手寫程式碼實現mini_batch以及神經網路預測波士頓房價(百度飛槳paddle公開課2020/8/12)感謝百度,2333,給個禮物波,muamua
關於波士頓房價數據集的下載與安裝
首先說百度的paddle真的可以解放我們雙手與大腦,看看我本文中的工作量就清楚了,另外matlab都能禁,萬一tf torch也給和諧了,對吧。所以多學個框架對我們也是很有好處的。同時感謝百度免費的公開課,謝謝,謝謝。
回到正文,本文採用keras.datasets中的boston數據集,匯入方法如下圖所示:
from keras.datasets import boston_housing
(train_x,train_y),(test_x,test_y)=boston_housing.load_data()但是沒有vpn的夥計估計下不了,這裏你可以先從網上找到波士頓數據集的檔案,然後放置於:C:\Users\你家電腦使用者名稱的名稱s\datasets。然後直接執行上方程式碼,就可以成功執行了。
關於神經網路
神經網路的手動搭建需要用到numpy庫進行矩陣運算。
同時補充最關鍵的數學知識
if y=np.matmul(x,w)+b
dy/dx=np.matmul(dy,w.T)
dy/dw=np.matmul(x.T,dy)
dy/db=dy
關於神經網路的原理就不多說了
關於mini_batch的實現
sklearn庫裡有skfold函數,挺好用的,這裏手寫mini_batch主要是爲了玩耍。
參數有四個:輸入數據集,Label,batch_size,是否正則化,是否洗牌。
def creat_bunch(Input,Label,bunch_size,random_shuffle=False,normalization=False):
if not isinstance(Input,np.ndarray):
Input=np.array(Input)
if normalization==True:
MAX=Input.max(axis=1)
MIN=Input.min(axis=1)
MEAN=Input.sum(axis=1)/Input.shape[0]
for i in range(Input.shape[1]):
Input[:,i]=(Input[:,i]-MEAN)/(MAX-MIN)
print("normalization ready")
print(" ")接上
if random_shuffle==True:
EVEN=1
if Input.shape[0]//2!=0:
EVEN=0
if EVEN==1:
mid=Input.shape[0]/2
for i in range(int(mid)):
index_choice=int(np.random.randint(0,mid))
index2=int(index_choice+mid-1)
Input[[index_choice,0,index2],:]
Label[[index_choice,0,index2]]
else:
mid=(Input.shape[0]+1)/2
for i in range(int(mid)-1):
index_choice=int(np.random.randint(0,mid))
index2=int(2*(mid-1)-index_choice)
Input[[index_choice,0,index2],:]
Label[[index_choice,0,index2]]
print("shuffle ready")
print(" ")還是接上
Size=len(Label)
if Size//bunch_size==0:
Bunch_num=Size/bunch_size
else:
Bunch_num=Size//bunch_size+1
Input_bunch=[]
Label_bunch=[]
print("total {0} pieces".format(Bunch_num))
for i in range(Bunch_num):
print("{0}th bunch is ready!".format(i+1))
if i!=Bunch_num-1:
Input_bunch.append(Input[i*bunch_size:(i+1)*bunch_size,:])
Label_bunch.append(Label[i*bunch_size:(i+1)*bunch_size])
else:
Input_bunch.append(Input[(i-1)*bunch_size:Input.shape[0],:])
Label_bunch.append(Label[(i-1)*bunch_size:Input.shape[0]])
print("complete!")
return Input_bunch,Label_bunchok,mini_batch實現了,關於爲什麼要把程式碼斷開發,主要是一塊髮網頁會卡死,暈,各位體諒,湊活着看吧。
房價預測之一層神經網路的實現
由於該數據集不大,所以我沒有minibatch處理,直接幹拉。
標準化feature
def normoralization(data):
try:
MAX=data.max(axis=1)
MIN=data.min(axis=1)
MEAN=data.sum(axis=1)/data.shape[0]
for i in range(data.shape[1]):
data[:,i]=(data[:,i]-MEAN)/(MAX-MIN)
return data
except Exception as result:
print(result)
train_x=normoralization(train_x)一層神經網路的實現without啓用函數
class network:
def __init__(self,Input,Label):
self.weighten=np.random.random((Input.shape[1],1))
self.bias=np.random.random((Input.shape[0],1))
self.Input=Input
self.Label=Label
def predict(self):
self.predict_=np.matmul(self.Input,self.weighten)+self.bias
return self.predict_
def cost(self):
error=(self.predict_-self.Label.reshape(-1,1))
self.error_=error
for i in range(error.shape[0]):
error[i]=error[i]*error[i]
self.error=error
return np.sum(self.error)/self.error.shape[0]
def backward(self,leraning_rate):
for i in range(self.weighten.shape[0]):
dic=np.mean(self.error_*(-self.Input[:,i]*0.0001)*leraning_rate)
self.weighten[i]=self.weighten[i]+abs(dic)
self.bias=self.bias+abs(self.error_*0.0001)模型訓練並且繪製損失函數
import matplotlib.pyplot as plt
%matplotlib inline
net=network(train_x,train_y)
net.predict()
loss=[]
for i in range(5000):
net.predict()
net.cost()
net.backward(0.0000000000001)
loss.append(net.cost())
plt.title("mse of the prediction of boston_housing")
plt.plot(loss)
plt.show()損失函數影象:
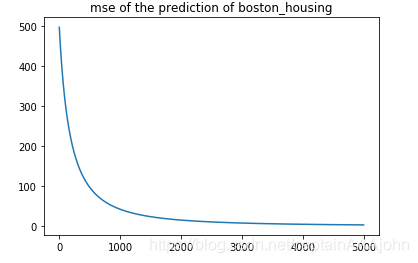
最後我簡單地實現了一下兩層神經網路的實現,基於反向傳播
兩層神經元簡單實現
定義各類函數
relu
class relu():
def __init__(self):
pass
def prediction(self,Input):
for i in range(Input.shape[0]):
for j in range(Input.shape[1]):
Input[i,j]=max(Input[i,j],0)
return Input
def backward(self,diff):
for i in range(diff.shape[0]):
for j in range(diff.shape[1]):
if diff[i,j]>0:
diff[i,j]=1
else:
diff[i,j]=0
return diffmatmul
class matmul():
def __init__(self):
pass
def prediction(self,x,w,b):
result=np.matmul(x,w)+b
return result
def backward(slef,diff,x,w,b):
b_diff=diff
w_diff=np.matmul(x.T,diff)
return b_diff,w_diff,np.matmul(diff,w.T)mse(mean squared error)
class mean_squared_error:
def __init__(self):
pass
def prediction(self,y,label):
cost=(y-label.reshape(-1,1))
return cost*cost
def backward(self,diff,y,label):
return 2*(y-label.reshape(-1,1))*y定義參數
#parameters
Epoch=20
Learning_rate=1e-20*3初始化變數
w1=np.random.random((train_x.shape[1],5))
b1=np.random.random((train_x.shape[0],5))
w2=np.random.random((5,1))
b2=np.random.random((train_x.shape[0],1))開始訓練
mse=mean_squared_error()
matmul=matmul()
activation=relu()接上
for j in range(100000):
#prediction
y1=matmul.prediction(train_x,w1,b1)
y2=activation.prediction(y1)
y3=matmul.prediction(y2,w2,b2)
#optimize
cost=mse.prediction(y3,train_y)
error=np.mean(cost,axis=0)
#backward
diff=mse.backward(0.00001,cost,train_y)
b2_diff,w2_diff,diff2=matmul.backward(diff,y2,w2,b2)
diff3=activation.backward(diff2)
b1_diff,w1_diff,diff4=matmul.backward(diff3,train_x,w1,b1)
b2-=b2_diff*Learning_rate
w2-=w2_diff*Learning_rate
b1-=b1_diff*Learning_rate
w1-=w1_diff*Learning_rate
print("the {0} turn's loss is {1}".format(j,error))完成,請大佬指出不足。也請各位施捨個贊,謝謝各位。比我還要新手的新手,建議不要把時間花在這上面,一方面演算法用CPP可能寫的更nice一點,另一方面學下paddle吧,可以讓你事半功倍。