nlp-語言表示模型
語言表示模型
四種語言表示模型
語言表示模型有很多種方式,常見的語言表示方式可以粗略的分成非神經網路的方式、基於神經網路的方式。
也可以分爲一下四種方式:
1.基於one-hot、tf-idf、textrank等的bag-of-words;
2.主題模型:LSA(SVD)、pLSA、LDA;
3.基於詞向量的固定表徵:word2vec、fastText、glove;
4.基於詞向量的動態表徵:elmo、GPT、bert、XLnet、RoBERTa、T5、ERNIE-Baidu、ELECTRA;
BOW
Bag of Words(BOW),就是將文字/Query看作是一系列詞的集合。由於詞很多,所以咱們就用袋子把它們裝起來,簡稱詞袋。根據詞語在文字中的統計資訊建立文字表示模型,最常見的有one-hot表示、詞頻表示、tfidf表示。
One-Hot
方法步驟:根據文字庫建立詞典,再對單個文字中進行表示,如果詞語出現在文字中則標註爲1否則該位置標註爲0

Count
Count統計詞頻方法

texts=["John likes to watch movies. Mary likes too.","John also likes to watch football games."]
from sklearn.feature_extraction.text import CountVectorizer
# bow_vectorizer = CountVectorizer(max_df=0.9, min_df=1, max_features=10, stop_words='english')# bag-of-words feature matrix
bow_vectorizer = CountVectorizer(max_features=4000)
bow = bow_vectorizer.fit_transform(texts)
print(bow_vectorizer.get_feature_names())
print(bow.toarray())
TFIDF
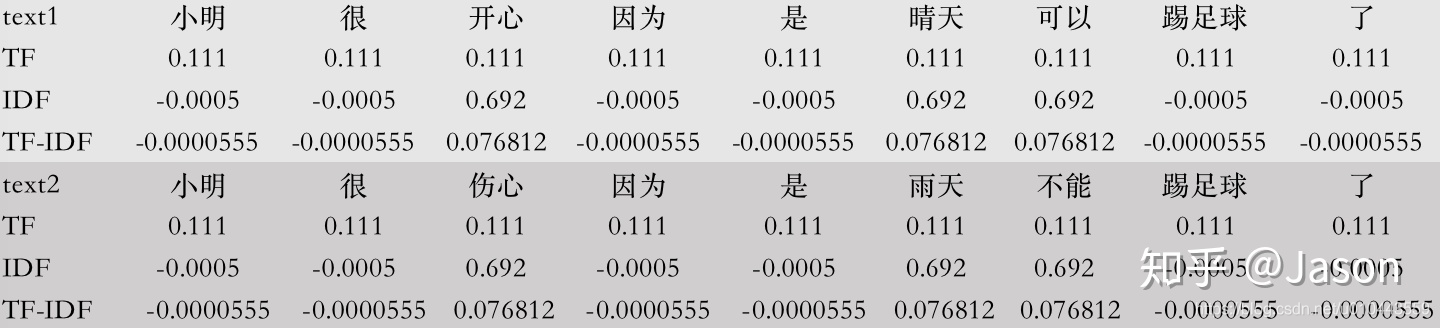
#TFIDF 文字表示形式
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer(lowercase=False, max_features=4000)
vec_matrix=vec.fit_transform(texts)
print(vec.get_feature_names())
print(vec_matrix.toarray())
N-gram方法
文件一:湯姆追傑瑞
文件二:湯姆傑瑞
文件三:傑瑞追湯姆 詞袋:「湯姆追」,「追傑瑞」,「湯姆傑瑞」,「傑瑞追」,「追湯姆」。
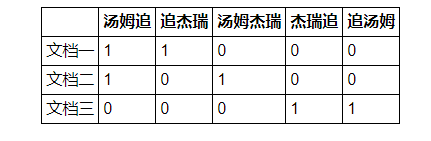
共現矩陣
主要用於發現主題,解決詞向量相近關係的表示;
將共現矩陣行(列)作爲詞向量
例如:語料庫如下:
• I like deep learning.
• I like NLP.
• I enjoy flying. 則共現矩陣表示如下:(使用對稱的窗函數(左右window length都爲1) )
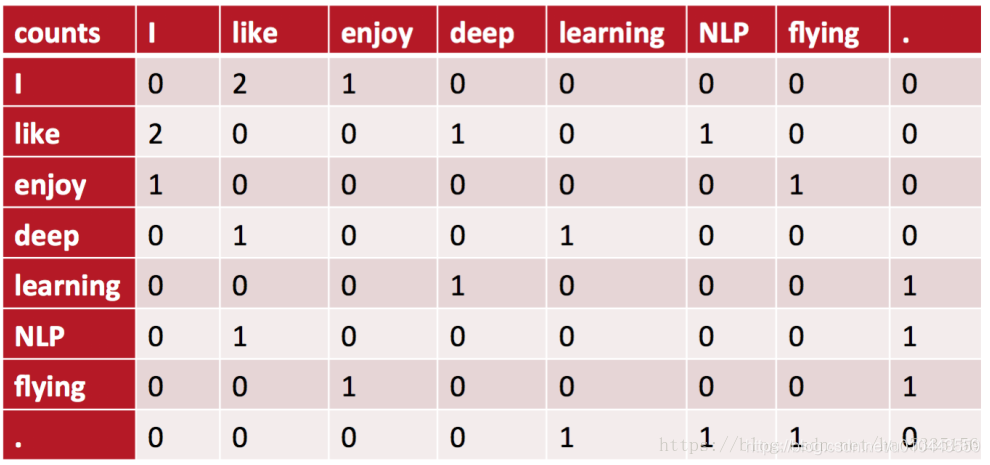
例如:「I like」出現在第1,2句話中,一共出現2次,所以=2。 對稱的視窗指的是,「like I」也是2次。共現視窗中的兩個詞語不考慮前後順序,所以矩陣是對稱矩陣。
將共現矩陣行(列)作爲詞向量表示後,可以知道like,enjoy都是在I附近且統計數目大約相等,他們意思相近。
缺點:面臨稀疏性問題、向量維數隨着詞典大小線性增長
解決:SVD、PCA降維,但是計算量大
主題模型
主題模型用於從文字庫中發現有代表性的主題(得到每個主題上面詞的分佈特性),並能夠計算出每篇文章的主題分佈。
LDA
隱狄利克雷模型(LDA)是利用文件中單詞的共現關係來對單詞按主題聚類,可以理解爲「文件-單詞」矩陣進行分解,得到「文件-主題」和「主題-單詞」兩個概率分佈。
輸出:文件-主題概率分佈矩陣和主題-詞概率分佈矩陣
訓練方法:利用文件中單詞的貢獻關係來對單詞按主題聚類,也可以理解爲對「文件-單詞」進行矩陣分解(有點像ALS,即將NM矩陣分解維 NK 和 K*M兩個矩陣,K爲主題個數)
用處:可以找到詞與主題,主題與文件之間的關係
LSA
Latent Semantic Analysis(LSA)假設以一定的概率選擇了一個主題,然後以一定的概率選擇當前主題的詞。
LSI是基於奇異值分解(SVD)的方法來得到文字的主題的。 通過一次SVD,就可以得到文件和主題的相關度,詞和詞義的相關度以及詞義和主題的相關度。
LSA**舉例**: 假設我們有下面 下麪這個有10個詞三個文字的詞頻TF對應矩陣如下:
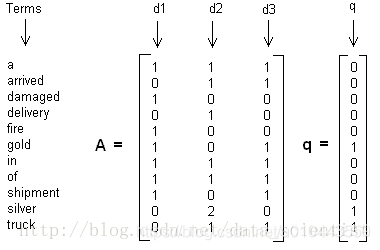
這裏我們沒有使用預處理,也沒有使用TF-IDF,在實際應用中最好使用預處理後的TF-IDF值矩陣作爲輸入。我們假定對應的主題數爲2,則通過SVD降維後得到的三矩陣爲:(m:詞語的個數,n文字個數,k主題個數)
:第i個詞和第j個主題的相關度
:第i個主題和第j個主題的相關度
:第i個文字和第j個主題的相關度

# 主題模型 https://blog.csdn.net/selinda001/article/details/80446766
doc1 = "Sugar is bad to consume. My sister likes to have sugar, but not my father."
doc2 = "My father spends a lot of time driving my sister around to dance practice."
doc3 = "Doctors suggest that driving may cause increased stress and blood pressure."
doc4 = "Sometimes I feel pressure to perform well at school, but my father never seems to drive my sister to do better."
doc5 = "Health experts say that Sugar is not good for your lifestyle."
# 整合文件數據
doc_complete = [doc1, doc2, doc3, doc4, doc5]
from nltk.stem.wordnet import WordNetLemmatizer
import string
stop = ["\n","\r","is","to","the","of","a","an","my","i","at","for","not","that","but"]
exclude = set(string.punctuation)
lemma = WordNetLemmatizer()
def clean(doc):
stop_free = " ".join([i for i in doc.lower().split() if i not in stop])
punc_free = ''.join(ch for ch in stop_free if ch not in exclude)
normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split())
return normalized
doc_clean = [clean(doc).split() for doc in doc_complete]
print(doc_clean)
import numpy as np
import gensim
from gensim import corpora
# 建立語料的詞語詞典,每個單獨的詞語都會被賦予一個索引
dictionary = corpora.Dictionary(doc_clean)
print(len(dictionary),dictionary)
# 使用上面的詞典,將轉換文件列表(語料)變成 DT 矩陣
doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean]
print(doc_term_matrix)
# 使用 gensim 來建立 LDA 模型物件
Lda = gensim.models.ldamodel.LdaModel
# 在 DT 矩陣上執行和訓練 LDA 模型
ldamodel = Lda(doc_term_matrix, num_topics=3, id2word = dictionary, passes=50)
print(ldamodel)
# 輸出結果
print(ldamodel.print_topics(num_topics=3, num_words=3))
#文字主題表示
for doc in ldamodel[doc_term_matrix]:
print(doc)
靜態詞向量
BOW優點:
1、解決了分類器不好處理離散數據的問題
2、 在一定程度上也起到了擴充特徵的作用
BOW缺點:
1、它是一個詞袋模型,不考慮詞與詞之間的順序(文字中詞的順序資訊也是很重要的);
2、它假設詞與詞相互獨立(實際上大多數情況下,詞與詞是相互影響的);
3、它得到的特徵是離散稀疏的
主題模型優點:
1、可以找到詞與主題,主題與文件之間的關係
主題模型缺點:
1、無法挖掘的詞與詞之間的相似度
2、計算量比較大(奇異值分解SVD)
爲了解決詞語向量的稀疏性問題,以及挖掘詞語之間的語意關係,研究者提出了用** 詞嵌入**的概念。
詞嵌入是一類將詞向量化的模型的統稱,核心思想是將每個詞對映成低維空間(通常K=50~300維)上的一個稠密向量(Dense Vector)。
神經網路將每個詞對映成低維空間(通常K=50~300維)上的一個稠密向量(Dense Vector)。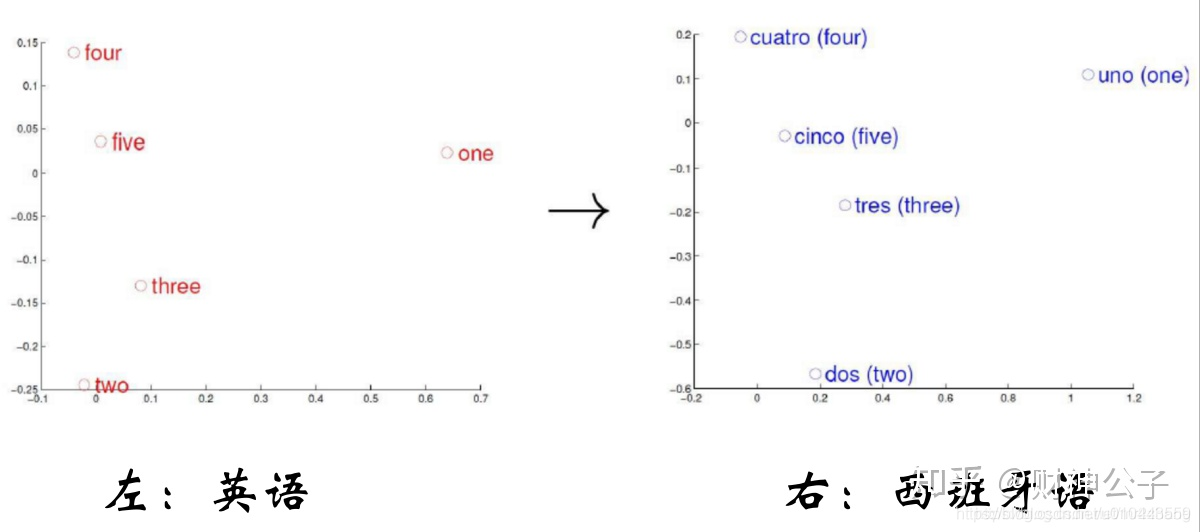
利用向量之間的距離可以計算詞語之間的語意關係

king和queen之間的關係相比與man與woman的關係大體應該相同的,那麼他們通過矩陣運算,維持住這種關係
Paris 和France之間的關係相比與Berlin與German的關係大體應該相同的,那麼他們通過矩陣運算,維持住這種關係
import gensim
from gensim.models import word2vec
word2vec_path = 'D:\py3.6code\data_nlp\word_vec\\200dim\word2vec.model'
model=gensim.models.Word2Vec.load(word2vec_path)
print(model.vector_size)#詞向量維度
sim_words = model.most_similar(positive=['女人'])
for word,similarity in sim_words:
print(word,similarity) # 輸出’女人‘相近的詞語和概率
print(model['女孩'])
NNLM
神經網路語言模型(2003,A Neural Probabilistic Language Model)其用前n-1個詞預測第n個詞的概率,並用神經網路搭建模型。
應用場景:已知前文數個詞語,通過概率計算預測下一個詞。
思路:輸入詞語文字第i個詞語的上下文詞語(視窗大小k)oneHot編碼,與矩陣C(vocabSizehiddenSize)相乘得到(oneHot編碼與C矩陣形成只有編碼爲1的位置得到維度爲)hiddenSize維度的向量;得到的khiddenSize維度矩陣,拼接起來得到(khiddenSize,)向量,在經過全連線層softmax得到下一個詞語的概率,(共有vocabSize個概率,且概率之和=1)。
輸入:語料中詞w以及它的上下文{w,Context(w)w,Context(w)};
輸出:預測語料中基於前文的前提下每個詞的概p(w∣Context(w))p(w∣Context(w))(即類條件概率);
目標:最大化似然函數。
NNLM具有三層網路結構,分別爲輸入(投影)層、隱含層和輸出層,如下圖所示。
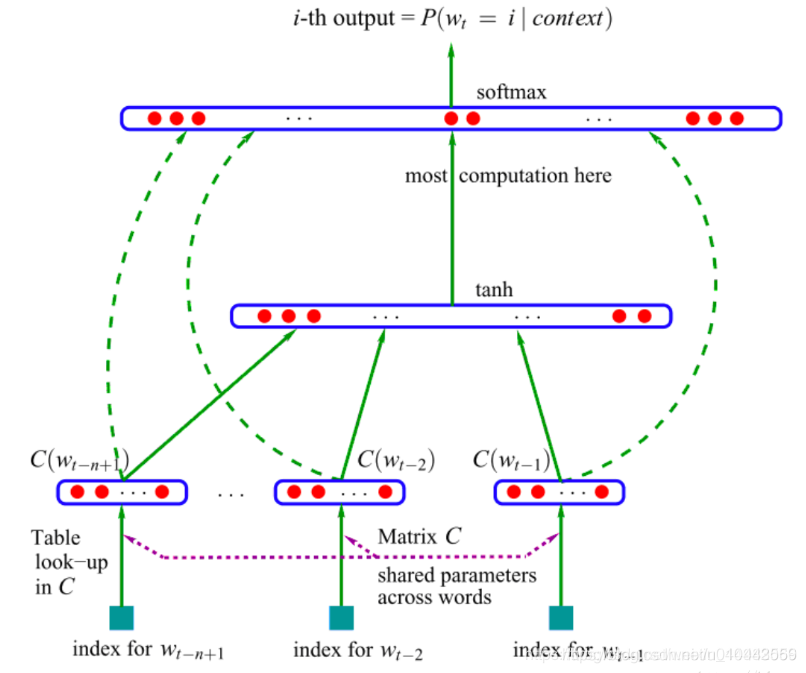
上述得到的C_vocabSize*hiddenSize 即可以將每個詞語表示成一個稠密向量(Dense Vector)表示,我們稱之爲詞嵌入表示方式。
word2vec
word2vec和神經網路語言模型不同,直接來學習這個詞向量,使用的基本假設是分佈式假設,如果兩個詞的上下文時相似的,那麼他們語意也是相似的。
Word2Vec是谷歌2013年提出的目前最常用的詞嵌入模型之一,Word2Vec實際上是一種淺層的神經網路模型,它有兩種網路結構,分別是CBOW(Continues Bag of Words)和Skip-gram。
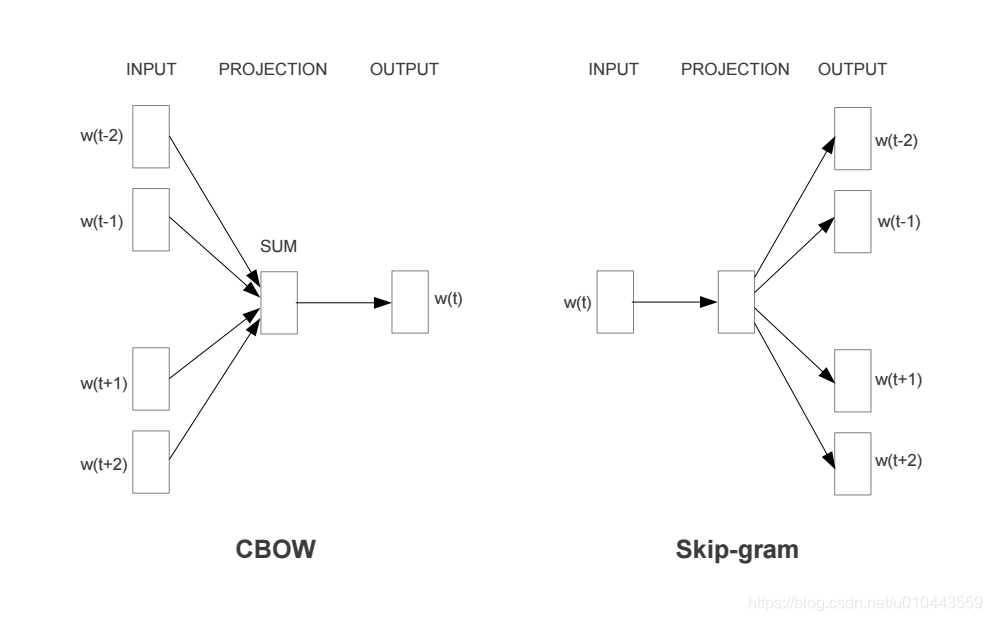
CBOW的目標是根據上下文出現的詞語來預測當前詞的生成概率;而Skip-gram是根據當前詞來預測上下文中各詞的生成概率。CBOW和Skip-gram都可以表示成輸入層(Input)、對映層(Projection)和輸出層(Output)組成的神經網路。
在神經網路語言模型的基礎上做了一些簡化: 這裏沒有做拼接,而是做了sum,直接去預測後面那個詞。
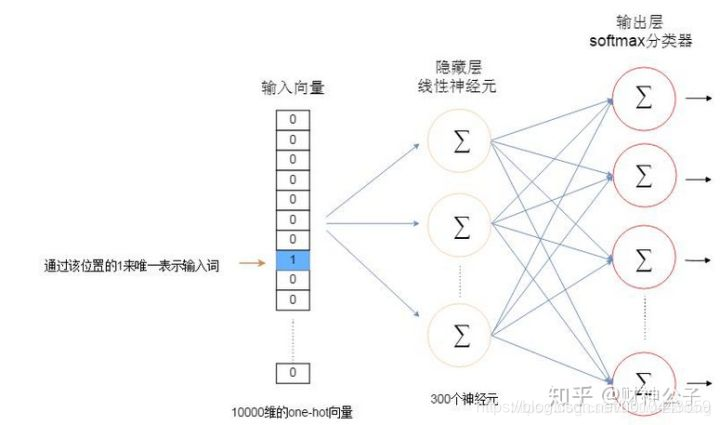
word2vec 兩點優化:
1、hierarchical-softmax哈夫曼樹將平鋪型softmax壓縮成層級softmax【優點】
(1)softmax計算量爲VocabSize,現在變成了log2VocabSize,
(2)使用霍夫曼樹是高頻的詞靠近樹根,這樣高頻詞需要更少的時間會被找到,這符合我們的貪心優化思想。
2、負採樣 【優點】
(1)negative sampling 每次讓一個訓練樣本僅僅更新一小部分的權重參數,從而降低梯度下降過程中的計算量。
(2)對頻繁詞進行二次抽樣和應用負抽樣不僅減少了訓練過程的計算負擔,而且還提高了其結果詞向量的品質。
fasttext
fasttext的模型與CBOW類似,實際上,fasttext的確是由CBOW演變而來的。CBOW預測上下文的中間詞,fasttext預測文字標籤。與word2vec演算法的衍生物相同,稠密詞向量也是在訓練神經網路的過程中得到的。
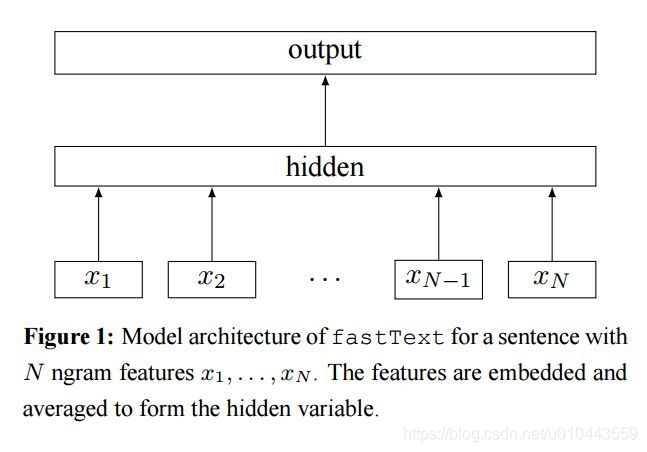
fasttext中採用層級softmax做分類,這與CBOW相同。fasttext演算法中還考慮了詞的順序問題,即採用N-gram,與之前介紹離散表示時的做法相同。如:今天天氣非常不錯,Bi-gram的表示就是:今天、天天、天氣、氣非、非常、常不、不錯。
Glove
Glove模型 Cbow/Skip-Gram 是一個local context window的方法,比如使用NS來訓練,缺乏了整體的詞和詞的關係,負樣本採用sample的方式會缺失詞的關係資訊。 另外,直接訓練Skip-Gram型別的演算法,很容易使得高曝光詞彙得到過多的權重。
Global Vector融合了矩陣分解Latent Semantic Analysis (LSA)的全域性統計資訊和local context window優勢。融入全域性的先驗統計資訊,可以加快模型的訓練速度,又可以控制詞的相對權重。
我們可以通過word2vec或者 glove這種模型在大量的未標註的語料上學習,我們可以學習到比較好的向量表示,可以學習到詞語之間的一些關係。比如男性和女性的關係距離,時態的關係,學到這種關係之後我們就可以把它作爲特徵用於後續的任務,從而提高模型的泛化能力。 但是同時存在一些問題比如:
He deposited his money in this bank .
His soldiers were arrayed along the river bank .
【bank 一詞多義問題】word embeding 有個問題就是我們的詞通常有很多語意的,比如bank是銀行還是河岸,具體的意思要取決與上下文,如果我們強行用一個向量來表示語意的話,只能把這兩種語意都編碼在這個向量裡,但實際一個句子中,一個詞只有一個語意,那麼這種編碼是有問題的。
動態詞向量
靜態詞向量優點
1、解決特徵表示稀疏問題
2、可以挖掘詞語之間的語意關係
靜態詞向量缺點:
1、無法解決一詞多義的問題
2、無法挖掘上下文語意資訊
Word2vec演算法通過使用一組固定維度的向量來表示單詞,但是往往一個詞語在不同的語境中會有不同的意思。 eg:「長」這個字,在「長度」這個詞中表示度量,在「長高」這個詞中表示增加。那麼爲什麼我們不通過「長」周圍是「度」或者是「高」來判斷它的讀音或者它的語意呢?這個問題就派生出語境中的詞嵌入模型。
要解決這一問題,就引入了【contextual word embedding】。
contextual word embedding:無監督的上下文的表示,這種無監督的學習是考慮上下文的,比如ELMo、OpenAI GPT、BERT都是上下文相關的表示方法。
elmo
ACL2017發表的《Semi-supervised sequence tagging with bidirectional language models》 EMLo改變Word2vec類的將單詞固定爲指定長度的向量處理方式,它是在爲每個單詞分配詞向量之前先檢視整個句子,然後使用bi-LSTM來訓練它對應的詞向量。
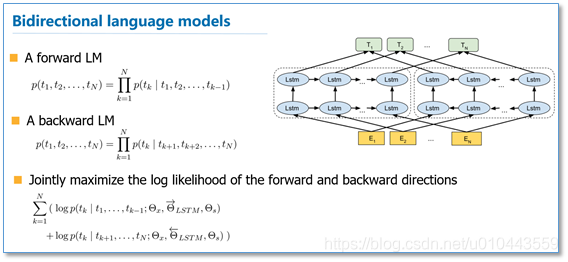
ELMO雖然用了雙向的LSTM模型解決了單向流問題,但是仍然會由順序依賴問題。
RNN 序列依賴問題
可以通過RNN/LSTM/GRU來解決上下文的語意問題,RNN與普通深度學習不同的是,RNN是一種序列的模型,會有一定的記憶單元,能夠記住之前的歷史資訊,從而可以建模這種上下文相關的一些語意。RNN中的記憶單元可以記住當前詞之前的資訊。
RNN序列可能會存在梯度消失或梯度爆炸的問題,因此提出LSTM模型。
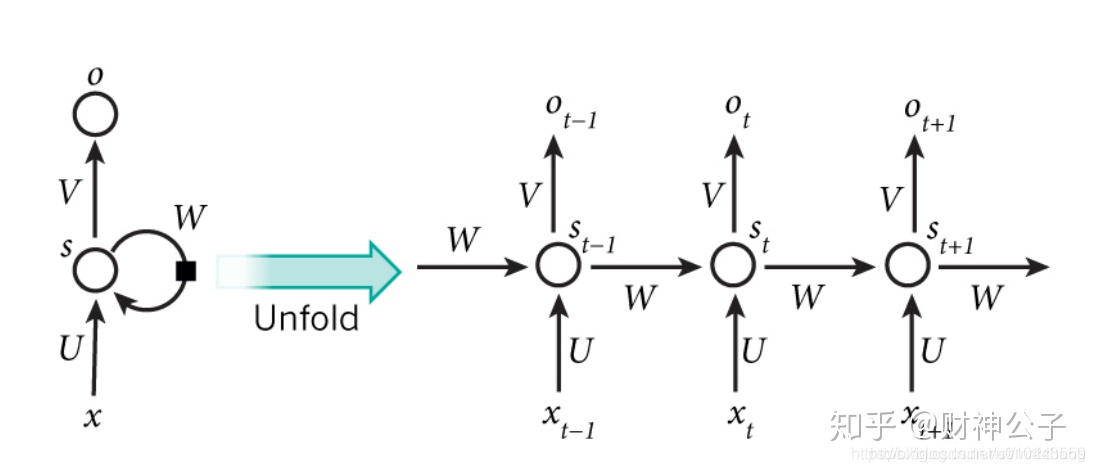
RNN的三個問題:
1、順序依賴,t依賴t-1時刻(序列的,很難並行的計算,持續的依賴的關係,通常很慢,無法並行)
The animal didn’t cross the street because it was too tired.
The animal didn’t cross the street because it was too narrow.
2、單向資訊流(如僅根據上文或下文的資訊不能確定文中it的指代)
3、需要一些比較多的監督數據,對於數據獲取成本很高的任務,就比較困難,在實際情況中很難學到複雜的上下文關係
爲了解決以上問題研究者們提出了用Transformer模型代替LSTM模型。
2017年6月google團隊在《Attention is all your need》論文中提出的Transformer解碼器作爲語言模型。Transformer模型主要是利用自注意力(self-attention)機制 機製的模型。https://www.cnblogs.com/robert-dlut/p/9824346.html
這篇論文主要亮點在於
(1)不同於以往主流機器翻譯使用基於RNN的seq2seq模型框架,該論文用attention機制 機製代替了RNN搭建了整個模型框架。
(2)提出了多頭注意力(Multi-headed attention)機制 機製方法,在編碼器和解碼器中大量的使用了多頭自注意力機制 機製(Multi-headed self-attention)。
(3)在WMT2014語料中的英德和英法任務上取得了先進結果,並且訓練速度比主流模型更快。
文字表示方法優缺點
參考bert.docx檔案,插入對比表格。
參考文獻
[1] https://blog.csdn.net/jiaowoshouzi/article/details/89073944
[2] https://www.cnblogs.com/gczr/p/11785930.html
[3] https://blog.csdn.net/MarsYWK/article/details/86648812
[4] https://zhuanlan.zhihu.com/p/48612853
[5] https://blog.csdn.net/sparkexpert/article/details/79890972
[6] https://www.cnblogs.com/robert-dlut/p/9824346.html
[7] https://www.cnblogs.com/robert-dlut/p/8638283.html
[8] https://zhuanlan.zhihu.com/p/106106079
[9] https://www.cnblogs.com/robert-dlut/p/9824346.html
[10] https://www.cnblogs.com/robert-dlut/p/8638283.html
[11] https://zhuanlan.zhihu.com/p/106106079
[12] https://zhuanlan.zhihu.com/p/106129657
[13] https://blog.csdn.net/haidixipan/article/details/84299039
[14] https://zhuanlan.zhihu.com/p/56382372
[15] https://zhuanlan.zhihu.com/p/56382372
[16] https://blog.csdn.net/data_scientist/article/details/79063138
跳轉下一篇Transformer:link.