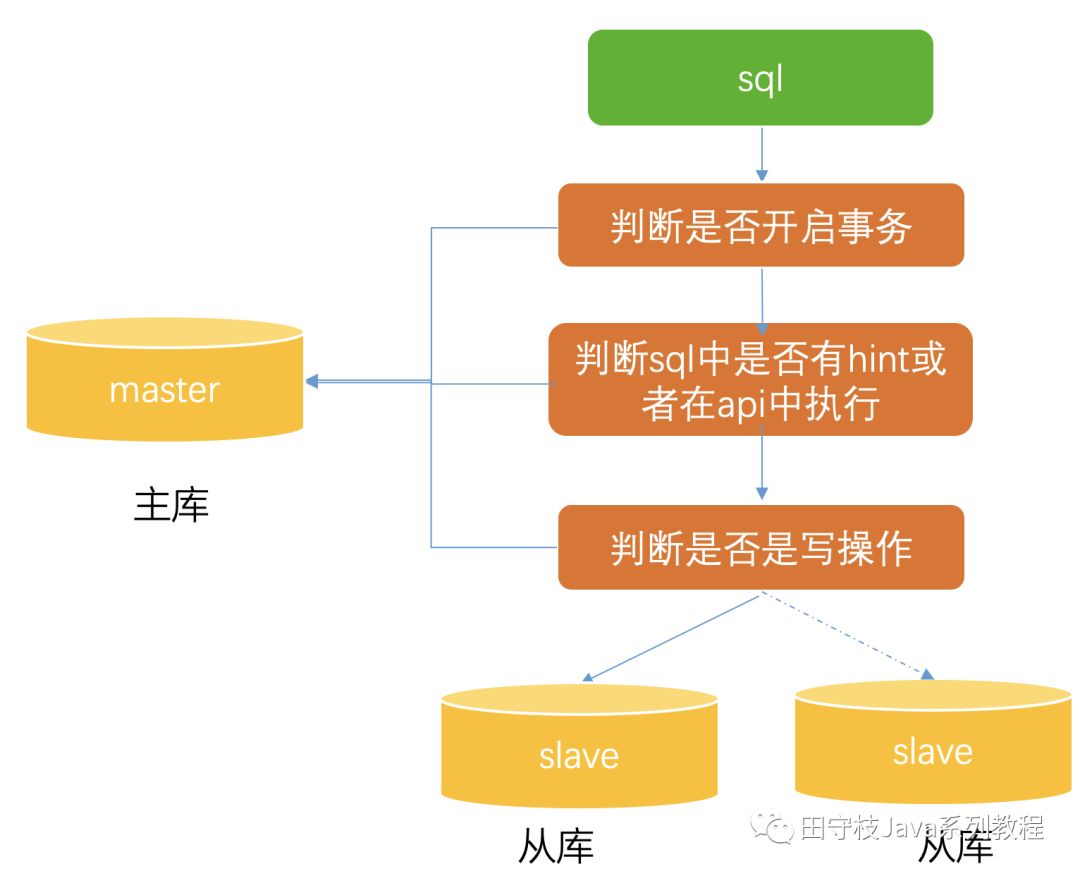
3.1.1 sql型別判斷
主要是判斷出來sql是讀還是寫sql,將讀sql到從庫上去執行,寫sql去主庫上執行
write語句:insert、update、delete、create、alter、truncate…
query語句:select、show、desc、explain…
3.1.2 強制走主庫
有的時候,對於一些強一致性的場景,需要寫入後,必須能讀取到數據。由於主從同步存在延遲,可能會出現主庫寫入,而從庫查不到的情況。這次時候,我們需要使用強制走主庫的功能。具體實現上有2種方案:hint 或API
hint,就是開發人員在sql上做一些特殊的標記,數據庫中介軟體識別到這個標記,就知道這個sql需要走主庫,如:
/*master*/select * from table_xx
這裏的/*master*/就是一個hint,表示需要走主庫。不同的數據庫中介軟體強制走主庫的hint可能不同,例如zebra的hint爲/*zebra:w+*/,hint到底是什麼樣是無所謂的,其作用僅僅就是一個標記而已。之所以將hint寫在/*…*/中,是因爲這是標準的sql註釋語法。即使數據庫中介軟體未能識別這個hint,也不會導致sql語法錯誤。
api:主要是通過程式碼的方式來新增sql走主庫的標識,hint通常只能加在某個sql上。如果我們希望多個sql同時都走主庫,也不希望加hint,則可以通過api的方式,其內部主要利用語言的thread local執行緒上下文特性,如:
ForceMasterHelper.forceMaster()//…執行多條sqlForceMasterHelper.clear()
在api標識範圍內執行的sql,都會走主庫。具體API到底應該是什麼樣,如何使用,也是由相應的數據庫中介軟體來決定的。
特別的,對於一些特殊的sql,例如 select last_insert_id;或者select @@identity等,這類sql總是需要走主庫。 這些sql是要獲得最後一個插入記錄的id,插入操作只可能發生在主庫上。
3.2 從庫路由策略
通常在一個叢集中,只會有一個master,但是有多個slave。當判斷是一個讀請求時,如何判斷選擇哪個slave呢?
一些簡單的選擇策略包括:
-
隨機選擇(random)
-
按照權重進行選擇(weight)
-
或者輪訓(round-robin)
-
等
特別的,對於一些跨IDC(數據中心)部署的數據庫叢集,通常需要有就近路由的策略,如下圖:
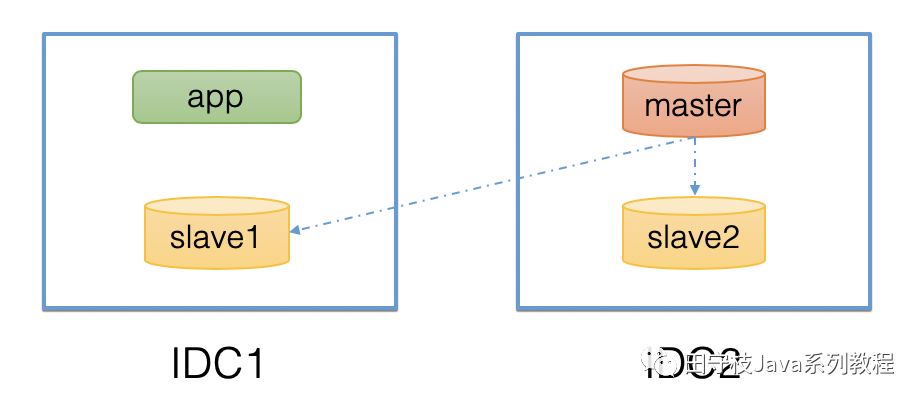
圖中,在IDC2部署了一個master,在IDC1和IDC2各部署了一個slave,應用app部署在IDC1。顯然當app接收到一個查詢請求時,應該優先查詢與其位於同一個數據中心的slave1,而不是跨數據中心去查詢slave2,這就是就近路由的概念。
當然一個數據中心內,可能會部署多個slave,也需要進行選擇,因此就近路由通常和一些基本的路由策略結合使用。另外,對於就近路由,通常也會有一個層級,例如同機房、同中心、同區域、跨區域等。
3.3 HA、Scalable相關
數據庫中介軟體除了需要具備上述提到的讀寫分離功能來存取底層的數據庫叢集。也需要一套支援高可用、動態擴充套件的體系:
-
從HA的角度來說,例如主庫宕機了,那麼應該從從庫選擇一個作爲新的主庫。開源的MHA可以幫助我們完成這個事;然而,MHA只能在主庫宕機的情況下,完成主從切換,對於僅僅是一個從庫宕機的情況下,MHA通常是無能爲力的。因此,通常都會在MHA進行改造,使其支援更多的HA能力要求。
-
從Scalable角度來說,例如讀qps實在太高,需要加一些從庫,來分擔讀流量。
事實上,無論是HA,還是Scalable,對於數據庫中介軟體(不論是proxy或者smart-client)來說,只是設定資訊發生了變更。
因此,通常我們會將所有的設定變更資訊寫到一個設定中心,然後設定心中監聽這個設定的變更,例如主從切換,只需要把最新的主從資訊設定到設定中心;增加從庫,把新從庫ip、port等資訊放到設定中心。數據庫中介軟體通過對這些設定資訊變更進行監聽,當設定發生變更時,實時的應用最新的設定資訊即可。
因此,一個簡化的數據庫中介軟體的高可用架構通常如下所示:
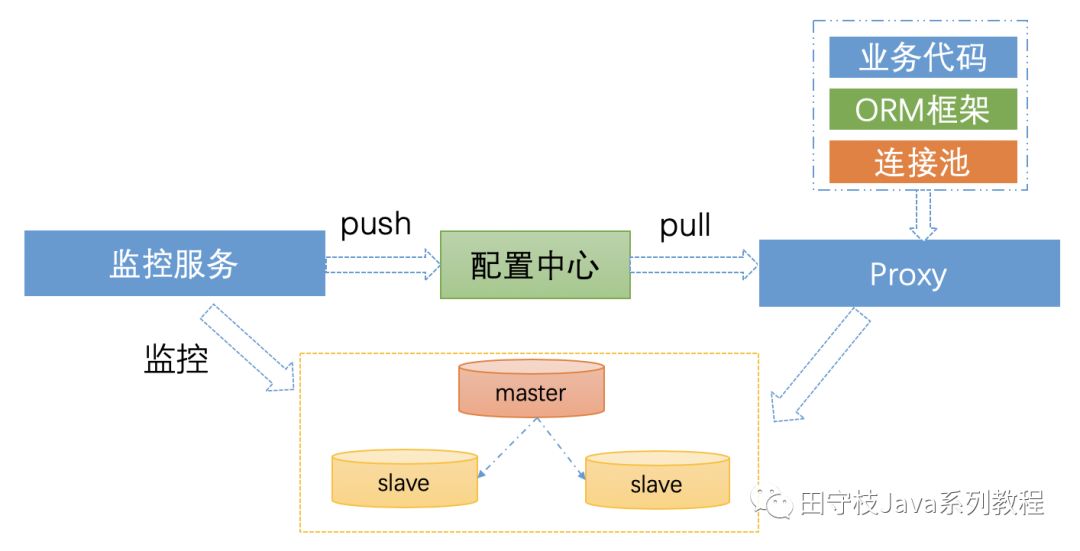
監控服務對叢集進行監控,當發生變更時,將變更的資訊push到設定中心中,數據庫中介軟體(proxy或smart-client)接收到設定變更,應用最新的設定。而整個過程,對於業務程式碼基本是無感知的。
對於設定中心的選擇,有很多,例如百度的disconf、阿裡的diamond、點評開源的lion、攜程開源的apollo等,也可以使用etcd、consul。通常如果沒有歷史包袱的話,建議使用攜程開源的apollo。
特別需要注意的一點是,通常監控服務監控到叢集資訊變更,推播到設定中心,再到數據庫中介軟體,必然存在一些延遲。對於一些場景,例如主從切換,沒有辦法做到徹底的業務無感知。當然,對於多個從庫中,某個從庫宕機的情況下,是可以做到業務無感知的。例如,某個從庫失敗,數據庫中介軟體,自動從其他正常的從庫進行重試。
另外,上圖中的HA方案強依賴於設定中心,如果某個數據庫叢集上建立了很多庫,這個叢集發生變更時,將會存在大量的設定資訊需要推播。又或者,如果數據庫叢集是多機房部署的,在某個機房整體宕機的情況下(例如光纖被挖斷了,或者機房宕機演練),也會存在大量的設定資訊需要推播。如果設定中心,推播有延遲,業務會有非常明顯的感知。
因此,通常我們會在用戶端進行一些輕量級的HA保障。例如,根據數據庫返回異常的sqlstate和vendor code,判斷異常的嚴重級別,確定數據庫範例能否正常提供服務,如果不能正常提供服務,則自動將其進行隔離,並啓動非同步執行緒進行檢測數據庫範例是否恢復。
最後,很多數據庫中介軟體,也會提供一些限流和降級的功能,計算sql的唯一標識(有些稱之爲sql指紋),對於一些爛sql,導致數據庫壓力變大的情況,可以實時的進行攔截,直接拋出異常,不讓這些sql打到後端數據庫上去。
4 分庫分表核心要點
從業務開發的角度來說,其不關心底層是否是分庫分表了,其還是希望想操作單個數據庫範例那樣編寫sql,那麼數據庫中介軟體就需要對其遮蔽所有底層的複雜邏輯。
下圖演示了一個數據庫表(user表)在分庫分表情況下,數據庫中介軟體內部是如何執行一個批次插入sql的:
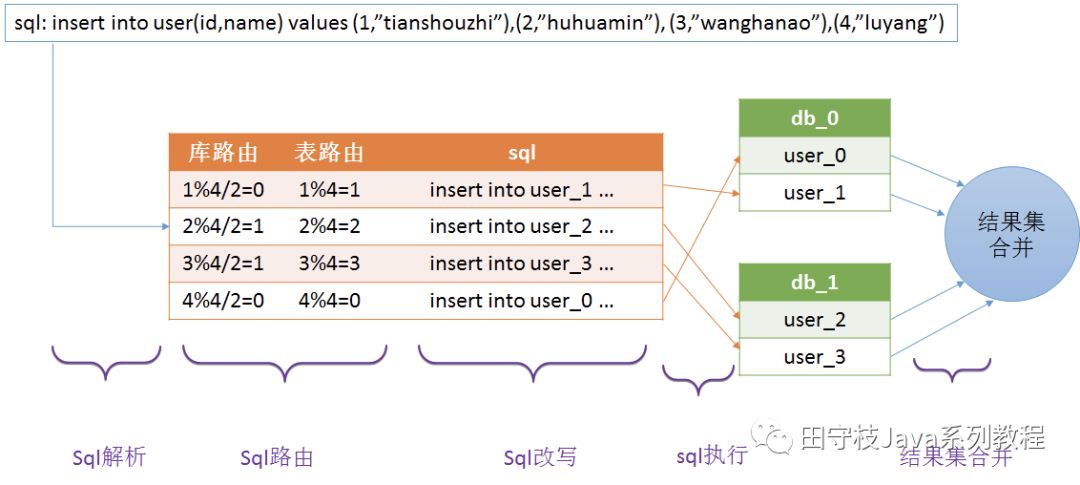
數據庫中介軟體主要對應用遮蔽了以下過程:
-
sql解析:首先對sql進行解析,得到抽象語法樹,從語法樹中得到一些關鍵sql資訊
-
sql路由:sql路由包括庫路由和表路由。庫路由用於確定這條記錄應該操作哪個分庫,表路由用於確定這條記錄應該操作哪個分表。
-
sql改寫:將sql改寫成正確的執行方式。例如,對於一個批次插入sql,同時插入4條記錄。但實際上使用者希望4個記錄分表儲存到一個分表中,那麼就要對sql進行改寫成4條sql,每個sql都只能插入1條記錄。
-
sql執行:一條sql經過改寫後可能變成了多條sql,爲了提升效率應該併發的去執行,而不是按照順序逐一執行
-
結果集合併:每個sql執行之後,都會有一個執行結果,我們需要對分庫分表的結果集進行合併,從而得到一個完整的結果。
4.1 SQL解析
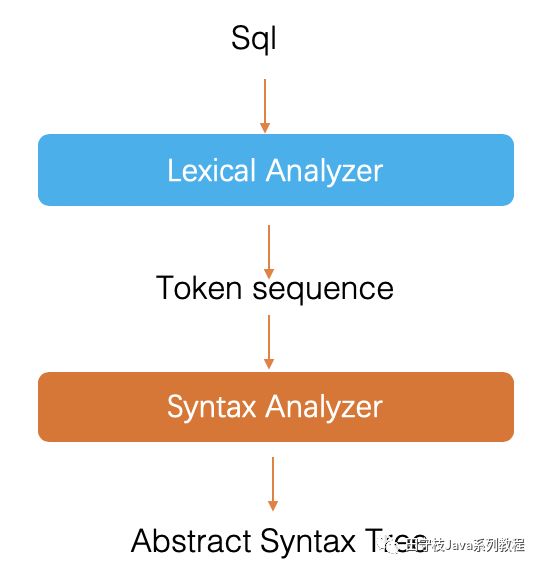
使用者執行只是一條sql,並傳入相關參數。數據庫中介軟體內部需要通過sql解析器,對sql進行解析。可以將sql解析,類比爲xml解析,xml解析的最終結果是得到一個document物件,而sql解析最終得到一個抽象語法樹(AST)。通過這個語法樹,我們可以很簡單的獲取到sql的一些執行,例如當前執行的sql型別,查詢了那些欄位,數據庫表名,where條件,sql的參數等一系列資訊。
通常來說,對於sql解析,內部需要經過詞法(lex)解析和語法(Syntax)解析兩個階段,最終得到一個語法樹。
SQL解析器的內部實現原理對業務同學是遮蔽的,業務同學也感知不到。一些數據庫中介軟體採用了第三方開源的sql解析器,也有一些自研sql解析器。例如mycat、zebra採用的都是druid解析器,shard-jdbc一開始也用的是druid解析器,後面自研瞭解析器。目前較爲流行的sql解析器包括:
-
FoundationDB SQL Parser
-
Jsqlparser
-
Druid SQL Parser
其中,其中Fdbparser和jsqlparser都是基於javacc實現的。
mycat團隊曾經做過一個效能測試,druid解析器的解析效能通常能達到基於javacc生成的sql解析器10~20倍。本人也進行過類似的測試,得出的結論基本一致。
如何對比不同的sql解析器的好壞呢?主要是考慮以下兩點:
解析效能:druid最好。
druid採用的是預測分析法,它只需要從字元的第一個到最後一個遍歷一遍,就同時完成了詞法解析和語法解析,語法樹也已經構造完成。
數據庫方言:druid支援的最多。
SQL-92、SQL-99等都是標準SQL,mysql/oracle/pg/sqlserver/odps等都是方言,sql-parser需要針對不同的方言進行特別處理。Druid的sql parser是目前支援各種數據語法最完備的SQL Parser。
注:這裏說的僅僅是基於Java實現的SQL解析器,druid是比較好的。大部分同學可能知道druid是一個爲監控而生的連線池,事實上,druid另一大特性,就是它的SQL解析器。很多開源的數據庫中介軟體,例如zebra、sharding-jdbc等,都使用了druid解析器。(sharding-jdbc後來自研瞭解析器)。雖然SQL解析是druid的一大亮點,不過github上也因爲SQL解析的bug,收到了不少issue。
4.2 SQL路由
路由規則是分庫分表的基礎,其規定了數據應該按照怎樣的規則路由到不同的分庫分表中。對於一個數據庫中介軟體來說,通常是支援使用者自定義任何路由規則的。路由規則本質上是一個指令碼表達式,數據庫中介軟體通過內建的指令碼引擎對錶達式進行計算,確定最終要操作哪些分庫、分表。常見的路由規則包括雜湊取模,按照日期等。
下圖展示了user表進行分庫分表後(2個分庫,每個分庫2個分表),並如何根據id進行路由的規則:
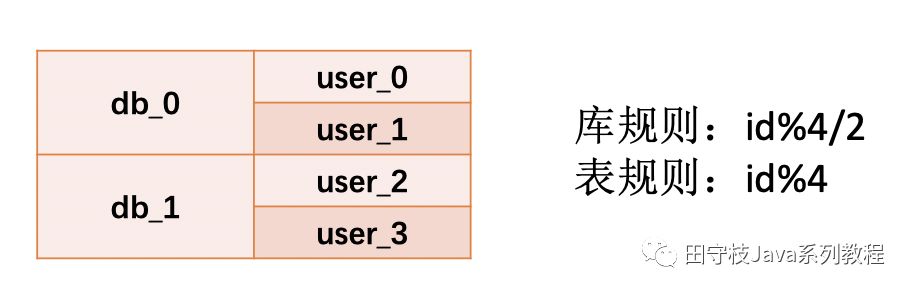
路由分則分爲:
-
庫規則:用於確定到哪一個分庫
-
表規則:用於確定到哪一個分表
在上例中,我們使用id來作爲計算分表、分表,因此把id欄位就稱之爲路由欄位,或者分割區欄位。
需要注意的是,不管執行的是INSERT、UPDATE、DELETE、SELECT語句,SQL中都應該包含這個路由欄位。否則,對於插入語句來說,就不知道插入到哪個分庫或者分表;對於UPDATE、DELETE、SELECT語句而言,則更爲嚴重,因爲不知道操作哪個分庫分表,意味着必須要對所有分表都進行操作。SELECT聚合所有分表的內容,極容易記憶體溢位,UPDATE、DELETE更新、刪除所有的記錄,非常容易誤更新、刪除數據。因此,一些數據庫中介軟體,對於SQL可能有一些限制,例如UPDATE、DELETE必須要帶上分割區欄位,或者指定過濾條件。
4.3 SQL改寫
前面已經介紹過,如一個批次插入語句,如果記錄要插入到不同的分庫分表中,那麼就需要對SQL進行改寫。 例如,將以下SQL
insert into user(id,name) values (1,」tianshouzhi」),(2,」huhuamin」), (3,」wanghanao」),(4,」luyang」)
改寫爲:
insert into user_1(id,name) values (1,」tianshouzhi」)insert into user_2(id,name) values (2,」huhuamin」)insert into user_3(id,name) values (3,」wanghanao」)insert into user_0(id,name) values (4,」luyang」)
這裏只是一個簡單的案例,通常對於INSERT、UPDATE、DELETE等,改寫相對簡單。比較複雜的是SELECT語句的改寫,對於一些複雜的SELECT語句,改寫過程中會進行一些優化,例如將子查詢改成JOIN,過濾條件下推等。因爲SQL改寫很複雜,所以很多數據庫中介軟體並不支援複雜的SQL(通常有一個支援的SQL),只能支援一些簡單的OLTP場景。
當然也有一些數據庫中介軟體,不滿足於只支援OLTP,在邁向OLAP的方向上進行了更多的努力。例如阿裡的TDDL、螞蟻的Zdal、大衆點評的zebra,都引入了apache calcite,嘗試對複雜的查詢SQL(例如巢狀子查詢,join等)進行支援,通過過濾條件下推,流式讀取,並結合RBO(基於規則的優化)、CBO(基於代價的優化)來對一些簡單的OLAP場景進行支援。
4.4 SQL執行
當經過SQL改寫階段後,會產生多個SQL,需要到不同的分片上去執行,通常我們會使用一個執行緒池,將每個SQL包裝成一個任務,提交到執行緒池裏面併發的去執行,以提升效率。
這些執行的SQL中,如果有一個失敗,則整體失敗,返回異常給業務程式碼。
4.5 結果集合併
結果集合併,是數據庫中介軟體的一大難點,需要case by case的分析,主要是考慮實現的複雜度,以及執行的效率問題,對於一些複雜的SQL,可能並不支援。例如:
對於查詢條件:大部分中介軟體都支援=、IN作爲查詢條件,且可以作爲分割區欄位。但是對於NIT IN、BETWEEN…AND、LIKE,NOT LIKE等,只能作爲普通的查詢條件,因爲根據這些條件,無法記錄到底是在哪個分庫或者分表,只能全表掃描。
聚合函數:大部分中介軟體都支援MAX、MIN、COUNT、SUM,但是對於AVG可能只是部分支援。另外,如果是函數巢狀、分組(GROUP BY)聚合,可能也有一些數據庫中介軟體不支援。
子查詢:分爲FROM部分的子查詢和WHERE部分的子查詢。大部分中對於子查詢的支援都是非常有限,例如語法上相容,但是無法識別子查詢中的分割區欄位,或者要求子查詢的表名必須與外部查詢表名相同,又或者只能支援一級巢狀子查詢。
JOIN:對於JOIN的支援通常很複雜,如果做不到過濾條件下推和流式讀取,在中介軟體層面,基本無法對JOIN進行支援,因爲不可能把兩個表的所有分表,全部拿到記憶體中來進行JOIN,記憶體早就崩了。當然也有一些取巧的辦法,一個是Binding Table,另外一個是小表廣播(見後文)。
分頁排序:通常中介軟體都是支援ORDER BY和LIMIT的。但是在分庫分表的情況下,分頁的效率較低。例如對於limit 100,10 ORDER BY id。表示按照id排序,從第100個位置開始取10條記錄。那麼,大部分數據庫中介軟體實際上是要從每個分表都查詢110(100+10)條記錄,拿到記憶體中進行重新排序,然後取出10條。假設有10個分表,那麼實際上要查詢1100條記錄,而最終只過濾出了10記錄。因此,在分頁的情況下,通常建議使用"where id > ? limit 10」的方式來進行查詢,應用記住每次查詢的最大的記錄id。之後查詢時,每個分表只需要從這個id之後,取10條記錄即可,而不是取offset + rows條記錄。
關於JOIN的特屬說明:
Binding Table:
適用於兩個表之間存在關聯關係,路由規則相同。例如,有user表和user_account表,由於user_account與user表強關聯,我們可以將這兩個表的路由規則設定爲完全一樣,那麼對於某個特定使用者的資訊,其所在的user分表和user_account分表必然唯一同一個分庫下,後綴名相同的分表中。在join時,某一個分庫內的join,就可以拿到這個使用者以及賬號的完整資訊,而不需要進行跨庫join,這樣就不需要把使用者的數據庫拿到記憶體中來進行join。
小表廣播:
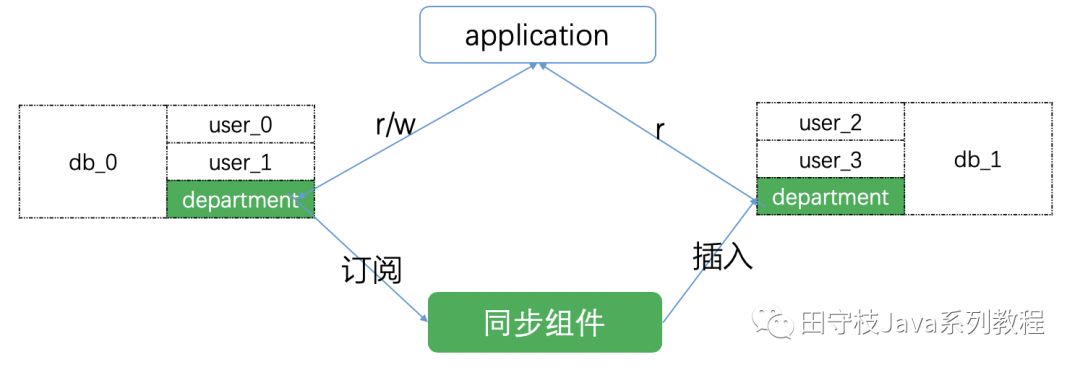
小表廣播通常是某一個表的數據量比較少, 例如部門表department。另外一個表數據量比較大,例如user。此時user需要進行分庫分表,但是department不需要進行分庫分表。爲了達到JOIN的目的,我們可以將 department表在每個分庫內都實時同步一份完整的數據。這樣,在JOIN的時候,數據庫中介軟體只需要將分庫JOIN的結果進行簡單合併即可。
下圖演示了小表廣播的流程,使用者在更新department表時,總是更新分庫db0的department表,同步元件將變更資訊同步到其他分庫中。
注:圖中的同步元件指的是一般是僞裝成數據庫的從庫,解析源庫binlog,插入目標庫。有一些開源的元件,如canal、puma可以實現這個功能,當然這些元件的應用場景非常廣泛,不僅限於此。筆者曾寫過一個系列的canal原始碼解析文章,目前完成了大部分。
4.6 二級索引
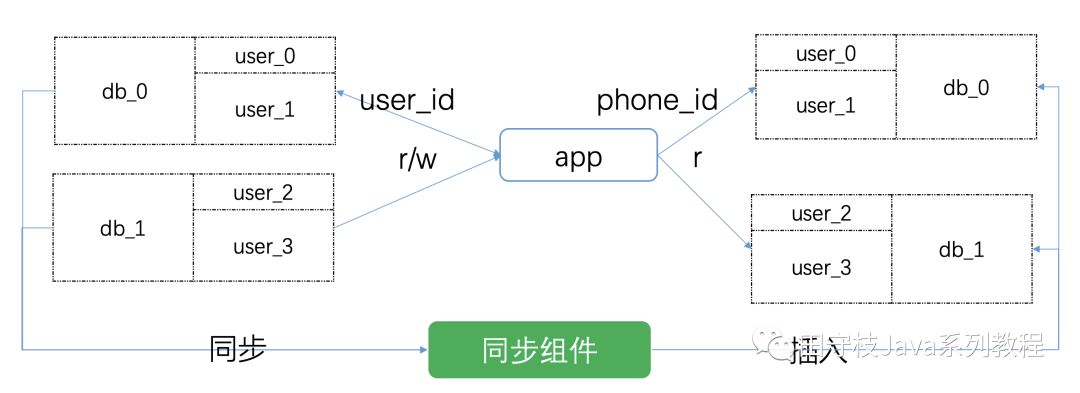
通常情況下,分庫分表的時候,分割區欄位只有一個。例如對於使用者表user,按照user_id欄位進行分割區,那麼之後查詢某個使用者的資訊,只能根據user_id作爲分割區欄位。使用其他欄位,則需要掃描所有分表,效率很低。但是又有根據其他欄位查詢某個使用者資訊的需求,例如根據手機號phone_id。
此時,我們可以將按照user_id插入的數據,進行一份全量拷貝。通過同步元件,重新按照phone_id插入到另一個分庫分表叢集中,這個叢集就成爲二級索引,或者叫輔維度同步。此後,對於根據user_id的操作,就在原來的分庫分表叢集中進行操作;根據phone_id的操作,就到二級索引叢集中去進行操作。
需要注意的是,對於更新操作,只能操作原叢集,二級索引叢集只能執行查詢操作。原叢集的增量數據變更資訊,實時的通過同步元件,同步到二級索引叢集中。
注:這是一個很常見的面試題。阿裡的一些面試官,比較喜歡問。一些面試者,可能自己想到了這個方案,因爲考慮到這樣比較浪費資源,就自行排除了。事實上,這點資源相對於滿足業務需求來說,都不是事。
4.7 分佈式id生成器
在分庫分表的情況下,數據庫的自增主鍵已經無法使用。所以要使用一個分佈式的id生成器。分佈式事務id生成器要滿足以下條件:唯一、趨勢遞增(減少落庫時的索引開銷)、高效能、高可用。
目前主流的分佈式id生成方案都有第三方元件依賴,如:
-
基於zk
-
基於mysql
-
基於快取
twitter的snowflake演算法是一個完全去中心化的分佈式id演算法,但是限制workid最多能有1024,也就是說,應用規模不能超過1024。雖然可以進行細微的調整,但是總是有數量的限制。
另外,美團之前在github開源了一個leaf元件,是用於生成分佈式id的,感興趣的讀者可以研究一下。
這裏提出一種支援動態擴容的去中心化分佈式id生成方案,此方案的優勢,除了保證唯一、趨勢遞增,沒有第三方依賴,支援儲存的動態擴容之外,還具有以下優勢:
-
支援按照時間範圍查詢,或者 時間範圍+ip查詢,可以直接走主鍵索引;
-
每秒的最大序列id就是某個ip的qps等
12位元日期+10位IP+6位序列ID+4位元數據庫擴充套件位
其中:
12位元日期:格式爲yyMMddHHmmss,意味着本方案的id生成策略可以使用到2099年,把時間部分前置,從而保證趨勢遞增。
10位ip:利用ip to decimal演算法將12位元的ip轉爲10進位制數位。通過ip地址,來保證全域性唯一。如果ip地址被回收重複利用了,也不用擔心id的唯一性,因爲日期部分還在變化。
6位序列id:意味着每秒最多支援生成100百萬個id(0~999999)。不足6位前置補0,如000123。
4位元數據庫擴充套件位:爲了實現不遷移數據的情況下,實現動態擴容,其中2位表示DB,2位表示TB,最多可擴容到10000張表。假設每張表儲存1000萬數據,則總共可以支援儲存1000億條數據。
關於數據庫擴充套件位實現動態擴容圖解:
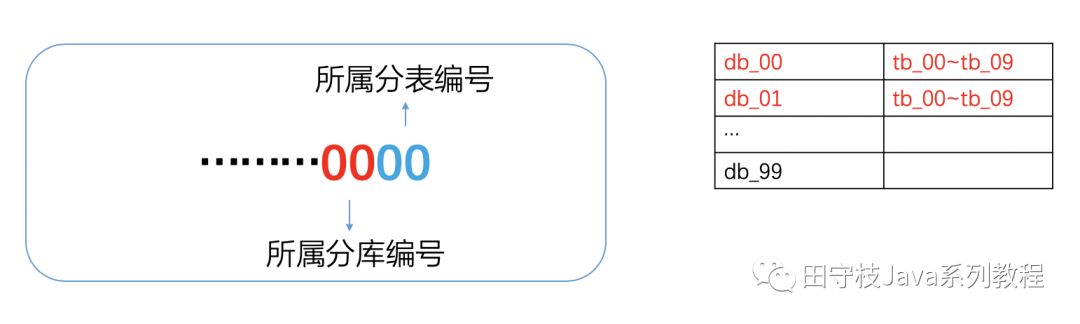
首先明確一點,路由策略始終根據數據庫最後四位,確定某一條記錄要到哪個分庫的哪個分表中。例如xxxx0001,意味着這條記錄肯定是在00分庫的01分表上。
接着,就要在id的生成策略上做文章。
假設初始狀態爲兩個分庫db_00,db_01,每個分庫裏面有10張分表,tb_00~tb_09。此時,業務要保證生成id的時候,始終保證db的兩位在00~01之間,tb的兩位始終在00~09之間。路由策略根據這些id,可以找到正確的分庫分表。
現在需要擴容到10個分庫,每個分表10個分表。那麼DBA首先將新增的分庫:db_02~db_09建立好,每個分庫裏面再建立10個分表:tb_01~tb_09。業務同學在此基礎上,將id生成策略改成:db的兩位在00~09之間,tb的兩位規則維持不變(只是分庫數變了,每個分庫的分表數沒變)。而由於路由從策略是根據最後四位確定到哪個分庫,哪個分表,當這些新的分庫分表擴充套件位id出現時,自然可以插入到新的分庫分表中。也就實現了動態擴容,而無需遷移數據。
當然,新的分庫分表中,一開始數據是沒有數據的,所以數據是不均勻的,可以調整id擴充套件位中db和tb生成某個值的概率,使得落到新的分庫分表中的概率相對大一點點(不宜太大),等到數據均勻後,再重新調整成完全隨機。
此方案的核心思想是,預分配未來的可能使用到的最大資源數量。通常,100個分庫,每個分庫100張分表,能滿足絕大部分應用的數據儲存。如果100個分庫都在不同的mysql範例上,假設每個mysql範例都是4T的磁碟,那麼可以儲存400T的數據,基本上可以滿足絕大部分業務的需求。
當然,這個方案不完美。如果超過這個值,這種方案可能就不可行了。然而,通常一個技術方案,可以保證在5~10年之間不需要在架構上做變動,應該就算的上一個好方案了。如果你追求的是完美的方案,可能類似於TIDB這種可以實現自動擴容的數據庫產品更適合,不過目前來說,TIDB等類似產品還是無法取代傳統的關係型數據庫的。說不定等到5~10年後,這些產品更成熟了,你再遷移過去也不遲。
4.7 分佈式事務
在分庫分表的情況下,由於操作多個分庫,此時就涉及到分佈式事務。例如執行一個批次插入SQL,如果記錄要插入到不同的分庫中,就無法保證一致性。因此,通常情況下,數據庫中介軟體,只會保證單個分庫的事務,也就是說,業務方在建立一個事務的時候,必須要保證事務中的所有操作,必須最終都在一個分庫中執行。
事實上,在微服務的架構下,事務的問題更加複雜,如下圖
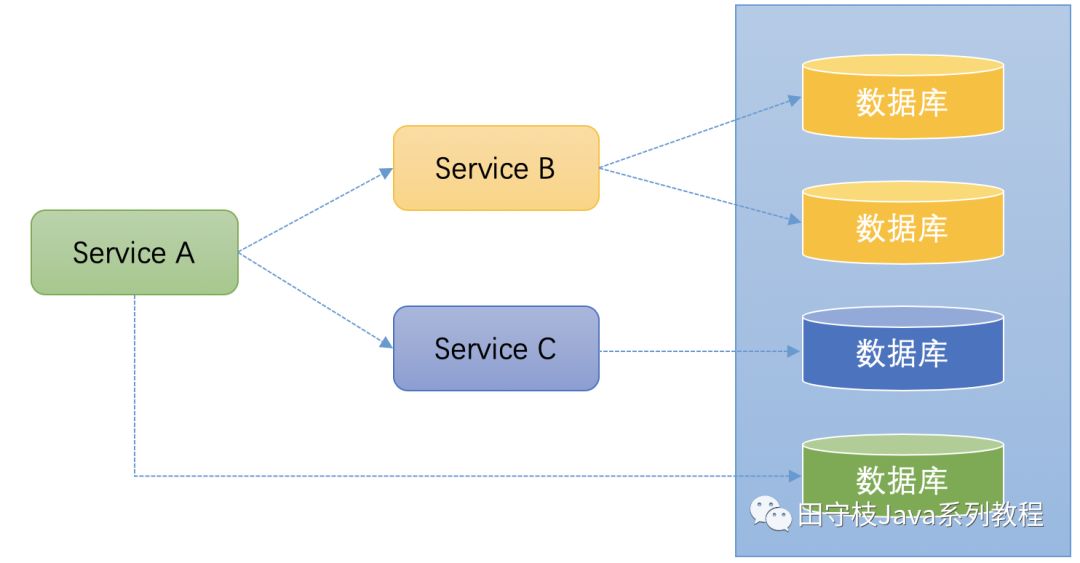
Service A在執行某個操作時,需要操作數據庫,同時呼叫Service B和Service C,Service B底層操作的數據庫是分庫分表的,Service C也要操作數據庫。
這種場景下,保證事務的一致性就非常麻煩。一些常用的一致性演算法如:paxios協定、raft協定也無法解決這個問題,因爲這些協定都是資源層面的一致性。在微服務架構下,已經將事務的一致性上升到了業務的層面。
如果僅僅考慮分庫分表,一些同學可能會想到XA,但是效能很差,對數據庫的版本也有要求,例如必須使用mysql 5.7,官方還建議將事務隔離級別設定爲序列化,這是無法容忍的。
由於分佈式事務的應用場景,並不是僅僅分庫分表,因此通常都是會有一個專門的團隊來做分佈式事務,並不一定是數據庫中介軟體團隊來做。例如,sharding-jdbc就使用了華爲開源的一套微服務架構解決方案service comb中的saga元件,來實現分佈式事務最終一致性。阿裡也有類似的元件,在內部叫TXC,在阿裡雲上叫GTS,最近開源到了GitHub上叫fescar(Fast & Easy Commit And Rollback)。螞蟻金服也有類似的元件,叫DTX,支援FMT模式和TCC模式。其中FMT模式就類似於TXC。