Python基礎語法筆記
2020-08-12 20:22:31
本文內容摘自《Python數據分析與挖掘實戰》。
目錄
1.1 賦值、運算、輸出
#1.基礎操作
a = 20 # 賦值運算
a * 1 # 數學四則運算
a ** 2 # 冪運算,即a^2,a*a
a, b, c = 2, 3, 4 # 支援多重賦值
print('Hello World!') # 列印Hello World!
1.2 if-else 條件判斷
# 條件判斷if
if 1 == 2: # 如果 if 跟隨的條件爲 假 那麼不執行屬於if 的語句,然後執行 elif 或者 else
print("假的")
elif :
pass
else: # 尋找到 else 之後 執行屬於else中的語句
print("1==2是假的")
# Python 一般不用花括號{},也不用end語句,而是使用縮排對齊作爲語句的層次標記。
# 同一層次的縮排量一定要一一對應,不然會報錯。
# 只能有一個if / else, elif可以有多個
# 如果條件判斷很多,if-else寫也很繁瑣,其實也可以用字典實現
test = {'2': 'a=2',
'3': 'a=3',
'4': 'a=4',
}
a = 2
print(test.get(a,'預設輸出')) # 如果a 的值在字典中不存在,則預設輸出None,也可以修改預設輸出(需要使用get函數)。
1.3 for / while 回圈操作
# 回圈操作---while
sum, n = 0
while n < 101: # 該回圈過程用於求和計算 1+2+3+...+100
n = n + 1
sum = sum + n
print(sum)
# 回圈操作---for
sum = 0
for i in range(101): # 該回圈過程用於求和計算 1+2+3+...+100
sum = sum + i
print(sum)
# 關鍵字 in 作用:判斷一個元素是否在列表/元組中存在。
# 關鍵字 range 作用:用來生成連續序列,
# 一般語法 range(a, b, c), 表示以 a 爲首相、c 爲公差且不超過 b-1 的等差數列。
s = 0
if s in range(4):
prinf("s 在[0,1,2,3]中")
if s not in range(1, 4, 1)
prinf("s 不在[1,2,3]中")
# break、continue
# break語句可以跳出 for 和 while 的回圈體
n = 1
while n <= 100:
if n > 10:
break
print(n)
n += 1
# continue語句跳過當前回圈,直接進行下一輪回圈
n = 1
while n < 10:
n = n + 1
if n % 2 == 0:
continue
print(n)
1.4 函數定義及呼叫
Python 函數一定會有返回值,如果沒有return,會返回None。
需要注意的是,Python 與一般程式語言不同的是,函數返回值可以使各種形式,比如返回列表,甚至返回多個值
# 函數定義及呼叫
def add(x):
return x+2
print(add(5)) # 輸出結果爲7
def add_2(x = 0, y = 0):
return [x+2, y+2]
def add_3(x, y):
return x+3, y+3
a, b = add_3(1, 2) # 此時 a=4, b=5
# 行內函數,又稱匿名函數、拉姆達函數
f = lambda x :x + 2 # 定義 f(x) = x + 2
g = lambda x, y :x + y # 定義 g(x, y) = x + y
1.5 列表和元組
# 數據結構---List(列表)
# 列表是寫在方括號 [] 之間、用逗號分隔開的元素列表。
# 列表元素可以是任何數據型別,
# 列表裏面可以套列表
# 列表索引值以 0 爲開始值,-1 爲從末尾的開始位置。
list = ['abcd', 786 , 2.23, 'runoob', 70.2]
print(list[1:3])
# 列表可以使用 + 操作符進行拼接。
tinylist = [123, 'runoob']
print(list + tinylist)
# 列表中的內容可以被修改
list[0] = 'hello' # 原來的值 abcd 被修改爲 hello
# 複製列表
# b = a # 錯誤,此乃參照,修改 b 的同時會修改 a
b = a[:] # 正確
# 數據結構---Tuple(元組)
# tuple與list類似,不同之處在於tuple的元素不能修改。tuple寫在小括號裡,元素之間用逗號隔開。
# 元組元素可以是任何數據型別,
# 元組裏面可以套元組
# 元組的元素不可變,但可以包含可變物件,如list。
t1 = ('abcd', 786 , 2.23, 'runoob', 70.2) # 此處是(),而列表是[]
# 注意:定義一個只有1個元素的tuple,必須加逗號。
t2 = (1, )
t3 = ('a', 'b', ['A', 'B']) # 元組的元素不可變,但可以包含可變物件,如list。
t3[2][0] = 'X' # ['A', 'B'] -> ['X', 'B']
print(t3) # ('a', 'b', ['X', 'B'])
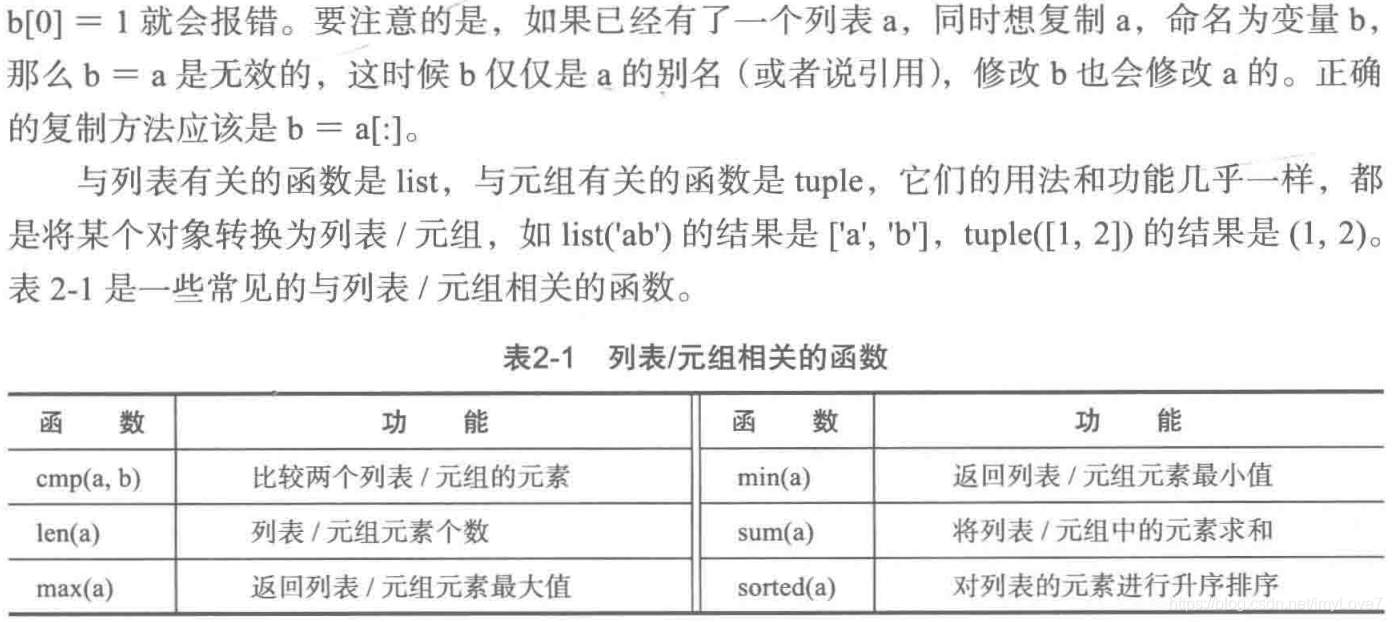



1.6 字串、元組、列表的操作
字串和元組不支援修改,即二次賦值。
#字串、元組、列表,讀取操作完全相同,拼接操作完全相同,可以相互轉換,都可以做切片操作,都可以通過下標讀取
str = '我是字串'
list = ['我', '是', '列','表']
list = ('我', '是', '元','組')
# 讀取
str[2]
list[2]
tuple[2]
# 拼接
str + str1
list + list2
tuple + tuple2
# 切片
str[1:4] #是字元,左包括,右不包括
list[1:3] #是列
tuple[1:3] #是元
str[1:] # 是字串,去掉了第一個元素(下標0),
str[:-1] # 我是字元,去掉了最後一個元素(下標-1),右邊不包括
str[-1:] # 串,取出最後一個元素
str[::-1] # 串符字是我,倒序輸出
str[::-2] # ------------------------------------這個不知道是什麼
str[:] # 複製一份,
# 原理:
# 當i預設時,預設爲0,即 a[:3]相當於 a[0:3]
# 當j預設時,預設爲len(alist), 即a[1:]相當於a[1:10]
# 當i,j都預設時,a[:]就相當於完整複製一份a
# b = a[i:j:s] # 表示:i,j與上面的一樣,但s表示步進,預設爲1.
# 所以a[i:j:1]相當於a[i:j]
# 當s<0時,i預設時,預設爲-1. j預設時,預設爲-len(a)-1
# 所以a[::-1]相當於 a[-1:-len(a)-1:-1],也就是從最後一個元素到第一個元素複製一遍,即倒序。
1.7 字典和集合
# 5.數據型別---dict(字典)
# 字典是無序的物件集合,使用鍵-值(key-value)儲存,具有極快的查詢速度。
# 鍵(key)必須使用不可變型別。
# 同一個字典中,鍵(key)必須是唯一的。
# 字典的建立和元素的存取
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
print(d['Michael'])

# list可以轉成字典,但前提是列表中元素都要成對出現
dict3 = dict([('name','楊超越'),('weight',45)])
print(dict3)
#字典裡的函數 items() keys() values()
dict5 = {'楊超越':165,'虞書欣':166,'上官喜愛':164}
print(dict5.items())
for key in dict5: #預設爲key(),列印的都是key值,
print(key)
for value in dict5.values(): # 列印value值
print(key)
for key,value in dict5.items(): # key 和 value 都列印
print(key, value)
#5.數據型別---set(集合)
#set和列表類似,區別是:1、set是無序的且不可重複,重複元素在set中自動被過濾。2、不支援索引。
s = {1, 1, 2, 3} # 1會自動去重,實際得到{1, 2, 3}
s = set([1, 1, 2, 2, 3, 3]) # set函數將列錶轉換成集合,自動去重,實際得到{1, 2, 3}
# set可以看成數學意義上的無序和無重複元素的集合,因此,兩個set可以做數學意義上的交集(&)、並集(|)、差集(-)等操作。

1.8 函數語言程式設計
1.8.1 lambda()
# 行內函數,又稱匿名函數、拉姆達函數
f = lambda x :x + 2 # 定義 f(x) = x + 2
g = lambda x, y :x + y # 定義 g(x, y) = x + y匿名函數
1.8.2 map()

有了列表解析,爲什麼還要有map函數呢?
其實列表解析,雖然程式碼簡短,但是本質上還是 for 命令,而Python的for命令效率不高,map函數不僅實現了相同的功能,而且效率高。
1.8.3 reduce()

1.8.4 filter()
