【UNIX/Liux】標準I/O庫【Part 3】
本文是筆者拜讀《UNIX環境高階程式設計》第5章(標準I/O庫)的學習筆記。本文的主要內容包括記憶體流、第5章小結和習題。文中不僅包含書中的知識點,也包括筆者的理解。
記憶體流
記憶體流相當於記憶體緩衝區,即用FILE指針存取記憶體流時,存取的不是磁碟檔案,而是記憶體。所有的I/O都是通過在緩衝區與主記憶體之間傳送位元組來完成的。
建立記憶體流的函數有:
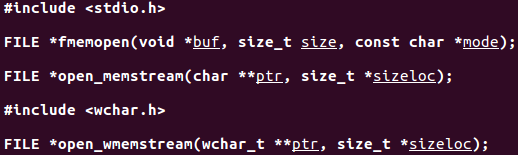
fmemopen函數允許呼叫者提供緩衝區用於記憶體流:buf參數指向緩衝區的開始位置,size參數指定了緩衝區的大小(單位是位元組)。如果buf爲空,fmemopen函數會分配size位元組數的緩衝區,當關閉流時,緩衝區被自動釋放。
fmemopen函數的mode參數和fopen函數的類似,但存在一些差別:
(1)以追加寫方式開啓記憶體流時,檔案當前位置設定爲緩衝區中的第一個NULL位元組,如果不存在NULL位元組,則檔案當前位置設定爲緩衝區結尾的後一個位元組。如果不是以追加寫方式開啓記憶體流時,當前位置設定爲緩衝區的開始位置。記憶體流不適合儲存二進制數據
(2)如果buf參數是一個NULL指針,開啓流進行只讀或只寫都沒有任何意義,因爲沒法找到緩衝區的地址。
(3)任何時候需要增加流緩衝區中數據量以及呼叫fclose、fflush、fseek、fseeko以及fsetpos時都會在當前位置寫入一個NULL位元組。
例:
#include <stdio.h>
#include <string.h>
#define N 36
int main() {
char buf[N];
memset(buf, 'a', N - 1);
buf[N - 1] = '\0';
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
FILE *fp = fmemopen(buf, N, "a");
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
fclose(fp);
fp = fmemopen(buf, N, "w+");
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
fprintf(fp, "hello world");
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
fflush(fp);
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
memset(buf, 'b', N - 1);
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
fprintf(fp, "hello world");
fseek(fp, 0, SEEK_SET);
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
memset(buf, 'c', N - 1);
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
fprintf(fp, "hello world");
fclose(fp);
fprintf(stdout, "%s, %ld\n", buf, (long)strlen(buf));
return 0;
}
執行結果:
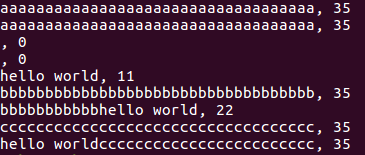
記憶體流有緩衝區
最後一個fclose(fp);爲什麼沒有自動新增NULL字元,fprintf(fp, "hello world");難道沒有增加流緩衝區中數據量?
用於建立記憶體流的其它兩個函數分別是open_memstream和open_wmemstream。
open_memstream函數建立的流是面向位元組的,open_wmemstream建立的流是面向寬位元組的,它們與fmemopen函數的不同在於:
(1)建立的流只能寫開啓。
(2)不能指定自己的緩衝區,但可以通過參數獲得緩衝區地址和大小。
(3)關閉流後需要自行釋放緩衝區。
(4)對流新增位元組會增加緩衝區大小。
小結
大多數UNIX應用程式都使用標準I/O庫。本章說明了該庫提供的很多函數以及某些實現細節和效率方面的考慮。標準I/O庫使用了緩衝技術,而它正是產生很多問題、引起許多混淆的部分。
習題
5.1
題目: 用setvbuf實現setbuf。
答:
#include <stdio.h>
void mySetBuf(FILE *fp, char *buf) {
if (!buf || fp == stderr) {
if (setvbuf(fp, buf, _IONBF, BUFSIZ) != 0) {
perror("set unbuffer error");
}
}
else if (fp == stdin || fp == stdout) {
if (setvbuf(fp, buf, _IOLBF, BUFSIZ) != 0) {
perror("set linebuffer error");
}
}
else {
if (setvbuf(fp, buf, _IOFBF, BUFSIZ) != 0) {
perror("set fullbuffer error");
}
}
}
5.2
題目: 使用每次一行I/O(fgets和fputs)複製檔案時,若MAXLINE很小,當複製的行超過該值時會出現什麼情況?對此進行解釋。
答: 使用fgets一次性最多隻能讀MAXLINE - 1個字元(如果能讀到的話,包含'\n')。如果輸入檔案中某行的數據過多,則需要呼叫多次fgets才能 纔能讀完。下次呼叫會從當前呼叫中讀到的最後一個字元的下一個位置開始讀。
5.3
題目:printf返回0值表示什麼?
答:printf的返回值是列印的字元數,如果什麼也沒列印出來,則返回值爲0。如:
printf("");
5.4
題目: 下面 下麪的程式碼在一些機器上執行正確,在另外一些機器上執行出錯,解釋問題所在。
#include <stdio.h>
int main(void) {
char c;
while ((c = getchar()) != EOF) {
putchar(c);
}
return 0;
}
答: EOF表示-1,當讀到檔案末尾時getchar會返回-1。getchar的返回值型別是int,程式中被轉換成了char。對有的編譯器來說char相當於signed char,此時-1就是-1,程式執行正確;而對有的編譯器來說char相當於unsigned char,此時-1被解釋爲一個很大的正數,程式執行錯誤。
int和unsigned int型別的數據比較時,會統一轉換爲unsigned int,因此-1和UINT_MAX「相等」,但對於char型別而言,情況似乎不同。
signed char a = -1;
unsigned char b = UCHAR_MAX;
printf("%d\n", a == b);
signed int ai = -1;
unsigned int bi = UINT_MAX;
printf("%d\n", ai == bi);
上面的程式會分別列印0和1。
5.5
題目: 對標準I/O流如何使用fsync函數?
答:
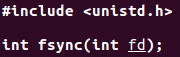
fsync作用於fd指定的檔案,等待往該檔案裡寫數據的實際寫磁碟操作結束。作用於標準輸出流是:
fsync(STDOUT_FILENO);
5.6
**題目:**下列程式中,列印的提示資訊沒有包含換行符,程式也沒有呼叫fflush函數,請解釋輸出提示資訊的原因是什麼?




**答:**在重新列印%符號前,父進程要等待子進程執行完畢,子進程執行完命令後會自帶一個'\n'符。
5.7
**題目:**基於BSD系統提供了funopen的函數呼叫使我們可以攔截讀、寫、定位以及關閉一個流的呼叫。使用這個函數爲FreeBSD和Mac OS X實現fmemopen。
不會。。。。筆者用的是Linux系統。