awk簡介
awk其名稱得自於它的創始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首個字母。實際上 AWK 的確擁有自己的語言: AWK 程式設計語言 , 三位建立者已將它正式定義爲「樣式掃描和處理語言」。它允許您建立簡短的程式,這些程式讀取輸入檔案、爲數據排序、處理數據、對輸入執行計算以及生成報表,還有無數其他的功能。
awk 是一種很棒的語言,它適合文字處理和報表生成,其語法較爲常見,借鑑了某些語言的一些精華,如 C 語言等。在 linux 系統日常處理工作中,發揮很重要的作用,掌握了 awk將會使你的工作變的高大上。 awk 是三劍客的老大,利劍出鞘,必會不同凡響。
使用方法
|
1
|
awk '{pattern + action}' {filenames}
|
儘管操作可能會很複雜,但語法總是這樣,其中 pattern 表示 AWK 在數據中查詢的內容,而 action 是在找到匹配內容時所執行的一系列命令。花括號({})不需要在程式中始終出現,但它們用於根據特定的模式對一系列指令進行分組。 pattern就是要表示的正則表達式,用斜槓括起來。
awk語言的最基本功能是在檔案或者字串中基於指定規則瀏覽和抽取資訊,awk抽取資訊後,才能 纔能進行其他文字操作。完整的awk指令碼通常用來格式化文字檔案中的資訊。
通常,awk是以檔案的一行爲處理單位的。awk每接收檔案的一行,然後執行相應的命令,來處理文字。
awk 的原理
通過一個簡短的命令,我們來了解其工作原理。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@Gin scripts]# awk '{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
.....................................................
[root@Gin scripts]# echo hhh|awk '{print "hello,world"}'
hello,world
[root@Gin scripts]# awk '{print "hiya"}' /etc/passwd
hiya
hiya
hiya
hiya
...............................................
|
你將會見到/etc/passwd 檔案的內容出現在眼前。現在,解釋 awk 做了些什麼。呼叫 awk時,我們指定/etc/passwd 作爲輸入檔案。執行 awk 時,它依次對/etc/passwd 中的每一行執行 print 命令。
所有輸出都發送到 stdout,所得到的結果與執行 cat /etc/passwd 完全相同。
現在,解釋{ print }程式碼塊。在 awk 中,花括號用於將幾塊程式碼組合到一起,這一點類似於 C 語言。在程式碼塊中只有一條 print 命令。在 awk 中,如果只出現 print 命令,那麼將列印當前行的全部內容。
再次說明, awk 對輸入檔案中的每一行都執行這個指令碼。

|
1
2
3
4
|
$ awk -F":" '{ print $1 }' /etc/passwd
$ awk -F":" '{ print $1 $3 }' /etc/passwd
$ awk -F":" '{ print $1 " " $3 }' /etc/passwd
$ awk -F":" '{ print "username: " $1 "\t\tuid:" $3" }' /etc/passwd
|
-F參數:指定分隔符,可指定一個或多個
print 後面做字串的拼接
下面 下麪通過幾範例來了解下awk的工作原理:
範例一:只檢視test.txt檔案(100行)內第20到第30行的內容(企業面試)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@Gin scripts]# awk '{if(NR>=20 && NR<=30) print $1}' test.txt
20
21
22
23
24
25
26
27
28
29
30
|
範例二:已知test.txt檔案內容爲:
|
1
2
|
[root@Gin scripts]# cat test.txt
I am Poe,my qq is 33794712
|
請從該檔案中過濾出'Poe'字串與33794712,最後輸出的結果爲:Poe 33794712
|
1
2
|
[root@Gin scripts]# awk -F '[ ,]+' '{print $3" "$7}' test.txt
Poe 33794712
|
BEGIN 和 END 模組
通常,對於每個輸入行, awk 都會執行每個指令碼程式碼塊一次。然而,在許多程式設計情況中,可能需要在 awk 開始處理輸入檔案中的文字之前執行初始化程式碼。對於這種情況, awk 允許您定義一個 BEGIN 塊。
因爲 awk 在開始處理輸入檔案之前會執行 BEGIN 塊,因此它是初始化 FS(欄位分隔符)變數、列印頁首或初始化其它在程式中以後會參照的全域性變數的極佳位置。
awk 還提供了另一個特殊塊,叫作 END 塊。 awk 在處理了輸入檔案中的所有行之後執行這個塊。通常, END 塊用於執行最終計算或列印應該出現在輸出流結尾的摘要資訊。
範例一:統計/etc/passwd的賬戶人數
|
1
2
3
4
|
[root@Gin scripts]# awk '{count++;print $0;} END{print "user count is ",count}' passwd
root:x:0:0:root:/root:/bin/bash
..............................................
user count is 27
|
count是自定義變數。之前的action{}裡都是隻有一個print,其實print只是一個語句,而action{}可以有多個語句,以;號隔開。這裏沒有初始化count,雖然預設是0,但是妥當的做法還是初始化爲0:
|
1
2
3
4
5
|
[root@Gin scripts]# awk 'BEGIN {count=0;print "[start] user count is ",count} {count=count+1;print $0} END{print "[end] user count is ",count}' passwd
[start] user count is 0
root:x:0:0:root:/root:/bin/bash
...................................................................
[end] user count is 27
|
範例二:統計某個資料夾下的檔案佔用的位元組數
|
1
2
|
[root@Gin scripts]# ll |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ",size}'
[end]size is 1489
|
如果以M爲單位顯示:
|
1
2
|
[root@Gin scripts]# ll |awk 'BEGIN{size=0;} {size=size+$5;} END{print "[end]size is ",size/1024/1024,"M"}'
[end]size is 0.00142002 M
|
awk運算子
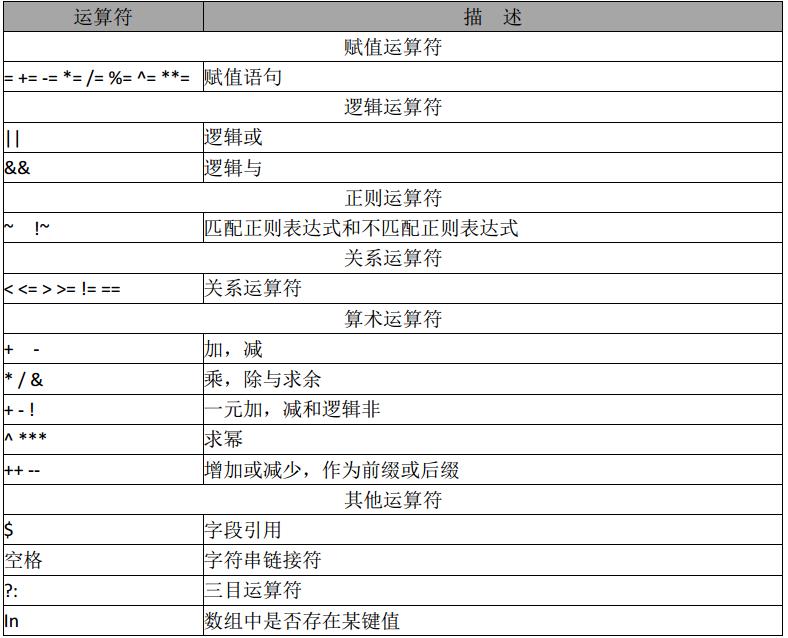
awk 賦值運算子:a+5;等價於: a=a+5;其他同類
|
1
2
|
[root@Gin scripts]# awk 'BEGIN{a=5;a+=5;print a}'
10
|
awk邏輯運算子:
|
1
2
|
[root@Gin scripts]# awk 'BEGIN{a=1;b=2;print (a>2&&b>1,a=1||b>1)}'
0 1
|
判斷表達式 a>2&&b>1爲真還是爲假,後面的表達式同理
awk正則運算子:
|
1
2
|
[root@Gin scripts]# awk 'BEGIN{a="100testaa";if(a~/100/) {print "ok"}}'
ok
|
|
1
2
|
[root@Gin scripts]# echo|awk 'BEGIN{a="100testaaa"}a~/test/{print "ok"}'
ok
|
關係運算符:
如: > < 可以作爲字串比較,也可以用作數值比較,關鍵看運算元如果是字串就會轉換爲字串比較。兩個都爲數位 才轉爲數值比較。字串比較:按照ascii碼順序比較。
|
1
2
3
4
5
|
[root@Gin scripts]# awk 'BEGIN{a="11";if(a>=9){print "ok"}}' #無輸出
[root@Gin scripts]# awk 'BEGIN{a=11;if(a>=9){print "ok"}}'
ok
[root@Gin scripts]# awk 'BEGIN{a;if(a>=b){print "ok"}}'
ok
|
awk 算術運算子:
說明,所有用作算術運算子進行操作,運算元自動轉爲數值,所有非數值都變爲0。
|
1
2
3
4
|
[root@Gin scripts]# awk 'BEGIN{a="b";print a++,++a}'
0 2
[root@Gin scripts]# awk 'BEGIN{a="20b4";print a++,++a}'
20 22
|
這裏的a++ , ++a與javascript語言一樣:a++是先賦值加++;++a是先++再賦值
三目運算子 ?:
|
1
2
3
4
|
[root@Gin scripts]# awk 'BEGIN{a="b";print a=="b"?"ok":"err"}'
ok
[root@Gin scripts]# awk 'BEGIN{a="b";print a=="c"?"ok":"err"}'
err
|
常用 awk 內建變數
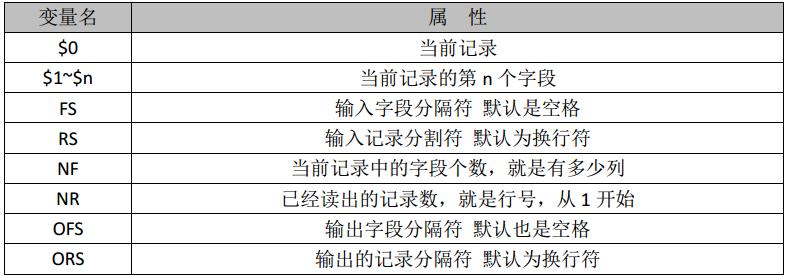
注:內建變數很多,參閱相關資料
欄位分隔符 FS
FS="\t" 一個或多個 Tab 分隔
|
1
2
3
4
|
[root@Gin scripts]# cat tab.txt
ww CC IDD
[root@Gin scripts]# awk 'BEGIN{FS="\t+"}{print $1,$2,$3}' tab.txt
ww CC IDD
|
FS="[[:space:]+]" 一個或多個空白空格,預設的
|
1
2
3
4
5
6
|
[root@Gin scripts]# cat space.txt
we are studing awk now!
[root@Gin scripts]# awk -F [[:space:]+] '{print $1,$2,$3,$4,$5}' space.txt
we are
[root@Gin scripts]# awk -F [[:space:]+] '{print $1,$2}' space.txt
we are
|
FS="[" ":]+" 以一個或多個空格或:分隔
|
1
2
3
4
|
[root@Gin scripts]# cat hello.txt
root:x:0:0:root:/root:/bin/bash
[root@Gin scripts]# awk -F [" ":]+ '{print $1,$2,$3}' hello.txt
root x 0
|
欄位數量 NF
|
1
2
3
4
5
|
[root@Gin scripts]# cat hello.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin:888
[root@Gin scripts]# awk -F ":" 'NF==8{print $0}' hello.txt
bin:x:1:1:bin:/bin:/sbin/nologin:888
|
記錄數量 NR
|
1
2
|
[root@Gin scripts]# ifconfig eth0|awk -F [" ":]+ 'NR==2{print $4}' ## NR==2也就是取第2行
192.168.17.129
|
RS 記錄分隔符變數
將 FS 設定成"\n"告訴 awk 每個欄位都佔據一行。通過將 RS 設定成"",還會告訴 awk每個地址記錄都由空白行分隔。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
[root@Gin scripts]# cat recode.txt
Jimmy the Weasel
100 Pleasant Drive
San Francisco,CA 123456
Big Tony
200 Incognito Ave.
Suburbia,WA 64890
[root@Gin scripts]# cat awk.txt
#!/bin/awk
BEGIN {
FS="\n"
RS=""
}
{
print $1","$2","$3
}
[root@Gin scripts]# awk -f awk.txt recode.txt
Jimmy the Weasel,100 Pleasant Drive,San Francisco,CA 123456
Big Tony,200 Incognito Ave.,Suburbia,WA 64890
|
OFS 輸出欄位分隔符
|
1
2
3
4
5
6
7
8
9
|
[root@Gin scripts]# cat hello.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin:888
[root@Gin scripts]# awk 'BEGIN{FS=":"}{print $1","$2","$3}' hello.txt
root,x,0
bin,x,1
[root@Gin scripts]# awk 'BEGIN{FS=":";OFS="#"}{print $1,$2,$3}' hello.txt
root#x#0
bin#x#1
|
ORS 輸出記錄分隔符
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
[root@Gin scripts]# cat recode.txt
Jimmy the Weasel
100 Pleasant Drive
San Francisco,CA 123456
Big Tony
200 Incognito Ave.
Suburbia,WA 64890
[root@Gin scripts]# cat awk.txt
#!/bin/awk
BEGIN {
FS="\n"
RS=""
ORS="\n\n"
}
{
print $1","$2","$3
}
[root@Gin scripts]# awk -f awk.txt recode.txt
Jimmy the Weasel,100 Pleasant Drive,San Francisco,CA 123456
Big Tony,200 Incognito Ave.,Suburbia,WA 64890
|
awk 正則

正則應用
規則表達式
awk '/REG/{action} ' file,/REG/爲正則表達式,可以將$0 中,滿足條件的記錄送入到:action 進行處理
|
1
2
3
4
5
6
7
8
9
|
[root@Gin scripts]# awk '/root/{print $0}' passwd ##匹配所有包含root的行
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@Gin scripts]# awk -F: '$5~/root/{print $0}' passwd ## 以分號作爲分隔符,匹配第5個欄位是root的行
root:x:0:0:root:/root:/bin/bash
[root@Gin scripts]# ifconfig eth0|awk 'BEGIN{FS="[[:space:]:]+"} NR==2{print $4}'
192.168.17.129
|
布爾表達式
awk '布爾表達式{action}' file 僅當對前面的布爾表達式求值爲真時, awk 才執行程式碼塊。
|
1
2
3
4
|
[root@Gin scripts]# awk -F: '$1=="root"{print $0}' passwd
root:x:0:0:root:/root:/bin/bash
[root@Gin scripts]# awk -F: '($1=="root")&&($5=="root") {print $0}' passwd
root:x:0:0:root:/root:/bin/bash
|
awk 的 if、回圈和陣列
條件語句
awk 提供了非常好的類似於 C 語言的 if 語句。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
if ($1=="foo"){
if($2=="foo"){
print "uno"
}else{
print "one"
}
}elseif($1=="bar"){
print "two"
}else{
print "three"
}
}
|
使用 if 語句還可以將程式碼:
|
1
|
! /matchme/ { print $1 $3 $4 }
|
轉換成:
|
1
2
3
4
5
|
{
if ( $0 !~ /matchme/ ) {
print $1 $3 $4
}
}
|
回圈結構
我們已經看到了 awk 的 while 回圈結構,它等同於相應的 C 語言 while 回圈。 awk 還有"do...while"回圈,它在程式碼塊結尾處對條件求值,而不像標準 while 回圈那樣在開始處求值。
它類似於其它語言中的"repeat...until"回圈。以下是一個範例:
do...while 範例
|
1
2
3
4
5
|
{
count=1do {
print "I get printed at least once no matter what"
} while ( count !=1 )
}
|
與一般的 while 回圈不同,由於在程式碼塊之後對條件求值, "do...while"回圈永遠都至少執行一次。換句話說,當第一次遇到普通 while 回圈時,如果條件爲假,將永遠不執行該回圈。
for 回圈
awk 允許建立 for 回圈,它就象 while 回圈,也等同於 C 語言的 for 回圈:
|
1
2
3
|
for ( initial assignment; comparison; increment ) {
code block
}
|
以下是一個簡短範例:
|
1
2
3
|
for ( x=1;x<=4;x++ ) {
print "iteration", x
}
|
此段程式碼將列印:
|
1
2
3
4
|
iteration1
iteration2
iteration3
iteration4
|
break 和 continue
此外,如同 C 語言一樣, awk 提供了 break 和 continue 語句。使用這些語句可以更好地控制 awk 的回圈結構。以下是迫切需要 break 語句的程式碼片斷:
|
1
2
3
4
5
|
while 死回圈
while (1) {
print "forever and ever..."
}
while 死回圈 1 永遠代表是真,這個 while 回圈將永遠執行下去。
|
以下是一個只執行十次的回圈:
|
1
2
3
4
5
6
7
8
9
|
#break 語句範例
x=1
while(1) {
print "iteration", x
if ( x==10 ) {
break
}
x++
}
|
這裏, break 語句用於「逃出」最深層的回圈。 "break"使回圈立即終止,並繼續執行回圈程式碼塊後面的語句。
continue 語句補充了 break,其作用如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
x=1while (1) {
if ( x==4 ) {
x++
continue
}
print "iteration", x
if ( x>20 ) {
break
}
x++
}
|
這段程式碼列印"iteration1"到"iteration21", "iteration4"除外。如果迭代等於 4,則增加 x並呼叫 continue 語句,該語句立即使 awk 開始執行下一個回圈迭代,而不執行程式碼塊的其餘部分。如同 break 一樣,
continue 語句適合各種 awk 迭代回圈。在 for 回圈主體中使用時, continue 將使回圈控制變量自動增加。以下是一個等價回圈:
|
1
2
3
4
5
6
|
for ( x=1;x<=21;x++ ) {
if ( x==4 ) {
continue
}
print "iteration", x
}
|
在while 回圈中時,在呼叫 continue 之前沒有必要增加 x,因爲 for 回圈會自動增加 x。
陣列
AWK 中的陣列都是關聯陣列,數位索引也會轉變爲字串索引
|
1
2
3
4
5
6
7
8
9
10
11
|
{
cities[1]=」beijing」
cities[2]=」shanghai」
cities[「three」]=」guangzhou」
for( c in cities) {
print cities[c]
}
print cities[1]
print cities[「1」]
print cities[「three」]
}
|
for…in 輸出,因爲陣列是關聯陣列,預設是無序的。所以通過 for…in 得到是無序的陣列。如果需要得到有序陣列,需要通過下標獲得。
陣列的典型應用
用 awk 中檢視伺服器連線狀態並彙總
|
1
2
3
|
netstat -an|awk '/^tcp/{++s[$NF]}END{for(a in s)print a,s[a]}'
ESTABLISHED 1
LISTEN 20
|
統計 web 日誌存取流量,要求輸出存取次數,請求頁面或圖片,每個請求的總大小,總存取流量的大小彙總
|
1
2
3
4
5
6
7
8
9
|
awk '{a[$7]+=$10;++b[$7];total+=$10}END{for(x in a)print b[x],x,a[x]|"sort -rn -k1";print
"total size is :"total}' /app/log/access_log
total size is :172230
21 /icons/poweredby.png 83076
14 / 70546
8 /icons/apache_pb.gif 18608
a[$7]+=$10 表示以第 7 列爲下標的陣列( $10 列爲$7 列的大小),把他們大小累加得到
$7 每次存取的大小,後面的 for 回圈有個取巧的地方, a 和 b 陣列的下標相同,所以一
條 for 語句足矣
|
常用字串函數
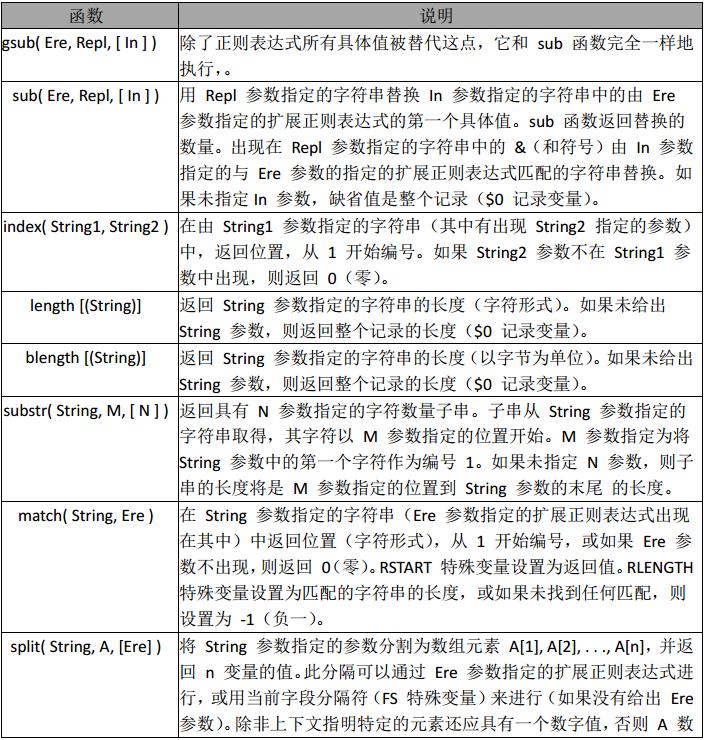

字串函數的應用
替換
|
1
2
3
|
awk 'BEGIN{info="this is a test2010test!";gsub(/[0-9]+/,"!",info);print info}' this is a test!test!
在 info 中查詢滿足正則表達式, /[0-9]+/ 用」!」替換,並且替換後的值,賦值給 info 未
給 info 值,預設是$0
|
查詢
|
1
2
|
awk 'BEGIN{info="this is a test2010test!";print index(info,"test")?"ok":"no found";}'
ok #未找到,返回 0
|
匹配查詢
|
1
2
|
awk 'BEGIN{info="this is a test2010test!";print match(info,/[0-9]+/)?"ok":"no found";}'
ok #如果查詢到數位則匹配成功返回 ok,否則失敗,返回未找到
|
擷取
|
1
2
|
awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10);}'
s is a tes #從第 4 個 字元開始,擷取 10 個長度字串
|
分割
|
1
2
3
4
|
awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}' 4
4 test 1 this 2 is 3 a
#分割 info,動態建立陣列 tA,awk for …in 回圈,是一個無序的回圈。 並不是從陣列下標
1…n 開始
|
轉載自:https://www.cnblogs.com/ginvip/p/6352157.html,侵刪