暑期實訓Python 第八天--分組 轉換 拼接
2020-08-12 22:43:57
分組
df = pd.DataFrame({
'Name':['BOSS','Jason','Jason','Han','BOSS','BOSS','Jason','BOSS'],
'Year':[2016,2016,2016,2016,2017,2017,2017,2017],
'Salary':[10000,2000,4000,5000,18000,25000,3000,4000],
'Bonus':[3000,1000,1000,1200,4000,2300,500,1000]
})
gb = df.groupby('Name')
按兩列 進行分組
df.groupby(["Name","Year"])
GroupBy 物件是可以迭代物件,所以可以用 for 回圈遍歷
for item in gb:
print(item)
聚合運算
單個聚合運算:
gb.sum()
Year Salary Bonus
Name
BOSS 8067 57000 10300
Han 2016 5000 1200
Jason 6049 9000 2500
gb.mean()
Year Salary Bonus
Name
BOSS 2016.750000 14250.0 2575.000000
Han 2016.000000 5000.0 1200.000000
Jason 2016.333333 3000.0 833.333333
gb.agg("sum")
Year Salary Bonus
Name
BOSS 8067 57000 10300
Han 2016 5000 1200
Jason 6049 9000 2500
gb.agg("mean")
Year Salary Bonus
Name
BOSS 2016.750000 14250.0 2575.000000
Han 2016.000000 5000.0 1200.000000
Jason 2016.333333 3000.0 833.333333
多個聚合運算
gb.agg(['mean','sum'])
Year Salary Bonus
mean sum mean sum mean sum
Name
BOSS 2016.750000 8067 14250 57000 2575.000000 10300
Han 2016.000000 2016 5000 5000 1200.000000 1200
Jason 2016.333333 6049 3000 9000 833.333333 2500
gb.agg([np.sum, np.mean])
Year Salary Bonus
sum mean sum mean sum mean
Name
BOSS 8067 2016.750000 57000 14250 10300 2575.000000
Han 2016 2016.000000 5000 5000 1200 1200.000000
Jason 6049 2016.333333 9000 3000 2500 833.333333
每個列單獨指定聚合演算法
gb.agg({"Salary":np.mean,"Bonus":np.sum})
Salary Bonus
Name
BOSS 14250 10300
Han 5000 1200
Jason 3000 2500
也可以接受 lambda 表達式
gb.agg({"Salary":np.mean, "Bonus":lambda x:x/2+10}
transform 方法
對 dataframe 中每個元素,按指定規則進行對映
df.loc[:,"Bonus"].transform((lambda x:x/2+10))
0 1510.0
1 510.0
2 510.0
3 610.0
4 2010.0
5 1160.0
6 260.0
7 510.0
Name: Bonus, dtype: float64
apply 函數
apply 函數既可以進行聚合運算,也可以進行對映運算,相當於 agg 和 transform 兩個函數功能的集合
df.loc[:, "Year":"Bonus"].apply(lambda x: sum(x))
Year 16132
Salary 71000
Bonus 14000
dtype: int64
df.loc[:, "Year":"Bonus"].apply(lambda x: x / 2 + 10)
Year Salary Bonus
0 1018.0 5010.0 1510.0
1 1018.0 1010.0 510.0
2 1018.0 2010.0 510.0
3 1018.0 2510.0 610.0
4 1018.5 9010.0 2010.0
5 1018.5 12510.0 1160.0
6 1018.5 1510.0 260.0
7 1018.5 2010.0 510.0
filter 函數
過濾掉不滿足條件的組
通過列名進行篩選滿足條件的列出來
df.filter(items=['one', 'three']) # 篩選列表中指定的列
df.filter(regex='e$', axis=1) #篩選列名滿足正則表達式條件的列
df.filter(like='ear', axis=0) #篩選列名中包含ear的列
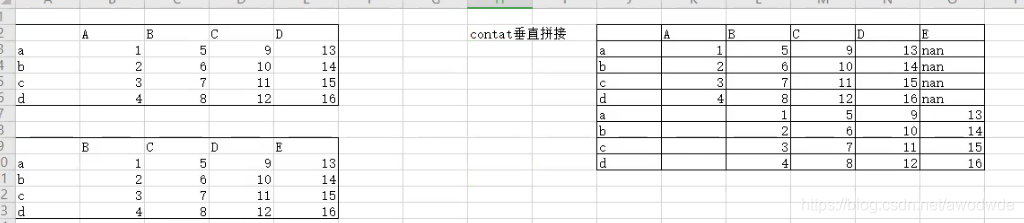
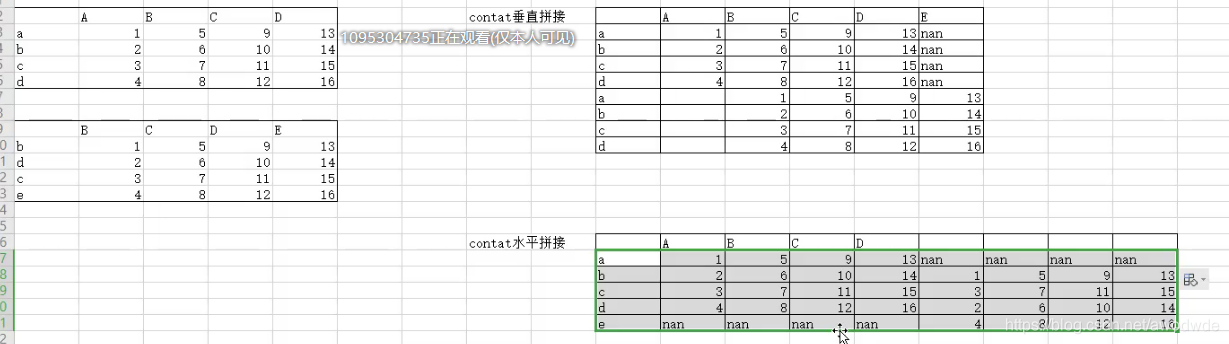
contat 拼接
pd.concat((df1, df2), axis=0) # 列對齊進行拼接,垂直拼接
pd.concat((df1, df2), axis=1) # 行對齊進行拼接,水平拼接
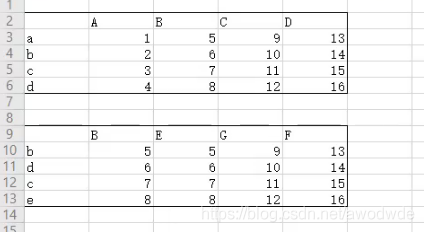
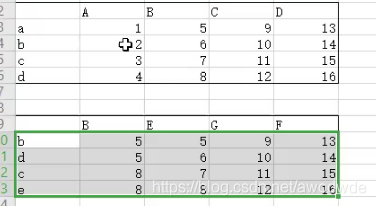
merge
df1 = pd.DataFrame(np.random.random((2, 3)), columns=['A', 'B', 'C'])
df2 = pd.DataFrame(np.random.random((2, 3)), columns=['B', 'C', 'D'])
df1.merge(df2, how="outer")
df1.merge(df2, how='inner')
df1.merge(df2, how='left')
df1.merge(df2, how='right')
一 對 一
一 對 多
pandas 數據視覺化
matplotlib
8.1 dataframe.plot() 折線圖,可以反應數據的變化趨勢
8.2 dataframe.plot.bar() 條形圖,可以方便對比不同列的數據的大小
dataframe.plot.bar(stacked=True) 堆疊條形圖,歸一化之後,可以非常方便對比不同列的佔比的大小
dataframe.T.plot.barh() 橫向的條形圖
8.3 dataframe.T.plot.hist() 直方圖,可以反應數據的分佈情況
8.3 dataframe.T.plot.hist() 直方圖,可以反應數據的分佈情況
8.4 dataframe.T.plot.box() 箱型圖,也可以從整體上比較概況反應數據的分佈情況,
# 可以在影象反應 異常值的情況、中位數、1/4分位數、3/4分位數、上下邊界
8.5 dataframe.T.plot.scatter() 散點圖,反應數據變化的相關性
8.6 Series.plot.pie() 餅狀圖,反應數據佔比情況