數據倉庫ETL工具箱——元數據
由於ETL是數據倉庫得核心,時常承擔着管理和儲存數據倉庫大量元數據得職責。在數據倉庫中ETL處理程式是元數據最重要得建立者——數據沿襲。數據沿襲追蹤數據從源系統和檔案中得請確位置直到最終被裝載之前。數據血統包括數據庫系統的數據定義和在數據參考古中最終靜止狀態。元數據分爲後臺元數據和前端元數據,後臺元數據是與處理相關的,指導抽取清洗裝載工作;前端元數據更偏向描述性和使我們的查詢工具和報表工具更加穩定。後臺將數據載入到數據倉庫,同時指明數據來源,而前端元數據主要是爲終端使用者服務的,可以作爲描述所有數據的業務數據字典。對於元數據應該進行以下工作:
- 制定完善的良好的註釋目錄
- 判定每一部分究竟有多重要
- 指定專人負責
- 判定一個和諧一致的工作規則
- 判定是否自己構建還是購買
- 專門儲存用以備份和恢復
- 對需要他們的人們開放
- 保證品質,保證完整和及時更新
- 實時控制
以上各項任務都需要完善的文件。數據源規範:
- 知識庫
- 來源計劃
- 拷貝記錄
- 所有權或第三方來源計劃
- 存檔主機數據的原有格式
- 相關源系統數據表和DDL
- 電子數據表
- Lotus Notes 數據庫
- 表達圖形
- URL來源規格說明
- 來源描述資訊:
1.各來源的所有描述資訊
2.各來源的業務描述
3.最初來源的更新頻率
4.各來源使用的司法侷限性
5.儲存方法,讀取許可權,和各來源存取口令
- 處理資訊
6.主機或源系統工作計劃
7.使用COBLO/JCL或C或Basic或其它語言來實現抽取
8.如果使用工具,則包含自動化抽取工具的設定
9.特殊抽取的結果,包括抽取時間和工作完成率
關於元數據的描述,數據需要的資訊:
- 數據傳輸計劃和特殊傳輸結果
- 數據傳送區的檔案用法,包括持續時間消耗和所有者資訊
維度表管理:
- 規範化維度的定義和規範化事實的定義
- 關聯源的Job規範,剝除域,查詢屬性
- 降低每一個引入描述屬性維度規則的變化速度
- 每一個生產鍵所分配的當前代理鍵,也包括記憶體中執行對映的查詢表
- 前一天生產維度的副本,最爲比較差的基礎
轉換和聚合:
- 數據清洗規範
- 數據增加和對映轉換
- 爲數據挖掘所準備的數據轉換
- 目標計劃涉及,源和目標數據流,和目標數據所有權
- 數據庫管理系統的匯入指令碼
- 聚合定義
- 聚合用法統計,基礎數據表使用統計,以及潛在的聚合
- 聚合更改日誌
審計,工作日誌和文件:
- 數據沿襲和審計記錄
- 數據轉換時間日誌
- 數據轉換執行時間日誌,成功記錄摘要,時間戳
- 數據軟體版本號
- 抽取過程的業務描述
- 抽取檔案,抽取軟體和抽取元數據的安全設定
- 數據轉換的安全設定(授權口令)
- 數據分段傳送區存檔檔案日誌和恢復進程
- 數據分段傳送區存檔檔案日誌安全設定
DBMS元數據中作用在以下部分:
- 數據庫管理系統系統表目錄
- 分割區設定
- 索引
- 磁碟帶區規範
- 程式處理提示
- 數據庫管理系統級別和安全的許可權和授權
- 檢視的定義
- 儲存過程和SQL管理指令碼
- 數據庫備份,狀態備份程式和備份安全性
在前端擴充套件的元數據包括:
- 縱列表分組的業務名稱和描述等等
- 模糊查詢和報表定義
- 連線規範工具設定
- 靈活列印規範說明
- 終端使用者文件和培訓幫助,包括供應商提供和IT提供
- 網路安全使用者授權
- 網路安全鑑定證數
- 網路安全使用統計,包括試圖讀取的日誌和使用者ID
- 個人使用者描述包括人力資源鏈接
- 提高影響讀取許可權的傳輸流暢性
- 連線到合約人和合作者可以追蹤讀取許可權的影響範圍
- 數據原理,數據庫表,和檢視報告的使用和讀取對映
- 資源回收統計
- 收藏的網頁
元數據包括了所有,從某種程度上來說,元數據是數據倉庫的DNA,它定義了所有元素及元素之間協同工作的方式。元數據可以分爲以下三類:
- 業務元數據,在業務層面描述數據的含義
- 技術元數據,描繪數據的技術方麪包括數據的屬性,如數據型別、長度、沿襲及評估統計等
- 過程處理元數據,介紹執行ETL處理的統計資訊,包括度量標準比如記錄匯入成功,記錄丟失,處理時間等等
除了這三種元數據之外,還應該考慮元數據的標準,數據倉庫後端的元數據流程如下圖:
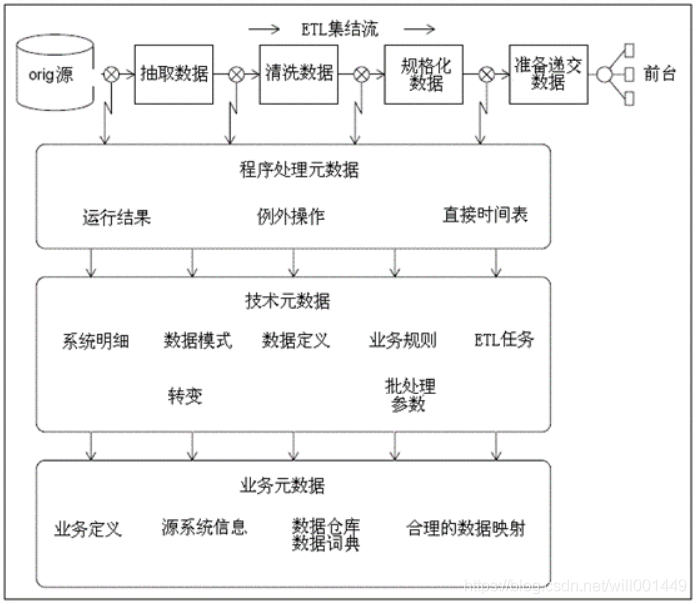
上圖描述了使用和收集的元數據的所有地方,包括:
- 每一個數據階段的起源和處理步驟
- 元數據資料庫作爲第三方ETL工具的一個有利條件
- 元數據需求構架:源表,清洗和處理
- 爲終端使用者介紹有用的元數據
- 抽取轉換應用
- 規範化元數據
- 元數據的XML描述
- 平面檔案中元數據的缺失
- 分析元數據的效果
- 計劃建立描述沿襲的元數據,業務定義,技術定義以及處理過程
- 邏輯數據檢視
- 抽取過程中源數據的捕獲計算
- 源數據庫描述
- ETL工具讀取ERP系統元數據
- 數據評估的結果
- 錯誤事件跟蹤事實表
- 審計維度
- 代理鍵最高值
- 聚合數據
- 處理數據搭建OLAP架構
- 裝載到控制檔案
- 支援恢復處理的元數據
- ETL參數
- 任務依賴
- 任務操作性統計,如效能和資源的使用
- 元數據資料庫報告
- 數據表淨化規則
業務定義對於數據倉庫至關重要,不僅是終端使用者需要業務定義,ETL也需要業務定義來給出正在操作數據的上下文關係。一個典型的業務定義矩陣包括3個主要組成部分:
- 物理表和列名稱,數據參控股中數據元素的業務解釋是基於數據庫中真實的表和列名稱。
- 業務列名稱,數據庫所儲存的數據元素在技術上是由字首後綴和下劃線組成的。業務名稱需要技術性名稱和有實際意義名稱之間的翻譯
- 業務定義,業務定義是指對業務屬性含義的描述。數據倉庫中每個屬性一定會有一個業務定義。
所有ETL工具都支援捕獲和儲存元數據,ETL工具應該和數據模型工具、數據庫一起獲得業務定義,並通過BI工具把業務名稱和業務定義展現給終端使用者。
數據在匯入數據倉庫前需要進行分析,指定數據改造計劃,使數據能夠較爲理想的被匯入到數據倉庫中,在分析源系統時,需要以下元數據屬性:
數據庫或檔案系統,當涉及到源系統或檔案的時候經常用到這個屬性
表規範,包括表的用途,表的大小,主鍵和預備鍵以及所有列的清單
排異處理規則
業務定義
業務規則,針對於每張表都要有相應的業務規則
在數據倉庫專案中,數據分析階段需要大量時間研究源系統,缺少源系統元數據和導致數據倉庫更多的故障,所有源系統的元數據必須在ETL開發之前提供給ETL團隊。
數據倉庫的數據字典時關於所有數據元素和他們業務定義的清單,與源系統業務定義相似,數據倉庫數據字典包括物理表和列名稱,業務名稱和業務定義。
邏輯數據檢視時ETL的生命線,從元數據的角度上看,邏輯數據檢視是由從源到目的的對映,從邏輯上解釋了數據從源系統中抽取出來到裝載到數據倉庫中的整個流程。邏輯數據對映是元數據的重要部分。
技術元數據服務於多種用途,它包括了到列名稱,數據型別,儲存和RAID矩陣的設定,需要瞭解數據倉庫中數據元素的物理模型及屬性。數據的技術定義是數據的容器和框架結構,必須瞭解數據定義的三種環境:
- 源數據庫
- 分段處理區域表
- 數據倉庫展現區
每個環境都應該被提供一個E-R圖,每個系統至少要包含以下元素:
- 表:表或檔案的一份詳盡清單,這份清單有可能在抽取和裝載過程中使用,通常這份清單隻提供邏輯數據對映的源系統數據表
- 列:對於每張表,都需要一張數據對映所要求列的清單,由源系統的DBA提供
- 數據型別:數據表的每一列都有一個數據型別,在不同數據庫系統中有些數據型別不盡相同,大部分ETL工具可以轉換相應的數據型別
- 關係型數據庫:關係型數據庫支援參照完整性,參照完整性和表之間的關聯關係能夠保證數據匯入的唯一一致性,數據之間的關聯關係是通過表與表之間的主外來鍵連線展示的
每一個潛在的數據儲存中的數據定義應該是一致的。數據每一次進入數據庫或者進入檔案後,數據品質很容易發生變化。如果在各個環境中的數據定義各不相同,則需要在ETL系統中進行轉換來避免數據不一致,必須要有下列數據定義的元數據內容:
- 表名稱:表和檔案的物理名稱
- 列名稱:表和檔案中列的物理名稱
- 數據型別:數位型、字元型、日期型、二進制以及自定義數據型別
- 域:數值要進入的列被稱爲域,域通過外來鍵和檢查約束或數據庫頂端應用來執行
- 參照完整性:數據倉庫中的參照完整性被認爲不是必要的,因爲所有的數據都是經過ETL處理以受約束的形式進入數據庫的,在數據庫級不需要強制的完整性約束
- 約束:約束時業務規則的另一種物理執行,數據庫約束可以消除空值,爭搶外來鍵查詢等
- 預設值:萬一實際值是不可獲取的,ETL元數據的預設值可以分配爲字串型別,數位型,日期型或bit型。在源系統中,預設值經常被分配爲數據庫級別的。在數據倉庫中,預設值的指派發生在ETL處理中,數據倉庫中的預設值最好堅持始終如一的一致性
- 儲存過程:儲存過程儲存了已經在數據庫中寫好的SQL語句,可以通過儲存過程看到源數據是如何使用的,每個數據倉庫專案都要涉及到源系統的分析型儲存過程
- 觸發:當數據庫系統中的記錄要增加,刪除或更新時通過觸發自動執行SQL程式。像儲存過程一樣,通過觸發器,也可以指導數據時如何使用的。觸發經常通過向加入到表中的數據增加額外的檢查來增強外來鍵約束。當表中的數據發生變化或被刪除時,觸發還承擔審覈表的責任,審覈表時數據倉庫中刪除數據的重要審覈來源。
業務規則可以分爲業務或技術源數據,多有的業務規則都要以彪馬的形式被包含在ETL過程中,業務規則可以包括起始域中的任何允許值、預設值和計算。在源系統中,業務規則在儲存過程、強制約束或數據庫觸發中被執行,但是業務規則還是最常出現在應用程式中。業務規則的元數據會在功能性或者技術性文件和本地程式語言的原始碼或虛擬碼之間進行改變。業務規則必須和邏輯數據檢視緊密結合在一起,有時業務規則會在邏輯數據檢視中被忽略,直到執行完第一次ETL處理之後才被人注意,或被使用者在UAT中發現。當有新的業務規則是,邏輯數據檢視的元數據必須更新來反映新的規則。
當ETL物理程式被建立之後,一定要生成明確的元數據來捕獲每個處理的內部工作,ETL元數據可以被分爲四類:
- ETL任務元數據:任務元數據包含了數據倉庫中各元素數據沿襲
- 轉換元數據:每個任務都由多個轉換組成,任務中數據處理的任何形式都是由專門轉換工作來執行的
- 批次處理元數據:批次處理時一種執行任務集合的技術,應該具有設定執行連續性和並行處理的能力,包含分支批次處理
- 處理元數據:每當執行批次處理,就會生成處理元數據,對於描述數據是否被陳工裝載到的數據倉庫中,處理元數據非常重要
下圖展現了ETL任務元數據被建立,儲存和發佈的元素:

- 任務名稱:物理ETL任務名稱
- 任務用途:最初中心任務的簡要描述
- 源表/檔案:所有源數據的名稱和路徑位置
- 目的表/檔案:在轉換完成之後所有結果數據的名稱和目錄路徑
- 丟棄檔名稱:丟棄檔案的名稱和路徑位置(在裝載過程中沒有載入目的地址的數據表或檔案稱爲丟棄檔案)
- 預處理前置任務:在任務被執行之前需要處理任務或指令碼
- 後置任務:在任務處理之後需要執行的任務或指令碼
任務是一系列轉換的集合,這些轉換執行物理上的抽取、轉換和裝載程式。一個任務的元數據是物理的源到目的對映,任務應該根據裝載的目標表或檔案來命名,ETL任務大致上可以分爲三類:
- 抽取,EXT_<table_name>,從名稱中看出這個任務的主要目的是從源系統中抽取數據
- 中間階段,STG_<table_name>,是一個數據存在於集結區的中間過程
- 目標,TRG_<table_name>意味着任務是裝載數據到目標數據倉庫的
轉換元數據是關於ETL處理構造的資訊,轉換是由客戶化函數,儲存程序,常規程式組成的,這些程式包含了指針、回圈、記憶體變數。在ETL處理過程中的任何對數據的操作都被認爲是轉換。專門的ETL工具爲數據倉庫環境預先定義了通用轉換,並把他們打包提供給使用者。預先建立的轉換加速了ETL的開發,而且還可以在暗中捕獲轉換元數據。在大部分ETL任務中的通用數據轉換包括:
- 源數據抽取
- 代理鍵生成器
- 查詢
- 篩選
- 路由器
- 聯合
- 聚合
- 異構連線
- 更新策略
- 目標裝載器
每個轉換獲得數據,操作數據的程度,然後傳送數據到任務佇列中進行下一個轉換,描述轉換的元數據屬性包括:
- 轉換名稱
- 轉換的意圖
- 輸入列
- 物理計算
- 邏輯計算
- 輸出列
轉換是ETL任務的一個構成部分,每種轉換在名命格式上都會稍有不同,由於可維護性的原因,在建立ETL轉換時最好遵從以下名命規則:
- 源數據抽取:SRC_<table_name>
- 代理鍵生成器:SEQ_<table_name>
- 查詢:LKP_<正在載入或參照的table_name>
- 篩選:FIL_<用途>
- 聚合:AGG_<用途>
- 異構連線:HJN_<第一張table_name>_<第二張table_name>
- 更新策略:UPD_<操作型別(INS,UPD,DEL,UPS)>_<標記table_name>
- 目標裝載器:TRG_<標記表名>
裝載進度取決於以下因素:
- 依賴的批次處理
- 頻度
- 執行進度
- 恢復步驟
數據倉庫中所有的處理元數據都是由ETL過程生成的,每次一個任務或批次處理執行,統計或成功指示器都需要被捕獲。匯入統計是元數據的一個重要部分。元數據元素可以幫助理解ETL任務中的活動和批次處理或評估成功的處理:
- 主題名稱:可以是數據集市或者描述爲某個特定區域而執行批次處理
- 任務名稱:執行程式的名稱
- 處理行:從源數據系統中讀取或處理的行數統計和百分比統計
- 成功行數:裝載到數據倉庫中數據的總數和百分比
- 失敗行數:被數據倉庫拒絕的數據總數和百分比
- 最近錯誤程式碼:在數據裝載過程中,最近的數據庫或者ETL異常的錯誤程式碼
- 最近錯誤:最近錯誤的文字描述
- 讀取能力:用來衡量ETL處理效能的,用行/秒來描述,當源系統讀取發生瓶頸時,記錄讀取能力
- 寫能力:用來衡量ETL處理效能的,用行/秒來描述
- 開始時間:任務開始時的日期,時間和分秒
- 結束時間:任務結束時的日期,時間和分秒,不考慮任務是否成功
- 耗時:效能分析的重要指標
- 原始檔名稱:ETL抽取涉及的數據的表或檔案的名稱
- 目標檔名稱:ETL涉及目標的數據的表或檔名稱
處理執行元數據在數據儲存中保留,以便進行趨勢分析,分析元數據可以發現ETL處理的瓶頸,可以保證數據倉庫效能的可控性,同時也可以衡量數據品質。
- 在執行過程中,可能引起數據記錄異常條件,可以採取以下措施:
- 主題名稱:可以是數據集市或關於批次處理的描述
- 任務名稱:執行程式的名稱
- 異常條件:異常條件的標準設定
- 嚴重性
- 採取措施
- 操作員
- 結果
批次處理是一系列要執行的ETL任務排程的集合,批次處理的名稱應該可以反應出其所屬主題,任務執行的頻率和任務中批次處理執行方式是並行還是序列。
爲了維護企業級數據倉庫所有ETL過程中可管理的任務,數據倉庫必須要建立標準,制定時考慮下列標準:
- 命名習慣
- 體系結構
- 基礎構造
維護ETL元數據的一個有利條件是元數據可以進行效果分析,通過效果分析,可以列出數據倉庫環境中的所有可以改變的特徵,還可以分析這些變化所帶來的影響。ETL工具要記錄源系統所有表,列到他們裝載到數據倉庫中的所有資訊。
本篇介紹了元數據的分類,至此所有數據倉庫中關於ETL工具的技術內容全部介紹完畢,下一篇將介紹ETL小組的職責作爲本書內容的收官之比。