SQLServer2016
目錄
第1章 數據庫系統概述
1 數據庫技術的發展歷史
- 概述:
數據管理是數據庫的核心任務,內容包括對數據的分類、組織、編碼、儲存、檢索、維護。發展歷史分爲下面 下麪幾個階段
- 人工管理階段
(1)數據基本不儲存
(2)沒有對數據進行管理的軟件系統
(3)沒有檔案的概念
(4)數據不具有獨立性
- 檔案系統階段
(1)數據可以長期儲存
(2)由檔案系統管理數據
(3)檔案的形式已經多樣化
(4)數據具有一定的獨立性
- 數據庫系統階段
(1)採用複雜的結構化的數據模型
(2)較高的數據獨立性
(3)最低的冗餘度
(4)數據控制功能
2 數據庫系統的基本概念
-
數據
數據(Data)是數據庫中儲存的基本物件。是人們用各種物理符號把資訊按一定格式記載下來的有意義的符號組合。 -
數據庫
數據庫(DataBase,簡稱DB),即存放數據的倉庫,數據庫中的數據並不是簡單的堆積,數據之間是相互關聯的。 -
數據庫管理系統
數據庫管理系統(DataBase Management System,簡稱DBMS)是專門用於管理數據庫的計算機系統軟體,介於應用程式與操作系統之間,是一層數據管理軟體。 -
數據庫系統
數據庫系統(DataBase System,簡稱DBS)是指在計算機系統中引入了數據庫後的系統,由計算機硬體、操作系統、數據庫管理系統、應用程式和使用者構成,即由計算機硬體
3 數據庫系統的結構
-
數據庫系統的三級模式結構:
-
模式:模式也稱爲邏輯模式,是對數據庫中全體數據的邏輯結構和特徵的描述,是所有使用者的公共數據檢視。不涉及數據的物理儲存細節和硬體環境,也與具體的應用程式和開發工具無關。模式實際上是數據庫數據在邏輯級上的檢視。一個數據庫只能有一個模式。模式只是對數據庫結構的一種描述,而不是數據庫本身,是裝配數據的一個框架
-
外模式:外模式也稱爲子模式或使用者模式,是數據庫使用者看到的數據檢視,是與某個應用有關的數據的邏輯表示
-
內模式:內模式也稱爲儲存模式,是數據在數據庫系統內部的表示或底層的描述,即對數據庫物理結構和儲存方式的描述。一個數據庫只能有一個內模式。
-
數據庫系統的二級映像:
-
外模式/模式的映像:模式描述的是數據的全域性邏輯結構,外模式描述的是數據的區域性邏輯結構。對於每個外模式,數據庫都有一個外模式/模式的映像,它定義並保證了外模式與模式之間的對應關係。這些映像定義通常包含在各自的外模式中
-
模式/內模式的映像:數據庫的內模式依賴於它的全域性邏輯結構,即模式。因爲一個數據庫只有一個模式,也只有一個內模式,所以模式/內模式的映像也是唯一的。它定義並保證了模式與內模式之間的對應關係
4 習題
- 數據庫三級模式體系結構的劃分,有利於保持數據庫的______。(數據對立性 )
- 什麼是數據?數據有什麼特徵?數據和資訊有什麼關係?
數據是用於載荷資訊的物理符號。
數據的特徵是:
① 數據有「型」和「值’之分;
② 數據受數據型別和取值範圍的約束;
③ 數據有定性表示和定量表示之分;
④ 數據應具有載體和多種表現形式。
數據與資訊的關係爲:數據是資訊的一種表現形式,數據通過能書寫的資訊編碼表示資訊。資訊有多種表現形式,它通過手勢、眼神、聲音或圖形等方式表達,但是數據是資訊的最佳表現形式。由於數據能夠書寫,因而它能夠被記錄、儲存和處理,從中挖掘出更深層的資訊。但是,數據不等於資訊,數據只是資訊表達方式中的一種。正確的數據可表達資訊,而虛假、錯誤的數據所表達的是謬誤,不是資訊。
- 什麼是數據庫?數據庫中的數據有什麼特點?
數據庫是數據管理的新方法和技術,它是一個按數據結構來儲存和管理數據的計算機軟件系統。
數據庫中的數據具有的特點是:
① 數據庫中的數據具有數據整體性,即數據庫中的數據要保持自身完整的數據結構;
② 數據庫中的數據具有數據共用性,不同的使用者可以按各自的用法使用數據庫中的數據,多個使用者可以同時共用數據庫中的數據資源。
- 什麼是數據庫管理系統?它的主要功能是什麼?
數據庫管理系統簡稱DBMS(Database Management System),它是專門用於管理數據庫的計算機系統軟體。數據庫管理系統能夠爲數據庫提供數據的定義、建立、維護、查詢和統計等操作功能,並完成對數據完整性、安全性進行控制的功能。
數據庫管理系統的主要功能是數據儲存、數據操作和數據控制功能。
- 什麼是數據的獨立性?
數據獨立性是指應用程式和數據之間的依賴程度低,相互影響小。數據獨立性分成物理數據獨立性和邏輯數據獨立性兩級。數據的物理獨立性是指應用程式對數據儲存結構的依賴程度。數據物理獨立性高是指當數據的物理結構發生變化時,應用程式不需要修改也可以正常工作。數據的邏輯獨立性是指應用程式對數據全域性邏輯結構的依賴程度。數據邏輯獨立性高是指當數據庫系統的數據全域性邏輯結構改變時,它們對應的應用程式不需要改變仍可以正常執行。
第2章 數據模型
1 三大世界
- 現實世界
現實世界(Real World)就是人們所能看到、接觸到的世界。現實世界存在無數事物,每個客觀存在的事物都可以看作一個個體,每個個體都有屬於自己的特徵。
- 資訊世界
資訊世界(Information World)是現實世界在人們頭腦中的反映。人們的思維以現實世界爲基礎,對事物進行選擇、命名、分類等抽象工作之後,並用文字元號表示出來,就形成了資訊世界
- 計算機世界
計算機世界(Computer World)又稱數據世界(Data World)。人們將資訊世界中的資訊經過抽象和組織,按照特定的數據結構(即數據模型)儲存在計算機中,就形成了計算機世界。
2 兩大模型
- 概念模型
概念模型用於資訊世界的建模,是對現實世界的抽象和概括。
- 數據模型
數據模型(Data Model)是嚴格定義的一組概唸的集合。精確地描述了系統的靜態和動態特性,是數據庫中用來對現實世界進行抽象的工具,是數據庫系統的核心和基礎,是描述數據的結構及定義在其上的操作和約束條件。
- 常用的數據模型
在設計數據庫全域性邏輯結構時,不同的數據庫管理系統對數據的具體組織方法不同。總的來說,當前實際的數據庫系統中最常見的數據組織方法有以下5種:
層次模型(Hierarchical Model)。
網狀模型(Network Model)。
關係模型(Relational Model)。
物件導向模型(Object Oriented Model)。
物件關係模型(Object Relational Model)。
其中,層次模型和網狀模型統稱爲非關係模型,也統稱爲格式化模型。
- 關係模型與非關係模型
① 關係模型不同於非關係模型,它是建立在嚴格的數學概念基礎之上的。
② 關係模型與非關係模型相比較,概念單一,結構清晰,容易理解。
③ 關係模型的存取路徑對使用者是透明的,從而簡化了使用者的工作,提高了效率。實際上,關係模型的查詢效率往往不如非關係模型,所以必須對關係模型的查詢進行優化,這就增加了開發數據庫的難度。
④ 關係模型中的數據聯繫是靠數據冗餘實現的。
- 關係模型的優缺點
關係模型的優點有:
① 使用表的概念來表示實體之間的聯繫,簡單直觀。
② 關係型數據庫都使用結構化查詢語句,存取路徑對使用者是透明的,從而提高了數據的獨立性,簡化了使用者的工作。
③ 關係模型是建立在嚴格的數學概念基礎之上的,具有堅實的理論基礎。
關係模型的缺點有:
關係模型的連線等查詢操作開銷較大,需要較高效能運算機的支援,所以必須提供查詢優化功能。
3 習題
- 實體、實體型、實體集、屬性、碼、實體聯繫圖(E-R圖)、數據模型
① 實體:現實世界中存在的可以相互區分的事物或概念稱爲實體。例如,一個學生、一個工人、一臺機器、一部汽車等是具體的事物實體,一門課、一個班級等稱爲概念實體。
② 實體型:現實世界中,對具有相同性質、服從相同規則的一類事物(或概念,即實體)的抽象稱爲實體型。實體型是實體集數據化的結果,實體型中的每一個具體的事物(實體)爲它的範例。
③ 實體集:具有相同特徵或能用同樣特徵描述的實體的集合稱爲實體集。例如,學生、工人、汽車等都是實體集。
④ 屬性:屬性爲實體的某一方面特徵的抽象表示。如學生,可以通過學生的「姓名」、「學號」、「性別」、「年齡」及「政治面貌」等特徵來描述,此時,「姓名」、「學號」、「性別」、「年齡」及「政治面貌」等就是學生的屬性。
⑤ 碼:碼也稱關鍵字,它能夠惟一標識一個實體。例如,在學生的屬性集中,學號確定後,學生的其他屬性值也都確定了,學生記錄也就確定了 由於學號可以惟一地標識一個學生,所以學號爲碼。
⑥ 實體聯繫圖(E-R圖):實體-聯繫方法(Entity-Relationship Approach,即E-R圖法)是用來描述現實世界中概念模型的一種著名方法。E-R圖法提供了表示實體集、屬性和聯繫的方法。
⑦ 數據模型:數據模型是一組嚴格定義的概念集合。這些概念精確地描述了系統的數據結構、數據操作和數據完整性約束條件。
- 試述數據模型的概念、數據模型的作用和數據模型的三要素。
數據模型是一組嚴格定義的概念集合,這些概念精確地描述了系統的數據結構、數據操作和數據完整性約束條件。數據模型是通過概念模型數據化處理得到的。
數據庫是根據數據模型建立的 因而數據模型是數據庫系統的基礎。
數據模型的三要素是數據結構、數據操作和完整性約束條件。其中:數據結構是所研究的物件型別的集合,它包括數據的內部組成和對外聯繫;數據操作是指對數據庫中各種數據物件允許執行的操作集合,它包括操作物件和有關的操作規則兩部分內容;數據約束條件是一組數據完整性規則的集合,它是數據模型中的數據及其聯繫所具有的制約和依存規則。
- 試述概念模型的作用。
概念模型也稱資訊模型,它是對資訊世界的管理物件、屬性及聯繫等資訊的描述形式。概念模型不依賴計算機及DBMS,它是現實世界的真實而全面的反映。概念模型通過系統需求分析得到,對概念模型數據化處理後就得到了數據庫的數據模型。
- 試述數據庫概念結構設計的重要性和設計步驟。
重要性:數據庫概念設計是整個數據庫設計的關鍵,將在需求分析階段所得到的應用需求首先抽象爲概念結構,以此作爲各種數據模型的共同基礎,從而能更好地、更準確地用某一 DBMS 實現這些需求。
設計步驟:概念結構的設計方法有多種,其中最經常採用的策略是自底向上方法,該方法的設計步驟通常分爲兩步:第 1 步是抽象數據並設計區域性檢視,第 2 步是整合區域性檢視,得到全域性的概念結構。
- 什麼是E-R圖?構成E-R圖的基本要素是什麼?
E-R圖爲實體-聯繫圖,提供了表示實體型、屬性和聯繫的方法,用來描述現實世界的概念模型。
構成E-R圖的基本要素是實體型、屬性和聯繫,其表示方法爲:
1)實體型,用矩形表示,矩形框內寫明實體名;
2)屬性,用橢圓形表示,並用無向邊將其與相應的實體連線起來;
3)聯繫,用菱形表示,菱形框內寫明聯繫名,並用無向邊分別與有關實體連線起來,同時在無向邊旁標上聯繫的型別(1:1,1:n或m:n)。
- E-R圖
看書吧
第3章 數據庫設計
1 規範化
-
範式的種類
爲了使關係模式設計的方法趨於完備,數據庫專家研究了關係規範化理論。所謂第幾範式,是指一個關係模式按照規範化理論設計符合哪個級別的要求 -
函數依賴
函數依賴(Functional Dependency)是關係模式中各個屬性之間的一種依賴關係,是規範化理論中一個最重要、最基本的概念
2 習題
- 關係數據庫是以(數據的關係模型)爲基礎設計的數據庫,利用( 關係模式 )描述現實世界。一個關係既可以描述(實體),也可以描述(實體間的聯繫)。
- 在關係數據庫中,二維表稱爲一個(關係),表的每一行稱爲(記錄),表的每一列稱爲(欄位或屬性)。
- 數據完整性約束分爲(實體完整性)、(參照完整性)和(使用者定義的完整性)。
- ① 主碼、候選碼、外碼。 ② 笛卡兒積、關係、元組、屬性、域。③ 關係、關係模式、關係數據庫。
主碼、候選碼、外碼。
若關係中的某一屬性組(或單個屬性)的值能惟一地標識一個元組,則稱該屬性組(或屬性)爲候選碼。爲數據管理方便,當一個關係有多個候選碼時,應選定其中的一個候選碼爲主碼。當然,如果關係中只有一個候選碼,這個惟一的候選碼就是主碼。
設F是基本關係R的一個或一組屬性,但不是關係R的主碼(或候選碼)。如果F與基本關係S的主碼Ks相對應,則稱F是基本關係R的外碼(Foreign Key),並稱基本關係R爲參照關係(Referencing Relation),基本關係S爲被參照關係(Referenced Relation)或目標關係(Target Relation)。
迪卡爾積、關係、元組、屬性、域。
給定一組域D1,D2,…, Dn.這些域中可以有相同的部分,則D1,D2,…, Dn的笛卡地積爲:D1×D2×…×Dn﹦{(dl,d2,…,dn)∣di∈Di,i=1,2, …,n}。
D1×D2×…×Dn的子集稱作在域D1,D2,…, Dn上的關係,表示爲:R(D1,D2,…, Dn)。其中,R表示關係的名字,n是關係的目。
笛卡兒積集閤中的每一個元素(dl,d2,…,dn)稱爲一個元組。
關係中的每一列稱爲一個屬性。
域爲數據集合,屬性值來源於域。
關係、關係模式、關係數據庫。
關係是留卡兒積的有限子集,所以關係也是一個二維表。
關係的描述稱爲關係模式。關係模式可以形式化地表示爲:R(U,D,Dom,F)。其中R爲關係名,它是關係的形式化表示;U爲組成該關係的屬性集合;D爲屬性組U中屬性所來自的域;Dom爲屬性向域的映像的集合;F爲屬性問數據的依賴關係集合。
在某一應用領域中,所有實體集及實體之間聯繫所形成關係的集合就構成了一個關係數據庫。
第4章 SQL Server 2016基礎
SQL Server 2016簡介
- 伺服器元件
1.SQL Server數據庫引擎
2.Analysis Services(分析服務)
3.Reporting Services(報表服務)
4.Integration Services(整合服務)
5.Master Data Services
6.R Services(數據庫內)
- 管理工具
1.SQL Server Management Studio
2.SQL Server設定管理器
3.SQL Server事件探查器
4.數據庫引擎優化顧問
5.數據品質用戶端
6.SQL Server Data Tools
7.連線元件
習題
1.數據庫引擎(SQL Server Database Engine,SSDE)是SQL Server 系統的核心服務。
2.Sql Server Configuration Manager稱爲SQL Server 設定管理器。
3.SSMS是一個整合環境,是SQL Server 2008最重要的圖形介面管理工具。
4.物件資源管理器以_樹型結構顯示和管理伺服器中的物件節點。
5.在SQL Server 2008 中,主數據檔案的後綴是_.mdf__,日誌數據檔案的後綴是.ldf。
6.每個檔案組可以有多個日誌檔案。
第5章 數據庫的建立與管理
1 數據庫常用物件
- 1.表
表(也稱爲數據表)是存放數據和表示關係的主要形式,是最主要的數據庫物件。 - 2.檢視
檢視是由一個或多個表生成的參照表(也稱虛擬表),是使用者檢視數據表中數據的一種方式。檢視的結構和數據建立在對錶的查詢基礎之上。在數據庫中並不存放檢視的數據,只存放其查詢定義。在開啓檢視時,需要執行其查詢定義以產生相應的數據。 - 3.索引
索引是指對錶記錄按某個列或列的組合(索引表達式)進行排序,通過搜尋索引表達式的值,可以實現對該類數據記錄的快速存取。 - 4.約束
約束用於保障數據的一致性與完整性。例如,主鍵約束和外來鍵約束,主鍵約束當前表記錄的主鍵欄位值的唯一性,外來鍵約束當前記錄與其他表的關係。 - 5.儲存過程
儲存過程是一組完成特定功能的SQL語句集合(包含查詢、插入、刪除和更新等操作),經編譯後以名稱的形式儲存在SQL Server伺服器端的數據庫中,由使用者通過指定儲存過程的名稱來執行。當這個儲存過程被呼叫執行時,其包含的操作也會同時執行。 - 6.觸發器
觸發器是一種特殊型別的儲存過程,它能夠在某個規定的事件發生時觸發執行。觸發器通常可以強制執行一定的業務規則,以保持數據完整性,檢查數據的有效性,同時實現數據庫的管理任務和一些附加的功能。
2 系統數據庫
SQL Server的安裝程式在安裝時預設建立4個系統數據庫(master,model,msdb,tempdb)
1.master數據庫
2.model數據庫
3.msdb數據庫
4.tempdb數據庫
3 檔案和檔案組
- 數據庫檔案
(1)主數據檔案
主數據檔案是數據庫的起點,指向數據庫中的其他檔案。每個數據庫都有一個主數據檔案。主數據檔案的推薦副檔名是.mdf。例如,某銷售管理系統的主數據檔名爲Sales_data.mdf。
(2)次要數據檔案
除主數據檔案以外的所有其他數據檔案都是次要數據檔案。某些數據庫可能不含有任何次要數據檔案,而有些數據庫則可能含有多個次要數據檔案。次要數據檔案的推薦副檔名是.ndf。
(3)日誌檔案
日誌檔案包含着用於恢復數據庫的所有日誌資訊。每個數據庫必須至少有一個日誌檔案,也可以有多個。日誌檔案的推薦副檔名是.ldf。例如,銷售管理系統的日誌檔名爲Sales_log.ldf。
SQL Server不強制使用.mdf,.ndf和.ldf副檔名,但使用它們有助於標識檔案的各種型別和用途。
- 檔案組
(1)主檔案組
主檔案組包含主數據檔案和任何沒有明確分配給其他檔案組的其他檔案。系統表都分配在主檔案組中。
(2)使用者定義檔案組
使用者定義檔案組是在CREATE DATABASE或ALTER DATABASE語句中使用 FILEGROUP指定的任何檔案組
每個數據庫中均有一個檔案組被指定爲預設檔案組。如果建立表或索引時未指定檔案組,則所有表或索引都將從預設檔案組中分配。一次只能有一個檔案組作爲預設檔案組。如果沒有指定預設檔案組,則將主檔案組作爲預設檔案組。
對檔案進行分組時,一定要遵循檔案和檔案組的設計規則:
檔案只能是一個檔案組的成員
檔案或檔案組不能由一個以上的數據庫使用
數據和日誌資訊不能屬於同一個檔案或檔案組
日誌檔案不能作爲檔案組的一部分
日誌空間與數據空間要分開管理
4 習題
-
1.查詢編輯器是一個 自由 格式的文字編輯器,主要用來編輯與執行Transact-SQL命令。
-
2.在Microsoft SQL Server中,主數據檔案的後綴是.mdf,日誌數據檔案的後綴是.ldf,每個檔案組可以有多個日誌檔案。
-
3.通過T-SQL語句,使用CREATE DATABASE命令建立數據庫,使用 sp_helpdb 命令檢視數據庫定義資訊,使用 ALTER DATABASE 命令修改數據庫結構,使用 DROP DATABASE命令刪除數據庫。
-
4.建立一個指定多個數據檔案和日誌檔案的數據庫。該數據庫名稱爲Students,有一個5MB和一個10MB的數據檔案和兩個5MB的事務日誌檔案。數據檔案邏輯名稱爲Students1和Students2,物理檔名爲Students1.mdf和Students2.ndf。主檔案是Students1,由PRIMARY指定,兩個數據檔案的最大大小分別爲無限大和100MB,增長速度分別爲10%和1MB。事務日誌檔案的邏輯名爲StudentsLog1和StudentsLog2,物理檔名爲StudentsLog1.ldf和StudentsLog2.ldf,最大大小均爲50MB,增長速度爲1MB。要求數據庫檔案和日誌檔案的物理檔案都存放在C槽的DATA資料夾下。
實現的步驟如下:
1)在C槽建立一個新的資料夾,名稱是「DATA」。
2)在SQL Server Management Studio中新建一個查詢頁面。
3)輸入以下程式段並執行此查詢:
CREATE DATABASE STUDENTS
ON PRIMARY
(NAME=STUDENTS1,
FILENAME='E:\DATA\STUDENTS1.mdf',
SIZE=5,
MAXSIZE=unlimited,
FILEGROWTH=10%),
(NAME= STUDENTS12,
FILENAME='C:\DATA\STUDENTS2.ndf',
SIZE=10,
MAXSIZE=100,
FILEGROWTH=1)
LOG ON
(NAME=STUDENTSLOG1,
FILENAME='C:\DATA\STUDENTSLOG1.ldf',
SIZE=5,
MAXSIZE=50,
FILEGROWTH=1),
(NAME=STUDENTSLOG2,
FILENAME='C:\DATA\STUDENTSLOG2.ldf',
SIZE=5,
MAXSIZE=50,
FILEGROWTH=1)
- 5.刪除已建立的數據庫Students2。
實現的步驟如下:
1)在SQL Server Management Studio中新建一個查詢頁面。
2)輸入以下程式段並執行此查詢:
DROP DATABASE STUDENTS
說明:當有別的使用者正在使用此數據庫時,則不能進行刪除操作。
- 6.將已存在的數據庫Student3重新命名爲Student_Back。
實現的步驟如下:
1)在SQL Server Management Studio中新建一個查詢頁面。
2)輸入以下程式段並執行此查詢:
SP_RENAMEDB 'STUDENT3','STUDENT_BACK'
第6章 表的建立與管理
1 表的基本概念
- 概述 :在數據庫中,表是由數據按一定的順序和格式構成的數據集合,是組成數據庫的基本元素。表由行和列組成,因此也稱爲二維表。每行代表一個記錄,每列代表記錄的一個欄位。
- 1.表結構
組成表的各列的名稱及數據型別,統稱爲表結構。 - 2.記錄
每個表包含了若幹行數據,它們是表的「值」。表中的一行稱爲一個記錄。因此,表是記錄的有限集合。 - 3.欄位
每個記錄由若幹個數據項構成。將構成記錄的數據項稱爲欄位。例如,表6-1中的表結構爲(學號,姓名,性別,出生日期,專業,總學分,備註),包含7個欄位,由8個記錄組成。 - 4.空值
空值(NULL)通常表示未知、不可用或將在以後新增的數據。若某列允許爲空值,則向表中輸入記錄時可不爲該列給出具體值;若某列不允許爲空值,則在輸入時必須給出具體值。 - 5.關鍵字
如果表中記錄的某個欄位或欄位組合能唯一標識記錄,則稱該欄位或欄位組合爲候選關鍵字(Candidate Key)。若一個表有多個候選關鍵字,則選定其中一個爲主關鍵字(Primary Key),也稱爲主鍵。當一個表僅有唯一的一個候選關鍵字時,該候選關鍵字就是主關鍵字。這裏的主關鍵字與前面講的主鍵所起的作用是相同的,都用來唯一標識記錄。
外來鍵就可以達到這個目的。它是對應主鍵而言的,就是「子表」中對應於「主表」的列,在「子表」中稱爲外來鍵或參照鍵。它的值要求與主表的主鍵相對應。外來鍵用來強制參照完整性。一個表可以有多個外來鍵。
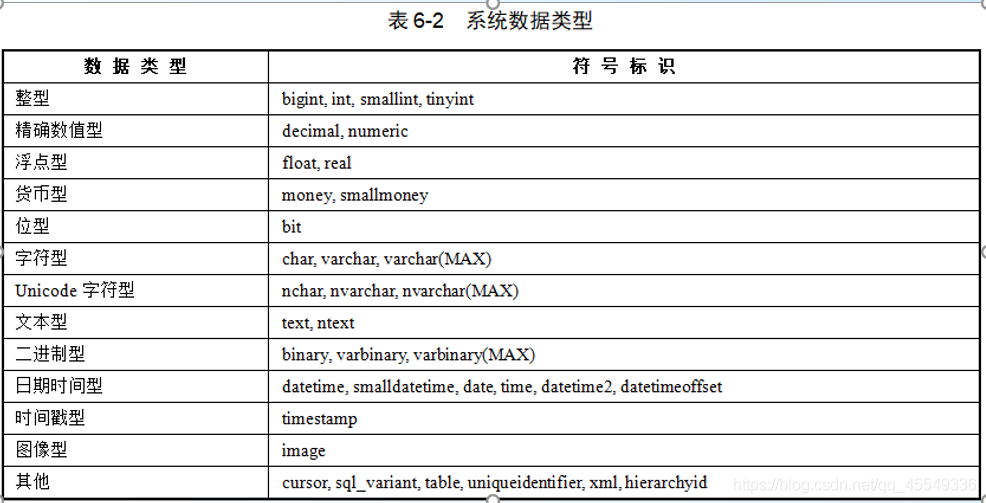
2 數據型別
3 使用T-SQL語句建立表
CREATE TABLE
[database_name.[owner].|owner.]table_name
({<column_definition>|column_name AS computed_column_expression|
<table_constraint>}[,…n])
[ON{ filegroup|DEFAULT}]
[TEXTIMAGE_ON { filegroup|DEFAULT}]
<column_definition>::={column_name data_type}
[COLLATE <collation_name>]
[[DEFAULT constant_expression]
|[IDENTITY[(seed,increment) [NOT FOR REPLICATION]]]]
[ROWGUIDCOL]
[<column_constraint>][,…n]
各參數的說明如下。
database_name:用於指定所建立表的數據庫名稱。
owner:用於指定新建表的所有者的使用者名稱。
table_name:用於指定新建表的名稱。
column_name:用於指定新建表的列名。
computed_column_expression:用於指定計算列的列值表達式。
ON {filegroup | DEFAULT}:用於指定儲存表的檔案組名。
TEXTIMAGE_ON:用於指定text,ntext和image列的數據儲存的檔案組。
data_type:用於指定列的數據型別。
COLLATE:用於指定表的校驗方式。
DEFAULT:用於指定列的預設值。
constant_expression:用於指定列的預設值的常數表達式,可以爲一個常數或NULL或系統函數。
IDENTITY(seed, increment):用於將列指定爲標識列。其中,seed用於指定標識列的初始值,increment用於指定標識列的增量值。
NOT FOR REPLICATION:用於指定列的IDENTITY屬性在把從其他表中複製的數據插到表中時不發生作用,即不生成列值,使得複製的數據行保持原來的列值。
ROWGUIDCOL:用於將列指定爲全域性唯一識別符號列(Row Global Unique Identifier Column)。
column_constraint和table_constraint:用於指定列約束和表約束。
約束
約束是SQL Server提供的自動保持數據庫完整性的一種方法,它通過限制欄位中的數據、記錄中的數據和表之間的數據來保證數據的完整性。在SQL Server中,對於基本表的約束分爲列級約束和表級約束兩種。
1)列級約束
列級約束也稱欄位約束,可以使用以下短語進行定義。
[NOT NULL|NULL]:定義不允許或允許欄位值爲空。
[PRIMARY KEY CLUSTERED|NON CLUSTERED:定義該欄位爲主鍵並建立聚集或非聚集索引。
[REFERENCE <參照表>(<對應欄位>)]:定義該欄位爲外來鍵,並指出被參照表及對應欄位。
[DEFAULT <預設值>]:定義欄位的預設值。
[CHECK(<條件>)]:定義欄位應滿足的條件表達式。
[IDENTITY(<初始值>,<步長>)]:定義欄位爲數值型數據,並指出它的初始值和逐步增加的步長值。
(2)表級約束
表級約束也稱記錄約束,語法格式爲:
CONSTRAINT <約束名> <約束式>
約束式主要有以下幾種。
[PRIMARY KEY [CLUSTERED|NONCLUSTERED](<列名組>)]:定義表的主鍵並建立主鍵的聚集或非聚集索引。
[FOREIGN KEY(<外來鍵>)REFERENCES<參照表>(<對應列>)]:指出表的外來鍵和被參照表。
[CHECK(<條件表達式>)]:定義記錄應滿足的條件。
[UNIQUE(<列組>)]:定義不允許重複值的欄位組。
習題
1.在一個表上可以定義多個CHECK約束。
2.建立表的語句是:CREATE TABLE 表名。
3.數據完整性包括:實體完整性、域完整性、參照完整性和使用者定義完整性。
4.刪除表Course中的Course_Name列所使用的語句是:
ALTER TABLE Course
DROP Course_Name
5.爲表Student刪除主鍵約束的語句程式碼是:
ALTER TABLE Student
DROP CONSTRAINT 約束名 PRIMARY KEY
6.假定利用CREATE TABLE 命令建立下面 下麪的BOOK表:
CREATE TABLE BOOK
(
總編號 char(6),
分類號 char(6),
書名 char(6),
單價 numeric(10,2)
)
則「單價」列的數據型別爲_數值_型,列寬度爲10,其中包含有2位小數。
第7章 數據的輸入與維護
習題
一、填空題
1.T-SQL語言中,將數據插入到數據表的語句是__,修改數據的語句是_。
2.SQL語言中,刪除一個表中所有數據,但保留表結構的命令是__。
答:
1.T-SQL語言將數據插入到數據表的語句是_INSERT_,修改數據的語句是_UPDATE_
2.SQL語言中,刪除一個表中所有數據,但保留表結構的命令是_DELETE_。
二、單項選擇題
1.SQL語言集數據查詢、數據操作、數據定義和數據控制功能於一體,語句INSERT、DELETE、UPDATE實現哪類功能__。B
A.數據查詢 B.數據操縱 C.數據定義 D.數據控制
2.下面 下麪關於INSERT語句的說法正確的是__。A
A.INSERT一次只能插入一行的元組 B.INSERT只能插入不能修改
C.INSERT可以指定要插入到哪行 D.INSERT可以加WHERE條件
第8章 數據查詢
1.SQL語句中條件短語的關鍵字是 where 。
2.在SELECT語句中, order 子句根據列的數據對查詢結果進行排序。
3.聯合查詢(連線查詢)指使用join運算將多個表合併到一起。
4.當一個子SELECT的結果作爲查詢的條件,即在一個SELECT語句的WHERE子句中出現另一個SELECT語句,這種查詢稱爲 巢狀 查詢。
5.在SELECT語句中,定義一個區間範圍的特殊運算子是 between ,檢查一個屬性值是否屬於一組值中的特殊運算子是 in 。
6.已知「出生日期」求「年齡」的表達式是 YEAR(GETDATE()) – YEAR(出生日期) 。
7.語句「SELECT * FROM 成績表WHERE 成績>(SELECT Avg(成績) FROM 成績表)」的功能是查詢成績表中成績大於成績平均分的所有記錄。
8.採用全外連線操作時,查詢結果中包括連線表中的所有數據行。
Mg:對第3小題,(連線查詢)是我加的。有些書籍(網站)把union當作聯合查詢,合併的是查詢結果,但本書中UNION查詢屬於3個集合查詢之一,相對來說連線查詢看作聯合查詢更貼切一些——百度搜尋也是有把join當作聯合查詢的。孰對孰錯就不去過度追究了。
二、單項選擇題
1.在SELECT語句中,如果需要顯示的內容使用「*」,則表示________。B
A.選擇任何屬性 B.選擇所有屬性
C.選擇所有元組 D.選擇主鍵
2.查詢時若要去掉重複的元組,則在SELECT語句中使用________。D
A.All B.UNION C.LIKE D.DISTINCT
3.使用SELECT語句進行分組檢索時,爲了去掉不滿足條件的分組,應當________。B
A.使用WHERE子句
B.在GROUP BY後面使用HAVING子句
C.先使用WHERE子句,再使用HAVING子句
D.先使用HAVING子句,再使用WHERE子句
4.在SQL語句中,與表達式「倉庫號NOT IN("wh1","wh2")」功能相同的表達式是________。D
A.倉庫號="wh1" And 倉庫號="wh2" B.倉庫號<>"wh1" Or 倉庫號<>"wh2"
C.倉庫號<>"wh1" Or 倉庫號="wh2" D.倉庫號<>"wh1" And 倉庫號<>"wh2"
第5~8題使用如下3個表:
部門:部門號 Char (8),部門名 Char (12),負責人 Char (6),電話 Char (16)
職工:部門號 Char (8),職工號 Char(10),姓名 Char (8),性別 Char (2),
出生日期 Datetime
工資:職工號 Char (10),基本工資 Numeric (8, 2),津貼 Numeric (8, 2),
獎金 Numeric (8, 2),扣除Numeric (8, 2)
5.查詢職工實發工資的正確命令是________。C
A.SELECT 姓名,(基本工資+津貼+獎金扣除) AS 實發工資 FROM 工資
B.SELECT 姓名,(基本工資+津貼+獎金扣除) AS 實發工資 FROM 工資 WHERE 職工.職工號=工資.職工號
C.SELECT 姓名,(基本工資+津貼+獎金扣除) AS 實發工資 FROM 工資,職工 WHERE 職工.職工號=工資.職工號
D.SELECT 姓名,(基本工資+津貼+獎金扣除) AS 實發工資 FROM 工資 JOIN 職工 WHERE 職工.職工號=工資.職工號
6.查詢1972年10月27日出生的職工資訊的正確命令是________。D
A.SELECT * FROM 職工 WHERE 出生日期={1972-10-27}
B.SELECT * FROM 職工 WHERE 出生日期=1972-10-27
C.SELECT * FROM 職工 WHERE 出生日期="1972-10-27"
D.SELECT * FROM 職工 WHERE 出生日期='1972-10-27'
7.查詢每個部門年齡最長者的資訊,要求得到的資訊包括部門名和最長者的出生日期,正確的命令是________。A
A.SELECT 部門名,MIN(出生日期) FROM 部門 JOIN 職工 ON 部門.部門號=
職工.部門號 GROUP BY 部門名
B.SELECT 部門名,MAX(出生日期) FROM 部門 JOIN 職工 ON 部門.部門號=
職工.部門號 GROUP BY 部門名
C.SELECT 部門名,MIN(出生日期) FROM 部門 JOIN 職工 WHERE 部門.部門號=職工.部門號 GROUP BY 部門名
D.SELECT 部門名,MAX(出生日期) FROM 部門 JOIN 職工 WHERE 部門.部門號=職工.部門號 GROUP BY 部門名
8.查詢所有目前年齡在35歲以上(不含35歲)的職工資訊(姓名、性別和年齡),正確的命令是________。C
A.SELECT 姓名,性別,YEAR(GETDATE())-YEAR(出生日期) AS 年齡 FROM 職工 WHERE 年齡>35
B.SELECT 姓名,性別,YEAR(GETDATE())-YEAR(出生日期) AS年齡 FROM 職工 WHERE YEAR(出生日期)>35
C.SELECT 姓名,性別,YEAR(GETDATE())-YEAR(出生日期) AS年齡 FROM 職工 WHERE YEAR(GETDATE())-YEAR(出生日期)>35
D.SELECT 姓名,性別,年齡=YEAR(GETDATE())-YEAR(出生日期) FROM 職工 WHERE YEAR(GETDATE())-YEAR(出生日期)>35
第9章 檢視
檢視的基礎知識
- 檢視是一種數據庫物件,它是從一個或多個表或檢視中導出的虛表,也就是說,它可以從一個或多個表中的一列或多列中提取數據,並按照表的行和列來顯示這些資訊,可以把檢視看作一個能把焦點定在使用者感興趣的數據上的監視器。
- 檢視是虛擬的表。與表不同的是,檢視本身並不儲存檢視中的數據。檢視是由表派生的。派生表被稱爲檢視的基本表,簡稱基表。檢視可以來源於一個或多個基表的行或列的子集,也可以是基表的統計彙總,或者是檢視與基表的組合。檢視中的數據是通過檢視定義語句由其基表中動態查詢得來的。
一、單項選擇題
1.SQL的檢視是從_______中導出的。C
A.基本表 B.檢視 C.基本表或檢視 D.數據庫
2.在檢視上不能完成的操作是_______。C
A.更新檢視數據 B.查詢
C.在檢視上定義新的基本表 D.在檢視上定義新檢視
3.關於數據庫檢視,下列說法正確的是_______。C
A.檢視可以提高數據的操作效能
B.定義檢視的語句可以是任何數據操作語句
C.檢視可以提供一定程度的數據獨立性
D.檢視的數據一般是物理儲存的
4.在下列關於檢視的敘述中,正確的是_______。 A
A.當某一檢視被刪除後,由該檢視導出的其他檢視也將被自動刪除
B.若導出某檢視的基本表被刪除了,則該檢視不受任何影響
C.檢視一旦建立,就不能被刪除
D.當修改某一檢視時,導出該檢視的基本表也隨之被修改
二、簡答題
1.簡答檢視的作用及檢視的優缺點。
答:
檢視是一種數據庫物件,它是從一個或多個表或檢視中導出的虛表,即它可以從一個或多個表中的一個或多個列中提取數據,並按照表的組成行和列來顯示這些資訊,可以把檢視看做是一個能把焦點定在使用者感興趣的數據上的監視器。
使用檢視有下列優點:
① 爲使用者集中數據,簡化使用者的數據查詢和處理。有時使用者所需要的數據分散在多個表中,定義檢視可將它們集中在一起,從而方便使用者進行數據查詢和處理。
② 遮蔽數據庫的複雜性。使用者不必瞭解複雜的數據庫中的表結構,並且數據庫表的更改也不影響使用者對數據庫的使用。
③ 簡化使用者許可權的管理。只需授予使用者使用檢視的許可權,而不必指定使用者只能使用表的特定列,也增加了安全性。
④ 便於數據共用。各使用者不必都定義和儲存自己所需的數據,而可共用數據庫的數據,這樣,同樣的數據只需儲存一次。
⑤ 可以重新組織數據以便輸出到其他應用程式中。
檢視的缺點主要表現在其對數據修改的限制上。當更新檢視中的數據時,實際上就是對基本表的數據進行更新。事實上,當從檢視中插入或者刪除時,情況也是一樣。然而,某些檢視是不能更新數據的,這些檢視有如下的特徵:
① 有UNION等集合操作符的檢視。
② 有GROUP BY子句的檢視。
③ 有諸如AVG、SUM等函數的檢視。
④ 使用DISTINCT短語的檢視。
⑤ 連線表的檢視(其中有一些例外)。
所以檢視的主要用途在於數據的查詢。在使用檢視時,要注意只能在當前數據庫中建立與儲存檢視,並且定義檢視的基表一旦被刪除,則檢視也將不可再用。
2.簡答基本表與檢視的區別和聯繫。
答:
檢視是虛擬的表,與表不同的是,檢視本身並不儲存檢視中的數據,檢視是由表派生的,派生表被稱爲檢視的基本表,簡稱基表。檢視可以來源於一個或多個基表的行或列的子集,也可以是基表的統計彙總,或者是檢視與基表的組合,檢視中的數據是通過檢視定義語句由其基本表中動態查詢得來的。
3.簡答檢視檢視定義資訊的方法。
答:
系統儲存過程sp_help可以顯示數據庫物件的特徵資訊,sp_helptext可以用於顯示檢視、觸發器或儲存過程等在系統表中的定義,sp_depends可以顯示數據庫物件所依賴的物件。它們的語法形式分別如下:
sp_help 數據庫物件名稱
sp_helptext 檢視(觸發器、儲存過程)
sp_depends 數據庫物件名稱
第10章 索引
簡述
在SQL Server中,數據儲存的基本單位是頁。一個頁是8KB的磁碟物理空間。向數據庫中插入數據時,數據按照插入的時間順序被放置在頁中。通常,放置數據的順序與數據本身的邏輯關係之間並沒有任何的關係。因此,從數據之間的邏輯關係方面來講,數據是亂七八糟地堆放在一起的。數據的這種堆放方式稱爲「堆」。當一個頁中的數據堆滿之後,其他的數據就堆放在另外一個頁中。
習題
一、填空題
1.在索引命令中使用關鍵字CLUSTERED和NONCLUSTERED表示將分別建立_______索引和_______索引。
2.存取數據庫中的數據有兩種方法,分別是:_______和_______。
3.索引一旦建立,將由_______自動管理和維護。
4.在一個表中,最多可以定義_______個聚集索引,最多可以有______個非聚集索引。
答:
1.在索引命令中使用關鍵字CLUSTERED和NONCLUSTERED分別表示將建立的是_聚集_索引和_非聚集__索引。
2.存取數據庫中的數據有兩種方法,分別是:__表掃描______和____索引查詢____。
3.索引一旦建立,將由__數據庫管理系統_____自動管理和維護。
4.在一個表上,最多可以定義___1____個聚集索引,最多可以有___多個__非聚集索引。
二、單項選擇題
1.爲數據表建立索引的目的是_______。A
A.提高查詢的檢索效能 B.節省儲存空間
C.便於管理 D.歸類
2.索引是指對數據庫表中_______欄位的值進行排序。C
A.一個 B.多個 C.一個或多個 D.零個
3.下列_______屬性不適合建立索引。D
A.經常出現在GROUP BY字句中的屬性 B.經常參與連線操作的屬性
C.經常出現在WHERE字句中的屬性 D.經常需要進行更新操作的屬性
三、簡答題
1.簡述引入索引的主要目的。
答:
索引是數據庫隨機檢索的常用手段,它實際上就是記錄的關鍵字與其相應地址的對應表。通過索引可大大提高查詢速度。
在沒有建立索引的表內,使用堆的集合方法組織數據頁。在堆的集閤中,數據行不按任何順序進行儲存,數據頁序列也沒有任何特殊順序。因此,掃描這些數據堆集花費的時間肯定較長。在建有索引的表內,數據行基於索引的鍵值按順序存放,必然改善了系統查詢數據的速度。
2.簡述聚集索引和非聚集索引的區別。
答:
根據索引的順序與數據表的物理順序是否相同,可以把索引分爲聚集索引和非聚集索引。聚集索引會對磁碟上的數據進行物理排序,所以這種索引對查詢非常有效。表中只能有一個聚集索引。當建立主鍵約束時,如果表中沒有聚集索引,SQL Server會用主鍵列作爲聚集索引鍵。聚集索引將數據行的鍵值在表內排序並儲存對應的數據記錄,使數據表的物理順序與索引順序相同。
非聚集索引與圖書中的目錄類似。非聚集索引不會對錶進行物理排序,數據記錄與索引分開儲存。使用非聚集索引不會影響數據表中記錄的實際儲存順序。非聚集索引中儲存了組成非聚集索引的關鍵字值和行定位器。由於非聚集索引使用索引頁儲存,因此它比聚集索引需要較少的儲存空間,但檢索效率比聚集索引低。由於一個表只能建一個聚集索引,當使用者需要建立多個索引時,就需要使用非聚集索引了。每個表中最多隻能建立249個非聚集索引。
3.刪除索引時,其所對應的數據表會被刪除嗎?
答:
不會
第11章 T-SQL語言、遊標和函數
T-SQL語言的構成
- 數據定義語言(DDL)
- 數據操縱語言(DML)
- 數據控制語言(DCL)
- T-SQL增加的語言元素
常數與變數
- 常數是指在程式執行過程中其值不變的量。(字串常數、數值常數、日期常數)
- 變數是指在程式執行過程中其值可以改變的量。變數又分爲區域性變數和全域性變數。
習題
一、填空題
1.T-SQL中的變數分爲區域性變數與全域性變數,區域性變數用_____開頭,全域性變數用____開頭。
2.T-SQL提供了______運算子,用於將兩個字元數據連線起來。
3.在WHILE回圈體內可以使用BREAK和CONTINUE語句,其中______語句用於終止回圈的執行,______語句用於將回圈返回到WHILE開始處,重新判斷條件,以決定是否重新執行新的一次回圈。
4.在T-SQL中,若回圈體內包含多條語句,則必須用______語句括起來。
5.在T-SQL中,可以使用巢狀的IF…ELSE語句來實現多分支選擇,也可以使用______語句來實現多分支選擇。
6.在自定義函數中,語句RETURNS INT表示該函數的返回值是一個整型數據,______表示該函數的返回值是一個表。
答:
1.T-SQL中的變數分爲區域性變數與全域性變數,區域性變數用__@____ 開頭,全域性變數用__@@____開頭。
2.T-SQL提供了___+___運算子,將兩個字元數據連線起來。
3.在WHILE回圈體內可以使用BREAK和CONTINUE語句,其中__ BREAK ____語句用於終止回圈的執行,__ CONTINUE ____語句用於將回圈返回到WHILE開始處,重新判斷條件,以決定是否重新執行新的一次回圈。
4.在T-SQL中,若回圈體內包含多條語句時,必須用__ BEGIN…END ____語句括起來。
5.在T-SQL中,可以使用巢狀的IF…ELSE語句來實現多分支選擇,也可以使用___ CASE ___語句來實現多分支選擇。
6.在自定義函數中,語句RETURNS INT表示該函數的返回值是一個整型數據,_ RETURNS TABLE _____表示該函數的返回值是一個表。
二、簡答題
1.什麼是批次處理?編寫批次處理時應注意哪些問題?
答:
批次處理就是一個或多個T-SQL語句的集合,使用者或應用程式一次將它發送給SQL Server,由SQL Server編譯成一個執行單元,此單元稱爲執行計劃,執行計劃中的語句每次執行一條。批次處理的種類較多,如儲存過程、觸發器、函數內的所有語句都可構成批次處理。
某些SQL語句不能放在同一個批次處理中執行,它們需要遵循下述規則:
① 多數CREATE 命令要在單個批次處理中執行,但CREATE DATABASE、CREATE TABLE、CREATE INDEX除外。
② 呼叫儲存過程時,如果它不是批次處理中第一個語句,則在它前面必須加上EXECUTE。
③ 不能把規則和預設值系結到使用者定義的數據型別上後,在同一個批次處理中使用它們。
④ 不能在給表欄位定義了一個CHECK約束後,在同一個批次處理中使用該約束。
⑤ 不能在修改表的欄位名後,在同一個批次處理中參照該新欄位名。
⑥ 一個批次處理中,只能參照全域性變數或自己定義的區域性變數。
2.什麼是遊標?如何使用遊標?
答:
數據庫的遊標是類似於C語言指針一樣的語言結構。通常情況下,數據庫執行的大多數SQL命令都是同時處理集合內部的所有數據。但是,有時侯使用者也需要對這些數據集閤中的每一行進行操作。在沒有遊標的情況下,這種工作不得不放到數據庫前端,用高階語言來實現。這將導致不必要的數據傳輸,從而延長執行的時間。通過使用遊標,可以在伺服器端有效地解決這個問題。遊標提供了一種在伺服器內部處理結果集的方法,它可以識別一個數據集合內部指定的工作行,從而可以有選擇地按行採取操作。
使用者在使用遊標時,應先宣告遊標,然後開啓並使用遊標,使用完後應關閉遊標、釋放資源。
3.簡答常用函數的分類。
答:
T-SQL程式語言提供了4種系統內建函數:行集函數、聚合函數、Ranking函數、標量函數。SQL Server提供的常用標量函數包括:數學函數、字串函數、日期和時間函數、遊標函數、元數據函數、設定函數、系統函數等。
第12章 儲存過程
儲存過程的基本概念
1.儲存過程的定義
儲存過程就是預先編譯和優化並儲存於數據庫中的過程,是由一系列對數據庫進行復雜操作的SQL語句、流程控制語句或函陣列成的批次處理作業。
2.儲存過程的特點
(1)大大增強了SQL語言的功能和靈活性
(2)可保證數據的安全性和完整性
(3)更快的執行速度
(4)將體現企業規則的運算放入數據庫伺服器中以便集中控制
3. 儲存過程的型別
在SQL Server中,儲存過程分爲3類:
1.系統儲存過程
2.擴充套件儲存過程
3.使用者儲存過程
(1)儲存過程
(2)CLR儲存過程
習題
一、填空題
1.儲存過程是SQL Server伺服器中________T-SQL語句的集合。
2.SQL Server中的儲存過程包括________、________和________三種類型。
3.建立儲存過程實際上是對儲存過程進行定義的過程,主要包含儲存過程名稱及其_______和儲存過程的主體兩部分。
4.在定義儲存過程時,若有輸入參數,則應放在關鍵字AS的________說明,若有區域性變數,則應放在關鍵字AS的________定義。
5.在儲存過程中,若在參數的後面加上________,則表明此參數爲輸出參數,執行該儲存過程時必須宣告變數來接收返回值,並且在變數後必須使用關鍵字 。
答:
1.儲存過程是SQL Server伺服器中_一組預編譯的___T-SQL語句的集合。
2.SQL Server中的儲存過程包括__系統儲存過程______、____擴充套件儲存過程____和__使用者儲存過程______3種類型。
3.建立儲存過程實際是對儲存過程進行定義的過程,主要包含儲存過程名稱及其__參數______和儲存過程的主體兩部分。
4.在定義儲存過程時,若有輸入參數則應放在關鍵字AS的___前面____說明,若有區域性變數則應放在關鍵字AS的____後面____定義。
5.在儲存過程中,若在參數的後面加上____ OUTPUT ____,則表明此參數爲輸出參數,執行該儲存過程必須宣告變數來接受返回值並且在變數後必須使用關鍵字 。
二、選擇題
1.在SQL Server伺服器中,儲存過程是一組預先定義並________的T-SQL語句。B
A.儲存 B.編譯 C.解釋 D.編寫
2.使用EXECUTE語句來執行儲存過程時,在________情況下可以省略該關鍵字。A
A.EXECUTE語句如果是批次處理中的第一條語句時
B.EXECUTE語句在DECLARE語句之後
C.EXECUTE在GO語句之後
D.任何時候
3.用於檢視錶的行數及表使用的儲存空間資訊的系統儲存過程是________。A
A.sq_spaceused B.sq_depends C.sq_help D.sq_rename
三、簡答題
1.什麼是儲存過程?請分別寫出使用SSMS和T-SQL語句建立儲存過程的主要步驟。
答:
儲存過程是一組編譯在單個執行計劃中的T-SQL語句,它將一些固定的操作集中起來交給SQL Server數據庫伺服器完成,以實現某個任務。
儲存過程就是預先編譯和優化並儲存於數據庫中的過程,由一系列對數據庫進行復雜操作的SQL語句、流程控制語句或函陣列成的批次處理作業。它像規則、檢視那樣作爲一個獨立的數據庫物件進行儲存管理。儲存過程通常是在SQL Server伺服器上預先定義並編譯成可執行計劃。在呼叫它時,可以接受參數、返回狀態值和參數值,並允許巢狀呼叫。
使用SSMS建立儲存過程的操作步驟如下。
1)啓動SSMS,在「物件資源管理器」窗格中展開伺服器,然後展開數據庫StudentManagement節點下的「可程式化性」節點。
2)右鍵單擊「儲存過程」選項,在彈出的快捷選單中,選擇「新建儲存過程」選單項。
3)開啓「儲存過程指令碼編輯」視窗。在該視窗中輸入要建立的儲存過程的程式碼,輸入完成後單擊「執行」按鈕,若執行成功則建立完成。
使用者可以使用CREATE PROCEDURE命令建立儲存過程,但要注意下列幾個事項:
① CREATE PROCEDURE語句不能與其他SQL語句在單個批次處理中組合使用。
② 必須具有數據庫的CREATE PROCEDURE許可權。
③ 只能在當前數據庫中建立儲存過程。
④ 不要建立任何使用sp_作爲字首的儲存過程。
CREATE PROCEDURE的語法形式如下:
CREATE { PROC | PROCEDURE } [schema_name.] procedure_name
[ { @parameter [ type_schema_name. ] data_type }
[ VARYING ] [ = default ] [ OUT | OUTPUT ] ] [ ,...n ] [ WITH ENCRYPTION ]
AS { <sql_statement> [;][ ...n ] }[;]
<sql_statement> ::= { [ BEGIN ] statements [ END ] }
2.如何將數據傳遞給一個儲存過程?如何將儲存過程的結果值返回?
答:
將數據值傳遞給儲存過程,儲存過程用來接收傳遞進來數據值的參數就是所謂的「輸入參數」。建立帶參數的儲存過程的語句格式:
CREATE PROC[EDURE] procedure_name
[{@parameter data_type} [=DEFAULT][OUTPUT]][ ,…n]
[WITH{RECOMPILE | ENCRYPTION| RECOMPILE, ENCRYPTI○N}]
AS sql_ statements
從儲存過程中返回一個或多個值,可以通過在建立儲存過程的語句中定義輸出參數來實現。爲了使用輸出參數,需要在CREATE PROCEDURE語句中指定OUTPUT關鍵字。通過使用輸出參數,任何由於執行了儲存過程的參數變化都可以保留,即使在儲存過程完全完成之後。具體語法如下:
@parameter_name datatype[=default] OUTPUT [ ,…n]
第13章 觸發器
觸發器的基本概念
- 觸發器的型別
1.DML觸發器
DML觸發器又分爲AFTER觸發器和INSTEAD OF觸發器兩種。
(1)AFTER觸發器
(2)INSTEAD OF觸發器
2.DDL觸發器
習題
1.觸發器是一種特殊的________,基於表而建立,主要用來保證數據的完整性。
2.觸發器可以在對一個表進行________、________和________操作中的任一種或幾種操作時被自動呼叫執行。
3.替代觸發器(INSTEAD OF)在數據變動前被觸發。對於每個觸發操作,只能定義________個INSTEAD OF 觸發器。
4.當某個表被刪除後,該表上的________將自動被刪除。
答:
1.觸發器是一種特殊的_儲存過程_______,基於表而建立,主要用來保證數據的完整性。
2.觸發器可以在對一個表進行__ INSERT ______、__ DELETE ______和___ UPDATE _____操作中的任一種或幾種操作時被自動呼叫執行。
3.替代觸發器(INSTEAD OF)將在數據變動前被觸發,對於每個觸發操作,只能定義________個INSTEAD OF 觸發器。
4.當某個表被刪除後,該表上的__所有觸發器______將自動被刪除。
二、選擇題
1.在SQL Server中,觸發器不具有________型別。D
A.INSERT觸發器 B.UPDATE觸發器
C.DELETE觸發器 D.SELECT觸發器
2.SQL Server爲每個觸發器建立了兩個臨時表,它們是________。B
A.inserted和updated B.inserted和deleted
C.updated和deleted D.selected和inserted
三、簡答題
1.什麼是觸發器?SQL Server有哪幾種類型的觸發器?
答:
觸發器是一種專用型別的儲存過程,它被捆綁到數據表或檢視上。換言之,觸發器是一種在數據表或檢視被修改時自動執行的內嵌儲存過程,主要是通過事件觸發而被執行。觸發器不允許帶參數,也不能直接呼叫,只能自動被激發。
在SQL Server中,按照觸發事件的不同可以將觸發器分爲兩大類:DML觸發器和DDL觸發器。
1.DML觸發器
DML觸發器是在使用者使用數據操作語言(DML)事件編輯數據時發生。DML事件是針對表或檢視的INSERT、UPDATE或DELETE語句。DML觸發器有助於在表或檢視中修改數據時強制業務規則,擴充套件數據完整性。
DML觸發器又分爲AFTER觸發器和INSTEAD OF觸發器兩種:
(1)AFTER觸發器
這種型別的觸發器將在數據變動(INSERT、UPDATE和DELETE操作)完成以後才被觸發。AFTER觸發器只能在表上定義。
(2)INSTEAD OF觸發器
INSTEAD OF觸發器將在數據變動以前被觸發,並取代變動數據的操作,而去執行觸發器定義的操作。INSTEAD OF觸發器可以在表或檢視上定義。每個INSERT、UPDATE和DELETE語句最多定義一個INSTEAD OF觸發器。
2.DDL觸發器
DDL觸發器也是由相應的事件觸發的,但DDL觸發器觸發的事件是數據定義語句(DDL)。這些語句主要是以CREATE、ALTER、DROP等關鍵字開頭的語句。DDL觸發器的主要作用是執行管理操作,例如審覈系統、控制數據庫的操作等。在通常情況下,DDL觸發器主要用於以下一些操作需求:防止對數據庫架構進行某些修改;希望數據庫中發生某些變化以利於相應數據庫架構中的更改;記錄數據庫架構中的更改或事件。DDL觸發器只在響應由T-SQL語法所指定的DDL事件時纔會觸發。
第14章 數據庫的備份和還原
習題
一、選擇題
1. 下面 下麪哪個不是備份數據庫的理由( D )?
A. 數據庫崩潰時恢復。
B. 將數據從一個伺服器轉移到另外一個伺服器。
C. 記錄數據的歷史檔案。
D. 轉換數據
2. 防止數據庫出現意外的有效方法是( C )。
A. 重建 B. 追加 C. 備份 D. 刪除
3. 在SQL Server的設定及其他數據被改變以後,都應該備份的數據庫是( A )。
A. Master B. Model C. Msdb D. Tempdb
4. 能將數據庫恢復到某個時間點的備份型別是( B )。
A. 完整數據庫備份 B. 差異備份
C. 事務日誌備份 D. 檔案組備份
二、簡答題
1.什麼是備份裝置?
答:
備份裝置是用來儲存數據庫、事務日誌或檔案和檔案組備份的儲存媒介,可以是硬碟、磁帶或管道。當使用磁碟時,SQL Server允許將本地主機硬碟和遠端主機上的硬碟作爲備份裝置。備份裝置在硬碟中是以檔案的方式儲存的。
2.SQL Server數據庫備份有幾種方法?試比較各種不同數據備份方法的異同點。
答:
SQL Server 2008中有兩種基本的備份:一是隻備份數據庫,二是備份數據庫和事務日誌,它們又都可以與完全或差異備份相結合。另外,當數據庫很大時,也可以進行個別檔案或檔案組的備份,從而將數據庫備份分割爲多個較小的備份過程。這樣就形成了以下4種備份方法:
① 完全數據庫備份
這種方法按常規定期備份整個數據庫,包括事務日誌。當系統出現故障時,可以恢復到最近一次數據庫備份時的狀態,但自該備份後所提交的事務都將丟失。
完全數據庫備份的主要優點是簡單,備份是單一操作,可按一定的時間間隔預先設定,恢復時只需一個步驟就可以完成。
② 數據庫和事務日誌備份
這種方法不需很頻繁地定期進行數據庫備份,而是在兩次完全數據庫備份期間,進行事務日誌備份,所備份的事務日誌記錄了兩次數據庫備份之間所有的數據庫活動記錄。當系統出現故障後,能夠恢復所有備份的事務,而只丟失未提交或提交但未執行完的事務。
執行恢復時,需要兩步:首先恢復最近的完全數據庫備份,然後恢復在該完全數據庫備份以後的所有事務日誌備份。
③ 差異備份
差異備份只備份自上次數據庫備份後發生更改的部分數據庫,它用來擴充完全數據庫備份或數據庫和事務日誌備份方法。對於一個經常修改的數據庫,採用差異備份策略可以減少備份和恢復時間。差異備份比全量備份工作量小而且備份速度快,對正在執行的系統影響也較小,因此可以更經常地備份。經常備份將減少丟失數據的危險。
使用差異備份方法,執行恢復時,若是數據庫備份,則用最近的完全數據庫備份和最近的差異數據庫備份來恢復數據庫;若是差異數據庫和事務日誌備份,則需用最近的完全數據庫備份和最近的差異備份後的事務日誌備份來恢復數據庫。
④ 數據庫檔案或檔案組備份
這種方法只備份特定的數據庫檔案或檔案組,同時還要定期備份事務日誌,這樣在恢復時可以只還原已損壞的檔案,而不用還原數據庫的其餘部分,從而加快了恢復速度。
3.什麼還是原數據庫?當還原數據庫時,使用者可以使用這些正在還原的數據庫嗎?
答:
數據庫還原是指將數據庫備份重新載入到系統中的過程。當還原數據庫的時候,使用者不可以使用這些正在還原的數據庫。
第15章 數據庫的安全管理
SQL Server的安全機制 機製
SQL Server的安全體系結構
(1)操作系統的安全機制 機製
(2)SQL Server伺服器的安全機制 機製
(3)SQL Server數據庫的安全機制 機製
(4)SQL Server數據庫物件的安全機制 機製
SQL Server的身份驗證模式
SQL Server有兩種身份驗證模式:
(1)Windows身份驗證模式
Windows身份驗證模式只在使用者登錄Windows時進行身份驗證,而登錄SQL Server時不再進行身份驗證
(2)SQL Server身份驗證模式
在SQL Server身份驗證模式下,SQL Server伺服器要對登錄的使用者進行身份驗證
習題
一、選擇題
1.當採用Windows驗證方式登錄時,只要使用者通過Windows使用者賬戶驗證,就可以_______到SQL Server數據庫伺服器。A
A. 連線 B. 整合 C. 控制 D. 轉換
2.T-SQL語句的GRANT和REMOVE語句主要用來維護數據庫的_______。C
A. 完整性 B. 可靠性 C. 安全性 D. 一致性
3.可以對固定伺服器角色和固定數據庫角色進行的操作是_______。B
A. 新增 B. 檢視 C. 刪除 D. 修改
4.下列使用者對檢視數據庫物件執行操作的許可權中,不具備的許可權是_______。C
A. SELECT B. INSERT C. EXECUTE D. UPDATE
5.「保護數據庫,防止未經授權的或不合法的使用造成的數據泄露、更改破壞」是指數據的_______。A
A.安全性 B.完整性 C.併發控制 D.恢復
6.在SQL Server中,爲便於管理使用者及許可權,可以將一組具有相同許可權的使用者組織在一起,這一組具有相同許可權的使用者稱爲_______。B
A. 賬戶 B. 角色 C. 登錄 D. SQL Server使用者
二、簡答題
1.簡述SQL Server的安全體系結構。
答:
(1)操作系統的安全防線
在使用者使用客戶計算機通過網路實現對SQL Server伺服器的存取時,使用者首先要獲得客戶計算機操作系統的使用權。
(2)伺服器的安全防線
SQL Server伺服器的安全性是建立在控制伺服器登錄賬號和口令的基礎上的。SQL Server採用了標準的SQL Server 登錄和整合Windows登錄兩種方法。無論是哪種登錄方式,使用者在登錄時提供的登錄賬號和口令決定了使用者能否獲得對SQL Server 伺服器的存取權,以及在獲得存取權後使用者可以利用的資源。設計和管理合理的登錄方式是SQL Server DBA(DataBase Administrator,數據庫管理員)的重要任務,在SQL Server的安全體系中,DBA是發揮主動性的第一道防線。
(3)SQL Server數據庫的安全防線
在使用者通過SQL Server伺服器的安全性檢查以後,將直接面對不同的數據庫入口。這是使用者接受的第三次安全性檢查。
在建立使用者的登錄賬號資訊時,SQL Server會提示使用者選擇預設的數據庫。以後使用者每次連線上伺服器後,都會自動轉到預設的數據庫上。如果在設定登錄賬號時沒有指定預設的數據庫,則對使用者的許可權將侷限在 Master數據庫內。
(4)SQL Server數據庫物件的安全防線
數據庫物件的安全性是覈查使用者許可權的最後一個安全等級。在建立數據庫物件時,SQL Server自動將該數據庫物件的所有權賦予該物件的建立者。物件的所有者可以實現以該物件的完全控制。
2.SQL Server的身份驗證模式有幾種?各是什麼?
答:
安全身份驗證用來確認登錄SQL Server的使用者的登錄帳號和密碼的正確性,由此來驗證該使用者是否具有連線SQL Server的許可權。SQL Server 2008有兩種身份驗證模式:Windows驗證模式和SQL Server驗證模式。
(1)Windows驗證模式
使用者登錄Windows時進行身份驗證,登錄SQL Server時就不再進行身份驗證。以下是對於Windows驗證模式登錄的幾點重要說明。
① 必須將Windows賬戶加入到SQL Server中,才能 纔能採用Windows賬戶登錄SQL Server。
② 如果使用Windows賬戶登錄到另一個網路的SQL Server,則必須在Windows中設定彼此的託管許可權。
(2)SQL Server驗證模式
在SQL Server驗證模式下,SQL Server伺服器要對登錄的使用者進行身份驗證。當SQL Server在Windows XP或Windows 2003等操作系統上執行時,系統管理員設定登錄驗證模式的型別可爲Windows驗證模式和混合模式。當採用混合模式時,SQL Server系統既允許使用Windows登錄名登錄,也允許使用SQL Server登錄名登錄。
3.SQL Server提供哪些型別的約束?
答:
SQL Server中有五種約束型別,分別是CHECK約束、DEFAULT約束、PRIMARY KEY約束、FOREIGN KEY 約束、UNIQUE約束。
4.什麼是角色?伺服器角色和數據庫角色有什麼不同?使用者可以建立哪種角色?
答:
角色是具有一定許可權的使用者組合。SQL Server使用者和角色分爲兩級:一種爲伺服器級使用者和角色;另一種是數據庫級使用者和角色。
伺服器角色是指根據SQL Server的管理任務,以及這些任務相對的重要性等級來把具有SQL Server管理職能的使用者劃分爲不同的使用者組,每一組所具有的管理SQL Server的許可權都是SQL Server內建的。伺服器角色存在於各個數據庫之中,要想加入使用者,該使用者必須有登錄帳號以便加入到角色中。
數據庫角色是爲某一使用者或某一組使用者授予不同級別的管理或存取數據庫以及數據庫物件的許可權,這些許可權是數據庫專有的,並且還可以給一個使用者授予屬於同一數據庫的多個角色。SQL Server提供了兩種型別數據庫角色:固定的數據庫角色和使用者自定義的數據庫角色。
5.SQL Server的許可權有哪幾種?各自的作用物件是什麼?
答:
在SQL Server中包括三種類型的許可權:即物件許可權、語句許可權和預定義許可權。
(1)物件許可權
物件許可權表示對特定的數據庫物件(即表、檢視、欄位和儲存過程)的操作許可權,它決定了能對錶、檢視等數據庫物件執行哪些操作。如果使用者想要對某一物件進行操作,其必須具有相應的操作的許可權。表和檢視許可權用來控制使用者在表和檢視上執行SELECT,INSERT,UPDATE和DELETE語句的能力。欄位許可權用來控制使用者在單個欄位上執行SELECT,UPDATE和REFERENCES操作的能力。儲存過程許可權用來控制使用者執行EXECUTE語句的能力。
(2)語句許可權
語句許可權表示對數據庫的操作許可權,也就是說,建立數據庫或者建立數據庫中的其他內容所需要的許可權型別稱爲語句許可權。這些語句通常是一些具有管理性的操作,如建立數據庫、表和儲存過程等。這種語句雖然仍包含有操作的物件,但這些物件在執行該語句之前並不存在於數據庫中。因此,語句許可權針對的是某個SQL語句,而不是數據庫中已經建立的特定的數據庫物件。
(3)預定義許可權
預定義許可權是指系統安裝以後有些使用者和角色不必授權就有的許可權。其中的角色包括固定伺服器角色和固定數據庫角色,使用者包括數據庫物件所有者。只有固定角色或者數據庫物件所有者的成員纔可以執行某些操作。執行這些操作的許可權就稱爲預定義許可權。
6.簡述規則和CHECK約束的區別,如果在列上已經系結了規則,當再次向它系結規則時,會發生什麼情況?
答:
規則是一組使用T-SQL語句組成的條件語句,規則提供了另外一種在數據庫中實現域完整性與使用者定義完整性的方法。
規則和CHECK約束功能類似,只不過規則可用於多個表中的列,以及使用者自定義的數據型別,而CHECK約束只能用於它所限制的列。一列上只能使用一個規則,但可以使用多個CHECK約束。規則一旦定義爲物件,就可以被多個表的多列所參照。
7.簡述SQL Server實現數據完整性的方法。
答:
數據完整性是指儲存在數據庫中的數據的一致性和準確性。數據的正確性是指防止數據庫中存在不符合語意的數據,而造成無效操作或錯誤資訊。數據的相容性是保護數據庫防止惡意的破壞和非法的存取。數據完整效能夠確保數據庫中數據的品質。
數據完整性包括實體完整性、域完整性和參照完整性。