唐詩視覺化專案
目錄
一、專案:唐詩視覺化
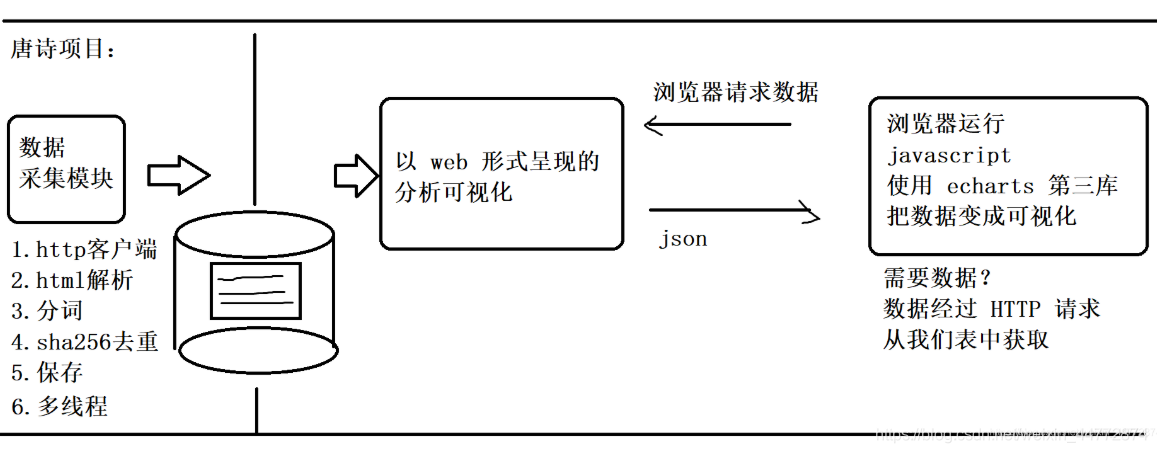
專案目的:爬取 古詩文網 唐詩三百首的內容,將爬取到的內容儲存到數據庫當中,並對數據進行處理分析等,最終將其以圖表等形式展示出來的一個 JavaWeb 專案,目的是使使用者能更直觀快速的去瞭解古代唐詩。
專案分爲兩個模組:詩詞爬取模組 和 數據視覺化模組。

專案核心技術:
- JDBC(數據庫操作)
- 唐詩數據儲存至數據庫 。
- 頁面展示時提取數據庫資訊。
- Servlet 的使用
- HTTP 協定
- HtmlUtil、ansj_seg 第三方庫的使用
- sha-256 演算法
- 多執行緒技術
- jQuery 前後端互動(進行非同步來提交更新數據)
- 軟體測試的基本策略和方法
專案設計:
1、獲取數據
- 存取列表頁(唐詩三百首大全)來獲取頁面中唐詩數據;
- 編寫程式模擬用戶端向瀏覽器構建 Http 請求獲取 Html 頁面數據;
- 將獲取到的列表頁 html 數據,儲存在 列表頁.html 中。
2、分析數據和整理數據
- 觀察 列表頁.xml 中的表單,提取每首唐詩頁面的子路徑 ,儲存至 LinkedList 中;
- 根據每首詩的 url ,獲取每首的詳情頁(詩詞頁)頁面數據,將頁面中詩的作者、標題、朝代、詩詞正文等提取出來;
- 計算 sha256(標題+正文),保證數據不重複;
- 呼叫分詞的第三方庫,對內容進行分詞;
- 將數據儲存至數據庫中。
3、提取數據庫中的資訊選擇合適的圖形介面來展示。
- 唐朝的各個詩人的作詩量(柱狀圖);
- 詩人們使用最頻繁的詞語(詞雲)。
二、技術選型
1、Maven 來進行專案管理
Maven 就是專門爲 Java 專案打造的管理和構建工具,它的主要功能有:
- 提供了一套標準化的專案結構;
- 提供了一套標準化的構建流程(編譯,測試,打包,發佈……);
- 提供了一套依賴管理機制 機製。
一個使用Maven管理的普通的Java專案,它的目錄結構預設如下:
專案的根目錄
a-maven-project是專案名,它有一個專案描述檔案
pom.xml,存放Java原始碼的目錄是src/main/java,存放資原始檔的目錄是src/main/resources,存放測試原始碼的目錄是src/test/java,存放測試資源的目錄是src/test/resources,最後,所有編譯、打包生成的檔案都放在target目錄裡。

2、Java 語言操作數據庫(JDBC)
在 pom.xml 中加入相應依賴:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
3、列表頁和詳情頁的請求解析(HtmlUtil)
HtmlUtil 是一款開源的 java 頁面分析工具,讀取頁面後,可以有效的使用HtmlUtil 分析頁面上的內容,專案可以模擬瀏覽器執行(一個沒有介面的瀏覽器),被譽爲 java 瀏覽器的開源實現,同時它的執行速度迅速。
在這裏,我們利用 HtmlUtil 第三方庫中的相應方法,來進行一個 Html 頁面的請求和解析工作。
在 pom.xml 中加入相應依賴:
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.36.0</version>
</dependency>
通過 HtmlUnit 庫,我們可以很方便的載入一個完整的 Html 頁面而且可以很輕易的模擬各種瀏覽器,發起對一個網頁的請求,並獲得相應的頁面元素 HtmlPage .
總結:HtmlUnit 說白了就是一個瀏覽器,這個瀏覽器是用 Java 寫的無介面的瀏覽器,正因爲其沒有介面,因此它執行的速度很快,HtmlUnit 還提供了一系列的 API,這些 API 可以提供的功能比較多,如表單的填充,表單的提交,模仿點選鏈接等等,由於它還內建了 Rhinojs 引擎,因此可以執行Javascript 程式碼。
4、分詞功能(ansj_seg)
展示頁面涉及到了根據每一個詞的出現頻率來進行詞圖的展示。這裏根據每一首詩的標題和內容來進行分詞。我們採用第三方類庫 ansj_seg 來完成分詞功能。
在 pom.xml 中加入相應依賴:
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
5、前端頁面展示渲染工具(echarts:enterprise charts,商業級數據圖表)
做一個視覺化專案:調研有哪些成熟的視覺化第三方類庫可以使用 echarts
echarts 它是一個開源免費的 javascript 視覺化庫,本專案中前端頁面展示中用到的柱狀圖和雲圖皆來源於它。
選擇第三方庫 echarts 的原因:
- 開源免費
- 使用簡單,在官網爲我們封裝了js,只要會參照就會得到完美的展示效果(可以直接在其網站上進行偵錯,得到自己想要的效果,然後進行下載)
- 功能豐富,種類繁多
6、前後端互動技術(jQuery)
利用 $.ajax() 發起一個 HTTP 請求,進行前後端數據的互動。
7、響應字串(fastjson)
控制自己編寫的每一個 Servlet 類實現的方法中的每一個返回值(響應數據)都是 JSON 格式的字串。
在 pom.xml 中加入相應依賴:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
三、數據庫表的設計
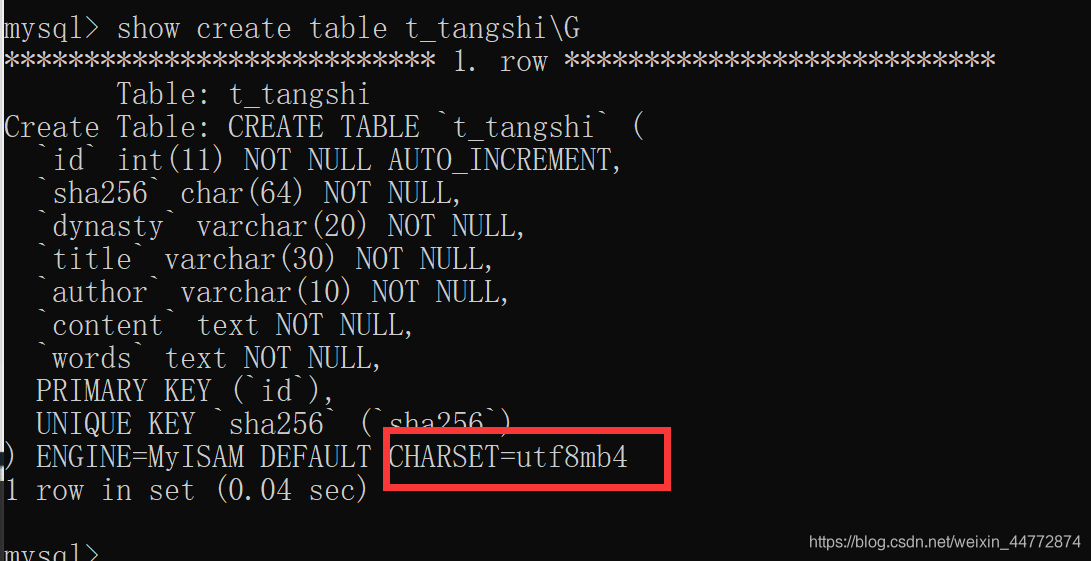
1、建表
CREATE DATABASE tangshi CHARSET utf8mb4;
use tangshi;
CREATE TABLE t_tangshi(
id INT PRIMARY KEY AUTO_INCREMENT,
sha256 CHAR(64) NOT NULL UNIQUE,
dynasty VARCHAR(20) NOT NULL,
title VARCHAR(30) NOT NULL,
author VARCHAR(10) NOT NULL,
content TEXT NOT NULL,
words TEXT NOT NULL
);
爲什麼要引入 sha-256 ?
使用 sha256 ,爲每首詩生成一個唯一識別符號,可以(標題 +正文)來計算 sha-256 的值,保證同一首詩不會被重複插入。
檢視字元編碼: 
四、選型技術的簡單使用Demo(預研階段)
1、使用 HtmlUtil 抓取網頁
步驟:
- 定義一個 WebClient 用戶端,就相當於定義了一個沒有介面的瀏覽器;
- 使用 WebClient 用戶端從指定 URL 獲取 HtmlPage,HtmlPage 中包含目標 URL頁面中的所有元素;
- 從 Htmlpage 中獲取我們需要的指定元素。
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class HtmlUtil {
public static void main(String[] args) throws IOException {
// 無介面的瀏覽器(Http用戶端)
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 關閉了瀏覽器的js執行引擎,不再執行網頁中的js指令碼
webClient.getOptions().setJavaScriptEnabled(false);
// 關閉了瀏覽器的css;執行引擎,不再執行網頁中的css佈局
webClient.getOptions().setCssEnabled(false);
// 請求列表頁
HtmlPage page=webClient.getPage("https://www.gushiwen.org/gushi/tangshi.aspx");
System.out.println(page);
// 儲存到指定路徑
File file=new File("唐詩三百首\\列表頁.html");
file.delete();
page.save(new File("唐詩三百首\\列表頁.html"));
// 如何從 html 中提取我們需要的元素
// 1、獲取 html 檔案中的 body 標籤中的內容
HtmlElement body=page.getBody();
// 2、在 body 標籤中的內容當中,獲取 div 標籤中 class 屬性值爲 typecont 的元素
List<HtmlElement> elements=body.getElementsByAttribute(
"div",
"class",
"typecont"
);
for(HtmlElement element:elements){
System.out.println(element);
}
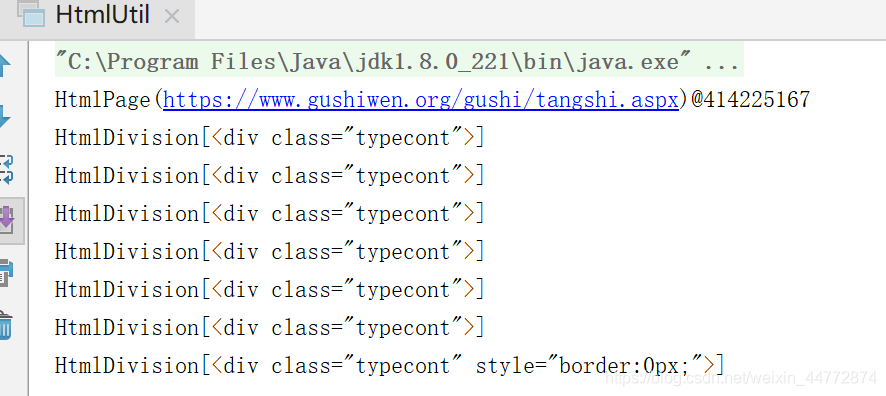
/*
列印結果:(獲取到了各個模組)
HtmlPage(https://www.gushiwen.org/gushi/tangshi.aspx)@414225167
HtmlDivision[<div class="typecont">] // 五言絕句
HtmlDivision[<div class="typecont">] // 七言絕句
HtmlDivision[<div class="typecont">] // 五言律詩
HtmlDivision[<div class="typecont">] // 七言律詩
HtmlDivision[<div class="typecont">] // 五言古詩
HtmlDivision[<div class="typecont">] // 七言古詩
HtmlDivision[<div class="typecont" style="border:0px;">] // 樂府
*/
System.out.println("-----------------------------------------------------");
// 取第一個模組——> 五言絕句
HtmlElement divElement=elements.get(0);
// 獲取 五言絕句 模組中的各首詩
List<HtmlElement> aElements=divElement.getElementsByAttribute(
"a",
"target",
"_blank"
);
for (HtmlElement element:aElements){
System.out.println(element);
}
System.out.println(aElements.size());
System.out.println(aElements.get(0).getAttribute("href"));
}
}
// 獲取各個模組
HtmlElement body=page.getBody();
List<HtmlElement> elements=body.getElementsByAttribute(
"div",
"class",
"typecont"
);for(HtmlElement element:elements){
System.out.println(element);
}
列表頁:
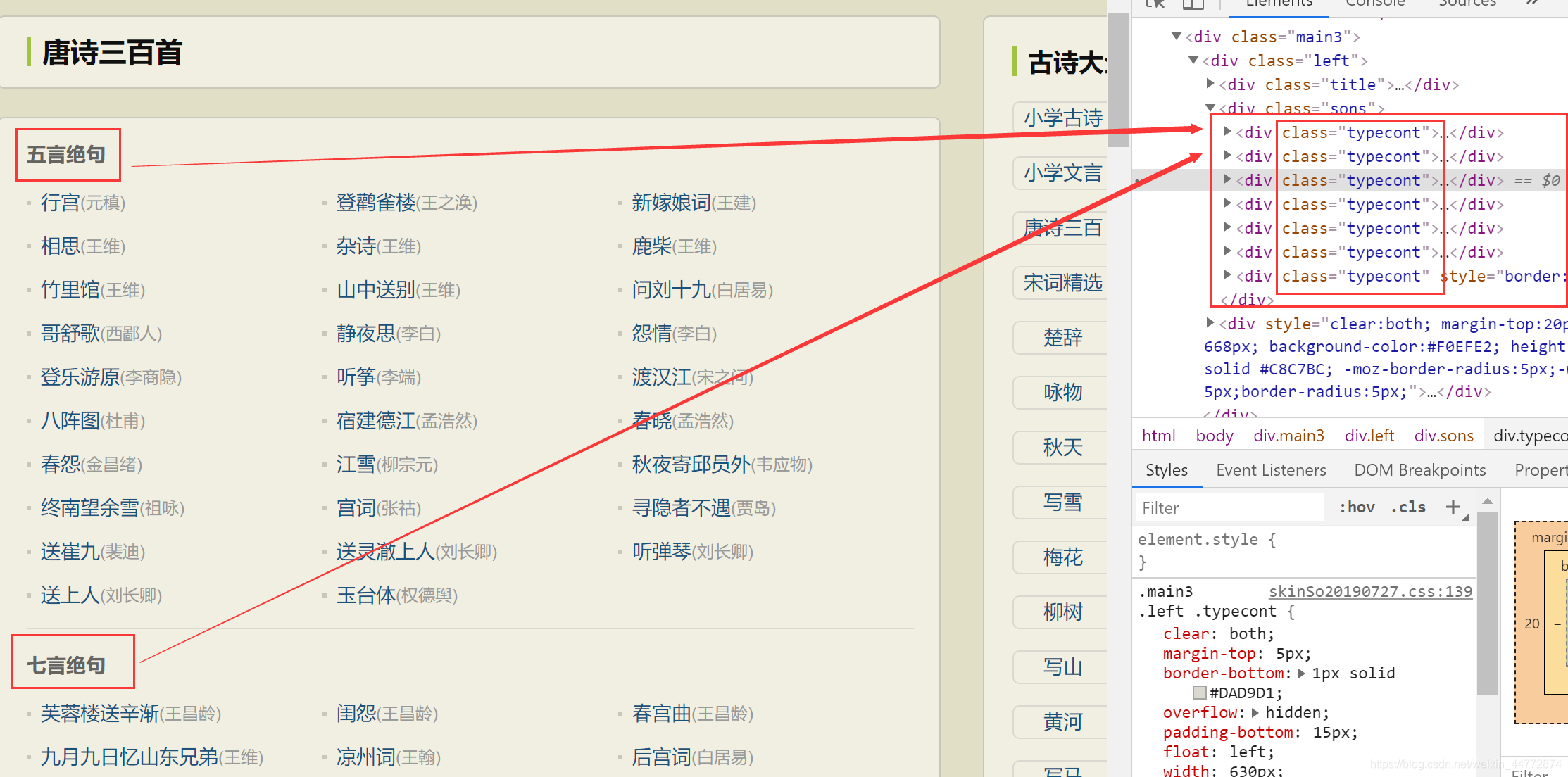
// 取第一個模組——> 五言絕句
HtmlElement divElement=elements.get(0);
// 獲取 五言絕句 模組中的各首詩
List<HtmlElement> aElements=divElement.getElementsByAttribute(
"a",
"target",
"_blank"
);
for (HtmlElement element:aElements){
System.out.println(element);
}


System.out.println(aElements.size());
System.out.println(aElements.get(0).getAttribute("href")); // 第一個模組的第一首詩的鏈接

2、詳情頁+詩集數據獲取
詳情頁:

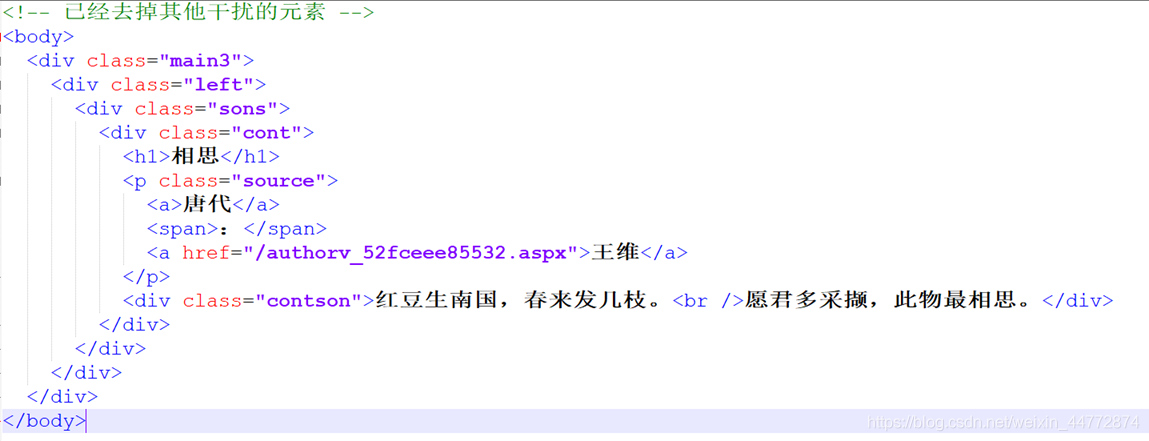
XPath:
標題:」//div[@class=‘cont’]/h1/text()」 // 表示獲取 div 標籤中 class 爲 cont 的標籤其下面 下麪的h1標籤的內容。
朝代:」//div[@class=‘cont’]/p[@class=‘source’]/[1]/a[1]/text()」 //a[1] 表示該路徑下不止一個a標籤此處取第一個 a 標籤,a[1]/text() 表示獲取第一個標籤的內容。
作者:」//div[@class=‘cont’]/p[@class=‘source’]/[1]/a[2]/text()」
正文:」//div[@class=‘cont’]/div[@class=‘contson’]」.getTextContent()
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomText;
import com.gargoylesoftware.htmlunit.html.Html;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.IOException;
public class 詳情頁下載提取Demo {
public static void main(String[] args) throws IOException {
try(WebClient webClient=new WebClient(BrowserVersion.CHROME)){
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
String url="https://so.gushiwen.org/shiwenv_45c396367f59.aspx";
HtmlPage page=webClient.getPage(url);
HtmlElement body=page.getBody();
//標題
{
String xpath="//div[@class='cont']/h1/text()";
// 表示獲取 div 標籤中 class 爲 cont 的標籤其下面 下麪的h1標籤的內容。這是通過XPath路徑獲取資訊,更爲方便。
Object o=body.getByXPath(xpath).get(0);
DomText domtext=(DomText)o;
// DomText 爲節點物件,asText() 爲獲取內容的文字形式。
System.out.println(domtext.asText());
}
//朝代
{
String xpath="//div[@class='cont']/p[@class='source']/a[1]/text()";
// a[1] 表示該路徑下不止一個a標籤此處取第一個 a 標籤,a[1]/text() 表示獲取第一個標籤的內容。
Object o=body.getByXPath(xpath).get(0);
DomText domtext=(DomText)o;
System.out.println(domtext.asText());
}
//作者
{
String xpath="//div[@class='cont']/p[@class='source']/a[2]/text()";
Object o=body.getByXPath(xpath).get(0);
DomText domtext=(DomText)o;
System.out.println(domtext.asText());
}
//正文
{
String xpath="//div[@class='cont']/div[@class='contson']";
Object o=body.getByXPath(xpath).get(0);
HtmlElement element=(HtmlElement)o;
System.out.println(element.getTextContent().trim());
}
}
}
}
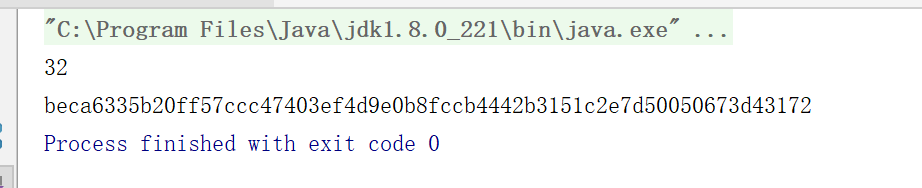
3、計算 SHA256 的值
SHA256,基於雜湊的加密方法, SHA即安全雜湊演算法(Secure Hash Algorithm), 256指的是雜湊值的位數,即256bit。SHA256的特性在於,相同的輸入資訊通過SHA256的輸出值是唯一的,當用SHA256加密的資訊中有修改時,即使是很小的修改,得到的結果也會完全不同。
MD5演算法的不足:現在看來,MD5已經較老,雜湊長度通常爲128位元,隨着計算機運算能力提高,找到「碰撞」是可能的。因此,在安全要求高的場合不使用MD5。
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class 求SHA256Demo {
public static void main(String[] args) throws NoSuchAlgorithmException, UnsupportedEncodingException {
MessageDigest messageDigest=MessageDigest.getInstance("SHA-256");
String s="你好世界";
byte[] bytes=s.getBytes("UTF-8");
messageDigest.update(bytes);
byte[] result=messageDigest.digest();
System.out.println(result.length);
for(byte b:result){
System.out.printf("%02x",b);
}
}
}
該MessageDigest類爲應用程式提供訊息摘要演算法的功能,如SHA-1或SHA-256。 訊息摘要是採用任意大小的數據並輸出固定長度雜湊值的安全單向雜湊函數。
MessageDigest物件開始初始化。 數據通過它使用update方法進行處理。 在任何時候可以呼叫reset來重置摘要。 一旦要更新的所有數據都被更新,則應呼叫其中一個digest方法來完成雜湊計算。
對於給定數量的更新,可以呼叫digest方法一次。 在digest之後,將MessageDigest物件重置爲初始化狀態。
4、計算分詞 分詞詞性標註規範
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.NlpAnalysis;
import java.util.List;
public class 分詞Demo {
public static void main(String[] args) {
String sentence="忽如一夜春風來,千樹萬樹梨花開。";
// 呼叫靜態方法將要解析的字串傳入並呼叫 getTerms() 方法返回一個 Term 的集合(一個 Term 就是一個單詞)
List<Term> termList=NlpAnalysis.parse(sentence).getTerms();
for(Term term:termList){
System.out.println(term.getNatureStr()+":"+term.getRealName());
}
}
}

5、將數據插入數據庫
import com.mysql.jdbc.jdbc2.optional.MysqlConnectionPoolDataSource;
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
import javax.activation.DataSource;
import java.sql.*;
public class 插入詩詞Demo {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
String 朝代="唐代";
String 作者="白居易";
String 標題="問劉十九";
String 正文="綠蟻新醅酒,紅泥小火爐。晚來天欲雪,能飲一杯無?";
/*
獲取 Connection的第一種方法
// 1、註冊 Driver
Class.forName("com.mysql.jdbc.Driver");
// 2、通過 DriverManger 獲取 Connection
String url="jdbc:mysql://175.24.50.87/tangshi?useSSL=false&characterEncoding=uft8";
Connection connection=DriverManager.getConnection(
url,
"root",
"maymay0722may"
);
System.out.println(connection);
Statement statement=connection.createStatement();
String sql="insert into tangshi(sha256,dynasty,author,content,words) values()";
statement.executeUpdate(sql);
*/
/*
獲取 Connection 的第二種方法
通過 DataSource 獲取 Connection
*/
Class.forName("com.mysql.jdbc.Driver");
//DataSource dataSource= (DataSource) new MysqlDataSource(); 不帶有連線池
MysqlConnectionPoolDataSource dataSource=new MysqlConnectionPoolDataSource(); //帶有連線池(有利於管理)
dataSource.setServerName("175.24.50.87");
dataSource.setPort(22);
dataSource.setUser("root");
dataSource.setPassword("maymay0722may");
dataSource.setDatabaseName("tangshi");
dataSource.setUseSSL(false);
dataSource.setCharacterEncoding("UTF-8");
try(Connection connection=dataSource.getConnection()){ //拿到連線
String sql="insert into tangshi(sha256,dynasty,author,title,content,words) values(?,?,?,?,?,?)";// 佔位符
try(PreparedStatement statement=connection.prepareStatement(sql)){
statement.setString(1,"sha256");
statement.setString(2,朝代);
statement.setString(3,作者);
statement.setString(4,朝代);
statement.setString(5,朝代);
statement.setString(6,朝代);
statement.executeUpdate(); //插入
}
}
}
}
五、實現思路
唐詩爬取模組:
1、請求和解析列表頁
- 列表頁中包含了每個詳情頁的後半部分 url
2、請求和解析詳情頁
- 進入到詳情頁頁面可以獲取詩詞的相關資訊(標題,作者,朝代,內容等資訊),這裏採用 XPath 來獲取這些資訊。
XPath的簡單介紹:

3、計算 sha-256 的值,目的是爲了使數據庫中不儲存同一首詩,不同詩的 sha-256 的值不同(利用標題+內容計算每一首詩的 sha-256的值)
4、計算分詞(只選取標題和正文的內容來進行分詞,並且長度小於 1 的詞不算,標點符號也不算一個詞,爲 null 也不算一個分詞)。由於分詞之後的詞有可能會重複情況發生,所以要進行統計,儲存的時候就是以 key-value 格式儲存到 Map 集合當中去的。( key是詞,value是詞頻 )
5、所有數據就緒完畢,將數據插入到數據庫
6、回圈執行序號 2-6 的操作,直至所有的古詩都已經全部插入到數據庫
數據視覺化模組:
1、編寫兩個 Servlet ,一個是 RankServlet(用來從數據庫中獲取作者和作者相對應的詩詞數量),一個是 WordsServlet (用來從數據庫中獲取每一首詩的分詞情況)兩個 Servlet 的響應內容都爲 JSON 格式的字串。
2、通過 $.ajax() 發起一個 HTTP 請求,從伺服器後端獲取相應數據,用來填充 echarts 圖表中的相關內容
3、提取數據庫中的資訊選擇合適的圖形介面來展示
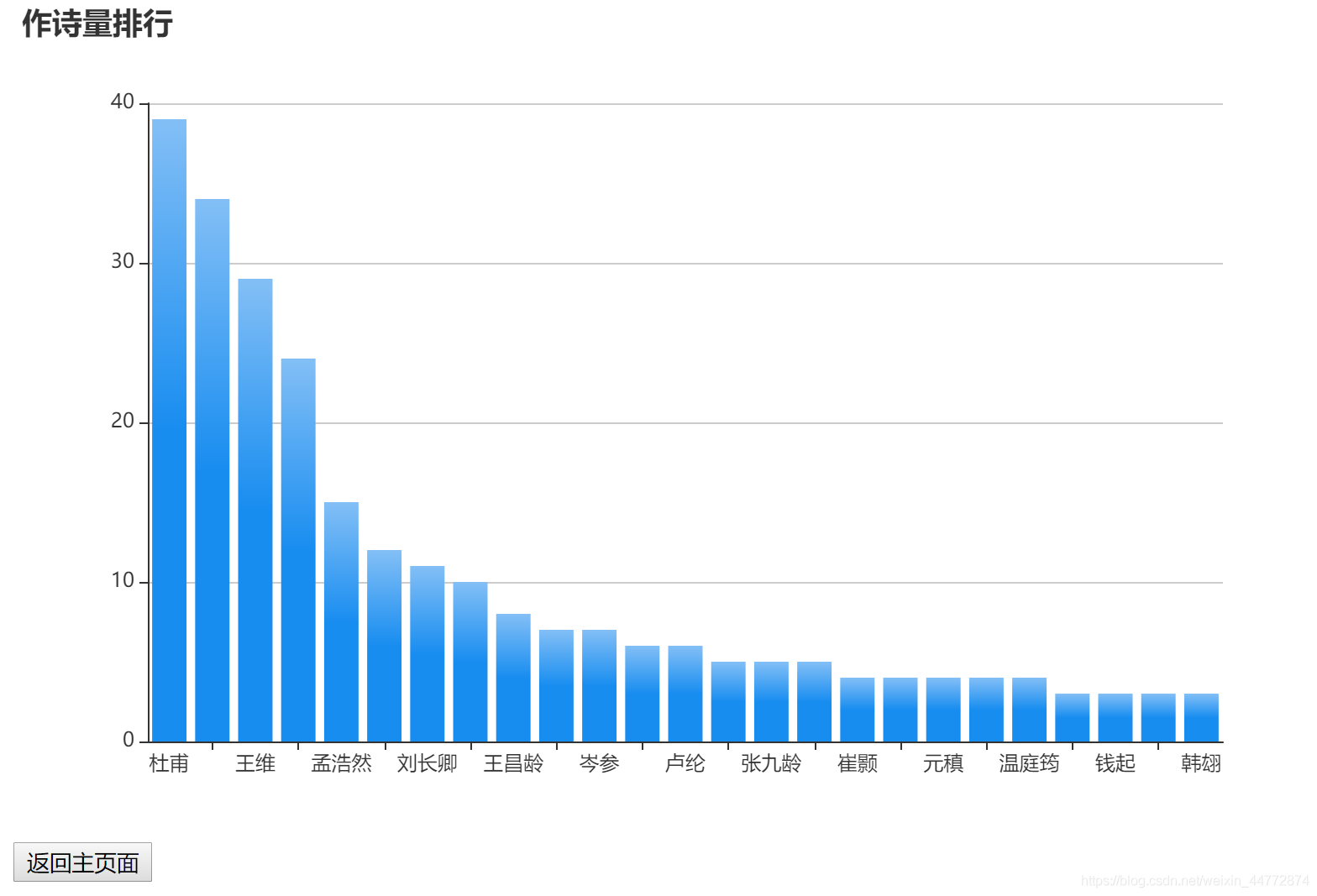
- 各個詩人以及其對應的詩詞創作數量(柱狀圖);
- 根據詞的出現頻率展示圖片(雲圖)。
六、唐詩爬取模組實現
單執行緒版本:
所有內容全部由主執行緒完成,無執行緒安全問題,但是速度最慢。
多執行緒版本:
列表頁的請求和解析主執行緒去做,詳情頁的請求和解析交給執行緒去做,目的是爲了提高效率。
速度增加,列表頁的請求和解析整個專案只執行一次,所以放在主執行緒中去做;
而詳情頁的請求和解析需要執行320次,在多執行緒中去做,同理提取詩詞資訊(標題,作者,內容)、計算 sha256 的值、計算分詞、資訊插入數據庫等步驟放到多執行緒中去做。

(1)多執行緒出現的問題:
WebClient,Connection,PreparedStatement ,生成SHA-256的MessageDigest 都不是執行緒安全的,加鎖的話達不到高效率的目的。
(2)解決方案:
讓上述這些物件在每一個執行緒中都有一個自己的物件,這樣就不會出現執行緒安全問題了。
執行緒池:
採用 Executors.newFixedThreadPool(int) 方式建立一個固定大小的的執行緒池
(1)出現問題:
執行緒池可以減少執行緒建立和銷燬的次數,但執行緒池中的執行緒不能自己停止,就算所有詩詞已經全部放入數據庫也不會停止。
(2)出現原因:
因爲 JVM 在所有的非後臺執行緒都結束後纔會結束,而執行緒池中的執行緒是永遠不會停止的(每個執行緒執行完任務後,自己又返回到執行緒池當中)那麼JVM 就不會停止。
(3)解決方法:
用CountDownLatch:在主執行緒中呼叫countDownLatch,待所有的詩都成功上傳到數據庫當中時,顯示呼叫 pool.shutdown(); 方法即可讓程式停止執行。
改進執行緒池的版本:
法一:通過 CountDownLatch
在主執行緒中建立物件 countDownLatch,並作爲參數傳給執行緒:
CountDownLatch countDownLatch=new CountDownLatch(detailUrlList.size()); //傳入的參數是詩的個數( 320 )
在每個執行緒任務結束的時候,加入程式碼:
countDownLatch.countDown(); //個數減1(最初該物件裏面的屬性值爲 320)
最後在主執行緒中加入:
countDownLatch.await(); //等待 320 首詩都上傳到數據庫(一直等到 countDownLatch 物件裏面的屬性值爲 0)
pool.shutdown(); //關閉執行緒池
法二:通過 Atomic 原子類
在類中定義變數:
private static AtomicInteger successCount=new AtomicInteger(0); //原子類
private static AtomicInteger failureCount=new AtomicInteger(0); //原子類
在每個執行緒(成功插入時)加入程式碼:
while(successCount.get()+failureCount.get()<detailUrlList.size()){
System.out.printf("一共 % 首詩,成功 %d,失敗 %d,%d\r",
detailUrlList.size(),successCount.get(),failureCount.get());
TimeUnit.SECONDS.sleep(1); // 1秒列印一次
}
System.out.println();
System.out.println("全部下載成功");
pool.shutdown();
七、數據視覺化模組實現
使用技術:Servlet,JSON,jQuery,ajax ,echarts
提供一個介面給前端處理作者作詩數的統計
RankServlet 處理作者作詩數:
@WebServlet("/rank")
public class RankServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("application/json; charset=utf-8");
String condition = req.getParameter("condition");
if (condition == null) {
condition = "3";
}
JSONArray jsonArray = new JSONArray();
try (Connection connection = DBUtil.getConnection()) {
String sql = "SELECT author, count(*) AS cnt FROM t_tangshi GROUP BY author HAVING cnt >= ? ORDER BY cnt DESC";
try (PreparedStatement statement = connection.prepareStatement(sql)) {
statement.setString(1, condition);
try (ResultSet rs = statement.executeQuery()) {
while (rs.next()) {
String author = rs.getString("author");
int count = rs.getInt("cnt");
JSONArray item = new JSONArray();
item.add(author);
item.add(count);
jsonArray.add(item);
}
resp.getWriter().println(jsonArray.toJSONString());
}
}
} catch (SQLException e) {
e.printStackTrace();
JSONObject object = new JSONObject();
object.put("error", e.getMessage());
resp.getWriter().println(object.toJSONString());
}
}
}
WordServlet提供給前端處理用詞統計:
@WebServlet("/words")
public class WordsServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("application/json; charset=utf-8");
JSONArray jsonArray = new JSONArray();
Map<String,Integer> map = new TreeMap<>();
try (Connection connection = DBUtil.getConnection()) {
String sql = "SELECT words FROM t_tangshi";
try (PreparedStatement statement = connection.prepareStatement(sql)) {
try (ResultSet rs = statement.executeQuery()) {
while (rs.next()) {
String words = rs.getString("words");
String word[] = words.split(",");
for (int i = 0;i < word.length;i++){
if (!map.containsKey(word[i])){
map.put(word[i],1);
}else {
map.put(word[i], map.get(word[i]) + 1);
}
}
}
for (Map.Entry<String,Integer> entry : map.entrySet()){
JSONArray item = new JSONArray();
item.add(entry.getKey());
item.add(entry.getValue());
jsonArray.add(item);
}
resp.getWriter().write(jsonArray.toJSONString());
}
}
} catch (SQLException e) {
e.printStackTrace();
JSONObject object = new JSONObject();
object.put("error", e.getMessage());
resp.getWriter().println(object.toJSONString());
}
}
}
index.html 新增下載的 js 檔案:
<script src="js/jquery-3.3.1.min.js"></script>
<script src="js/echarts.min.js"></script>
<script src="js/echarts-gl.min.js"></script>
<script src="js/echarts-wordcloud.min.js"></script>
編寫 ajax_and_echarts.js:
利用$.ajax()發起一個HTTP請求,後臺收到請求時返回給前端一個index.html檔案,這個檔案裏面的Script標籤又會主動向後臺發送http請求,得到json格式的數據,js中的程式碼把數據寫到echart中,頁面就展示出來了也引入第三方庫,js請求交給相對應的servlet去處理(創作數量排行榜用RankServlet()去處理,詩詞用詞雲圖用wordServlet()去處理)
$.ajax(
{
method: "get", // 發起 ajax 請求時,使用什麼 http 方法
url: "rank?condition=3", // 請求哪個 url
dataType: "json", // 返回的數據當成什麼格式解析
success: function (data) { // 成功後,執行什麼方法
var names = [];
var counts = [];
for (var i in data) {
names.push(data[i][0]);
counts.push(data[i][1]);
}
console.log(names);
console.log(counts);
var myChart = echarts.init(document.getElementById('main'));
var option = {
// 圖示的標題
title: {
text: '作詩量排行'
},
tooltip: {},
legend: {
data:['銷量']
},
// 橫座標
xAxis: {
data: names
},
yAxis: {},
series: [
{
name: '作詩數',
type: 'bar', // bar 代表柱狀圖
itemStyle: {
color: new echarts.graphic.LinearGradient(
0, 0, 0, 1,
[
{offset: 0, color: '#83bff6'},
{offset: 0.5, color: '#188df0'},
{offset: 1, color: '#188df0'}
]
)
},
emphasis: {
itemStyle: {
color: new echarts.graphic.LinearGradient(
0, 0, 0, 1,
[
{offset: 0, color: '#2378f7'},
{offset: 0.7, color: '#2378f7'},
{offset: 1, color: '#83bff6'}
]
)
}
},
data: counts
}
]
};
myChart.setOption(option);
}
}
);
八、實驗結果
index.html:
rank.html:
word.html:

九、專案測試

十、回味無窮