Shell程式設計7_awk
目錄
awk不同於grep的文字搜尋與sed工具的文字處理,它更偏向於對文字的格式化處理輸出。
awk的適用場景
- 超大檔案處理
- 輸出格式化的文字報表
- 執行算數運算
- 執行字串操作等
一、語法及結構
Awk 語法格式如下圖所示:

1、開始塊(BEGIN BLOCK)
語法:
BEGIN{awk-commands}
開始塊就是awk程式啓動時執行的程式碼部分(在處理輸入流之前執行),並且在整個過程中只執行一次;
一般情況下,我們在開始塊中初始化一些變數。BEGIN是awk的關鍵字,因此必須要大寫。
【注:開始塊部分是可選,即你的awk程式可以沒有開始塊部分】
2、主體塊(Body Block)
語法:
/pattern/{awk-commands}
針對每一個輸入的行都會執行一次主體部分的命令,預設情況下,對於輸入的每一行,awk都會執行主體部分的命令,但是我們
可以使用/pattern/限制其在指定模式下。
3、結束塊(END BLOCK)
語法:
END{awk-commands}
結束塊是awk程式結束時執行的程式碼(在處理完輸入流之後執行),END也是awk的關鍵字,必須大寫,與開始塊類似,結束塊
也是可選的。
二、awk命令詳解
1、awk print輸出
print item1,item2...
awk命令格式解析,其常用命令選項:
- -F: 指定分隔符,可省略(預設空格或Tab位)
- -f: 呼叫awk指令碼進行處理
- -v: 呼叫外部shell變數
column,格式化列顯示
- -c 字元數 指定顯示的列寬
- -s「 分隔符 「 使用 -t 選項時,指定分隔符(允許指定多個分隔符)
- -t 判斷輸入行的列數來建立一個表。分隔符是使用在-s中指定的字元。如果沒有指定分隔符,預設是空格
- -x 更改排列順序(左→右)。預設的順序爲(上→下)
[root@master ~]# awk -F: '{print $1,$NF}' /etc/passwd|column -t
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
awk print輸出特點:
1.各欄位之間逗號隔開,輸出時以空白字元分隔;
2.輸出的欄位可以爲字串或數值,當前記錄的欄位(如$1)、變數或 awk 的表達式;數值先會轉換成字串然後輸出;
3.print 命令後面的 item 可以省略,此時其功能相當於print $0,如果想輸出空白,可以使用print "";
2、awk printf 輸出
printf 命令的使用格式:
printf <format> item1,item2...
要點:
1.其與 print 命令最大區別,printf 需要指定 format,format 必須給出;
2.format 用於指定後面的每個 item 輸出格式;
3.printf 語句不會自動列印換行字元\n。
format 格式的指示符都以 % 開頭,後跟一個字元:
%c:顯示ascall碼
%d:%i:十進制整數
%e,%E:科學計數法
%f:浮點數
%s:字串
%u:無符號整數
%%:顯示%自身
修飾符:
#[.#]:第一個#控制顯示的寬度:第二個#表示小數點後的精度:
%3.1f
-:左對齊
+:顯示陣列符號
例如:
[root123@localhost /]$ awk -F: '{printf "Username:%-15s,Uid:%d\n",$1,$3}' /etc/passwd
Username:root ,Uid:0
Username:bin ,Uid:1
Username:daemon ,Uid:2
Username:adm ,Uid:3
Username:lp ,Uid:4
Username:sync ,Uid:5
Username:shutdown ,Uid:6
Username:halt ,Uid:7
Username:mail ,Uid:8
Username:operator ,Uid:11
Username:games ,Uid:12
Username:ftp ,Uid:14
Username:nobody ,Uid:99
Username:systemd-network,Uid:192
Username:dbus ,Uid:81
三、awk變數
1、記錄變數
- IFS(input field separator),輸入欄位分隔符(預設空白)
- OFS(output field separator),輸出欄位分隔符
- RS(Record separator):輸入文字換行符(預設回車)
- ORS:輸出文字換行符
2、數據變數
- NR:the number of input records,awk 命令所處理的檔案的行數,如果有多個檔案,這個數目會將處理的多個檔案計數
- NF:number of field,當前記錄的 field 個數
// $NF獲取最大位置的變數
[root123@localhost /]$ awk -F ":" '{print $NF}' /etc/passwd
/bin/bash
/sbin/nologin
// NF代表field個數
[root123@localhost /]$ awk -F ":" '{print NF}' /etc/passwd
7
7
3、自定義變數
-v var=value
變數名稱區分大小寫
// 注意-v是小寫
[root@master ~]# awk -v test="abc" 'BEGIN{print test}'
abc
[root@master ~]# awk 'BEGIN{var="name";print var}'
name
四、操作範例
1、算術運算:+,-,*,/,^,%。
例如:
[root@master ~]# awk 'BEGIN{a=5;b=3;print "a + b =",a+b}'
a + b = 8
2、字串操作
無符號操作符,表示字串連線,例如:
[root@master ~]# awk 'BEGIN { str1="Hello,"; str2="World"; str3 = str1 str2; print str3 }'
Hello,World
3、賦值操作:=,+=,-=,*=,/=,%=,^=
例如:
[root@master ~]# awk 'BEGIN{a=5;b=6;if(a == b) print "a == b";else print "a!=b"}'
a!=b
[root@master ~]# awk -F: '{sum+=$3}END{print sum}' /etc/passwd
72349
4、模式匹配
~:是否匹配
!~:是否不匹配
[root@master ~]# awk -F: '$1~"root"{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
5、邏輯操作:&& 、 || 、 !
例如:
[root@master ~]# awk 'BEGIN{a=6;if(a > 0 && a <= 6) print "true";else print "false"}'
true
6、條件表達式(三元運算)
- selection?if-true-expresssion:if-false-expression
[root@master ~]# awk -F: '{$3>=100?usertype="common user":usertype="sysadmin";printf "%15s:%s\n",$1,usertype}' /etc/passwd
root:sysadmin
bin:sysadmin
daemon:sysadmin
7、正則匹配Pattern
- empty:空模式,匹配每一行
- /regular expression/:僅處理能被此處模式匹配到的行,
範例:從passwd中列印以root開頭的行
awk 'BEGIN{FS=":"}/^root/{print $0}' /etc/passwd
執行結果

範例:列印passwd中uid<50的資訊
awk 'BEGIN{FS=":"}$3<50{print $0}' /etc/passwd
五、範例練習
(1)/tmp目錄下有幾個檔案,ls返回部分結果如下:
amp-content-display-portlet-1.0.1-20120829.081044-11.war
amp-facebook-post-editor-1.0.1-20120829.084615-1.war
amp-services-portlet-1.0.2-20120829.085733-3.war
要求把版本號及後面的數位都給遮蔽了(即其中粉紅色部分),只匹配檔名。
分析:這其實是一個正則匹配的問題,很多工具都可以實現,這裏給出一種解法:
ls | awk '/^amp/{sub(/-[0-9].*-[0-9]*/,"");print}' $*
sub函數對指定的正則表達式進行替換,省略了第三個參數,即對每一行$0進行匹配。
正則匹配:-[0-9].*匹配 -1.0.2-20120829.085733;-[0-9]*匹配-11;
(2)統計/etc/fstab 檔案中每個檔案系統型別出現的次數
awk '$1 != "#" && !/^$/{filetype[$3]++}END{for( i in filetype){print i,filetype[i]}}' /etc/fstab
// 執行範例
[root123@localhost ~]$ awk '$1 != "#" && !/^$/{filetype[$3]++}END{for( i in filetype){print i,filetype[i]}}' /etc/fstab
swap 1
ext4 1
xfs 2
[root123@localhost ~]$
其中$1 != "#"去除註釋行,!/^$/去除空行。awk中陣列的下標不僅可以爲"數位",還可以爲"任意字串",但陣列本質上還是是關聯陣列。陣列學習詳細鏈接
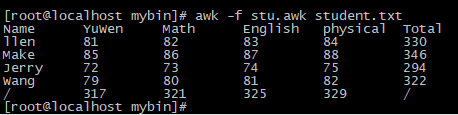
(3)計算學生成擊的橫向成績和縱向成績總和
給定一組數據student.txt:要求給每個數據加上對應的課程名稱,並分別計算該學生成績的總成績以及該科目的總成績。
Allen 81 82 83 84
Make 85 86 87 88
Jerry 72 73 74 75
Wang 79 80 81 82
Shell指令碼範例:建立stu.awk檔案
BEGIN{
printf "%-10s%-10s%-10s%-10s%-10s%-10s\n",
"Name","YuWen","Math","English","physical","Total"
}
{
# 計算總成績
total=$2+$3+$4+$5
# 分科計算各科成績
yuwen_sum+=$2
math_sum+=$3
english_sum+=$4
physical_sum+=$5
printf "%-10s%-10d%-10d%-10d%-10d%-10d\n", $1,$2,$3,$4,$5,total
}
END{
printf "%-10s%-10d%-10d%-10d%-10d%-10s\n", "/",yuwen_sum,math_sum,english_sum,physical_sum,"/"
}
執行範例:awk -f stu.awk student.txt