[論文翻譯] Machine learning: Trends, perspectives, and prospects
[論文題目]:Machine learning: Trends, perspectives, and prospects
[論文來源]:Machine learning: Trends, perspectives, and prospects
[翻譯人]:BDML@CQUT實驗室
Machine learning:Trends,perspectives, and prospects
機器學習:趨勢、觀點和前景
Abstract
Machine learning addresses the question of how to build computers that improve automatically through experience. It is one of today’s most rapidly growing technical fields, lying at the intersection of computer science and statistics, and at the core of artificial intelligence and data science. Recent progress in machine learning has been driven both by the development of new learningalgorithms and theory and by the ongoing explosion in the availability of online data and low-cost computation.The adoption of data-intensive machine-learning methods can be found throughout science, technology and commerce, leading to more evidence-based decision-making across many walks of life, including health care, manufacturing, education, financial modeling, policing, and marketing.
摘要
機器學習解決的問題是如何建立通過經驗自動改進的計算機。它是當今發展最快的技術領域之一,位於電腦科學和統計學的交叉點,是人工智慧和數據科學的核心。機器學習的最新進展是由新的學習演算法和理論的發展以及線上數據的可用性和低成本的持續爆炸所推動的計算採用數據密集型機器學習方法可以在科學、技術和商業中找到,在許多行業,包括醫療保健、製造業、教育、金融建模、警務和市場行銷等領域,都會帶來更多基於證據的決策。
正文
Machine learning is a discipline focused on two interrelated questions: How can one construct computer systems that automatically improve through experience? and What are the fundamental statistical computational-information-theoretic laws that govern all learning systems, including computers, humans, and organizations? The study of machine learning is important both for addressing these fundamental scientific and engineering questions and for the highly practical computer software it has produced and fielded across many applications.
機器學習是一門專注於兩個相互關聯的問題的學科:如何構建一個通過經驗自動改進的計算機系統?統計計算資訊理論的基本定律是什麼,支配着所有的學習系統,包括計算機、人類和組織?機器學習的研究對於解決這些基本的科學和工程問題以及它在許多應用中產生和應用的高度實用的計算機軟體都很重要。
Machine learning has progressed dramatically over the past two decades, from laboratory curiosity to a practical technology in widespread commercial use. Within artificial intelligence (AI), machine learning has emerged as the method of choice for developing practical software for computer vision, speech recognition, natural language processing, robot control, and other applications. Many developers of AI systems now recognize that, for many applications, it can be far easier to train a system by showing it examples of desired input-output behavior than to program it manually by anticipating the desired response for all possible inputs. The effect of machine learning has also been felt broadly across computer science and across a range of industries concerned with data intensive issues, such as consumer services, the diagnosis of faults in complex systems, and the control of logistics chains. There has been a similarly broad range of effects across empirical sciences, from biology to cosmology to social science, as machine-learning methods have been developed to analyze high throughput experimental data in novel ways. See Fig. 1 for a depiction of some recent areas of application of machine learning.
機器學習在過去的二十年裏取得了巨大的進步,從實驗室的好奇心到廣泛商業應用的實用技術。在人工智慧(AI)中,機器學習已經成爲開發計算機視覺、語音識別、自然語言處理、機器人控制和其他應用的實用軟體的首選方法。許多人工智慧系統的開發人員現在認識到,對於許多應用來說,通過展示期望的輸入-輸出行爲的例子來訓練一個系統要比通過預測所有可能輸入的期望響應來手動程式設計要容易得多。機器學習的影響在電腦科學和涉及數據密集型問題的一系列行業中也得到廣泛的感受,如消費者服務、複雜系統故障診斷和物流鏈控制。從生物學到宇宙學再到社會科學,在經驗科學中也有類似廣泛的影響,因爲機器學習方法已經被開發出來以新的方式分析高通量的實驗數據。有關機器學習的一些最新應用領域的描述,請參見圖1。
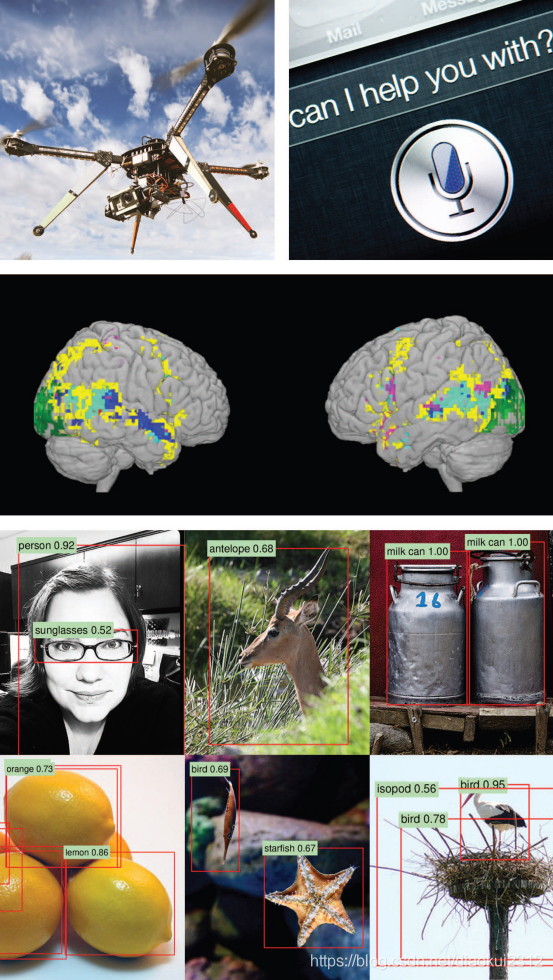
Fig. 1. Applications of machine learning. Machine learning is having a substantial effect on many areas of technology and science; examples of recent applied success stories include robotics and autonomous vehicle control (top left), speech processing and natural language processing (top right), neuroscience research (middle), and applications in computer vision (bottom). [The middle panel is adapted from (29). The images in the bottom panel are from the ImageNet database; object recognition annotation is by R. Girshick.]
圖1。機器學習的應用。機器學習對許多技術和科學領域產生了重大影響;最近的應用成功案例包括機器人和自動車輛控制(左上)、語音處理和自然語言處理(右上)、神經科學研究(中)和計算機視覺應用(下)。[中間面板改編自(29)。底部面板中的影象來自ImageNet數據庫;物件識別註釋由R.Girshick提供。]
A learning problem can be defined as the problem of improving some measure of perform ance when executing some task, through some type of training experience. For example, in learning to detect credit-card fraud, the task is to assign a label of 「fraud」 or 「not fraud」 to any given credit-card transaction. The performance metric to be improved might be the accuracy of this fraud classifier, and the training experience might consist of a collection of historical credit-card transactions, each labeled in retrospect as fraudulent or not. Alternatively, one might define a different performancemetric that assigns ahigher penalty when 「fraud」 is labeled 「not fraud」 than when 「not fraud」 is incorrectly labeled 「fraud.」 One might also define a different type of training experience—for example, by including unlabeled credit-card transactions along with labeled examples.
學習問題可以定義爲在執行某項任務時,通過某種型別的訓練經驗來提高某種績效的問題。例如,在學習檢測信用卡欺詐時,任務是給任何給定的信用卡交易指定一個「欺詐」或「不欺詐」的標籤。需要改進的效能指標可能是該欺詐分類器的準確性,而培訓經驗可能包括一組歷史信用卡交易,每一筆交易回顧起來都被標記爲欺詐或不欺詐。或者,可以定義一種不同的績效指標,當「欺詐」被標爲「非欺詐」時,比「不欺詐」被錯誤地標記爲「欺詐」時,會給予更高的懲罰。也可以定義不同類型的培訓體驗,例如,通過將未標記的信用卡交易與標記的範例一起包含在內。
A diverse array of machine-learning algorithms has been developed to cover the wide variety of data and problem types exhibited across different machine-learning problems. Conceptually, machine learning algorithms can be viewed as searching through a large space of candidate programs, guided by training experience, to find a program that optimizes the performance metric. Machine-learning algorithms vary greatly, in part by the way in which they represent candidate programs (e.g., decision trees, mathematical functions, and generalprogramming languages) and in part by the way in which they search through this space of programs (e.g., optimization algorithms with well-understood convergence guarantees and evolutionary search methods that evaluate successive generations of randomly mutated programs). Here, we focus on approaches that have been particularly successful to date.
已經開發了一系列不同的機器學習演算法,以涵蓋不同機器學習問題中顯示的各種數據和問題型別。從概念上講,機器學習演算法可以看作是在訓練經驗的指導下,在大量候選程式空間中搜尋,找到一個優化效能指標的程式。機器學習演算法變化很大,部分原因在於它們表示候選程式的方式(如決策樹、數學函數和通用程式設計語言),另一部分在於它們在程式空間中搜尋的方式(例如。,優化演算法具有良好的收斂保證和進化搜尋方法,評估連續幾代的隨機變異程式)。在這裏,我們關注迄今爲止特別成功的方法。
Many algorithms focus on function approximation problems, where the task is embodied in a function (e.g., given an input transaction, output a 「fraud」 or 「not fraud」 label), and the learning problem is to improve the accuracy of that function, with experience consisting of a sample of known input-output pairs of the function. In some cases, the function is represented explicitly as a parameterized functional form; in other cases, the function is implicit and obtained via a search process, a factorization, an optimization procedure, or a simulation-based procedure. Even when implicit, the function generally depends on parameters or other tunable degrees of freedom, and training corresponds to finding values for these parameters that optimize the performance metric.
許多演算法側重於函數逼近問題,其中任務體現在函數中(例如,給定一個輸入事務,輸出一個「欺詐」或「不欺詐」標籤),學習問題是提高該函數的準確性,經驗包括函數的已知輸入輸出對的樣本。在某些情況下,函數顯式表示爲參數化函數形式;在其他情況下,函數是隱式的,並通過搜尋過程、因子分解、優化過程或基於模擬的過程獲得。即使是隱式的,函數通常也依賴於參數或其他可調自由度,而訓練對應於爲這些參數尋找優化效能指標的值。
Whatever the learning algorithm, a key scientific and practical goal is to theoretically characterize the capabilities of specific learning algorithms and the inherent difficulty of any given learning problem: How accurately can the algorithm learn from a particular type and volume of training data? How robust is the algorithm to errors in its modeling assumptions or to errors in the training data? Given a learning problem with a given volume of training data, is it possible to design a successful algorithm or is this learning problem fundamentally intractable? Such theoretical characterizations of machine-learning algorithms and problems typically makeuse of thefamiliar frameworks of statistical decision theory and computational complexity theory. In fact, attempts to characterize machine-learning algorithms theoretically have led to blends of statistical and computationaltheory in whichthe goalis to simultaneously characterize the sample complexity (how much data are required to learn accurately) and the computational complexity (how much computation is required) and to specify how these depend on features of the learning algorithm such as the representation it uses for what it learns . A specific form of computational analysis that has proved particularly useful in recent years has been that of optimization theory, with upper and lower bounds on rates of convergence of optimization procedures merging well with the formulation of machine-learning problems as the optimization of a performance metric .
無論學習演算法是什麼,一個關鍵的科學和實用的目標是從理論上描述特定學習演算法的能力和任何給定學習問題的固有困難:演算法如何準確地從特定型別和數量的訓練數據中學習?該演算法對其建模假設中的錯誤或對訓練數據中的錯誤的魯棒性如何?給定一個學習問題,在給定的訓練數據量下,有沒有可能設計出一個成功的演算法,或者這個學習問題從根本上說是難以解決的?這種機器學習演算法和問題的理論描述通常使用統計決策理論和計算複雜性理論的相似框架。事實上,從理論上描述機器學習演算法的嘗試導致了統計理論和計算理論的融合,其中的目標是同時描述樣本複雜性(準確學習需要多少數據)和計算複雜性(需要多少計算),並指定它們是如何依賴的學習演算法的特性,例如它所學內容的表示。近年來被證明特別有用的計算分析的一種具體形式是優化理論,它將優化過程的收斂速度的上下界與機器學習問題的表述很好地結合起來,作爲效能指標的優化。
As a field of study, machine learning sits at the crossroads of computer science, statistics and a variety of other disciplines concerned with automatic improvement over time, and inference and decision-making under uncertainty. Related disciplines include the psychological study of human learning, the study of evolution, adaptive control theory, the study of educational practices, neuroscience, organizational behavior, and economics. Although the past decade has seen increased crosstalk with these other fields, we are just beginning to tap the potential synergies and the diversity of formalisms and experimental methods used across these multiple fields for studying systems that improve with experience.
作爲一個研究領域,機器學習處於電腦科學、統計學和其他各種學科的十字路口,這些學科涉及隨着時間的推移自動改進,以及在不確定性下的推理和決策。相關學科包括人類學習的心理學研究、進化研究、適應性控制理論、教育實踐研究、神經科學、組織行爲學和經濟學。儘管在過去的十年中,與這些其他領域的串擾有所增加,但我們纔剛剛開始挖掘潛在的協同效應,以及在這些多個領域使用的形式和實驗方法的多樣性,以研究隨着經驗而改進的系統。
Drivers of machine-learning progress
機器學習進程的驅動因素
The past decade has seen rapid growth in the ability of networked and mobile computing systems to gather and transport vast amounts of data, a phenomenon often referred to as 「Big Data.」 The scientists and engineers who collect such data have often turned to machine learning for solutions to the problem of obtaining useful insights, predictions, and decisions from such data sets. Indeed, the sheer size of the data makes it essential to develop scalable procedures that blend computational and statistical considerations, but the issue is more than the mere size of modern data sets; it is the granular, personalized nature of much of these data. Mobile devices and embedded computing permit large amounts of data to be gathered about individual humans, and machine-learning algorithms can learn from these data to customize their services to the needs and circumstances of each individual. Moreover, these personalized services can be connected, so that an overall service emerges that takes advantage of the wealth and diversity of data from many individuals while still customizing to the needs and circumstances of each. Instances of this trend toward capturing and mining large quantities of data to improve services and productivity can be found across many fields of commerce, science, and government. Historical medical records are used to discover which patients will respond best to which treatments; historical traffic data are used to improve traffic control and reduce congestion; historical crime data are used to help allocate local police to specific locations at specific times; and large experimental data sets are captured and curated to accelerate progress in biology, astronomy, neuroscience, and other dataintensive empirical sciences. We appear to be at the beginning of a decades-long trend toward increasingly data-intensive, evidence-based decisionmaking across many aspects of science, commerce, and government.
在過去的十年裏,網路化和移動計算系統收集和傳輸大量數據的能力迅速增長,這一現象通常被稱爲「大數據」。收集這些數據的科學家和工程師經常求助於機器學習來解決獲取有用見解的問題,這些數據集的預測和決策。事實上,數據的巨大規模使得開發融合計算和統計考慮的可伸縮程式變得至關重要,但問題不僅僅是現代數據集的大小,而是這些數據的粒度和個性化特性。移動裝置和嵌入式計算允許收集大量關於人類個體的數據,而機器學習演算法可以從這些數據中學習,以根據每個人的需要和環境定製他們的服務。此外,這些個性化服務可以連線起來,這樣就形成了一個整體服務,它利用了來自許多個人的豐富和多樣的數據,同時仍然可以根據每個人的需要和情況進行定製。捕捉和挖掘大量數據以提高服務和生產率的趨勢在商業、科學和政府的許多領域都可以找到。歷史醫療記錄用於發現哪些患者對哪種治療反應最好;歷史交通數據用於改善交通管制和減少擁堵;歷史犯罪數據用於幫助在特定時間將當地警察分配到特定地點;大量的實驗數據集被捕獲和管理,以加速生物學、天文學、神經科學和其他數據密集型經驗科學的發展。我們似乎正處於一個長達數十年的趨勢的開端,這一趨勢在科學、商業和政府的許多方面越來越依賴於數據、基於證據的決策。
With the increasing prominence of large-scale data in all areas of human endeavor has come a wave of new demands on the underlying machinelearning algorithms. For example, huge data sets require computationally tractable algorithms, highly personal data raise the need for algorithms that minimize privacy effects, and the availability of huge quantities of unlabeled data raises the challenge of designing learning algorithms to take advantage of it. The next sections survey some of the effects of these demands on recent work in machine-learning algorithms, theory, and practice.
隨着大規模數據在人類各個領域的日益突出,對底層機器學習演算法提出了新的要求。例如,巨大的數據集需要計算上可處理的演算法,高度個人數據增加了對最小化隱私影響的演算法的需求,大量未標記數據的可用性提出了設計學習演算法以利用它的挑戰。接下來的部分將介紹這些需求對機器學習演算法、理論和實踐的最新工作的一些影響。
Core methods and recent progress
核心方法和最新進展
The most widely used machine-learning methods are supervised learning methods. Supervised learning systems, including spam classifiers of e-mail, face recognizers over images, and medical diagnosis systems for patients, all exemplify the function approximation problem discussed earlier, where the training data take the form of a collection of (x, y) pairs and the goal is to produce a prediction y* in response to a query x*. The inputs x may be classical vectors or they may be more complex objects such as documents, images, DNA sequences, or graphs. Similarly, many different kinds of output y have been studied. Much progress has been made by focusing on the simple binary classification problem in which y takes on one of two values (for example, 「spam」 or 「not spam」), but there has also been abundant research on problems such as multiclass classification (where y takes on one of K labels), multilabel classification (where y is labeled simultaneously by several of the K labels), ranking problems (where y provides a partial order on some set), and general structured prediction problems (where y is a combinatorial object such as a graph, whose components may be required to satisfy some set of constraints). An example of the latter problem is part-of-speech tagging, where the goal is to simultaneously label every word in an input sentence x as being a noun, verb, or some other part of speech. Supervised learning also includes cases in which y has realvalued components or a mixture of discrete and real-valued components.
最廣泛使用的機器學習方法是監督學習方法。有監督的學習系統,包括電子郵件的垃圾郵件分類器、影象上的人臉識別器和針對患者的醫療診斷系統,都是前面討論過的函數近似問題的例子,其中訓練數據採用(x,y)對的集合形式,目標是生成對查詢x的預測y。輸入x可以是經典的向量,也可以是更復雜的物件,例如文件、影象、DNA序列或圖形。類似地,研究了許多不同種類的輸出y。在簡單的二元分類問題中,y取兩個值中的一個(例如,「spam」或「not spam」)已經取得了很大的進展,但是對於諸如多類分類(y取K個標籤中的一個)的問題也有大量的研究,多標籤分類(其中y由多個K標籤同時標記)、排序問題(其中y在某個集合上提供偏序)和一般結構化預測問題(其中y是組合物件,例如圖,其元件可能需要滿足某些約束集)。後一個問題的一個例子是詞性標註,目標是同時將輸入句子x中的每個單詞標記爲名詞、動詞或其他詞性。監督學習還包括y具有實值分量或離散分量與實值分量的混合的情況。
Supervised learning systems generally form their predictions via a learned mapping f(x), which produces an output y for each input x (or a probability distribution over y given x). Many different forms of mapping f exist, including decision trees, decision forests, logistic regression, support vector machines, neural networks, kernel machines, and Bayesian classifiers . A variety of learning algorithms has been proposed to estimate these different types of mappings, and there are also generic procedures such as boosting and multiple kernel learning that combine the outputs of multiple learning algorithms. Procedures for learning f from data often make use of ideas from optimization theory or numerical analysis, with the specific form of machinelearning problems (e.g., that the objective function or function to be integrated is often the sum over a large number of terms) driving innovations. This diversity of learning architectures and algorithms reflects the diverse needs of applications, with different architectures capturing different kinds of mathematical structures, offering different levels of amenability to post hoc visualization and explanation, and providing varying trade-offs between computational complexity, the amount of data, and performance.
有監督學習系統通常通過學習對映f(x)形成預測,f(x)爲每個輸入x產生一個輸出y(或y給定x上的概率分佈)。存在許多不同形式的對映,包括決策樹、決策森林、logistic迴歸、支援向量機、神經網路、核機器和貝葉斯分類器。人們已經提出了各種學習演算法來估計這些不同類型的對映,還有一些通用的過程,如boosting和多核學習,它們結合了多種學習演算法的輸出。從數據中學習f的過程通常利用最佳化理論或數值分析的思想,以機器學習問題的具體形式(例如,目標函數或待整合的函數通常是大量術語的總和)推動創新。學習體系結構和演算法的多樣性反映了應用程式的不同需求,不同的體系結構捕獲了不同種類的數學結構,爲事後視覺化和解釋提供了不同程度的適應性,並在計算複雜度之間提供了不同的權衡,數據量和效能。
One high-impact area of progress in supervised learning in recent years involves deep networks, which are multilayer networks of threshold units, each of which computes some simple parameterized function of its inputs.Deep learning systems make use of gradient-based optimization algorithms to adjust parameters throughout such a multilayered network based on errors at its output. Exploiting modern parallel computing architectures, such as graphics processing units originally developed for video gaming, it has been possible to build deep learning systems that contain billions of parameters and that can be trained on the very large collections of images, videos, and speech samples available on the Internet. Such large-scale deep learning systems have had a major effect in recent years in computer vision and speech recognition, where they have yielded major improvements in performance over previous approaches (see Fig. 2). Deep network methods are being actively pursued in a variety of additional applications from natural language translation to collaborative filtering.
近年來,監督學習的一個重要進展領域涉及深度網路,即閾值單元的多層網路,其中每一個都計算它的一些簡單的參數化函數輸入。深學習系統使用基於梯度的優化演算法,根據輸出的誤差調整多層網路中的參數。利用現代並行計算體系結構,如最初爲視訊遊戲開發的圖形處理單元,可以構建包含數十億個參數的深度學習系統,這些系統可以根據網際網路上提供的大量影象、視訊和語音樣本進行訓練。近年來,這種大規模的深度學習系統在計算機視覺和語音識別方面產生了重大影響,與以前的方法相比,它們在效能上取得了重大的改進(見圖2)。從自然語言翻譯到共同作業過濾,深層網路方法正被廣泛應用。
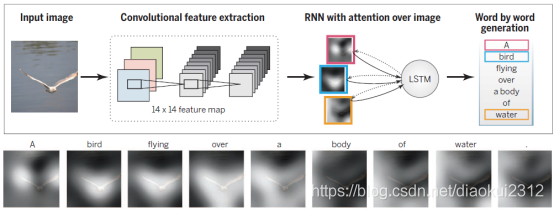
Fig. 2. Automatic generation of text captions for images with deep networks. A convolutional neural network is trained to interpret images, and its output is then used by a recurrent neural network trained to generate a text caption (top). The sequence at the bottom shows the word-by-word focus of the network on different parts of input image while it generates the caption word-by-word. [Adapted with permission from (30)]
圖2。使用深度網路自動生成影象的文字標題。訓練一個折積神經網路來解釋影象,然後它的輸出被訓練成生成文字標題(top)的遞回神經網路使用。底部的序列顯示了網路對輸入影象不同部分的逐字焦點,同時逐字生成標題。[經(30)批準改編]
The internal layers of deep networks can be viewed as providing learned representations of the input data. While much of the practical success in deep learning has come from supervised learning methods for discovering such representations, efforts have also been made to develop deep learning algorithms that discover useful representations of the input without the need for labeled training data. The general problem is referred to as unsupervised learning, a second paradigm in machine-learning research.
深層網路的內部層可以看作是提供輸入數據的學習表示。雖然深度學習的許多實際成功來自於發現這種表示的監督學習方法,但也努力開發深度學習演算法,在不需要標記訓練數據的情況下發現有用的輸入表示。一般的問題被稱爲無監督學習,這是機器學習研究的第二種範式。
Broadly, unsupervised learning generally involves the analysis of unlabeled data under assumptions about structural properties of the data (e.g., algebraic, combinatorial, or probabilistic). For example, one can assume that data lie on a low-dimensional manifold and aim to identify that manifold explicitly from data. Dimension reduction methods including principal components analysis, manifold learning, factor analysis, random projections, and autoencoders—make different specific assumptions regarding the underlying manifold (e.g., that it is a linear subspace, a smooth nonlinear manifold, or a collection of submanifolds). Another example of dimension reduction is the topic modeling framework depicted in Fig. 3. A criterion function is defined that embodies these assumptions—often making use of general statistical principles such as maximum likelihood, the method of moments, or Bayesian integration and optimization or sampling algorithms are developed to optimize the criterion. As another example, clustering is the problem of finding a partition of the observed data (and a rule for predicting future data) in the absence of explicit labels indicating a desired partition. A wide range of clustering procedures has been developed, all based on specific assumptions regarding the nature of a 「cluster.」 In both clustering and dimension reduction, the concern with computational complexity is paramount, given that the goal is to exploit the particularly large data sets that are available if one dispenses with supervised labels.
廣義地說,無監督學習通常涉及在假設數據的結構屬性(例如代數、組合或概率)下對未標記數據進行分析。例如,我們可以假設數據位於低維流形上,目的是從數據中顯式地識別該流形。降維方法包括主成分分析、流形學習、因子分析、隨機投影和自編碼等,對底層流形(例如,它是線性子空間、光滑非線性流形或子流形的集合)做出不同的具體假設。降維的另一個例子是圖3所示的主題建模框架。定義了一個包含這些假設的準則函數,通常利用一般統計原理,如最大似然法、矩量法或貝葉斯積分,並開發優化或抽樣演算法來優化準則。另一個例子是,聚類是在沒有表示所需分割區的顯式標籤的情況下,找到觀測數據的分割區(以及預測未來數據的規則)的問題。已經開發了一系列的聚類程式,所有這些都是基於關於「聚類」性質的特定假設。在聚類和降維中,對計算複雜性的關注是最重要的,考慮到目標是利用特別大的數據集,如果不使用監督標籤,這些數據集是可用的。
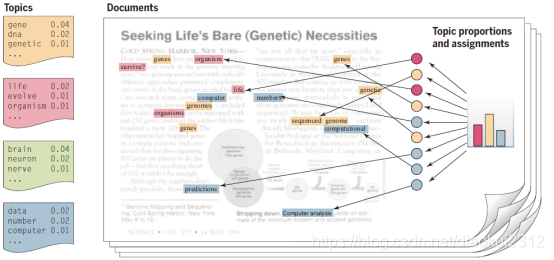
Fig. 3.Topic models. Topic modeling is a methodology for analyzing documents, where a document is viewed as a collection of words, and the words in the document are viewed as being generated by an underlying set of topics (denoted by the colors in the figure). Topics are probability distributions across words (leftmost column), and each document is characterized by a probability distribution across topics (histogram). These distributions are inferred based on the analysis of a collection of documents and can be viewed to classify, index, and summarize the content of documents. [From (31). Copyright 2012, Association for Computing Machinery, Inc. Reprinted with permission]
圖3.主題模型。主題建模是一種用於分析文件的方法,其中文件被視爲一組單詞,文件中的單詞被視爲由一組底層主題(由圖中的顏色表示)生成。主題是單詞之間的概率分佈(最左邊的列),每個文件的特徵是主題之間的概率分佈(直方圖)。這些分佈是根據對文件集合的分析推斷出來的,可以檢視這些分佈來對文件的內容進行分類、索引和彙總。[來自(31)。版權所有2012,計算機械協會,經許可轉載]
A third major machine-learning paradigm is reinforcement learning.Here, the information available in the training data is intermediate between supervised and unsupervised learning. Instead of training examples that indicate the correct output for a given input, the training data in reinforcement learning are assumed to provide only an indication as to whether an action is correct or not; if an action is incorrect, there remains the problem of finding the correct action. More generally, in the setting of sequences of inputs, it is assumed that reward signals refer to the entire sequence; the assignment of credit or blame to individual actions in the sequence is not directly provided. Indeed, although simplified versions of reinforcement learning known as bandit problems are studied, where it is assumed that rewards are provided after each action, reinforcement learning problems typically involve a general control-theoretic setting in which the learning task is to learn a control strategy(a 「policy」) for anagentacting inanunknown dynamical environment, where that learned strat egy is trained to chose actions for any given state, with the objective of maximizing its expected reward over time. The ties to research in control theory and operations research have increased over the years, with formulations such as Markov decision processes and partially observed Markov decision processes providing points of contact Reinforcement-learning algorithms generally make use of ideas that are familiar from the control-theory literature, such as policy iteration, value iteration, rollouts, and variance reduction, with innovations arising to address the specific needs of machine learning (e.g., largescale problems, few assumptions about the unknown dynamical environment, and the use of supervised learning architectures to represent policies). It is also worth noting the strong ties between reinforcement learning and many decades of work on learning in psychology and neuroscience, one notable example being the use of reinforcement learning algorithms to predict the response of dopaminergic neurons in monkeys learning to associate a stimulus light with subsequent sugar reward.
第三種主要的機器學習範式是強化學習。這裏,訓練數據中的可用資訊介於有監督學習和無監督學習之間。強化學習中的訓練數據不是指示給定輸入的正確輸出的訓練範例,而是假設只提供一個動作是否正確的指示;如果一個動作不正確,則仍然存在找到正確動作的問題。更一般地說,在輸入序列的設定中,假定獎勵信號指的是整個序列;在序列中,對單個行爲的信任或責備並不直接提供。事實上,雖然強化學習的簡化版本被稱爲bandit問題,但假設在每次行動之後都會有獎勵,強化學習問題通常涉及一個一般的控制理論環境,在這個背景下,學習任務是學習一個控制策略(「策略」),用於管理未知的動態環境,其中學習的策略被訓練成對任何給定狀態的行爲進行選擇,其目標是最大化其預期回報時間。近年來,與控制理論和運籌學研究的聯繫日益密切,馬爾可夫決策過程和部分觀察的馬爾可夫決策過程等公式提供了接觸點強化學習演算法,通常使用控制理論文獻中熟悉的思想,例如策略迭代、值迭代、展開和方差縮減,通過創新來解決機器學習的特定需求(例如,大規模問題、關於未知動態環境的很少假設、以及使用監督學習體系結構來表示策略)。同樣值得注意的是,強化學習與心理學和神經科學數十年的學習工作有着密切的聯繫,其中一個顯著的例子就是使用強化學習演算法來預測猴子學習將刺鐳射與隨後的糖獎勵聯繫起來的多巴胺能神經元的反應。
Although these three learning paradigms help to organize ideas, much current research involves blends across these categories. For example, semisupervised learning makes use of unlabeled data to augment labeled data in a supervised learning context, and discriminative training blends architectures developed for unsupervised learning with optimization formulations that make use of labels. Model selection is the broad activity of using training data not only to fit a model but also to select from a family of models, and the fact that training data do not directly indicate which model to use leads to the use of algorithms developed for bandit problems and to Bayesian optimization procedures. Active learning arises when the learner is allowed to choose data points and query the trainer to request targeted information, such as the label of an otherwise unlabeled example. Causal modeling is the effort to go beyond simply discovering predictive relations among variables, to distinguish which variables causally influence others (e.g., a high white blood-cell count can predict the existence of an infection, but it is the infection that causes the high white-cell count). Many issues influence the design of learning algorithms across all of these paradigms, including whether data are available in batches or arrive sequentially over time, how data have been sampled, requirements that learned models be interpretable by users, and robustness issues that arise when data do not fit prior modeling assumptions.
儘管這三種學習範式有助於組織思想,但目前的許多研究涉及到這些範疇的融合。例如,半監督學習利用未標記的數據在有監督的學習環境中增加有標記的數據,而區分訓練將爲無監督學習開發的體系結構與利用標籤的優化公式相結合。模型選擇是一項廣泛的活動,即使用訓練數據不僅擬合模型,而且還從一系列模型中進行選擇,而且由於訓練數據不能直接指示要使用哪個模型,這就導致了使用爲bandit問題開發的演算法和貝葉斯優化過程。當學習者被允許選擇數據點並詢問培訓師以請求有針對性的資訊時,就會產生主動學習,例如未標記範例的標籤。因果建模不僅僅是簡單地發現變數之間的預測關係,而是要區分哪些變數會對其他變數產生因果影響(例如,高白細胞計數可以預測是否存在感染,但導致高白細胞計數的是感染)。許多問題影響了學習演算法在所有這些範例中的設計,包括數據是成批可用還是隨時間順序到達,數據是如何採樣的,學習模型的使用者可解釋的要求,以及當數據不符合先前的建模假設時出現的健壯性問題。
Emerging trends
新興趨勢
The field of machine learning is sufficiently young that it is still rapidly expanding, often by inventing new formalizations of machine-learning problems driven by practical applications. (An example is the development of recommendation systems, as described in Fig. 4.) One major trend driving this expansion is a growing concern with the environment in which a machine-learning algorithm operates. The word 「environment」 here refers in part to the computing architecture; whereas a classical machine-learning system involved a single program running on a single machine, it is now common for machine-learning systems to be deployed in architectures that include many thousands or ten of thousands of processors,such that communication constraints and issues of parallelism and distributed processing take center stage. Indeed, as depicted in Fig. 5, machine-learning systems are increasingly taking the form of complex collections of software that run on large-scale parallel and distributed computing platforms and providearange of algorithms and services to data analysts.
機器學習的領域相當年輕,以至於它仍在迅速擴充套件,通常是通過發明由實際應用驅動的機器學習問題的新形式化。(一個例子是推薦系統的開發,如圖4所述)推動這種擴充套件的一個主要趨勢是對機器學習演算法執行環境的日益關注。這裏的「環境」一詞在一定程度上指的是計算體系結構;而經典的機器學習系統涉及在一臺機器上執行的單個程式,而現在機器學習系統通常部署在包括成千上萬個處理器的體系結構中,因此,通訊約束、並行性和分佈式處理問題佔據了中心地位。實際上,如圖5所示,機器學習系統正越來越多地採取複雜的軟體集合的形式,這些軟體在大規模並行和分佈式計算平臺上執行,併爲數據分析師提供各種演算法和服務。
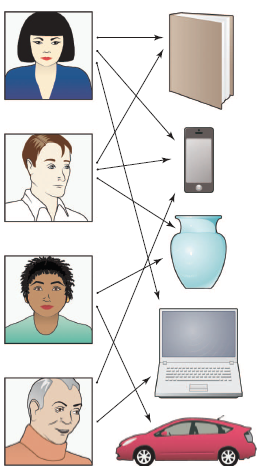
Fig. 4. Recommendation systems. A recommendation system is a machine-learning system that is based on data that indicate links between a set of a users (e.g., people) and a set of items (e.g., products). A link between a user and a product means that the user has indicated an interest in the product in some fashion (perhaps by purchasing that item in the past).The machine-learning problem is to suggest other items to a given user that he or she may also be interested in, based on the data across all users.
圖4。推薦系統。推薦系統是一種機器學習系統,它基於一組使用者(例如人)和一組專案(例如產品)之間的聯繫的數據。使用者和產品之間的鏈接意味着使用者已經以某種方式表示對產品感興趣(可能是通過過去購買該產品)。機器學習問題是根據所有使用者的數據向給定使用者推薦他或她可能也感興趣的其他商品。
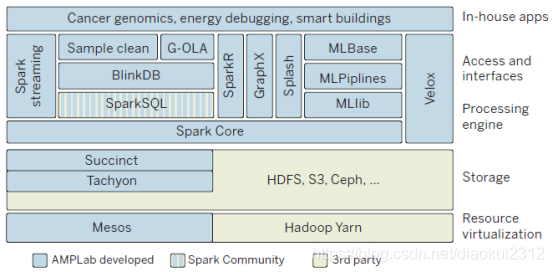
Fig. 5. Data analytics stack. Scalable machine-learning systems are layered architectures that are built on parallel and distributed computing platforms. The architecture depicted here—an opensource data analysis stack developed in the Algorithms, Machines and People (AMP) Laboratory at the University of California, Berkeley—includes layers that interface to underlying operating systems; layers that provide distributed storage, data management, and processing; and layers that provide core machine-learning competencies such as streaming, subsampling, pipelines, graph processing, and model serving.
圖5。數據分析堆疊。可伸縮機器學習系統是建立在並行和分佈式計算平臺上的分層體系結構。這裏描述的體系結構是由加州大學伯克利分校的演算法、機器和人員(AMP)實驗室開發的一個開源數據分析堆疊,包括與底層操作系統介面的層;提供分佈式儲存、數據管理和處理的層;以及提供核心機器學習能力的層,如流式處理、子採樣、管道、圖形處理和模型服務。
The word 「environment」 also refers to the source of the data, which ranges from a set of people who may have privacy or ownership concerns, to the analyst or decision-maker who may have certain requirements on a machine-learning system (for example, that its output be visualizable), and to the social, legal, or political framework surrounding the deployment of a system. The environment also may include other machinelearning systems or other agents, and the overall collection of systems may be cooperative or adversarial. Broadly speaking, environments provide various resources to a learning algorithm and place constraints on those resources. Increasingly, machine-learning researchers are formalizing theserelationships, aiming to design algorithms that are provably effective in various environments and explicitly allow users to express and control trade-offs among resources.
「環境」一詞也指數據的來源,從一組可能有隱私或所有權顧慮的人,到可能對機器學習系統有某些要求(例如,其輸出是視覺化的)的分析員或決策者,以及周圍的社會、法律或政治框架系統的部署。環境還可能包括其他機器學習系統或其他代理,系統的總體集合可以是共同作業的或是敵對的。廣義地說,環境爲學習演算法提供各種資源,並對這些資源施加限制。越來越多的機器學習研究人員正將這些關係形式化,旨在設計在各種環境下有效的演算法,並明確允許使用者表達和控制資源之間的權衡。
As an example of resource constraints, let us suppose that the data are provided by a set of individuals who wish to retain a degree of privacy. Privacy can be formalized via the notion of 「differential privacy,」 which defines a probabilistic channel between the data and the outside world such that an observer of the output of the channel cannot infer reliably whether particular individuals have supplied data or not . Classical applications of differential privacy have involved insuring that queries (e.g., 「what is the maximum balance across a set of accounts?」) to a privatized database return an answer that is close to that returned on the nonprivate data. Recent research has brought differential privacy into contact with machine learning, where queries involve predictions or other inferential assertions (e.g., 「given the data I’ve seen so far, what is the probability that a new transaction is fraudulent?」). Placing the overall design of a privacy-enhancing machine-learning system within a decision-theoretic framework provides users with a tuning knob wherebytheycanchoose a desired level of privacy that takes into account the kinds of questions that will be asked of the data and their own personal utility for the answers. For example, a person may be willing to reveal most of their genome in the context of research on a disease that runs in their family but may ask for more stringent protection if information about their genome is being used to set insurance rates.
作爲資源限制的一個例子,我們假設數據是由一組希望保留一定程度隱私的個人提供的。隱私可以通過「差異隱私」的概念正式化,它定義了數據和外部世界之間的一個概率通道,這樣通道輸出的觀察者就無法可靠地推斷特定的個人是否提供了數據。差異隱私的經典應用包括確保查詢(例如,「一組帳戶的最大餘額是多少?」?)返回一個接近非私有數據返回的答案。最近的研究將差異隱私與機器學習聯繫起來,在機器學習中,查詢涉及預測或其他推斷斷言(例如,「根據我目前看到的數據,新交易欺詐的概率有多大?」). 將隱私增強機器學習系統的總體設計放在決策理論框架內,爲使用者提供了一個調節旋鈕,使用者可以通過該旋鈕選擇所需的隱私級別,該級別考慮到將要對數據提出的各種問題以及他們自己的個人效用來獲得答案。例如,一個人可能願意在研究其家族遺傳疾病的背景下揭示其大部分基因組,但如果有關其基因組的資訊被用於制定保險費率,則可能會要求更嚴格的保護。
Communication is another resource that needs to be managed within the overall context of a distributed learning system. For example, data may be distributed across distinct physical locations because their size does not allow them to be aggregated at a single site or because of administrative boundaries. In sucha setting, we may wish to impose a bit rate communication constraint on the machine-learning algorithm. Solving the design problem under such a constraint will generally show how the performance of the learning system degrades under decrease in communication bandwidth, but it can also reveal how the performance improves as the number of distributed sites (e.g., machines or processors) increases, trading off these quantities against the amount of data . Much as in classical information theory, this line of research aims at fundamental lower bounds on achievable performance and specific algorithms that achieve those lower bounds.
通訊是另一種需要在分佈式學習系統的整體環境中進行管理的資源。例如,數據可能分佈在不同的物理位置,因爲它們的大小不允許在單個站點上聚合,或者由於管理邊界的原因。在這種情況下,我們可能希望對機器學習演算法施加位元率通訊約束。在這種約束下解決設計問題通常會顯示學習系統的效能在通訊頻寬減少的情況下是如何降低的,但它也可以揭示隨着分佈式站點(如機器或處理器)數量的增加,效能是如何提高的,將這些數量與數據量進行權衡。與經典資訊理論一樣,這一研究方向旨在研究可實現效能的基本下限以及實現這些下限的特定演算法。
A major goal of this general line of research is to bring the kinds of statisticalresources studied in machine learning (e.g., number of data points, dimension of a parameter, and complexity of a hypothesis class) into contact with the classical computational resources of time and space. Such a bridge is present in the 「probably approximately correct」 (PAC) learning framework, which studies the effect of adding a polynomial-time computation constraint on this relationship among error rates, training data size, and other parameters of the learning algorithm. Recent advances in this line of research include various lower bounds that establish fundamental gaps in performance achievable in certain machine-learning problems (e.g., sparse regression and sparse principal components analysis) via polynomial-time and exponential-time algorithms. The core of the problem, however, involves time-data tradeoffs that are far from the polynomial/exponential boundary. The large data sets that are increasingly the norm require algorithms whose time and space requirements are linear or sublinear in the problem size (number of data points or number of dimensions). Recent research focuses on methods such as subsampling, random projections, and algorithm weakening to achieve scalability while retaining statistical control. The ultimate goal is to be able to supply time and space budgets to machine-learning systems in addition to accuracy requirements, with the system finding an operating point that allows such requirements to be realized.
這一總體研究路線的一個主要目標是將機器學習中研究的統計資源(例如,數據點的數量、參數的維數和假設類的複雜性)與經典的時間和空間計算資源聯繫起來。這種橋樑存在於「可能近似正確」(PAC)學習框架中,該框架研究新增多項式時間計算約束對錯誤率、訓練數據大小和學習演算法其他參數之間關係的影響。這一研究領域的最新進展包括通過多項式時間和指數時間演算法在某些機器學習問題(例如稀疏迴歸和稀疏主成分分析)中建立效能的基本差距的各種下界。然而,問題的核心是時間數據的權衡,而這些權衡離多項式/指數邊界很遠。日益成爲範數的大數據集要求演算法的時間和空間要求在問題大小(數據點的數目或維數)上是線性或次線性的。最近的研究集中在諸如子抽樣、隨機投影和演算法弱化等方法上,以在保持統計控制的同時實現可伸縮性。最終目標是除了精度要求外,還能夠爲機器學習系統提供時間和空間預算,系統找到一個允許實現這些要求的操作點。
Opportunities and challenges
機遇與挑戰
Despite its practical and commercial successes, machine learning remains a young field with many underexplored research opportunities. Some of these opportunities can be seen by contrasting current machine learning approaches to the types of learning we observe in naturally occurring systems such as humans and other animals, organizations, economies, and biological evolution. For example, whereas most machinelearning algorithms are targeted to learn one specific function ordata model fromonesingle data source, humans clearly learn many different skills and types of knowledge, from years of diverse training experience, supervised and unsupervised, in a simple-to-more-difficult sequence (e.g., learning to crawl, then walk, then run). This has led some researchers to begin exploring the question of how to construct computer lifelong or never-ending learners that operate nonstop for years, learning thousands of interrelated skills or functions within an overall architecture that allows the system to improve its ability to learn one skill based on having learned another. Another aspect of the analogy to natural learning systems suggests the idea of team-based, mixed-initiative learning. For example, whereas current machinelearning systems typically operate in isolation to analyze the given data, people often work in teams to collect and analyze data (e.g., biologists have worked as teams to collect and analyze genomic data, bringing together diverse experiments and perspectives to make progress onthis difficult problem).Newmachine learning methods capable of working collaboratively with humans to jointly analyze complex data sets might bring together the abilities of machines to tease out subtle statistical regularities from massive data sets with the abilitiesof humans to drawon diverse background knowledge to generate plausible explanations and suggest new hypotheses. Many theoretical results inmachine learning apply to all learning systems, whether they are computer algorithms, animals, organizations, or natural evolution. As the field progresses, we may see machine-learning theory and algorithms increasingly providing models for understanding learning in neural systems, organizations, and biological evolution and see machine learning benefit from ongoing studies of these other types of learning systems.
儘管機器學習在實踐和商業上取得了成功,但它仍然是一個年輕的領域,有許多未被充分開發的研究機會。通過將當前機器學習方法與我們在自然發生的系統(如人類和其他動物、組織、經濟和生物進化)中觀察到的學習型別進行對比,可以看到其中一些機會。例如,雖然大多數機器學習演算法的目標是從一個單一的數據源學習一個特定的功能或數據模型,但人類顯然從多年的不同訓練經驗中學習了許多不同的技能和知識型別,不管是有監督的還是無監督的,都是以簡單到更困難的順序(例如,學習爬行,然後走,然後跑)。這使得一些研究人員開始探索如何構建計算機終身學習者或永無止境的學習者,這些學習者可以在一個整體架構中學習數千種相互關聯的技能或功能,使系統能夠在學習另一種技能的基礎上提高其學習一種技能的能力。與自然學習系統相類比的另一個方面提出了基於團隊的混合主動學習的思想。例如,當前的機器學習系統通常是孤立執行來分析給定的數據,而人們通常是以團隊的方式來收集和分析數據的(例如,生物學家以團隊的形式收集和分析基因組數據,新的機器學習方法能夠與人類合作,共同分析複雜的數據集,可能會將機器從海量數據中挑出細微統計規律的能力與人類利用不同的背景知識來產生合理的解釋並提出新的假設。機器學習的許多理論成果適用於所有的學習系統,無論是計算機演算法、動物、組織還是自然進化。隨着該領域的發展,我們可以看到機器學習理論和演算法越來越多地爲理解神經系統、組織和生物進化中的學習提供模型,並看到機器學習從這些其他型別學習系統的持續研究中受益。
As with any powerful technology, machine learning raises questions about which of its potential uses society should encourage and discourage. The push in recent years to collect new kinds of personal data, motivated by its economic value, leads to obvious privacy issues, as mentioned above. The increasing value of data also raises a second ethical issue: Who will have access to, and ownership of, online data, and who will reap its benefits? Currently, much data are collected by corporations for specific uses leading to improved profits, with little or no motive for data sharing. However, the potential benefits that society could realize, even from existing online data, would be considerable if those data were to be made available for public good.
與任何強大的技術一樣,機器學習提出了一個問題,即社會應該鼓勵和阻止它的哪些潛在用途。如前所述,近年來,受其經濟價值的推動,收集新型別個人數據的趨勢導致了明顯的隱私問題。數據價值的不斷增加也引發了第二個倫理問題:誰將有權存取和擁有線上數據,誰將從中獲益?目前,企業收集的大量數據用於特定用途,從而提高了利潤,很少或根本沒有分享數據的動機。然而,如果將這些數據用於公益事業,那麼即使從現有的線上數據中,社會能夠實現的潛在利益也將是相當可觀的。
To illustrate, consider one simple example of how society could benefit from data that is already online today by using this data to decrease the risk of global pandemic spread from infectious diseases. By combining location data from online sources (e.g., location data from cell phones, from credit-card transactions at retail outlets, and from security cameras inpublic places and private buildings) with online medical data (e.g., emergency room admissions), it would be feasible today to implement a simple system to telephone individuals immediately if a person they were in close contact with yesterday was just admitted to the emergency room with an infectious disease, alerting them to the symptoms they should watch for and precautions they should take. Here, there is clearly a tension and trade-off between personal privacy and public health, and society at large needs to make the decision on how to make this trade-off. The larger point of this example, however, is that, although the data are already online, we do not currently have the laws, customs, culture, or mechanisms to enable society to benefit from them, if it wishes to do so. In fact, much of these data are privately held and owned, even though they are data about each of us. Considerations such as these suggest that machine learning is likely to be one of the most transformative technologies of the 21st century. Although it is impossible to predict the future, it appears essential that society begin now to consider how to maximize its benefits.
爲了說明這一點,考慮一個簡單的例子,說明社會如何能夠從今天已經線上的數據中獲益,通過使用這些數據來降低傳染病在全球範圍內傳播的風險。通過將來自線上來源的位置數據(例如,來自手機的位置數據、零售店的信用卡交易數據、公共場所和私人建築的安全攝像頭的位置數據)與線上醫療數據(如急診室入院)相結合,今天,如果一個與他們有密切接觸的人剛剛因傳染病住進急診室,提醒他們應該注意的症狀和應該採取的預防措施,那麼在今天實施一個簡單的系統立即給個人打電話是可行的。在這裏,個人隱私和公共健康之間顯然存在着一種緊張和權衡,整個社會需要就如何進行這種權衡做出決定。然而,這個例子更重要的一點是,儘管數據已經線上,但我們目前還沒有法律、習俗、文化或機制 機製使社會能夠從中受益,如果社會願意的話。事實上,這些數據大多是私人持有和擁有的,儘管它們是關於我們每個人的數據。這些考慮表明,機器學習可能是21世紀最具變革性的技術之一。雖然不可能預測未來,但社會現在開始考慮如何使其利益最大化似乎至關重要。