基於NCNN的3x3可分離折積再思考盒子濾波
【GiantPandaCV導語】這篇文章主要是對NCNN 的3x3可分離折積的armv7架構的實現進行了非常詳細的解析和理解,然後將其應用於盒子濾波,並獲得了筆者最近關於盒子濾波的優化實驗的最快速度,即相對於原始實現有37倍加速,希望對做工程部署或者演算法優化的讀者有一定啓發。程式碼鏈接:
https://github.com/BBuf/ArmNeonOptimization
1. 前言
前面已經做了一系列實驗來優化盒子濾波演算法,然後經nihui大佬提醒去看了一下NCNN的深度可分離折積運算元的實現,在理解了這個程式碼實現之後將其拆分出來完成了一個的盒子濾波,並新增了一些額外的思考以及實現,最終在A53上將盒子濾波相對於最原始的實現加速了37倍,然後就有了這篇文章。完整速度測試結果如下:
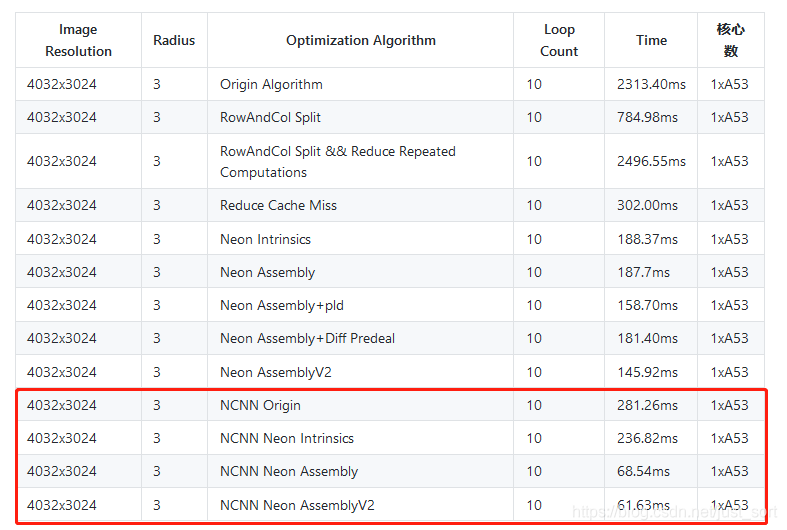
上篇文章我們已經將半徑爲的盒子的濾波在A53上優化到了,影象的解析度是,所以本次系列實驗的BaseLine已經明確,這一節就基於NCNN的convolutiondepthwise3x3.h將其核心程式碼拆出來實現這個盒子濾波,並對其做速度以及實現分析,所以也可以把這篇文章當成NCNN的可分離折積運算元實現程式碼分析。NCNN的convolutiondepthwise3x3.h地址爲:https://github.com/Tencent/ncnn/blob/master/src/layer/arm/convolutiondepthwise_3x3.h 。
十分感謝德澎在我做這篇優化文章時的耐心指導以及指出一些關鍵指令的正確理解方式,學習路上擁有良師益友是十分幸運之事。
2. 原始實現—將盒子濾波看成折積來做
實際上盒子濾波本來就是CNN中一個折積的過程,只不過這裏參與折積的特徵圖通道數是1,然後折積核固定爲一個的全矩陣,那麼我們可以藉助NCNN的https://github.com/Tencent/ncnn/blob/master/src/layer/arm/convolutiondepthwise_3x3.h展示的思路,將濾波核直接完全展開,一次讀三行/四行來進行計算,這樣做有個好處就是我們仍然規避掉了在行方向進行頻繁切換導致的Cache Miss增加,並且在列方向可以做Neon加速。下面 下麪的程式碼展示了基於這一想法的普通實現版本,程式碼如下:
// 原始實現,一次讀四行進行計算
void BoxFilterBetterOrigin(float *Src, float *Dest, int Width, int Height, int Radius){
int OutWidth = Width - Radius + 1;
int OutHeight = Height - Radius + 1;
//折積核爲全1矩陣,因爲這裏處理的是盒子濾波
float *kernel = new float[Radius*Radius];
for(int i = 0; i < Radius*Radius; i++){
kernel[i] = 1.0;
}
float *k0 = kernel;
float *k1 = kernel + 3;
float *k2 = kernel + 6;
float* r0 = Src;
float* r1 = Src + Width;
float* r2 = Src + Width * 2;
float* r3 = Src + Width * 3;
float* outptr = Dest;
float* outptr2 = Dest + OutWidth;
int i = 0;
//一次處理4行,對應2個輸出
for (; i + 1 < OutHeight; i += 2){
int remain = OutWidth;
for(; remain > 0; remain--){
float sum1 = 0, sum2 = 0;
sum1 += r0[0] * k0[0];
sum1 += r0[1] * k0[1];
sum1 += r0[2] * k0[2];
sum1 += r1[0] * k1[0];
sum1 += r1[1] * k1[1];
sum1 += r1[2] * k1[2];
sum1 += r2[0] * k2[0];
sum1 += r2[1] * k2[1];
sum1 += r2[2] * k2[2];
sum2 += r1[0] * k0[0];
sum2 += r1[1] * k0[1];
sum2 += r1[2] * k0[2];
sum2 += r2[0] * k1[0];
sum2 += r2[1] * k1[1];
sum2 += r2[2] * k1[2];
sum2 += r3[0] * k2[0];
sum2 += r3[1] * k2[1];
sum2 += r3[2] * k2[2];
*outptr = sum1;
*outptr2 = sum2;
r0++;
r1++;
r2++;
r3++;
outptr++;
outptr2++;
}
r0 += 2 + Width;
r1 += 2 + Width;
r2 += 2 + Width;
r3 += 2 + Width;
outptr += OutWidth;
outptr2 += OutWidth;
}
for(; i < OutHeight; i++){
int remain = OutWidth;
for(; remain > 0; remain--){
float sum1 = 0;
sum1 += r0[0] * k0[0];
sum1 += r0[1] * k0[1];
sum1 += r0[2] * k0[2];
sum1 += r1[0] * k1[0];
sum1 += r1[1] * k1[1];
sum1 += r1[2] * k1[2];
sum1 += r2[0] * k2[0];
sum1 += r2[1] * k2[1];
sum1 += r2[2] * k2[2];
*outptr = sum1;
r0++;
r1++;
r2++;
outptr++;
}
r0 += 2;
r1 += 2;
r2 += 2;
}
}
由於原始實現非常簡單,這裏就不再贅述了,相信大家很容易就看懂了,這裏列印了一下經過這個函數處理後的輸出矩陣的前20個元素,值爲:
308.00000 343.00000 360.00000 352.00000 330.00000 318.00000 327.00000 338.00000 331.00000 314.00000 304.00000 307.00000 323.00000 341.00000 348.00000 348.00000 350.00000 355.00000 355.00000 353.00000
然後處理完這張圖片速度爲281.26ms,可以從第一節的圖中更直觀的對比。
3. Neon Intrinsics 優化
將上面的原始實現的列方向進行Neon Intrinsics優化,德澎幫忙加了超詳細註釋的程式碼版本如下,不需要講任何細節,因爲細節確實都在程式碼和註釋裡:
void BoxFilterBetterNeonIntrinsics(float *Src, float *Dest, int Width, int Height, int Radius){
int OutWidth = Width - Radius + 1;
int OutHeight = Height - Radius + 1;
// 這裏雖然 kernel 大小是根據輸入設定
// 但是下面 下麪的計算寫死了是3x3的kernel
// boxfilter 權值就是1,直接加法即可,
// 額外的乘法會增加耗時
float *kernel = new float[Radius*Radius];
for(int i = 0; i < Radius*Radius; i++){
kernel[i] = 1.0;
}
// 下面 下麪程式碼,把 kernel 的每一行存一個 q 暫存器
// 而因爲一個 vld1q 會載入 4 個浮點數,比如 k012
// 會多載入下一行的一個數字,所以下面 下麪
// 會用 vsetq_lane_f32 把最後一個數字置0
float32x4_t k012 = vld1q_f32(kernel);
float32x4_t k345 = vld1q_f32(kernel + 3);
// 這裏 kernel 的空間如果 Radius 設爲3
// 則長度爲9,而從6開始讀4個,最後一個就讀
// 記憶體越界了,可能會有潛在的問題。
float32x4_t k678 = vld1q_f32(kernel + 6);
k012 = vsetq_lane_f32(0.f, k012, 3);
k345 = vsetq_lane_f32(0.f, k345, 3);
k678 = vsetq_lane_f32(0.f, k678, 3);
// 輸入需要同時讀4行
float* r0 = Src;
float* r1 = Src + Width;
float* r2 = Src + Width * 2;
float* r3 = Src + Width * 3;
float* outptr = Dest;
float* outptr2 = Dest + OutWidth;
int i = 0;
// 同時計算輸出兩行的結果
for (; i + 1 < OutHeight; i += 2){
int remain = OutWidth;
for(; remain > 0; remain--){
// 從當前輸入位置連續讀取4個數據
float32x4_t r00 = vld1q_f32(r0);
float32x4_t r10 = vld1q_f32(r1);
float32x4_t r20 = vld1q_f32(r2);
float32x4_t r30 = vld1q_f32(r3);
// 因爲 Kernel 最後一個權值置0,所以相當於是
// 在計算一個 3x3 的折積點乘累加中間結果
// 最後的 sum1 中的每個元素之後還需要再加在一起
// 還需要一個 reduce_sum 操作
float32x4_t sum1 = vmulq_f32(r00, k012);
sum1 = vmlaq_f32(sum1, r10, k345);
sum1 = vmlaq_f32(sum1, r20, k678);
// 同理計算得到第二行的中間結果
float32x4_t sum2 = vmulq_f32(r10, k012);
sum2 = vmlaq_f32(sum2, r20, k345);
sum2 = vmlaq_f32(sum2, r30, k678);
// [a,b,c,d]->[a+b,c+d]
// 累加 這裏 vadd 和下面 下麪的 vpadd 相當於是在做一個 reduce_sum
float32x2_t _ss = vadd_f32(vget_low_f32(sum1), vget_high_f32(sum1));
// [e,f,g,h]->[e+f,g+h]
float32x2_t _ss2 = vadd_f32(vget_low_f32(sum2), vget_high_f32(sum2));
// [a+b+c+d,e+f+g+h]
// 這裏因爲 intrinsic 最小的單位是 64 位,所以用 vpadd_f32 把第一行和第二行最後結果拼在一起了
float32x2_t _sss2 = vpadd_f32(_ss, _ss2);
// _sss2第一個元素 存回第一行outptr
*outptr = vget_lane_f32(_sss2, 0);
*outptr2 = vget_lane_f32(_sss2, 1);
//同樣這樣直接讀4個數據,也會有讀越界的風險
r0++;
r1++;
r2++;
r3++;
outptr++;
outptr2++;
}
r0 += 2 + Width;
r1 += 2 + Width;
r2 += 2 + Width;
r3 += 2 + Width;
outptr += OutWidth;
outptr2 += OutWidth;
}
for(; i < OutHeight; i++){
int remain = OutWidth;
for(; remain > 0; remain--){
float32x4_t r00 = vld1q_f32(r0);
float32x4_t r10 = vld1q_f32(r1);
float32x4_t r20 = vld1q_f32(r2);
//sum1
float32x4_t sum1 = vmulq_f32(r00, k012);
sum1 = vmlaq_f32(sum1, r10, k345);
sum1 = vmlaq_f32(sum1, r20, k678);
float32x2_t _ss = vadd_f32(vget_low_f32(sum1), vget_high_f32(sum1));
_ss = vpadd_f32(_ss, _ss);
*outptr = vget_lane_f32(_ss, 0);
r0++;
r1++;
r2++;
outptr++;
}
r0 += 2;
r1 += 2;
r2 += 2;
}
}
然後板端執行之後獲得的輸出矩陣的前20個元素爲:
308.00000 343.00000 360.00000 352.00000 330.00000 318.00000 327.00000 338.00000 331.00000 314.00000 304.00000 307.00000 323.00000 341.00000 348.00000 348.00000 350.00000 355.00000 355.00000 353.00000
可以看到和原始實現是完全對應的,然後速度測試結果請看第一節的圖,從281.26ms優化到了236.82ms。
4. Neon Assembly優化
將上面的程式碼對應翻譯爲Neon Assembly程式碼如下(實際上就是NCNN 的深度可分離折積實現,不過這裏將其改成盒子濾波場景,去掉了Bias),對於程式碼中的細節都在註釋裏面詳細的描述,這裏的計算是十分巧妙的。帶詳細解析版的程式碼如下,介於篇幅原因這裏只貼出完整程式碼中核心部分的內聯彙編實現,完整實現請移步我的github地址:https://github.com/BBuf/ArmNeonOptimization ,如果內容對你有用請點個星哦。
//q9->[d18, d19]
//q10->[d20, 0]
//neon assembly
// : "0"(nn),
// "1"(outptr),
// "2"(outptr2),
// "3"(r0),
// "4"(r1),
// "5"(r2),
// "6"(r3),
// "w"(k012), // %14
// "w"(k345), // %15
// "w"(k678) // %16
if(nn > 0){
asm volatile(
"pld [%3, #192] \n"
// 因爲每一行連續計算 4 個輸出,所以連續載入
// 6個數據即可,4個視窗移動步長爲1,有重疊
// r0 原來的記憶體排布 [a, b, c, d, e, f]
// d18 -> [a, b], r19 -> [c, d], r20 -> [e, f]
"vld1.f32 {d18-d20}, [%3 :64] \n" //r0
// r0 指針移動到下一次讀取起始位置也就是 e
"add %3, #16 \n"
// q9 = [d18, d19] = [a, b, c, d]
// q10 = [d20, d21] = [e, f, *, *]
// q11 = [b, c, d, e]
// q12 = [c, d, e, f]
// 關於 vext 見:https://community.arm.com/developer/ip-products/processors/b/processors-ip-blog/posts/coding-for-neon---part-5-rearranging-vectors
//
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
"0: \n"
// 這裏計算有點巧妙
// 首先因爲4個折積視窗之間是部分重疊的
// q9 其實可以看做是4個連續視窗的第1個元素排在一起
// q11 可以看做是4個連續視窗的第2個元素排在一起
// q12 可以看做是4個連續視窗的第3個元素排在一起
// 原來連續4個折積視窗對應的數據是
// [a, b, c], [b, c, d], [c, d, e], [d, e, f]
// 現在相當於 是數據做了下重排,但是重排的方式很巧妙
// q9 = [a, b, c, d]
// q11 = [b, c, d, e]
// q12 = [c, d, e, f]
// 然後下面 下麪的程式碼就很直觀了,q9 和 k012 權值第1個權值相乘
// 因爲 4 個視窗的第1個元素就只和 k012 第1個權值相乘
// %14 指 k012,假設 %14 放 q0 暫存器,%e 表示取 d0, %f指取 d1
"vmul.f32 q7, q9, %e14[0] \n" //
// 4 個視窗的第2個元素就只和 k012 第2個權值相乘
"vmul.f32 q6, q11, %e14[1] \n" //
// 4 個視窗的第3個元素就只和 k012 第3個權值相乘
// 這樣子視窗之間的計算結果就可以直接累加
// 然後q13相當於只算了3x3折積第一行 1x3 折積,中間結果
// 下面 下麪指令是把剩下 的 兩行計算完
"vmul.f32 q13, q12, %f14[0] \n"
// 計算第二行
"pld [%4, #192] \n"
"vld1.f32 {d18-d20}, [%4] \n" // r1
"add %4, #16 \n"
//把第二行的[a, b, c, d] 和 k345 的第1個權值相乘,然後累加到q7暫存器上
"vmla.f32 q7, q9, %e15[0] \n"
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
//把第二行的[b, c, d, e] 和 k345 的第2個權值相乘,然後累加到q6暫存器上
"vmla.f32 q6, q11, %e15[1] \n"
//把第三行的[c, d, e, f] 和 k345 的第3個權值相乘,然後累加到q13暫存器上
"vmla.f32 q13, q12, %f15[0] \n"
// 爲outptr2做準備,計算第二行的 [a, b, c, d, e, f] 和 k012 的乘積
// 把第二行的 [a, b, c, d] 和 k012的第1個權值相乘,賦值給q8暫存器
"vmul.f32 q8, q9, %e14[0] \n"
// 把第二行的 [b, c, d, e] 和 k012的第2個權值相乘,賦值給q14暫存器
"vmul.f32 q14, q11, %e14[1] \n"
// 把第二行的 [c, d, e, f] 和 k012的第3個權值相乘,賦值給q15暫存器
"vmul.f32 q15, q12, %f14[0] \n"
//和上面的過程完全一致,這裏是針對第三行
"pld [%5, #192] \n"
"vld1.f32 {d18-d20}, [%5 :64] \n" // r2
"add %5, #16 \n"
// 把第三行的 [a, b, c, d] 和 k678 的第1個權值相乘,然後累加到q7暫存器上
"vmla.f32 q7, q9, %e16[0] \n"
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
// 把第三行的 [b, c, d, e] 和 k678 的第2個權值相乘,然後累加到q6暫存器上
"vmla.f32 q6, q11, %e16[1] \n"
// 把第三行的 [c, d, e, f] 和 k678 的第3個權值相乘,然後累加到q13暫存器上
"vmla.f32 q13, q12, %f16[0] \n"
// 把第三行的 [a, b, c, d] 和 k345 的第1個權值相乘,然後累加到q8暫存器上
"vmla.f32 q8, q9, %e15[0] \n"
// 把第三行的 [b, c, d, e] 和 k345 的第2個權值相乘,然後累加到q14暫存器
"vmla.f32 q14, q11, %e15[1] \n"
// 把第三行的 [c, d, e, f] 和 k345 的第3個權值相乘,然後累加到q15暫存器
"vmla.f32 q15, q12, %f15[0] \n"
"pld [%6, #192] \n"
"vld1.f32 {d18-d20}, [%6] \n" // r3
"add %6, #16 \n"
// 把第四行的 [a, b, c, d] 和 k678 的第1個權值相乘,然後累加到q8暫存器上
"vmla.f32 q8, q9, %e16[0] \n"
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
// 把第四行的 [b, c, d, e] 和 k678 的第2個權值相乘,然後累加到q14暫存器上
"vmla.f32 q14, q11, %e16[1] \n"
// 把第四行的 [c, d, e, f] 和 k678 的第3個權值相乘,然後累加到q15暫存器上
"vmla.f32 q15, q12, %f16[0] \n"
"vadd.f32 q7, q7, q6 \n" // 將q6和q7累加到q7上,針對的是outptr
"pld [%3, #192] \n"
"vld1.f32 {d18-d20}, [%3 :64] \n" // r0
"vadd.f32 q8, q8, q14 \n" // 將q14和q8累加到q8上,針對的是outptr2
"vadd.f32 q7, q7, q13 \n" // 將q13累加到q7上,針對的是outptr
"vadd.f32 q8, q8, q15 \n" // 將q15和q8累加到q8上,針對的是outptr2
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
"add %3, #16 \n"
"vst1.f32 {d14-d15}, [%1]! \n" // 將q7暫存器的值儲存到outptr
"vst1.f32 {d16-d17}, [%2]! \n" // 將q8暫存器的值儲存到outptr2
"subs %0, #1 \n" // nn -= 1
"bne 0b \n" // 判斷條件:nn != 0
"sub %3, #16 \n" //
: "=r"(nn), // %0
"=r"(outptr), // %1
"=r"(outptr2), // %2
"=r"(r0), // %3
"=r"(r1), // %4
"=r"(r2), // %5
"=r"(r3) // %6
: "0"(nn),
"1"(outptr),
"2"(outptr2),
"3"(r0),
"4"(r1),
"5"(r2),
"6"(r3),
"w"(k012), // %14
"w"(k345), // %15
"w"(k678) // %16
: "cc", "memory", "q6", "q7", "q8", "q9", "q10", "q11", "q12", "q13", "q14", "q15"
);
}
同樣列印一下盒子濾波的輸出矩陣的前20個元素:
308.00000 343.00000 360.00000 352.00000 330.00000 318.00000 327.00000 338.00000 331.00000 314.00000 304.00000 307.00000 323.00000 341.00000 348.00000 348.00000 350.00000 355.00000 355.00000 353.00000
和前面的兩個版本是一致的,證明程式碼改寫無誤,然後耗時情況可以從第一節的圖中看到,由236.82ms變成 68.54ms,接近4倍的加速,並且比我一份樸實無華的行動端盒子濾波演算法優化筆記中最快的版本還快2-3倍。
5. Neon AssemblyV2
因爲我們是盒子濾波,然後折積核全部爲1,實際上乘法對我們來說就不是必要的了,所以我們可以去掉所有的乘法相關的指令,改用vadd來實現相關操作。這樣可以對上個版本進行進一步加速,將上一節的核心程式碼利用vadd指令改寫後的程式碼如下::
//注意這個過程是計算盒子濾波,所以不會像NCNN一樣考慮Bias
for (; i + 1 < OutHeight; i += 2){
// 在回圈體內每行同時計算4個輸出
// 同時計算兩行,也就是一次輸出 2x4 個點
int nn = OutWidth >> 2;
int remain = OutWidth - (nn << 2);
//q9->[d18, d19]
//q10->[d20, 0]
//neon assembly
// : "0"(nn),
// "1"(outptr),
// "2"(outptr2),
// "3"(r0),
// "4"(r1),
// "5"(r2),
// "6"(r3),
// "w"(k012), // %14
// "w"(k345), // %15
// "w"(k678) // %16
if(nn > 0){
asm volatile(
"pld [%3, #192] \n"
// 因爲每一行連續計算 4 個輸出,所以連續載入
// 6個數據即可,4個視窗移動步長爲1,有重疊
// r0 原來的記憶體排布 [a, b, c, d, e, f]
// d18 -> [a, b], r19 -> [c, d], r20 -> [e, f]
"vld1.f32 {d18-d20}, [%3 :64] \n" //r0
"add %3, #16 \n"
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
"0: \n"
"vmov.f32 q7, q9 \n" //
"vmov.f32 q6, q11 \n" //
"vmov.f32 q13, q12 \n"
"pld [%4, #192] \n"
"vld1.f32 {d18-d20}, [%4] \n" // r1
"add %4, #16 \n"
"vadd.f32 q7, q7, q9 \n"
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
"vadd.f32 q6, q11, q6 \n"
"vadd.f32 q13, q12, q13 \n"
"vmov.f32 q8, q9 \n"
"vmov.f32 q14, q11 \n"
"vmov.f32 q15, q12 \n"
"pld [%5, #192] \n"
"vld1.f32 {d18-d20}, [%5 :64] \n" // r2
"add %5, #16 \n"
"vadd.f32 q7, q9, q7 \n"
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
"vadd.f32 q6, q11, q6 \n"
"vadd.f32 q13, q12, q13 \n"
"vmov.f32 q8, q9 \n"
"vmov.f32 q14, q11 \n"
"vmov.f32 q15, q12 \n"
"pld [%6, #192] \n"
"vld1.f32 {d18-d20}, [%6] \n" // r3
"add %6, #16 \n"
"vmov.f32 q8, q9 \n"
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
"vmov.f32 q14, q11 \n"
"vmov.f32 q15, q12 \n"
"vadd.f32 q7, q7, q6 \n"
"pld [%3, #192] \n"
"vld1.f32 {d18-d20}, [%3 :64] \n" // r0
"vadd.f32 q8, q8, q14 \n" // 將q14和q8累加到q8上,針對的是outptr2
"vadd.f32 q7, q7, q13 \n" // 將q13累加到q7上,針對的是outptr
"vadd.f32 q8, q8, q15 \n" // 將q15和q8累加到q8上,針對的是outptr2
"vext.32 q11, q9, q10, #1 \n"
"vext.32 q12, q9, q10, #2 \n"
"add %3, #16 \n"
"vst1.f32 {d14-d15}, [%1]! \n" // 將q7暫存器的值儲存到outptr
"vst1.f32 {d16-d17}, [%2]! \n" // 將q8暫存器的值儲存到outptr2
"subs %0, #1 \n" // nn -= 1
"bne 0b \n" // 判斷條件:nn != 0
"sub %3, #16 \n" //
: "=r"(nn), // %0
"=r"(outptr), // %1
"=r"(outptr2), // %2
"=r"(r0), // %3
"=r"(r1), // %4
"=r"(r2), // %5
"=r"(r3) // %6
: "0"(nn),
"1"(outptr),
"2"(outptr2),
"3"(r0),
"4"(r1),
"5"(r2),
"6"(r3),
"w"(k012), // %14
"w"(k345), // %15
"w"(k678) // %16
: "cc", "memory", "q6", "q7", "q8", "q9", "q10", "q11", "q12", "q13", "q14", "q15"
);
}
這裏的程式碼註釋和上一節基本一樣,介於文章長度這裏就刪除掉了,可以結合上一小節的程式碼註釋理解。
最後列印輸出矩陣的前20個元素如下:
308.00000 343.00000 360.00000 352.00000 330.00000 318.00000 327.00000 338.00000 331.00000 314.00000 304.00000 307.00000 323.00000 341.00000 348.00000 348.00000 350.00000 355.00000 355.00000 353.00000
和之前的版本也完全一致,說明這個指令集改寫應該是無誤的,然後進行速度測試就獲得了第一節圖中的最後一列結果了,即從上個版本的68.54ms優化到了61.63ms。
6. 結語
這篇文章主要是對NCNN 的3x3可分離折積的armv7架構的實現進行了非常詳細的解析和理解,然後將其應用於盒子濾波,並獲得了最近關於盒子濾波的優化實驗的最快速度(截至到目前,並不代表一定是最快的),希望對做工程部署或者演算法優化的讀者有一定啓發,以上。
歡迎關注GiantPandaCV, 在這裏你將看到獨家的深度學習分享,堅持原創,每天分享我們學習到的新鮮知識。( • ̀ω•́ )✧
有對文章相關的問題,或者想要加入交流羣,歡迎新增BBuf微信:

爲了方便讀者獲取資料以及我們公衆號的作者發佈一些Github工程的更新,我們成立了一個QQ羣,二維條碼如下,感興趣可以加入。
