kafka必修課
Kafkas是什麼?
Kafka是一個分佈式訊息佇列, 也是一個開源訊息系統,由Scala語言寫成。kafka對訊息儲存時根據Topic進行歸類,發送訊息者稱爲Producer,訊息接受者稱爲Consumer,此外 kafka叢集有多個kafka範例組成,每個範例(server)稱爲broker。無論是kafka叢集,還是consumer都依賴於zookeeper叢集儲存一些mate資訊,來保證系統可用性。在通常的流式計算中,kafka 一般用來快取數據,而Storm或者Spark Streaming通過消費kafka的數據進行計算。
Kafka架構分析圖:
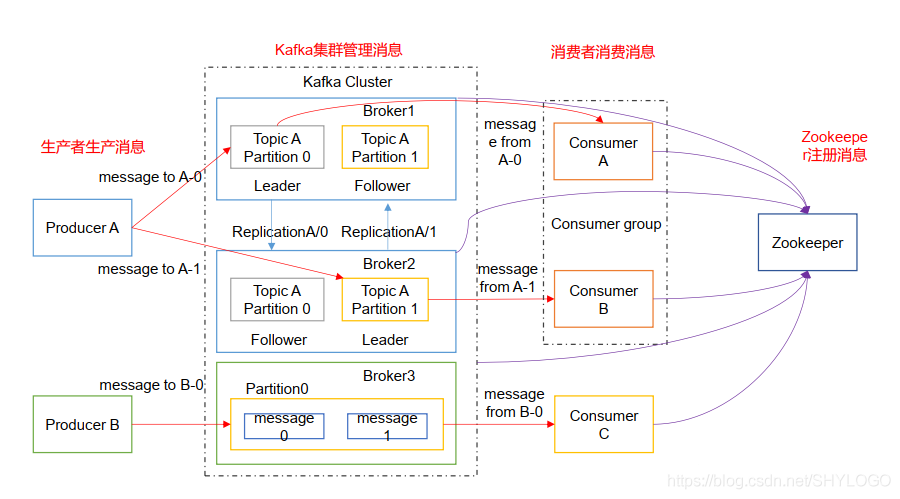
(1)Producer:訊息生產者,就是向kafka broker發訊息的用戶端。
(2)Consumer:訊息消費者,向kafka broker取訊息的用戶端。
(3)Topic:可以理解爲一個佇列。
(4)ConsumerGroup(CG):這是kafka用來實現一個topic訊息的廣播(發給所有的consumer)和單播(發給任意一個consumer)的手段。一個topic可以有多個CG。topic 的訊息會複製(不是真的複製,是概念上的)到所有的CG,但每個partition只會把訊息發給該CG中的一個consumer。如果需要實現廣播,只要每個consumer有一個獨立的CG就可以了。要實現單播只要所有的consumer在同一個CG。用CG還可以將consumer進行自由的分組而不需要多次發送訊息到不同的topic。
(5)Broker:一臺kafka伺服器就是一個broker。一個叢集由多個broker組成。一個broker可以容納多個topic。
(6)Partition:爲了實現擴充套件性,一個非常大的topic可以分佈到多個broker(即伺服器)上,一個topic可以分爲多個partition,每個partition是一個有序的佇列。partition中的每條訊息都會被分配一個有序的id(offset)。kafka只保證按一個partition中的順序將訊息發給consumer,不保證一個topic的整體(多個partition 間)的順序。
(7)Offset: kafka的儲存檔案都是按照offset.kafka來命名,用offset做名字的好處是方便查詢。例如你想找位於2049的位置,只要找到2048.kafka的檔案即可。當然the first offset就是00000000000.kafka
Kafka生產過程分析:
(1)寫入方式: producer採用推(push)模式將訊息發佈到broker,每條訊息都被追加 (append)到分割區(partition)中,屬於順序寫磁碟(順序寫磁碟效率比隨機寫記憶體要高,保障kafka吞吐率)。
(2)分割區(Partition):訊息發送時都被髮送到一個topic,其本質就是一個目錄,而 topic是由一些 Partition Logs(分割區日誌)組成, 其組織結構如下圖所示:
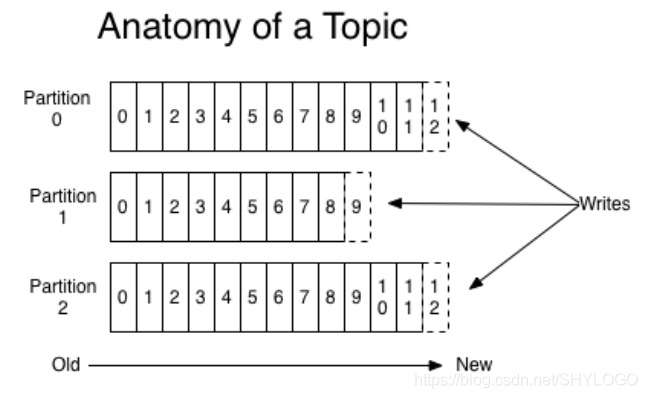
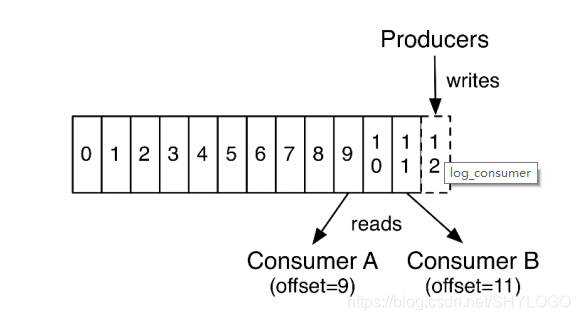
每個Partition中的訊息都是有序的,生產的訊息被不斷追加到Partition log上,其中的每一個訊息都被賦予了一個唯一的offset值。
(3)分割區的原因:
a、方便在叢集中擴充套件,每個Partition可以通過調整以適應它所在的機器,而一個topic又可以有多個Partition組成,因此整個叢集就可以適應任意大小的數據了。
b、可以提高併發,因爲可以以Partition爲單位讀寫了。
(4)分割區的原則:
a、指定了partition,則直接使用。
- 未指定partition但指定key,通過對key的value進行hash出一個partition。
- partition和key都未指定,使用輪詢選出一個partition。
(5)副本(Replication):
同一個partition可能會有多個replication(對應server.properties設定中的default.replication.factor=N)。沒有replication的情況下,一旦broker宕機,其上所有patition的數據都不可被消費,同時producer 也不能再將數據存於其上的 patition。引入replication之後,同一個partition可能會有多個replication,而這時需要在這些replication之間選出一個leader,producer和consumer只與這個leader 互動,其它replication作爲follower從leader中複製數據。
(6)寫入流程:
producer寫入訊息流程如下:
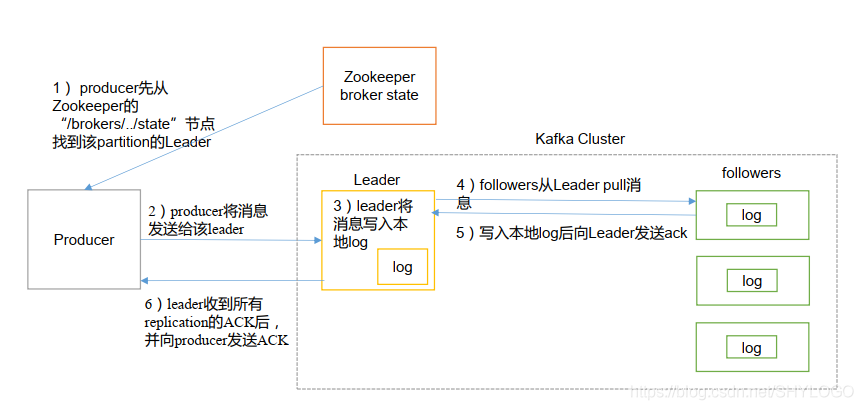
a、producer先從zookeeper的"/brokers/.../state"節點找到該partition的leader。
b、producer將訊息發送給該leader。
c、leader將訊息寫入本地log。
d、followers從leader pull訊息,寫入本地log後向leader發送ACK。
e、leader收到所有ISR中的replication的ACK後,增加HW(high watermark,最後commit的offset)並向producer發送ACK。
(7)Broker儲存訊息
a、儲存方式
物理上把topic分成一個或多個partition(對應server.properties中的 num.partitions=3設定),每個partition物理上對應一個資料夾(該資料夾儲存該 partition 的所有訊息和索引檔案)。
b、儲存策略
無論訊息是否被消費,kafka都會保留所有訊息。有兩種策略可以刪除舊數據基於時間: log.retention.hours=168
基於大小: log.retention.bytes=1073741824
需要注意的是,因爲kafka讀取特定訊息的時間複雜度爲O(1),即與檔案大小無關,所以刪除過期檔案與提高kafka效能無關。
Kafka生產過程分析:
kafka提供了兩套consumer API:高階Consumer API和低階Consumer API。
(1)高階API
優點:
高階API寫起來簡單。
不需要自行去管理offset,系統通過zookeeper自行管理。
不需要管理分割區,副本等情況,系統自動管理。
消費者斷線會自動根據上一次記錄在zookeeper中的offset去接着獲取數據(預設設定1分鐘更新一下zookeeper中存的offset)可以使用group來區分對同一個topic的不同程式存取分離開來(不同的group記錄不同的offset,這樣不同程式讀取同一個topic纔不會因爲offset互相影響)。
缺點:
不能自行控制offset(對於某些特殊需求來說)。
不能細化控制如分割區、副本、zk 等。
(2)低階API
優點:
能夠讓開發者自己控制offset,想從哪裏讀取就從哪裏讀取。
自行控制連線分割區,對分割區自定義進行負載均衡。
對zookeeper的依賴性降低(如:offset 不一定非要靠zk儲存,自行儲存 offset即可,比如存在檔案或者記憶體中)。
缺點:
太過複雜,需要自行控制offset,連線哪個分割區,找到分割區leader 等。
(3)消費者組
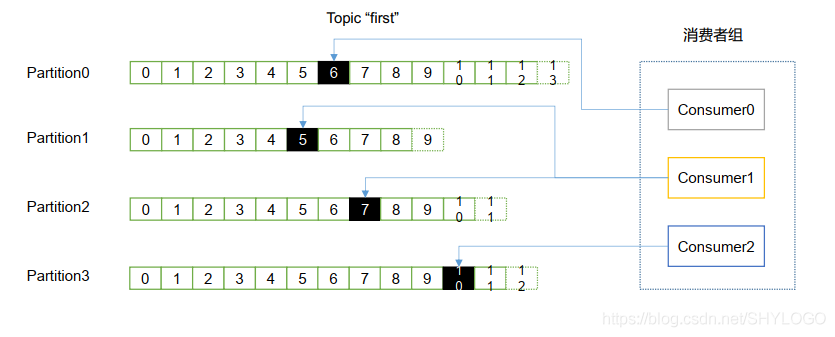
消費者是以consumer group 消費者組的方式工作,由一個或者多個消費者組成一個組,共同消費一個topic。每個分割區在同一時間只能由group中的一個消費者讀取,但是多個group可以同時消費這個partition。在圖中,有一個由三個消費者組成的group,有一個消費者讀取主題中的兩個分割區,另外兩個分別讀取一個分割區。某個消費者讀取某個分割區,也可以叫做某個消費者是某個分割區的擁有者。
在這種情況下,消費者可以通過水平擴充套件的方式同時讀取大量的訊息。另外,如果一個消費者失敗了,那麼其他的group 成員會自動負載均衡讀取之前失敗的消費者讀取的分割區。
(4)消費方式
consumer採用pull(拉)模式從broker中讀取數據。push(推)模式很難適應消費速率不同的消費者,因爲訊息發送速率是由broker決定的。它的目標是儘可能以最快速度傳遞訊息,但是這樣很容易造成consumer來不及處理訊息,典型的表現就是拒絕服務以及網路擁塞。而pull模式則可以根據consumer的消費能力以適當的速率消費訊息。對於kafka而言,pull模式更合適,它可簡化broker的設計,consumer可自主控制消費訊息的速率,同時consumer可以自己控制消費方式—即可批次消費也可逐條消費,同時還能選擇不同的提交方式從而實現不同的傳輸語意。pull模式不足之處是,如果kafka沒有數據,消費者可能會陷入回圈中,一直等待數據到達。爲了避免這種情況,可以在拉請求中有參數,允許消費者請求在等待數據到達的「長輪詢」中進行阻塞(並且可選地等待到給定的位元組數,以確保大的傳輸大小)。