知識圖譜學習(二):電商知識圖譜
知識圖譜學習(二):電商知識圖譜
——本文摘自機械工業出版社華章圖書《阿裡巴巴B2B電商演算法實戰》,參考文獻請參見原書。
目錄
前言
網際網路創業潮
網際網路是20世紀最偉大的技術發明之一。 在20世紀60年代至80年代,各種網際網路核心技術突飛猛進。從20世紀90年代開始,基於網際網路的商業創新層出不窮,伴隨技術變革而產生的創新商業模式已經完全改變了人們的衣、食、住、行、社交、消費等生活方式,在技術的驅動下,商業在不斷爲人們創造美好的生活。中國網際網路的商業化始於1994年,20世紀90年代最後5年建立的網際網路公司奠定了後續20年中國網際網路的商業格局,其中不乏成長爲商業巨頭的公司,如阿裡巴巴和騰訊。網際網路商業化在中國演進的近30年曆史中,經歷了3次大的浪潮。
第一次浪潮:PC網際網路(1995-2000)
20世紀90年代最後的5年,以網易、搜狐、新浪爲代表的入口網站紛紛成立,並在後續5年改變了人們獲取資訊的方式。同時,阿裡巴巴(電商)、騰訊(社交)、百度(搜尋)、攜程(出行) 也先後 先後於這段時期創立。延續第一次浪潮的餘波,2005年,Web 2.0開始在中國綻放,天涯社羣、人人網、QQ空間等與傳統入口網站不同的新的內容生產和消費形式陸續出現,網友從資訊接收者和消費者變爲戶網站不同的新的內容生產和消費形式陸續出現,網友從資訊接收者和消費者變爲內容生產者,爲後續自媒體和移動化社交的進一步發展埋下伏筆。
第二次浪潮:行動網際網路(2009-2015)
隨着4G網路和智慧手機的普及,2012年手機網友數量達到4.2億,超過PC網友數量。行動網際網路的爆發,激發了新的商業模式和生活方式,成就了手機淘寶、微信等超級App。延續行動網際網路浪潮,移動出行、共用單車、團購、外賣又引爆了一波創業浪潮,滴滴與快的、摩拜與ofo、美團與大衆點評,商戰交鋒,跌宕起伏。
第三次浪潮:產業網際網路(2015年至今)
2015年,「網際網路+」的概念首次被提出,產業網際網路已逐漸成爲行業聚焦點,行動網際網路、雲端計算、大數據與工業製作結合,促進了現代製造企業的轉型升級。消費網際網路以線上個性化的方式將商品推播給消費者;產業網際網路則從更上遊切入,聚焦基於下遊需求洞察的柔性生產製造供應鏈升級。其中,典型的案例是電商界的「黑馬」拼多多。拼多多聚焦下沉市場,撼動了整個電商格局。拼多多當下正致力於C2M轉型和品牌升級,推出了"新品牌」計劃。當然,阿裡巴巴和京東作爲電商行業的領跑者也不會靜觀其變,分別推出了"廠銷通」和"廠直優品」計劃。優質供給產業鏈的競爭又必將是一場腥風血雨。
回顧近30年的網際網路創業潮,其內在驅動力都可以歸因於科技進步。從技術角度看,網際網路的變遷可分爲以下階段。
- 第一階段:門戶時代,核心技術是分類索引。
- 第二階段:搜尋時代,核心技術是搜尋引擎。
- 第三階段: SNS時代, 核心技術是關係圖譜。
- 第四階段:資訊時代,核心技術是推薦演算法。
電商生態
網際網路中最豐富的資源是流量,而流量變現最直接的方式是電商,所以放眼當前各個主流App,諸如今日頭條、快手、微信等,都在嘗試直播帶貨和社交分銷的運營模式。當然,以電商爲核心商業模式的平臺App,也都在以各種形式構建自己獨特的行銷玩法和商業壁壘。正如本書書名所表明的,本書內容強調阿裡巴巴B2B商業模式背後的演算法技術支撐力和驅動力。在正文開始之前,我們先簡要介紹主流的電商業態以及相應的核心演算法和技術能力,以便讀者迅速瞭解全貌。
平臺模式是當下主流電商形態,即便是以社交電商自居的拼多多也繞不開平臺模式,筆者認爲其背後的關鍵是基於平臺中心化流量的強抓手和強管控特性,設計商業化變現機制 機製,從而實現商業營收、資本回報。整體而言,打造有競爭力的平臺,核心切入點是實現供需兩端的匹配。在供給端,尋找優質供給商家和工廠,通過演算法技術提供商品數位化、線上化的工具,並且通過平臺流量分發機制 機製給予增量買家扶持。在需求端,洞察消費者需求,通過演算法技術提供搜尋和推薦觸達方式,提供更精準、優質的服務。對於匹配機制 機製,結合商家能力、商品特性、買家身份和行爲偏好,構建以點選率和轉化率爲變數因子的匹配模型。當然,深耕平臺價值,還需要關注外圍電商基礎設施的建設,包括商家和商品的品質認證體系、交易擔保體系、供應鏈履約體系等。以阿裡巴巴爲例,集團內部有「平臺品質」一級部門來把控整體品質風險。2004年, 支付寶的出現,簡化了交易流程; 2014年, 菜鳥物流的出現,標誌着完備的智慧物流體系已構建好。
電商業態主要分爲B2B (Business to Business)、B2C (Business to Customer)和C2C (Customer to Customer) 3種模式。
B2B平臺的參與方通常都是商家,平臺的核心價值是工具化賦能供需兩端,其商業化變現方法是收取會員費和增值服務費。典型代表公司是阿裡巴巴CBU事業部、慧聰網、敦煌網。
B2C平臺將商家生產的具有品牌價值的商品傳遞給消費者,平臺的核心價值體現爲降本提效,其商業變現方法是傭金提成。典型代表公司是京東和天貓,這兩家公司在整個B2C市場中的份額超過80%。
C2C平臺的絕對領導者是淘寶,2019年「雙十一」大促期間,整個淘寶系電商平臺的GMV (成交總額)達到了2684億元。除了在演算法技術層面對搜尋和推薦功能持續深度優化外,淘寶也在強化內容帶貨的價值,主流玩法包括淘寶直播和哇哦視訊。
除了上述3種典型模式,同時串聯起B2B、B2C、 C2C模式的C2M模式也逐漸成爲當下各主流電商平臺的爭奪點,平臺基於大數據智慧洞察和挖掘市場機會,並通過集單議價牽弓|供給,爲買家提供極具性價比的供給,爲工廠賣家提供貨品銷售的更多機會,同時也爲中小工廠開店、選品、行銷提供全方位的技術支援。
毫不誇張地說,阿裡巴巴的發家史就是中國電商的演進史,阿裡人始終直面「戰爭」,通過商戰贏得勝利,同時也助推經濟發展和產業升級。阿裡CBU和淘寶分別成爲當下B2B和C2C市場的第一梯隊領跑者, 它們近20年的核心技術發展歷程如下圖所示,並且兩者在2019年形成合力,互通供需兩個主賽道。

一、知識工程與專家系統
在1977年第五屆國際人工智慧會議上,美國斯坦福大學電腦科學家Edward A. Felgenbaum發表的文章 The art of artificial intelligence. 1. Themes and case studies of knowledge engineering,系統性地闡述了「專家系統」的思想,並且提出了「知識工程」的概念。他認爲:「知識工程利用了人工智慧的原理和方法,爲那些需要專家知識才能解決的應用難題提供求解的一般準則和工具。在1984年8月全國第五代計算機專家討論會上,史忠植教授提出:「知識工程是研究知識資訊處理的學科,提供開發智慧系統的技術,是人工智慧、數據庫技術、數理邏輯、認知科學、心理學等學科交叉發展的結果。」專家系統最成功的案例是DEC的專家設定系統XCON。1980年,XCON最初被用於DEC位於新罕布什爾州薩利姆的工廠,它擁有大約2500條規則。截至1986年,它一共處理了80 000條指令,準確率達到95%~98%。據估計,通過減少技師出錯時送給客戶的元件以加速組裝流程和增加客戶滿意度,它每年爲DEC節省2500萬美元。一個典型的專家系統如圖1所示,其特點主要包括:
- 在特定領域裏要具有和人一樣或者超出人的高品質解決困難問題的能力;
- 擁有大量、全面的關於特定領域的專業知識;
- 採用啓發的方法來指導推理過程,從而縮小解決方案的搜尋範圍;
- 能夠提供對自己的推理決策結果進行解釋的能力;
- 引入表示不同類型知識(如事實、概念和規則)的符號,專家系統在解決問題的時候用這些符號進行推理;
- 能夠提供諮詢建議、修改、更新、拓展能力,並能處理不確定和不相關的數據。
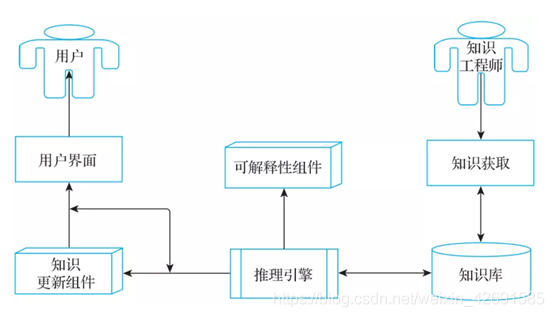
可以看到,專家系統大量依靠領域專家人工構建的知識庫。在數據量激增、資訊暴漲的當下,人工維護知識庫的方式在效率和覆蓋率上都難以達到令人滿意的水平。另外,推理規則的增加也增加了系統的複雜度,從而導致系統非常難以維護。
二、語意網絡與知識圖譜
1. 語意網絡
伴隨着Web技術的不斷髮展,人類先後 先後經歷了以網頁的鏈接爲主要特徵的Web 1.0時代到以數據的鏈接(Linked Data)爲主要特徵的Web 2.0時代,目前Web技術正逐步朝向Web之父Berners Lee在2001年提出的基於知識互聯的語意網絡(semantic Web),也就是Web 3.0時代邁進。在Web 2.0時代,網際網路發展迅猛,數據的規模呈爆發式增長,基於統計的機器學習方法佔據主流,並且在各個領域取得不錯的成果。例如搜尋引擎,搜尋的流程大致可拆分爲基於使用者查詢、召回、L2R這3個過程,一定程度提升了使用者獲取資訊的效率。但是這種服務模式仍然是把一系列資訊拋給使用者,使用者最終還是需要對數據進行篩選、甄別,才能 纔能拿到自己最需要的資訊。因此這種服務方式在效率、準確率上都有缺陷。語意網絡的目標是構建一個人與機器都可理解的萬維網,使得網路更加智慧化,在解析使用者查詢意圖的基礎上,提供更加精準和快速的服務。傳統的語意網絡要做到這一點,就需要把所有線上文件構成的數據都進行處理並存放在一起,形成一個巨大、可用的數據庫。這麼做需要強大的數據處理和Web內容智慧分析能力:首先就需要對這些Web數據進行語意標註,但是由於Web數據具有體量巨大、異質異構、領域範圍大等特點,所以如何自動給Web上的網頁內容新增合適的標籤成爲技術痛點之一。另外,面對已經標註過的Web數據,機器如何進行思考和推理也是亟待解決的問題。由於上述問題的存在,在語意網絡提出後的10年間,其沒有得到大規模應用,但是在對其研究的過程中,積累沉澱了成熟的本體模型建模和形式化知識表達方法,例如RDF(Resource Description Framework)和萬維網本體語言(Web Ontology Language,OWL),這爲後續知識圖譜的出現奠定了基礎。
2. 知識圖譜
① 知識圖譜概述
知識圖譜由Google公司於2012年5月16日第一次正式提出並應用於Google搜尋中的輔助知識庫。谷歌知識圖譜除了顯示其他網站的鏈接列表,還提供結構化及詳細的相關主題的資訊。其目標是提高搜尋引擎的能力,希望使用者能夠使用這項功能來解決他們遇到的查詢問題,從而提高搜尋品質和使用者體驗。知識圖譜是結構化的語意知識庫,用於以符號形式描述物理世界中的概念及其之間的關係。其基本組成單位是 「實體-關係-實體」三元組,以及實體及其相關屬性-值對,實體間通過關係相互連線,構成網狀的知識結構。隨着知識圖譜構建規模越來越大,複雜度越來越高,開始出現實體、類別、屬性、關係等多顆粒度、多層次的語意單元,這些關聯關係通過統一的知識模式(Schema)抽象層和知識範例(Instance)層共同作用構成更加複雜的知識系統。從定義中可以看到,知識圖譜是一個語意知識庫,具備足夠的領域知識,其最重要的組成成分是三元組。三元組通常可以表示爲G=<Eh,R,Et>,其中R表示知識圖譜中實體間所有關係的集合,例如關係「is_a」。一般情況下,關係都是帶方向且有明確語意的,反之則關係不能成立,例如「阿裡巴巴is_a公司」。也有一些關係是雙向的,例如「張三is_friend_of李四」,反之亦然。對於這種雙向關係,通常情況會對調實體位置,拆分爲2個三元組分別儲存。實體Eh、Et⊆E={e1,e2,…,e|E|}分別表示頭實體(Head Entity)、尾實體(Tail Entity),兩個實體共同用於表徵關係的方向。實體及其屬性可以用一種特殊的關係三元組表示,例如「has_a」。實體和屬性的界線比較模糊,一般從業務角度出發,在設計Schema的時候,如果認爲某類屬性具有一類概唸的共性,同時在後面的推理(例如路徑遊走時新關係發現)中能夠發揮作用,就可以把它作爲實體對待。還有一類屬性,比如年齡、身高,這類單純描述實體特徵的最細粒度屬性,則一般被設計爲屬性。
② 常見開放知識圖譜
WordNet是由普林斯頓大學認知科學實驗室於1985年構建的一個英文電子詞典和本體知識庫,採用人工標註的方法構建。WordNet主要定義了名詞、形容詞、動詞和副詞之間的語意關係,包括同義關係、反義關係、上下位關係、整體部分關係、蘊含關係、因果關係、近似關係等。比如,其中的名詞之間的上下位關係,「水果」是「蘋果」的上位詞。Freebase是由創業公司MetaWeb於2005年啓動的一個以開放、共用、協同的方式構建的大規模鏈接數據庫語意網絡專案,2010年被谷歌收購併成爲谷歌知識圖譜中的重要組成部分。Freebase主要數據源有Wikipedia、世界名人數據庫(NNDB)、開放音樂數據庫(Music-Brainz)以及社羣使用者的貢獻。它主要通過三元組構造知識,並採用圖數據儲存,有5800多萬個實體和30多億個實體間關係三元組。2016年正式關閉,數據和API服務都遷移至Wikidata。Yago是由德國馬普研究所研發的鏈接知識庫,主要整合了Wikipedia、WordNet和GeoNames這3個數據庫中的數據。Yago將WordNet的詞彙定義與Wikipedia的分類體系進行融合,從而使得Yago相對於DBpedia有更加豐富的實體分類體系,同時Yago還考慮了時間和空間知識,爲知識條目增加了時間和空間維度屬性描述。目前Yago已經包含1.2億條三元組知識,是IBM Watson的後端知識庫之一。OpenKG是一個面向中文領域的開放知識圖譜社羣專案,主要目的是促進中文領域知識圖譜數據的開放與互聯。OpenKG上已經收錄了大量開放中文知識圖譜數據、工具及文獻。目前開放的知識圖譜數據包括百科類的zhishi.me(狗尾草科技、東南大學)、CN-DBpedia(復旦大學)、XLore(清華大學) 等。當然,還有一些垂直領域知識圖譜,這類知識圖譜不像上述通用領域知識圖譜那樣所涉內容廣而全。垂直領域知識圖譜主要面向特定領域的特定知識、應用場景進行構建,比如醫療領域的Linked Life Data、電商領域的阿裡巴巴商品知識圖譜和場景導購知識圖譜。
三、知識圖譜構建
知識圖譜構建是一個系統工程,涵蓋多種資訊處理技術,用於滿足圖譜構建過程中的各種需要。典型的圖譜構建流程主要包括:知識抽取、知識推理和知識儲存。知識表示貫穿於整個知識圖譜構建和應用的過程,在不同階段知識表示具有不同的體現形式,例如在圖譜構建階段,知識表示主要用於描述知識圖譜結構,指導和展示知識抽取、知識推理過程;在應用階段,知識表示則主要考慮上層應用期望知識圖譜提供什麼型別的語意資訊,用以賦能上層應用的語意計算。本節重點講述面嚮應用的知識圖譜表示。
1. 知識抽取
知識抽取是知識圖譜構建的第一步,是構建大規模知識圖譜的關鍵,其目的是在不同來源、不同結構的基礎數據中進行知識資訊抽取。按照知識在圖譜中的組成成分,知識抽取任務可以進一步細分爲實體抽取、屬性抽取和關係抽取。知識抽取的數據源有可能是結構化的(如現有的各種結構化數據庫),也有可能是半結構化的(如各種百科數據的infobox)或非結構化的(如各種純文字數據)。針對不同類型的數據源,知識抽取所需要的技術不同,技術難點也不同。通常情況下,一個知識圖譜構建過程面對的數據源不會是單一型別數據源。本節重點介紹針對非結構化文字數據進行資訊抽取的技術。如上文所述,實體和屬性間的界線比較模糊,故可以用一套抽取技術實現,所以下文如果不做特殊說明,實體抽取泛指實體、屬性抽取。
① 實體抽取
實體抽取技術歷史比較久遠,具有成體系、成熟度高的特點。早期的實體抽取也稱爲命名實體識別(Named Entity Recognition,NER),指的是從原始語料中自動識別出命名實體。命名實體指的是具有特定意義的實體名詞,如人名、機構名、地名等專有名詞。實體是知識圖譜中的最基本的元素,其效能將直接影響知識庫的品質。按照NER抽取技術特點,可以將實體抽取技術分爲基於規則的方法、基於統計機器學習的方法和基於深度學習的方法。
-
基於規則的方法:
基於規則的方法首先需要人工構建大量的實體抽取規則,然後利用這些規則在文字中進行匹配。雖然這種方法對領域知識要求較高,設計起來會非常複雜,且實現規則的全覆蓋比較困難,移植性比較差,但是在啓動的時候可以通過這個方法可以快速得到一批標註語料。 -
基於統計機器學習的方法:
既然是機器學習的方法,就需要標註語料,高品質的標註語料是通過這類方法得到好的效果的重要保障。該方法的實現過程爲:在高品質的標註語料的基礎上,通過人工設計的特徵模板構造特徵,然後通過序列標註模型,如隱馬爾可夫模型(Hidden Markov Model,HMM)、最大熵模型(Maximum Entropy Model,MEM)和條件隨機場模型(Conditional Random Fields,CRF)進行訓練和識別。模型特徵的設計需要較強的領域知識,需要針對對應實體型別的特點進行設計。例如,在人名識別任務中,一箇中文人名本身的顯著特點是一般由姓和一兩個漢字組成,並且人名的上下文也有一些規律,如「×××教授」「他叫×××」。在有了高品質的標註語料的基礎上,合適的特徵設計是得到好的序列標註模型效果的又一重要保障。對於序列標註模型,一般我們對需要識別的目標字串片段(實體)通過SBIEO(Single、Begin、Inside、End、Other)或者SBIO(Single、Begin、Inside、Other)標註體系進行標註。命名實體標註由實體的起始字元(B)、中間字元(I)、結束字元(E)、單獨成實體的字元(S)、其他字元(O)等組成,如圖2所示。

爲了區分實體的型別,會在標註體系上帶上對應的型別標籤,例如ORG-B、ORG-I、ORG-E。在實體抽取中,我們最常用的基於統計的序列標註學習模型是HMM、CRF。其中,HMM描述由隱藏的隱馬爾可夫隨機生成觀測序列的聯合分佈的P(X,Y)過程,屬於生成模型(Generative Model),CRF則是描述一組輸入隨機變數條件下另一組構成馬爾可夫隨機場的數據變數的條件概率分佈P(Y|X),屬於判別模型(Discrimination Model)。以HMM爲例,模型可形式化表示爲λ= (A,B,π),設I是長度爲T的狀態序列,O是對應長度的觀測序列,M爲所有可能的觀測數(對應於詞典集合大小),N爲所有狀態數(對應標註的類別數),A是狀態轉移矩陣:
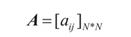
其中:
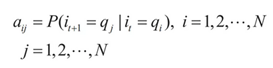
aij表示在時刻t處於qi的條件下在時刻t+1轉移到qj的概率。B是觀測概率矩陣:
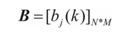
其中:
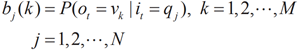
π是初始狀態概率向量:
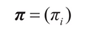
其中:
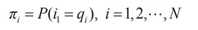
πi表示在時刻t=1處於狀態qi的概率。HMM模型的參數學習即學習上面的A,B,π矩陣,有很多實現方法,比如EM和最大似然估計。一般在語料充足的情況下,爲了簡化過程,採用最大似然估計,例如:
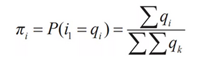
序列標註任務可以抽象爲求解給定觀察序列O=(o1,o2,…,oT)和模型λ=(A,B,π),也就是計算在模型λ下使給定觀測序列條件概率P(I|O)最大的觀測序列I=(i1,i2,…,iT),即在給定觀測序列(即原始字串文字)中求最有可能的對應的狀態序列(標註結構)。一般採用維特比演算法,這是一種通過動態規劃方法求概率最大路徑的演算法,一條路徑對應一個狀態序列。定義在時刻t狀態爲i的所有單個路徑(i1,i2,…,it)中概率最大值爲:
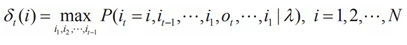
可以得到變數δ的遞推公式:
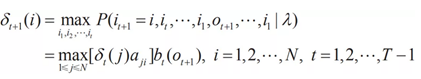
定義在時刻t狀態爲i的所有單個路徑(i1,i2,…,it-1,i)中概率最大的路徑的第t-1個節點爲:
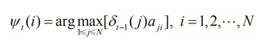
維特比演算法在初始化δ1(i)=πibi(o1),Ψ1(i)=0,i=1,2,…,N之後,通過上述遞推公式,得到最優序列。CRF演算法與維特比演算法類似,其得到在各個位置上的非規範化概率的最大值,同時記錄該路徑:
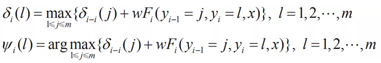
- 基於深度學習的方法
在上面介紹用統計機器學習的方法構造特徵的時候,我們發現實體在原始文字中的上下文特徵非常重要。構建上下文特徵需要大量的領域知識,且要在特徵工程上下不少功夫。隨着深度學習的方法在自然語言處理上的廣泛應用,構建上下文特徵開始變得簡單了。深度學習的方法直接以詞/字向量作爲輸入,一些模型(如RNN、Transformer等)本身就能很好地學習到上下文資訊,並且不需要專門設計特徵來捕捉各種語意資訊,相比傳統的統計機器學習模型,效能都得到了顯著提高。這一類模型的通用結構基本都是一個深度神經網路+CRF,如bi-LSTM-CRF、IDCNN-CRF、LSTM-CNN-CRF、Bert-biLSTM-CRF等,模型可以基於字或詞輸入(一般來說,基於字的模型效能更加優秀,它可以有效解決OOV問題)。這個DNN模型可以學習上下文語意特徵、預測各個位置上輸出各個標籤的概率,然後再接入CRF層來學習各標籤之間的依賴關係,得到最終的標註結果。
② 關係抽取
關係抽取的目標是抽取兩個或者多個實體間的語意關係,從而使得知識圖譜真正成爲一張圖。關係抽取的研究是以MUC(Message Understanding Conference)評測會議和後來取代MUC的ACE(Automatic Content Extraction)評測會議爲主線進行的。ACE會議會提供測評數據,現在許多先進的演算法已經被提出。一般關係抽取的順序是,先識別實體,再抽取實體之間可能存在的關係。其實也可以把實體抽取、關係抽取聯合在一起同時完成。目前,關係抽取方法可以分爲基於模板的關係抽取和基於監督學習的關係抽取兩種方法。
-
基於模板的關係抽取
基於模板的關係抽取,即由人工設計模板,再結合語言學知識和具體關係的語料特點,採用boot-strap思路到語料裡匹配並進行抽取關係。這種方法適用於小規模、特定領域任務冷啓動時的關係抽取,這種場景下效果比較穩定。 -
基於監督學習的關係抽取
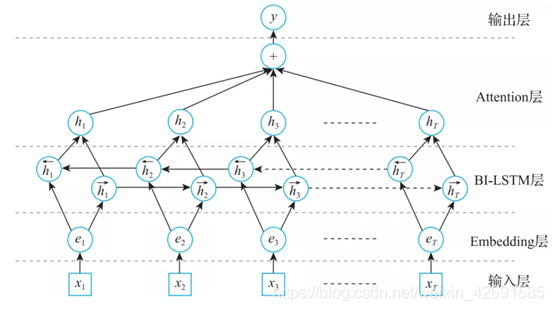
基於監督學習的關係抽取方法一般把關係抽取任務當作一系列的分類問題處理。即基於大規模的標註語料,針對實體所在的句子訓練有監督的分類模型。分類模型有很多,例如統計機器學習方法SVM及深度學習方法(如CNN)等。傳統的機器學習方法重點在特徵選擇上,除了實體本身的詞特徵,還包括實體詞本身、實體型別、兩個實體間的詞以及實體距離等特徵。很多研究都引入了依存句法特徵,用以引入實體間的線性依賴關係。基於深度學習的關係抽取方法則不需要人工構建各種特徵,輸入一般只要包括句子中的詞及其位置的向量表示特徵。目前基於深度學習的關係抽取方法可以分爲流水線方法(Pipeline)和聯合抽取方法(Jointly) 。前者是將實體識別和關係抽取作爲兩個前後依賴的分離過程;後者則把兩個方法相結合,在統一模型中同時完成,從而避免流水線方法中存在的錯誤累計問題。在經典的深度學習關係抽取方法中,輸入層採用的就是詞、位置資訊,將在Embedding層得到的向量作爲模型的輸入,經過一個BI-LSTM層和Attention層,輸出得到各個關係的概率,如圖3所示。
③ 知識融合
通過知識抽取,我們得到大量實體(屬性)和關係,但是由於描述、寫法的不同,結果中存在大量冗餘和錯誤資訊,有必要對這些數據進行消歧、清洗和整合處理。作爲知識融合的重點技術,實體鏈接(Entity Linking) 的目的是將在文字中抽取得到的實體物件鏈接到知識庫中與之對應的唯一確定的實體物件,以實現實體消歧和共指消解。實體消歧(Entity Disambiguation) 專門用於解決同名實體的歧義問題,最簡單的方法是通過實體的屬性、周邊的詞構成特徵向量,通過向量的餘弦相似度評估兩個實體的相似度。基於這個思想,我們可以有更多的基於語意的方法來表徵目標實體,從而評估兩個實體是否是同一個。共指消解(Entity Resolution) 是指解決多個不同寫法的實體指向同一個實體的問題。一般這類問題可以參考實體消歧方法解決,也可以具體問題具體分析,通過一些規則方法解決。
2. 知識推理
知識推理是基於現有的知識圖譜結構,進一步挖掘隱含的知識,用來補全現有知識圖譜屬性、關係,從而發現新的知識,拓展和豐富圖譜。例如可以通過推理髮現新屬性,如由已知實體的出生年月屬性推理出年齡;也可以發現新關係,例如,已知(A,股東,B公司)、(C,股東,B公司)可以推理得出(A,合作夥伴,C)。知識推理的方法可以分爲兩大類:基於邏輯的推理和基於圖的推理。
① 基於邏輯的推理
基於邏輯的推理主要包括一階謂詞邏輯(First Order Logic)推理、描述邏輯(Description Logic)推理。一階謂詞對應着知識庫裡的實體物件和關係,通過謂詞之間的「與」和「或」的關係來表示知識變遷從而實現推理。例如通過「媽媽是女人」「女人是人」可以推理得到「媽媽是人」。描述邏輯則是在一階謂詞的基礎上,解決一階謂詞邏輯的表示能力有限的問題,通過TBox(Terminology Box)和ABox(Assertion Box),可以將知識圖譜中複雜的實體關係推理轉化爲一致性的檢驗問題,從而簡化推理。
② 基於圖的推理
基於圖的推理方法,主要藉助圖的結構特徵,通過路徑遊走的方法,如Path Ranking演算法和神經網路圖向量表示方法,進行基於圖的推理。Path Ranking演算法的基本思想是從圖譜的一個節點出發,經過邊在圖上遊走,如果能夠通過一個路徑到達目標節點,則推測源節點和目標節點存在關係。神經網路圖向量表示方法則是對通過向量表示後的圖節點、關係進行相似度運算,推理節點之間是否存在關係。
3. 知識圖譜儲存
知識圖譜中的資訊可以用RDF結構表示,它的主要組成成分是三元組,主要包括實體及其屬性、關係三類元素。在實際應用中,按照底層數據庫的儲存方式不同,可以分成基於表結構的儲存和基於圖結構的儲存。基於表結構的儲存可以理解爲一般的關係型數據庫,常見的如MySQL、Oracle,基於圖儲存的數據庫常見的有Neo4j、OrientDB、GraphDB等。
① 基於表結構的儲存
基於表結構的知識圖譜儲存利用二維數據表對知識圖譜中的數據進行儲存,有3種常見的設計方案:基於三元組的儲存、基於型別表的儲存和基於關係型數據庫的儲存。
- 基於三元組的儲存
因爲知識圖譜可以由三元組描述,所以我們可以把知識圖譜轉化成三元組的描述方式,將其放到一張數據表中。例如可以類似表1所示的形式。

這種儲存的優點很明顯,結構比較簡單,可以通過再加一些欄位來增強對關係的資訊的描述,例如區分是屬性還是關係。其缺點也很明顯:首先,這樣有很高的冗餘,儲存開銷很大,其次,因修改、刪除和更新操作帶來的操作開銷也很大;最後,由於所有的知識都是以一行一個三元組的方式儲存的,因此所有的複雜查詢都要拆分爲對三元組的查詢才能 纔能得到答案。
-
基於型別表的儲存
針對上述方案存在的缺點,可以爲每一種實體型別設計一張數據庫表,把所有同一型別的實體都放在同一張表中,用表的欄位來表示實體的屬性/關係。這種方案可解決上面儲存簡單、冗餘度高的問題,但是缺點也很明顯:首先,表欄位必須事先確定,所以要求窮舉實體的屬性/關係,且無法新增(否則需要修改表結構);其次,因爲屬性/關係都是儲存在特定列中的,所以無法支援對不確定型別的屬性和關係的查詢;最後,因爲數據按照型別放在對應表中,所以在查詢之前就需要事先知道實體的型別。 -
基於關係型數據庫儲存
關係型數據庫通過表的屬性來實現對現實世界的描述。我們可以在第二種方案的基礎上設計實體表(用於儲存實體屬性)、關係表(用於儲存實體間的關係),這一定程度上可以解決表結構固定、無法新增關係的問題,因爲一般我們認爲實體的屬性可以在Schema設計時事先列舉完。例如表7-1,可以拆分爲3張表(見表2、表3和表4)。



4. 基於圖結構的儲存
知識圖譜本身就是圖結構的,實體可以看作圖的節點,關係可以看作圖的關係,基於圖的方式儲存知識,可以直接、準確地反映知識圖譜內部結構,有利於知識的查詢、遊走。基於圖譜的結構進行儲存,可以借用圖論的相關演算法進行知識推理。常見的圖數據庫有Neo4j、OrientDB、GraphDb、GDB(阿裡雲) 等。Neo4j是一個開源的圖數據庫,它將結構化的數據以圖的形式儲存,基於Java實現(現在也提供Python介面),是一個具備完全事務特性的高效能數據系統,具有成熟數據庫的所有特性。Neo4j分爲商業版和社羣版。其中社羣版是開源的,是一個本地數據庫;商業版則實現了分佈式功能,能夠將多臺機器構造成數據庫叢集來提供服務。它採用的查詢語言是cypher,可以通過Neo4j實現知識圖譜節點、關係的建立(create命令)和查詢(match命令)。Neo4j在Linux上的安裝非常簡單,到官網上下載對應的安裝包,解壓後安裝到bin目錄,然後通過./neo4j start命令啓動。我們可以在:http://localhost:7474/browser/存取視覺化介面(見圖4),可以在這個Web頁面上通過cypher和圖數據庫進行互動。
阿裡巴巴內部也研發了圖數據庫用於儲存知識圖譜數據,如GDB、iGraph等,其中GDB(Graph Database,圖數據庫) 是由阿裡雲自主研發的,是一種支援Property Graph圖模型、用於處理高度連線數據查詢與儲存的實時、可靠的線上數據庫。它支援Apache TinkerPop Gremlin查詢語言,可以快速構建基於高度連線的數據集的應用程式。GDB非常適合用於社羣網路、欺詐檢測、推薦引擎、實時圖譜、網路/IT運營這類需要用到高度互連數據集的場景。目前GDB正處於公測期間,阿裡巴巴內部很多知識圖譜業務都基於GDB儲存,它具備如下優勢:
- 標準圖查詢語言:支援屬性圖,高度相容Gremlin圖查詢語言。
- 高度優化的自研引擎:高度優化的自研圖計算層和儲存層,通過雲盤多副本方案保障數據超高可靠性,支援ACID事務。
- 服務高可用:支援高可用範例,單節點出故障後業務會迅速轉移到其他節點,從而保障了業務的連續性。
- 易運維:提供備份恢復、自動升級、監控告警、故障切換等豐富的運維功能,大幅降低運維成本。
四、知識表示
知識表示是指在不同的語意環境下有不同的含義,例如在圖譜構建階段,知識表示可以認爲是基於RDF用三元組形式,如「<實體,屬性,值>」或者「<實體,關係,實體>」(也有描述爲<主語,謂詞,賓語>) 來表徵知識圖譜的語意資訊的。在知識圖譜接入上層應用場景後,尤其是隨着深度學習方法的廣泛採用,如何將知識圖譜和深度學習模型融合,藉助知識圖譜引入領域知識來提升深度學習模型效能,引起了學術界和工業界的廣泛關注。本節將重點介紹基於知識表示的學習方法,介紹如何將知識圖譜中的高度稀疏的實體、關係表示成一個低維、稠密向量。
1. 距離模型
結構表示(Structured Embedding,SE),將每個實體用d維的向量表示,所有實體被投影到同一個d維向量空間中,同時,爲了區分關係的有向特徵,爲每個關係r定義了2個矩陣Mr,1,Mr,2∈Rd*d,用於三元組中頭實體和尾實體的投影操作,將頭實體、尾實體投影到關係r的空間中來計算兩個向量的距離,公式爲:
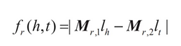
用以反映2個實體在關係r下的語意相關度,距離越小,說明這2個實體存在這種關係的可能性越大。然而該模型有一個重要缺陷,它使用頭、尾兩個不同的矩陣進行投影,這個矩陣相互獨立沒有協同,往往無法精確刻畫兩個實體基於關係的語意聯繫。爲了解決這個問題,後續出現了單層神經網路模型(Single Layer Model,SLM)、語意匹配能量模型(Semantic Matching Energy,SME)等方法,如RESCAL。RESACL模型是一個基於矩陣分解的模型,在該模型中,將整個知識圖譜編碼爲一個三維張量X,如果三元組存在,則Xhrt=1,否則爲0。張量分解的目標是要將每個三元組對應的張量分解爲實體和關係,使得Xhrt儘量接近lhMrlt,函數可表示爲:
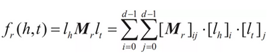
2. 翻譯模型
自從Mikolov等人於2013年提出word2vec模型開始,表示學習Embedding在自然語言處理領域受到廣泛關注,該模型發現在詞向量空間中平移(加減)不變現象,即:
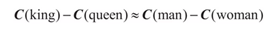
其中C(w)表示w通過word2vec得到的詞向量。受這類類比推理實驗啓發,Bordes等人提出了TransE模型,之後又出現多種衍生模型,如TransH、TransR等。TransE將知識庫中的關係看作實體間的平移向量,對於每個三元組,TransE希望:
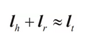
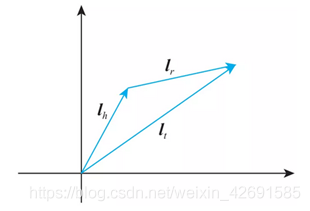
即期望頭節點向量沿關係平移後,儘量和尾節點向量重合(見圖5)。
模型的損失函數定義如下:
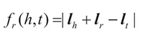
「||」表示取模運算,如L2距離。在實際學習過程中,爲了增強模型知識表示的區分能力,TransE採用了最大間隔,目標函數爲:
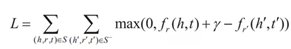
其中,S是正確的三元組集合,S-是錯誤的三元組集合,γ爲正確三元組得分和錯誤三元組得分之間的間隔距離,是一個超參數。S-的產生與負樣本的生成方式不同,不通過直接隨機採樣三元組,而是將S中每一個三元組的頭實體、關係、尾實體其中之一隨機替換成其他實體或關係來構造。TransE模型簡單有效,後續很多知識表示學習方法都是以此爲代表進行拓展的。例如TransH模型,爲了解決TransE在處理1-N、N-1、N-N複雜關係時的侷限性,提出讓一個實體在不同關係下擁有不同的表示。另外,雖然TransH模型使得每個實體在不同關係下擁有了不同的表示,但是它仍然假設實體和關係處於統一語意空間中,這和我們一般的認知有點不同,於是有學者提出了TransR模型。TransR模型首先通過一個投影矩陣Mr把實體投影到關係的語意空間,然後再進行關係類比推理(見圖6):
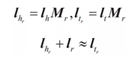
五、電商知識圖譜應用
知識圖譜提供了一種更好的組織、管理和利用海量資訊的方式,描述了現實世界中的概念、實體以及它們之間的關係。自從谷歌提出知識圖譜並應用在搜尋引擎中,用以提升搜尋引擎使用體驗,提高搜尋引擎品質以後,知識圖譜在各種垂直領域場景中都扮演了重要的角色。隨着消費升級,行業會場+爆款的導購模式已經無法滿足消費者心智,人們對貨品的需求逐漸轉化爲對場景的需求。通過場景重新定義貨品的需求產生,場景運營平臺應運而生。場景運營平臺通過對商品知識的挖掘,將具有共同特徵的商品通過演算法模型聚合在一起,形成事實上的跨品類商品搭配。在演算法端完成場景-商品知識圖譜的建設後,通過當前訴求挖掘消費者深層次訴求,推薦某個場景下互相搭配的商品,給予消費者對應場景下一站式的購物體驗,達到鼓勵消費者跨類目購買行爲及提升客單價的目的。例如在阿裡電商平臺,導購場景就有了很好的應用,並取得了不錯的效果。1688團隊在阿裡內部數據和演算法基建的基礎上,基於B類商品特徵,構建了自己的商品知識圖譜,以CPV的方式表徵一個商品,具體商品表徵如圖7所示。

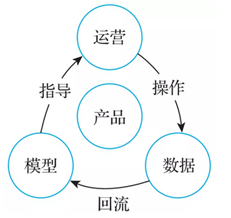
任何知識圖譜應用的構建,整體上都要經歷如下幾個步驟:文字等非結構化或半結構化資訊→結構化的知識圖譜→知識圖譜表徵→特定應用場景。1688的商品知識圖譜,在阿裡通用的電商NLP技術的基礎上,完成了半結構化資訊向結構化的知識圖譜轉化的步驟,但是中間存在大量品質較差、語意模糊甚至錯誤的數據。爲了優化這部分數據,阿裡做了大量的工作,包括實體合併、消歧、長尾數據裁剪等。針對初步加工過的數據,還需要大量的人工來標註清洗,以發揮數據的價值。而數據標註清洗這種累活一般是找專門的數據標註公司外包完成的。爲了減少專門標註的成本,我們採用了「以戰養兵」的思路,讓運營直接使用這份經過初步加工的數據,通過收集運營的操作數據,快速反饋到演算法模型中並不斷優化結果,形成運營-數據的相互反饋,如圖8所示,讓工具越用越順手,越用越好。
具體的主題錄入方式是:運營指定一個主題場景,比如婚慶主題,在指定主題下涵蓋商品的類目、屬性、屬性值。比如列舉一組設定,可以搭配後臺設定截圖。通過行業運營專家的經驗將主題和相應的商品圖譜關聯起來,我們可以明確哪些CPV數據存在業務關聯,以及運營認爲哪些數據是有效的。除了主題數據的人工錄入,我們還配套了相關的自動化頁面搭建方案。電商經常需要做促銷活動,活動會場頁面的製作需要投入大量人力,常見的活動頁面如圖9所示。

這種活動類導購頁面的搭建,核心是站在買家的角度幫助他們發現和選擇商品,如圖10所示。其中,什麼商品、如何挑選、怎樣呈現就是導購頁面包含的核心要素和業務流程。對映到技術領域,則會涉及建立頁面、數據分析、投放策略的三個方面。
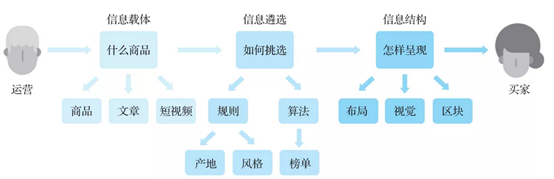
1688在活動頁面製作方面沉澱多年,有衆多實用的技術和工具供運營使用,如頁面元件化搭建產品(積木盒子、奇美拉)、指標選品工具(選品庫)、商品排序投放產品(投放平臺)等。這些產品都有各自的細分業務域,運營通常需要跳轉到多個平臺進行設定,才能 纔能完成一張活動頁面的搭建,整體流程如圖11所示。
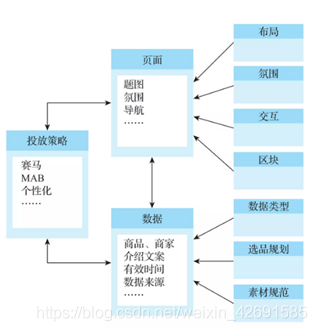
這就像是辦證件,A視窗讓你去B視窗登記,B視窗讓你去C視窗填表。我們都圍着一個個的「視窗」轉,這是一種以資源爲中心的工作方式。以前讓使用者圍繞着資源轉,是爲了最大化資源的使用效率,但是在今天這個人力成本高的時代,需要從資源視角轉向使用者視角,讓資源圍着使用者轉,這樣可以最大化價值流動效率。我們通過幾個月的努力,將十餘個系統打通,實現了數據源標準化方案、數據頁面系結方案、頁面自動多端搭建方案、投放自動化方案等,形成瞭如圖12所示的產品體系。
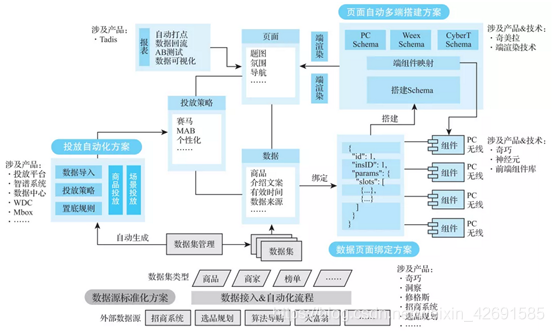
通過將系統打通,使得運營搭建一個頁面的設定工作量減少了83.2%。而在剩餘的16.8%的工作裡,有87%是選品工作。藉助主題會場,我們希望將運營選品的工作量也降低50%以上,並藉助數據和演算法,實現智慧選品、智慧搭建、智慧投放。