2020年,知識圖譜都有哪些研究風向?

摘要:隨着認知智慧走進了人們的視野,知識圖譜的重要性便日漸凸顯。在今年的自然語言處理頂會 ACL 2020 上,自然語言知識圖譜領域發生了巨大的革新。ACL 作爲 NLP 領域的頂級學術會議,無疑能夠很好地呈現該領域的研究風 ...
人工智慧學習離不開實踐的驗證,推薦大家可以多在FlyAI-AI競賽服務平臺多參加訓練和競賽,以此來提升自己的能力。FlyAI是爲AI開發者提供數據競賽並支援GPU離線訓練的一站式服務平臺。每週免費提供專案開源演算法樣例,支援演算法能力變現以及快速的迭代演算法模型。
隨着認知智慧走進了人們的視野,知識圖譜的重要性便日漸凸顯。在今年的自然語言處理頂會 ACL 2020 上,自然語言知識圖譜領域發生了巨大的革新。ACL 作爲 NLP 領域的較高階學術會議,無疑能夠很好地呈現該領域的研究風向。
本文作者Michael Galkin(電腦科學家,主要研究方向爲知識圖譜)從問答系統、知識圖譜嵌入、自然語言生成、人工智慧對話系統、資訊提取等方面總結了 ACL 2020 上知識圖譜工作。
ACL 2020 完全採取了線上會議的模式。想要舉辦這麼龐大的線上活動,讓來自多個時區的參會者共同參與其中,並展示超過 700 篇論文是十分困難的。不過在所有講者、參會者、組織者的努力下,這屆大會得以圓滿進行。
那麼與 ACL 2019 相比,知識圖譜和自然語言處理領域發生了大的變化嗎?
答案是肯定的!我們將今年該領域的進展概括爲:
知識圖譜展現了更好地揭示其它非結構化數據中的高階相關性的能力。
1、基於結構化數據的問答系統
在該任務中,研究者們面向 SPARQL 的知識圖譜或 SQL 數據庫這樣的結構化數據源提出了問題。
在今年的 ACL 大會上,我們可以看到越來越多考慮複雜(也被稱爲多跳)問題的工作。
舉例而言,Saxena 等人的論文「Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings」在研究複雜知識圖譜問答任務時,將知識圖譜嵌入與問題嵌入向量耦合在它們的 EmbedKGQA 系統中。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.412.pdf
首先,作者通過一些演算法(本文作者選用了論文「Complex Embeddings for Simple Link Prediction 」中提出的演算法)對底層知識圖譜進行嵌入,從而使每個實體與關係與一個特定的向量相關聯。在某些情況下,作者凍結這些向量,或者根據知識圖譜的規模持續調優。
其次,作者使用 RoBERTA 模型對輸入進行編碼(最後一層中爲 [CLS] ),並經過 4 個全連線層處理,我們希望通過這種方式將問題投影到複雜的空間中。
而關鍵的部分在於評分函數,其中作者採用知識圖譜嵌入的框架,並且構建了一個(頭實體,問題,候選實體)三元組。這裏的評分函數與 ComplEx 演算法使用的一樣,頭實體是問題的主實體,問題被當做三元組中的關係,候選實體要麼是小型知識圖譜中的全部實體,要麼是頭實體周圍 2 跳以內的子圖(當需要剪枝時)。這確實與典型的用於訓練知識圖譜嵌入的「1-N」評分機制 機製相類似。通過計算並閾值化問題嵌入 h_q 和每個關係嵌入 h_r 之間的點積(h_q,h_r),可以進一步對候選空間進行剪枝。
在 MetaQA 和 WebQuestionsSP 上進行的實驗中,作者探索了一種特定的場景:隨機刪除 50% 的邊構造一個不完整的知識圖譜,從而使系統必須學會推理出這些缺失的鏈接。在知識圖譜完整的場景下,EmbedKGQA 與 PullNet 效能相當(在 3 跳問題上效能稍優),在 Hits@1 的得分上比不使用額外的文字增強知識圖譜的基線高出 10-40%。
即使如此,研究 EmbedKGQA 如何處理需要聚合或具有多個具體實體的問題,還是很有趣的。

圖 1:EmbedKGQA 架構示意圖。
另一方面,Lan 等人在論文「Query Graph Generation for Answering Multi-hop Complex Questions from Knowledge Bases」中提出使用迭代的基於強化學習的(知識圖譜嵌入無關)查詢生成方法。基於通過一些實體鏈接(作者通過谷歌知識圖譜 API 連線到 FreeBase 獲得)得到的主題實體,作者提出了應用於種子實體的三種操作,即「擴充套件」(extend)、「聯繫」(connect)、「聚合」(aggregate),通過以上三種操作來構建一個查詢模式。自然而然地,這些操作使其能夠通過 min/max 聚合函數實現複雜的多跳模式。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.91.pdf
在每一步中,作者使用集束搜尋(beam search)保留 K 個較佳的模式,他們爲每個圖派生出一個 7 維特徵向量,並將該向量輸入給帶有 softmax 的前饋網路,從而對這些模式進行排序。在該模型中,被納入查詢圖的實體和關係的表面形式(surface form)被線性化處理後與輸入問題相連線,然後輸入給 BERT,從而在最後一層得到 [CLS] 的表徵(是 7 維特徵之一)。
作者在 ComplexWebQuestions、WebQuestionsSP、ComplexQuestions 上測試了該方法,實驗表明該模型的效能顯著超過了對比基線。模型簡化實驗(又稱消融實驗,ablation study)說明,「擴充套件」、「聯繫」、「聚合」三種操作是十分重要的。令人驚訝的是:這是一篇短文!
我向大家隆重推薦這篇論文,這是一篇很優秀的短文範例,它傳達了主要的思想,展示了實驗過程和結果,通過模型簡化實驗說明了方法的有效性。

圖 2:「Query Graph Generation for Answering Multi-hop Complex Questions from Knowledge Bases」中擴充套件、聯繫、聚合三種操作的示意圖。
結構化問答系統還包含在 SQL 表上的語意解析,許多新的複雜數據集推動了 SQLandia 的研究。
值得一提的是,Wang 等人的論文「RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers」提出了一種面向關係的 Transformer「RAT-SQL」。爲了編碼數據庫模式,他們定義了列和表之間顯式的邊。作者還定義了初始的數據庫模式和值的連線,從而獲得候選的列和表。此外,列、表,以及問題詞例將被一同送入改良後的自注意力層。最後,樹結構的解碼器會構建一個 SQL 查詢。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.677.pdf
當使用 BERT 對問題詞例的嵌入進行初始化時,RAT-SQL 在Spider 任務上取得了顯著的效能提升。

圖 3:模式編碼器中的 RAT 層示意圖。
通常,在與一個語意解析系統互動時,我們往往會想要快速地指出或修正解析器的小錯誤。Elgohary 等人在論文「Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback」中解決了該問題,併發布了 SPLASH數據集,旨在通過自然語言反饋糾正 SQL 解析器的錯誤。這種糾錯的場景與對話式 test2SQL 任務不同,所以即使目前效能最優的模型(如 EditSQL)在糾錯任務中與人類標註者的效能也存在着很大的差距(SOTA 模型的準確率爲 25%,而人類標註者爲 81%)。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.187.pdf
在相同的任務中,Zeng 等人在論文「PHOTON: A Robust Cross-Domain Text-to-SQL System」中提出了 Photon,這是一個相當成熟的可以執行查詢糾錯任務的「text-to-SQL」系統。
論文地址:https://www.aclweb.org/anthology/2020.acl-demos.24.pdf

圖 4:PHOTON 系統示意圖。
2、知識圖譜嵌入:雙曲和超關係知識圖譜
雙曲空間是機器學習領域中最近很活躍的話題之一。簡而言之,在一個雙曲空間中,得益於其特性,我們可以在使用更少的維度的同時,更爲高效地表徵層次和樹狀結構。
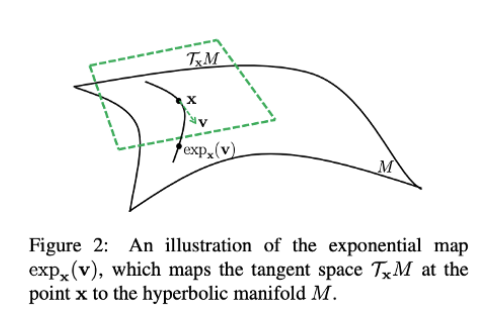
圖 5:將點 x 處的正切空間對映到雙曲流形上。
在這一目標的驅使下,Chami 等人在論文「Low-Dimensional Hyperbolic Knowledge Graph Embeddings」中提出了 AttH,這是一種使用旋轉、反射、平移變換對知識圖譜中的邏輯和層次模式進行建模的雙曲知識圖譜嵌入演算法。「Att」指的是應用於旋轉和反射後的向量的雙曲注意力。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.617.pdf
爲了避開不穩定的黎曼優化,作者使用了正切空間,d 維龐加萊球上的所有點都可以對映到其中。在這種複雜的場景下,每種關係都不僅僅與一個向量有關,還與描述特定關係的反射和旋轉的參數有關。儘管如此,在真實世界的知識圖譜中 R<<V,因此總開銷也不會過高。
在實驗中,AttH 在 WN18RR 和 Yago 3-10 上的表現十分優異,這些數據集展現出了某些層次化的結構,AttH 在 FB15k-237 數據集上的效能提升就較小。更重要的是,在真實的複雜場景下,與現有的 32 維模型相比,僅僅 32 維的 AttH 就展現出了巨大的效能提升。此外,在 WN18RR 和 FB15k-237 數據集上,32 維 AttH 的得分僅僅比當前效能最優的 500 維嵌入模型低 0.02-0.03 個 MRR。模型簡化實驗的結果說明引入可學習的曲率是十分重要的,而與本文最接近的工作「Multi-relational Poincaré Graph Embeddings」,則使用了固定的曲率。
在圖表徵學習領域,另一個日漸凸顯的趨勢是:不僅僅侷限於簡單的由三元組組成的知識圖譜,進一步學習更復雜的超關係知識圖譜,例如 Rosso 等人在論文「Beyond Triplets: Hyper-Relational Knowledge Graph Embedding for Link Prediction」中所做的工作。此時,每個三元組可能還包含一組「鍵-值」屬性對,它們給出了三元組在各種上下文中正確性的細粒度細節資訊。實際上,Wikidata 在「Wikidata Statement」模型中就採用了超關係模型,其中屬性被稱爲「限定符」(qualifier)。需要注意是,不要將模型與生成冗餘謂詞的 n 元事實以及超圖弄混。也就是說,如果你只在三元組層面上使用 Wikidata,那麼你將損失很多的資訊。
論文地址:https://exascale.info/assets/pdf/rosso2020www.pdf

圖 6:超關係事實與事實的 N 元表徵。
Guan 等人在論文「NeuInfer: Knowledge Inference on N-ary Facts」中,並不想丟失 Wikidata 中的大量三元組之外的資訊,提出了一種學習超關係知識圖譜嵌入的方法。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.546.pdf
NeuInfer 旨在計算一個超關係事實的正確性與相容性得分。首先,作者將(h,r,t)嵌入輸入一個全連線網路(FCN),從而估計該三元組的似然度(正確性)。接着,對於每個鍵值對,作者構建了一個五元組(h,r,t,k,v),然後將其輸入到另一組全連線網路中。當有了 m 對鍵值對時,構造出的 m 個向量會經過最小池化處理,最終得到的結果代表相容性得分,即這些限定符與主要的三元組的共存情況。最後,作者使用了這兩種得分的加權求和來得到最終得分。
作者在標準的對比基準測試任務 JF17K(從 Freebase 中抽取得到)和 WikiPeople 上測試了 NeuInfer,並展示了在 JF17K 任務中,在預測頭實體、尾實體、屬性值時,該模型相較於 NaLP 模型取得的顯著提升。
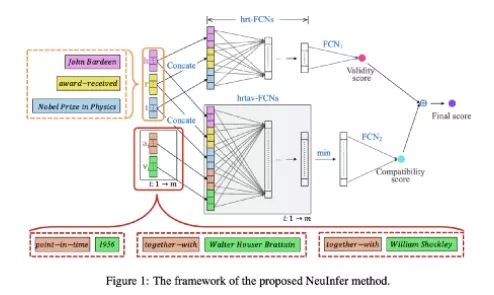
圖 7:NruInfer 的正確性與相容性融合框架。
下面 下麪,我們將討論發表在 ACL 2019 上的知識圖譜嵌入演算法的可復現性。
Sun、Vashishth、Sanyal 等人發現,一些近期發佈的知識圖譜嵌入模型聲稱它們得到了目前較先進的效果,但是它們存在測試集泄露問題,或者在經過了爲正確的三元組評分的 ReLU 啓用函數後會出現許多值爲零的神經元。此外,他們還說明了,效能度量得分(例如 Hits@K 和 MRR)取決於正確三元組在採樣的負樣本中的位置(實際上正確三元組不應該出現在負樣本中)。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.489.pdf
另一方面,目前存在的效能很強的對比基線在任何位置的表現都是一樣的。作者要做的就是使用評估協定,將一個有效的三元組隨機放置在否定的位置上。與此同時,使用將一個正確三元組放置在負樣本中隨機位置上的評估協定。
圖 8:重新評估知識圖譜補全方法。
本文作者的團隊也在發表的另一篇題爲「Bringing Light Into the Dark: A Large-scale Evaluation of Knowledge Graph Embedding Models Under a Unified Framework」的論文中,討論了這一問題。
論文地址:https://arxiv.org/pdf/2006.13365
他們花費了逾 21,000 GPU 小時進行了超過 65,000 次實驗,評估了 19 種模型。在這些模型中,最早的有 2011 年首次發佈的 RESCAL,的有 2019 年發標的 RotatE 和 TuckER。他們嘗試了 5 種損失函數以及各種包含/不包含負採樣的訓練策略,並且考慮了許多很重要的超參數。我們也向社羣公開了所有模型的較佳超參數。此外,他們發佈了 PyKEEN 1.0,這是一個用於訓練知識圖譜嵌入模型並進行對比實驗的 PyTorch 程式庫。
開源地址:https://github.com/pykeen/pykeen
我建議讀者通讀 Sachan 的論文「Knowledge Graph Embedding Compression」,他們研究了通過離散化技術對知識圖譜實體嵌入進行壓縮。例如,「Barack Obama」會被編碼爲「2-1-3-3」而不是一個 200 維的 float32 格式的向量,「Mihcelle Obama」則會被編碼爲「2-1-3-2」。也就是說,你僅僅需要一個長度爲 D、取值範圍爲 K 的向量(在本例中,D=4,K=3)。爲了進行離散化,「tempered softmax」是一種較好的實現方式。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.238.pdf
作者建議使用雙向 LSTM 作爲將 KD 編碼轉化回 N 維浮點向量的反函數。實驗結果令人驚訝,在 FB15K-237 和 WN18RR 上的壓縮率達到了 100-1000 倍,而在進行推理(將 KD 編碼解碼回去)時只會產生微笑(最多爲 2%MRR) 的效能下降,計算開銷也很小。我建議大家重新思考一下現在的知識圖譜嵌入流程(尤其是在生產場景下)。例如,通過 PyTorch-BigGraph獲取的 78M Wikidata 實體的 200 維嵌入需要 1100GB 的儲存空間。試想一下,僅僅壓縮 100 倍會是什麼樣子。
以下是一些對流行的知識圖譜嵌入模型的改進工作:
Tang 等人(https://www.aclweb.org/anthology/2020.acl-main.241.pdf)通過正交關係變換將 RotatE 從二維旋轉泛化到了高維空間中,該模型在 1-N 和 N-N 關係上的效能有所提升。
Xu 等人(https://www.aclweb.org/anthology/2020.acl-main.358.pdf)通過把密集向量分到 K 個組內,將雙線性模型泛化到多線性場景下。他們說明了當 K=1 時,該方法與 DisMult差不多,當 K=2 時,該方法會減化爲 ComplEx和 HolE方法,作者還測試了 K=4 和 K=8 的情況。
Xie 等人(https://www.aclweb.org/anthology/2020.acl-main.526.pdf)通過將標準的折積核替換爲計算機視覺領域著名的 Inception網路中的折積核從而擴充套件了 ConvE。
Nguyen 等人(https://www.aclweb.org/anthology/2020.acl-main.313.pdf)將自注意力類的編碼器以及一個折積神經網路解碼器應用於三元組分類以及個性化搜尋任務。
3、從數據到文字的自然語言生成:準備 Transformer
隨着知識圖譜(更廣義地說是結構化數據)在 2020 年被廣泛應用於 NLP 領域,我們可以看到大量利用一系列 RDF 三元組/AMR 圖/一系列表單元的自然語言生成(NLG)方法,它們可以生成說明或問題等連貫的人類可讀的文字。
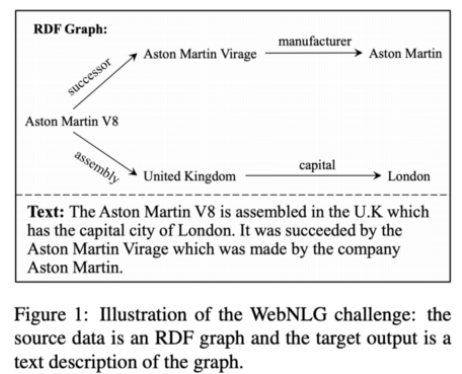
圖 9:WebNLG 挑戰示意圖:源數據爲 RDF 圖,目標輸出是一個圖的文字描述。
此外,當前的各種 RDF-to-text 方法僅僅在 WebNLG 2017 上進行了評價,然而新一輪的挑戰——WebNLG 2020 已經誕生,大家也可以在該挑戰上評估方法。
下面 下麪這條來自 Dmitry Lepikhin 的推特很好地概括了今年 NLG 領域的發展趨勢:
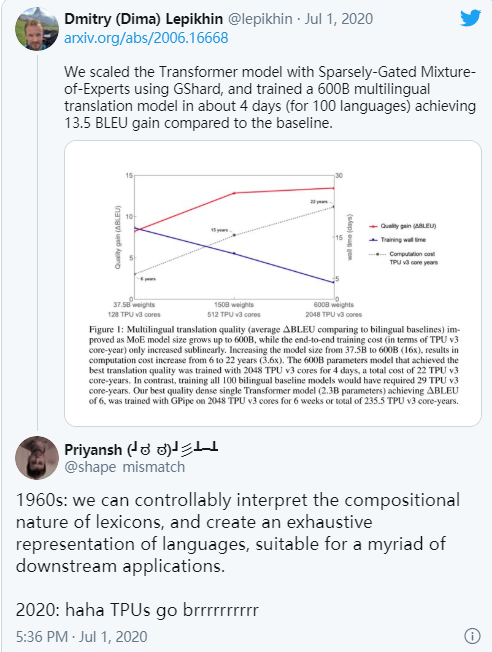
圖 10:今年 NLG 領域的發展趨勢
我們需要設計複雜的規劃器和執行器嗎?需要使用結構化的對齊技術嗎?實際上,使用優秀的預訓練語言模型就可以得到不錯的效果。
事實上,加入預訓練的語言模型並將一些範例輸入給它確實是有效的。Chen 等人在論文「Few-Shot NLG with Pre-Trained Language Model」中,使用一些表中的資訊以及 GPT-2 解碼器說明了這一現象。他們首次將表單元輸入給了一個可學習的 LSTM 編碼器,從而得到拷貝機制 機製的隱藏狀態。另一方面,輸入 GPT-2 的文字使用了凍結的權重。這種拷貝機制 機製有助於保留表單元中的稀有詞例。作者在 WikiBio 上進行的實驗表明,僅僅使用 200 個訓練範例就足以生成比複雜的強對比基線更好的文字。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.18.pdf

圖 11:預訓練語言模型在 NLG 任務中的應用。
同樣是使用表數據,Chen 等人在論文「Logical Natural Language Generation from Open-Domain Tables」中構建了一個新的數據集 LogicNLG,它需要在標準的文字生成方法的基礎上使用額外的邏輯。例如,我們需要使用一些比較和計數操作來納入「1 more gold medal」或「most gold medals」等部分,這些部分會使得生成的文字更加自然和生動。用於實驗數據集的對比基線使用了預訓練的 GPT-2 和 BERT,但似乎在這個任務上的語言模型仍然還有很大的提升空間。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.708.pdf
Song 等人在論文「Structural Information Preserving for Graph-to-Text Generation」中,應用了一個稍加修改的 Transformer 編碼器,它顯式地處理了表面形式的關係。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.712.pdf
模型的輸入就是一個線性化的圖(你可以通過深度優先搜尋 DFS 等方式構建)。解碼器並沒有對 Transformer 做任何修改。該方法關鍵的部分在於向標準的語言模型損失中新增了兩種自編碼損失,它們是專門爲了捕獲與語言化圖的結構而設計的。第一個損失重建了三元關係,另一個損失則重建了線性化輸入圖的節點和連邊的標籤。在 AMR 和 RDF 圖(WebNLG)上進行的實驗說明,僅僅加入這兩種損失就可以在 BLEU 指標上提升 2 個點。
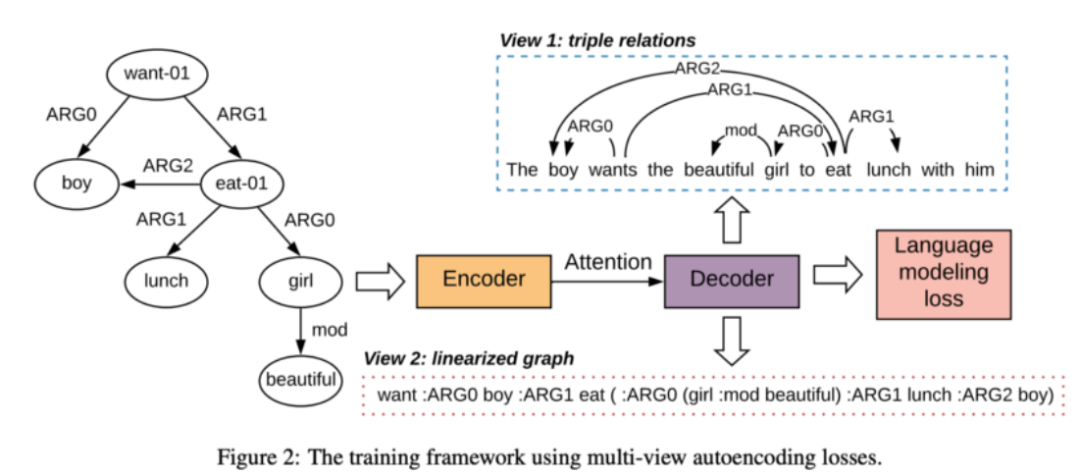
圖 12:使用多檢視自編碼損失進行訓練。
在這裏,我想勸大家:每個人都應該停止使用 BLEU 評價 NLG 的品質。ACL 2020 的較佳論文提名獎獲得者也這麼認爲。WebNLG 2020 的組織者也非常贊同這一觀點,他們在經典的度量標準之外,正式地加入了 chrF++ 和 BertScore 兩種度量標準。此外,在 ACL 2020 上,研究人員提出了一種新的度量標準 BLEURT,它與人類的判斷更相符。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.704.pdf
儘管如此,Zhao 等人在論文「Bridging the Structural Gap Between Encoding and Decoding for Data-To-Text Generation」中提出了一種「編碼器-規劃器-解碼器」模型 DualEnc。首先,他們對輸入圖進行預處理,從而將某種關係變換爲一個顯式的節點。這樣一來,該節點就會包含一些有標籤的邊「s->p, p->s, p->o, o->p」。接着,他們通過 R-GCN 對該圖進行編碼,從而得到實體和關係的嵌入。他們還是用另一個考慮了額外的特徵的 R-GCN 對同一個圖進行編碼,從而說明某種關係是否已經被利用了。他們通過以下的方式構建內容規劃:當存在未存取的關係時,softmax 選擇最可能的關係,然後將該關係新增到內容規劃中。一旦序列準備好了,它就被擴充套件爲這些關係的主語和賓語。最後,通過 LSTM 對生成的序列進行編碼。他們將圖編碼和規劃編碼輸入解碼器,從而生成輸出結果。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.224.pdf
實驗結果表明:(1)DualEnc 在構建內容規劃時,在未見過的測試集上有很好的泛化效果(2)文字生成品質比直接使用 Transformer 更高(3)規劃階段的速度提升很大,2019 年較佳的模型需要 250 秒才能 纔能處理一個「7-三元組」範例,而 DualEnc 在 10 秒中就可以處理 4,928 個範例。

圖 13:DualEnc 模型架構示意圖。
最後,在摘要生成領域中,Huang 等人在論文「Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward」中提出了 ASGARD,利用根據某個文件構建的知識圖譜改進了文字生成過程。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.457.pdf

圖 14:帶有文件級圖編碼的 ASGARD 框架示意圖。
具體而言,編碼器由兩部分組成。
步驟 1:他們使用 RoBERTa 對輸入段落進行編碼。最後一層嵌入會被輸入給一個雙向 LSTM,從而獲得隱藏狀態。
步驟 2:他們使用 OpenIE 提取三元組,從輸入文件中導出一張圖。他們將關係詞例變換爲與 DualEnc 相似的顯式節點,然後使用前面的雙向 LSTM 的隱藏狀態對節點的狀態進行初始化。他們使用圖注意力網路(GAT)更新節點狀態,並使用一個讀出函數獲取圖的上下文向量。
步驟 3:他們將前兩步獲得的向量作爲條件,從而生成文字。
值得一提的是,訓練時出現了一些神奇的現象:ASGARD 使用了強化學習演算法,其中獎勵函數是基於 ROUGE 和完形填空得分構建的。完形填空的部分包括根據人類編寫的摘要提取 OpenIE 圖,並基於它們生成完形填空風格的問題,以便系統更好地瞭解摘要文件的含義。所以從某種程度上說,這裏面也包含了一個問答系統模型。作者爲 CNN 和 NYT 數據集生成了一百萬多個完形填空問題。實驗結果表明,該方法超越了以前的對比基線。然而,預訓練好的 BART 在目標數據集上進行調優後成爲了最終的較佳模型。
4、對話式人工智慧:改進面向目標的機器人
在對話式人工智慧(ConvAI)領域,我更偏愛面向目標的系統,因爲知識圖譜和結構化數據自然而然地擴充套件了它們的能力。

圖 15:SLoTQUESTION 的模板以及另一個用於生成互動範例的不針對特定對話的模板。
首先,Campagna 等人在論文「Zero-Shot Transfer Learning with Synthesized Data for Multi-Domain Dialogue State Tracking」中提出了一種合成面向目標的對話作爲附加訓練數據的方法,用於對話狀態跟蹤(DST)任務。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.12.pdf
作者建立了一個定義基本狀態、動作和轉移函數的抽象模型(也可以將其稱之爲本體)。它的貢獻在於:(1)該模型可以應用於各種領域,如餐廳預訂或訓練帶有任意空槽和值的連線搜尋;(2)合成的數據允許在你在有監督數據十分有限的域內進行零樣本遷移;(3)事實上,實驗表明,(在真實的 MultiWoz 2.1 測試中)僅使用合成的語料庫進行訓練和評估的準確性達到使用原始完整訓練集時的約 2/3。
我相信在研發特定領域的對話系統或已標註訓練數據十分有限時,該方法可以作爲一個通用的數據增強方法。
Yu 等人在論文「Dialogue-Based Relation Extraction」專注於對話中的關係提取任務,研發了 DialogRE。這是一個新的數據集,由從《老友記》中的兩千段對話中提取出的 36 中關係組成。儘管沒有使用 Wikidata 或 DBpedia 的資源識別符號(URI)對這些關係進行標註,該數據集仍然提出了一個巨大的挑戰,即使對 BERT 也是如此。此外,作者還提出了一種新的度量標準,它可以說明一個系統需要經過多少輪才能 纔能提取出某種關係。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.444.pdf
OpenDialKG 這項工作由於在一個新的數據集上提升了對話系統中的基於知識圖譜的推理而獲得了 ACL 2019 較佳論文提名。
論文地址:https://pdfs.semanticscholar.org/0d3c/68c207fc83fb402b7217811af22066300fc9.pdf
Zhou 等人在論文「KdConv: A Chinese Multi-domain Dialogue Dataset Towards Multi-turn Knowledge-driven Conversation 」中,將 OpenDialKG 中的主要思想用於了適用於中文的 KdConv 數據集。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.635.pdf
還有一些工作研究如何將外部知識納入端到端的對話系統。如果背景知識被表示爲文字三元組或表單元(或者即使是純文字),Lin 等人建議使用 Transformer 作爲知識編碼器,而 Qin 等人(https://www.aclweb.org/anthology/2020.acl-main.6.pdf)則推薦使用記憶網路式的編碼器。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.6.pdf
如果有一個像 ConceptNet 這樣的常識知識圖譜,Zhang 等人在論文「」中從話語中提取出了一些概念,從而構建了一個區域性圖,然後通過一個 GNN 編碼器對會影響解碼器的對話的「中心概念」進行編碼。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.184.pdf
5、資訊提取:OpenIE 和鏈接預測
如果你從事的工作恰好與根據原始文字構建知識圖譜相關,也許你已經知道大家約定俗成將 OpenIE 作爲起點。正如前文所述,像 OpenIE4 或 OpenIE 5 這種基於規則的框架仍然被廣泛使用。也就是說,提升 OpenIE 資訊提取的指令可以緩解知識圖譜構建過程中存在的許多問題。請注意:使用 OpenIE 獲得的知識圖譜也被成爲「Open KG」(開放知識圖譜)。
Kolluru 等人在論文「IMOJIE: Iterative Memory-Based Joint Open Information Extraction 」中提出了一種生成式的 OpenIE 方法「IMoJIE」(迭代式的基於記憶的聯合資訊提取)。在 CopyAttention 範式的啓發下,作者提出了一種迭代式的序列到序列資訊提取演算法:在每一輪迭代中,將原始序列與之前提取的資訊連線,並將其輸入給 BERT 從而獲得最終的嵌入。接着,將帶有拷貝和注意力機制 機製的 LSTM 解碼器用於生成新的資訊提取結果(包含三元組的詞例)。爲了進一步改進訓練集,作者將 OpenOE 3 和 OpenIE 4 以及其它系統的結果作爲生成結果的「銀標籤」進行了聚合和排序。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.521.pdf
儘管該架構看似簡單,但它相較於現有的對比基線確實帶來了顯著的效能提升。模型簡化實驗(又稱消融實驗)的結果表明,BERT 對於整體的資訊提取品質至關重要,所以我猜想如果使用一個更大的 Transformer,或使用一個針對特定領域預訓練的語言模型(例如,如果你的文字是來自法律或生物醫學領域)資訊提取品質會得到進一步的提升。
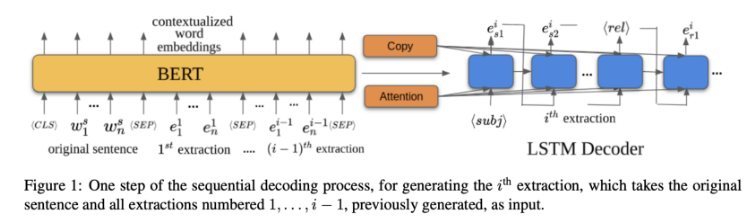
圖 16:序列化解碼過程。
儘管在 RDF 式的知識圖譜上的鏈接預測(LP)任務中,人們已經做出了一些裡程碑式的工作,我們並不能認爲在開放知識圖譜(open KG)上也是如此。
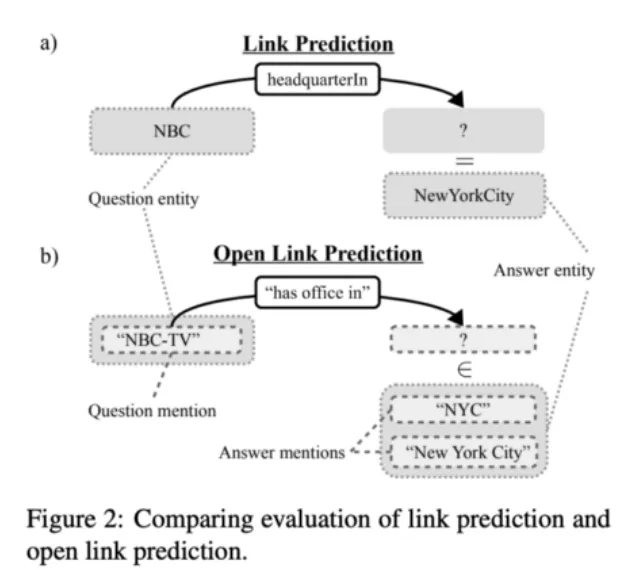
圖 17:對鏈接預測和開放鏈接預測的對比評價。
但現在可以做到了!
Broscheit 等人在論文「Can We Predict New Facts with Open Knowledge Graph Embeddings? A Benchmark for Open Link Prediction」中定義了給定開放知識圖譜在面臨以下挑戰時的開放鏈接預測任務:
給定一個(「主語文字」或「關係文字」)的查詢,系統需要預測真實的、不能被簡單解釋的新事實。
然而,並沒有可用的實體或關係 URI 能將表面形式系結到同一個表徵上。
儘管如此,許多相同實體或關係的表面形式可能會造成測試機泄露,因此需要仔細地構建並清洗測試集。
論文地址:https://www.aclweb.org/anthology/2020.acl-main.209.pdf
作者提出了一種構建並清洗數據集的方法、一種評價協定,以及一種對比基準測試任務。OLPBench 是一種較大的基於知識圖譜嵌入的鏈接預測數據集:它包含超過 30M 三元組、1M 獨特的開放關係、800K 個被提及了 2.5M 次的實體。在實驗中,作者使用了 ComplEx,通過 LSTM 聚合多詞例宣告。開放鏈接預測任務由此變得十分困難:即使強大的 768 維 ComplEx 也只得到了 3.6 MRR,2 Hit@1,6.6 Hits@10 的測試結果。
顯然,這是一個頗具挑戰的數據集:看到這些方法不僅可以被擴充套件到如此之大的圖上,還能夠將效能提升到與 FB15K-237 相當的水平上(目前,這一數位是 35 MRR 以及 55 Hits@10)是十分有趣的。
此外,如果你對根據文字構建知識圖譜感興趣,我推薦你參閱 AKBC 2020的會議論文集:https://www.akbc.ws/2020/papers/
6、結語
在今年的 ACL 2020 上,我們發現有關知識圖譜增強的語言模型和命名實體識別(NER)的工作變少了,而另一方面,「Graph-to-Text」方面的自然語言生成工作正處於上升趨勢!
via https://towardsdatascience.com/knowledge-graphs-in-natural-language-processing-acl-2020-ebb1f0a6e0b1
更多關於人工智慧的文章,敬請存取:FlyAI-AI競賽服務平臺學習圈學習;同時FlyAI歡迎廣大演算法工程師在平臺發文,獲得更多原創獎勵。此外,FlyAI競賽平臺提供大量數據型賽題供學習黨和競賽黨蔘與,免費GPU試用,更多大賽經驗分享;如有任何疑問可新增下方微信服務號(FlyAI小助手)進行諮詢。

更多福利可新增「FlyAI小助手」獲取~