在詞表示學習中的web語意知識WESEK(2019 AAAI)

摘要:
提出利用從web結構化數據中自動挖掘語意知識來增強WRL(詞表示學習)。首先構造一個語意相似度圖,即語意知識,它是基於從web上提取的大量語意列表,使用幾種預定義的HTML標記模式。然後提出了一種有效的聯合詞表示學習模型,從語意知識和文字語料庫中獲取語意。
背景
分佈式單詞表示提高了許多NLP應用程式的效能,主要是因爲它們能夠從文字序列集閤中捕獲語意規則。許多研究工作試圖從語意的角度利用語意詞彙來加強詞彙表徵學習(WRL)。語意詞典可以看作是一個列表集合,每個列表由語意相關的詞組成。一些現有的工作通過後處理模型將同義詞向量拉近。或同義詞之間的距離作爲正則化因子的聯合表徵學習模型。最近,許多人工精心設計的語意關係或語言學家的結構,如同義詞和反義詞,概念趨同和詞彙分歧,被用來增強單詞的語意。
問題
然而,應該指出的是,大多數現有模型可能有侷限性,因爲它們要求高品質,人工創造的,語意詞彙或語言結構。即使是像WordNet這樣的高品質語意資源,覆蓋範圍也可能相當有限。以英語WordNet爲例,它只包含155K個單詞,用176K個語法集組織起來,與訓練數據中的大詞彙量相比,這是相當小的。Vuli’c等人。(2018)和Glavaˇs和Vuli´c(2018)部分解決了這一問題,首先設計了一個對映函數來學習所見單詞的專門化過程,然後將所學函數應用於語意詞彙中的看不到的單詞。不幸的是,他們的方法仍然依賴於來自人工建立的資源的語言限制。因此,我們應該利用能夠自動構建的詞彙覆蓋率相對較高的語意資源。
IDEA
使用一些預先定義的htmltag模式來大規模地從web數據中提取語意列表。然而,現有的方法無法直接使用所提取的語意列表,因爲它們含有大量的噪聲,而且有些列表是高度冗餘的。爲了解決這個問題,設計了一個相似度函數來度量每個共現詞對之間的語意相關性。然後構建語意相似度圖,將詞表示爲頂點,每條邊表示對應兩個頂點之間的相似度。該語意相似度圖被視爲web語意知識,以進一步增強WRL。
Web Semantic Knowledge Extraction
從web結構化數據中構造語意知識主要有兩個步驟:
(1)語意列表抽取;
(2)相似圖構造。進一步利用相似圖(也稱爲語意知識)進行詞彙表徵學習。
Semantic Lists Extraction
在將HTML頁面解析爲DOM樹之後,如果同一級別的文字節點向上到根節點的祖先是相同的,則將其提取爲語意列表。

表1顯示了本文中使用的HTML標記模式,其中T是提取的語意列表中的一個條目。
Similarity Graph Construction
從web上提取的語意列表並不能直接替代先前工作中使用的語意詞典,因爲它們可能包含太多的噪音或是高度冗餘。
爲了解決這個問題,設計了一個相似函數。對於每個共現詞對:
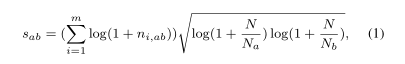
其中n,是域中單詞和在同一列表中協同出現的次數,共有個域;是從web中提取的語意列表總數;N,N分別是包含單詞a和b的語意列表的數量。
該函數的右側(詞根部分)考慮了單詞a和b在整個語料庫中的頻率,這與反向文件頻率(IDF)相似。對於左側,如果一對詞出現在多個網站中,且出現頻率相對較高,則該詞得分較高。
剪枝操作
爲了保證語意資源的高品質,通過去除相似度較低的邊緣來對圖進行剪枝。給定一個詞,設{b1,b2,…,bK}表示a的鄰域,按相似度的降序排列。通過移除長尾鄰居來獲得語意相關的前k個鄰居
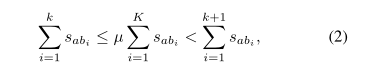
其中,µ是0和1之間的閾值,S表示a和b的相似性。剪枝後的相似度圖被認爲是高品質的語意知識,可以用來改進WRL
WRL with Semantic Knowledge
Skip-gram and Negative Sampling
Skip-gram是從文字中學習高品質單詞表示的一種有效方法。SG的目標是學習能夠準確預測給定單詞周圍單詞的單詞表示。給定一系列單詞w,w,,w,Skip-gram旨在最大化對數概率:
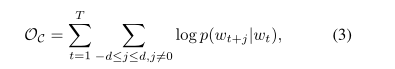
d是視窗大小
p(w | w)是上下文詞w在目標詞w上的條件的預測概率,由softmax函數定義:
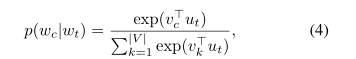
其中,u和v分別是單詞w和w的「輸入」和「輸出」向量表示。|V |是詞彙表中的單詞數。輸入嵌入通常表示原始單詞嵌入,而輸出嵌入表示上下文中的單詞。直覺上,上下文相似的詞應該有相似的表示。
負採樣
一般來說,詞彙量很大。在整個詞彙表中計算softmax函數是非常昂貴的。一種計算效率高的近似方法是負採樣方法。負數採樣不是在可預測空間上進行預測,而是對目標詞的上下文中是否存在一個詞進行二元預測。形式上,對於目標單詞w位置t,讓視窗大小內的所有上下文單詞都是正範例,並從詞彙表中隨機抽取否定範例。負採樣的目標函數爲最小化下列函數:
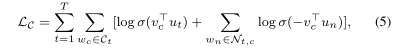
其中σ爲sigmoid function,c是目標詞w的上下文集,N是從上下文詞w的噪聲分佈Pn(w)中提取的一組負樣本。其中Pn(w)
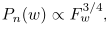
其中f是單詞w的頻率。
方法:WESEK: Word Embedding with SemanticKnowledge
Problem formulation.
在相似度圖中,把w和w之間的相似度得分表示爲s。給定一個目標詞w,S是剪枝相似圖中所有對應鄰域的集合。對於每個相鄰詞w ,我們將其關聯得分定義爲:
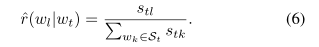
從詞彙表徵的角度,定義w和w之間的語意關聯得分:
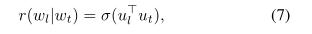
目標是在語意相似度圖中連線單詞時,最大化所學單詞表示的相似度。考慮到單詞w和它的鄰居S,我們的目標是最大化以下目標:
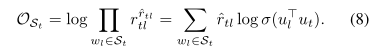
化簡:
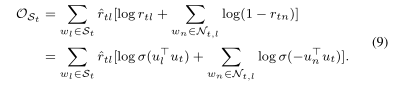
爲了從文字和語意知識中聯合學習表示,一種簡單的方法是將目標引入Skip-gram模型。然而,更新目標詞及其所有相鄰詞的表示仍然很耗時。我們提出了正採樣,即不更新所有鄰居的表示,而是隻更新鄰居的一個子集,該子集可視爲正樣本。給定一個目標詞w,考慮語意知識的關聯度,從分佈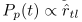
中提取正樣本,得到正樣本集P。因此,目標變爲:
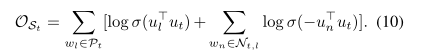
然後,對於訓練數據中的每個目標詞,目標是使以下目標函數最大化:
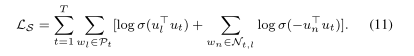
通過將其與原始SG模型相結合,聯合目標是最大化:
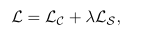
實驗
爲了確保比較是公平的,在English Wikipedia dump(http://dumps. wikimedia. org/ enwiki/)上訓練所有的嵌入。頻率低於5的單詞被過濾掉。訓練數據有大約12億個token,詞彙量爲290萬。
使用表1中定義的模式從http://commoncrawl.org/中爬取大量語意列表,並過濾出訓練數據詞彙表中不存在的條目。條目數小於3的列表將被刪除,我們只選擇頻率高於5的單詞。然後,我們構造了語義相似度圖,如第三節所述。我們通過使用等式2(剪枝)刪除相似度低的邊來修剪圖,其中µ=0.2,即,對於每個單詞,我們選擇其相似度累積和至少佔總和20%的最上等權鄰域。當µ在0.1-0.5之間時,效能相當穩定;當其高於0.5時,效能略有下降。得到的剪枝後的相似圖-語意知識-有160萬個節點和830萬條邊(這表明語意知識對詞彙的覆蓋率相對較高)
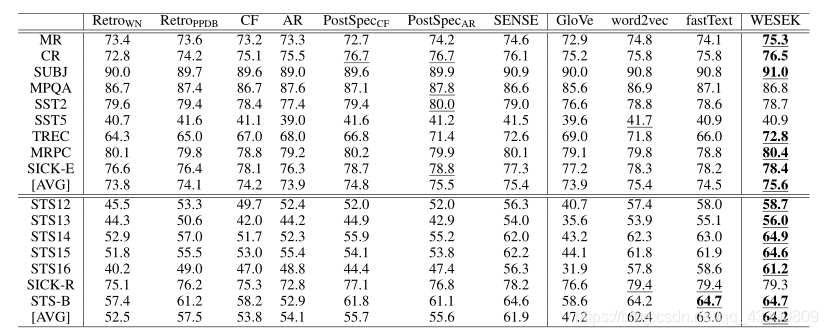
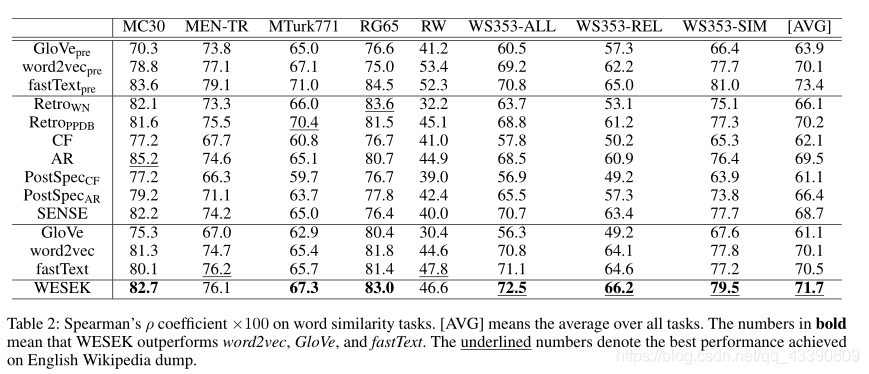
Word Similarity 評估
Text Classification and Textual Similarity評估