LTR問題 position debias方法
LTR中的一個常見問題就是position debias,在面試諸如推薦、搜尋這樣的職位的時候很有可能被問到。
所謂position bias就是指,當給使用者展現搜尋和推薦結果時,使用者傾向於點選第一個item的這個行爲裏面,既有item的品質的影響,還有item排在第一個這個事件本身的影響。所以直接從原始log的數據中學習排序模型的學到的結果是有偏的。那麼解決這種bias的方法主要有一下幾種:
1、樣本安排的trick:
a. 正樣本後的樣本都不算到訓練樣本中,如下圖所示。這樣就不會計算正樣本後的樣本,因爲這些樣本很可能沒有被看到
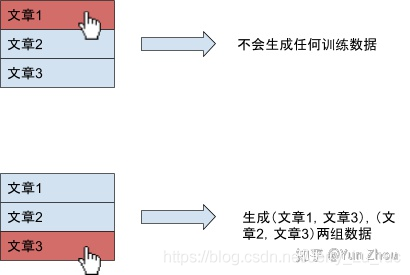
(這個方法的缺點是使用者點選第一個展示就不會產生樣本,那麼每次訓練總是傾向於修改之前的結果)-> 改進:正樣本後算有限個樣本。
b. 分一部分流量展示topK隨機排序,將這部分無偏集加入訓練 (但是這個流量小的話數據不多,大的話可能會影響一部分人的體驗)
2、特徵&模型設計:
a. 將位置資訊作爲特徵加入到模型特徵中 (缺點是預測時沒有位置資訊,使用缺失值代替的話就造成了訓練和預測的不一致,covariate shift)
b. 點選模型校準:通過各種方法得到使用者是否看到了位置K(K越大這個概率越小)的概率,然後用1/P(K)給主模型的訓練樣本進行加權。可以是對使用者歷史瀏覽記錄的統計,也可以通過向使用者展示一些隨機排序的item然後統計看到各個位置的概率得到看到位置K的概率。這個看到位置K的概率是user_id的函數,不同使用者的概率分佈不同歐諾個
c. YouTube的一篇文章:https://zhuanlan.zhihu.com/p/86627202
用一個shallow tower 獨立於主模型之外對position建模,然後作爲偏置項加到logit裡來算損失。預測的時候處理爲missing。基本思想是訓練的時候由shallow tower來糾偏,認爲這樣主模型就能學到無偏結果,區別於a中直接將位置作爲特徵加入到主模型中