Android Bander設計與實現 - 設計篇
關鍵詞
Binder Android IPC Linux 內核 驅動
摘要
Binder是Android系統進程間通訊(IPC)方式之一。Linux已經擁有管道,system V IPC,socket等IPC手段,卻還要倚賴Binder來實現進程間通訊,說明Binder具有無可比擬的優勢。深入瞭解Binder並將之與傳統IPC做對比有助於我們深入領會進程間通訊的實現和效能優化。本文將對Binder的設計細節做一個全面的闡述,首先通過介紹Binder通訊模型和Binder通訊協定瞭解Binder的設計需求;然後分別闡述Binder在系統不同部分的表述方式和起的作用;最後還會解釋Binder在數據接收端的設計考慮,包括執行緒池管理,記憶體對映和等待佇列管理等。通過本文對Binder的詳細介紹以及與其它IPC通訊方式的對比,讀者將對Binder的優勢和使用Binder作爲Android主要IPC方式的原因有深入瞭解。
1 引言
基於Client-Server的通訊方式廣泛應用於從網際網路和數據庫存取到嵌入式手持裝置內部通訊等各個領域。智慧手機平臺特別是Android系統中,爲了嚮應用開發者提供豐富多樣的功能,這種通訊方式更是無處不在,諸如媒體播放,視音訊頻捕獲,到各種讓手機更智慧的感測器(加速度,方位,溫度,光亮度等)都由不同的Server負責管理,應用程式只需做爲Client與這些Server建立連線便可以使用這些服務,花很少的時間和精力就能開發出令人眩目的功能。Client-Server方式的廣泛採用對進程間通訊(IPC)機制 機製是一個挑戰。目前linux支援的IPC包括傳統的管道,System V IPC,即訊息佇列/共用記憶體/號志,以及socket中只有socket支援Client-Server的通訊方式。當然也可以在這些底層機制 機製上架設一套協定來實現Client-Server通訊,但這樣增加了系統的複雜性,在手機這種條件複雜,資源稀缺的環境下可靠性也難以保證。
另一方面是傳輸效能。socket作爲一款通用介面,其傳輸效率低,開銷大,主要用在跨網路的進程間通訊和本機上進程間的低速通訊。訊息佇列和管道採用儲存-轉發方式,即數據先從發送方快取區拷貝到內核開闢的快取區中,然後再從內核快取區拷貝到接收方快取區,至少有兩次拷貝過程。共用記憶體雖然無需拷貝,但控制複雜,難以使用。
表 1 各種IPC方式數據拷貝次數
|
IPC |
數據拷貝次數 |
|
共用記憶體 |
0 |
|
Binder |
1 |
|
Socket/管道/訊息佇列 |
2 |
還有一點是出於安全性考慮。Android作爲一個開放式,擁有衆多開發者的的平臺,應用程式的來源廣泛,確保智慧終端的安全是非常重要的。終端使用者不希望從網上下載的程式在不知情的情況下偷窺隱私數據,連線無線網路,長期操作底層裝置導致電池很快耗盡等等。傳統IPC沒有任何安全措施,完全依賴上層協定來確保。首先傳統IPC的接收方無法獲得對方進程可靠的UID/PID(使用者ID/進程ID),從而無法鑑別對方身份。Android爲每個安裝好的應用程式分配了自己的UID,故進程的UID是鑑別進程身份的重要標誌。使用傳統IPC只能由使用者在數據包裡填入UID/PID,但這樣不可靠,容易被惡意程式利用。可靠的身份標記只有由IPC機制 機製本身在內核中新增。其次傳統IPC存取接入點是開放的,無法建立私有通道。比如命名管道的名稱,system V的鍵值,socket的ip地址或檔名都是開放的,只要知道這些接入點的程式都可以和對端建立連線,不管怎樣都無法阻止惡意程式通過猜測接收方地址獲得連線。
基於以上原因,Android需要建立一套新的IPC機制 機製來滿足系統對通訊方式,傳輸效能和安全性的要求,這就是Binder。Binder基於Client-Server通訊模式,傳輸過程只需一次拷貝,爲發送發新增UID/PID身份,既支援實名Binder也支援匿名Binder,安全性高。
2 物件導向的 Binder IPC
Binder使用Client-Server通訊方式:一個進程作爲Server提供諸如視訊/音訊解碼,視訊捕獲,地址本查詢,網路連線等服務;多個進程作爲Client向Server發起服務請求,獲得所需要的服務。要想實現Client-Server通訊據必須實現以下兩點:一是server必須有確定的存取接入點或者說地址來接受Client的請求,並且Client可以通過某種途徑獲知Server的地址;二是制定Command-Reply協定來傳輸數據。例如在網路通訊中Server的存取接入點就是Server主機的IP地址+埠號,傳輸協定爲TCP協定。對Binder而言,Binder可以看成Server提供的實現某個特定服務的存取接入點, Client通過這個‘地址’向Server發送請求來使用該服務;對Client而言,Binder可以看成是通向Server的管道入口,要想和某個Server通訊首先必須建立這個管道並獲得管道入口。
與其它IPC不同,Binder使用了物件導向的思想來描述作爲存取接入點的Binder及其在Client中的入口:Binder是一個實體位於Server中的物件,該物件提供了一套方法用以實現對服務的請求,就象類的成員函數。遍佈於client中的入口可以看成指向這個binder物件的‘指針’,一旦獲得了這個‘指針’就可以呼叫該物件的方法存取server。在Client看來,通過Binder‘指針’呼叫其提供的方法和通過指針呼叫其它任何本地物件的方法並無區別,儘管前者的實體位於遠端Server中,而後者實體位於本地記憶體中。‘指針’是C++的術語,而更通常的說法是參照,即Client通過Binder的參照存取Server。而軟體領域另一個術語‘控制代碼’也可以用來表述Binder在Client中的存在方式。從通訊的角度看,Client中的Binder也可以看作是Server Binder的‘代理’,在本地代表遠端Server爲Client提供服務。本文中會使用‘參照’或‘控制代碼’這個兩廣泛使用的術語。
物件導向思想的引入將進程間通訊轉化爲通過對某個Binder物件的參照呼叫該物件的方法,而其獨特之處在於Binder物件是一個可以跨進程參照的物件,它的實體位於一個進程中,而它的參照卻遍佈於系統的各個進程之中。最誘人的是,這個參照和java裡參照一樣既可以是強型別,也可以是弱型別,而且可以從一個進程傳給其它進程,讓大家都能存取同一Server,就象將一個物件或參照賦值給另一個參照一樣。Binder模糊了進程邊界,淡化了進程間通訊過程,整個系統彷彿執行於同一個物件導向的程式之中。形形色色的Binder物件以及星羅棋佈的參照彷彿粘接各個應用程式的膠水,這也是Binder在英文裡的原意。
當然物件導向只是針對應用程式而言,對於Binder驅動和內核其它模組一樣使用C語言實現,沒有類和物件的概念。Binder驅動爲物件導向的進程間通訊提供底層支援。
3 Binder 通訊模型
Binder框架定義了四個角色:Server,Client,ServiceManager(以後簡稱SMgr)以及Binder驅動。其中Server,Client,SMgr執行於使用者空間,驅動執行於內核空間。這四個角色的關係和網際網路類似:Server是伺服器,Client是客戶終端,SMgr是域名伺服器(DNS),驅動是路由器。
3.1 Binder 驅動
和路由器一樣,Binder驅動雖然默默無聞,卻是通訊的核心。儘管名叫‘驅動’,實際上和硬體裝置沒有任何關係,只是實現方式和裝置驅動程式是一樣的:它工作於內核態,提供open(),mmap(),poll(),ioctl()等標準檔案操作,以字元驅動裝置中的misc設備註冊在裝置目錄/dev下,使用者通過/dev/binder存取該它。驅動負責進程之間Binder通訊的建立,Binder在進程之間的傳遞,Binder參照計數管理,數據包在進程之間的傳遞和互動等一系列底層支援。驅動和應用程式之間定義了一套介面協定,主要功能由ioctl()介面實現,不提供read(),write()介面,因爲ioctl()靈活方便,且能夠一次呼叫實現先寫後讀以滿足同步互動,而不必分別呼叫write()和read()。Binder驅動的程式碼位於linux目錄的drivers/misc/binder.c中。
3.2 ServiceManager 與實名Binder
和DNS類似,SMgr的作用是將字元形式的Binder名字轉化成Client中對該Binder的參照,使得Client能夠通過Binder名字獲得對Server中Binder實體的參照。註冊了名字的Binder叫實名Binder,就象每個網站除了有IP地址外還有自己的網址。Server建立了Binder實體,爲其取一個字元形式,可讀易記的名字,將這個Binder連同名字以數據包的形式通過Binder驅動發送給SMgr,通知SMgr註冊一個名叫張三的Binder,它位於某個Server中。驅動爲這個穿過進程邊界的Binder建立位於內核中的實體節點以及SMgr對實體的參照,將名字及新建的參照打包傳遞給SMgr。SMgr收數據包後,從中取出名字和參照填入一張查詢表中。
細心的讀者可能會發現其中的蹊蹺:SMgr是一個進程,Server是另一個進程,Server向SMgr註冊Binder必然會涉及進程間通訊。當前實現的是進程間通訊卻又要用到進程間通訊,這就好象蛋可以孵出雞前提卻是要找只雞來孵蛋。Binder的實現比較巧妙:預先創造一隻雞來孵蛋:SMgr和其它進程同樣採用Binder通訊,SMgr是Server端,有自己的Binder物件(實體),其它進程都是Client,需要通過這個Binder的參照來實現Binder的註冊,查詢和獲取。SMgr提供的Binder比較特殊,它沒有名字也不需要註冊,當一個進程使用BINDER_SET_CONTEXT_MGR命令將自己註冊成SMgr時Binder驅動會自動爲它建立Binder實體(這就是那隻預先造好的雞)。其次這個Binder的參照在所有Client中都固定爲0而無須通過其它手段獲得。也就是說,一個Server若要向SMgr註冊自己Binder就必需通過0這個參照號和SMgr的Binder通訊。類比網路通訊,0號參照就好比域名伺服器的地址,你必須預先手工或動態設定好。要注意這裏說的Client是相對SMgr而言的,一個應用程式可能是個提供服務的Server,但對SMgr來說它仍然是個Client。
3.3 Client 獲得實名Binder的參照
Server向SMgr註冊了Binder實體及其名字後,Client就可以通過名字獲得該Binder的參照了。Client也利用保留的0號參照向SMgr請求存取某個Binder:我申請獲得名字叫張三的Binder的參照。SMgr收到這個連線請求,從請求數據包裡獲得Binder的名字,在查詢表裏找到該名字對應的條目,從條目中取出Binder的參照,將該參照作爲回覆 回復發送給發起請求的Client。從物件導向的角度,這個Binder物件現在有了兩個參照:一個位於SMgr中,一個位於發起請求的Client中。如果接下來有更多的Client請求該Binder,系統中就會有更多的參照指向該Binder,就象java裡一個物件存在多個參照一樣。而且類似的這些指向Binder的參照是強型別,從而確保只要有參照Binder實體就不會被釋放掉。通過以上過程可以看出,SMgr象個火車票代售點,收集了所有火車的車票,可以通過它購買到乘坐各趟火車的票-得到某個Binder的參照。
3.4 匿名 Binder
並不是所有Binder都需要註冊給SMgr廣而告之的。Server端可以通過已經建立的Binder連線將建立的Binder實體傳給Client,當然這條已經建立的Binder連線必須是通過實名Binder實現。由於這個Binder沒有向SMgr註冊名字,所以是個匿名Binder。Client將會收到這個匿名Binder的參照,通過這個參照向位於Server中的實體發送請求。匿名Binder爲通訊雙方建立一條私密通道,只要Server沒有把匿名Binder發給別的進程,別的進程就無法通過窮舉或猜測等任何方式獲得該Binder的參照,向該Binder發送請求。
下圖展示了參與Binder通訊的所有角色,將在以後章節中一一提到。
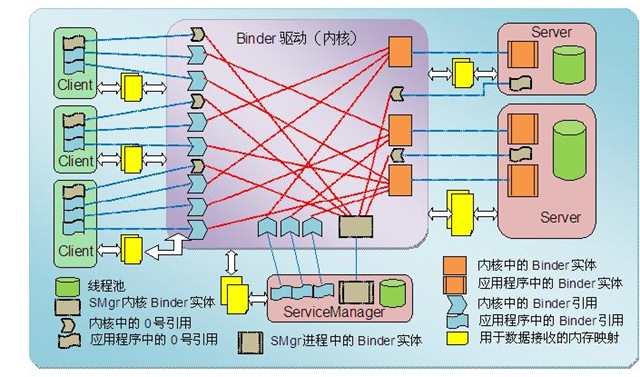
圖 1 Binder通訊範例
4 Binder 協定
Binder協定基本格式是(命令+數據),使用ioctl(fd, cmd, arg)函數實現互動。命令由參數cmd承載,數據由參數arg承載,隨cmd不同而不同。下表列舉了所有命令及其所對應的數據:
表 2 Binder通訊命令字
|
命令 |
含義 |
arg |
|
BINDER_WRITE_READ |
該命令向Binder寫入或讀取數據。參數分爲兩段:寫部分和讀部分。如果write_size不爲0就先將write_buffer裡的數據寫入Binder;如果read_size不爲0再從Binder中讀取數據存入read_buffer中。write_consumed和read_consumed表示操作完成時Binder驅動實際寫入或讀出的數據個數。 |
struct binder_write_read { signed long write_size; signed long write_consumed; unsigned long write_buffer; signed long read_size; signed long read_consumed; unsigned long read_buffer; }; |
|
BINDER_SET_MAX_THREADS |
該命令告知Binder驅動接收方(通常是Server端)執行緒池中最大的執行緒數。由於Client是併發向Server端發送請求的,Server端必須開闢執行緒池爲這些併發請求提供服務。告知驅動執行緒池的最大值是爲了讓驅動發現執行緒數達到該值時不要再命令接收端啓動新的執行緒。 |
int max_threads; |
|
BINDER_SET_CONTEXT_MGR |
將當前進程註冊爲SMgr。系統中同時只能存在一個SMgr。只要當前的SMgr沒有呼叫close()關閉Binder驅動就不能有別的進程可以成爲SMgr。 |
--- |
|
BINDER_THREAD_EXIT |
通知Binder驅動當前執行緒退出了。Binder會爲所有參與Binder通訊的執行緒(包括Server執行緒池中的執行緒和Client發出請求的執行緒)建立相應的數據結構。這些執行緒在退出時必須通知驅動釋放相應的數據結構。 |
--- |
|
BINDER_VERSION |
獲得Binder驅動的版本號。 |
--- |
這其中最常用的命令是BINDER_WRITE_READ。該命令的參數包括兩部分數據:一部分是向Binder寫入的數據,一部分是要從Binder讀出的數據,驅動程式先處理寫部分再處理讀部分。這樣安排的好處是應用程式可以很靈活地處理命令的同步或非同步。例如若要發送非同步命令可以只填入寫部分而將read_size置成0;若要只從Binder獲得數據可以將寫部分置空即write_size置成0;若要發送請求並同步等待返回數據可以將兩部分都置上。
Binder寫操作的數據時格式同樣也是(命令+數據)。這時候命令和數據都存放在binder_write_read 結構write_buffer域指向的記憶體空間裡,多條命令可以連續存放。數據緊接着存放在命令後面,格式根據命令不同而不同。下表列舉了Binder寫操作支援的命令:
表 3 Binder寫操作命令字
|
cmd |
含義 |
arg |
|
BC_TRANSACTION |
BC_TRANSACTION用於Client向Server發送請求數據;BC_REPLY用於Server向Client發送回覆 回復(應答)數據。其後面緊接着一個binder_transaction_data結構體表明要寫入的數據。 |
struct binder_transaction_data |
|
BC_ACQUIRE_RESULT |
暫未實現 |
--- |
|
BC_FREE_BUFFER |
釋放一塊對映的記憶體。Binder接收方通過mmap()對映一塊較大的記憶體空間,Binder驅動基於這片記憶體採用最佳匹配演算法實現接收數據快取的動態分配和釋放,滿足併發請求對接收快取區的需求。應用程式處理完這片數據後必須儘快使用該命令釋放快取區,否則會因爲快取區耗盡而無法接收新數據。 |
指向需要釋放的快取區的指針;該指針位於收到的Binder數據包中 |
|
BC_INCREFS |
這組命令增加或減少Binder的參照計數,用以實現強指針或弱指針的功能。 |
32位元Binder參照號 |
|
BC_INCREFS_DONE |
第一次增加Binder實體參照計數時,驅動向Binder實體所在的進程發送BR_INCREFS, BR_ACQUIRE訊息;Binder實體所在的進程處理完畢回饋BC_INCREFS_DONE,BC_ACQUIRE_DONE |
void *ptr:Binder實體在使用者空間中的指針 void *cookie:與該實體相關的附加數據 |
|
BC_REGISTER_LOOPER |
這組命令同BINDER_SET_MAX_THREADS一道實現Binder驅動對接收方執行緒池管理。BC_REGISTER_LOOPER通知驅動執行緒池中一個執行緒已經建立了;BC_ENTER_LOOPER通知驅動該執行緒已經進入主回圈,可以接收數據;BC_EXIT_LOOPER通知驅動該執行緒退出主回圈,不再接收數據。 |
--- |
|
BC_REQUEST_DEATH_NOTIFICATION |
獲得Binder參照的進程通過該命令要求驅動在Binder實體銷燬得到通知。雖說強指針可以確保只要有參照就不會銷燬實體,但這畢竟是個跨進程的參照,誰也無法保證實體由於所在的Server關閉Binder驅動或異常退出而消失,參照者能做的是要求Server在此刻給出通知。 |
uint32 *ptr; 需要得到死亡通知的Binder參照 void **cookie: 與死亡通知相關的資訊,驅動會在發出死亡通知時返回給發出請求的進程。 |
|
BC_DEAD_BINDER_DONE |
收到實體死亡通知書的進程在刪除參照後用本命令告知驅動。 |
void **cookie |
在這些命令中,最常用的是BC_TRANSACTION/BC_REPLY命令對,Binder請求和應答數據就是通過這對命令發送給接收方。這對命令所承載的數據包由結構體struct binder_transaction_data定義。Binder互動有同步和非同步之分,利用binder_transaction_data中flag域區分。如果flag域的TF_ONE_WAY位爲1則爲非同步互動,即Client端發送完請求互動即結束, Server端不再返回BC_REPLY數據包;否則Server會返回BC_REPLY數據包,Client端必須等待接收完該數據包方纔完成一次互動。
4.2 BINDER_WRITE_READ :從Binder讀出數據
從Binder裡讀出的數據格式和向Binder中寫入的數據格式一樣,採用(訊息ID+數據)形式,並且多條訊息可以連續存放。下表列舉了從Binder讀出的命令字及其相應的參數:
表 4 Binder讀操作訊息ID
|
訊息 |
含義 |
參數 |
|
BR_ERROR |
發生內部錯誤(如記憶體分配失敗) |
--- |
|
BR_OK |
操作完成 |
--- |
|
BR_SPAWN_LOOPER |
該訊息用於接收方執行緒池管理。當驅動發現接收方所有執行緒都處於忙碌狀態且執行緒池裏的執行緒總數沒有超過BINDER_SET_MAX_THREADS設定的最大執行緒數時,向接收方發送該命令要求建立更多執行緒以備接收數據。 |
--- |
|
BR_TRANSACTION |
這兩條訊息分別對應發送方的BC_TRANSACTION和BC_REPLY,表示當前接收的數據是請求還是回覆 回復。 |
binder_transaction_data |
|
BR_ACQUIRE_RESULT |
尚未實現 |
--- |
|
BR_DEAD_REPLY |
互動過程中如果發現對方進程或執行緒已經死亡則返回該訊息 |
--- |
|
BR_TRANSACTION_COMPLETE |
發送方通過BC_TRANSACTION或BC_REPLY發送完一個數據包後,都能收到該訊息做爲成功發送的反饋。這和BR_REPLY不一樣,是驅動告知發送方已經發送成功,而不是Server端返回請求數據。所以不管同步還是非同步互動接收方都能獲得本訊息。 |
--- |
|
BR_INCREFS |
這一組訊息用於管理強/弱指針的參照計數。只有提供Binder實體的進程才能 纔能收到這組訊息。 |
void *ptr:Binder實體在使用者空間中的指針 void *cookie:與該實體相關的附加數據 |
|
BR_DEAD_BINDER |
向獲得Binder參照的進程發送Binder實體死亡通知書;收到死亡通知書的進程接下來會返回BC_DEAD_BINDER_DONE做確認。 |
void **cookie:在使用BC_REQUEST_DEATH_NOTIFICATION註冊死亡通知時的附加參數。 |
|
BR_FAILED_REPLY |
如果發送非法參照號則返回該訊息 |
--- |
和寫數據一樣,其中最重要的訊息是BR_TRANSACTION 或BR_REPLY,表明收到了一個格式爲binder_transaction_data的請求數據包(BR_TRANSACTION)或返回數據包(BR_REPLY)。
4.3 struct binder_transaction_data :收發數據包結構
該結構是Binder接收/發送數據包的標準格式,每個成員定義如下:
表 5 Binder收發數據包結構:binder_transaction_data
|
成員 |
含義 |
|
union { size_t handle; void *ptr; } target; |
對於發送數據包的一方,該成員指明發送目的地。由於目的是在遠端,所以這裏填入的是對Binder實體的參照,存放在target.handle中。如前述,Binder的參照在程式碼中也叫控制代碼(handle)。 當數據包到達接收方時,驅動已將該成員修改成Binder實體,即指向Binder物件記憶體的指針,使用target.ptr來獲得。該指針是接收方在將Binder實體傳輸給其它進程時提交給驅動的,驅動程式能夠自動將發送方填入的參照轉換成接收方Binder物件的指針,故接收方可以直接將其當做物件指針來使用(通常是將其reinterpret_cast成相應類)。 |
|
void *cookie; |
發送方忽略該成員;接收方收到數據包時,該成員存放的是建立Binder實體時由該接收方自定義的任意數值,做爲與Binder指針相關的額外資訊存放在驅動中。驅動基本上不關心該成員。 |
|
unsigned int code; |
該成員存放收發雙方約定的命令碼,驅動完全不關心該成員的內容。通常是Server端定義的公共介面函數的編號。 |
|
unsigned int flags; |
與互動相關的標誌位,其中最重要的是TF_ONE_WAY位。如果該位置上表明這次互動是非同步的,Server端不會返回任何數據。驅動利用該位來決定是否構建與返回有關的數據結構。另外一位TF_ACCEPT_FDS是出於安全考慮,如果發起請求的一方不希望在收到的回覆 回復中接收檔案形式的Binder可以將該位置上。因爲收到一個檔案形式的Binder會自動爲數據接收方開啓一個檔案,使用該位可以防止開啓檔案過多。 |
|
pid_t sender_pid; uid_t sender_euid; |
該成員存放發送方的進程ID和使用者ID,由驅動負責填入,接收方可以讀取該成員獲知發送方的身份。 |
|
size_t data_size; |
該成員表示data.buffer指向的緩衝區存放的數據長度。發送數據時由發送方填入,表示即將發送的數據長度;在接收方用來告知接收到數據的長度。 |
|
size_t offsets_size; |
驅動一般情況下不關心data.buffer裡存放什麼數據,但如果有Binder在其中傳輸則需要將其相對data.buffer的偏移位置指出來讓驅動知道。有可能存在多個Binder同時在數據中傳遞,所以須用陣列表示所有偏移位置。本成員表示該陣列的大小。 |
|
union { struct { const void *buffer; const void *offsets; } ptr; uint8_t buf[8]; } data; |
data.bufer存放要發送或接收到的數據;data.offsets指向Binder偏移位置陣列,該陣列可以位於data.buffer中,也可以在另外的記憶體空間中,並無限制。buf[8]是爲了無論保證32位元還是64位元平臺,成員data的大小都是8個位元組。 |
這裏有必要再強調一下offsets_size和data.offsets兩個成員,這是Binder通訊有別於其它IPC的地方。如前述,Binder採用物件導向的設計思想,一個Binder實體可以發送給其它進程從而建立許多跨進程的參照;另外這些參照也可以在進程之間傳遞,就象java裡將一個參照賦給另一個參照一樣。爲Binder在不同進程中建立參照必須有驅動的參與,由驅動在內核建立並註冊相關的數據結構後接收方纔能使用該參照。而且這些參照可以是強型別,需要驅動爲其維護參照計數。然而這些跨進程傳遞的Binder混雜在應用程式發送的數據包裡,數據格式由使用者定義,如果不把它們一一標記出來告知驅動,驅動將無法從數據中將它們提取出來。於是就使用陣列data.offsets存放用戶數據中每個Binder相對data.buffer的偏移量,用offsets_size表示這個陣列的大小。驅動在發送數據包時會根據data.offsets和offset_size將散落於data.buffer中的Binder找出來並一一爲它們建立相關的數據結構。在數據包中傳輸的Binder是型別爲struct flat_binder_object的結構體,詳見後文。
對於接收方來說,該結構只相當於一個定長的訊息頭,真正的用戶數據存放在data.buffer所指向的快取區中。如果發送方在數據中內嵌了一個或多個Binder,接收到的數據包中同樣會用data.offsets和offset_size指出每個Binder的位置和總個數。不過通常接收方可以忽略這些資訊,因爲接收方是知道數據格式的,參考雙方約定的格式定義就能知道這些Binder在什麼位置。
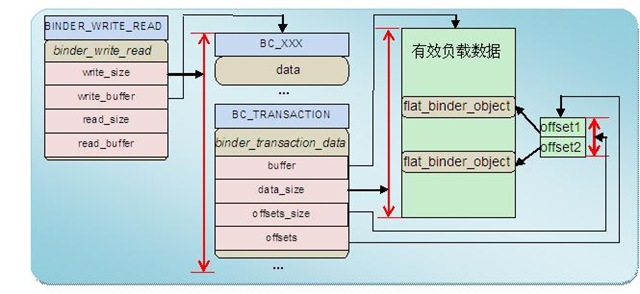
圖 2 BINDER_WRITE_READ數據包範例
5 Binder 的表述
考察一次Binder通訊的全過程會發現,Binder存在於系統以下幾個部分中:
· 應用程式進程:分別位於Server進程和Client進程中
· Binder驅動:分別管理爲Server端的Binder實體和Client端的參照
· 傳輸數據:由於Binder可以跨進程傳遞,需要在傳輸數據中予以表述
在系統不同部分,Binder實現的功能不同,表現形式也不一樣。接下來逐一探討Binder在各部分所扮演的角色和使用的數據結構。
5.1 Binder 在應用程式中的表述
雖然Binder用到了物件導向的思想,但並不限制應用程式一定要使用物件導向的語言,無論是C語言還是C++語言都可以很容易的使用Binder來通訊。例如儘管Android主要使用java/C++,象SMgr這麼重要的進程就是用C語言實現的。不過物件導向的方式表述起來更方便,所以本文假設應用程式是用物件導向語言實現的。
Binder本質上只是一種底層通訊方式,和具體服務沒有關係。爲了提供具體服務,Server必須提供一套介面函數以便Client通過遠端存取使用各種服務。這時通常採用Proxy設計模式:將介面函數定義在一個抽象類中,Server和Client都會以該抽象類爲基礎類別實現所有介面函數,所不同的是Server端是真正的功能實現,而Client端是對這些函數遠端呼叫請求的包裝。如何將Binder和Proxy設計模式結合起來是應用程式實現物件導向Binder通訊的根本問題。
5.1.1 Binder 在Server端的表述 – Binder實體
做爲Proxy設計模式的基礎,首先定義一個抽象介面類封裝Server所有功能,其中包含一系列純虛擬函式留待Server和Proxy各自實現。由於這些函數需要跨進程呼叫,须爲其一一編號,從而Server可以根據收到的編號決定呼叫哪個函數。其次就要引入Binder了。Server端定義另一個Binder抽象類處理來自Client的Binder請求數據包,其中最重要的成員是虛擬函式onTransact()。該函數分析收到的數據包,呼叫相應的介面函數處理請求。
接下來採用繼承方式以介面類和Binder抽象類爲基礎類別構建Binder在Server中的實體,實現基礎類別裡所有的虛擬函式,包括公共介面函數以及數據包處理常式:onTransact()。這個函數的輸入是來自Client的binder_transaction_data結構的數據包。前面提到,該結構裡有個成員code,包含這次請求的介面函數編號。onTransact()將case-by-case地解析code值,從數據包裡取出函數參數,呼叫介面類中相應的,已經實現的公共介面函數。函數執行完畢,如果需要返回數據就再構建一個binder_transaction_data包將返回數據包填入其中。
那麼各個Binder實體的onTransact()又是什麼時候呼叫呢?這就需要驅動參與了。前面說過,Binder實體須要以Binde傳輸結構flat_binder_object形式發送給其它進程才能 纔能建立Binder通訊,而Binder實體指針就存放在該結構的handle域中。驅動根據Binder位置陣列從傳輸數據中獲取該Binder的傳輸結構,爲它建立位於內核中的Binder節點,將Binder實體指針記錄在該節點中。如果接下來有其它進程向該Binder發送數據,驅動會根據節點中記錄的資訊將Binder實體指針填入binder_transaction_data的target.ptr中返回給接收執行緒。接收執行緒從數據包中取出該指針,reinterpret_cast成Binder抽象類並呼叫onTransact()函數。由於這是個虛擬函式,不同的Binder實體中有各自的實現,從而可以呼叫到不同Binder實體提供的onTransact()。
5.1.2 Binder 在Client端的表述 – Binder參照
做爲Proxy設計模式的一部分,Client端的Binder同樣要繼承Server提供的公共介面類並實現公共函數。但這不是真正的實現,而是對遠端函數呼叫的包裝:將函數參數打包,通過Binder向Server發送申請並等待返回值。爲此Client端的Binder還要知道Binder實體的相關資訊,即對Binder實體的參照。該參照或是由SMgr轉發過來的,對實名Binder的參照或是由另一個進程直接發送過來的,對匿名Binder的參照。
由於繼承了同樣的公共介面類,Client Binder提供了與Server Binder一樣的函數原型,使使用者感覺不出Server是執行在本地還是遠端。Client Binder中,公共介面函數的包裝方式是:建立一個binder_transaction_data數據包,將其對應的編碼填入code域,將呼叫該函數所需的參數填入data.buffer指向的快取中,並指明數據包的目的地,那就是已經獲得的對Binder實體的參照,填入數據包的target.handle中。注意這裏和Server的區別:實際上target域是個聯合體,包括ptr和handle兩個成員,前者用於接收數據包的Server,指向 Binder實體對應的記憶體空間;後者用於作爲請求方的Client,存放Binder實體的參照,告知驅動數據包將路由給哪個實體。數據包準備好後,通過驅動介面發送出去。經過BC_TRANSACTION/BC_REPLY回合完成函數的遠端呼叫並得到返回值。
5.2 Binder 在傳輸數據中的表述
Binder可以塞在數據包的有效數據中越進程邊界從一個進程傳遞給另一個進程,這些傳輸中的Binder用結構flat_binder_object表示,如下表所示:
表 6 Binder傳輸結構:flat_binder_object
|
成員 |
含義 |
|
unsigned long type |
表明該Binder的型別,包括以下幾種: BINDER_TYPE_BINDER:表示傳遞的是Binder實體,並且指向該實體的參照都是強型別; BINDER_TYPE_WEAK_BINDER:表示傳遞的是Binder實體,並且指向該實體的參照都是弱型別; BINDER_TYPE_HANDLE:表示傳遞的是Binder強型別的參照 BINDER_TYPE_WEAK_HANDLE:表示傳遞的是Binder弱型別的參照 BINDER_TYPE_FD:表示傳遞的是檔案形式的Binder,詳見下節 |
|
unsigned long flags |
該域只對第一次傳遞Binder實體時有效,因爲此刻驅動需要在內核中建立相應的實體節點,有些參數需要從該域取出: 第0-7位:程式碼中用FLAT_BINDER_FLAG_PRIORITY_MASK取得,表示處理本實體請求數據包的執行緒的最低優先順序。當一個應用程式提供多個實體時,可以通過該參數調整分配給各個實體的處理能力。 第8位元:程式碼中用FLAT_BINDER_FLAG_ACCEPTS_FDS取得,置1表示該實體可以接收其它進程發過來的檔案形式的Binder。由於接收檔案形式的Binder會在本進程中自動開啓檔案,有些Server可以用該標誌禁止該功能,以防開啓過多檔案。 |
|
union { void *binder; signed long handle; }; |
當傳遞的是Binder實體時使用binder域,指向Binder實體在應用程式中的地址。 當傳遞的是Binder參照時使用handle域,存放Binder在進程中的參照號。 |
|
void *cookie; |
該域只對Binder實體有效,存放與該Binder有關的附加資訊。 |
無論是Binder實體還是對實體的參照都從屬與某個進程,所以該結構不能透明地在進程之間傳輸,必須經過驅動翻譯。例如當Server把Binder實體傳遞給Client時,在發送數據流中,flat_binder_object中的type是BINDER_TYPE_BINDER,binder指向Server進程使用者空間地址。如果透傳給接收端將毫無用處,驅動必須對數據流中的這個Binder做修改:將type該成BINDER_TYPE_HANDLE;爲這個Binder在接收進程中建立位於內核中的參照並將參照號填入handle中。對於發生數據流中參照型別的Binder也要做同樣轉換。經過處理後接收進程從數據流中取得的Binder參照纔是有效的,纔可以將其填入數據包binder_transaction_data的target.handle域,向Binder實體發送請求。
這樣做也是出於安全性考慮:應用程式不能隨便猜測一個參照號填入target.handle中就可以向Server請求服務了,因爲驅動並沒有爲你在內核中建立該參照,必定會被驅動拒絕。唯有經過身份認證確認合法後,由‘權威機構’(Binder驅動)親手授予你的Binder才能 纔能使用,因爲這時驅動已經在內核中爲你使用該Binder做了註冊,交給你的參照號是合法的。
下表總結了當flat_binder_object結構穿過驅動時驅動所做的操作:
表 7 驅動對flat_binder_object的操作
|
Binder 型別( type 域) |
在發送方的操作 |
在接收方的操作 |
|
BINDER_TYPE_BINDER BINDER_TYPE_WEAK_BINDER |
只有實體所在的進程能發送該型別的Binder。如果是第一次發送驅動將建立實體在內核中的節點,並儲存binder,cookie,flag域。 |
如果是第一次接收該Binder則建立實體在內核中的參照;將handle域替換爲新建的參照號;將type域替換爲BINDER_TYPE_(WEAK_)HANDLE |
|
BINDER_TYPE_HANDLE BINDER_TYPE_WEAK_HANDLE |
獲得Binder參照的進程都能發送該型別Binder。驅動根據handle域提供的參照號查詢建立在內核的參照。如果找到說明參照號合法,否則拒絕該發送請求。 |
如果收到的Binder實體位於接收進程中:將ptr域替換爲儲存在節點中的binder值;cookie替換爲儲存在節點中的cookie值;type替換爲BINDER_TYPE_(WEAK_)BINDER。 如果收到的Binder實體不在接收進程中:如果是第一次接收則建立實體在內核中的參照;將handle域替換爲新建的參照號 |
|
BINDER_TYPE_FD |
驗證handle域中提供的開啓檔案號是否有效,無效則拒絕該發送請求。 |
在接收方建立新的開啓檔案號並將其與提供的開啓檔案描述結構系結。 |
5.2.1 檔案形式的 Binder
除了通常意義上用來通訊的Binder,還有一種特殊的Binder:檔案Binder。這種Binder的基本思想是:將檔案看成Binder實體,進程開啓的檔案號看成Binder的參照。一個進程可以將它開啓檔案的檔案號傳遞給另一個進程,從而另一個進程也打開了同一個檔案,就象Binder的參照在進程之間傳遞一樣。
一個進程開啓一個檔案,就獲得與該檔案系結的開啓檔案號。從Binder的角度,linux在內核建立的開啓檔案描述結構struct file是Binder的實體,開啓檔案號是該進程對該實體的參照。既然是Binder那麼就可以在進程之間傳遞,故也可以用flat_binder_object結構將檔案Binder通過數據包發送至其它進程,只是結構中type域的值爲BINDER_TYPE_FD,表明該Binder是檔案Binder。而結構中的handle域則存放檔案在發送方進程中的開啓檔案號。我們知道開啓檔案號是個侷限於某個進程的值,一旦跨進程就沒有意義了。這一點和Binder實體使用者指針或Binder參照號是一樣的,若要跨進程同樣需要驅動做轉換。驅動在接收Binder的進程空間建立一個新的開啓檔案號,將它與已有的開啓檔案描述結構struct file勾連上,從此該Binder實體又多了一個參照。新建的開啓檔案號覆蓋flat_binder_object中原來的檔案號交給接收進程。接收進程利用它可以執行read(),write()等檔案操作。
傳個檔案爲啥要這麼麻煩,直接將檔名用Binder傳過去,接收方用open()開啓不就行了嗎?其實這還是有區別的。首先對同一個開啓檔案共用的層次不同:使用檔案Binder開啓的檔案共用linux VFS中的struct file,struct dentry,struct inode結構,這意味着一個進程使用read()/write()/seek()改變了檔案指針,另一個進程的檔案指針也會改變;而如果兩個進程分別使用同一檔名開啓檔案則有各自的struct file結構,從而各自獨立維護檔案指針,互不幹 不乾擾。其次是一些特殊裝置檔案要求在struct file一級共用才能 纔能使用,例如android的另一個驅動ashmem,它和Binder一樣也是misc裝置,用以實現進程間的共用記憶體。一個進程開啓的ashmem檔案只有通過檔案Binder發送到另一個進程才能 纔能實現記憶體共用,這大大提高了記憶體共用的安全性,道理和Binder增強了IPC的安全性是一樣的。
5.3 Binder 在驅動中的表述
驅動是Binder通訊的核心,系統中所有的Binder實體以及每個實體在各個進程中的參照都登記在驅動中;驅動需要記錄Binder參照->實體之間多對一的關係;爲參照找到對應的實體;在某個進程中爲實體建立或查詢到對應的參照;記錄Binder的歸屬地(位於哪個進程中);通過管理Binder的強/弱參照建立/銷燬Binder實體等等。
驅動裡的Binder是什麼時候建立的呢?前面提到過,爲了實現實名Binder的註冊,系統必須建立第一隻雞–爲SMgr建立的,用於註冊實名Binder的Binder實體,負責實名Binder註冊過程中的進程間通訊。既然建立了實體就要有對應的參照:驅動將所有進程中的0號參照都預留給該Binder實體,即所有進程的0號參照天然地都指向註冊實名Binder專用的Binder,無須特殊操作即可以使用0號參照來註冊實名Binder。接下來隨着應用程式不斷地註冊實名Binder,不斷向SMgr索要Binder的參照,不斷將Binder從一個進程傳遞給另一個進程,越來越多的Binder以傳輸結構 - flat_binder_object的形式穿越驅動做跨進程的遷徙。由於binder_transaction_data中data.offset陣列的存在,所有流經驅動的Binder都逃不過驅動的眼睛。Binder將對這些穿越進程邊界的Binder做如下操作:檢查傳輸結構的type域,如果是BINDER_TYPE_BINDER或BINDER_TYPE_WEAK_BINDER則建立Binder的實體;如果是BINDER_TYPE_HANDLE或BINDER_TYPE_WEAK_HANDLE則建立Binder的參照;如果是BINDER_TYPE_HANDLE則爲進程開啓檔案,無須建立任何數據結構。詳細過程可參考表7。隨着越來越多的Binder實體或參照在進程間傳遞,驅動會在內核裡建立越來越多的節點或參照,當然這個過程對使用者來說是透明的。
5.3.1 Binder 實體在驅動中的表述
驅動中的Binder實體也叫‘節點’,隸屬於提供實體的進程,由struct binder_node結構來表示:
表 8 Binder節點描述結構:binder_node
|
成員 |
含義 |
|
int debug_id; |
用於偵錯 |
|
struct binder_work work; |
當本節點參照計數發生改變,需要通知所屬進程時,通過該成員掛入所屬進程的to-do佇列裡,喚醒所屬進程執行Binder實體參照計數的修改。 |
|
union { struct rb_node rb_node; struct hlist_node dead_node; }; |
每個進程都維護一棵紅黑樹,以Binder實體在使用者空間的指針,即本結構的ptr成員爲索引存放該進程所有的Binder實體。這樣驅動可以根據Binder實體在使用者空間的指針很快找到其位於內核的節點。rb_node用於將本節點鏈入該紅黑樹中。 銷燬節點時须將rb_node從紅黑樹中摘除,但如果本節點還有參照沒有切斷,就用dead_node將節點隔離到另一個鏈表中,直到通知所有進程切斷與該節點的參照後,該節點纔可能被銷燬。 |
|
struct binder_proc *proc; |
本成員指向節點所屬的進程,即提供該節點的進程。 |
|
struct hlist_head refs; |
本成員是佇列頭,所有指向本節點的參照都鏈接在該佇列裡。這些參照可能隸屬於不同的進程。通過該佇列可以遍歷指向該節點的所有參照。 |
|
int internal_strong_refs; |
用以實現強指針的計數器:產生一個指向本節點的強參照該計數就會加1。 |
|
int local_weak_refs; |
驅動爲傳輸中的Binder設定的弱參照計數。如果一個Binder打包在數據包中從一個進程發送到另一個進程,驅動會爲該Binder增加參照計數,直到接收進程通過BC_FREE_BUFFER通知驅動釋放該數據包的數據區爲止。 |
|
int local_strong_refs; |
驅動爲傳輸中的Binder設定的強參照計數。同上。 |
|
void __user *ptr; |
指向使用者空間Binder實體的指針,來自於flat_binder_object的binder成員 |
|
void __user *cookie; |
指向使用者空間的附加指針,來自於flat_binder_object的cookie成員 |
|
unsigned has_strong_ref; unsigned pending_strong_ref; unsigned has_weak_ref; unsigned pending_weak_ref |
這一組標誌用於控制驅動與Binder實體所在進程互動式修改參照計數 |
|
unsigned has_async_transaction; |
該成員表明該節點在to-do佇列中有非同步互動尚未完成。驅動將所有發送往接收端的數據包暫存在接收進程或執行緒開闢的to-do佇列裡。對於非同步互動,驅動做了適當流控:如果to-do佇列裡有非同步互動尚待處理則該成員置1,這將導致新到的非同步互動存放在本結構成員 – asynch_todo佇列中,而不直接送到to-do佇列裡。目的是爲同步互動讓路,避免長時間阻塞發送端。 |
|
unsigned accept_fds |
表明節點是否同意接受檔案方式的Binder,來自flat_binder_object中flags成員的FLAT_BINDER_FLAG_ACCEPTS_FDS位。由於接收檔案Binder會爲進程自動開啓一個檔案,佔用有限的檔案描述符,節點可以設定該位拒絕這種行爲。 |
|
int min_priority |
設定處理Binder請求的執行緒的最低優先順序。發送執行緒將數據提交給接收執行緒處理時,驅動會將發送執行緒的優先順序也賦予接收執行緒,使得數據即使跨了進程也能以同樣優先順序得到處理。不過如果發送執行緒優先順序過低,接收執行緒將以預設的最小值執行。 該域的值來自於flat_binder_object中flags成員。 |
|
struct list_head async_todo |
非同步互動等待佇列;用於分流發往本節點的非同步互動包 |
每個進程都有一棵紅黑樹用於存放建立好的節點,以Binder在使用者空間的指針作爲索引。每當在傳輸數據中偵測到一個代表Binder實體的flat_binder_object,先以該結構的binder指針爲索引搜尋紅黑樹;如果沒找到就建立一個新節點新增到樹中。由於對於同一個進程來說記憶體地址是唯一的,所以不會重複建設造成混亂。
5.3.2 Binder 參照在驅動中的表述
和實體一樣,Binder的參照也是驅動根據傳輸數據中的flat_binder_object建立的,隸屬於獲得該參照的進程,用struct binder_ref結構體表示:
表 9 Binder參照描述結構:binder_ref
|
成員 |
含義 |
|
int debug_id; |
偵錯用 |
|
struct rb_node rb_node_desc; |
每個進程有一棵紅黑樹,進程所有參照以參照號(即本結構的desc域)爲索引添入該樹中。本成員用做鏈接到該樹的一個節點。 |
|
struct rb_node rb_node_node; |
每個進程又有一棵紅黑樹,進程所有參照以節點實體在驅動中的記憶體地址(即本結構的node域)爲所引添入該樹中。本成員用做鏈接到該樹的一個節點。 |
|
struct hlist_node node_entry; |
該域將本參照做爲節點鏈入所指向的Binder實體結構binder_node中的refs佇列 |
|
struct binder_proc *proc; |
本參照所屬的進程 |
|
struct binder_node *node; |
本參照所指向的節點(Binder實體) |
|
uint32_t desc; |
本結構的參照號 |
|
int strong; |
強參照計數 |
|
int weak; |
弱參照計數 |
|
struct binder_ref_death *death; |
應用程式向驅動發送BC_REQUEST_DEATH_NOTIFICATION或BC_CLEAR_DEATH_NOTIFICATION命令從而當Binder實體銷燬時能夠收到來自驅動的提醒。該域不爲空表明使用者訂閱了對應實體銷燬的‘噩耗’。 |
就象一個物件有很多指針一樣,同一個Binder實體可能有很多參照,不同的是這些參照可能分佈在不同的進程中。和實體一樣,每個進程使用紅黑樹存放所有正在使用的參照。不同的是Binder的參照可以通過兩個鍵值索引:
· 對應實體在內核中的地址。注意這裏指的是驅動建立於內核中的binder_node結構的地址,而不是Binder實體在使用者進程中的地址。實體在內核中的地址是唯一的,用做索引不會產生二義性;但實體可能來自不同使用者進程,而實體在不同使用者進程中的地址可能重合,不能用來做索引。驅動利用該紅黑樹在一個進程中快速查詢某個Binder實體所對應的參照(一個實體在一個進程中只建立一個參照)。
· 參照號。參照號是驅動爲參照分配的一個32位元標識,在一個進程內是唯一的,而在不同進程中可能會有同樣的值,這和進程的開啓檔案號很類似。參照號將返回給應用程式,可以看作Binder參照在使用者進程中的控制代碼。除了0號參照在所有進程裡都固定保留給SMgr,其它值由驅動動態分配。向Binder發送數據包時,應用程式將參照號填入binder_transaction_data結構的target.handle域中表明該數據包的目的Binder。驅動根據該參照號在紅黑樹中找到參照的binder_ref結構,進而通過其node域知道目標Binder實體所在的進程及其它相關資訊,實現數據包的路由。
6 Binder 記憶體對映和接收快取區管理
暫且撇開Binder,考慮一下傳統的IPC方式中,數據是怎樣從發送端到達接收端的呢?通常的做法是,發送方將準備好的數據存放在快取區中,呼叫API通過系統呼叫進入內核中。內核服務程式在內核空間分配記憶體,將數據從發送方快取區複製到內核快取區中。接收方讀數據時也要提供一塊快取區,內核將數據從內核快取區拷貝到接收方提供的快取區中並喚醒接收執行緒,完成一次數據發送。這種儲存-轉發機制 機製有兩個缺陷:首先是效率低下,需要做兩次拷貝:使用者空間->內核空間->使用者空間。Linux使用copy_from_user()和copy_to_user()實現這兩個跨空間拷貝,在此過程中如果使用了高階記憶體(high memory),這種拷貝需要臨時建立/取消頁面對映,造成效能損失。其次是接收數據的快取要由接收方提供,可接收方不知道到底要多大的快取纔夠用,只能開闢儘量大的空間或先呼叫API接收訊息頭獲得訊息體大小,再開闢適當的空間接收訊息體。兩種做法都有不足,不是浪費空間就是浪費時間。
Binder採用一種全新策略:由Binder驅動負責管理數據接收快取。我們注意到Binder驅動實現了mmap()系統呼叫,這對字元裝置是比較特殊的,因爲mmap()通常用在有物理儲存媒介的檔案系統上,而象Binder這樣沒有物理媒介,純粹用來通訊的字元裝置沒必要支援mmap()。Binder驅動當然不是爲了在物理媒介和使用者空間做對映,而是用來建立數據接收的快取空間。先看mmap()是如何使用的:
fd = open("/dev/binder", O_RDWR);
mmap(NULL, MAP_SIZE, PROT_READ, MAP_PRIVATE, fd, 0);
這樣Binder的接收方就有了一片大小爲MAP_SIZE的接收快取區。mmap()的返回值是記憶體對映在使用者空間的地址,不過這段空間是由驅動管理,使用者不必也不能直接存取(對映型別爲PROT_READ,只讀對映)。
接收快取區對映好後就可以做爲快取池接收和存放數據了。前面說過,接收數據包的結構爲binder_transaction_data,但這只是訊息頭,真正的有效負荷位於data.buffer所指向的記憶體中。這片記憶體不需要接收方提供,恰恰是來自mmap()對映的這片快取池。在數據從發送方向接收方拷貝時,驅動會根據發送數據包的大小,使用最佳匹配演算法從快取池中找到一塊大小合適的空間,將數據從發送快取區複製過來。要注意的是,存放binder_transaction_data結構本身以及表4中所有訊息的記憶體空間還是得由接收者提供,但這些數據大小固定,數量也不多,不會給接收方造成不便。對映的快取池要足夠大,因爲接收方的執行緒池可能會同時處理多條併發的互動,每條互動都需要從快取池中獲取目的儲存區,一旦快取池耗竭將產生導致無法預期的後果。
有分配必然有釋放。接收方在處理完數據包後,就要通知驅動釋放data.buffer所指向的記憶體區。在介紹Binder協定時已經提到,這是由命令BC_FREE_BUFFER完成的。
通過上面介紹可以看到,驅動爲接收方分擔了最爲繁瑣的任務:分配/釋放大小不等,難以預測的有效負荷快取區,而接收方只需要提供快取來存放大小固定,最大空間可以預測的訊息頭即可。在效率上,由於mmap()分配的記憶體是對映在接收方使用者空間裡的,所有總體效果就相當於對有效負荷數據做了一次從發送方使用者空間到接收方使用者空間的直接數據拷貝,省去了內核中暫存這個步驟,提升了一倍的效能。順便再提一點,Linux內核實際上沒有從一個使用者空間到另一個使用者空間直接拷貝的函數,需要先用copy_from_user()拷貝到內核空間,再用copy_to_user()拷貝到另一個使用者空間。爲了實現使用者空間到使用者空間的拷貝,mmap()分配的記憶體除了對映進了接收方進程裡,還對映進了內核空間。所以呼叫copy_from_user()將數據拷貝進內核空間也相當於拷貝進了接收方的使用者空間,這就是Binder只需一次拷貝的‘祕密’。
7 Binder 接收執行緒管理
Binder通訊實際上是位於不同進程中的執行緒之間的通訊。假如進程S是Server端,提供Binder實體,執行緒T1從Client進程C1中通過Binder的參照向進程S發送請求。S爲了處理這個請求需要啓動執行緒T2,而此時執行緒T1處於接收返回數據的等待狀態。T2處理完請求就會將處理結果返回給T1,T1被喚醒得到處理結果。在這過程中,T2彷彿T1在進程S中的代理,代表T1執行遠端任務,而給T1的感覺就是象穿越到S中執行一段程式碼又回到了C1。爲了使這種穿越更加真實,驅動會將T1的一些屬性賦給T2,特別是T1的優先順序nice,這樣T2會使用和T1類似的時間完成任務。很多資料會用‘執行緒遷移’來形容這種現象,容易讓人產生誤解。一來執行緒根本不可能在進程之間跳來跳去,二來T2除了和T1優先順序一樣,其它沒有相同之處,包括身份,開啓檔案,棧大小,信號處理,私有數據等。
對於Server進程S,可能會有許多Client同時發起請求,爲了提高效率往往開闢執行緒池併發處理收到的請求。怎樣使用執行緒池實現併發處理呢?這和具體的IPC機制 機製有關。拿socket舉例,Server端的socket設定爲偵聽模式,有一個專門的執行緒使用該socket偵聽來自Client的連線請求,即阻塞在accept()上。這個socket就象一隻會生蛋的雞,一旦收到來自Client的請求就會生一個蛋 – 建立新socket並從accept()返回。偵聽執行緒從執行緒池中啓動一個工作執行緒並將剛下的蛋交給該執行緒。後續業務處理就由該執行緒完成並通過這個單與Client實現互動。
可是對於Binder來說,既沒有偵聽模式也不會下蛋,怎樣管理執行緒池呢?一種簡單的做法是,不管三七二十一,先建立一堆執行緒,每個執行緒都用BINDER_WRITE_READ命令讀Binder。這些執行緒會阻塞在驅動爲該Binder設定的等待佇列上,一旦有來自Client的數據驅動會從佇列中喚醒一個執行緒來處理。這樣做簡單直觀,省去了執行緒池,但一開始就建立一堆執行緒有點浪費資源。於是Binder協定引入了專門命令或訊息幫助使用者管理執行緒池,包括:
· INDER_SET_MAX_THREADS
· BC_REGISTER_LOOP
· BC_ENTER_LOOP
· BC_EXIT_LOOP
· BR_SPAWN_LOOPER
首先要管理執行緒池就要知道池子有多大,應用程式通過INDER_SET_MAX_THREADS告訴驅動最多可以建立幾個執行緒。以後每個執行緒在建立,進入主回圈,退出主回圈時都要分別使用BC_REGISTER_LOOP,BC_ENTER_LOOP,BC_EXIT_LOOP告知驅動,以便驅動收集和記錄當前執行緒池的狀態。每當驅動接收完數據包返回讀Binder的執行緒時,都要檢查一下是不是已經沒有閒置執行緒了。如果是,而且執行緒總數不會超出線程池最大執行緒數,就會在當前讀出的數據包後面再追加一條BR_SPAWN_LOOPER訊息,告訴使用者執行緒即將不夠用了,請再啓動一些,否則下一個請求可能不能及時響應。新執行緒一啓動又會通過BC_xxx_LOOP告知驅動更新狀態。這樣只要執行緒沒有耗盡,總是有空閒執行緒在等待佇列中隨時待命,及時處理請求。
關於工作執行緒的啓動,Binder驅動還做了一點小小的優化。當進程P1的執行緒T1向進程P2發送請求時,驅動會先檢視一下執行緒T1是否也正在處理來自P2某個執行緒請求但尚未完成(沒有發送回覆 回復)。這種情況通常發生在兩個進程都有Binder實體並互相對發時請求時。假如驅動在進程P2中發現了這樣的執行緒,比如說T2,就會要求T2來處理T1的這次請求。因爲T2既然向T1發送了請求尚未得到返回包,說明T2肯定(或將會)阻塞在讀取返回包的狀態。這時候可以讓T2順便做點事情,總比等在那裏閒着好。而且如果T2不是執行緒池中的執行緒還可以爲執行緒池分擔部分工作,減少執行緒池使用率。
8 數據包接收佇列與(執行緒)等待佇列管理
通常數據傳輸的接收端有兩個佇列:數據包接收佇列和(執行緒)等待佇列,用以緩解供需矛盾。當超市裏的進貨(數據包)太多,貨物會堆積在倉庫裡;購物的人(執行緒)太多,會排隊等待在收銀臺,道理是一樣的。在驅動中,每個進程有一個全域性的接收佇列,也叫to-do佇列,存放不是發往特定執行緒的數據包;相應地有一個全域性等待佇列,所有等待從全域性接收佇列裡收數據的執行緒在該佇列裡排隊。每個執行緒有自己私有的to-do佇列,存放發送給該執行緒的數據包;相應的每個執行緒都有各自私有等待佇列,專門用於本執行緒等待接收自己to-do佇列裡的數據。雖然名叫佇列,其實執行緒私有等待佇列中最多隻有一個執行緒,即它自己。
由於發送時沒有特別標記,驅動怎麼判斷哪些數據包該送入全域性to-do佇列,哪些數據包該送入特定執行緒的to-do佇列呢?這裏有兩條規則。規則1:Client發給Server的請求數據包都提交到Server進程的全域性to-do佇列。不過有個特例,就是上節談到的Binder對工作執行緒啓動的優化。經過優化,來自T1的請求不是提交給P2的全域性to-do佇列,而是送入了T2的私有to-do佇列。規則2:對同步請求的返回數據包(由BC_REPLY發送的包)都發送到發起請求的執行緒的私有to-do佇列中。如上面的例子,如果進程P1的執行緒T1發給進程P2的執行緒T2的是同步請求,那麼T2返回的數據包將送進T1的私有to-do佇列而不會提交到P1的全域性to-do佇列。
數據包進入接收佇列的潛規則也就決定了執行緒進入等待佇列的潛規則,即一個執行緒只要不接收返回數據包則應該在全域性等待佇列中等待新任務,否則就應該在其私有等待佇列中等待Server的返回數據。還是上面的例子,T1在向T2發送同步請求後就必須等待在它私有等待佇列中,而不是在P1的全域性等待佇列中排隊,否則將得不到T2的返回的數據包。
這些潛規則是驅動對Binder通訊雙方施加的限制條件,體現在應用程式上就是同步請求互動過程中的執行緒一致性:1) Client端,等待返回包的執行緒必須是發送請求的執行緒,而不能由一個執行緒發送請求包,另一個執行緒等待接收包,否則將收不到返回包;2) Server端,發送對應返回數據包的執行緒必須是收到請求數據包的執行緒,否則返回的數據包將無法送交發送請求的執行緒。這是因爲返回數據包的目的Binder不是使用者指定的,而是驅動記錄在收到請求數據包的執行緒裡,如果發送返回包的執行緒不是收到請求包的執行緒驅動將無從知曉返回包將送往何處。
接下來探討一下Binder驅動是如何遞交同步互動和非同步互動的。我們知道,同步互動和非同步互動的區別是同步互動的請求端(client)在發出請求數據包後須要等待應答端(Server)的返回數據包,而非同步互動的發送端發出請求數據包後互動即結束。對於這兩種互動的請求數據包,驅動可以不管三七二十一,統統丟到接收端的to-do佇列中一個個處理。但驅動並沒有這樣做,而是對非同步互動做了限流,令其爲同步互動讓路,具體做法是:對於某個Binder實體,只要有一個非同步互動沒有處理完畢,例如正在被某個執行緒處理或還在任意一條to-do佇列中排隊,那麼接下來發給該實體的非同步互動包將不再投遞到to-do佇列中,而是阻塞在驅動爲該實體開闢的非同步互動接收佇列(Binder節點的async_todo域)中,但這期間同步互動依舊不受限制直接進入to-do佇列獲得處理。一直到該非同步互動處理完畢下一個非同步互動方可以脫離非同步互動佇列進入to-do佇列中。之所以要這麼做是因爲同步互動的請求端需要等待返回包,必須迅速處理完畢以免影響請求端的響應速度,而非同步互動屬於‘發射後不管’,稍微延時一點不會阻塞其它執行緒。所以用專門佇列將過多的非同步互動暫存起來,以免突發大量非同步互動擠佔Server端的處理能力或耗盡執行緒池裏的執行緒,進而阻塞同步互動。
9 總結
Binder使用Client-Server通訊方式,安全性好,簡單高效,再加上其物件導向的設計思想,獨特的接收快取管理和執行緒池管理方式,成爲Android進程間通訊的中流砥柱。
版權宣告:本文爲博主原創文章,遵循 CC 4.0 BY-SA 版權協定,轉載請附上原文出處鏈接和本宣告。
本文鏈接:https://blog.csdn.net/universus/article/details/6211589