Pulsar 與 Kafka 全方位對比(上篇):功能、效能、用例
越來越多的訊息平臺開始採用實時流技術,這促進了 Pulsar 的使用與發展。在 2020 年,Pulsar 的受關注度與使用量都有了顯著增加。從《財富》百強企業到有前瞻性的初創團隊,凡是開發訊息平臺和事件流應用程式的公司都對 Pulsar 保持關注,一直在激勵着 Pulsar 的發展,並且,圍繞 Pulsar 專案的生態也有了迅猛發展,近期多家媒體也在對此爭相報道。
最近的新聞和部落格文章都在客觀地介紹 Pulsar,讀者可以清晰地瞭解 Pulsar 的效能及用例。Verizon Media、Iterable、Nutanix、Overstock.com 等公司最近也發佈了 Pulsar 的用例,並分享了關於如何通過 Pulsar 實現商業目標的一系列想法。
但是,媒體的資訊並非完全真實準確。此外,Pulsar 社羣的小夥伴也向我們發出請求,希望我們針對近期 Confluent 部落格發表的《 Kafka、Pulsar 和 RabbitMQ對比》技術文章做出迴應。很慶幸,Pulsar 能夠發展如此迅速,併成爲一項革新性的技術,我們也很想藉此機會深入探究 Pulsar 的效能。
本文將深入介紹 Pulsar 技術、社羣及生態的相關資訊,客觀、全面地展示事件流的整體情況。本系 本係列文章共有兩篇,本文爲上篇,主要對比 Pulsar 和 Kafka 在效能、架構和特性方面的區別。下篇主要介紹 Pulsar 的用例、支援與社羣等。
注意
由於 Kafka 的可用文件更爲全面,熟知的人也更多,本文會重點介紹目前 Pulsar 相對基礎和文件中涉及不多的內容。
概況
元件
Pulsar 由 3 個主要元件組成:broker、Apache BookKeeper 和 Apache ZooKeeper。Broker 是無狀態服務,用戶端需要連線到 broker 進行核心訊息傳遞。而 BookKeeper 和 ZooKeeper 是有狀態服務。BookKeeper 節點(bookie)儲存訊息與遊標,ZooKeeper 則只用於爲 broker 和 bookie 儲存元數據。另外,BookKeeper 使用 RocksDB 作爲內嵌數據庫,用於儲存內部索引,但 RocksDB 的管理不獨立於 BookKeeper。
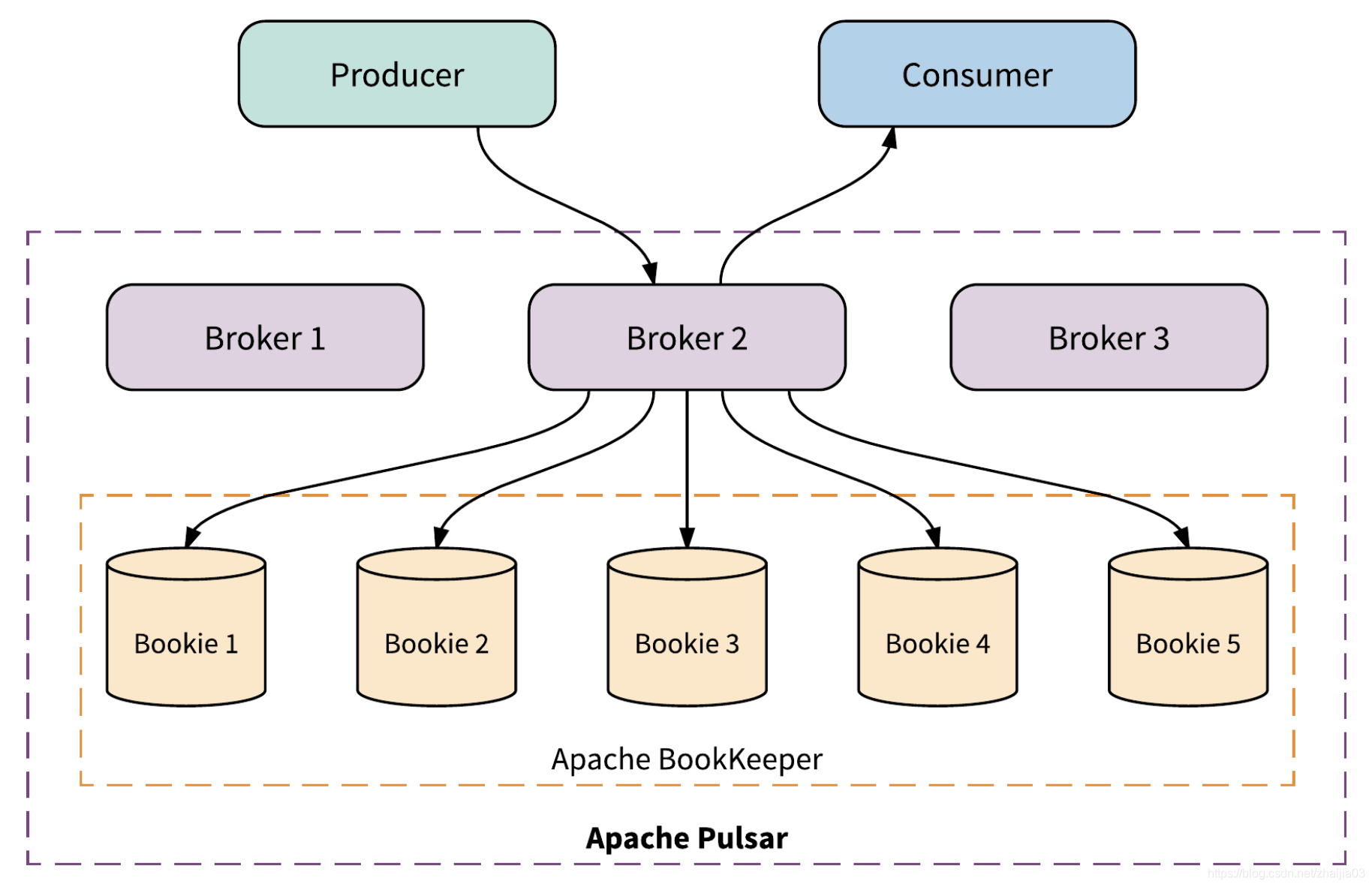
Kafka 採用單片架構模型,將服務與儲存相結合,而 Pulsar 則採用了多層架構,可以在單獨的層內進行管理。Pulsar 中的 broker 在一個層上進行計算,而 bookie 則在另一個層上管理有狀態儲存。
Pulsar 的多層架構看起來似乎比 Kafka 的單片架構更爲複雜,但實際情況卻沒這麼簡單。架構設計需要權衡利弊,BookKeeper 使得 Pulsar 更具可伸縮性、操作負擔更低、速度更快,效能也更一致。在後文中,我們會就以上幾點進行詳細討論。
儲存架構
Pulsar 的多層架構影響到了其儲存數據的方式。Pulsar 將 topic 分區劃分爲分片,然後將這些分片儲存在 Apache BookKeeper 的儲存節點上,以提高效能、可伸縮性和可用性。
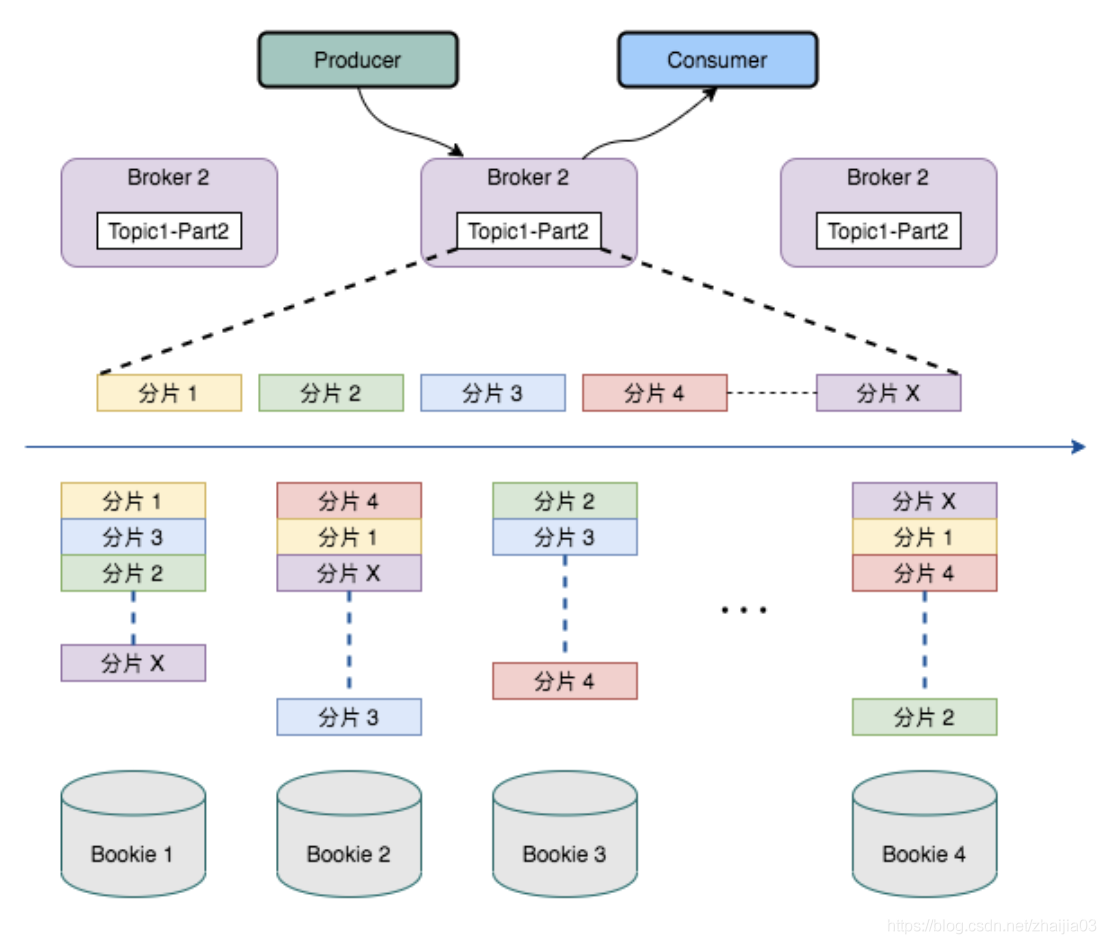
Pulsar 的無限分佈式日誌以分片爲中心,藉助擴充套件日誌儲存(通過 Apache BookKeeper)實現,內建分層儲存支援,因此分片可以均勻地分佈在儲存節點上。由於與任一給定 topic 相關的數據都不會與特定儲存節點進行捆綁,因此很容易替換儲存節點或縮擴容。另外,叢集中最小或最慢的節點也不會成爲儲存或頻寬的短板。
Pulsar 的架構無分割區,也沒有重平衡,保證了及時可伸縮性和高可用性。這兩個重要特性使 Pulsar 尤其適用於構建與關鍵任務相關的服務,如金融用例的計費平臺,電子商務和零售商的交易處理系統,金融機構的實時風險控制系統等。
通過利用效能強大的 Netty 架構,數據從 producers 到 broker,再到 bookie 的轉移都是零拷貝,都不會生成副本。這一特性對所有流用例都非常友好,因爲數據直接通過網路或磁碟進行傳輸,沒有任何效能損失。
訊息消費
Pulsar 的消費模型採用了流拉取的方式。流拉取是長輪詢的改進版,不僅實現了單個呼叫和請求之間的零等待,還可以提供雙向訊息流。通過流拉取模型,Pulsar 實現了比所有現有長輪詢訊息系統(如 Kafka)都低的端到端延遲。
使用簡單
運維簡單
在評估特定技術的操作簡便性時,不僅要考慮初始設定,還要考慮長期維護和可伸縮性。需要考慮以下幾項:
- 要跟上業務增長的速度,擴充套件叢集的操作是否迅速便捷?
- 叢集是否對多租戶(對應於多團隊、多使用者)開箱可用?
- 運維任務(如替換硬體)是否會影響業務的可用性與可靠性?
- 是否可以輕鬆複製數據以實現數據的地理冗餘或不同的存取模式?
長期使用 Kafka 的使用者會發現在運維 Kafka 時上述問題都不容易回答。其中多數任務都需要 Kafka 之外的其他工具,如用於管理叢集再平衡的 cruise control,以及用於複製需求的 Kafka mirror-maker。
由於 Kafka 很難在團隊之間共用,很多機構開發了用於支援和管理多個不同叢集的工具。這些工具對成功大規模使用 Kafka 至關重要,但同時也增加了 Kafka 的複雜性。最適合用來管理 Kafka 叢集的工具都是商業軟體,不開源。那這就不意外了,囿於 Kafka 複雜的管理和運維,許多企業轉而採買 Confluent 的商業服務。
相比之下,Pulsar 的目標是簡化運維和可延伸。根據 Pulsar 的效能,我們對以上問題作出如下回答:
-
要跟上業務增長的速度,擴充套件叢集的操作是否迅速便捷?
Pulsar 的自動負載均衡功能可以自動並立即使用叢集中新加的計算和儲存能力。這使得 broker 之間可以遷移 topic 來平衡負載,新 bookie 節點可以立即接受新數據分片的寫入流量,而無需手動重新平衡或管理 broker。 -
叢集是否對多租戶(對應於多團隊、多使用者)開箱可用?
Pulsar 採用分層架構,租戶和名稱空間能夠與機構或團隊形成良好的邏輯對映,Pulsar 通過這種相同的機構支援簡易 ACL、配額、自主服務控制,甚至也支援資源隔離,從而允許叢集使用者輕鬆管理共用叢集。 -
運維任務(如替換硬體)是否會影響業務的可用性與可靠性?
替換 Pulsar 的無狀態 broker 操作簡單,無需擔心數據丟失。Bookie 節點會自動複製全部未複製的數據分片,而且用於解除和替換節點的工具爲內建工具,很容易實現自動化。 -
是否可以輕鬆複製數據以實現數據的地理冗餘或不同的存取模式?
Pulsar 具有內建的複製功能,可用於無縫跨越地理區域同步數據或複製數據到其他叢集,以實現其他功能(如災備、分析等)。
相比於 Kafka,Pulsar 的特性爲流數據的現實問題提供了更完整的解決方案。從這個角度看,Pulsar 擁有更完善的核心功能集,使用簡單,因而允許使用者和開發者專注於業務的核心需求。
文件與學習
由於 Pulsar 是一項比 Kafka 更新的技術,其生態系統還不夠完善,文件和培訓資源也仍在補充中。但是,這也正是在過去一年半的時間裏,Pulsar 的主要發展方向。以下爲一些主要成果:
- Pulsar Summit Virtual Conference 2020,Pulsar 的首次全球峯會 ,來自超過 25 個機構的演講者共計進行了 36 次分享,註冊參會者超過 600 人。
- 2020 年已原創 50+ 視訊及培訓版塊。
- Pulsar 每週直播及互動教學。
- 業內領先講師進行專業培訓。
- 與戰略商業夥伴每月舉辦一次網路研討會。
- 發佈塗鴉、OVHCloud、騰訊、Yahoo!Japan 等用例的白皮書。
更多關於 Pulsar 文件和培訓的內容,參閱 StreamNative 的 Resources 網站。
企業支援
Kafka 和 Pulsar 都可以提供企業級支援。多個大型供應商(包括 Confluent)爲 Kafka 提供了企業級支援。StreamNative 爲 Pulsar 提供了企業級支援,但 StreamNative 仍在起步發展階段。StreamNative 爲企業提供全面託管的 Pulsar 雲端服務及 Pulsar 企業級支援服務。
StreamNative 團隊在訊息和事件流方面經驗豐富,成長迅速。StreamNative 由 Pulsar 和 BookKeeper 核心成員建立。在 StreamNative 團隊的幫助下,Pulsar 生態系統在短短幾年時間裏突飛猛進,如得到了戰略合作夥伴的支援,這種支援將會進一步促進 Pulsar 的發展,以滿足大量用例的需求(這部分內容將在下篇文章中詳細介紹)。
Pulsar 最近的重大進展如 KoP(即 Kafka-on-Pulsar),由 OVHCloud 和 StreamNative 於 2020 年 3 月推出。通過向現有 Pulsar 叢集新增 KoP 協定處理程式,使用者可以將現有的 Kafka 應用程式和服務遷移到 Pulsar,而無需修改程式碼。在 2020 年 6 月,中國移動與 StreamNative 宣佈推出另一重要產品 —— AoP(即 AMQP on Pulsar)。AoP 使得 RabbitMQ 應用程式可以利用 Pulsar 的特性,如使用 Apache BookKeeper 和分層儲存支援無限事件流儲存等。這部分內容會在下篇中詳細介紹。
生態整合
隨着 Pulsar 使用者迅速增加,Pulsar 社羣已經發展成爲大型、高度參與、使用者全球化的社羣。Pulsar 生態系統中周邊工具外掛數量迅速增長,活躍的 Pulsar 社羣起到了極其重要的推動作用。在過去的六個月裡,Pulsar 生態系統中官方支援的 connector 數量急劇增長。
爲了進一步支援 Pulsar 社羣的發展,StreamNative 不久前推出了 StreamNative Hub。StreamNative Hub 支援使用者查詢、下載整合。這一平臺將有助於加速 Pulsar connector 和外掛生態系統的發展。
Pulsar 社羣也一直在積極地與其他社羣密切合作,以整合雙方的專案。例如,Pulsar 社羣與 Flink 社羣一直在共同開發 Pulsar-Flink Connector (FLIP-72 的一部分)。通過 Pulsar-Spark Connector,使用者可以使用 Apache Spark 處理 Apache Pulsar 中的處理事件。SkyWalking Pulsar 外掛整合了 Apache SkyWalking 和 Apache Pulsar,允許使用者通過 SkyWalking 追蹤訊息。除此之外,Pulsar 社羣還有很多正在進行中的整合專案。
多元用戶端庫
Pulsar 目前官方支援 7 種語言,而 Kafka 只支援 1 種語言。Confluent 部落格指出 Kafka 目前支援 22 種語言,但是,官方用戶端並不能支援這麼多種語言,而且一些語言已經不再維護。根據最新統計,Apache Kafka 官方用戶端只支援 1 種語言,而 Apache Pulsar 官方用戶端支援 7 種語言。
- Java
- C
- C++
- Python
- Go
- .NET
- Node
Pulsar 還支援由 Pulsar 社羣開發的諸多用戶端,如:
- Rust
- Scala
- Ruby
- Erlang
效能與可用性
吞吐量、延遲與容量
Pulsar 和 Kafka 都被廣泛用於多個企業用例,也各有優勢,都能通過數量基本相同的硬體處理大流量。部分使用者誤以爲 Pulsar 使用了更多的元件,因此需要更多的伺服器來實現與 Kafka 相匹敵的效能。雖然這種想法的確適用於一些特定硬體設定,但 在多數同等資源設定中,Pulsar 優勢更加明顯,可以以相同的資源實現更多效能。
舉例來說,Splunk 最近分享了他們選擇 Pulsar 而非 Kafka 的原因,其中提到由於分層架構,Pulsar 幫助他們將成本降低了 1.5 - 2 倍,延遲降低了 5 - 50 倍,運營成本降低 2 -3 倍(幻燈片第 34 頁)。Splunk 團隊發現這是因爲 Pulsar 可以更好地利用磁碟 IO,降低 CPU 利用率,同時更好地控制記憶體。
騰訊等公司選擇 Pulsar 在很大程度上是因爲 Pulsar 的效能屬性。在騰訊計費平臺白皮書中提到,騰訊計費平臺擁有百萬級使用者,管理約 300 億第三方託管賬戶,目前正在使用 Pulsar 處理每天數億美元的交易。考慮到 Pulsar 可預測的低延遲、更強的一致性和永續性保證,騰訊選擇了 Pulsar 而非 Kafka。
有序性保證
Apache Pulsar 支援四種不同訂閱模式。單個應用程式的訂閱模式由排序和消費可延伸性需求決定。以下爲這四種訂閱模式及相關的排序保證:
- 獨佔和災備訂閱模式都在分割區級別支援強排序保證,支援跨 consumer 並行消費同一 topic 上的訊息。
- 共用訂閱模式支援將 consumer 的數量擴充套件至超過分割區的數量,因此這種模式非常適合 worker 佇列用例。
- 鍵共用訂閱模式結合了其他訂閱模式的優點,支援將 consumer 的數量擴充套件至超過分割區的數量,也支援鍵級別的強排序保證。
更多關於 Pulsar 訂閱模式和相關排序保證的資訊,參閱訂閱。
特性
內建流處理
Pulsar 和 Kafka 對於內建流處理的目標不盡相同。針對較爲複雜的流處理需求,Pulsar 整合了 Flink 和 Spark 這兩個成熟的流處理框架,並開發了 Pulsar Functions 來處理輕量級計算。Kafka 則開發並使用 Kafka Streams 這一成熟的流處理引擎。
但是,使用 Kafka Streams 要更復雜一些。使用者需要弄清楚使用 KStreams 應用程式的場景及方法。並且,對於大多數輕量級計算用例來說,KStreams 過於複雜。
另外,Pulsar Functions 輕鬆實現了輕量級計算用例,並允許使用者建立複雜的處理邏輯,而無需部署單獨的臨近系統。Pulsar Functions 還支援原生語言和易於使用的 API。使用者不必學習複雜的 API 就可以編寫事件流應用程式。
一份最近提交的 Pulsar 改進方案(Pulsar Improvement Proposal,PIP)中介紹了 Function Mesh。Function Mesh 是無伺服器架構的事件流框架,結合使用多個 Pulsar Functions 以便於構建複雜的事件流應用程式。
Exactly-Once 處理
目前,Pulsar 通過 broker 端去重支援 exactly-once producer。這個重大專案正在開發中,敬請期待!
Pulsar 自 PIP-31 起支援事務型訊息流,目前仍在開發中。這一特性提高了 Pulsar 的訊息傳遞語意和處理保證。在交易型流中,每條訊息只會寫入一次、處理一次,即便 broker 或 Function 範例出現故障,也不會出現數據重複或數據丟失。交易型訊息不僅簡化了使用 Pulsar 或 Pulsar Functions 嚮應用程式寫入的操作,還擴充套件了 Pulsar 支援的用例的範圍。關於 Pulsar 這一特性的開發進展順利,將會在 Pulsar 2.7.0 版本中發佈,預計發佈時間 2020 年 9 月。
Topic(日誌)壓縮
Pulsar 旨在支援使用者消費數據。應用程式可以需要選擇使用原始數據或壓縮數據。Pulsar 通過這種按需選擇的方式,允許未壓縮數據通過保留策略控制無限制增長,但仍允許通過週期性壓縮生成最新的實物化檢視。內建的分層儲存特性支援 Pulsar 從 BookKeeper 解除安裝未壓縮數據到雲端儲存中,因而降低長期儲存事件的成本。
相比於 Pulsar,Kafka 不支援使用者使用原始數據。並且,在數據壓縮後,Kafka 會立即刪除原始數據。
用例
事件流
雅虎最初開發 Pulsar 將其同時用作發佈/訂閱訊息的平臺(又稱雲訊息)。但是,Pulsar 現在不僅是一個訊息平臺,還是統一的訊息和事件流平臺。Pulsar 引入了一系列工具,作爲平臺的一部分,爲構建事件流應用程式提供必要的基礎。Pulsar 支援以下事件流功能:
-
無限事件流儲存支援通過向外擴充套件日誌儲存(通過 Apache BookKeeper)大規模儲存事件,並且 Pulsar 內建的分層儲存支援高品質、低成本的系統,如 S3、HDFS 等。
-
統一的發佈/訂閱訊息模型支援使用者輕易地嚮應用程式中新增訊息。這一模型可以根據流量和使用者需求進行伸縮。
-
協定處理框架、Pulsar 與 Kafka 的協定相容性(通過 Kafka-on-Pulsar,KoP),以及 AMQP(通過 AMQP-on-Pulsar)支援應用程式使用任一現有協定在任一位置生產和消費事件。
-
Pulsar IO 提供了一組與大型生態系統整合的 connector,允許使用者從外部系統獲取數據,而無需編寫程式碼。
-
Pulsar 與 Flink 的整合支援全面的事件處理。
-
Pulsar Functions 提供了一個輕量級無伺服器框架來處理到達的事件。
-
Pulsar 與 Presto 的整合(Pulsar SQL)支援數據專家和使用者使用 ANSI 相容的 SQL 來分析數據和處理業務。
訊息路由
通過 Pulsar IO、Pulsar Functions、Pulsar Protocol Handler,Pulsar 具有全面路由的功能。Pulsar 的路由功能包括基於內容的路由、訊息轉換,和訊息擴充。
和 Kafka 相比,Pulsar 的路由能力更穩健。Pulsar 爲 connector 和 Functions 提供了更靈活的部署模型。簡易的部署可以在 broker 中執行。另外,部署也可以在專用的節點池中執行(類似於 Kafka Streams),節點池支援大規模擴充套件。Pulsar 還與 Kubernetes 原生整合。另外,可以將 Pulsar 設定爲以 pod 的形式來排程 Functions 和 connector 的工作負載,充分利用 Kubernetes 的彈性。
訊息佇列
如前文所述,Pulsar 最初的開發目的是作爲統一的訊息發佈/訂閱平臺。Pulsar 團隊深入瞭解了現有開源訊息系統的優缺點,並基於團隊的經驗設計了 Pulsar 的統一訊息模型。Pulsar 訊息 API 同時支援佇列和流。不僅可以實現 worker 佇列,以輪詢的方式將訊息發送給相互競爭的 consumer(通過共用訂閱),還可以通過兩種方式支援事件流:一是基於分割區(通過災備訂閱)中訊息的順序;二是基於鍵範圍(通過鍵共用訂閱)中訊息的順序。使用者可以在同一組數據上構建訊息應用程式和事件流應用程式,而無需複製數據到不同數據系統。
另外,Pulsar 社羣還在嘗試使 Apache Pulsar 可以原生支援不同的訊息協定(如 AoP、KoP),以擴充套件 Pulsar 的功能。
結語
Pulsar 社羣一直在不斷髮展壯大,Pulsar 技術的發展和用例數量的增加已經形成良性回圈,Pulsar 生態也在壯大。
Pulsar 具有許多優勢,因此能夠在統一的訊息和事件流平臺脫穎而出,併成爲更多人的選擇。相比於 Kafka,Pulsar 更具有彈性,在運維和擴充套件上更爲簡單。
大多數新技術的推出和被採用都需要花一些時間,但 Pulsar 不僅提供了全套解決方案,維護成本低,還可以在安裝後立即使用。Pulsar 涵蓋了構建事件流應用程式所需的全部基礎,並整合了許多內建特性(包括多種工具)。Pulsar 的工具也可以立即使用,不需要單獨安裝。
StreamNative 一直致力於在開發 Pulsar 新功能的同時,加強現有功能,同時促進社區發展。在實現 2020 年年度任務的過程中,目前一切進展順利,我們期待在九月發佈 Pulsar 2.7.0。
敬請關注本系 本係列文章下篇:Pulsar 的使用、用例、支援與社羣。
特別緻謝
感謝爲本文撰寫發佈提供幫助的多位 Pulsar 社羣成員:Jerry Peng、Jesse Anderson、Joe Francis、Matteo Merli、Sanjeev Kulkarni、Addison Higham 等。