主題挖掘LSA方法與LDA對比實驗
主題挖掘LSA方法與LDA對比實驗
實驗簡介
本實驗或者說案例,是使用Pycharm編寫程式碼,對同一組新聞數據集進行新聞主題挖掘,來訓練兩個不同的NLP模型,並提供訓練集對訓練結果進行測試,並量化。隨後通過視覺化方法對比兩組實驗結果。(爲了保留實驗過程以及實現結果的視覺化,保留了實驗生成的日誌文件和某次實驗結果的參考圖)
首先,該實驗數據集爲爬取到的新聞主題的數據集,大約包含22000條content資訊可以供模型訓練使用,但由於數據集來自爬蟲爬取的含html標籤形式的txt檔案,需要進行數據清洗來提取新聞內容。簡略的實驗流程描述如下:在清洗過數據集之後,對數據集進行分詞和詞性標註(該過程的耗時較長)。隨後通過分詞後的數據構建詞袋模型(也就是語料庫,包含詞典,TF-IDF矩陣等資訊)。構建完畢後,人爲給定一個挖掘的主題個數後,分別使用剛纔構建好的語料庫去訓練LSA模型和LDA模型。訓練完畢後,儲存兩種模型並準備帶入到測試集中檢視預測效果。隨後,用同樣的預處理方法提取測試集的語料,並將測試集語料帶入到兩種不同的模型中檢視結果,通過視覺化方法進行對比,得到比較明顯的實驗結果。
實驗全程的每一個子過程均記錄了起止時間,並列印到了日誌文件log.txt中用於對比和檢驗試驗過程的耗時情況。
實驗環境
軟體環境
Windows 10操作系統,Pycharm IDE環境。
硬體環境
12執行緒CPU,16G記憶體,6G視訊記憶體
第三方庫的使用
- Jieba函數庫(用於分詞和詞性標註與過濾)
- Bs4函數庫(用於清洗’lxml’標籤)
- Gensim函數庫(用於詞袋語料庫預處理以及模型的訓練)
- Tarfile函數庫(用於解壓數據集檔案)
- Os函數庫(用於路徑分析和檔案操作以及日誌操作)
- Matplotlib函數庫(用於數據視覺化過程便於對比實驗結果)
- Time函數庫(用於記錄每一步子過程的時間節點)
實驗目標
對比LSA模型和LDA模型挖掘新聞主題的效果,評價兩種模型的優勢與缺點。效果評價主要從以下幾個方面進行:模型訓練時間,模型預測準確度,模型主題之間的相關度等。將兩個模型的訓練結果和預測結果都表示出來,並進行對比,並記錄分析,是該實驗的主要目標。
實驗過程
實驗的數據集的原始形式是.tar.gz格式的壓縮檔案,包含多個被切割的txt文件。首先需要對其進行解壓縮。記錄壓縮所消耗的時間。然後將解壓之後的所有content綜合起來準備進行清洗。記錄數據合併的時間消耗。而這個數據集的數據主要來自網路爬蟲的爬取結果,所以txt中包含大量的冗餘資訊,在解壓和合併之後,首先使用bs4.BeautifulSoup函數庫將html標籤和無關數據過濾掉,僅提取出我們想要使用的content標籤當中的新聞內容,同時記錄下數據清洗所消耗的時間。
數據清洗過後,要開始構建單詞文字矩陣了,首先需要把大段的文字資訊進行分詞,並對詞性進行標註,爲的是過濾掉無關的連線詞和空白content中的無關資訊。該過程使用到了Jieba函數庫的posseg子庫,記錄下分詞和詞性標註開始的時間和結束時間。
標註結束後使用詞袋模型預處理常式,對分好詞的數據集進行處理,首先構建詞典,記錄下這一過程起止時間。再緊接着構建語料庫,這是爲了訓練模型是能夠參照着無權的語料數據(LDA隨機抽樣目標),同樣記錄下起止時間來計算消耗。然後爲了綜合權重資訊,我們使用TF-IDF來表示綜合重要程度(同時體現一個文字中某單詞出現次數的佔比和含有某單詞的語料佔全部文字的比例),也記錄下這個過程的時間消耗。
首先,我人爲的(主觀可變參數 - num_topics = 10)指定了10個主題個數進行挖掘。將預處理的結果,應用於模型的訓練當中,分別訓練LSA和LDA模型,並列印出訓練的結果,結果呈現爲主題序號和主題關鍵字的鍵值對形式。可以通過觀察這個過程結果。來觀察有沒有很好的避免一詞多義和多詞一義。在這個過程中記錄下來兩個模型的訓練消耗時長,作爲其中一個關鍵參數進行對比。
最後通過一組測試及樣本進行測試,首先也是對測試機進行語料的預處理,然後作爲預測樣本帶入到兩個模型中去,分別得到兩個模型,對該樣本的預測結果。表示爲10個主題的相似度鍵值對結果。將預測結果進行歸一化和標準化後,用matplotlib視覺化的方法將數據呈現出來進行比較分析。
實驗程式碼
函數庫參照部分:
# Author:JinyuZ1996
# Creation date:2020/7/25 20:03
# -*- coding: utf-8 -*-
import os
import tarfile
import matplotlib.pyplot as plt
import jieba.posseg as pseg
import time as t
# 使用jieba第三方類庫對文字進行切割(中文分詞類庫),但是我們接下來要使用的是posseg的cut方法(大坑)
from bs4 import BeautifulSoup
from gensim import corpora, models
#踩坑,在使用LSA的時候必須指明包內呼叫的是lsimodel,而網上大多數博主沒說或者說之前的寫法可以用
import gensim.models.lsimodel as lsi
函數定義部分:(註釋詳細)
# 函數定義部分
# 數據集分詞方法:將輸入的文字句子根據詞性標註做分詞
# (參數是:從數據集或者測試集中提取的文字句子,爲標準字串型別)
def cut_word(text):
word_type = ['z', 'vn', 'v', 't', 'nz', 'nr', 'ns', 'n', 'l', 'i', 'j', 'an', 'a'] # 定義各種不同的詞性規則
words = pseg.cut(text) # 在這裏踩了個大坑
# 使用jieba中定義的cut方法來進行中文分詞,這裏cut方法通過查庫,得知是精準模式,它會把文字精確的切分開,不存在冗餘單詞
cut_result = [word_cut.word for word_cut in words if word_cut.flag in word_type] # 這是一個地道的寫法,可以避免主觀上知道被分成了多少詞項
return cut_result # 返回符合規則的分詞結果
# 文字預處理方法:如果是訓練階段,返回詞典、TF-IDF物件和TF-IDF向量空間數據;如果是預測階段,返回TF-IDF向量空間數據
# (參數是:詞項表——列表型數據;TF_IDF模型物件——預設值是None;標誌位,標誌現在是什麼過程,訓練還是測試)
def text_pre(words_list, tfidf_object=None, training=True):
# 分詞列錶轉字典
t_dic_start = t.time()
dic = corpora.Dictionary(words_list) # 將分好詞的詞項錶轉換爲字典形式
t_dic_end = t.time()
if training:
print('訓練集詞典構建完畢.用了' + str(format(t_dic_end-t_dic_start,'.2f')) + '秒,構建模型語料庫開始......')
# 下面 下麪這三行曾經是爲了展示一下詞典模型的樣式
# print('{:-^50}'.format('測試展示詞典索引值與分詞表:'))
# for i, w in list(dic.items())[:20]: # 回圈讀出字典前20條的每個key和value,對應的是索引值和分詞
# print('索引值:%s -- 分詞:%s' % (i, w)) # 因爲數據量比較大這裏只是做個展示,讓大家看一下數據處理的步驟
else:
print('測試集字典構建完畢.')
# 構建完了詞典再來構建語料庫corpus,這裏的doc2bow方法是構建bow模型的內建方法
# 該模型忽略掉文字的語法和語序等要素,將其僅僅看作是若幹個詞彙的集合,文件中每個單詞的出現都是獨立的(也就是構成了原始的語料)
t_corpus_start = t.time()
corpus = [dic.doc2bow(words) for words in words_list] # 用於儲存語料庫的列表
t_corpus_end = t.time()
if training:
print('訓練集語料庫構建完畢.用了' + str(format(t_corpus_end-t_corpus_start,'.2f')) + '秒,構建模型TF—IDF開始......')
# 下面 下麪這兩局曾經用於測試檢視詞袋模型語料庫形式
# print('{:-^50}'.format('語料庫一維樣本展示:'))
# print(corpus[0]) # 展示語料庫的第一維
else:
print('測試集語料集合分析完畢.')
# TF-IDF轉換(首先判定是否爲訓練過程,如果是的話則使用語料庫進行權值矩陣的構建)
if training:
t_TFIDF_start = t.time()
tfidf = models.TfidfModel(corpus) # 建立TF-IDF模型物件,TF_IDF也是定義在gensim上的既有方法
corpus_tfidf = tfidf[corpus] # 得到TF-IDF向量稀疏矩陣
# 下面 下麪這兩句曾經用於測試檢視詞袋模型的樣子
# print('{:-^50}'.format('TF-IDF 模型一維展示:'))
# print(list(corpus_tfidf)[0]) # 展示第一維
t_TFIDF_end = t.time()
print('構建TF-IDF過程結束,用了'+str(format(t_TFIDF_end-t_TFIDF_start,'.2f'))+'秒.')
return dic, corpus_tfidf, tfidf
else:
return tfidf_object[corpus] # 如果試執行測試集的話不做處理tfidf_object=None
# 全形轉半形方法:用於數據及預處理環節,數據清洗使用
# (參數是:content標籤裡的原始文字)
def str_convert(content):
strs = []
for each_char in content: # 回圈讀取每個字元
code_num = ord(each_char) # 讀取字元的ASCII值或Unicode值
if code_num == 12288: # 全形空格直接轉換
code_num = 32
elif 65281 <= code_num <= 65374: # 全形字元(除空格)根據關係轉化
code_num -= 65248
strs.append(chr(code_num))
return ''.join(strs)
# 解析檔案內容數據預處理之前的簡單清洗
# (參數是:數據集檔案讀取過來的文字格式包含大量標籤格式和髒數據)
def data_parse(data):
#BeautifulSoup庫的作用就是幫助我們去提取網頁格式標籤內的資訊
raw_code = BeautifulSoup(data, 'lxml') # 建立BeautifulSoup物件
content_code = raw_code.find_all('content') # 從包含文字的程式碼塊中找到content標籤,將新聞資訊過濾出來
# 將每個content標籤中的文字提取出來之後,轉成半形str字串格式物件儲存返回一個字串list(過程中還進行了判空,清洗掉了數據庫髒數據)
content_list = [str_convert(each_content.text) for each_content in content_code if len(each_content) > 0]
return content_list
案例實現過程部分:(註釋詳細)
# 案例實現過程部分
# 建立日誌檔案用於記錄執行過程及結果
doc = open('log.txt','w')
# 解壓縮檔案過程(找了一個比較完整的讀取tar.gz格式壓縮檔案的步驟(之前找的全炸),建議收着)
print('解壓過程開始......')
print('解壓過程開始......',file=doc)
t_unzip_start = t.time()
if not os.path.exists('./news_data'): # 如果不存在數據目錄,則先解壓數據檔案(就是有沒有解壓的資料夾在)
with tarfile.open('news_data.tar.gz') as tar: # 開啓tar.gz壓縮包物件(有時包內部巢狀多層)
names = tar.getnames() # 獲得壓縮包內的每個檔案物件的名稱
for name in names: # 回圈讀出每個檔案
tar.extract(name, path='./') # 將檔案解壓到指定目錄
# 彙總所有內容(因爲通過觀察數據集在壓縮目錄中被分爲多個子檔案,個人粗略估計大概有22000+個content)
t_unzip_end = t.time()
print('解壓過程結束,用了'+str(format(t_unzip_end-t_unzip_start,'.2f'))+'秒,數據合併過程開始......')
print('解壓過程結束,用了'+str(format(t_unzip_end-t_unzip_start,'.2f'))+'秒,數據合併過程開始......',file=doc)
t_datamerg_start = t.time()
all_content = [] # 構建總列表,待會兒用於儲存所有檔案的文字內容
for root, dirs, files in os.walk('./news_data'): # os.walk()遊走方法,分別讀取遍歷目錄下的根目錄、子目錄和檔案列表
for file in files: # 回圈讀取每個檔案
file_name = os.path.join(root, file) # 將目錄路徑與檔名合併爲帶有完整路徑的檔名
with open(file_name, encoding='utf-8') as f: # 以只讀方式開啓檔案(預設就是隻讀)
data = f.read() # 讀取檔案內容
all_content.extend(data_parse(data)) # 從檔案內容中獲取文字,清洗數據並將結果追加到總列表
# 數據集分詞過程開始
t_datamerg_end = t.time()
print('數據合併過程結束,用了'+str(format(t_datamerg_end-t_datamerg_start,'.2f'))+'秒,分詞過程開始......')
print('數據合併過程結束,用了'+str(format(t_datamerg_end-t_datamerg_start,'.2f'))+'秒,分詞過程開始......',file=doc)
# 獲取分詞列表,用於儲存所有檔案的分詞結果(在all_content中獲得)
t_cutWord_start = t.time()
print("開始對數據集進行分詞和詞性標註(該過程比較耗時)......")
print("開始對數據集進行分詞和詞性標註(該過程比較耗時)......",file=doc)
words_list = [list(cut_word(each_content)) for each_content in all_content]
t_cutWord_end = t.time()
print("分詞過程完成,用了"+str(format(t_cutWord_end-t_cutWord_start,'.2f'))+'秒,開始構建詞典模型......')
t_wordwash_start = t.time()
dic, corpus_tfidf, tfidf = text_pre(words_list) # 有了數據,我們先對訓練集的文字進行預處理
num_topics = 10 # 主觀的設定主題個數(先設定10個測試)
t_wordWash_end = t.time()
print('詞袋預處理過程結束,'+str(format(t_wordWash_end-t_wordwash_start,'.2f'))+'秒,開始構建LDA主題模型......')
print('詞袋預處理過程結束,'+str(format(t_wordWash_end-t_wordwash_start,'.2f'))+'秒,開始構建LDA主題模型......',file=doc)
# 使用數據集分別訓練LDA和LSA兩種模型(分別記錄訓練時間用於結果比較)
t_lda_start = t.time()
lda = models.LdaModel(corpus_tfidf, id2word=dic, num_topics=num_topics) #通過LDA進行主題建模
t_lda_end = t.time()
print('LDA模型構建完畢,用了'+str(format(t_lda_end-t_lda_start,'.2f'))+'秒,開始構建LSA主題模型......')
print('LDA模型構建完畢,用了'+str(format(t_lda_end-t_lda_start,'.2f'))+'秒,開始構建LSA主題模型......',file=doc)
print('{:-^50}'.format('構建好的主題LDA:'))
print('{:-^50}'.format('構建好的主題LDA:'),file=doc)
print(lda.print_topics()) #列印所有LDA的主題
print(lda.print_topics(),file=doc)
t_lsa_start = t.time()
lsa = lsi.LsiModel(corpus_tfidf, id2word=dic, num_topics=num_topics) #通過LSA進行主題建模
t_lsa_end = t.time()
print('LSA模型構建完畢,用了'+str(format(t_lsa_end-t_lsa_start,'.2f'))+'秒.')
print('LSA模型構建完畢,用了'+str(format(t_lsa_end-t_lsa_start,'.2f'))+'秒.',file=doc)
print('{:-^50}'.format('構建好的主題LSA:'))
print('{:-^50}'.format('構建好的主題LSA:'),file=doc)
print(lsa.print_topics()) #列印所有LSA的主題
print(lsa.print_topics(),file=doc)
# 新數據集的主題模型預測
print('開始測試集過程,測試集檔案開啓......')
print('開始測試集過程,測試集檔案開啓......',file=doc)
with open('article.txt', encoding='utf-8') as f: # 開啓測試集的文字
text_new = f.read() # 讀取文字數據
text_content = data_parse(data) # 解析新的文字
words_list_new = cut_word(text_new) # 將文字分詞爲下一步預處理做準備
corpus_tfidf_new = text_pre([words_list_new], tfidf_object=tfidf, training=False) # 新文字數據集的預處理(注意把標誌位置false)
# LDA預測部分(使用訓練好的LDA模型去預測新聞主題)
# t_testLda_start = t.time()
corpus_lda_new = lda[corpus_tfidf_new] # 用訓練好的lda去獲取新的分詞詞袋列表(文件)的主題概率分佈
# t_testLda_end = t.time()
print('{:-^50}'.format('測試樣本LDA主題預測:'))
print('{:-^50}'.format('測試樣本LDA主題預測:'),file=doc)
pre_list = list(corpus_lda_new)
trans_list = sorted(pre_list[0],key = (lambda x:[x[1],x[0]]),reverse=True) #2020-08-05改進程式碼通過排序方式將最大概率的預測結果顯示在第一位
print(trans_list) #列印出排序好的話題序列預測結果
print(trans_list,file=doc)
# print('LDA模型對測試集數據預測完畢,用了'+str(format(t_testLda_end-t_testLda_start,'.2f'))+'秒.') #爲什麼不寫了呢,因爲我發現真的這個過程是很快的,快到.2f不是很好展示
print('LDA模型對測試集數據預測完畢.')
print('LDA模型對測試集數據預測完畢.',file=doc)
# LSA預測部分(使用訓練好的LSA模型去預測新聞主題)
# t_testLsa_start = t.time() #記錄LSA預測測實際的開始時間
corpus_lsa_new = lsa[corpus_tfidf_new] #用構建好的lsa去處理測試集語料庫
# t_testLsa_end = t.time() #記錄LSA預測結束的時間
print('{:-^50}'.format('測試樣本LSA主題預測:'))
print('{:-^50}'.format('測試樣本LSA主題預測:'),file=doc)
pre_list_lsa = list(corpus_lsa_new) #將訓練好的結果轉成List物件
trans_list_lsa = sorted(pre_list_lsa[0],key = (lambda x:[abs(x[1]),x[0]]),reverse=False) #對值得部分進行排序(排序的時候要使用絕對值形式排序)
print(trans_list_lsa) #列印出排序好的話題序列預測結果
print(trans_list_lsa,file=doc)
# print('LSA模型對測試集數據預測完畢,用了'+str(format(t_testLsa_end-t_testLsa_start,'.2f'))+'秒.') #爲什麼不寫了呢,因爲我發現真的這個過程是很快的,快到.2f不是很好展示
print('LSA模型對測試集數據預測完畢.')
print('LSA模型對測試集數據預測完畢.',file=doc)
# 圖形化展LSA的測試結果(柱狀圖)
id_lsa = [] #話題編號list(注意要與值一一對應)
val_lsa = [] #權重值的list
lsa_Outlist = trans_list_lsa #個人習慣再賦個新名字
for i in range(0,len(lsa_Outlist)): #該回圈用於將上方矩陣中的值轉移到兩個新的list當中用於結果的展示
id_lsa.append("tp-"+str(lsa_Outlist[i][0])) #將編號放入新的list中準備列印
val_lsa.append(float(format((1-10*abs(lsa_Outlist[i][1]))*10,'.3f'))) #將權重放入新的list,注意取絕對值並同時對數據進行歸一化方便展示
print(id_lsa) #測試列印序號序列
print(val_lsa) #測試列印權重序列
fig = plt.figure(figsize=(10, 5)) #設定表單大小
fig.canvas.set_window_title('Using LSA to predict Testing Set') #設定表單title
plt.title('Using LSA to predict Testing Set') #設定圖表的title
plt.xlabel('Predicted subject sequence number') #被預測的話題序號
plt.ylabel('Weight of prediction possibility') #被預測的話題可能性權重
# 我這裏只設置了九種顏色,要是後期同學們再增加新的話題個數的話就需要再增加顏色種類
plt.bar(range(len(val_lsa)),val_lsa,width=0.5,tick_label=id_lsa,color =['grey','gold','darkviolet','turquoise','red','green','blue','pink','tan'])
plt.show()
# 圖形化展示LDA測試結果(柱狀圖)
id_lda = [] #話題編號list(注意要與值一一對應)
val_lda = [] #權重值的list
lda_Outlist = trans_list
for i in range(0,len(lda_Outlist)): #該回圈用於將上方矩陣中的值轉移到兩個新的list當中用於結果的展示
id_lda.append("tp-"+str(trans_list[i][0])) #將編號放入新的list中準備列印
val_lda.append(float(format((trans_list[i][1])*10,'.3f'))) #將權重放入新的list,lda的數據好處理一些
print(id_lda) #測試列印序號序列
print(val_lda) #測試列印權重序列
# 曾經對lda嘗試過繪製餅圖,但是效果不是很好,但是保留這種寫法以後參考用。參數(值,標誌,顏色分類,自動轉化爲百分比形式,還可以設定陰影shadow=,或者設定凸顯某一部分explode=)
# plt.pie(x=value,labels=id_lda,colors=['C0', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9'],autopct='%1.1f%%')
# plt.axis('equal') #用'正'圓餅圖來視覺化預測結果
fig = plt.figure(figsize=(10, 5)) #設定表單大小
fig.canvas.set_window_title('Using LDA to predict Testing Set') #設定表單title
plt.title('Using LDA to predict Testing Set') #設定圖表的title
plt.xlabel('Predicted subject sequence number') #被預測的話題序號
plt.ylabel('Weight of prediction possibility') #被預測的話題可能性權重
# 我這裏只設置了九種顏色,要是後期同學們再增加新的話題個數的話就需要再增加顏色種類
plt.bar(range(len(val_lda)),val_lda,width=0.5,tick_label=id_lda,color =['grey','gold','darkviolet','turquoise','red','green','blue','pink','tan'])
plt.show()
#再比較一下二者花費時間的差距
lda_cost = t_lda_end-t_lda_start
lsa_cost = t_lsa_end-t_lsa_start
if lda_cost>lsa_cost:
print("LDA模型花費" + str(format(lda_cost, '.2f')) + '秒.\nLSA模型花費' + str(format(lsa_cost, '.2f')) + '秒.')
print("LDA模型花費" + str(format(lda_cost, '.2f')) + '秒.\nLSA模型花費' + str(format(lsa_cost, '.2f')) + '秒.', file=doc)
print("LDA模型比LSA模型要多花費" + str(format(lda_cost - lsa_cost, '.2f')) + '秒.')
print("LDA模型比LSA模型要多花費" + str(format(lda_cost - lsa_cost, '.2f')) + '秒.',file=doc)
else:
print("LDA模型花費" + str(format(lda_cost,'.2f')) + '秒.\nLSA模型花費' + str(format(lsa_cost,'.2f')) + '秒.')
print("LDA模型花費" + str(format(lda_cost, '.2f')) + '秒.\nLSA模型花費' + str(format(lsa_cost, '.2f')) + '秒.', file=doc)
print("LSA模型比LDA模型要多花費" + str(format(lsa_cost - lda_cost,'.2f')) + '秒.')
print("LSA模型比LDA模型要多花費" + str(format(lsa_cost - lda_cost, '.2f')) + '秒.',file=doc)
實驗結果分析
首先,根據某次實驗log.txt給出的結果和視覺化數據結果來進行觀察(事先已經進行了超過20次實驗,這裏取其中一次比較有代表性的試驗結果來分析):
從訓練結果來看,根據對log.txt當中LSA和LDA主題訓練結果的內容觀察分析可以得知,LSA明顯的在多個主題中都有着部分與體育相關的單詞,我們可以理解這種情況產生的原因,之前我在視訊中提到過關於新聞主題個數的問題,大約在22-30個左右的時候可以實現最佳粒度,但目前爲了儘快得到實驗結果和放大實驗效果,我們主觀的取num_topics = 10,來進行試驗。但事實上你可以清楚地發現,在LDA訓練結果中就有很高的區分度,即便目前僅僅只有10個話題,每個話題之間的關聯度也都很小,只是偶爾會出現個別相關聯單詞被分配到其他主題的情況,佔的權重也很小。所以當我們只觀測到訓練結果的時候,初步推測,LSA將會出現預測不準,或預測模糊的狀況,而相對的LDA應該能夠避免這種情況。
然後,從訓練時間來看,在我們目前規定的數據及規模和話題量爲10的實驗條件下,LSA在多次重複試驗過程中基本上都會比LDA慢2s左右。
最後讓我們看一看二者對測試集的預測結果,測試集是一則體育新聞,LDA精準的將其預測爲話題9,帶有比較高的權值,且所有話題集的相似度均以正數排列,幾乎不需要篩選返回值和歸一化,當然後期爲了在影象中方便展示進行了format,而LSA模型返回值鍵值對之間差距較大,相似度表達爲與主題偏離的程度,需要先取絕對值,在進行從小到大排序,並且由於我們先前分析的結果,多個話題之間保有較小的差距,所以可以看到多個話題(abs後)都有着比較小的偏差,預測結果相對LDA來說比較模糊,且後期數據處理較爲複雜。
只看log.txt已經不太直觀了,當我們對兩者返回值list進行歸一化展示後,我們會清楚地得到兩張圖表。
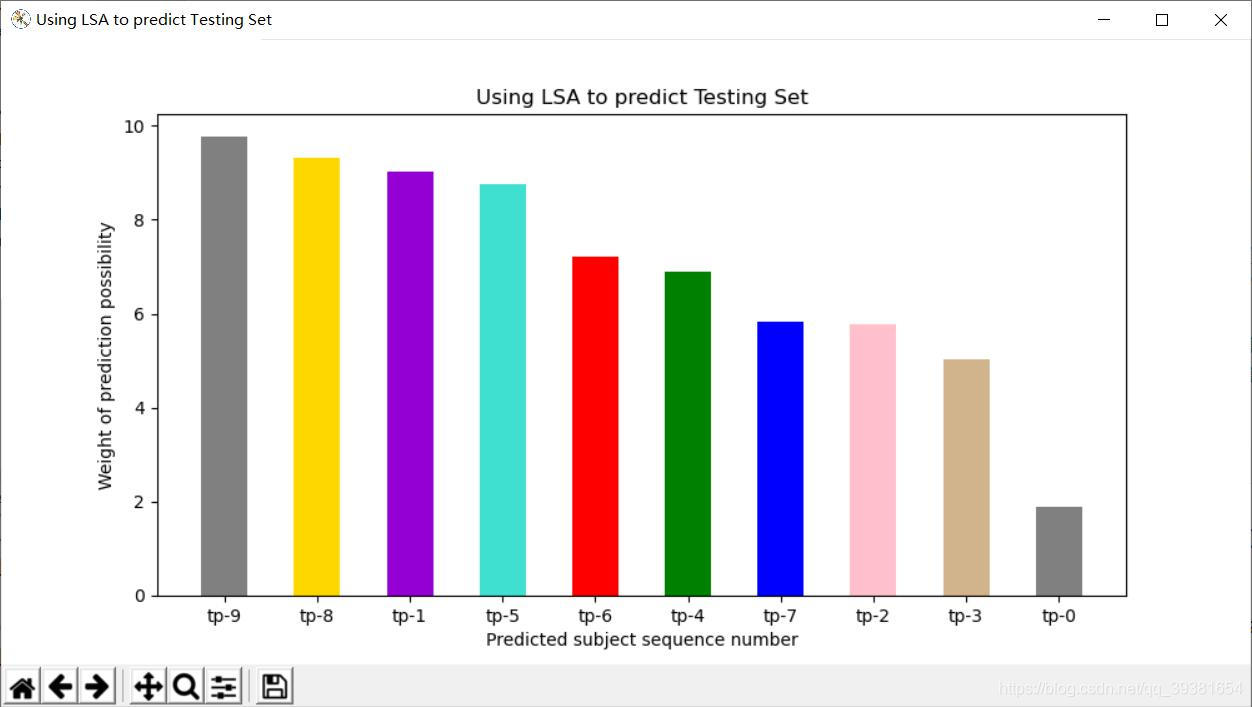
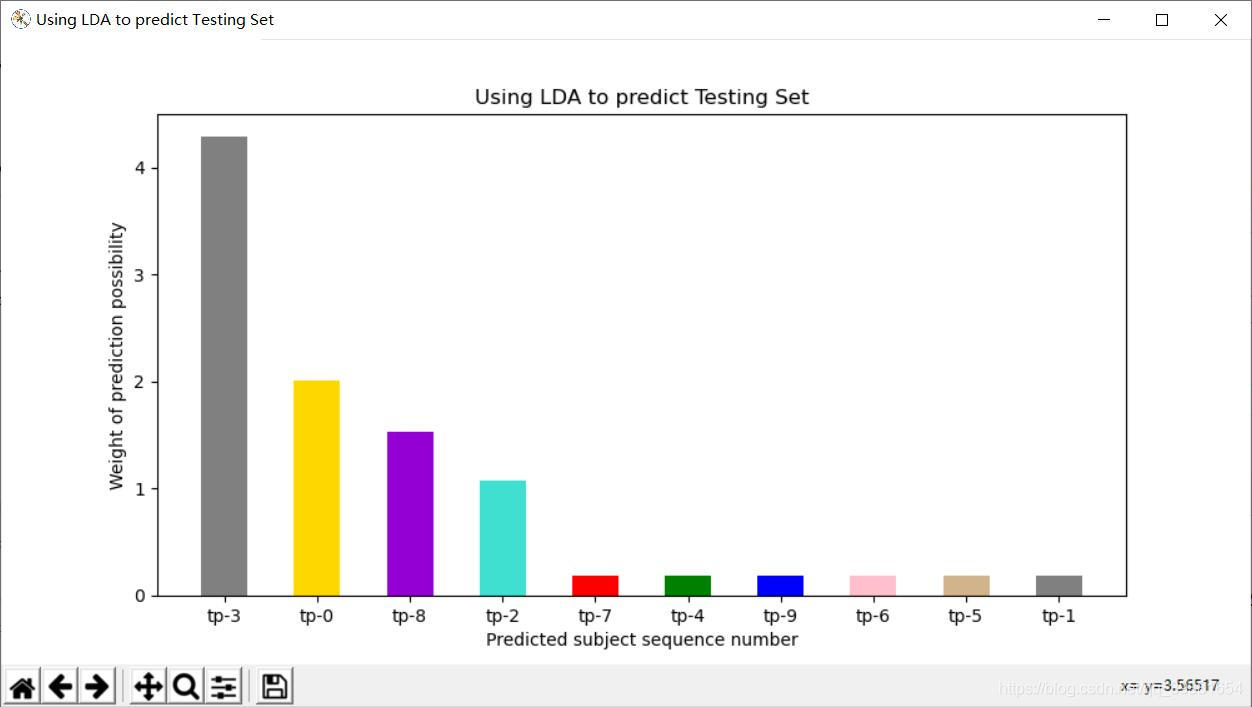
通過觀察,我們可以明顯的看到,LDA擁有更加清晰地預測反饋,不同的話題相似度之間有着明顯的差距,據此可以明確的定義其中某一話題(topic3)爲所預測話題的目標話題。而LSA的結果就比較模糊,話題9,8,1,5都有着比較高的相似度,雖然仍可以比較出9是最爲相似的話題,但是效果顯然不如LDA明顯。
事實上,還有一處區別是在實驗過程中發現的,那就是LDA每次實驗所生成的話題順序是不同的,有的時候話題3代表着體育,有的時候話題6代表着體育,但是都具有相同的預測精度。而LSA每次的預測結果幾乎都是相似的,影象也基本一致。這是因爲,LSA使用SVD奇異值分解,而LDA使用的是隨機抽樣的方法,由於隨機抽樣,所以每次產生的話題序列生成結果也不盡相同,這是非常正常的現象。
得出結論
通過實驗和多組資訊的對比,LDA與LSA相比在規定了話題個數的前提下,LDA的挖掘效果要更加突出和明顯,預測的精度相對更高,且LDA也抱有更小的時間消耗,LSA的預測結果就相對模糊。分析原因的話,我們也可以得知,在之前的學習過程中,我們知道LSA是通過SVD降維手段將原始相似度不高的高維矩陣對映到新的低維語意空間中來實現的,所以其每次的分解結果都是相近的,而且我們知道它可以解決多詞一義的問題,而解決不了一詞多義的問題,這也就是它在多個話題中包含多個相似單詞的重要原因之一。相對的來說LDA,使用MCMC中的Gibbs抽樣演算法實現隨機抽樣,於是它每次產生的訓練序列會有所不同,但是卻能保持相對較高的預測效果,同時也避免了一詞多義與多詞一義的問題,使得話題預測結果沒有歧義,單個話題預測相似度能夠明顯地優於其他多個話題。
實驗的不足
事實上能夠提出來的不足也馬上就能夠解決,只是寫報告的時候,完善實驗在時間上有些不太夠了。第一個可以改進的點,應該在log中列印多次重複試驗的所有日誌資訊,而不是僅保留最近一次試驗的日誌結果。第二個可以改進的點,該專門寫一個類或者函數,把訓練和測試LDA和LSA的步驟分別封裝起來,程式碼可讀性會相對更高。第三個可以改進的點,根據最近查資料和對庫的進一步學習才得知,語料庫是可以實現暫存的。而該實驗沒有很好地對分詞結果進行儲存,導致每次實驗都要重新進行分詞和詞性標註,導致實驗的時間成本變高。