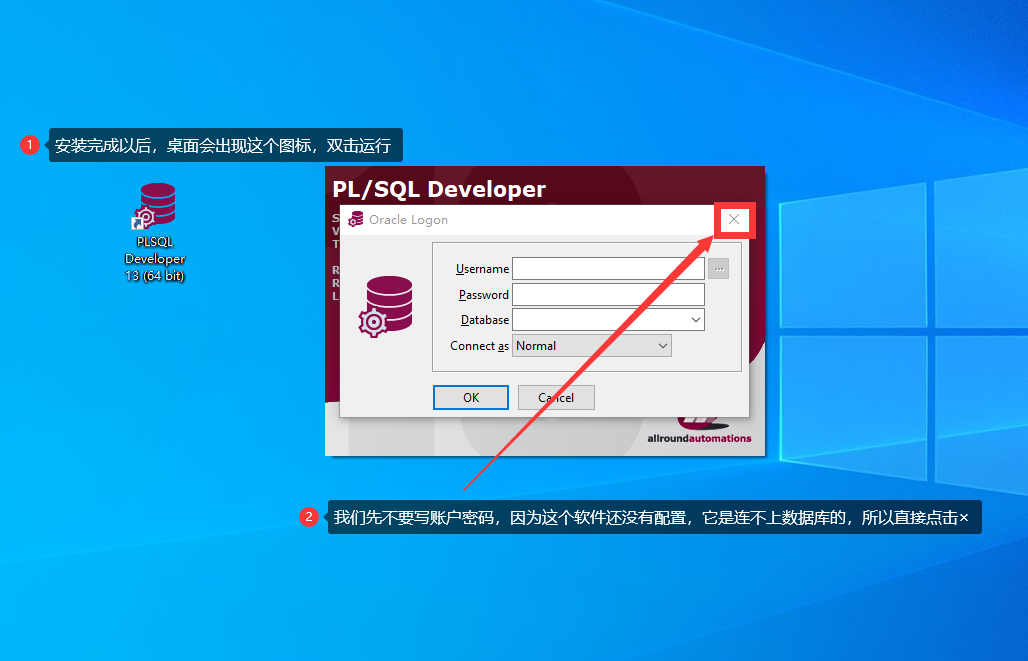
學習Oracle這一篇就夠了
配套資料,免費下載
鏈接:https://pan.baidu.com/s/1yjJY3IstA8aMQBPYhWNlCw
提取碼:qmpd
複製這段內容後開啓百度網路硬碟手機App,操作更方便哦
第一章 數據庫概述
1.1、數據庫的好處
- 將數據持久化到本地
- 提供結構化查詢功能
1.2、數據庫的常見概念
- DB:數據庫,儲存數據的倉庫
- DBMS:數據庫管理系統,又稱爲數據庫軟體或者數據庫產品,用於建立和管理數據庫,常見的有MySQL、Oracle、SQL Server
- DBS:數據庫系統,數據庫系統是一個通稱,包括數據庫、數據庫管理系統、數據庫管理人員等,是最大的範疇
- SQL:結構化查詢語言,用於和數據庫通訊的語言,不是某個數據庫軟體特有的,而是幾乎所有的主流數據庫軟體通用的語言
1.3、數據庫的儲存特點
- 數據存放到表中,然後表再放到庫中
- 一個庫中可以有多張表,每張表具有唯一的表名用來標識自己
- 表中有一個或多個列,列又稱爲「欄位」,相當於Java中「屬性」
- 表中的每一行數據,相當於Java中「物件」
1.4、數據庫的常見分類
- 關係型數據庫:MySQL、Oracle、DB2、SQL Server
- 非關係型數據庫:
- 鍵值儲存數據庫:Redis、Memcached、MemcacheDB
- 列儲存數據庫:HBase、Cassandra
- 面向文件的數據庫:MongDB、CouchDB
- 圖形數據庫:Neo4J
1.5、SQL語言的分類
- DQL:數據查詢語言:select、from、where
- DCL:數據控制語言:grant、revoke
- DDL:數據定義語言:create、alter、drop、truncate
- DML:數據操作語言:insert、update、delete
- TCL:事務控制語言:commit、rollback
第二章 Oracle概述
2.1、Oracle的概述
Oracle Database,又名Oracle RDBMS,或簡稱Oracle。是甲骨文公司的一款關係數據庫管理系統。它是在數據庫領域一直處於領先地位的產品。可以說Oracle數據庫系統是目前世界上流行的關係數據庫管理系統,系統可移植性好、使用方便、功能強,適用於各類大、中、小、微機環境。它是一種高效率、可靠性好的、適應高吞吐量的數據庫方案
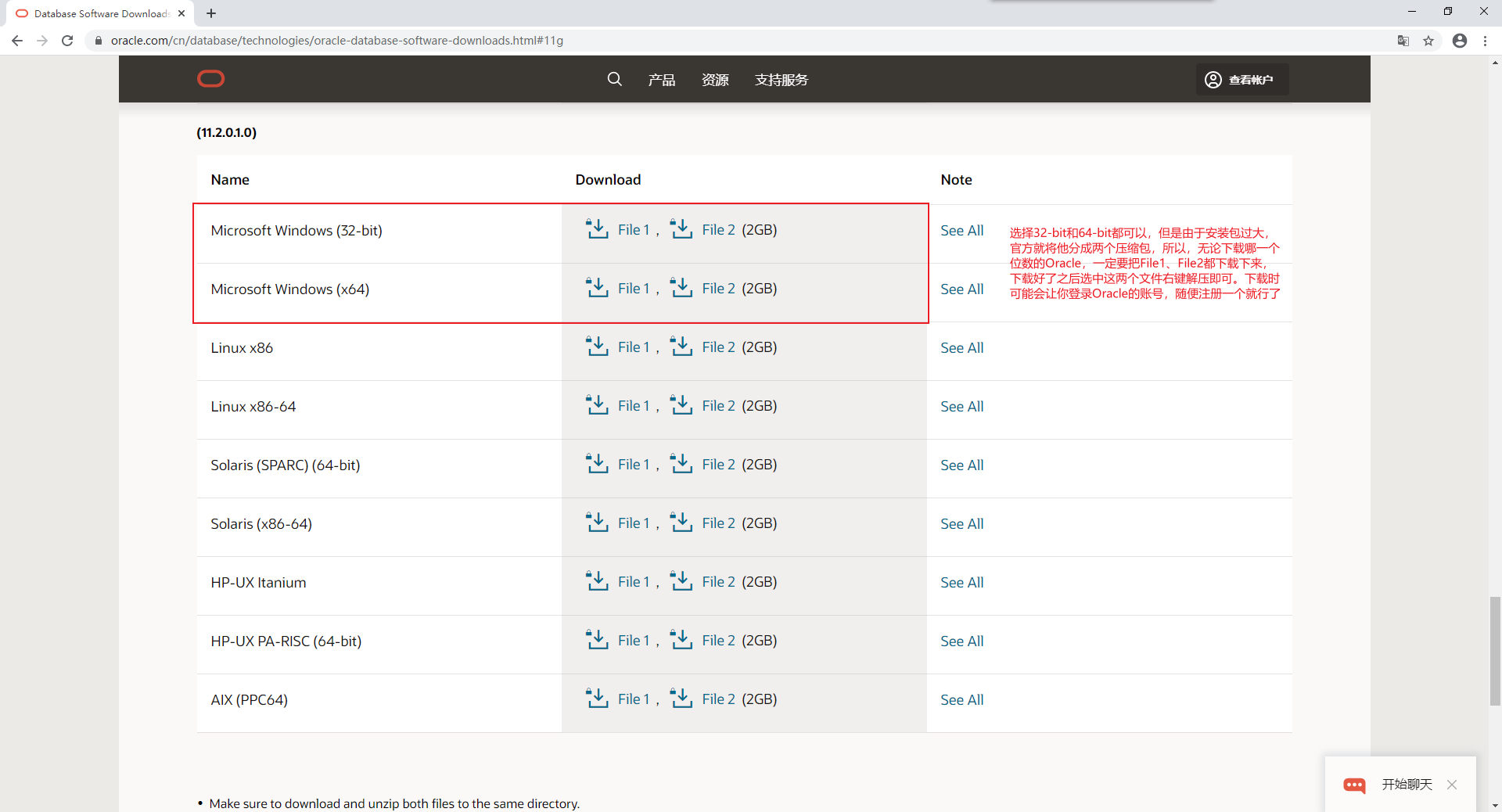
2.2、Oracle的下載
課程使用:Windows 10
官網地址:Oracle 11gR2
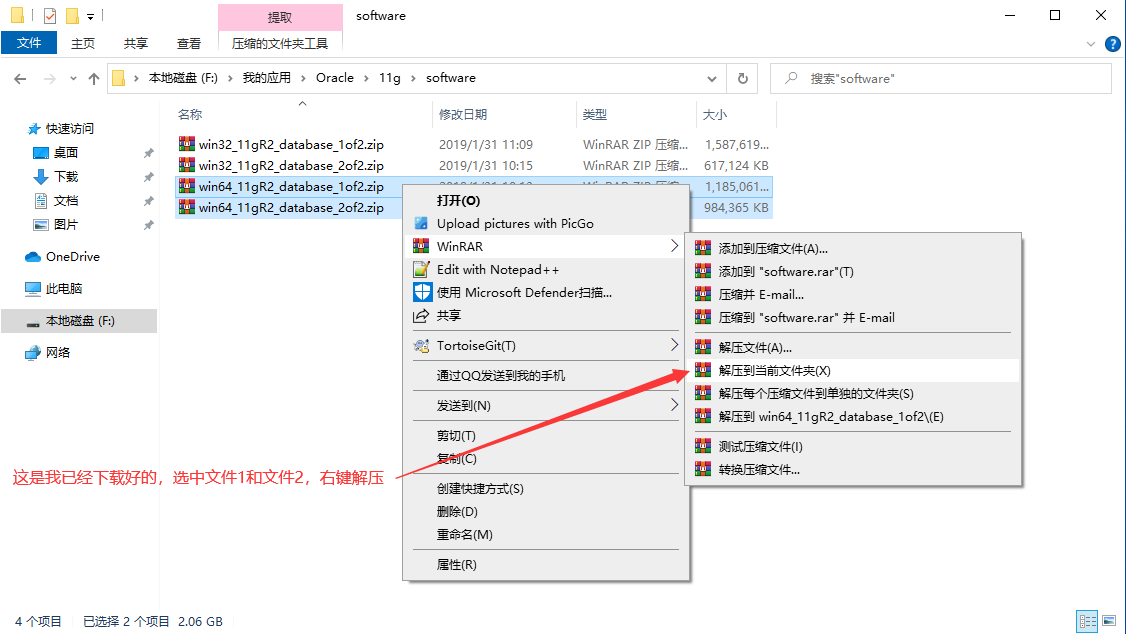
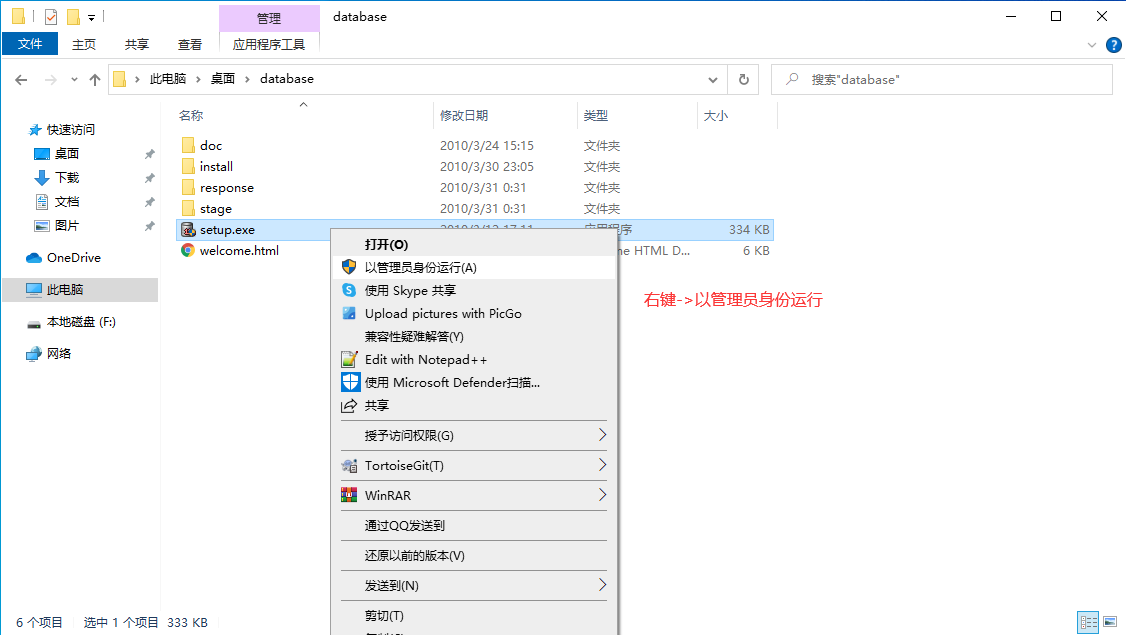
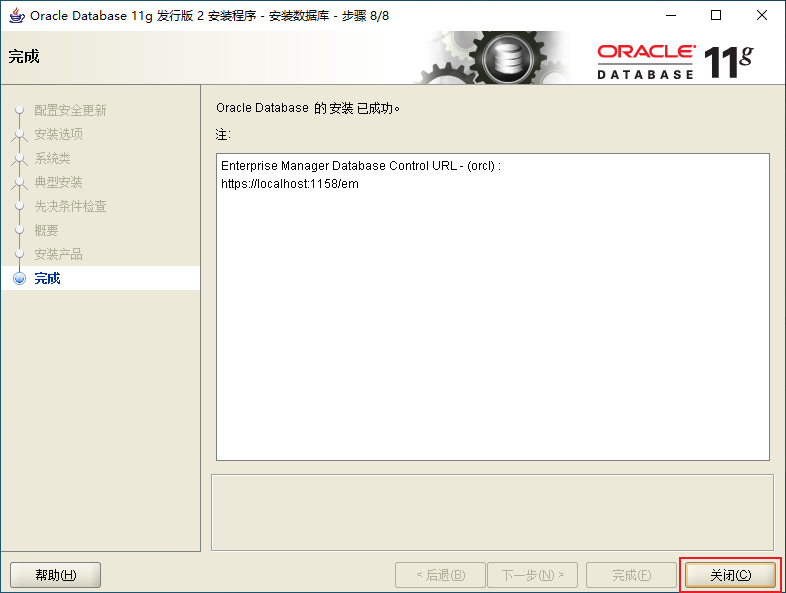
2.3、Oracle的安裝
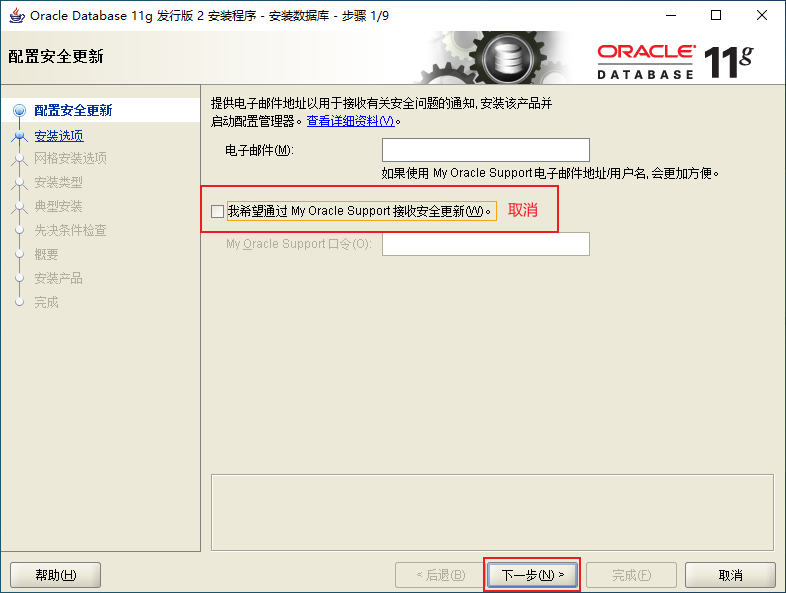
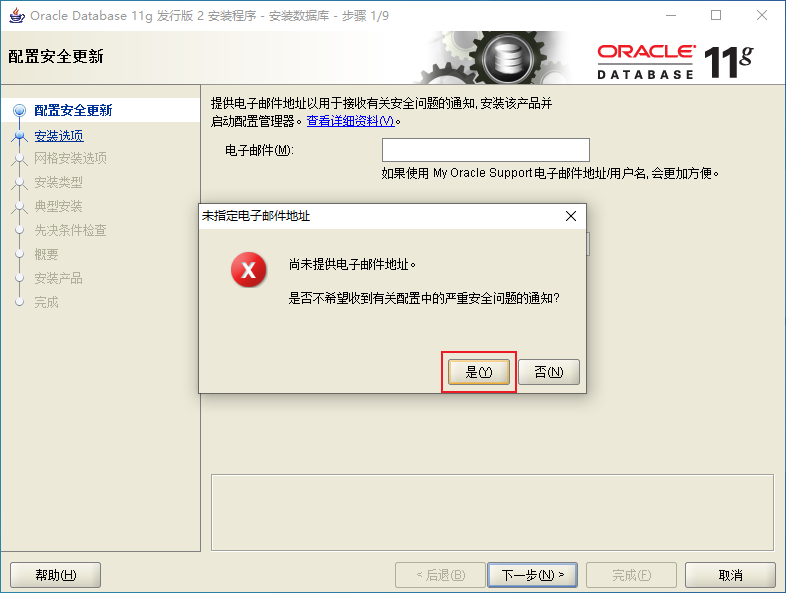
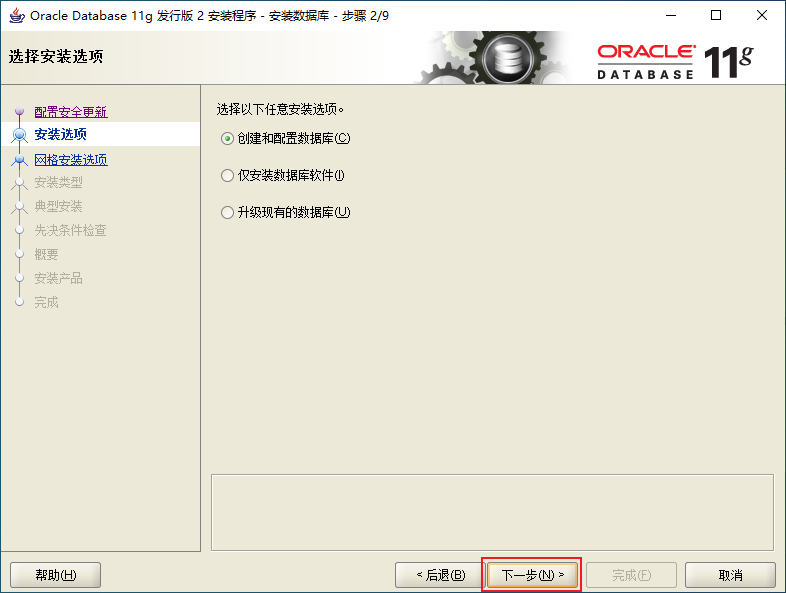
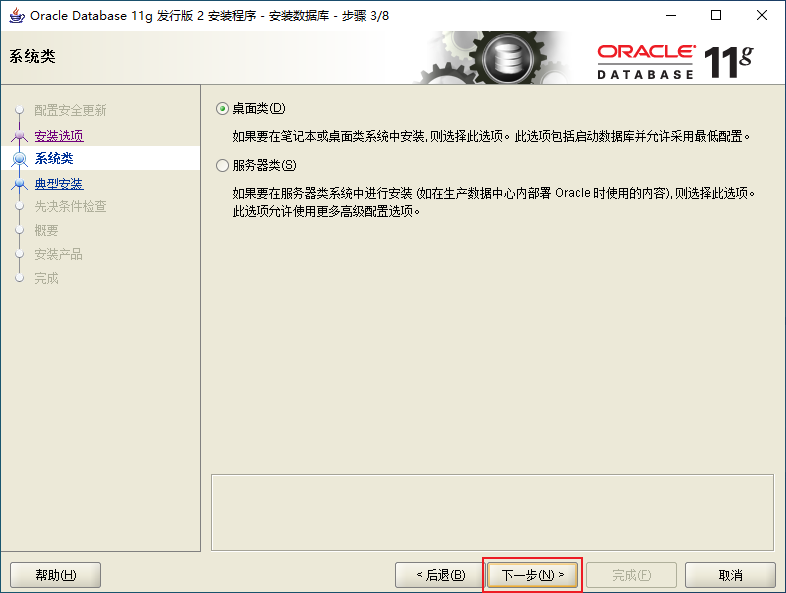
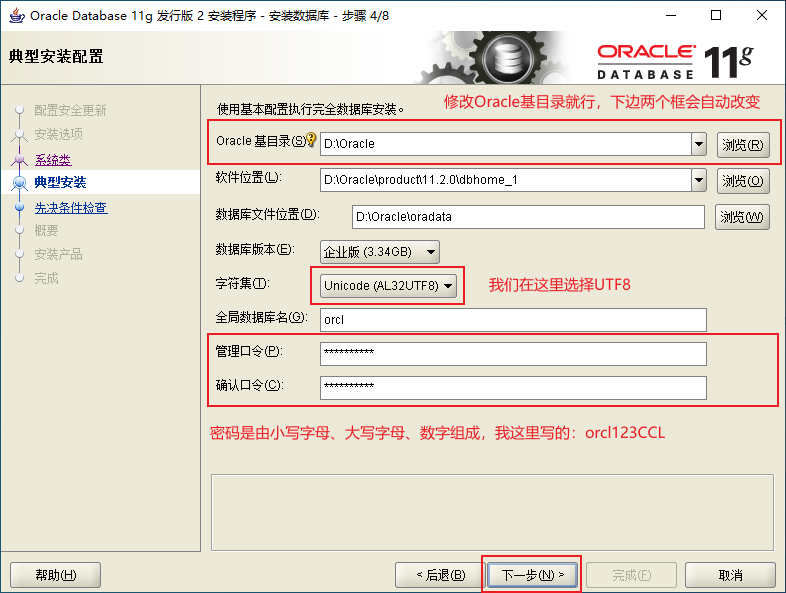
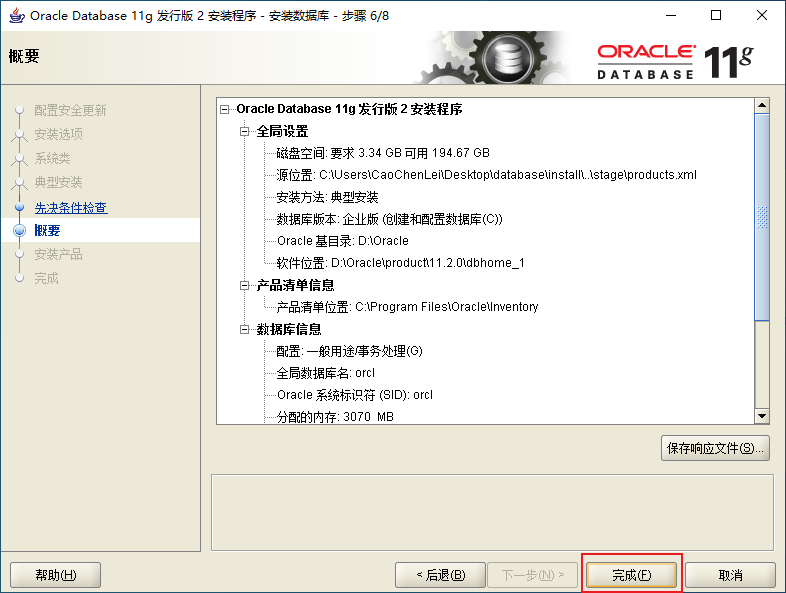
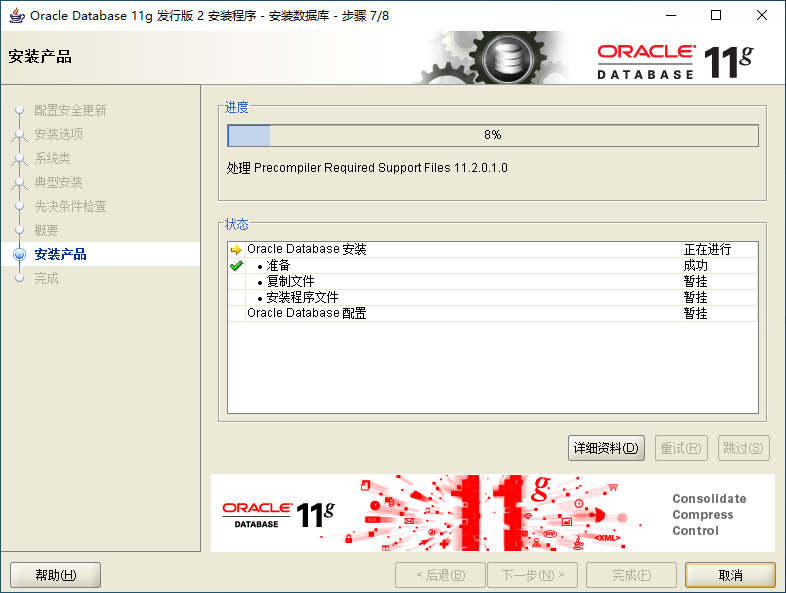
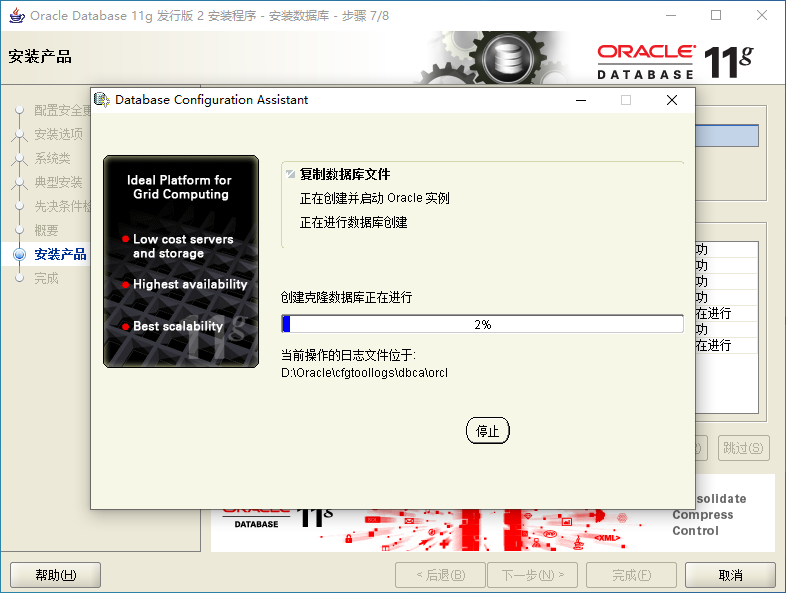
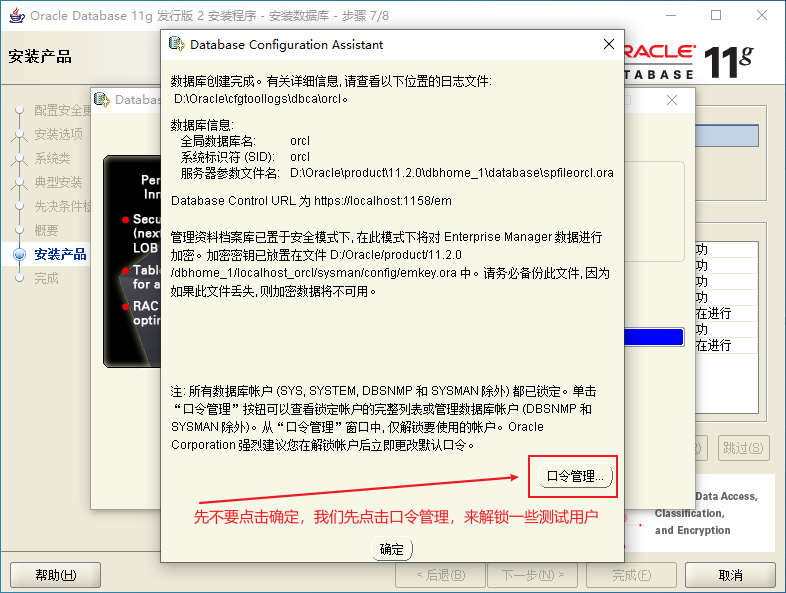
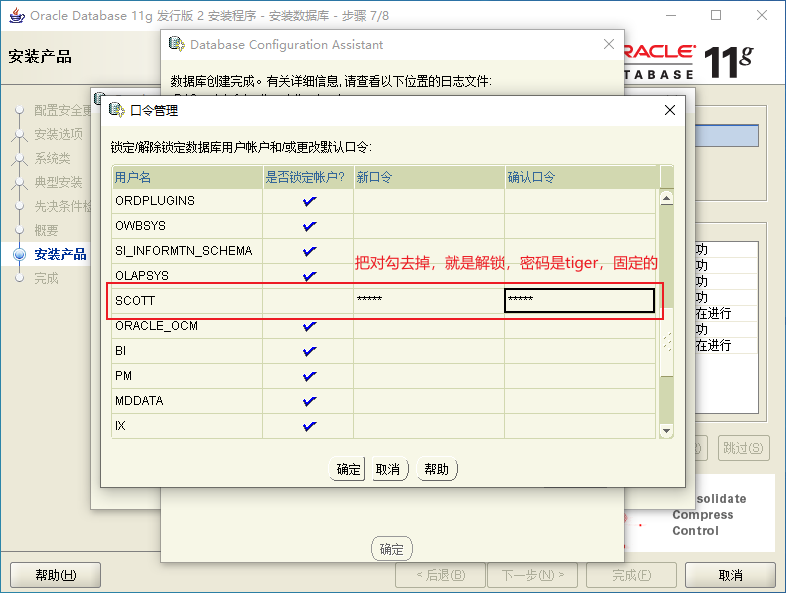
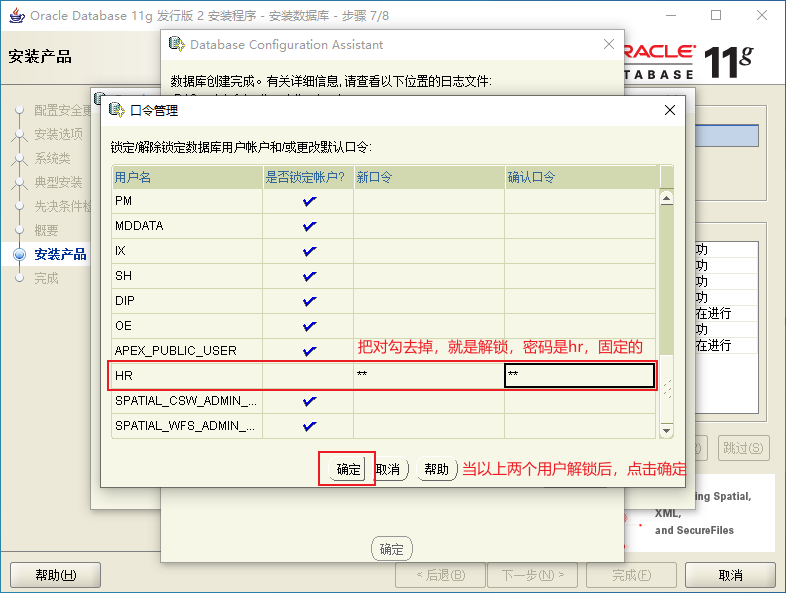
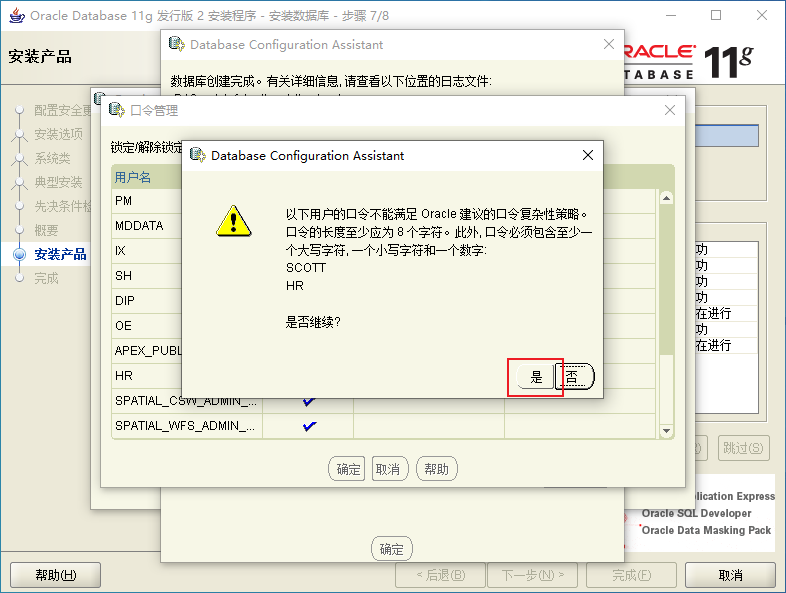
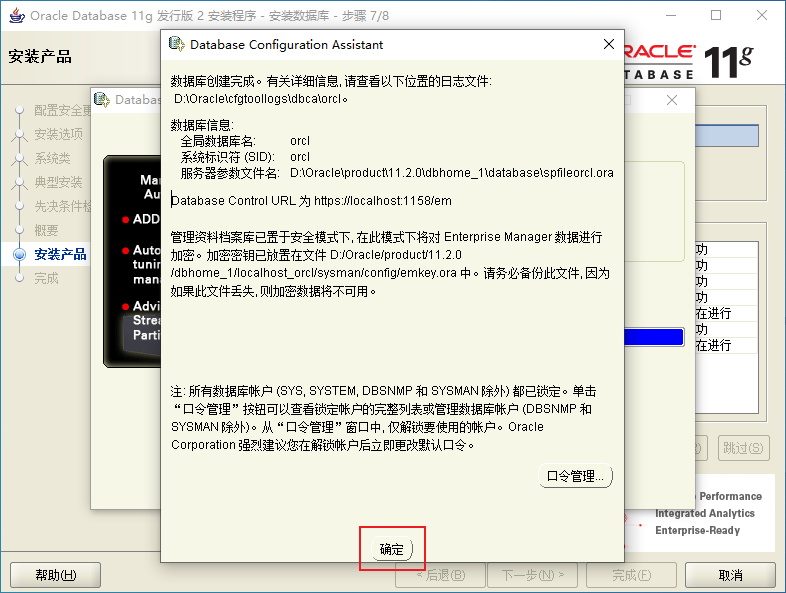
2.4、Oracle的目錄
-
admin目錄
描述:記錄Oracle範例的設定,執行日誌等檔案,每一個範例一個目錄,SID:SystemIDentifier的縮寫,是Oracle範例的唯一標記,在Oracle中一個範例只能操作一個數據庫,如果安裝多個庫那麼就會有多個範例,我們可以通過範例SID來區分。 -
cfgtoollogs目錄
描述:下面 下麪子目錄分別存放當執行dbca,emca,netca等圖形化設定程式時的log。 -
checkpoints目錄
描述:存放檢查點檔案。 -
diag目錄
描述:Oracle11g新增的一個重組目錄,其中的子目錄,基本上Oracle每個元件都有了自己的單獨目錄,在Oracle10g中我們詬病的log檔案散放在四處的問題終於得到解決,無論是asm還是crs還是rdbms,所有元件需要被用來診斷的log檔案都存放在這個新的目錄下。 -
flash_recovery_area(閃回區)目錄
描述:分配一個特定的目錄位置來存放一些特定的恢復檔案,用於集中和簡化管理數據庫恢復工作。閃回區可儲存完全的數據檔案備份,增量備份、數據檔案副本、當前控制檔案、備份的控制檔案、spfile檔案、快照控制檔案、聯機日誌檔案、歸檔日誌、塊跟蹤檔案、閃回日誌。 -
oradata目錄
描述:存放數據檔案。
- CONTROL01.CTL
描述:Oracle數據庫的控制檔案 - EXAMPLE01.DBF
描述:Oracle數據庫表空間檔案 - REDO01.LOG
描述:Oracle數據庫的重做日誌檔案,此檔案有三個 - SYSAUX01.DBF
描述:11g新增加的表空間,主要儲存除數據字典以外的其他數據物件,由系統內部自動維護 - SYSTEM01.DBF
描述:用於存放Oracle系統內部表和數據字典的數據。比如:表名、列名、使用者名稱等 - TEMP01.DBF
描述:臨時表空間檔案 - UNDOTBS01.DBF
描述:復原表空間檔案,用來儲存回滾數據 - USERS01.DBF
描述:使用者表空間
- CONTROL01.CTL
-
product目錄
描述:數據庫範例存放檔案。
2.5、Oracle的設定
前方高能:如果你是把Oracle 11gR2直接安裝到本地電腦上的,這一章,你就直接跳過吧!
注意事項:如果你是把Oracle 11gR2安裝到了伺服器中,那麼你要想用戶端遠端存取,接下來的這些步驟,請你仔細閱讀!
用戶端爲了和伺服器連線,必須先和伺服器上的監聽進程聯絡。ORACLE通過tnsnames.ora檔案中的連線描述符來說明連線資訊。一般tnsnames.ora 是建立在用戶端上的。如果是用戶端/伺服器結構,整個網路上只有一臺機器安裝了ORACLE數據庫伺服器,那麼只需在每個要存取ORACLE伺服器的用戶端上定義該檔案,在伺服器上無需定義。也就是說,如果用戶端想連線到伺服器上的Oracle數據庫範例,用戶端就必須有tnsnames.ora這個檔案。一般在Oracle數據庫安裝的時候,它就會生成一個listener.ora(監聽器組態檔)、tnsnames.ora(網路服務名組態檔),因爲我們現在已經將Oracle安裝到本地了,並沒有安裝到伺服器上,爲了能夠測試連線伺服器是否需要tnsnames.ora檔案,我們假設D:\Oracle是伺服器上的一個目錄,D:\Oracle以外都是用戶端的目錄。
第一步:開啓資料夾(假設當前電腦是伺服器):D:\Oracle\product\11.2.0\dbhome_1\NETWORK\ADMIN
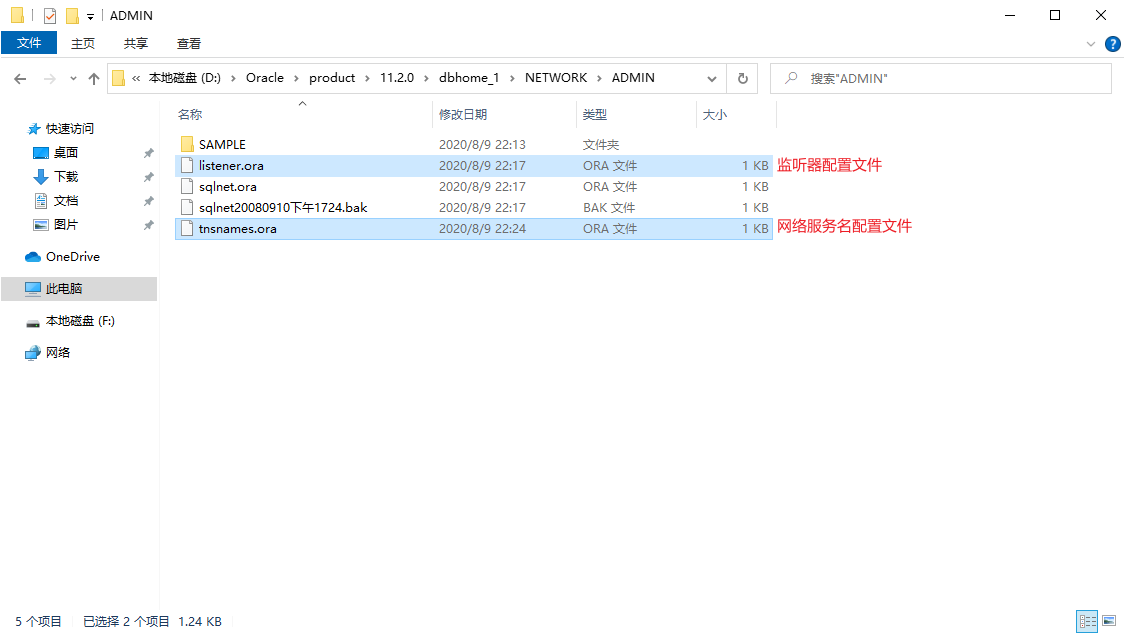
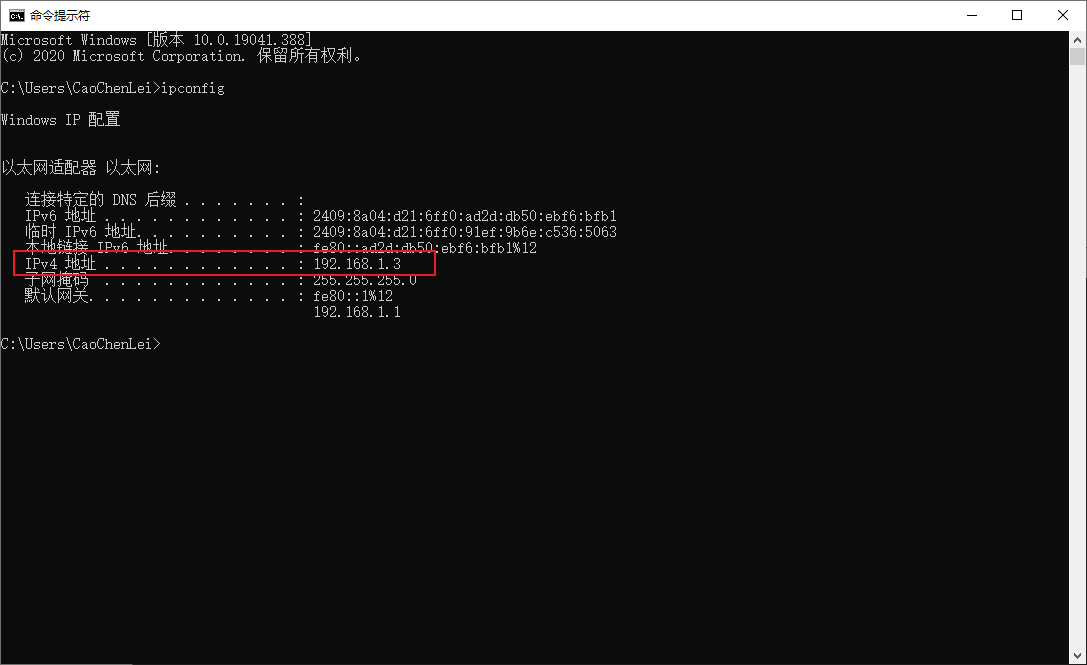
第二步:獲取伺服器IP地址(假設當前電腦是伺服器):192.168.1.3
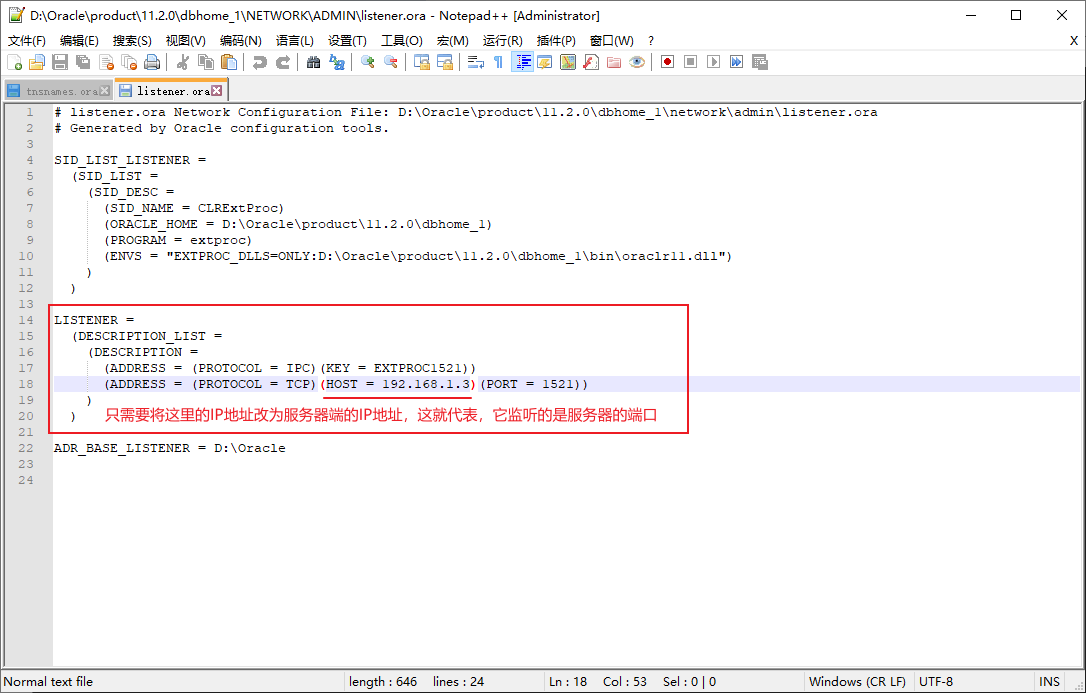
第三步:修改listener.ora檔案(假設當前電腦是伺服器):
第四步:修改tnsnames.ora檔案(假設當前電腦是伺服器):
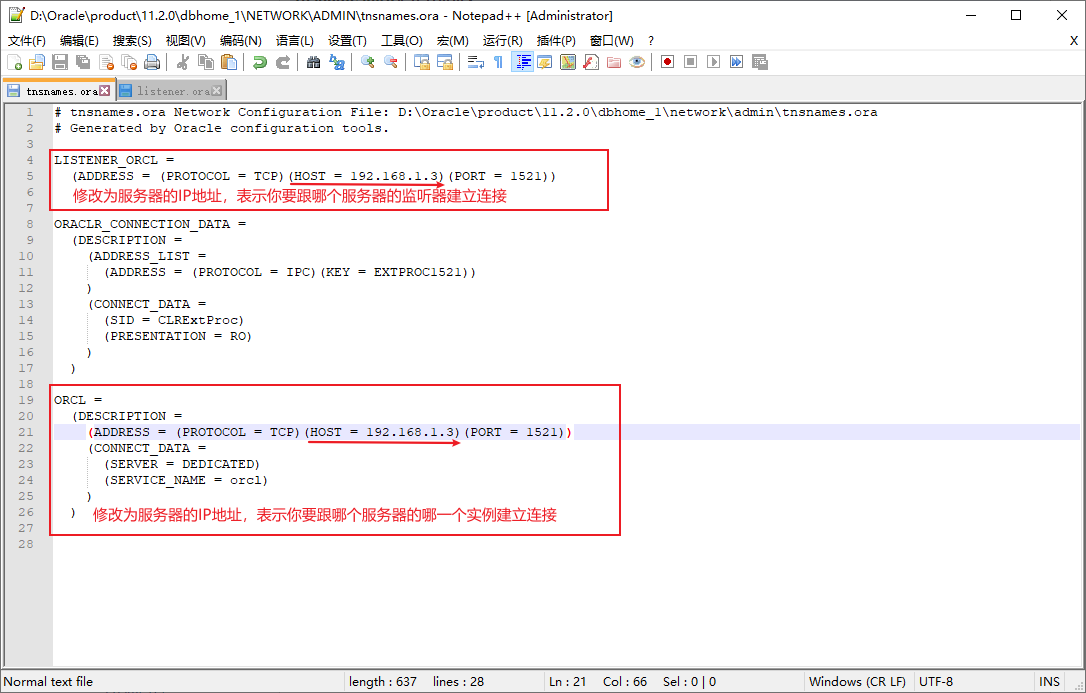
第五步:重新啓動伺服器Oracle的服務(假設當前電腦是伺服器):
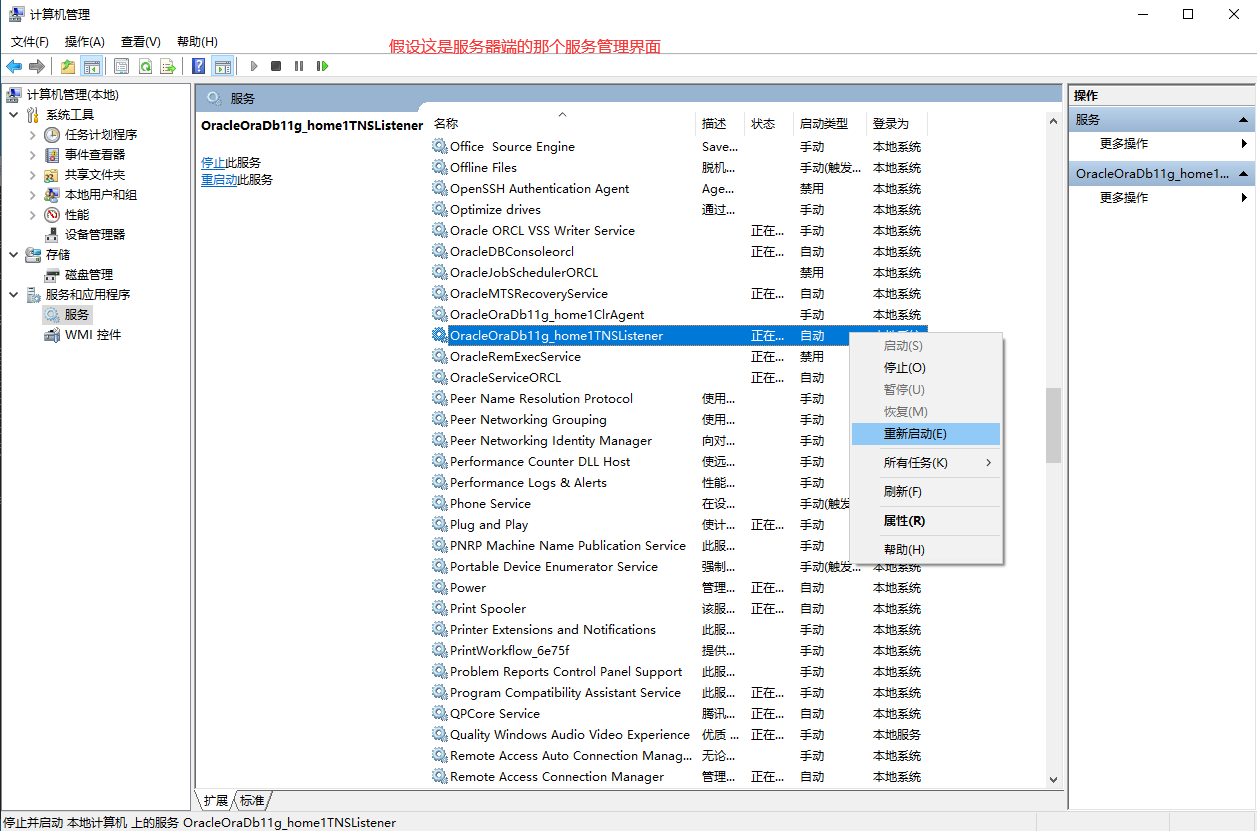
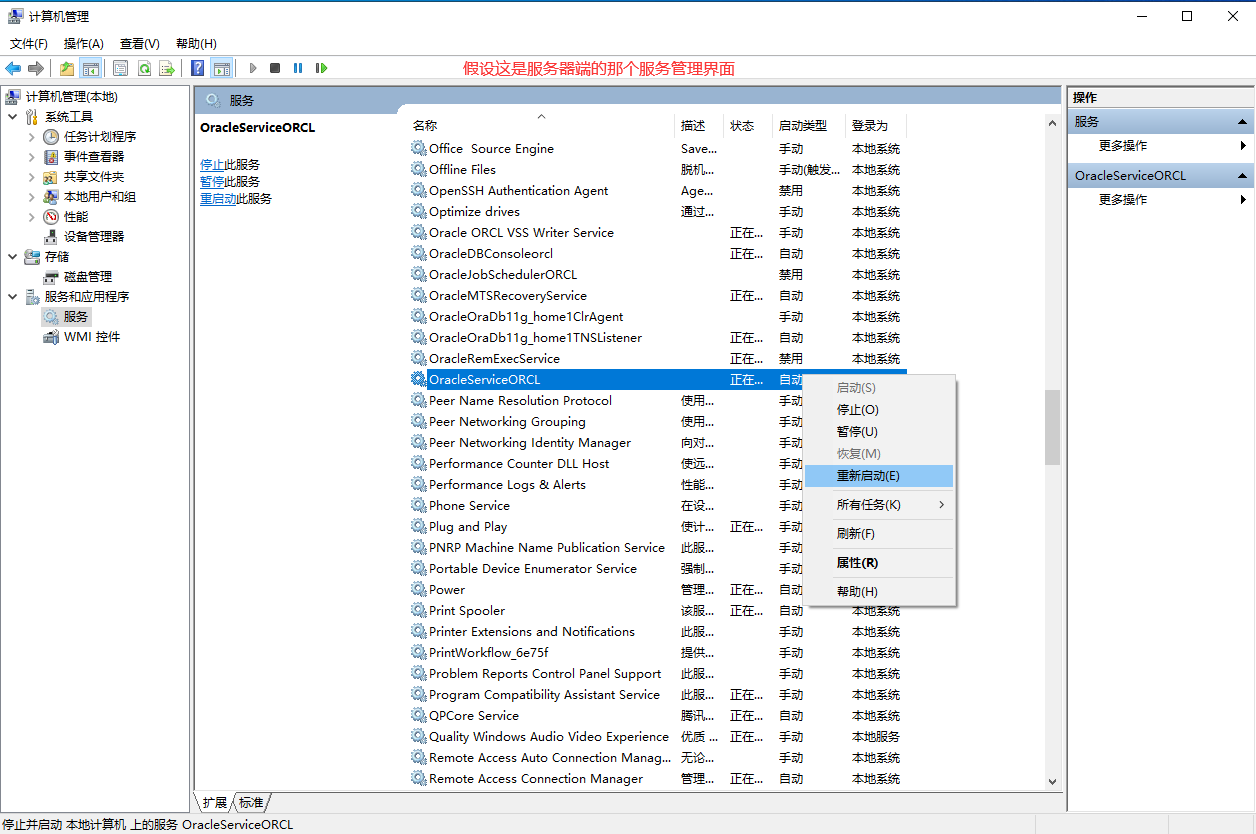
第六步:複製tnsnames.ora檔案到用戶端(假設當前電腦是用戶端):D:\Config
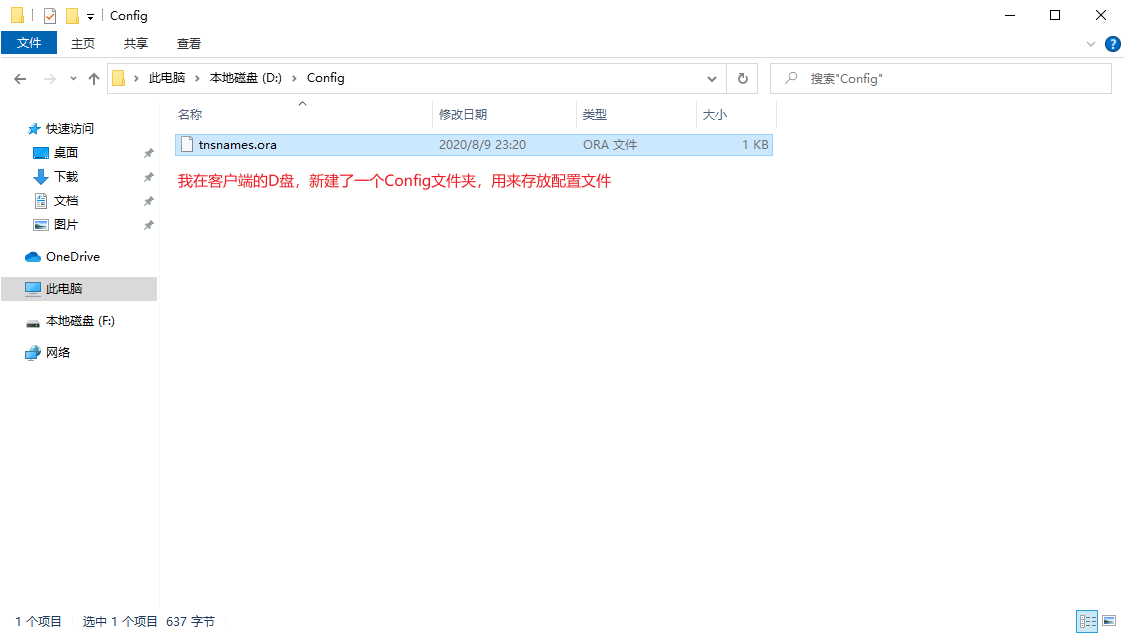
第七步:設定tnsnames.ora檔案到環境變數(假設當前電腦是用戶端):TNS_ADMIN = D:\Config
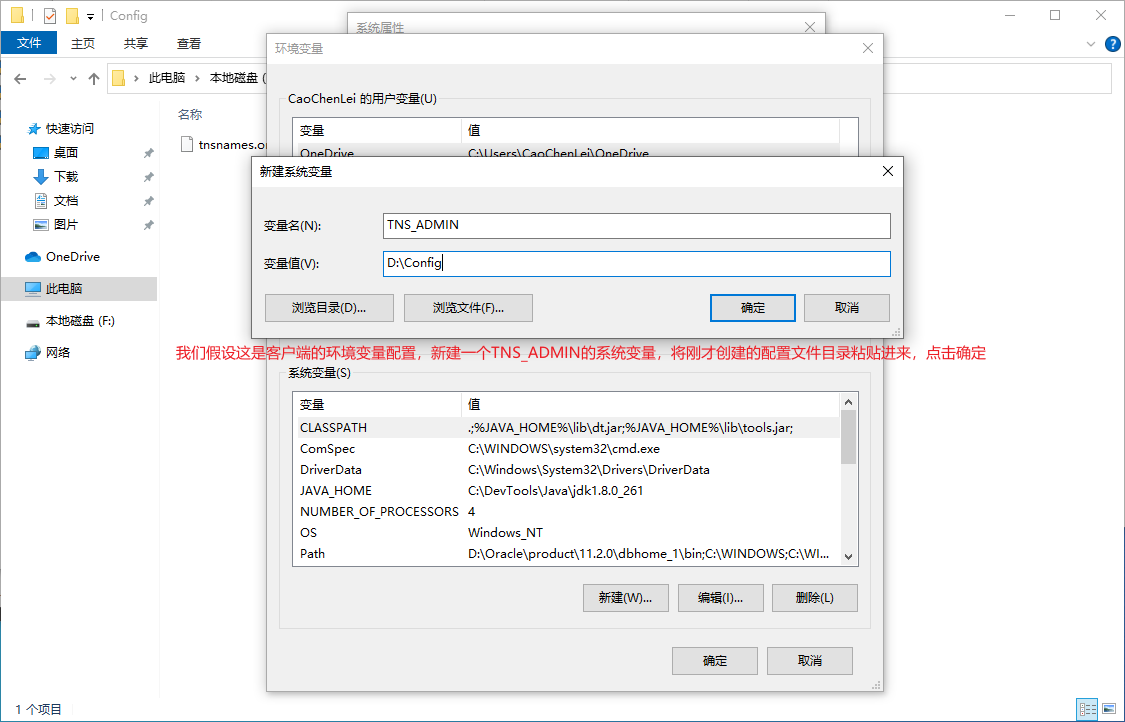
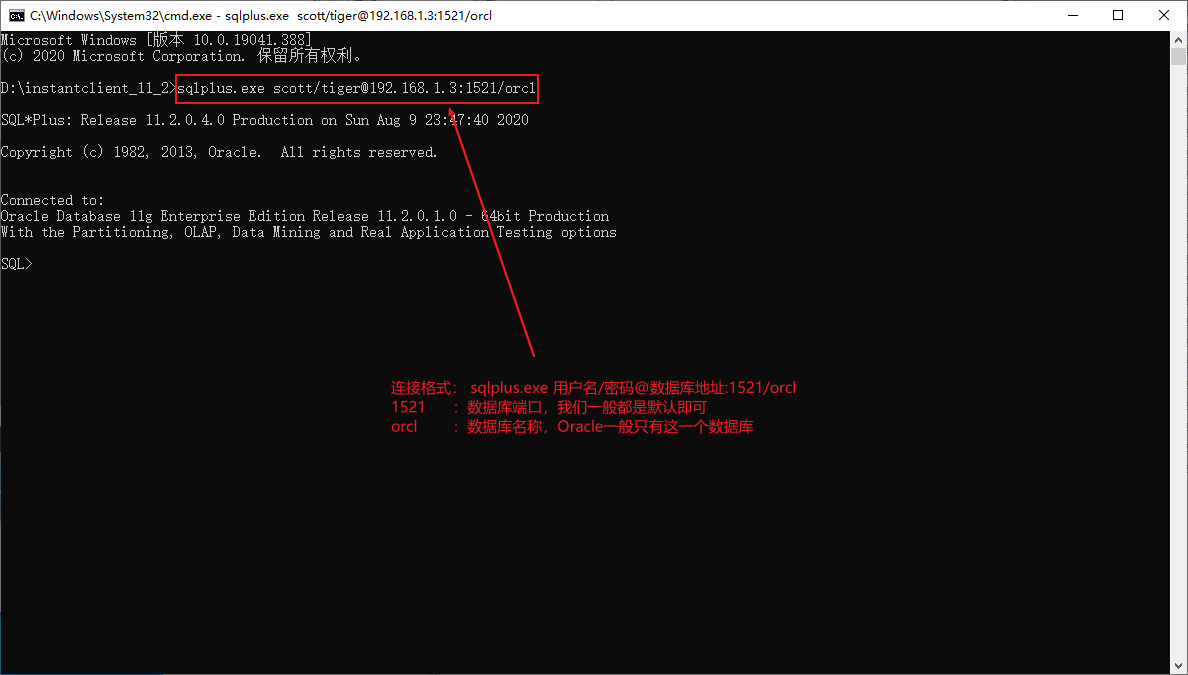
2.6、Oracle的命令列連線
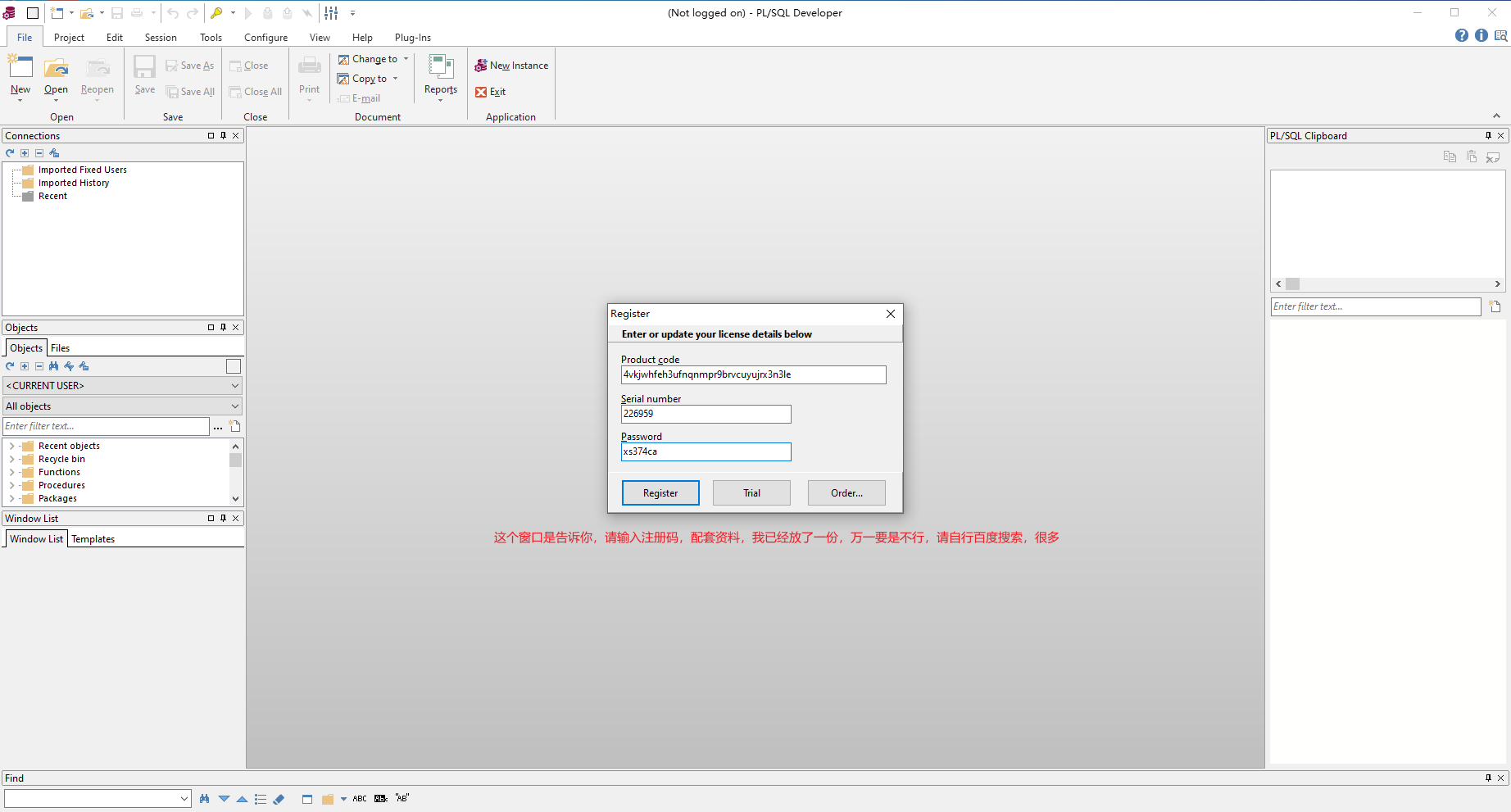
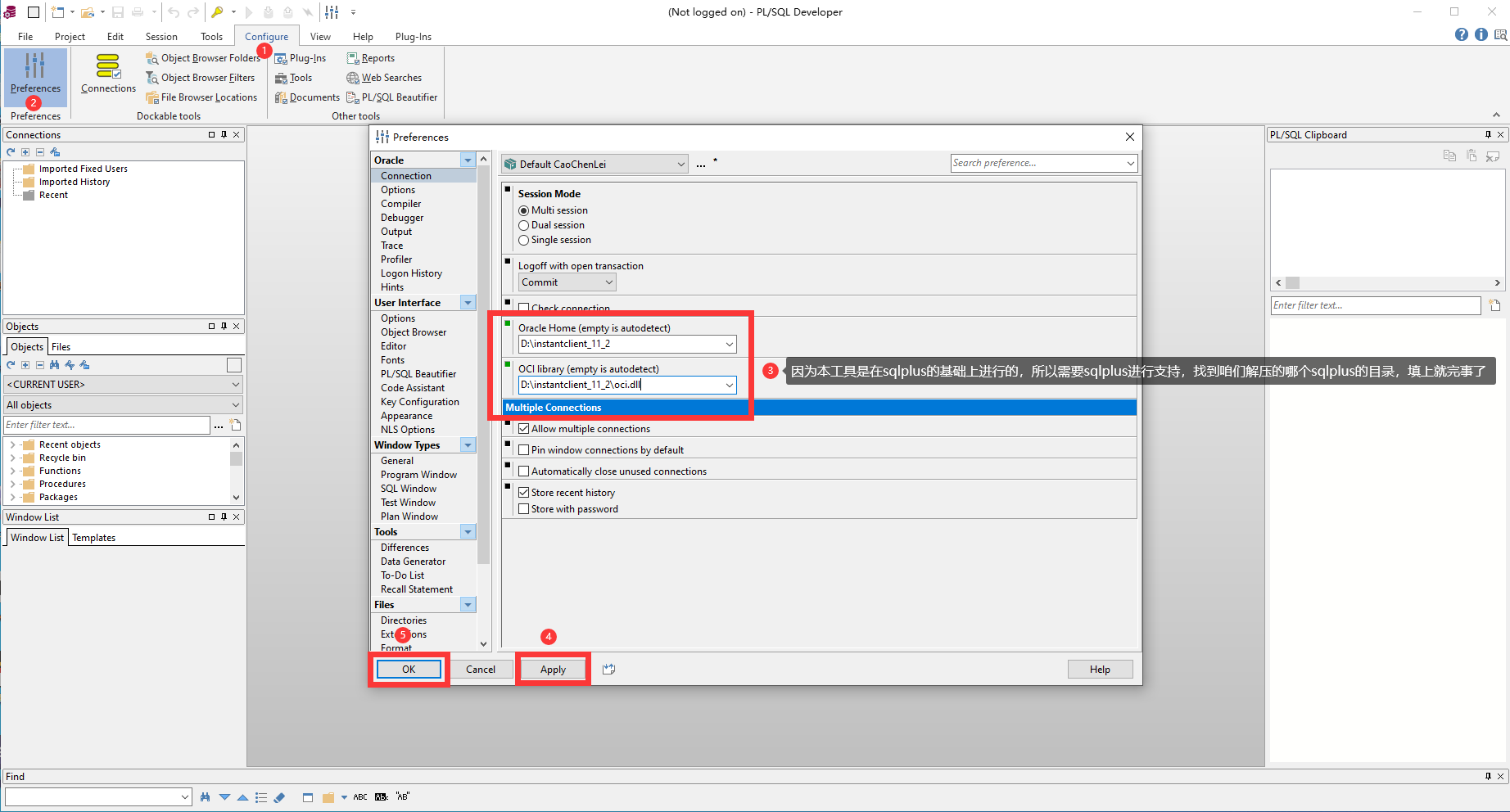
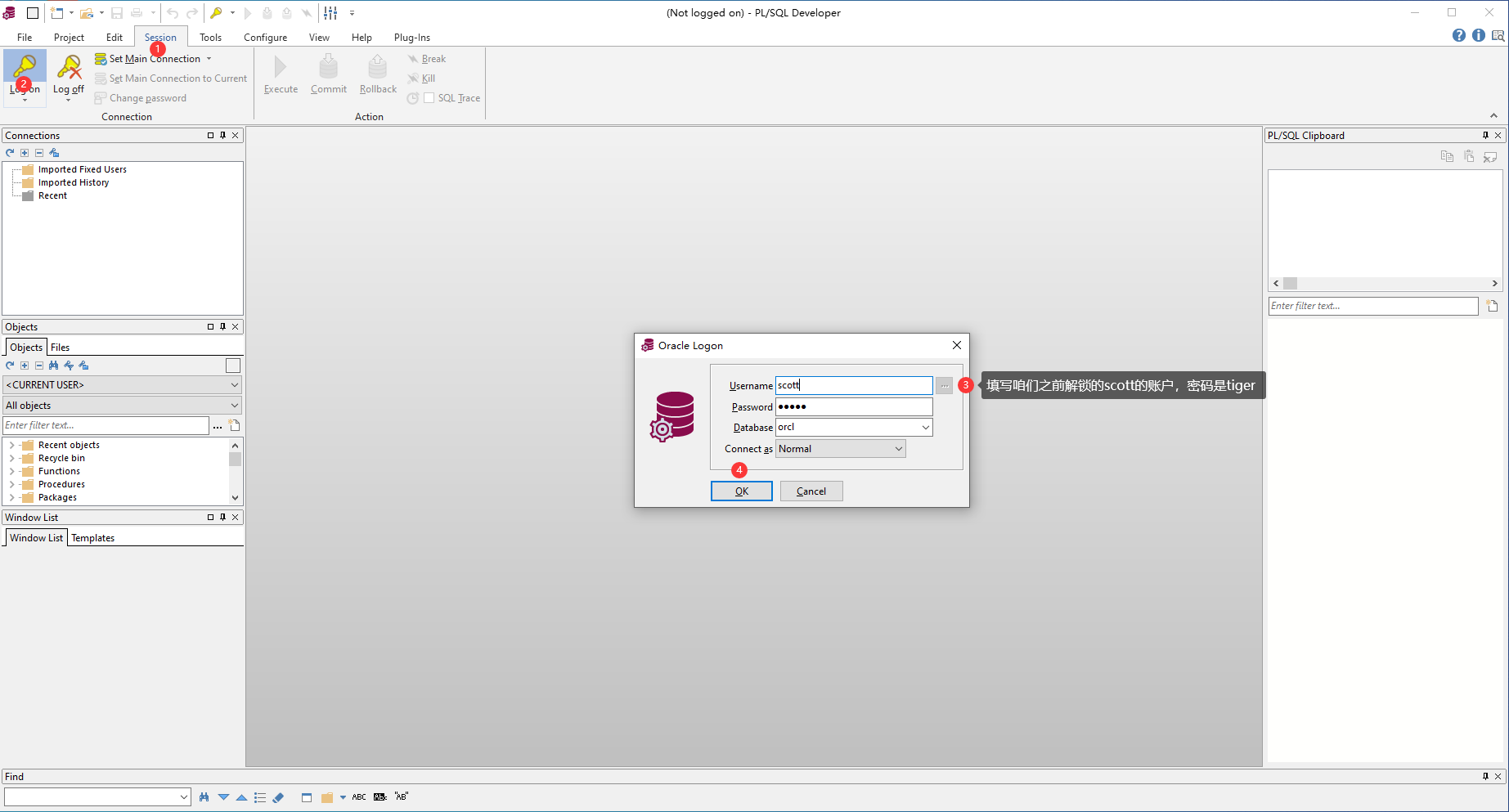
Oracle數據庫的連線不像MySQL那樣可以直接使用CMD視窗就能連線,它需要一些輔助軟體,也就是下邊的sqlplus。
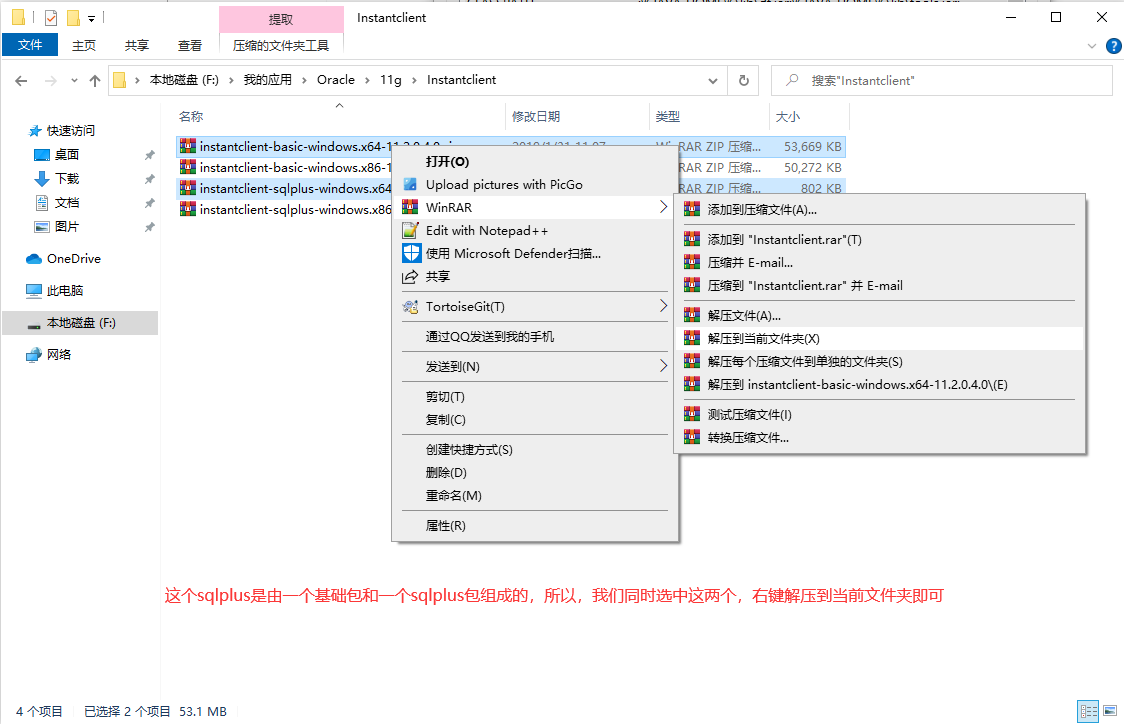
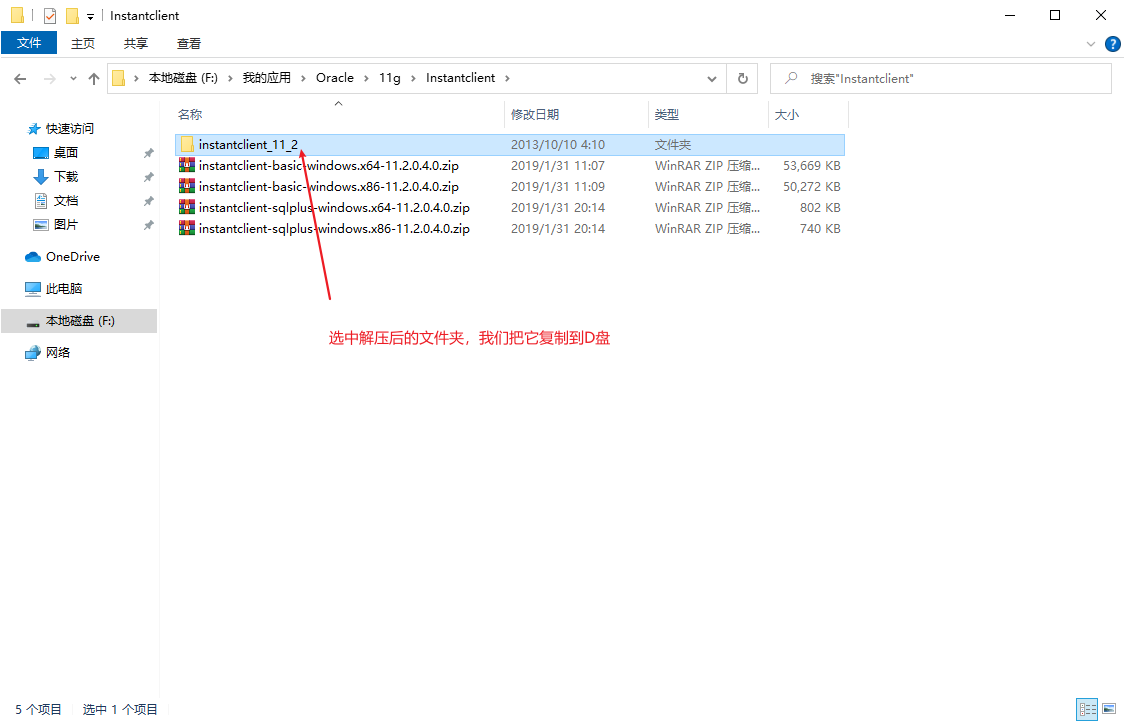
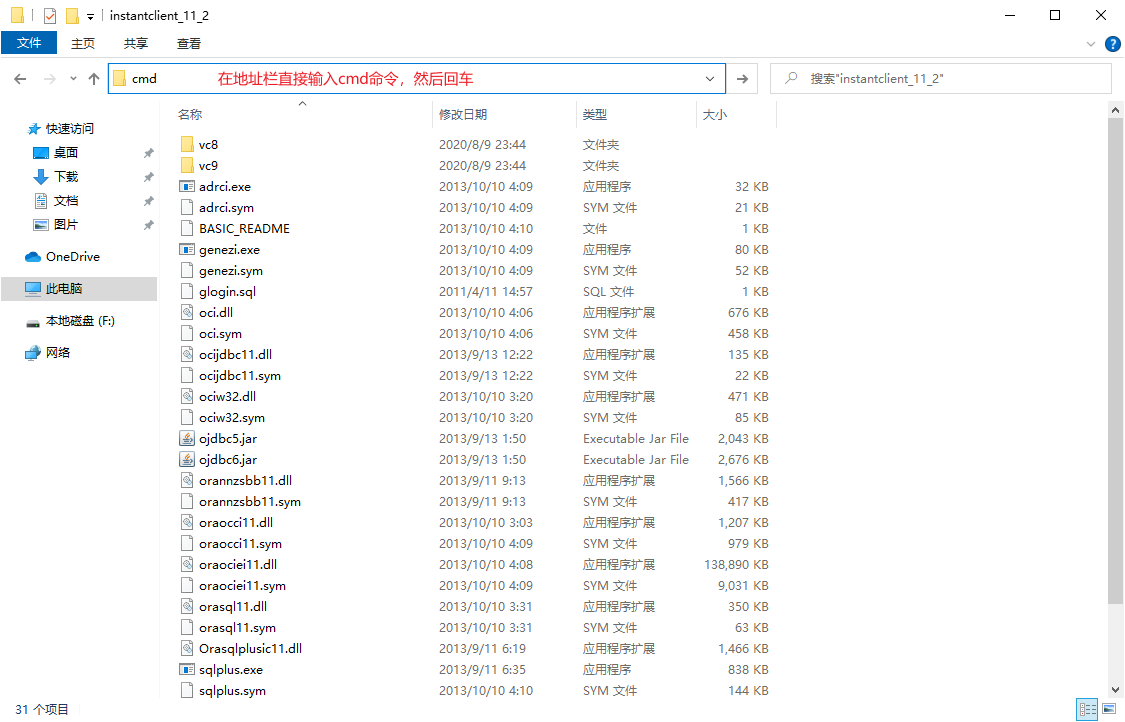
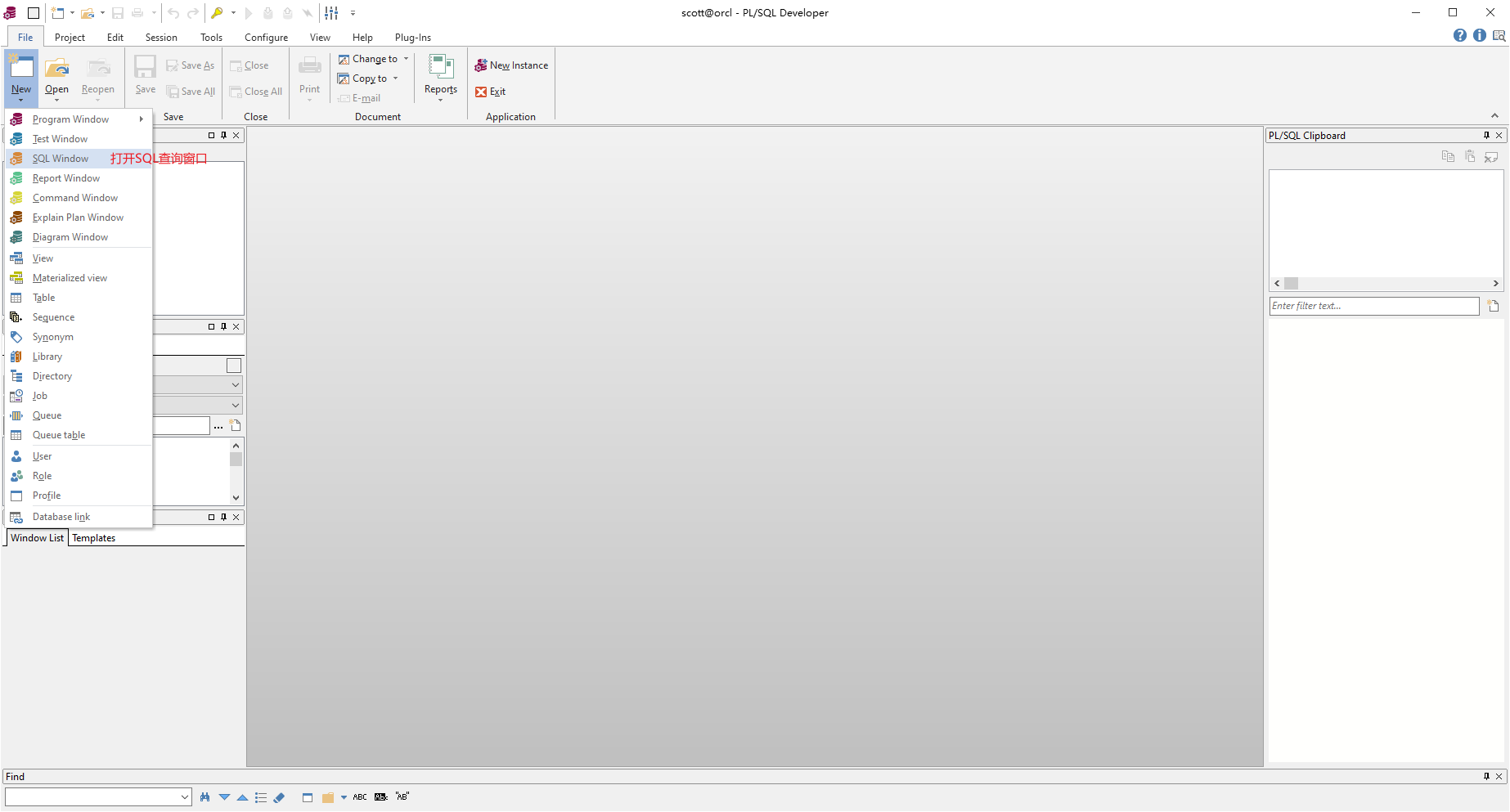
 2.7、Oracle的視窗化連線
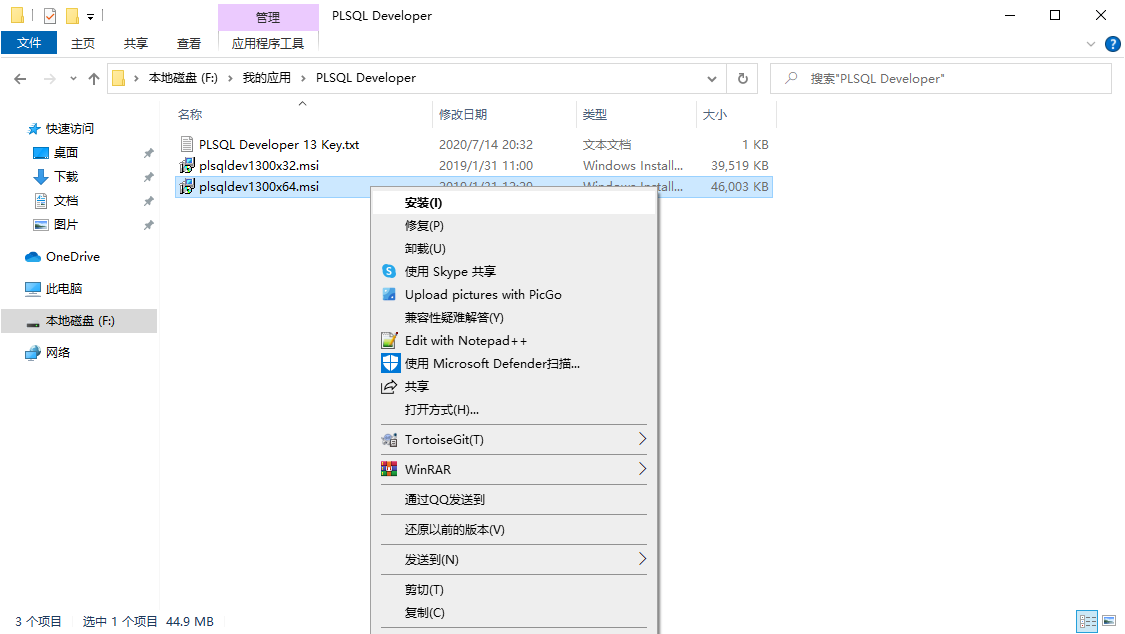
2.7、Oracle的視窗化連線
既然是使用視窗化連線,那我們就需要一個視窗化連線的工具,這裏我們使用的是程式碼補全提示比較好的PLSQL Developer。
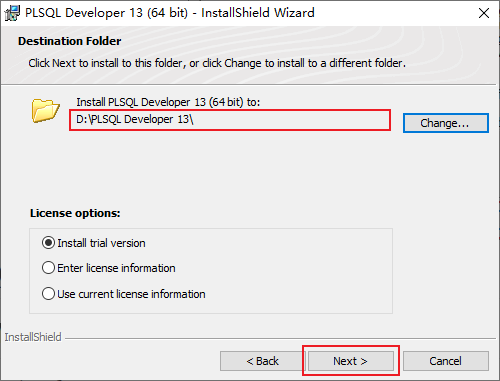
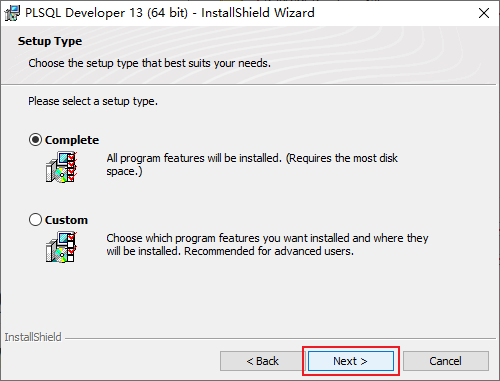
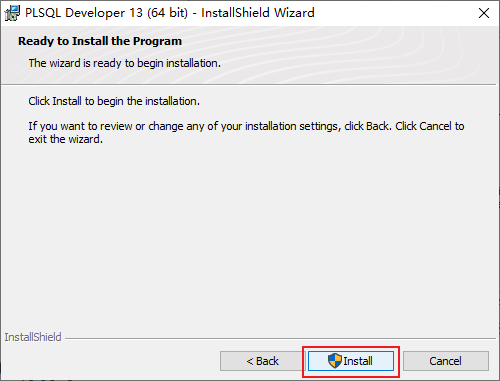
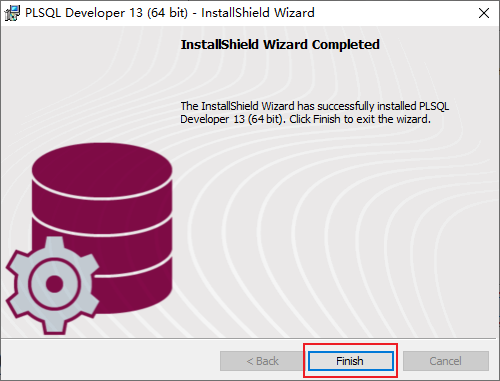
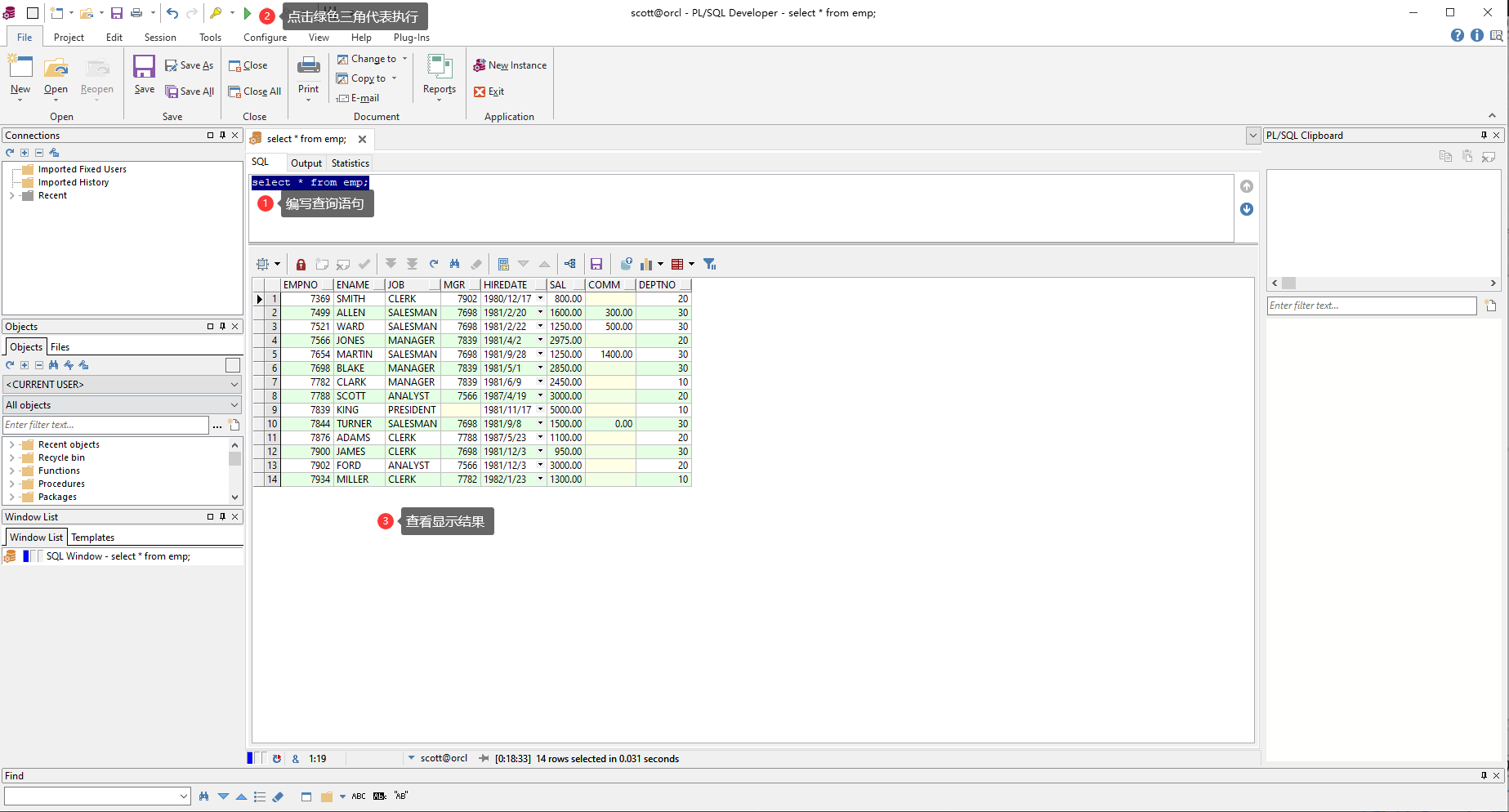
但是,如果你使用帶有中文的別名查詢會亂碼,這是因爲PLSQL Developer的字元集編碼和Oracle不一樣,那如何設定呢?首先查詢Oracle數據庫的字元集編碼:select userenv(‘language’) from dual;
2.8、Oracle的體系結構
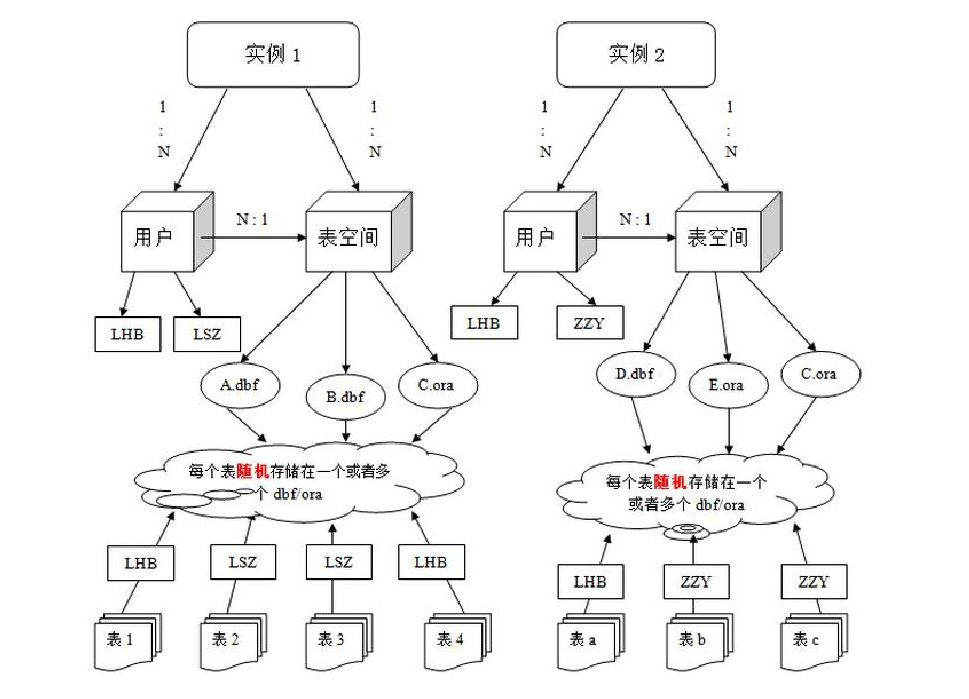
- 數據庫:Oracle是一種關係型的數據庫管理系統
- 數據庫範例:數據庫範例其實就是用來存取和使用數據庫的一塊進程,它只存在於記憶體中,就像Java中new出來的範例物件一樣
- 表空間:Oracle數據庫是通過表空間來儲存物理表的,一個數據庫範例可以有N個表空間,一個表空間下可以有N張表
- 使用者:Oracle數據庫建好後,要想在數據庫裡建表,必須先爲數據庫建立使用者,併爲使用者指定表空間
2.9、Oracle的測試使用者
scott測試使用者下的表:
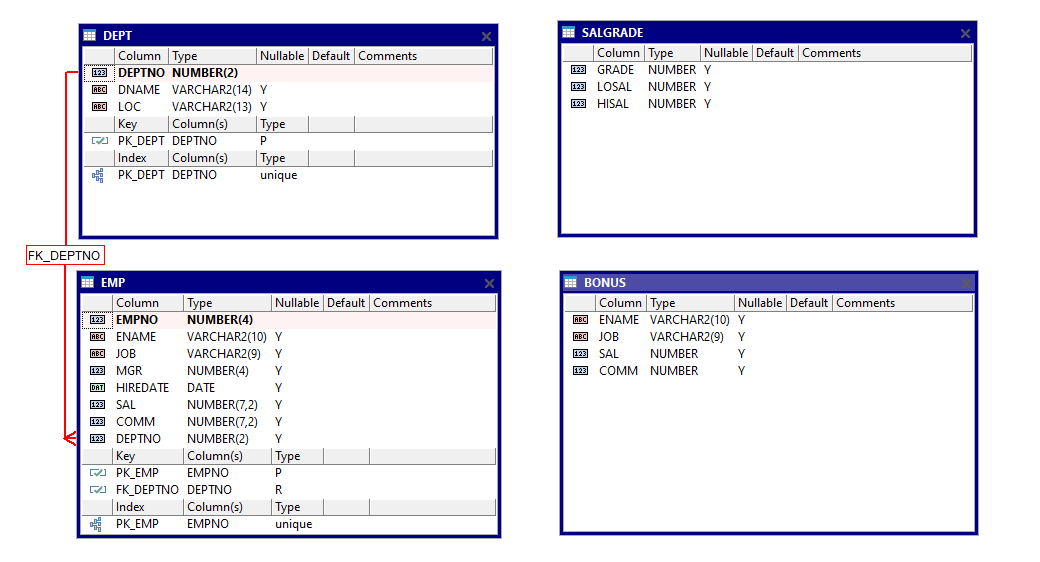
hr測試使用者下的表:
第三章 DQL語言
3.1、完整語法
一、語法
select [TOP|DISTINCT] [選擇列表]|[*]
from 數據源
[where 查詢條件]
[group by 分組條件]
[having 過濾條件]
[order by 排序條件 asc|desc nulls first|last];
二、執行順序
(5)select [(5-3)TOP|(5-2)DISTINCT] (5-1)[選擇列表]|[*]
(1)from 數據源
(2)[where 查詢條件]
(3)[group by 分組條件]
(4)[having 過濾條件]
(6)[order by asc|desc nulls first|last];
3.2、簡單查詢
--查詢所有員工的資訊
select * from emp;
3.3、別名查詢
--查詢所有員工的姓名
select e.ename from emp e;
3.4、去重查詢
--查詢所有部門的編號
select distinct e.deptno from emp e;
3.5、條件查詢
一、運算子
- 條件運算子:>、>=、<、<=、=、<=>、!=、<>
- 邏輯運算子:and、or、not
- 模糊運算子:
- like:%任意多個字元、_任意單個字元、如果有特殊字元,需要使用escape跳脫
- between and
- not between and
- in
- is null
- is not null
二、演示
--查詢工資>3000的員工資訊
select * from emp where sal > 3000;
3.6、分組查詢
--統計每個部門有多少個人
select deptno as "部門",count(*) as "人數" from emp group by deptno;
3.7、分組過濾
--統計部門人數>5人的部門的編號
select deptno as "部門", count(*) as "人數"
from emp
group by deptno
having count(*) > 5;
3.8、排序查詢
--按照員工主管編號由高到低進行排序,NULL值放到最後邊
select * from emp order by mgr desc nulls last;
3.9、分頁查詢
--查詢前10條員工的資訊
--注意:Oracle中不支援limit,需要在原始表加上一列:行號,然後使用子查詢來實現分頁
select *
from (select rownum hanghao,e.* from emp e) t
where t.hanghao >=1 and t.hanghao <= 10;
3.10、多表查詢
- 內連線
- 隱式內連線:select * from emp e1, dept d1 where e1.deptno = d1.deptno;
- 顯示內連線:select * from emp e1 inner join dept d1 on e1.deptno = d1.deptno;
- 外連線
- 左外連線
- 隱式左外連線:select * from emp e1,dept d1 where e1.deptno = d1.deptno(+);
- 顯示左外連線:select * from emp e1 left outer join dept d1 on e1.deptno = d1.deptno;
- 右外連線
- 隱式右外連線:select * from emp e1,dept d1 where e1.deptno(+) = d1.deptno;
- 顯示右外連線:select * from emp e1 right outer join dept d1 on e1.deptno = d1.deptno;
- 全外連線:select * from emp e1 full outer join dept d1 on e1.deptno = d1.deptno;
- 左外連線
- 交叉連線
- 隱式交叉連線:select * from emp, dept;
- 顯示交叉連線:select * from emp e1 cross join dept d1;
3.11、聯合查詢
- 並集運算:將兩個查詢結果進行合併
/*
union : 它會去除重複的,並且排序
union all : 不會去除重複的,不會排序
*/
--工資大於1500或者20號部門下的員工
select * from emp where sal > 1500
union
select * from emp where deptno = 20;
--工資大於1500或者20號部門下的員工
select * from emp where sal > 1500
union all
select * from emp where deptno = 20;
- 交集運算:找兩個查詢結果的交集
--工資大於1500並且20號部門下的員工
select * from emp where sal > 1500
intersect
select * from emp where deptno = 20;
- 差集運算:找兩個查詢結果的差集
--1981年入職員工(不包括總裁和經理)
select * from emp where to_char(hiredate,'yyyy') = '1981'
minus
select * from emp where job = 'PRESIDENT' or job = 'MANAGER';
- 注意事項:
- 列的型別要一致
- 列的順序要一致
- 列的數量要一致,如果不夠,可以使用null填充
3.12、子查詢
- 單行子查詢:>、>=、<、<=、!=、<>、=、<=>
- 多行子查詢:in、not in、any、some、all、exits
1、in的使用
--查詢所有經理的資訊
select * from emp where empno in (select mgr from emp where mgr is not null);
2、not in的使用
--查詢不是經理的資訊
select * from emp where empno not in (select mgr from emp where mgr is not null);
3、any的使用
--查詢出比10號部門任意一個員工薪資高的員工資訊
select * from emp where sal > any (select sal from emp where deptno = 10);
4、some的使用
--查詢出比10號部門任意一個員工薪資高的員工資訊
select * from emp where sal > some (select sal from emp where deptno = 10);
5、all的使用
--查詢出比20號部門所有員工薪資高的員工資訊
select * from emp where sal > all (select sal from emp where deptno = 20);
6、exits的使用
--查詢有員工的部門的資訊
select * from dept d1 where exists (select * from emp e1 where e1.deptno = d1.deptno);
第四章 函數大全
具體用法,請參考資料中的Oracle函數大全.chm
4.1、數值型函數

4.2、字元型函數

4.3、日期函數

4.4、轉換函數

4.5、聚組函數

4.6、分析函數

4.7、其它函數

第五章 DCL語言
5.1、建立表空間
一、語法
create tablespace 表空間的名稱
datafile '檔案的路徑'
size 初始化大小
autoextend on
next 每次擴充套件的大小;
二、演示
create tablespace mytest
datafile 'd:/mytest.dbf'
size 100m
autoextend on
next 10m;
5.2、刪除表空間
一、語法
drop tablespace 表空間的名稱;
二、演示
drop tablespace mytest;
5.3、建立使用者
一、語法
create user 使用者名稱
identified by 密碼
default tablespace 表空間的名稱;
二、演示
create user zhangsan
identified by 123456
default tablespace mytest;
5.4、刪除使用者
5.5、授權使用者
一、語法
grant 系統許可權列表 to 使用者名稱;
或者
grant 實體許可權列表 on 表名稱 to 使用者名稱;
二、許可權列表
系統許可權分類:(系統許可權只能由DBA使用者授出)
- DBA:擁有全部特權,是系統最高許可權,只有DBA纔可以建立數據庫結構。
- RESOURCE:擁有Resource許可權的使用者只可以建立實體,不可以建立數據庫結構。
- CONNECT:擁有Connect許可權的使用者只可以登錄Oracle,不可以建立實體,不可以建立數據庫結構。
實體許可權分類:select、update、insert、alter、index、delete、all
三、演示
grant CONNECT to zhangsan;
或者
grant CONNECT,RESOURCE to zhangsan;
或者
grant CONNECT,RESOURCE,DBA to zhangsan;
或者
grant DBA to zhangsan;
或者
grant all on emp to zhangsan;
5.6、取消授權
一、語法
revoke 系統許可權列表 from 使用者名稱;
或者
revoke 實體許可權列表 on 表名稱 from 使用者名稱;
二、注意事項
系統許可權只能由DBA使用者回收
二、演示
revoke CONNECT from zhangsan;
或者
revoke CONNECT,RESOURCE from zhangsan;
或者
revoke CONNECT,RESOURCE,DBA from zhangsan;
或者
revoke DBA from zhangsan;
或者
revoke all on emp from zhangsan;
5.7、修改密碼
一、語法
alter user 使用者名稱 identified by "密碼";
二、演示
alter user zhangsan identified by "123456";
第六章 DDL語言
6.1、數據型別
注意:這裏整理的都是常用的並沒有全部整理出所有型別
- 字串型別
- CHAR:定長字串,它會用空格填充來達到其最大長度,最多可以儲存2000位元組的資訊
- NCHAR:這是一個包含UNICODE格式數據的定長字串,最多可以儲存2000位元組的資訊
- VARCHAR2:變長字串,它不會用空格填充來達到其最大長度,最多可以儲存4000位元組的資訊
- NVARCHAR2:這是一個包含UNICODE格式數據的變長字串,最多可以儲存4000位元組的資訊
- 數值型別
- NUMBER:NUMBER(p,s)是最常見的數位型別,關於NUMBER的有效位§和精確位(s)遵循以下規則:
- p:是有效數據總位數,取值範圍爲【1-38】,預設值是38
- s:表示精確到多少位,取值範圍爲【-84-127】,預設值是0
- INTEGER:INTEGER是NUMBER的子型別,它等同於NUMBER(38,0),用來儲存整數
- FLOAT:Float(n)是NUMBER的子型別,數 n 指示位的精度,n值的範圍可以從1到126
- NUMBER:NUMBER(p,s)是最常見的數位型別,關於NUMBER的有效位§和精確位(s)遵循以下規則:
- 日期型別
- DATE:DATE是最常用的日期數據型別,它可以儲存日期和時間資訊,雖然可以用字元或數位型別表示日期和時間資訊,但是日期數據型別具有特殊關聯的屬性。Oracle 爲每個日期值儲存以下資訊: 世紀、 年、 月、 日期、 小時、 分鐘和秒,一般佔用7個位元組的儲存空間
- TIMESTAMP:這是一個7位元組或12位元組的定寬日期/時間數據型別。它與DATE數據型別不同,因爲TIMESTAMP可以包含小數秒,帶小數秒的TIMESTAMP在小數點右邊最多可以保留9位
6.2、建立表
一、語法
create table 表名(
列名 列的型別 [列的約束],
列名 列的型別 [列的約束]
);
二、演示
create table users(
id number,
username varchar2(20),
password varchar2(20)
);
6.3、複製表
一、語法
create table 表名 as 查詢語句;
二、演示
create table emp_copy as
select * from emp
;
6.4、刪除表
一、語法
方式一:drop table 表名;
方式二:truncate table 表名;
二、演示
方式一:drop table emp_copy;
方式二:truncate table emp_copy;
6.5、修改表
1、新增一列
格式:alter table 表名 add 列名 列的型別;
演示:alter table users add phone varchar2(11);
2、修改列名
格式:alter table 表名 rename column 舊列名 to 新列名;
演示:alter table users rename column phone to mobile;
3、修改型別
格式:alter table 表名 modify 列名 列的型別;
演示:alter table users modify mobile char(11);
4、刪除一列
格式:alter table 表名 drop column 列名;
演示:alter table users drop column mobile;
5、修改表名
格式:rename 舊錶名 to 新表名;
演示:rename users to myusers;
6.6、表約束
一、語法
CREATE TABLE 表名(
列名 列的型別 primary key,--主鍵約束
列名 列的型別 not null,--非空約束
列名 列的型別 unique,--唯一約束
列名 列的型別 check(列名 in (檢查列表)),--檢查約束
constraint 約束名 foreign key(欄位名) references 主表(被參照列)--外來鍵約束
) ;
二、演示
--商品分類表
create table category(
cid number primary key,
cname varchar2(20)
);
--商品詳情表
create table product(
pid number primary key,--主鍵約束
pname varchar2(50) not null,--非空約束
pimg varchar2(50) unique,--唯一約束
pflag varchar2(10) check(pflag in ('上架','下架')),--檢查約束
cid number,
constraint FK_CATEGORY_ID foreign key(cid) references category(cid)--外來鍵約束
);
三、修改
1、主鍵約束
新增
alter table product add constraint PK_PRODUCT_PID primary key(pid);
刪除
alter table product drop constraint PK_PRODUCT_PID;
或者
alter table product drop primary key;
2、非空約束
新增
alter table product modify pname not null;
刪除
alter table product modify pname null;
3、唯一約束
新增
alter table product add constraint UK_PRODUCT_PIMG unique(pimg);
刪除
alter table product drop constraint UK_PRODUCT_PIMG;
或者
alter table product drop unique(pimg);
4、檢查約束
新增
alter table product add constraint CK_PRODUCT_PFLAG check(pflag in ('上架','下架'));
刪除
alter table product drop constraint CK_PRODUCT_PFLAG;
5、外來鍵約束
新增
alter table product add constraint FK_PRODUCT_ID foreign key(cid) references category(cid);
刪除
alter table product drop constraint FK_PRODUCT_ID;
第七章 DML語言
7.1、插入語句
格式:insert into 表名(列名1,列名2,...) values(值1,值2,...);
演示:insert into category(cid,cname) values(1,'電視');
注意:commit;
7.2、修改語句
格式:update 表名 set 列名1=值1,列名2=值2,... where 查詢條件;
演示:update category set cname='汽車' where cid = 1;
注意:commit;
7.3、刪除語句
格式:delete from 表名 where 查詢條件;
演示:delete from category where cid = 1;
注意:commit;
第八章 TCL語言
8.1、事務
一、含義
一條或多條sql語句組成一個執行單位,一組sql語句要麼都執行要麼都不執行
二、特點(ACID)
- 原子性:一個事務是不可再分割的整體,要麼都執行要麼都不執行
- 一致性:一個事務的執行不能破壞數據庫數據的完整性和一致性
- 隔離性:一個事務不受其它事務的幹擾,多個事務是互相隔離的
- 永續性:一個事務一旦提交了,則永久的持久化到本地
三、分類
1、開啓事務
Oracle 11g中事務是隱式自動開始的,它不需要使用者顯示的執行開始事務語句
2、編寫一組邏輯sql語句
注意:sql語句支援的是insert、update、delete
【設定回滾點】
savepoint 回滾點名;
3、結束事務
提交:commit;
回滾:rollback;
回滾到指定的地方: rollback to 回滾點名;
8.2、事務併發(讀問題)
一、事物的併發問題如何發生?
多個事務同時操作同一個數據庫的相同數據時
二、事務的併發問題都有哪些?
- 髒讀:一個事務讀到了另一個事務還未提交的update數據,導致多次查詢的結果不一樣(Oracle中不會產生)
- 不可重複讀:一個事務讀到了另一個事務已經提交的update數據,導致多次查詢結果不一致
- 幻讀:一個事務讀到了另一個事務已經提交的insert數據,導致多次查詢的結果不一樣
三、事物的併發問題如何解決?
通過設定隔離級別來解決併發問題
四、隔離級別
Oracle中只支援READ COMMITTED、SERIALIZABLE、READ ONLY、READ WRITE,這些語句是互斥的,不能同時設定兩個或兩個以上的選項,一般預設即可。
8.3、丟失更新(寫問題)
一、定義
在事務的隔離級別內容中,能夠了解到兩個不同的事務在併發的時候可能會發生數據的影響。細心的話可以發現事務隔離級別章節中,髒讀、不可重複讀、幻讀三個問題都是由事務A對數據進行修改、增加,事務B總是在做讀操作。如果兩事務都在對數據進行修改則會導致另外的問題:丟失更新。
二、解決
- 悲觀鎖:認爲兩個事務更新操作一定會發生丟失更新
- 解決:通過在語句後邊新增for update來實現行級上鎖,所以又稱爲「行級鎖」,例如:select * from t_account t wheret.id=‘1’ for update;
- 樂觀鎖:認爲事務不一定會產生丟失更新,讓事務進行併發修改,不對事務進行鎖定
- 解決:由程式設計師自己解決,可以通過給數據表新增自增的version欄位或時間戳timestamp,進行數據修改時,數據庫會檢測version欄位或者時間戳是否與原來的一致,若不一致,拋出異常或者重新查詢
三、注意
對於賬戶交易建議直接使用悲觀鎖,數據庫的效能很高,併發度不是很高的場景兩者效能沒有太大差別。如果是交易減庫存的操作可以考慮樂觀鎖,保證併發度。
第九章 高階部分
9.1、序列
一、含義
序列是Oracle數據庫中特有的,使用序列可以生成類似於 auto_increment 這種ID自動增長 1,2,3,4,5… 的效果
二、語法
create sequence 序列名稱
start with 從幾開始
increment by 每次增長多少
[maxvalue 最大值] | nomaxvalue
[minvalue 最小值] | nominvalue
cycle | nocycle --是否自動回圈
[cache 快取數量] | nocache;
三、演示
--建立序列
create sequence auto_increment_seq
start with 1
increment by 1
nomaxvalue
minvalue 1
nocycle
cache 10000;
--呼叫序列
select auto_increment_seq.nextval from dual;
select auto_increment_seq.currval from dual;
9.2、PLSQL程式設計
9.2.1、格式
declare
--宣告變數
begin
--業務邏輯
end;
9.2.2、變數
declare
--宣告變數
-- 格式一:變數名 變數型別;
-- 格式二:變數名 變數型別 := 初始值;
-- 格式三:變數名 變數型別 := &文字方塊名;
-- 格式四:變數名 表名.欄位名%type;
-- 格式五:變數名 表名%rowtype;
vnum number;
vage number := 28;
vabc number := &abc;--輸入一個數值,從一個文字方塊輸入
vsal emp.sal%type; --參照型的變數,代表emp.sal的型別
vrow emp%rowtype; --記錄型的變數,代表emp一行的型別
begin
--業務邏輯
dbms_output.put_line(vnum); --輸出一個未賦值的變數
dbms_output.put_line(vage); --輸出一個已賦值的變數
dbms_output.put_line(vabc); --輸出一個文字方塊輸入的變數
select sal into vsal from emp where empno = 7654; --將查詢到的sal內容存入vsal並輸出
dbms_output.put_line(vsal);
select * into vrow from emp where empno = 7654; --將查詢到的一行內容存入vrow並輸出
dbms_output.put_line(vrow.sal);
dbms_output.put_line(123); --輸出一個整數
dbms_output.put_line(123.456); --輸出一個小數
dbms_output.put_line('Hello,World'); --輸出一個字串
dbms_output.put_line('Hello'||',World'); --輸出一個拼接的字串,||拼接符Oracle特有
dbms_output.put_line(concat('Hello',',World')); --輸出一個拼接的字串,concat函數比較通用
end;
9.2.3、if判斷
一、語法
if 條件1 then
elsif 條件2 then
else
end if;
二、演示
declare
age number := &age;
begin
if age < 18 then
dbms_output.put_line('小屁孩');
elsif age >= 18 and age <= 24 then
dbms_output.put_line('年輕人');
elsif age > 24 and age < 40 then
dbms_output.put_line('老司機');
else
dbms_output.put_line('老年人');
end if;
end;
9.2.4、while回圈
一、語法
while 條件 loop
end loop;
二、演示
--輸出1~10
declare
i number := 1;
begin
while i <= 10 loop
dbms_output.put_line(i);
i := i + 1;
end loop;
end;
9.2.5、for回圈
一、語法
for 變數 in [reverse] 起始值..結束值 loop
end loop;
二、演示
--輸出1~10
declare
begin
for i in reverse 1 .. 10 loop
dbms_output.put_line(i);
end loop;
end;
9.2.6、loop回圈
一、語法
loop
exit when 條件
end loop;
二、演示
--輸出1~10
declare
i number := 1;
begin
loop
exit when i > 10;
dbms_output.put_line(i);
i := i + 1;
end loop;
end;
9.2.7、意外
一、含義
意外是程式執行的過程發生的異常,相當於是Java中的異常
二、語法
declare
--宣告變數
begin
--業務邏輯
exception
--處理異常
when 異常1 then
...
when 異常2 then
...
when others then
...處理其它異常
end;
三、分類
-
系統異常
- zero_divide :除數爲零異常
- value_error :型別轉換異常
- no_data_found : 沒有找到數據
- too_many_rows : 查詢出多行記錄,但是賦值給了%rowtype一行數據變數
-
自定義異常
-
declare --宣告變數 異常名稱 exception; begin --業務邏輯 if 觸發條件 then raise 異常名稱; --拋出自定義的異常 exception --處理異常 when 異常名稱 then dbms_output.put_line('輸出了自定義異常'); when others then dbms_output.put_line('輸出了其它的異常'); end;
-
四、演示
1、內建系統異常
vi number;
vrow emp%rowtype;
begin
--以下四行對應四個異常,測試請依次放開
vi := 8/0;
--vi := 'aaa';
--select * into vrow from emp where empno = 1234567;
--select * into vrow from emp;
exception
when zero_divide then
dbms_output.put_line('發生除數爲零異常');
when value_error then
dbms_output.put_line('發生型別轉換異常');
when no_data_found then
dbms_output.put_line('沒有找到數據異常');
when too_many_rows then
dbms_output.put_line('查詢出多行記錄,但是賦值給了%rowtype一行數據變數');
when others then
dbms_output.put_line('發生了其它的異常' || sqlerrm);
end;
2、拋出系統異常
--查詢指定編號的員工,如果沒有找到,則拋出系統異常
declare
--1.宣告一個變數 %rowtype
vrow emp%rowtype;
begin
--查詢員工資訊,儲存起來
select * into vrow from emp where empno = 8000;
--判斷是否觸發異常的條件
if vrow.sal is null then
--拋出系統異常
raise_application_error(-20001,'員工工資爲空');
end if;
exception
when others then
dbms_output.put_line('輸出了其它的異常' || sqlerrm);
end;
3、拋出自定義異常
--查詢指定編號的員工,如果沒有找到,則拋出自定義異常
declare
--1.宣告一個變數 %rowtype
vrow emp%rowtype;
--2.宣告一個自定義的異常
no_emp exception;
begin
--查詢員工資訊,儲存起來
select * into vrow from emp where empno = 8000;
--判斷是否觸發異常的條件
if vrow.sal is null then
raise no_emp; --拋出自定義的異常
end if;
exception
when no_emp then
dbms_output.put_line('輸出了自定義異常');
when others then
dbms_output.put_line('輸出了其它的異常' || sqlerrm);
end;
9.3、索引
一、含義
索引相當於是一本書的目錄,能夠提高我們的查詢效率
二、語法
1、建立索引
create [UNIQUE]|[BITMAP] index 索引名 on 表名(列名1,列名2,...);
2、修改索引
--重新命名索引
alter index 索引名稱 rename to 新的名稱;
--合併索引
alter index 索引名稱 coalesce;
--重建索引
alter index 索引名稱 rebuild;
--修改某列
先刪除,在建立
3、刪除索引
drop index 索引名稱;
三、演示
1、建立索引
create index INX_CATEGORY_CNAME on category(cname);
2、修改索引
--重新命名索引
alter index INX_CATEGORY_CNAME rename to INX_CATEGORY_CNAME_NEW;
--合併索引
alter index INX_CATEGORY_CNAME_NEW coalesce;
--重建索引
alter index INX_CATEGORY_CNAME_NEW rebuild;
--修改某列
先刪除,在建立
3、刪除索引
drop index INX_CATEGORY_CNAME;
9.4、檢視
一、含義
檢視是對查詢結果的一個封裝,視圖裏面所有的數據,都是來自於它查詢的那張表,檢視本身不儲存任何數據,但是可以修改原數據,但是不建議這樣使用
二、語法
1、建立檢視
create view 檢視名稱
as 查詢語句
[with read only];
2、修改檢視
create or replace view 檢視名稱
as 查詢語句
[with read only];
3、刪除檢視
drop view 檢視名稱;
三、演示
1、建立檢視
create view view_emp as
select ename,job,mgr from emp;
2、修改檢視
create or replace view view_emp as
select ename,job,mgr,deptno from emp;
3、刪除檢視
drop view view_emp;
9.5、同義詞
一、含義
同義詞就是別名的意思和檢視的功能類似,就是一種對映關係
二、語法
1、建立同義詞
create [public] synonym 同義詞名稱 for 物件的名稱;
2、修改同義詞
create or replace [public] synonym 同義詞名稱 for 物件的名稱;
3、刪除同義詞
drop [public] synonym 同義詞名稱;
三、演示
1、建立同義詞
--建立
create synonym syno_emp for emp;
--呼叫
select * from syno_emp;
2、修改同義詞
--建立
create or replace synonym syno_emp_update for emp;
--呼叫
select * from syno_emp_update;
3、刪除同義詞
drop synonym syno_emp_update;
9.6、遊標
一、含義
遊標是用來操作查詢結果集,相當於是JDBC中ResultSet,它可以對查詢的結果一行一行的獲取
二、語法
--第一步:定義遊標
--第一種:普通遊標
cursor 遊標名[(參數 參數型別)] is 查詢語句;
--第二種:系統參照遊標
遊標名 sys_refcursor;
--第二步:開啓遊標
--第一種:普通遊標
open 遊標名[(參數 參數型別)];
--第二種:系統參照遊標
open 遊標名 for 查詢語句;
--第三步:獲取一行
fetch 遊標名 into 變數;
--第四步:關閉遊標
close 遊標名;
三、演示
1、普通遊標使用
--輸出指定部門下的員工姓名和工資
declare
--1.宣告遊標
cursor vrows(dno number) is select * from emp where deptno = dno;
--宣告變數
vrow emp%rowtype;
begin
--2.開啓遊標
open vrows(10);
--3.回圈遍歷
loop
fetch vrows into vrow;
exit when vrows%notfound;
dbms_output.put_line('姓名:' || vrow.ename || ' 工資: ' || vrow.sal);
end loop;
--4.關閉遊標
close vrows;
end;
2、系統參照遊標使用
--輸出員工表中所有的員工姓名和工資
declare
--1.宣告系統參照遊標
vrows sys_refcursor;
--宣告變數
vrow emp%rowtype;
begin
--2.開啓遊標
open vrows for select * from emp;
--3.回圈遍歷
loop
fetch vrows into vrow;
exit when vrows%notfound;
dbms_output.put_line('姓名:' || vrow.ename || ' 工資: ' || vrow.sal);
end loop;
--4.關閉遊標
close vrows;
end;
3、使用for回圈輸出
--輸出員工表中所有的員工姓名和工資
declare
cursor vrows is select * from emp;
begin
--自動定義變數vrow,自動開啓遊標,自動關閉遊標
for vrow in vrows loop
dbms_output.put_line('姓名:' || vrow.ename || ' 工資: ' || vrow.sal || '工作:' || vrow.job);
end loop;
end;
9.7、儲存過程
一、含義
儲存過程實際上是封裝在伺服器上一段PLSQL程式碼片斷,它已經編譯好了,如果用戶端呼叫儲存過程,執行效率就會非常高效
二、語法
1、建立儲存過程
create procedure 儲存過程名稱(參數名 in|out 參數型別,參數名 in|out 參數型別,...)
is|as
--宣告部分
begin
--業務邏輯
end;
2、修改儲存過程
create [or replace] procedure 儲存過程名稱(參數名 in|out 參數型別,參數名 in|out 參數型別,...)
is|as
--宣告部分
begin
--業務邏輯
end;
3、刪除儲存過程
drop procedure 儲存過程名稱;
4、呼叫儲存過程
--方式一:
call 儲存過程名稱(...);
--方式二:
declare
begin
儲存過程名稱(...);
end;
三、演示
1、建立儲存過程
--給指定員工漲薪並列印漲薪前和漲薪後的工資
create procedure proc_update_sal(vempno in number,vnum in number)
is
--宣告變數
vsal number;
begin
--查詢當前的工資
select sal into vsal from emp where empno = vempno;
--輸出漲薪前的工資
dbms_output.put_line('漲薪前:' || vsal);
--更新工資
update emp set sal = vsal + vnum where empno = vempno;
--輸出漲薪後的工資
dbms_output.put_line('漲薪後:' || (vsal + vnum));
--提交事物
commit;
end;
--給員工編號爲7521的員工漲工資10元
call proc_update_sal(7521, 10);
2、修改儲存過程
--給指定員工漲薪並列印漲薪前和漲薪後的工資
create or replace procedure proc_update_sal(vempno in number,vnum in number)
is
--宣告變數
vsal number;
begin
--查詢當前的工資
select sal into vsal from emp where empno = vempno;
--輸出漲薪前的工資
dbms_output.put_line('漲薪前:' || vsal);
--更新工資
update emp set sal = vsal + vnum where empno = vempno;
--輸出漲薪後的工資
dbms_output.put_line('漲薪後:' || (vsal + vnum));
--提交事物
commit;
end;
--給員工編號爲7521的員工漲工資10元
call proc_update_sal(7521, 10);
3、刪除儲存過程
drop procedure proc_update_sal;
9.8、函數
一、含義
函數實際上是封裝在伺服器上一段PLSQL程式碼片斷,它已經編譯好了,如果用戶端呼叫儲存過程,執行效率就會非常高效,它跟儲存過程沒有什麼本質區別,儲存過程能做的函數也能做,只不過函數有返回值
二、語法
1、建立函數
create function 函數名稱(參數名 in|out 參數型別,參數名 in|out 參數型別,...) return 返回的參數型別
is|as
--宣告部分
begin
--業務邏輯
end;
2、修改函數
create [or replace] function 函數名稱(參數名 in|out 參數型別,參數名 in|out 參數型別,...) return 返回的參數型別
is|as
--宣告部分
begin
--業務邏輯
end;
3、刪除函數
drop function 函數名稱;
4、呼叫函數
--方式一:
select 函數名稱(...) from dual;
--方式二:
declare
變數名 變數型別;
begin
變數名 = 函數名稱(...);
end;
三、演示
1、建立函數
--查詢指定員工的年薪
/*
參數 : 員工的編號
返回 : 員工的年薪
*/
create function func_getsal(vempno number) return number
is
vtotalsal number;
begin
select sal * 12 + nvl(comm, 0) into vtotalsal from emp where empno = vempno;
return vtotalsal;
end;
--查詢員工編號爲7788的年薪
declare
vsal number;
begin
vsal := func_getsal(7788);
dbms_output.put_line(vsal);
end;
2、修改函數
--查詢指定員工的年薪
/*
參數 : 員工的編號
返回 : 員工的年薪
*/
create or replace function func_getsal(vempno number) return number
is
vtotalsal number;
begin
select sal * 12 + nvl(comm, 0) into vtotalsal from emp where empno = vempno;
return vtotalsal;
end;
--查詢員工編號爲7788的年薪
declare
vsal number;
begin
vsal := func_getsal(7788);
dbms_output.put_line(vsal);
end;
3、刪除函數
drop function func_getsal;
9.9、觸發器
一、含義
當使用者執行了 insert | update | delete 這些操作之後,可以觸發一系列其它的動作、業務邏輯,使用觸發器可以協助應用在數據庫端確保數據的完整性、日誌記錄 、數據校驗等操作。使用別名 OLD 和 NEW 來參照觸發器中發生變化的記錄內容,這與其他的數據庫是相似的。現在Oracle觸發器不僅支援行級觸發,還支援語句級觸發
二、分類
| 觸發器型別 | NEW 和 OLD的使用 |
|---|---|
| INSERT 型觸發器 | NEW 表示將要或者已經新增的數據 |
| UPDATE 型觸發器 | OLD 表示修改之前的數據 , NEW 表示將要或已經修改後的數據 |
| DELETE 型觸發器 | OLD 表示將要或者已經刪除的數據 |
三、語法
1、建立觸發器
create trigger 觸發器名稱
before|after
insert|update|delete
on 表名稱
[for each row]--行級觸發器
declare
--宣告部分
begin
--業務邏輯
end;
2、修改觸發器
create [or replace] trigger 觸發器名稱
before|after
insert|update|delete
on 表名稱
[for each row]--行級觸發器
declare
--宣告部分
begin
--業務邏輯
end;
3、刪除觸發器
drop trigger 觸發器名稱;
四、演示
1、INSERT 型觸發器
--新員工入職之後,輸出一句話: 歡迎加入我們
create or replace trigger tri_emp_insert
after
insert
on emp
declare
begin
dbms_output.put_line('歡迎加入我們');
end;
--插入數據就可以自動觸發觸發器
insert into emp(empno, ename) values(9527, '馬哈哈');
2、UPDATE 型觸發器
--判斷員工漲工資後的工資一定要大於漲工資前的工資
create or replace trigger tri_emp_update_sal
before
update
on emp
for each row
declare
begin
if :old.sal > :new.sal then
raise_application_error(-20002,'舊的工資不能大於新的工資');
end if;
end;
--更新數據就可以自動觸發觸發器(無異常)
update emp set sal = sal + 10;
select * from emp;
--更新數據就可以自動觸發觸發器(有異常)
update emp set sal = sal - 100;
select * from emp;
3、DELETE 型觸發器
--老員工離職之後,輸出一句話: 有員工離職了
create or replace trigger tri_emp_delete
after
delete
on emp
declare
begin
dbms_output.put_line('有員工離職了');
end;
--刪除數據就可以自動觸發觸發器
delete from emp where empno = 9527;
4、刪除觸發器
drop trigger tri_emp_insert;
drop trigger tri_emp_update_sal;
drop trigger tri_emp_delete;
第十章 數據備份
10.1、全部導出
--注意:以下操作爲cmd命令列操作
全部導出: exp 管理員帳號/密碼 file='d:\beifen.dmp' full=y
10.2、全部匯入
--注意:以下操作爲cmd命令列操作
全部匯入: imp 管理員帳號/密碼 file='d:\beifen.dmp' full=y
10.3、按使用者導出
--注意:以下操作爲cmd命令列操作
按使用者導出: exp 管理員帳號/密碼 file='d:\beifen.dmp' owner=帳號
10.4、按使用者匯入
--注意:以下操作爲cmd命令列操作
按使用者匯入: imp 管理員帳號/密碼 file='d:\beifen.dmp' fromuser=帳號