什麼是分佈式?什麼是CAP?不看你就後悔去吧
一、分佈式鎖
在單機場景下,可以使用語言的內建鎖來實現進程同步。但是在分佈式場景下,需要同步的進程可能位於不同的節點上,那麼就需要使用分佈式鎖。
阻塞鎖通常使用互斥量來實現:
- 互斥量爲 0 表示有其它進程在使用鎖,此時處於鎖定狀態;
- 互斥量爲 1 表示未鎖定狀態。
1 和 0 可以用一個整型值表示,也可以用某個數據是否存在表示。
數據庫的唯一索引
獲得鎖時向表中插入一條記錄,釋放鎖時刪除這條記錄。唯一索引可以保證該記錄只被插入一次,那麼就可以用這個記錄是否存在來判斷是否處於鎖定狀態。
存在以下幾個問題:
- 鎖沒有失效時間,解鎖失敗的話其它進程無法再獲得該鎖;
- 只能是非阻塞鎖,插入失敗直接就報錯了,無法重試;
- 不可重入,已經獲得鎖的進程也必須重新獲取鎖。
Redis 的 SETNX 指令
使用 SETNX(set if not exist)指令插入一個鍵值對,如果 Key 已經存在,那麼會返回 False,否則插入成功並返回 True。
SETNX 指令和數據庫的唯一索引類似,保證了只存在一個 Key 的鍵值對,那麼可以用一個 Key 的鍵值對是否存在來判斷是否存於鎖定狀態。
EXPIRE 指令可以爲一個鍵值對設定一個過期時間,從而避免了數據庫唯一索引實現方式中釋放鎖失敗的問題。
Redis 的 RedLock 演算法
使用了多個 Redis 範例來實現分佈式鎖,這是爲了保證在發生單點故障時仍然可用。
- 嘗試從 N 個互相獨立 Redis 範例獲取鎖;
- 計算獲取鎖消耗的時間,只有時間小於鎖的過期時間,並且從大多數(N / 2 + 1)範例上獲取了鎖,才認爲獲取鎖成功;
- 如果獲取鎖失敗,就到每個範例上釋放鎖。
Zookeeper 的有序節點
1. Zookeeper 抽象模型
Zookeeper 提供了一種樹形結構的名稱空間,/app1/p_1 節點的父節點爲 /app1。

2. 節點型別
- 永久節點:不會因爲對談結束或者超時而消失;
- 臨時節點:如果對談結束或者超時就會消失;
- 有序節點:會在節點名的後面加一個數字後綴,並且是有序的,例如生成的有序節點爲 /lock/node-0000000000,它的下一個有序節點則爲 /lock/node-0000000001,以此類推。
3. 監聽器
爲一個節點註冊監聽器,在節點狀態發生改變時,會給用戶端發送訊息。
4. 分佈式鎖實現
- 建立一個鎖目錄 /lock;
- 當一個用戶端需要獲取鎖時,在 /lock 下建立臨時的且有序的子節點;
- 用戶端獲取 /lock 下的子節點列表,判斷自己建立的子節點是否爲當前子節點列表中序號最小的子節點,如果是則認爲獲得鎖;否則監聽自己的前一個子節點,獲得子節點的變更通知後重復此步驟直至獲得鎖;
- 執行業務程式碼,完成後,刪除對應的子節點。
5. 對談超時
如果一個已經獲得鎖的對談超時了,因爲建立的是臨時節點,所以該對談對應的臨時節點會被刪除,其它對談就可以獲得鎖了。可以看到,這種實現方式不會出現數據庫的唯一索引實現方式釋放鎖失敗的問題。
6. 羊羣效應
一個節點未獲得鎖,只需要監聽自己的前一個子節點,這是因爲如果監聽所有的子節點,那麼任意一個子節點狀態改變,其它所有子節點都會收到通知(羊羣效應,一隻羊動起來,其它羊也會一鬨而上),而我們只希望它的後一個子節點收到通知。
二、分佈式事務
指事務的操作位於不同的節點上,需要保證事務的 ACID 特性。
例如在下單場景下,庫存和訂單如果不在同一個節點上,就涉及分佈式事務。
分佈式鎖和分佈式事務區別:
- 鎖問題的關鍵在於進程操作的互斥關係,例如多個進程同時修改賬戶的餘額,如果沒有互斥關係則會導致該賬戶的餘額不正確。
- 而事務問題的關鍵則在於事務涉及的一系列操作需要滿足 ACID 特性,例如要滿足原子性操作則需要這些操作要麼都執行,要麼都不執行。
2PC
兩階段提交(Two-phase Commit,2PC),通過引入協調者(Coordinator)來協調參與者的行爲,並最終決定這些參與者是否要真正執行事務。
1. 執行過程
1.1 準備階段
協調者詢問參與者事務是否執行成功,參與者發回事務執行結果。詢問可以看成一種投票,需要參與者都同意才能 纔能執行。
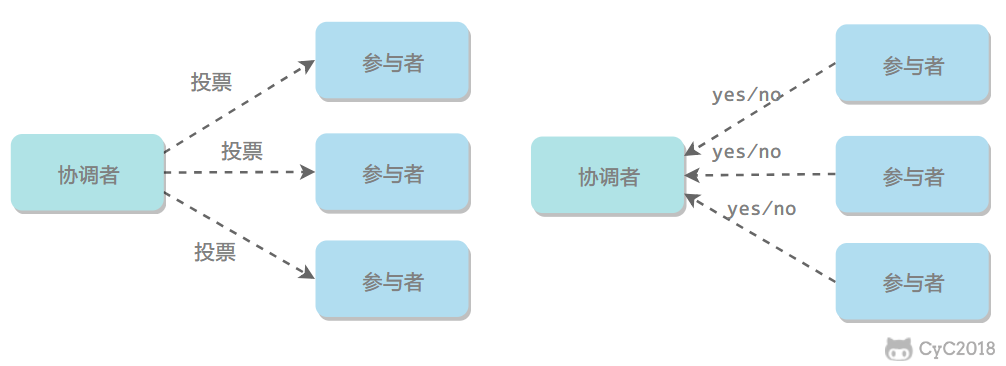
1.2 提交階段
如果事務在每個參與者上都執行成功,事務協調者發送通知讓參與者提交事務;否則,協調者發送通知讓參與者回滾事務。
需要注意的是,在準備階段,參與者執行了事務,但是還未提交。只有在提交階段接收到協調者發來的通知後,才進行提交或者回滾。
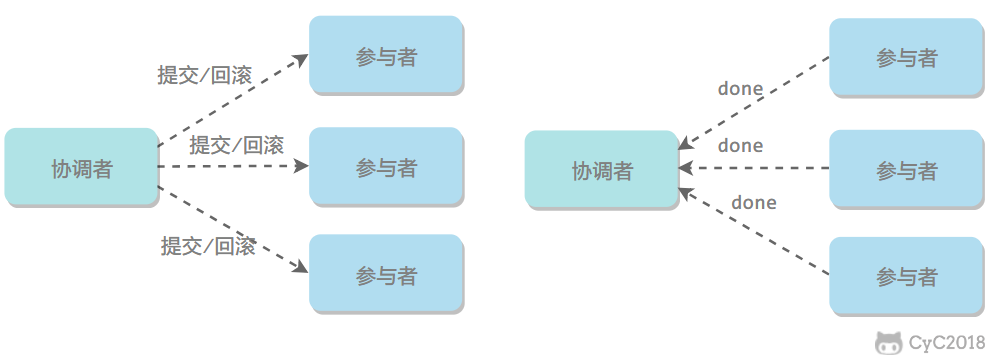
2. 存在的問題
2.1 同步阻塞
所有事務參與者在等待其它參與者響應的時候都處於同步阻塞等待狀態,無法進行其它操作。
2.2 單點問題
協調者在 2PC 中起到非常大的作用,發生故障將會造成很大影響。特別是在提交階段發生故障,所有參與者會一直同步阻塞等待,無法完成其它操作。
2.3 數據不一致
在提交階段,如果協調者只發送了部分 Commit 訊息,此時網路發生異常,那麼只有部分參與者接收到 Commit 訊息,也就是說只有部分參與者提交了事務,使得系統數據不一致。
2.4 太過保守
任意一個節點失敗就會導致整個事務失敗,沒有完善的容錯機制 機製。
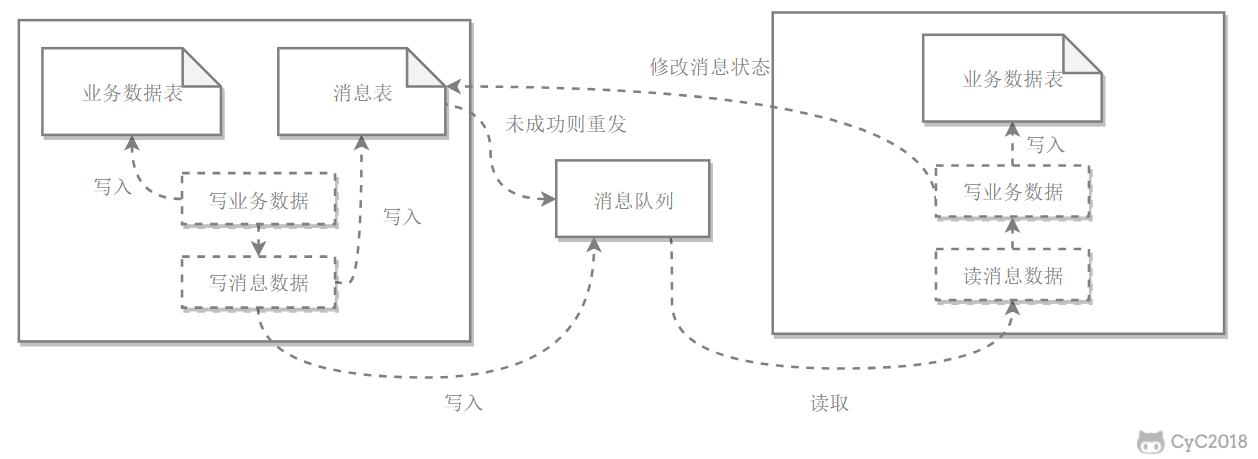
本地訊息表
本地訊息表與業務數據表處於同一個數據庫中,這樣就能利用本地事務來保證在對這兩個表的操作滿足事務特性,並且使用了訊息佇列來保證最終一致性。
- 在分佈式事務操作的一方完成寫業務數據的操作之後向本地訊息表發送一個訊息,本地事務能保證這個訊息一定會被寫入本地訊息表中。
- 之後將本地訊息表中的訊息轉發到訊息佇列中,如果轉發成功則將訊息從本地訊息表中刪除,否則繼續重新轉發。
- 在分佈式事務操作的另一方從訊息佇列中讀取一個訊息,並執行訊息中的操作。
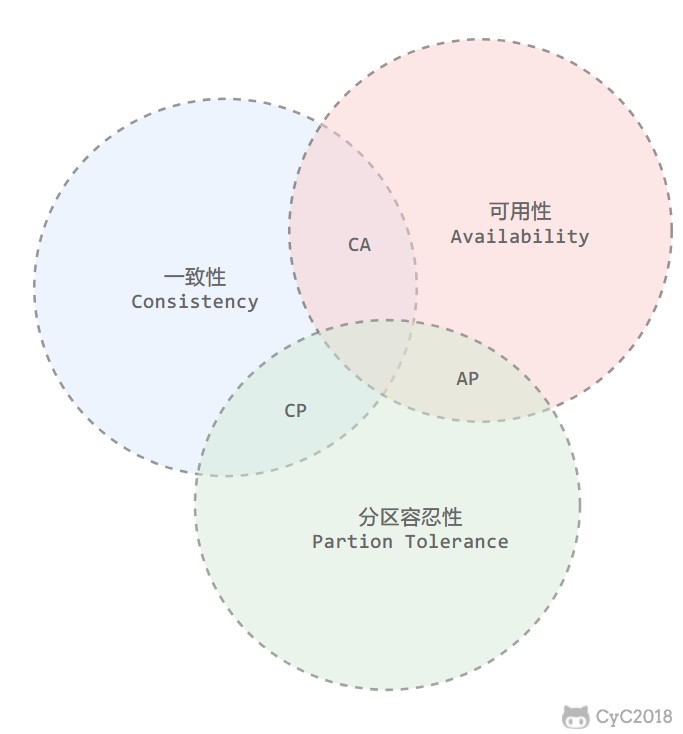
三、CAP
分佈式系統不可能同時滿足一致性(C:Consistency)、可用性(A:Availability)和分割區容忍性(P:Partition Tolerance),最多隻能同時滿足其中兩項。
一致性
一致性指的是多個數據副本是否能保持一致的特性,在一致性的條件下,系統在執行數據更新操作之後能夠從一致性狀態轉移到另一個一致性狀態。
對系統的一個數據更新成功之後,如果所有使用者都能夠讀取到最新的值,該系統就被認爲具有強一致性。
可用性
可用性指分佈式系統在面對各種異常時可以提供正常服務的能力,可以用系統可用時間佔總時間的比值來衡量,4 個 9 的可用性表示系統 99.99% 的時間是可用的。
在可用性條件下,要求系統提供的服務一直處於可用的狀態,對於使用者的每一個操作請求總是能夠在有限的時間內返回結果。
分割區容忍性
網路分割區指分佈式系統中的節點被劃分爲多個區域,每個區域內部可以通訊,但是區域之間無法通訊。
在分割區容忍性條件下,分佈式系統在遇到任何網路分割區故障的時候,仍然需要能對外提供一致性和可用性的服務,除非是整個網路環境都發生了故障。
權衡
在分佈式系統中,分割區容忍性必不可少,因爲需要總是假設網路是不可靠的。因此,CAP 理論實際上是要在可用性和一致性之間做權衡。
可用性和一致性往往是衝突的,很難使它們同時滿足。在多個節點之間進行數據同步時,
- 爲了保證一致性(CP),不能存取未同步完成的節點,也就失去了部分可用性;
- 爲了保證可用性(AP),允許讀取所有節點的數據,但是數據可能不一致。
四、BASE
BASE 是基本可用(Basically Available)、軟狀態(Soft State)和最終一致性(Eventually Consistent)三個短語的縮寫。
BASE 理論是對 CAP 中一致性和可用性權衡的結果,它的核心思想是:即使無法做到強一致性,但每個應用都可以根據自身業務特點,採用適當的方式來使系統達到最終一致性。
基本可用
指分佈式系統在出現故障的時候,保證核心可用,允許損失部分可用性。
例如,電商在做促銷時,爲了保證購物系統的穩定性,部分消費者可能會被引導到一個降級的頁面。
軟狀態
指允許系統中的數據存在中間狀態,並認爲該中間狀態不會影響系統整體可用性,即允許系統不同節點的數據副本之間進行同步的過程存在時延。
最終一致性
最終一致性強調的是系統中所有的數據副本,在經過一段時間的同步後,最終能達到一致的狀態。
ACID 要求強一致性,通常運用在傳統的數據庫系統上。而 BASE 要求最終一致性,通過犧牲強一致性來達到可用性,通常運用在大型分佈式系統中。
在實際的分佈式場景中,不同業務單元和元件對一致性的要求是不同的,因此 ACID 和 BASE 往往會結合在一起使用。
五、Paxos
用於達成共識性問題,即對多個節點產生的值,該演算法能保證只選出唯一一個值。
主要有三類節點:
- 提議者(Proposer):提議一個值;
- 接受者(Acceptor):對每個提議進行投票;
- 告知者(Learner):被告知投票的結果,不參與投票過程。

執行過程
規定一個提議包含兩個欄位:[n, v],其中 n 爲序號(具有唯一性),v 爲提議值。
1. Prepare 階段
下圖演示了兩個 Proposer 和三個 Acceptor 的系統中執行該演算法的初始過程,每個 Proposer 都會向所有 Acceptor 發送 Prepare 請求。

當 Acceptor 接收到一個 Prepare 請求,包含的提議爲 [n1, v1],並且之前還未接收過 Prepare 請求,那麼發送一個 Prepare 響應,設定當前接收到的提議爲 [n1, v1],並且保證以後不會再接受序號小於 n1 的提議。
如下圖,Acceptor X 在收到 [n=2, v=8] 的 Prepare 請求時,由於之前沒有接收過提議,因此就發送一個 [no previous] 的 Prepare 響應,設定當前接收到的提議爲 [n=2, v=8],並且保證以後不會再接受序號小於 2 的提議。其它的 Acceptor 類似。
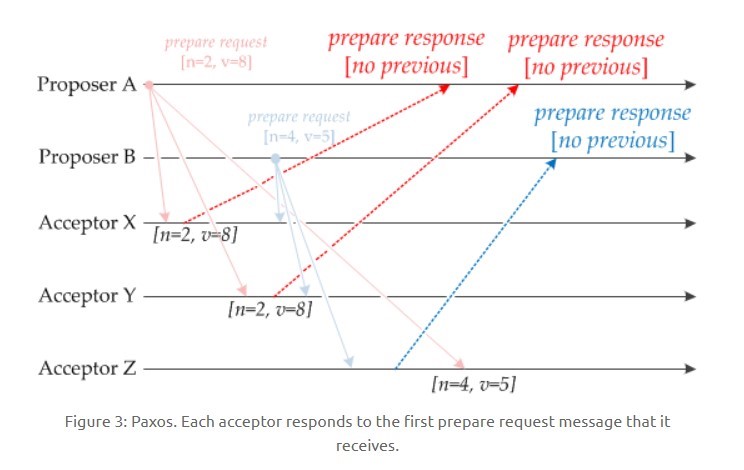
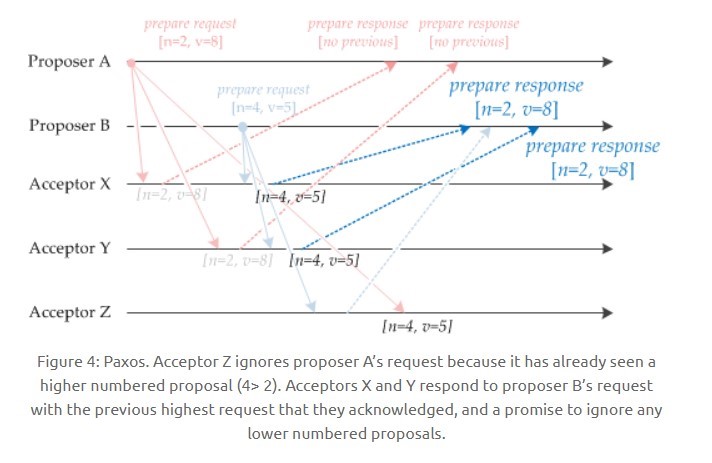
如果 Acceptor 接收到一個 Prepare 請求,包含的提議爲 [n2, v2],並且之前已經接收過提議 [n1, v1]。如果 n1 > n2,那麼就丟棄該提議請求;否則,發送 Prepare 響應,該 Prepare 響應包含之前已經接收過的提議 [n1, v1],設定當前接收到的提議爲 [n2, v2],並且保證以後不會再接受序號小於 n2 的提議。
如下圖,Acceptor Z 收到 Proposer A 發來的 [n=2, v=8] 的 Prepare 請求,由於之前已經接收過 [n=4, v=5] 的提議,並且 n > 2,因此就拋棄該提議請求;Acceptor X 收到 Proposer B 發來的 [n=4, v=5] 的 Prepare 請求,因爲之前接收到的提議爲 [n=2, v=8],並且 2 <= 4,因此就發送 [n=2, v=8] 的 Prepare 響應,設定當前接收到的提議爲 [n=4, v=5],並且保證以後不會再接受序號小於 4 的提議。Acceptor Y 類似。
2. Accept 階段
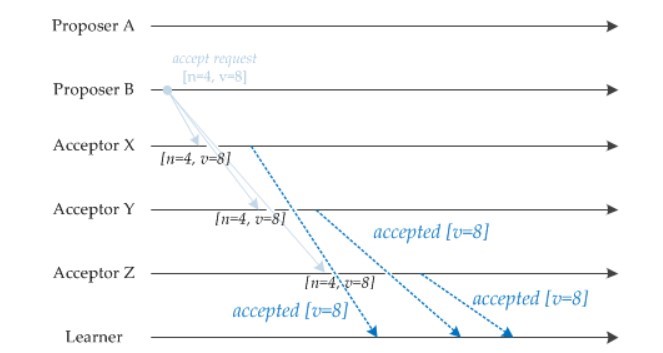
當一個 Proposer 接收到超過一半 Acceptor 的 Prepare 響應時,就可以發送 Accept 請求。
Proposer A 接收到兩個 Prepare 響應之後,就發送 [n=2, v=8] Accept 請求。該 Accept 請求會被所有 Acceptor 丟棄,因爲此時所有 Acceptor 都保證不接受序號小於 4 的提議。
Proposer B 過後也收到了兩個 Prepare 響應,因此也開始發送 Accept 請求。需要注意的是,Accept 請求的 v 需要取它收到的最大提議編號對應的 v 值,也就是 8。因此它發送 [n=4, v=8] 的 Accept 請求。

3. Learn 階段
Acceptor 接收到 Accept 請求時,如果序號大於等於該 Acceptor 承諾的最小序號,那麼就發送 Learn 提議給所有的 Learner。當 Learner 發現有大多數的 Acceptor 接收了某個提議,那麼該提議的提議值就被 Paxos 選擇出來。
約束條件
1. 正確性
指只有一個提議值會生效。
因爲 Paxos 協定要求每個生效的提議被多數 Acceptor 接收,並且 Acceptor 不會接受兩個不同的提議,因此可以保證正確性。
2. 可終止性
指最後總會有一個提議生效。
Paxos 協定能夠讓 Proposer 發送的提議朝着能被大多數 Acceptor 接受的那個提議靠攏,因此能夠保證可終止性。
六、Raft
Raft 也是分佈式一致性協定,主要是用來競選主節點。
單個 Candidate 的競選
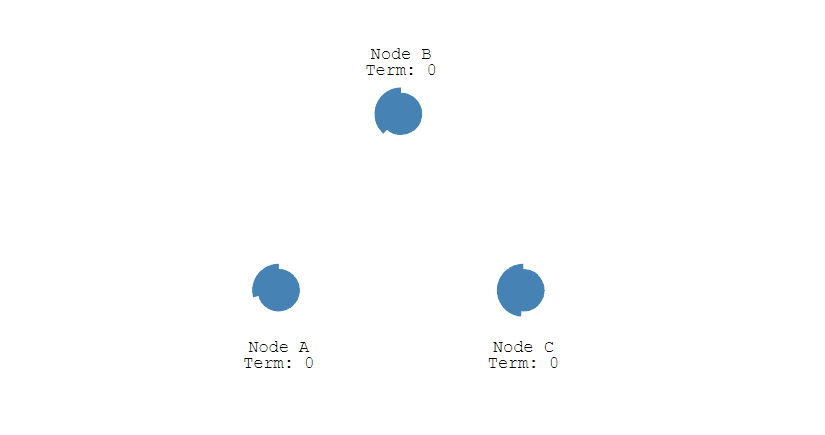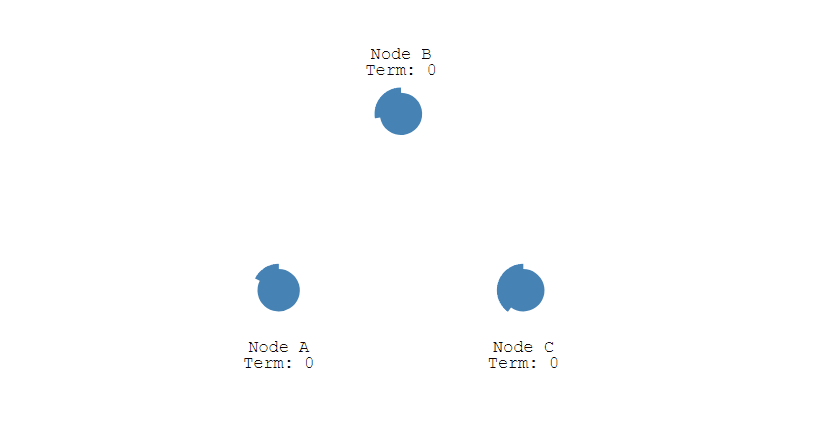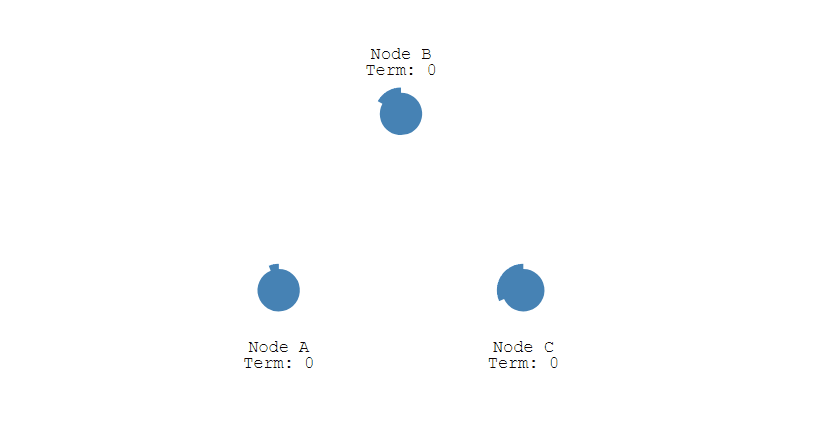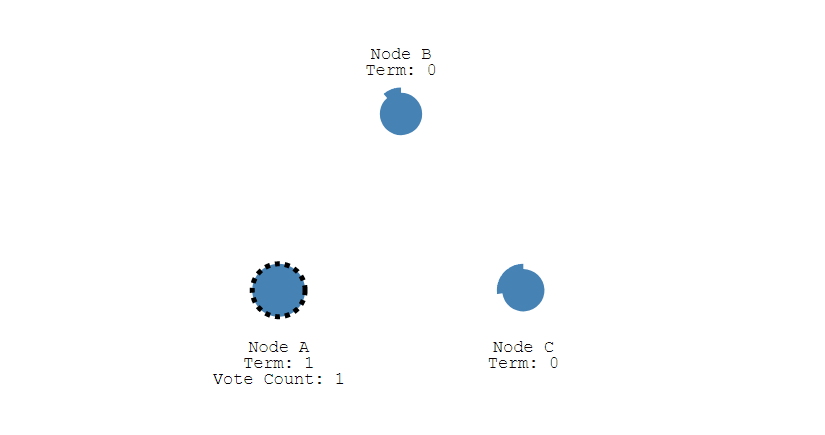
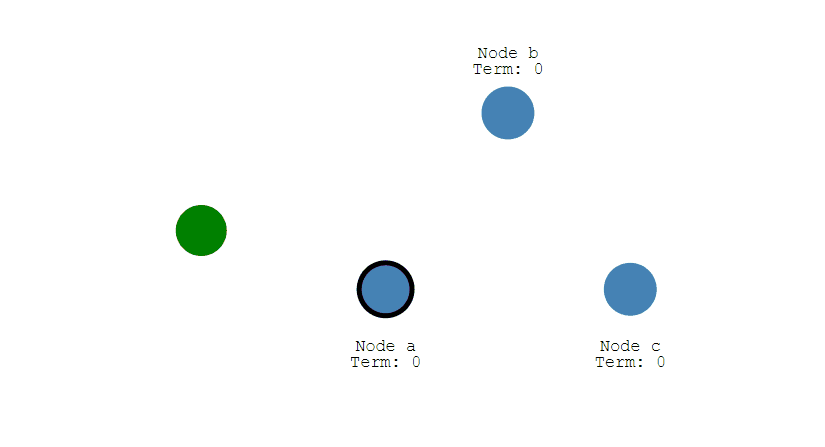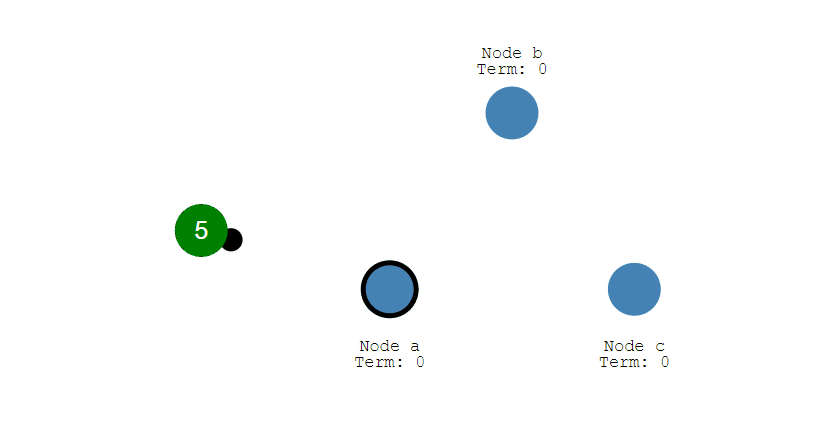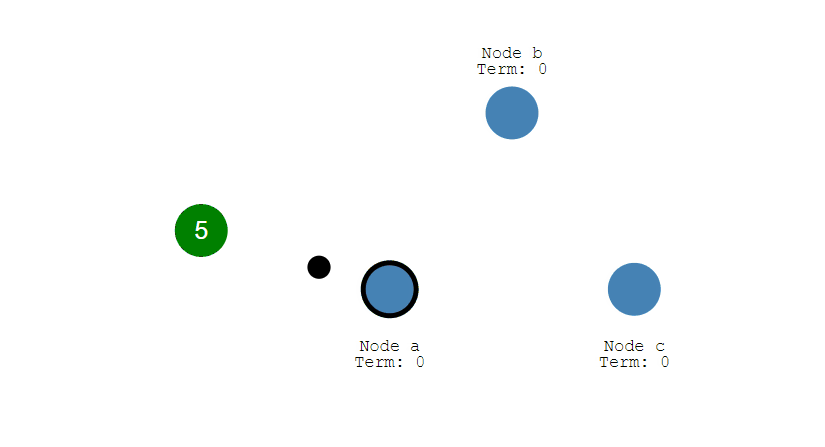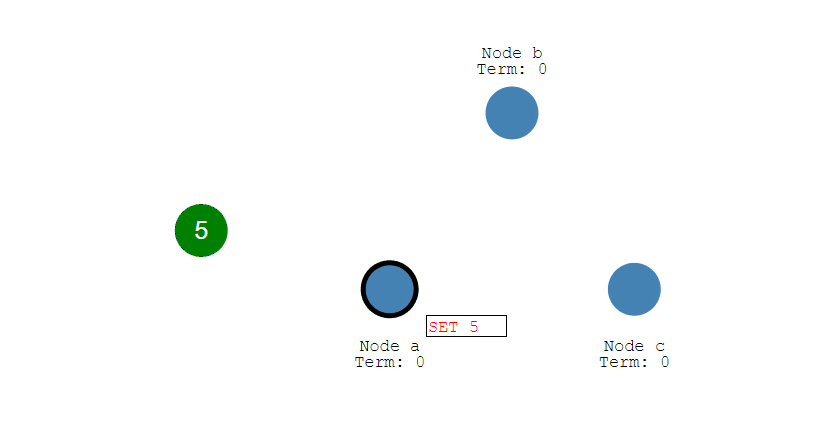
有三種節點:Follower、Candidate 和 Leader。Leader 會週期性的發送心跳包給 Follower。每個 Follower 都設定了一個隨機的競選超時時間,一般爲 150ms~300ms,如果在這個時間內沒有收到 Leader 的心跳包,就會變成 Candidate,進入競選階段。
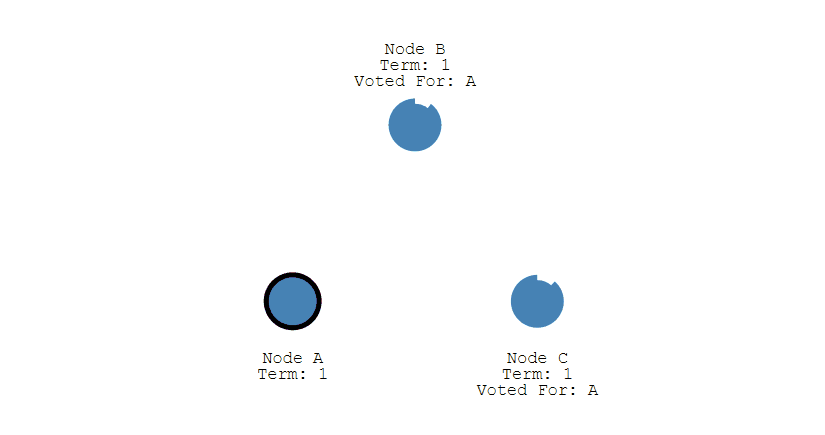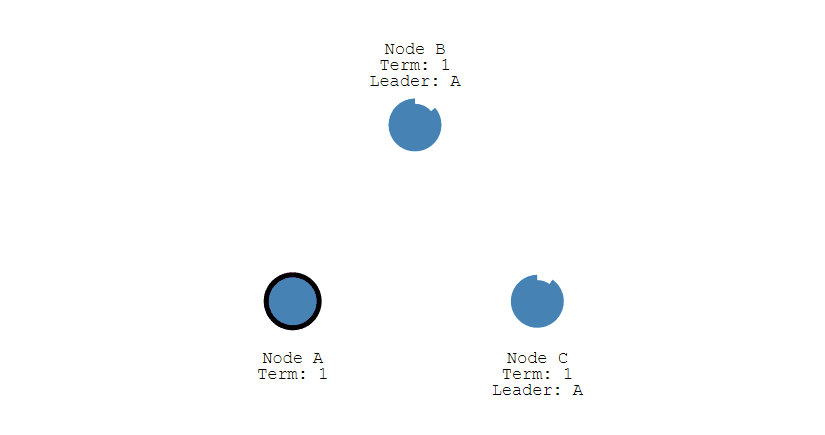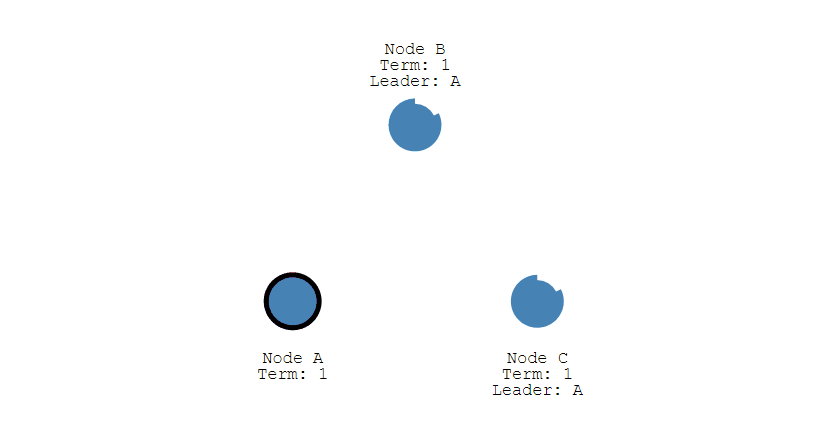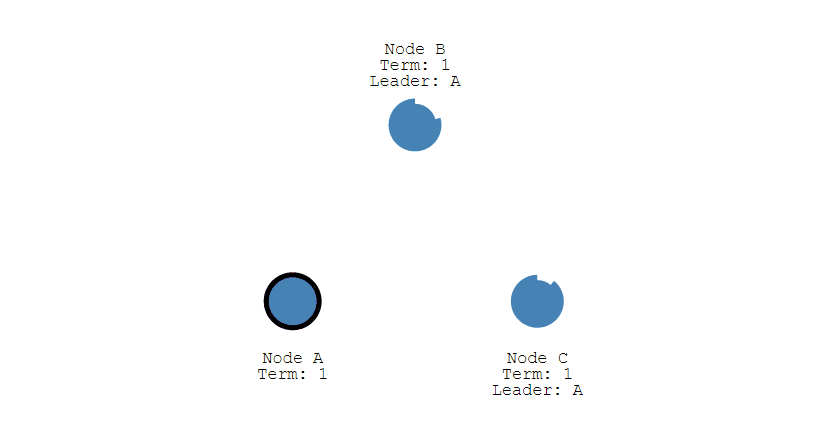
- 下圖展示一個分佈式系統的最初階段,此時只有 Follower 沒有 Leader。Node A 等待一個隨機的競選超時時間之後,沒收到 Leader 發來的心跳包,因此進入競選階段。
- 此時 Node A 發送投票請求給其它所有節點。

- 其它節點會對請求進行回覆 回復,如果超過一半的節點回復了,那麼該 Candidate 就會變成 Leader。
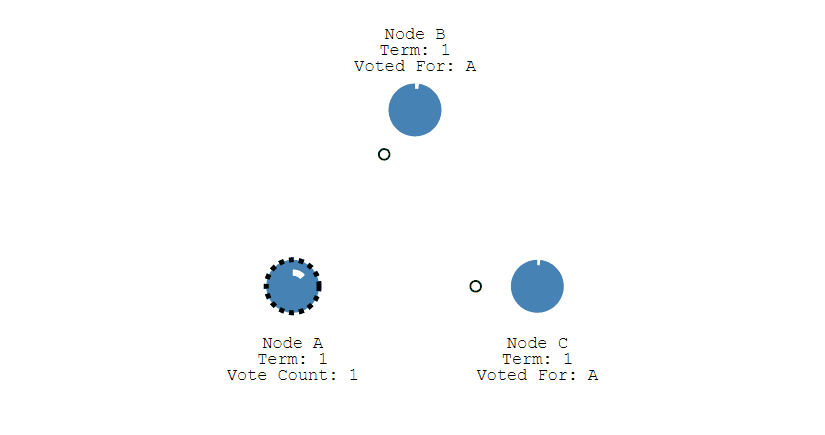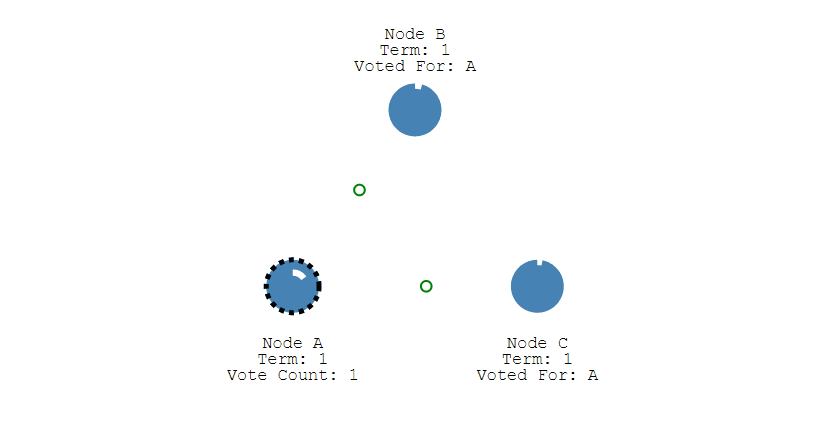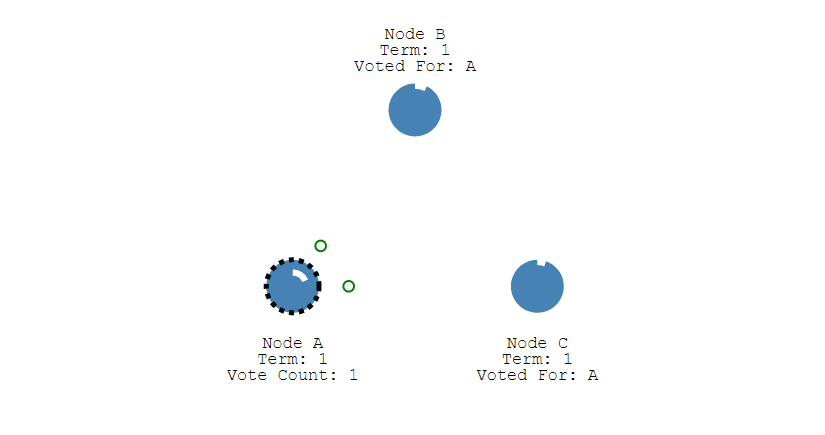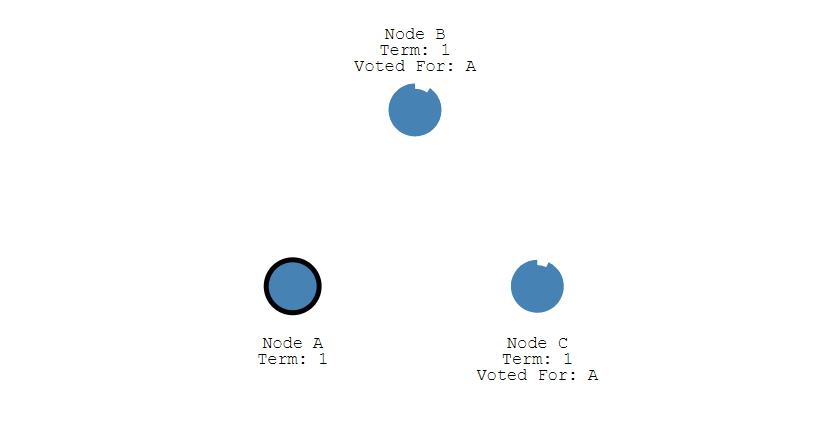
- 之後 Leader 會週期性地發送心跳包給 Follower,Follower 接收到心跳包,會重新開始計時。
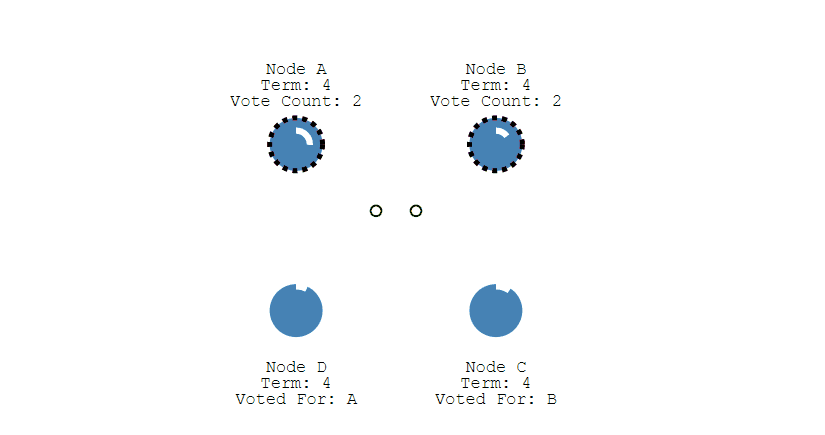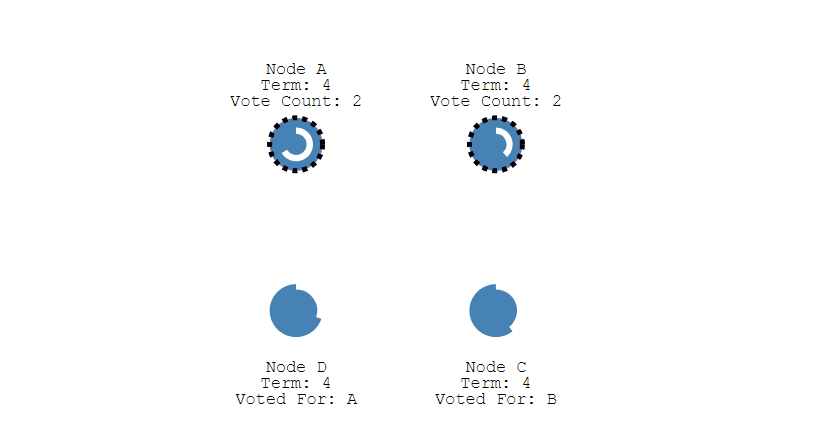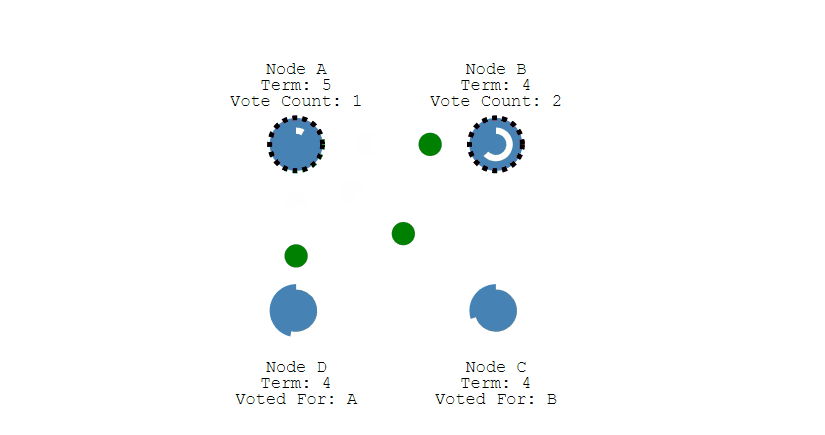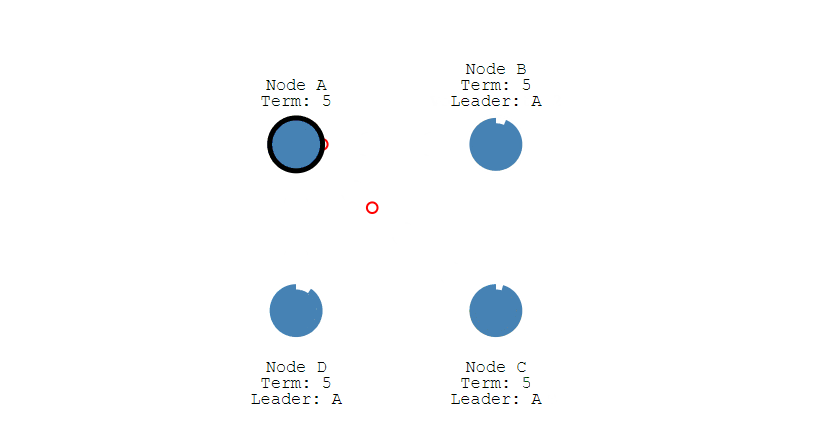
多個 Candidate 競選
- 如果有多個 Follower 成爲 Candidate,並且所獲得票數相同,那麼就需要重新開始投票。例如下圖中 Node B 和 Node D 都獲得兩票,需要重新開始投票。

- 由於每個節點設定的隨機競選超時時間不同,因此下一次再次出現多個 Candidate 並獲得同樣票數的概率很低。
數據同步
- 來自用戶端的修改都會被傳入 Leader。注意該修改還未被提交,只是寫入日誌中。
- Leader 會把修改複製到所有 Follower。
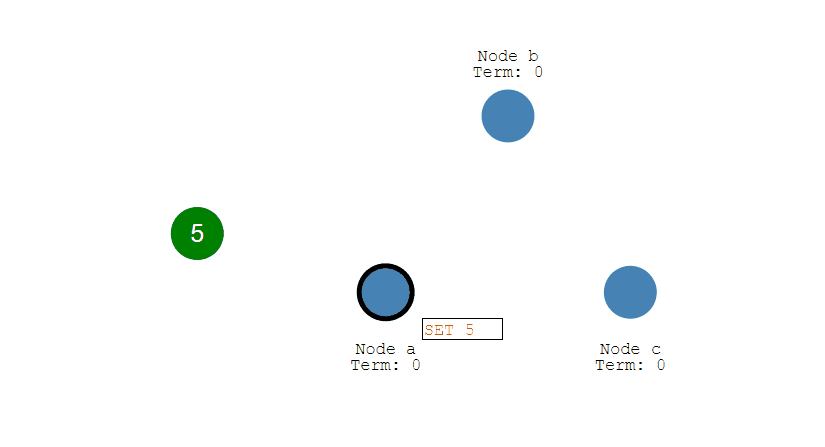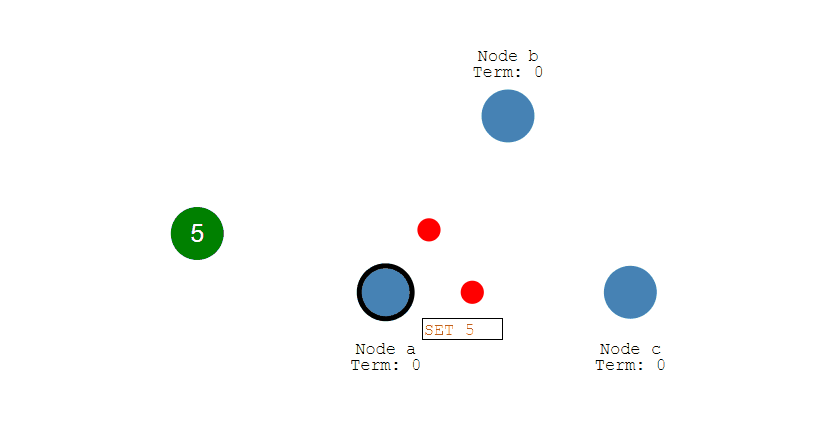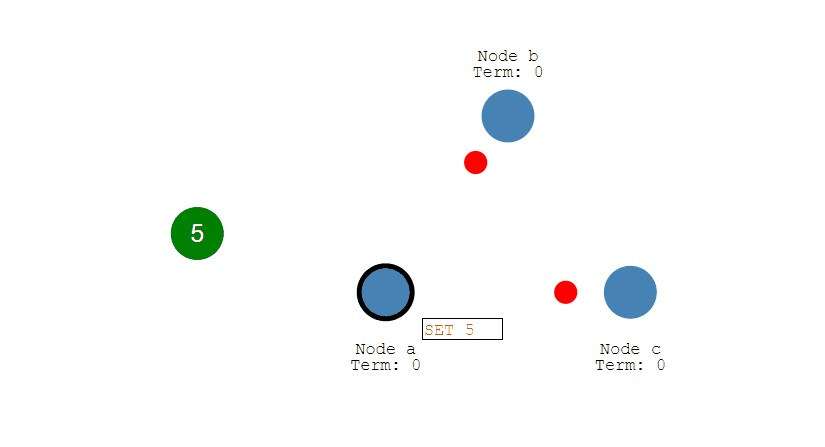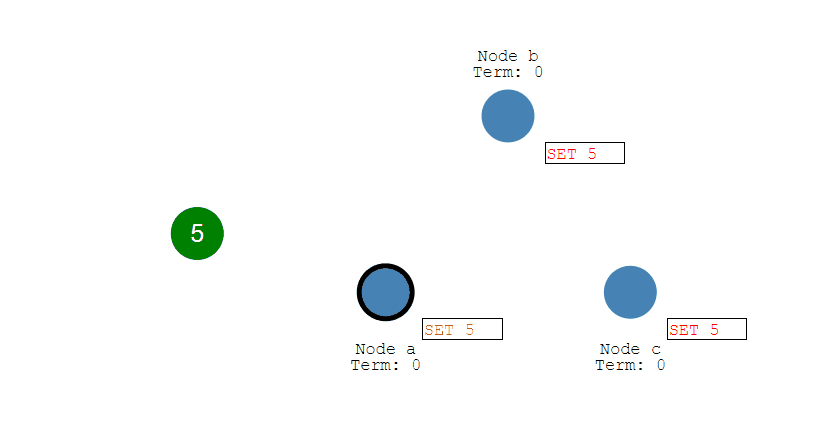
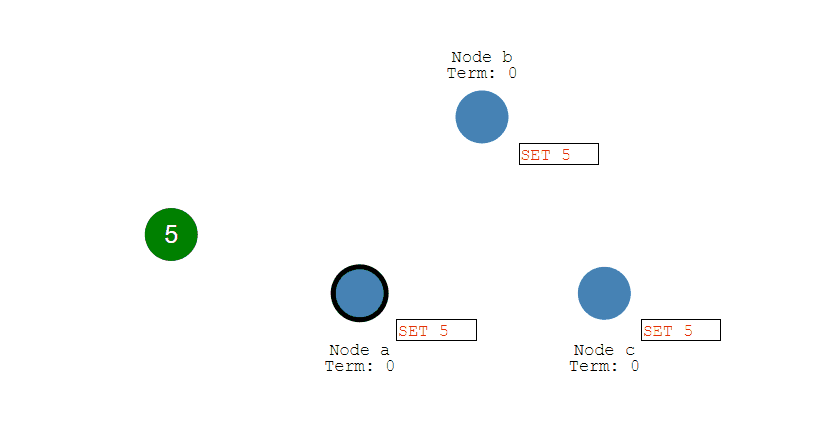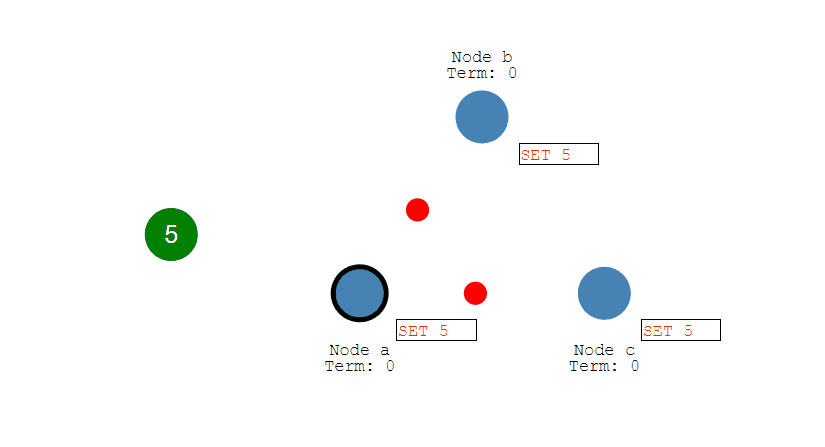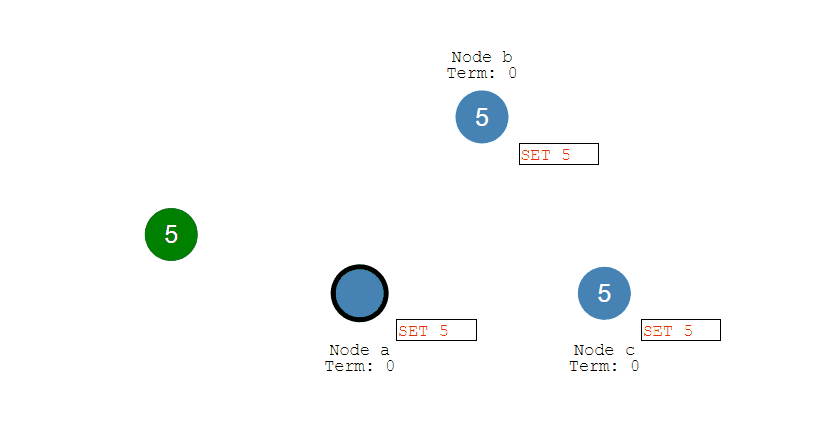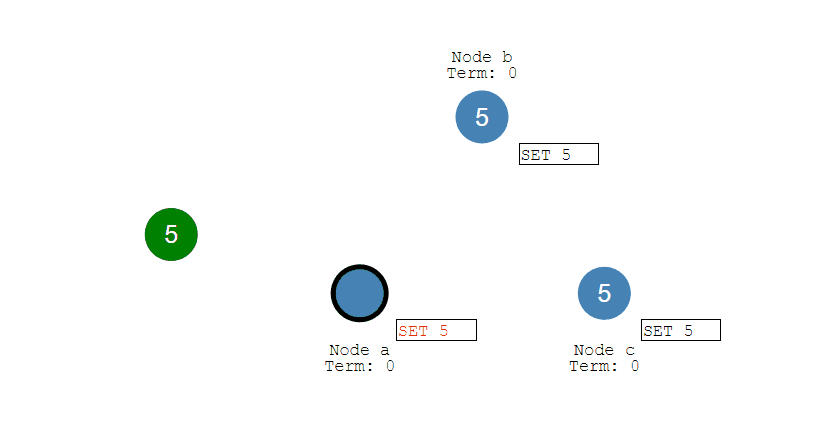
- Leader 會等待大多數的 Follower 也進行了修改,然後纔將修改提交。

- 此時 Leader 會通知的所有 Follower 讓它們也提交修改,此時所有節點的值達成一致。
參考
- 倪超. 從 Paxos 到 ZooKeeper : 分佈式一致性原理與實踐 [M]. 電子工業出版社, 2015.
- Distributed locks with Redis
- 淺談分佈式鎖
- 基於 Zookeeper 的分佈式鎖
- 聊聊分佈式事務,再說說解決方案
- 分佈式系統的事務處理
- 深入理解分佈式事務
- What is CAP theorem in distributed database system?
- NEAT ALGORITHMS - PAXOS
- Paxos By Example