編譯鏈接執行原理
編譯鏈接執行原理
我們知道,在操作系統中,只能識別機器碼(0,1),爲了讓一個.c檔案編譯成爲一個可執行的進程,我們需要進行五步操作:預編譯,編譯,彙編,鏈接,執行。那它們在這些階段裡做了什麼事情,需要我們去研究它們。
編譯器
編譯器就是將高階語言翻譯成機器語言的一個工具。就像我們用c/c++語言寫的一個程式可以使用編譯器將其翻譯成機器可以執行的命令及數據
預編譯階段
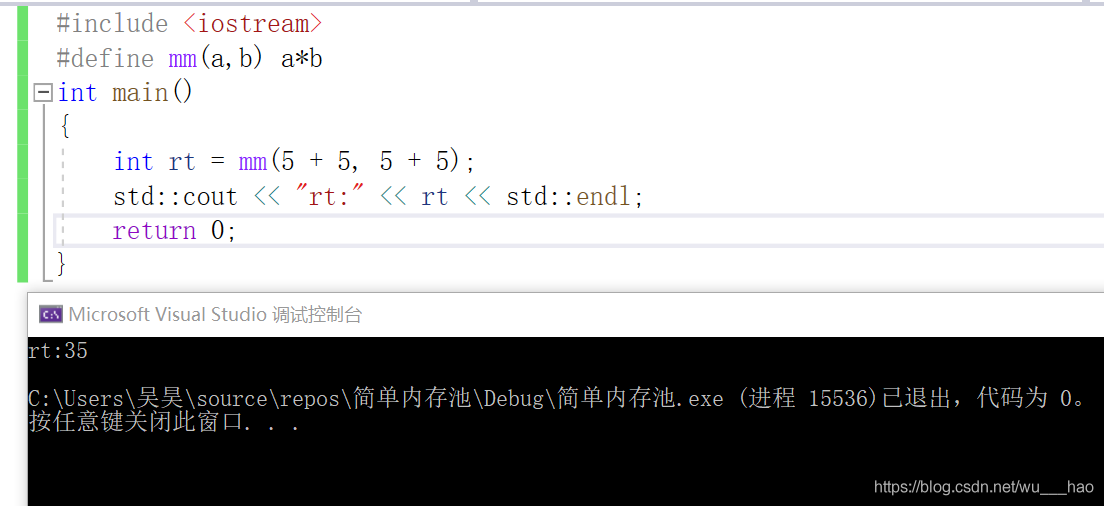
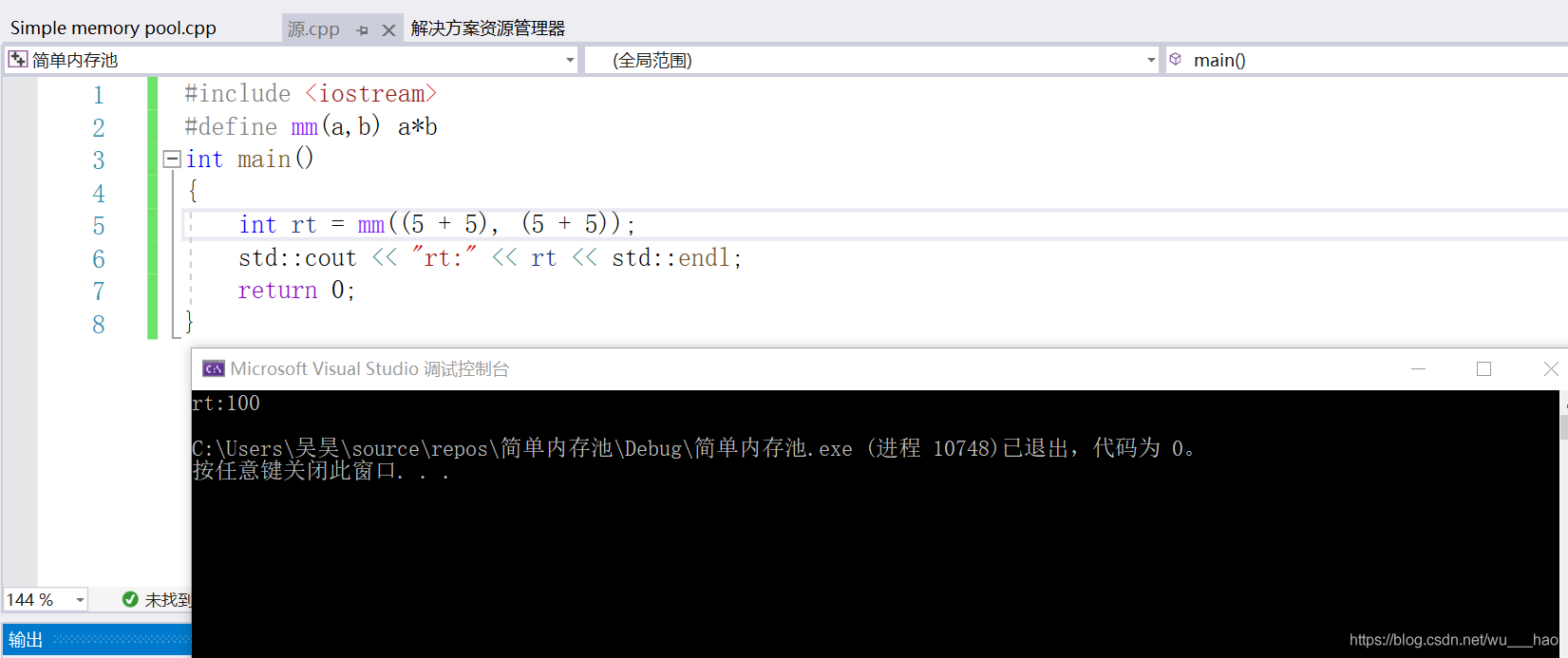
**預編譯階段我們第一步是刪除宏,即刪除#define,並將其替換成文字檔案。**但是我們一般不會去使用宏,因爲它的風險大。看下面 下麪程式碼:
我們在宏中定義了一個乘法運算,讓ab,編譯列印出來的結果沒有我們預想的100,而是35。這是因爲在宏替換成文字後,它的表達式是這樣的:5+55+5,即rt的值是35.但是當我們給每一個5+5都加上括號時,因爲優先順序原因,最終的表達式是(5+5)*(5+5)=100。
宏處理是一個簡單的文字替換,沒有型別檢查和安全檢查
預編譯的第二部是處理#include開頭的標頭檔案,它是一個遞回展開的過程在標頭檔案中可能包含了其他的標頭檔案
預編譯的第三步是處理預編譯指令,比如#if,#endif
預編譯的第四步是刪除註釋。
預編譯的第五步是新增行號和檔案標識,在程式出錯時,快速的定位到出錯的位置
預編譯的第六步是保留#pragma,留給編譯器來處理
預編譯完成後由.c檔案生成.i檔案,此時.i檔案還是高階語言
編譯階段
編譯階段主要做的事有:
詞法分析(每個單詞的組成是否規則)
我們將原始碼程式輸入到掃描器(scanner),它負責將原始碼的字元序列分割成一系列的記號
語法分析(分析的是一行表達式)
對掃描器產生的記號進行語法分析,產生語法樹。整個分析過程與上下文無關的分析手段
語意分析(多行分析)
編譯器所能分析的語意是靜態語意,即在編譯期間可以確定的語意。與之對應的是動態語意,即只有在執行期間才能 纔能確定的語意
程式碼優化(編譯器優化)
生成彙編指令(.s檔案,介於高階語言和機器語言中間的低階語言)
彙編
彙編是將彙編程式碼轉變成指令翻譯成二進制(.o檔案),目標檔案,也叫可重入檔案。
目標檔案就是原始碼編譯後但未進行鏈接的中間檔案,其中動態鏈接庫和靜態鏈接庫的檔案也都是按照庫執行檔案格式儲存
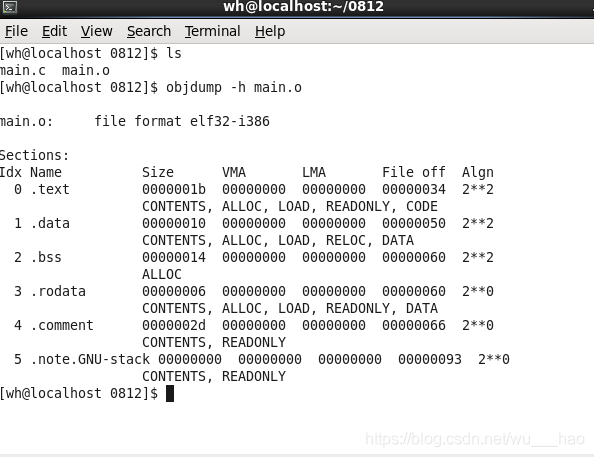
.o檔案是一個ELF格式的檔案,我們可以在linux中使用objdump -h xxx.o來檢視一個檔案的核心佈局
例如a=30;它的指令是mov dword ptr[a] 1E(將30移動到a的記憶體欄位中,一個字是兩個位元組)
| ELF header |
±--------------+
| .text section | 指令段,執行指令的程式碼
±--------------+
| .data section | 數據段,已初始化且初始化不爲0的全域性變數或區域性靜態變數
±--------------+
| .bss section | 在檔案中只有一個.data端。.bss段是不存在的,因爲它們的數據都是0,所以沒有開闢空間的必要。未初始化或初始化爲0的全域性變數和區域性靜態變數
±--------------+
| . comment section | 註釋資訊段
±--------------+
| .rodata section |只讀數據段,存放的一般是隻讀變數(const 修飾的變數)和字串常數
±--------------+
那我們這樣做的目的是爲了什麼呢?它有三點好處:
1,數據區域對於進程來說是可讀寫的,指令區域是可讀的,分開可以防止程式的指令被有意無意的修改
2,
現代cpu的快取一般都被設計成數據快取和指令快取分離,這將對cpu的快取命中率提高有好處
3,當系統中執行着多個該程式的副本時,它們的指令都是一樣的,所以記憶體中只需要儲存一份即可,這樣可以極大的節省空間
可執行檔案 , 可以直接執行的檔案,/bin/bash檔案windows下的.exe
可重定位檔案,包含了程式碼和數據,可以被用來鏈接成可執行檔案或者共用目標檔案,包括靜態庫,Linux的.o,windows下的.obj
共用目標檔案,跟其他的可重定位檔案和共用目標檔案鏈接,產生新的目標檔案或者時做一個動態庫,如:Linux的.so windows的DLL
我們可以在linux下使用file命令檢視相應的檔案格式,如file foobar.o
我們對main.檔案只進行編譯不連線,生成.o檔案main.o使用gcc -c main.c
我們用objdump -h main.o命令來檢視main.o 的結構,我們會發現處理.bss段以外每個段的下面 下麪都有一個CONTENTS,它代表這個段是真實存在的,那麼就可以說明.bss段是不存在的,你可以把它理解爲因本書上的目錄。還有最後一個段我們稱爲「堆疊提示段」,它下面 下麪雖然有CONTENTS,但是我們發現它的大小爲0,我們姑且認爲它也不是真是存在的。
我們可以用size main.o來檢視每個段中數據的大小

我們可以通過objdump -s -d main.o。其中-s可以將原有段中的內容以十六進制的方式列印出來,-d可以將所有包含指令的段反彙編
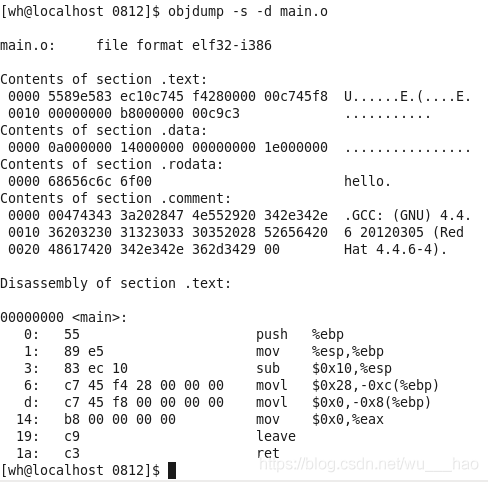
那其實除了以上幾種段以外還有很多的段,比如:
.rdatal:和rdata其實是一樣的
.debug:偵錯資訊
.dynamic:動態連線資訊
.hash:符號雜湊表
.line:偵錯時的行號表,即原始碼行號與編譯後指令的對應表
.symtab:符號表
.shstrtab:段名錶
鏈接
1.合併段和符號表
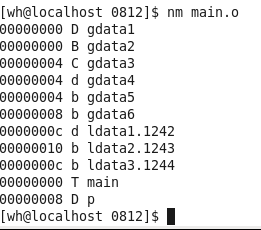
符號表:在連線中,目標檔案之間互相拼合實際上是目標檔案之間對地址的參照,即對函數和變數之間的參照。在連線中我們統稱函數和變數爲符號,函數名和變數名就是符號名。每一個檔案都會有一個相應的符號表,每一個符號都有一個符號值。對於變數和函數來說,符號值就是它們的地址。我們可以用nm main.o 命令來檢視都有哪些符號:
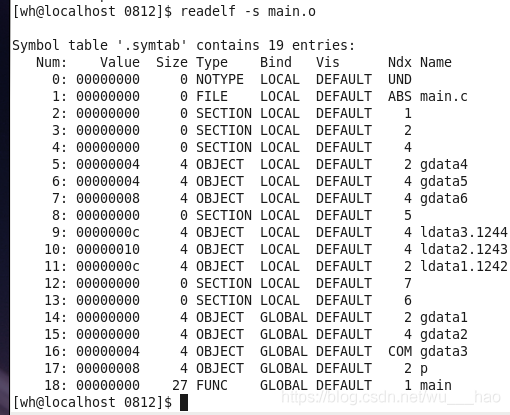
我們可以通過readeil -s main.o來檢視符號表所對應的資訊
**空間與地址分配:**掃描所有的輸入目標檔案,並且獲得它們段的長度、屬性、位置,並將目標檔案中的符號表中所有的符號定義和符號參照收集起來,放到一個符號表。聯結器可以獲得所有輸入目標檔案的長度,並將它們合併,計算出輸出檔案中段合併後的長度與位置,建立對映關係。
**符號解析與重定位:**使用蒐集 搜集好的資訊來讀取輸入檔案中的數據、重定位資訊,並進行符號解析與重定位、調整程式碼中的地址。
強弱符號(鏈接階段處理):在c中,已初始化的符號叫做強符號,沒有初始化的符號稱爲弱符號。如果出現兩個同名強符號,系統會報錯;如果有一強一弱,最終會選擇強符號;如果是兩個弱符號,系統先編譯哪個符號,就會選擇哪個,但是也有可能直接報錯。
預編譯,編譯,彙編,都是編譯單元,即一個原始檔編譯完再去編譯另外一個原始檔。當我們去編譯時遇到一個弱符號,我們不知道別的原始檔中是否還存在強符號,所以我們會將這個弱符號放在.comment段來儲存。當我們進行連線時,此時所有段已經合併,編譯器進行比較選擇。
重定位表:在ELF檔案中,有一個叫重定位表的結構來專門儲存這些與重定位相關的資訊。我們可以用objdump -r main.o來檢視重定位
表的內容。也就是說,在main.o中所有要參照到外部符號的地址,都會生成一個重定位入口,而重定位入口的偏移表示該入口在要被重定位的段中的位置。
我們假設有個全域性變數var,它在目標檔案A中,如果我們要在目標檔案B裏面存取這個變數
得到 movl $0x2a, var,這條指令是將var這個變數賦值給0x2a,相當於var=32。編譯目標檔案B,得到指令機器碼:
c7 05 00 00 00 00 2a 00 00 00
由於我們在編譯目標檔案B時,不知道目標檔案A中var的位置,所以我們將mov指令的目標地址置爲0(虛假地址),假設A和B鏈接後,變數var的地址爲0x100,那麼聯結器就會將這個指令的目標地址修改爲0x100。這個地址的修正過程也叫做重定位,每一個要被修正的地方叫做重定位入口
符號解析:我們將多個目標檔案鏈接起來的目的是因爲我們要找的符號被定義在了其他的目標檔案中。如果沒有鏈接到一起系統就會報錯,最常見的是我們在鏈接時少了某個庫或者目標檔案的路徑不正確,我們可以通過readelf -s main.o來檢視符號表,未定義的符號我們會將其放在"UND",即"undefined"(未定義區)
指令修正方式:一般的指令有跳轉指令(jmp)子程式呼叫指令(call)數據傳送指令(mov)
對於32位元X86平臺來說只有絕對近址和相對近址,這兩種指令的修正方式每個被修正的位置長度都爲32位元,即4個位元組。
x86有兩種重定位型別:R_386_32絕對定址修正方法S+A;R_386_PC32相對定址修正方法S+A-P。
A=儲存在被修正位置的值
P=被修正的位置(偏移量或者虛擬地址)
S=符號的實際地址