詞向量表示
1、語言表示
語音中,用音訊頻譜序列向量所構成的矩陣作爲模型的輸入;在影象中,用影象的畫素構成的矩陣數據作爲模型的輸入。這些都可以很好表示語音/影象數據。而語言高度抽象,很難刻畫詞語之間的聯繫,比如「麥克風」和「話筒」這樣的同義詞,從字面上也難以看出這兩者意思相同,即「語意鴻溝」現象。
1.1、分佈假說
上下文相似的詞,其語意也相似。
1.2、語言模型
文字學習:詞頻、詞的共現、詞的搭配。
語言模型判定一句話是否爲自然語言。機器翻譯、拼寫糾錯、音字轉換、問答系統、語音識別等應用在得到若幹候選之後,然後利用語言模型挑一個儘量靠譜的結果。
n元語言模型:對語料中一段長度爲n 的序列wn−i+1,...,wi−1,即長度小於n的上文,n元語言模型需要最大化如下似然:
![]()
wi爲語言模型要預測的目標詞,序列wn−i+1,...,wi−1爲模型的輸入,即上下文,輸出則爲目標詞wi的分佈。用頻率估計估計n元條件概率:
![]()
通常,n越大,越能保留詞序資訊,但是長序列出現的次數會非常少,導致數據稀疏的問題。一般三元模型較爲常用。
2、詞向量表示
2.1、詞向量表示之one-hot
1、 構建語料庫
2、構建id2word的詞典
3、詞向量表示
例如構建的詞典爲:
{「John」: 1, 「likes」: 2, 「to」: 3, 「watch」: 4, 「movies」: 5, 「also」: 6, 「football」: 7, 「games」: 8, 「Mary」: 9, 「too」: 10}
則詞向量表示爲:
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- 缺點:維度大;詞與詞之間是孤立的,無法表示詞與詞之間的語意資訊!
2.2、詞帶模型之 (Bag of Words)
1)文件的向量表示可以直接將各詞的詞向量表示加和
John likes to watch movies. Mary likes too. => [1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2)計算詞權重 TF-IDF
IDF計算需要考慮到所有的文件,計算逆詞頻數
這種一般也可以統計ngram的tf-idf
2.3、詞的分佈式表示
分佈式表示 主要分爲三類:基於矩陣的分佈式表示、基於聚類的分佈式表示、基於神經網路的分佈式表示。這三種方法使用了不同的技術手段,但是它們都是基於分佈假說,核心思想也都由兩部分組成:一是選擇一種方式描述上下文,二是選擇一種模型刻畫目標詞與上下文之間的關係。
2.3.1 基於矩陣的分佈式表示
基於矩陣的分佈表示主要是構建「詞-上下文」矩陣,通過某種技術從該矩陣中獲取詞的分佈表示。矩陣的行表示詞,列表示上下文,每個元素表示某個詞和上下文共現的次數,這樣矩陣的一行就描述了改詞的上下文分佈。
常見的上下文有:(1)文件,即「詞-文件」矩陣;(2)上下文的每個詞,即「詞-詞」矩陣;(3)n-元詞組,即「詞-n-元組」矩陣。矩陣中的每個元素爲詞和上下文共現的次數,通常會利用TF-IDF、取對數等技巧進行加權和平滑。另外,矩陣的維度較高並且非常稀疏,可以通過SVD、NMF等手段進行分解降維,變爲低維稠密矩陣。
eg:

這是一個矩陣,這裏的一行表示一個詞在哪些title(文件)中出現了(詞向量表示),一列表示一個title中有哪些詞。比如說T1這個title中就有guide、investing、market、stock四個詞,各出現了一次,我們將這個矩陣進行SVD,得到下面 下麪的矩陣:

左奇異向量表示詞的一些特性,右奇異向量表示文件的一些特性,中間的奇異值矩陣表示左奇異向量的一行與右奇異向量的一列的重要程式,數位越大越重要。
將左奇異向量和右奇異向量都取後2維(之前是3維的矩陣),投影到一個平面上,可以得到(如果對左奇異向量和右奇異向量單獨投影的話也就代表相似的文件和相似的詞):
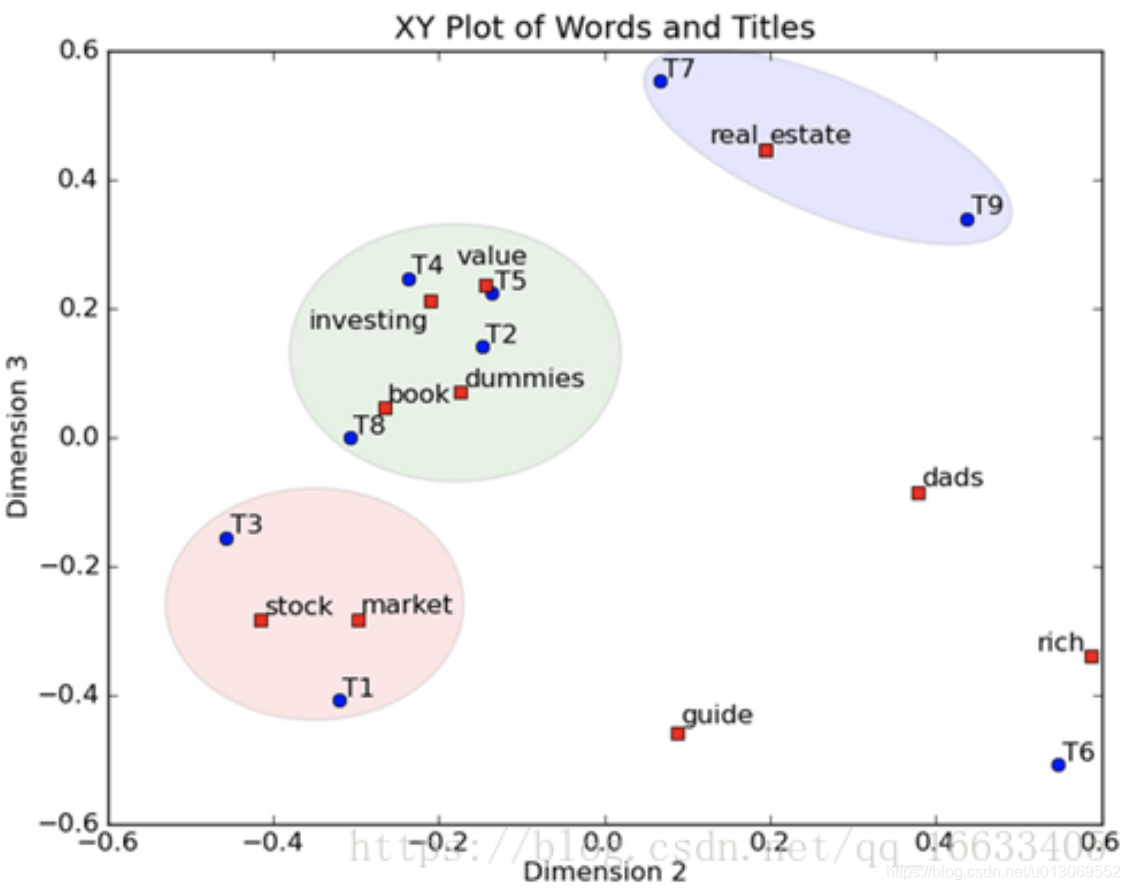
在圖上,每一個紅色的點,都表示一個詞,每一個藍色的點,都表示一篇文件,這樣我們可以對這些詞和文件進行聚類,比如說stock 和 market可以放在一類,因爲他們老是出現在一起,real和estate可以放在一類,dads,guide這種詞就看起來有點孤立了。按這樣聚類出現的效果,可以提取文件集閤中的近義詞,這樣當使用者檢索文件的時候,是用語意級別(近義詞集合)去檢索了,而不是之前的詞的級別。這樣一減少我們的檢索、儲存量,因爲這樣壓縮的文件集合和PCA是異曲同工的,二可以提高我們的使用者體驗,使用者輸入一個詞,我們可以在這個詞的近義詞的集閤中去找,這是傳統的索引無法做到的。
詳細的LSI演算法可以參考這篇部落格https://blog.csdn.net/qq_16633405/article/details/80577851
2.3.2 基於聚類的分佈式表示
這類方法通過聚類手段構建詞與其上下文之間的關係。布朗聚類(Brown clustering);目前看到的是可以將相似的詞聚到一個簇裏面,具體的詞向量表示,本人還沒太理解,有待探討。
布朗聚類原理詳細解釋可參考:https://zhuanlan.zhihu.com/p/158892642
https://blog.csdn.net/u014516670/article/details/50574147
2.4基於神經網路的分佈式表示
2.4.1、NNLM
Bengio 神經網路語言模型(Neural Network Language Model ,NNLM)是對 n 元語言模型進行建模,估算 P(wi|wn−i+1,...,wi−1) 的概率值。與n-gram等模型區別在於:NNLM不用記數的方法來估算 n 元條件概率,而是使用一個三層的神經網路模型(前饋神經網路),根據上下文的表示以及上下文與目標詞之間的關係進行建模求解,如下圖:

wt−1,...,wt−n+1 爲 wt 之前的 n−1 個詞,NNLM就是要根據這 n−1 個詞預測下一個詞 wt。C(w) 表示 w對應的詞向量,儲存在矩陣 C 中,C(w) 爲矩陣 C 中的一列,其中,矩陣 C 的大小爲 m∗|V|,|V| 爲語料庫中總詞數,m 爲詞向量的長度。
輸入層 x:將 n−1 個詞的對應的詞向量 C(wt−n+1),...,C(wt−1) 順序拼接組成長度爲 (n−1)∗m的列向量,用 x 表示,
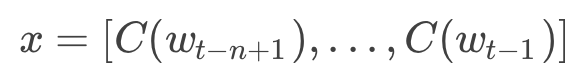
隱含層
h:使用 tanh 作爲激勵函數,輸出
![]()
![]() 爲輸入層到隱藏層的權重矩陣,d 爲偏置項(biases);
爲輸入層到隱藏層的權重矩陣,d 爲偏置項(biases);
輸出層
y:一共有 |V| 個節點,分量 y(wt=i) 爲上下文爲 wt−n+1,...,wt−1 的條件下,下一個詞爲 wt 的可能性,即上下文序列和目標詞之間的關係,而 yi 或者 y(wt) 是未歸一化 log 概率(unnormalized log-probabilities),其中,y 的計算爲:
![]()
,![]() 爲隱藏層到輸出層的權重矩陣,b爲偏置項,
爲隱藏層到輸出層的權重矩陣,b爲偏置項,![]() 爲輸入層到輸出層直連邊的權重矩陣,對輸入層到輸出層做一線性變換1。由於輸出層的各個元素yi之和不等於1,最後使用 softmax 啓用函數將輸出值 yi 進行歸一化,將 y 轉化爲對應的概率值:
爲輸入層到輸出層直連邊的權重矩陣,對輸入層到輸出層做一線性變換1。由於輸出層的各個元素yi之和不等於1,最後使用 softmax 啓用函數將輸出值 yi 進行歸一化,將 y 轉化爲對應的概率值:
![]()
訓練時使用梯度下降優化上述目標,每次訓練從語料庫中隨機選取一段序列wi−n+1,...,wi−1作爲輸入,利用如下方式進行迭代:
![]()
其中,α爲學習速率,θ=(b,d,W,U,H,C)。
該結構的學習中,各層的規模:
輸入層:n爲上下文詞數,一般不超過5,m爲詞向量維度,10~10^3;
隱含層:n_hidden,使用者指定,一般爲10^2量級;
輸出層:詞表大小V,10^4~10^5量級;
同時,也可以發現,該模型的計算主要集中在隱含層到輸出層 tanh 的計算以及輸出層 softmax 的計算。
參考部落格:https://blog.csdn.net/aspirinvagrant/article/details/52928361
https://zhuanlan.zhihu.com/p/46026058 (綜述)
https://blog.csdn.net/aspirinvagrant/article/details/52928361 (綜述 cbow和skip-gram繼續看着篇)
https://www.jianshu.com/p/2a1af0497bcc (RNNLM)
https://blog.csdn.net/u014203254/article/details/104428602 (另一篇詞向量綜述,word2vec解釋比較詳細)