深入理解MySQL鎖、事務隔離級別與MVCC原理
深入理解MySQL鎖、事務隔離級別與MVCC原理
1 鎖定義
鎖是計算機協調多個進程或執行緒併發存取某一資源的機制 機製。
在數據庫中,除了傳統的計算資源(如CPU、RAM、I/O等)的爭用以外,數據也是一種供需要使用者共用的資源。如何保證數據併發存取的一致性、有效性是所有數據庫必須解決的一個問題,鎖衝突也是影響數據庫併發存取效能的一個重要因素。
2 鎖分類
Mysql鎖簡單介紹:Mysql中不同的儲存引擎支援不同的鎖機制 機製。比如MyISAM和MEMORY儲存引擎採用的表級鎖,BDB採用的是頁面鎖,也支援表級鎖,InnoDB儲存引擎既支援行級鎖,也支援表級鎖,預設情況下採用行級鎖。
- 從效能上分爲樂觀鎖(用版本對比來實現)和悲觀鎖
樂觀鎖
-- 1.獲取數據
select * from order where id = 233;
-- 2.修改數據時使用樂觀鎖
update order set status = 2 and version=version+1 where id = 233 and version = {version}
悲觀鎖
-- 0.開始事務
begin;/begin work;/start transaction; (三者選一就可以)
-- 1.查詢出商品資訊
select status from order where id=233 for update; #增加樂觀鎖
-- 2.根據商品資訊生成訂單
insert into order (id,goods_id) values (null,1);
-- 3.修改商品status爲2
update table set status=2 where id=1;
-- 4.提交事務(任選一種釋放鎖)
commit;/commit work;
- 實現悲觀鎖利用select … for update加鎖, 操作完成後使用commit來釋放鎖
- innodb引擎時, 預設行級鎖, 當有明確欄位時會鎖一行, 如無查詢條件或條件欄位不明確時, 會鎖整個表. 條件爲範圍時會鎖整個表
- 查不到數據時, 則不會鎖表
- 從對數據庫操作的型別劃分,分爲讀鎖和寫鎖(都屬於悲觀鎖)
- 讀鎖(共用鎖):針對同一份數據,多個讀操作可以同時進行而不會互相影響
- 寫鎖(排它鎖):當前寫操作沒有完成前,它會阻斷其他寫鎖和讀鎖
- 從對數據操作的粒度分,分爲表鎖和行鎖
2.1 表鎖
每次操作鎖住整張表。開銷小,加鎖快;不會出現死鎖;鎖定粒度大,發生鎖衝突的概率最高,併發度最低;
2.1.1 基本操作
--建表
CREATE TABLE `mylock` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR (20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = MyISAM DEFAULT CHARSET = utf8;
-- 插入數據
INSERT INTO`test_db`.`mylock` (`id`, `NAME`) VALUES ('1', 'a');
INSERT INTO`test_db`.`mylock` (`id`, `NAME`) VALUES ('2', 'b');
INSERT INTO`test_db`.`mylock` (`id`, `NAME`) VALUES ('3', 'c');
INSERT INTO`test_db`.`mylock` (`id`, `NAME`) VALUES ('4', 'd');
- 手動增加表鎖
lock table 表名稱 read(write),表名稱2 read(write);
- 檢視錶上是否加鎖
show open tables;
- 刪除鎖
2.1.2 案例分析(加讀鎖)
lock table mylock read;
當前session和其他session都可以讀該表 ,以及增加讀鎖
當前session中插入或者更新鎖定的表都會報錯,其他session插入或更新則會等待
2.1.3 案例分析(加寫鎖)
lock table mylock write;
當前session對該表的增刪改查都沒有問題,其他session對該表的所有操作被阻塞
2.1.4 案例結論
第一步:session1 給mylock表增加讀鎖。
lock table mylock read;
第二步:session1 查詢 mylock 表。(可以查詢)
mysql> select * from mylock;
+----+------+
| id | NAME |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+----+------+
4 rows in set (0.00 sec)
第三步:session2 查詢 mylock 表。(可以查詢)
mysql> select * from mylock;
+----+------+
| id | NAME |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+----+------+
4 rows in set (0.00 sec)
第四步:session2 給mylock表增加讀鎖。(成功)
mysql> lock table mylock read;
Query OK, 0 rows affected (0.00 sec)
第五步:session2 查詢 mylock 表。(可以查詢)
mysql> select * from mylock;
+----+------+
| id | NAME |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+----+------+
4 rows in set (0.00 sec)
第六步:session1 修改id = 4的數據。(不能修改)
mysql> update mylock set NAME = 'd1' where id = 4;
ERROR 1099 (HY000): Table 'mylock' was locked with a READ lock and can't be updated
第七步:session2 修改id = 4第數據。(不能修改)
mysql> update mylock set NAME = 'd1' where id = 4;
ERROR 1099 (HY000): Table 'mylock' was locked with a READ lock and can't be updated
第八步:session2 給mylock增加寫鎖。(不能新增)
被阻塞了。
第九步:session2 新增一條記錄。
mysql> INSERT INTO`test_db`.`mylock` (`id`, `NAME`) VALUES ('5', 'e');
Query OK, 1 row affected (0.00 sec)
第十步:session1 查詢數據mylock表。
被阻塞了
再試試新增呢?
依然被阻塞了。
MyISAM在執行查詢語句(SELECT)前,會自動給涉及的所有表加讀鎖,在執行增刪改操作前,會自動給涉及的表加寫鎖。
- 對MyISAM表的讀操作(加讀鎖) ,不會阻寒其他進程對同一表的讀請求,但會阻賽對同一表的寫請求。只有當讀鎖釋放後,纔會執行其它進程的寫操作。
- 對MylSAM表的寫操作(加寫鎖) ,會阻塞其他進程對同一表的讀和寫操作,只有當寫鎖釋放後,纔會執行其它進程的讀寫操作
總結:
簡而言之,就是讀鎖會阻塞寫,但是不會阻塞讀。而寫鎖則會把讀和寫都阻塞。
2.2 行鎖
每次操作鎖住一行數據。開銷大,加鎖慢;會出現死鎖;鎖定粒度最小,發生鎖衝突的概率最低,併發度最高。
InnoDB與MYISAM的最大不同有兩點:
2.2.1 行鎖支援事務
- 事務(Transaction)及其ACID屬性
事務是由一組SQL語句組成的邏輯處理單元,事務具有以下4個屬性,通常簡稱爲事務的ACID屬性。
原子性(Atomicity) :事務是一個原子操作單元,其對數據的修改,要麼全都執行,要麼全都不執行。
一致性(Consistent) :在事務開始和完成時,數據都必須保持一致狀態。這意味着所有相關的數據規則都必須應用於事務的修改,以保持數據的完整性;事務結束時,所有的內部數據結構(如B樹索引或雙向鏈表)也都必須是正確的。
隔離性(Isolation) :數據庫系統提供一定的隔離機制 機製,保證事務在不受外部併發操作影響的「獨立」環境執行。這意味着事務處理過程中的中間狀態對外部是不可見的,反之亦然。
永續性(Durable) :事務完成之後,它對於數據的修改是永久性的,即使出現系統故障也能夠保持。
- 併發事務處理帶來的問題
- 更新丟失(Lost Update)
當兩個或多個事務選擇同一行,然後基於最初選定的值更新該行時,由於每個事務都不知道其他事務的存在,就會發生丟失更新問題–最後的更新覆蓋了由其他事務所做的更新。
- 髒讀(Dirty Reads)
一個事務正在對一條記錄做修改,在這個事務完成並提交前,這條記錄的數據就處於不一致的狀態;這時,另一個事務也來讀取同一條記錄,如果不加控制,第二個事務讀取了這些「髒」數據,並據此作進一步的處理,就會產生未提交的數據依賴關係。這種現象被形象的叫做「髒讀」。
一句話:事務A讀取到了事務B已經修改但尚未提交的數據,還在這個數據基礎上做了操作。此時,如果B事務回滾,A讀取的數據無效,不符合一致性要求。
- 不可重讀(Non-Repeatable Reads)
一個事務在讀取某些數據後的某個時間,再次讀取以前讀過的數據,卻發現其讀出的數據已經發生了改變、或某些記錄已經被刪除了!這種現象就叫做「不可重複讀」。
一句話:事務A讀取到了事務B已經提交的修改數據,不符合隔離性
- 幻讀(Phantom Reads)
一個事務按相同的查詢條件重新讀取以前檢索過的數據,卻發現其他事務插入了滿足其查詢條件的新數據,這種現象就稱爲「幻讀」。
一句話:事務A讀取到了事務B提交的新增數據,不符合隔離性。
- 事務隔離級別
髒讀」、「不可重複讀」和「幻讀」,其實都是數據庫讀一致性問題,必須由數據庫提供一定的事務隔離機制 機製來解決。
| 隔離級別 | 髒讀(DirtyRead) | 不可重複讀(NonRepeatable Read) | 幻讀(Phantom Read) |
|---|---|---|---|
| 讀未提交(Read uncommitted) | 可能 | 可能 | 可能 |
| 讀已提交(Read committed) | 不可能 | 可能 | 可能 |
| 可重複讀(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可序列化(Serializable) | 不可能 | 不可能 | 不可能 |
數據庫的事務隔離越嚴格,併發副作用越小,但付出的代價也就越大,因爲事務隔離實質上就是使事務在一定程度上「序列化」進行,這顯然與「併發」是矛盾的。
同時,不同的應用對讀一致性和事務隔離程度的要求也是不同的,比如許多應用對「不可重複讀"和「幻讀」並不敏感,可能更關心數據併發存取的能力。
常看當前數據庫的事務隔離級別: show variables like ‘tx_isolation’;
設定事務隔離級別:set tx_isolation=‘REPEATABLE-READ’;
2.2.2 行鎖與隔離級別案例分析
--建立表
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `test_db`.`account` (`name`, `balance`) VALUES ('lilei', '450');
INSERT INTO `test_db`.`account` (`name`, `balance`) VALUES ('hanmei','16000');
INSERT INTO `test_db`.`account` (`name`, `balance`) VALUES ('lucy', '2400');
1、行鎖演示
一個session開啓事務更新不提交,另一個session更新同一條記錄會阻塞,更新不同記錄不會阻塞。
行鎖也分爲讀鎖和寫鎖。更新數據的時候,是寫鎖,但是如果select 語句是可以指定讀鎖或者寫鎖的。mysql InnoDb引擎中update,delete,insert語句自動加排他鎖的問題。
-- 讀鎖(共用鎖)
begin;
select * from account where id = 1 LOCK IN SHARE MODE;
-- 寫鎖(排它鎖)
begin;
select * from account where id = 1 for update
2、讀未提交
- 開啓一個用戶端A,並設定當前事務模式爲read uncommitted(未提交 讀),查詢表account的初始值:
set tx_isolation=‘read-uncommitted’ – 設定隔離級別爲讀未提交。
用戶端A:
mysql> set tx_isolation='read-uncommitted';
Query OK, 0 rows affected (0.02 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 450 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.02 sec)
- 在用戶端A事務提交之前,開啓用戶端B,更新表account:
用戶端B:
mysql> set tx_isolation='read-uncommitted';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set balance = balance - 40 where id = 1;
Query OK, 1 row affected (0.05 sec)
Rows matched: 1 Changed: 1 Warnings: 0
- 這時,雖然用戶端B的事務還沒有提交,但是用戶端A就可以查詢用戶端B更新的新數據。
用戶端A:
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 410 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 一旦用戶端B的事務由於某些原因回滾了,所有的操作撤銷了,那麼用戶端查詢到的數據其實就是髒數據。
用戶端B:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 450 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 在用戶端A執行更新語句update account set balance = balance - 50 where id =1,lilei的balance沒 有變成360,居然是400,是不是很奇怪,數據不一致啊,如果你這麼想就太天真了,在應用程式中,我們會 用400-50=350,並不知道其他對談回滾了,要想解決這個問題可以採用讀已提交的隔離級別 。
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 410 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
mysql> update account set balance = balance - 50 where id = 1;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from account where id = 1 ;
+----+-------+---------+
| id | name | balance |
+----+-------+---------+
| 1 | lilei | 400 |
+----+-------+---------+
1 row in set (0.00 sec)
3、讀已提交
- 開啓一個用戶端A,並設定當前事務模式爲read-committed(已提交 讀),查詢表account的所有記錄:
用戶端A:
mysql> set tx_isolation='read-committed';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 450 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 在用戶端A事務提交之前,開啓用戶端B,更新表account:
用戶端B:
mysql> set tx_isolation='read-committed';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set balance = balance - 50 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
- 這時,用戶端B的事務還沒有提交,用戶端A無法查詢到用戶端B更新的新數據,解決了髒讀的問題。
用戶端A:
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 450 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 用戶端B提交事務:
用戶端B:
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
- 用戶端A再次查詢數據,發現數據發生了改變,即產生了不可重複讀的問題。
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 450 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
4、可重複讀
- 開啓一個用戶端A,並設定當前事務模式爲repeatable read,查詢表account的所有記錄:set tx_isolation=‘repeatable-read’
用戶端A:
mysql> set tx_isolation='repeatable-read';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 在用戶端A的事務提交之前,開啓用戶端B,更新account記錄並提交。
用戶端B:
mysql> set tx_isolation='repeatable-read';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set balance = balance + 50 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
- 在用戶端A查詢表account所有記錄,與步驟1一致,解決了不可重複讀的問題。
用戶端A:
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 在用戶端A中,執行一個update account set balance = balance-50 where id = 1;balance並沒有變成 400-50 = 350,lilei的balance值用的是步驟2的中的450 的值算的,所以應該是400,數據的一致性沒有被破壞,可重複讀隔離級別下使用了MVCC(multi-version concurrency control)機制 機製,select操作不會更新版本號,查詢到的是快找,但是insert、update、delete等操作則會更新版本號。是讀的當前版本。
用戶端A:
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.01 sec)
mysql> update account set balance = balance-50 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 重新開啓B用戶端,插入一條數據,提交事務。
用戶端B:
mysql> set tx_isolation='repeatable-read';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO `test_db`.`account` (`name`, `balance`) VALUES ('luxian', '2500');
Query OK, 1 row affected (0.01 sec)
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
| 4 | luxian | 2500 |
+----+--------+---------+
4 rows in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
- 在用戶端A查詢表account的所有記錄,沒有查出新增,沒有出現幻讀。
用戶端A:
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+----+--------+---------+
3 rows in set (0.00 sec)
- 驗證幻讀:在用戶端A中執行update account set balance=888 where id = 4; 發現能更新成功,再次查詢數據。能夠查詢到用戶端B新增的數據。
用戶端A:
mysql> update account set balance=888 where id = 4;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
| 4 | luxian | 888 |
+----+--------+---------+
4 rows in set (0.00 sec)
5、可序列化
- 開啓一個用戶端A,並設定當前事務模式爲serializable,查詢表account的初始值:
set tx_isolation='serializable';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+‐‐‐‐‐‐+‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐+
| id | name | balance |
+‐‐‐‐‐‐+‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐+
| 1 | lilei | 10000 |
| 2 | hanmei | 10000 |
| 3 | lucy | 10000 |
| 4 | lily | 10000 |
+‐‐‐‐‐‐+‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐+
4 rows in set (0.00 sec)
- 開啓一個用戶端B,並設定當前事務模式爲serializable,插入一條記錄報錯,表被鎖了插入失敗,mysql中事務隔離級別爲serializable時會鎖表,因此不會出現幻讀的情況,這種隔離級別併發性極低,開發中很少會用到。
mysql> set session transaction isolation level serializable;
Query OK, 0 rows affected (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values(5,'tom',0);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
間隙鎖(Gap Lock)
間隙鎖,鎖的就是兩個值之間的空隙。Mysql預設級別是repeatable-read,有辦法解決幻讀問題嗎?間隙鎖 在某些情況下可以解決幻讀問題。
假設account表裏數據如下:
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
| 4 | luxian | 888 |
| 10 | 666 | 2400 |
| 15 | 777 | 2400 |
| 20 | 888 | 2400 |
+----+--------+---------+
7 rows in set (0.00 sec)
間隙就有id爲(4,10),(10,15),(15,20),(20,+∞) 這四個區間,我們在用戶端A中 使用select * from account where id >8 and id <12 for update;則其他的session沒法在這個範圍所包含的所有行記錄(包括間隙行記錄)以及行記錄所在的間隙裡插入或修改任何數據,即id在 (3,20]區間都無法修改數據,注意最後那個20也是包含在內的。
間隙鎖是在可重複讀隔離級別下纔會生效。
id < 8 and id > 12 他是佔用了兩個區間(4,10),(10,15) ,那麼這兩個區間內的所有的ID ,都會被鎖住。
Mysql預設級別是repeatable-read,有辦法解決幻讀問題嗎?間隙鎖在某些情況下可以解決幻讀問題
要避免幻讀可以用間隙鎖在Session_1下面 下麪執行update account set name =‘zhangsan’ where id > 10 and id <=20;,則其他Session沒法在這個範圍所包含的間隙裡插入或修改任何數據
臨鍵鎖(Next-key Lock)
Next-Key Locks是行鎖與間隙鎖的組合。像上面那個例子裡的這個(4,15]的整個區間可以叫做臨鍵鎖。
無索引行鎖會升級爲表鎖:鎖主要是加在索引上,如果對非索引欄位更新, 行鎖可能會變表鎖
session1執行:
update account set balance = 800 where name = ‘lilei’;
session2對該表任一行操作都會阻塞住
InnoDB的行鎖是針對索引加的鎖,不是針對記錄加的鎖。並且該索引不能失效,否則都會從行鎖升級爲表鎖。
鎖定某一行還可以用lock in share mode(共用鎖) 和for update(排它鎖),例如:select * from test_innodb_lock where a = 2 for update;
這樣其他session只能讀這行數據,修改則會被阻塞,直到鎖定行的session提交
2.2.3 案例總結
Innodb儲存引擎由於實現了行級鎖定,雖然在鎖定機制 機製的實現方面所帶來的效能損耗可能比表級鎖定會要更高一下,但是在整體併發處理能力方面要遠遠優於MYISAM的表級鎖定的。當系統併發量高的時候,Innodb的整體效能和MYISAM相比就會有比較明顯的優勢了。
但是,Innodb的行級鎖定同樣也有其脆弱的一面,當我們使用不當的時候,可能會讓Innodb的整體效能表現不僅不能比MYISAM高,甚至可能會更差。
2.2.4 行鎖分析
通過檢查InnoDB_row_lock狀態變數來分析系統上的行鎖的爭奪情況
show status like’innodb_row_lock%’;
對各個狀態量的說明如下:
Innodb_row_lock_current_waits: 當前正在等待鎖定的數量
Innodb_row_lock_time: 從系統啓動到現在鎖定總時間長度
Innodb_row_lock_time_avg: 每次等待所花平均時間
Innodb_row_lock_time_max:從系統啓動到現在等待最長的一次所花時間
Innodb_row_lock_waits:系統啓動後到現在總共等待的次數
對於這5個狀態變數,比較重要的主要是:
Innodb_row_lock_time_avg (等待平均時長)
Innodb_row_lock_waits (等待總次數)
Innodb_row_lock_time(等待總時長)
尤其是當等待次數很高,而且每次等待時長也不小的時候,我們就需要分析系統
中爲什麼會有如此多的等待,然後根據分析結果着手製定優化計劃。
2.2.5 死鎖
set tx_isolation=‘repeatable-read’;
Session_1執行:select * from account where id=1 for update;
Session_2執行:select * from account where id=2 for update;
Session_1執行:select * from account where id=2 for update;
Session_2執行:select * from account where id=1 for update;
檢視近期死鎖日誌資訊:show engine innodb status\G;
大多數情況mysql可以自動檢測死鎖並回滾產生死鎖的那個事務,但是有些情況
mysql沒法自動檢測死鎖
2.2.6 優化建議
- 儘可能讓所有數據檢索都通過索引來完成,避免無索引行鎖升級爲表鎖
- 合理設計索引,儘量縮小鎖的範圍
- 儘可能減少檢索條件範圍,避免間隙鎖
- 儘量控制事務大小,減少鎖定資源量和時間長度,涉及事務加鎖的sql儘量放在事務最後執行
- 儘可能低級別事務隔離
3 MVCC模式
Mysql在可重複讀隔離級別下如何保證事務較高的隔離性,我們上節課給大家演示過,同樣的sql查詢語句在一個事務 裡多次執行查詢結果相同,就算其它事務對數據有修改也不會影響當前事務sql語句的查詢結果。 這個隔離性就是靠**MVCC(Multi-Version Concurrency Control)**機制 機製來保證的,對一行數據的讀和寫兩個操作預設 是不會通過加鎖互斥來保證隔離性,避免了頻繁加鎖互斥,而在序列化隔離級別爲了保證較高的隔離性是通過將所有操 作加鎖互斥來實現的。
Mysql在讀已提交和可重複讀隔離級別下都實現了MVCC機制 機製。
3.1 undo日誌版本鏈與read view 機制 機製詳解
3.1.1 undo日誌版本鏈
undo日誌版本鏈是指一行數據被多個事務依次修改過後,在每個事務修改完後,Mysql會保留修改前的數據undo回滾 日誌,並且用兩個隱藏欄位trx_id和roll_pointer把這些undo日誌串聯起來形成一個歷史記錄版本鏈(見下圖,需參考視 頻裡的例子理解)
例圖:
read-view: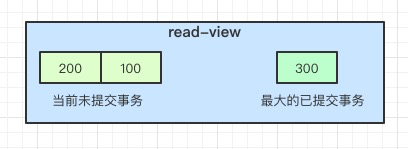
3.1.2 read view 機制 機製詳解
在可重複讀隔離級別,當事務開啓,執行任何查詢sql時會生成當前事務的一致性檢視read-view,該檢視在事務結束 之前都不會變化(如果是讀已提交隔離級別在每次執行查詢sql時都會重新生成),這個檢視由執行查詢時所有未提交事 務id陣列(數組裏最小的id爲min_id)和已建立的最大事務id(max_id)組成,事務裡的任何sql查詢結果需要從對應 版本鏈裡的最新數據開始逐條跟read-view做比對從而得到最終的快照結果。
版本鏈對比規則:
- 如果 row 的 trx_id 落在橙色部分( trx_id<min_id ),表示這個版本是已提交的事務生成的,這個數據是可見的;
- 如果 row 的 trx_id 落在綠色部分( trx_id>max_id ),表示這個版本是由將來啓動的事務生成的,是不可見的(若 row 的 trx_id 就是當前自己的事務是可見的);
- 如果 row 的 trx_id 落在黃色部分(min_id <=trx_id<= max_id),那就包括兩種情況:
- 若 row 的 trx_id 在檢視陣列中,表示這個版本是由還沒提交的事務生成的,不可見,若 row 的 trx_id 就是當前 自己的事務是可見的;
- 若 row 的 trx_id 不在檢視陣列中,表示這個版本是已經提交了的事務生成的,可見。
對於刪除的情況可以認爲是update的特殊情況,會將版本鏈上最新的數據複製一份,然後將trx_id修改成刪除操作的 trx_id,同時在該條記錄的頭資訊(record header)裡的(deleted_flag)標記位寫上true,來表示當前記錄已經被 刪除,在查詢時按照上面的規則查到對應的記錄如果delete_flag標記位爲true,意味着記錄已被刪除,則不返回數據。
注意:begin/start transaction 命令並不是一個事務的起點,在執行到它們之後的第一個修改操作InnoDB表的語句, 事務才真正啓動,纔會向mysql申請事務id,mysql內部是嚴格按照事務的啓動順序來分配事務id的。
總結:MVCC機制 機製的實現就是通過read-view機制 機製與undo版本鏈比對機制 機製,使得不同的事務會根據數據版本鏈對比規則讀取 同一條數據在版本鏈上的不同版本數據。