聊聊Redis
聊聊Redis
1、 NoSql概述
1.1、 爲什麼要用nosql
要瞭解NoSql的背景,首先要先簡單瞭解下架構的演進。
- 單機MySQL時代

在這個階段,一個網站的存取量基本不會太大,單機的MySql完全足夠用了。
更多的是使用靜態頁面Html~,伺服器沒有什麼太大的壓力
這個階段的瓶頸就是:
1、 如果數據量太大話,一個機器放不下;
2、 數據的索引(B+Tree),一個機器也放不下
3、 存取量太大(包含讀寫操作),一個伺服器承受不了
-
Memcached快取 + MySql + 垂直拆分
網站80%都是在讀,只有20%的寫操作,如果每次重複去查詢數據庫就會十分的麻煩,這個時候我們可以用快取來保證查詢的效率。
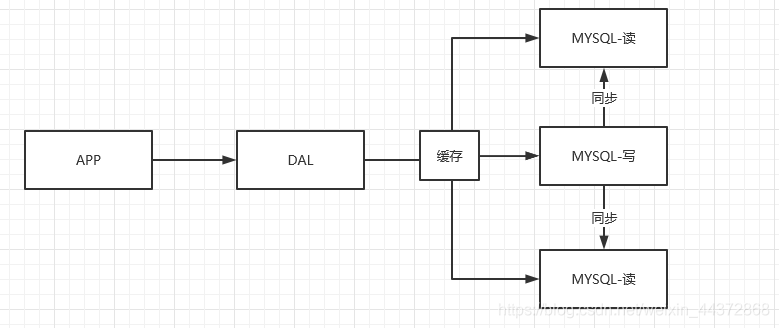
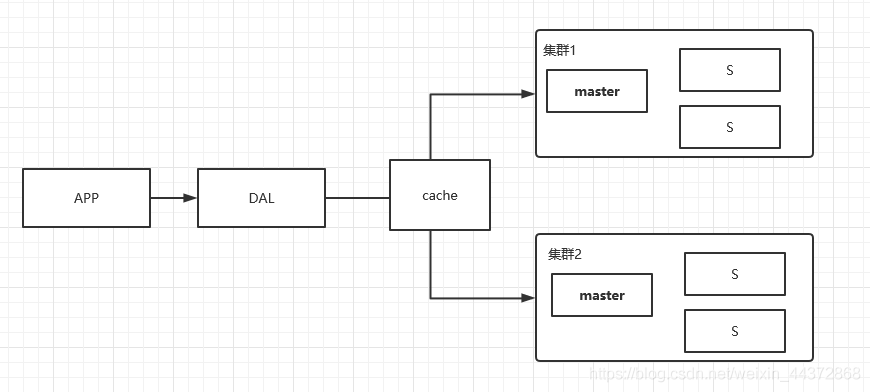
- 分庫分表 + 水平拆分 + MySql叢集
1.2、什麼是NoSql
not only sql (不僅僅是sql), 泛指非關係型數據庫。
具有如下幾個特點:
-
拓展性強, 數據之間沒有關係,容易拓展
-
大數據量高效能 (Redis一秒鐘可以寫8萬次,讀11萬次)
-
數據型別多樣性(5中基本型別和3種特殊型別)
-
NoSql和關係型數據庫的區別:
RDBMS - 結構化組織(表、列) - SQL - 數據和關係都存在單獨的表中 - 數據操作, 數據定義語言 - 嚴格的一致性 - 基礎的事務 ...NoSql - 不僅僅是數據 - 沒有固定的查詢語言 - 鍵值對儲存、列儲存、文件儲存、圖形數據庫(社交關係) - 最終一致性 - CAP理論和BASE (異地多活) - 高效能 高可用 高可擴 - ...
1.3、 NoSql的四大分類
key-value鍵值對:
- 新浪:redis
- 美團: redis+Tair
- 阿裡百度: redis + memecache
文件型數據庫(bson (和json的格式一樣))
- MongoDB 是一個基於分佈式檔案的數據庫, c++編寫,主要是爲了處理大量的文件
- MongoDb是一種介於關係型數據庫和非關係型數據庫的中間產物
列儲存數據庫
- HBase
- 分佈式檔案系統
圖形關係數據庫(拓撲圖)
- Neo4j
- InofGrid
2、 Redis入門
1、 概述
Redis(Remote Dictionary Server),即遠端字典服務
是一個開源的使用ANSI C語言編寫、支援網路、可基於記憶體亦可持久化的日誌型、Key-Value型的數據庫,並提供了多種語言的API。
也被人們稱之爲結構化數據庫。
Redis會週期性的把更新的數據寫入磁碟或修改操作寫入追加的記錄檔案,並在此基礎上實現了
master-slave(主從)同步。
2、 用途
- 記憶體儲存、持久化
- 效率高、可用於快取記憶體
- 發佈訂閱系統
- 地圖資訊分析
- 計時器、計數器
3、特性
- 多樣的數據型別
- 持久化
- 叢集
- 事務
4、 基礎知識
redis有16個數據庫:在組態檔中可以看到:
databases 16
預設使用的是第0個
可以使用select切換數據庫
127.0.0.1:6379> select 3 #切換數據庫
OK
127.0.0.1:6379[3]> dbsize #檢視db大小
(integer) 0
儲存的數據後,db的大小會發生變化,但是這個數據只在當前數據庫有效:
127.0.0.1:6379[3]> set name zzp
OK
127.0.0.1:6379[3]> get name
"zzp"
127.0.0.1:6379[3]> dbsize
(integer) 1
127.0.0.1:6379[3]> select 7
OK
127.0.0.1:6379[7]> get name
(nil)
127.0.0.1:6379[7]> select 3
OK
127.0.0.1:6379[3]> get name
"zzp"
檢視數據庫所有的key:
清空當前庫:
127.0.0.1:6379[3]> keys *
1) "name"
127.0.0.1:6379[3]> flushdb
OK
127.0.0.1:6379[3]> keys *
(empty list or set)
清空全部數據庫內容:
127.0.0.1:6379[3]> flushall
OK
設定過期時間
檢視當前key的型別
127.0.0.1:6379> expire age 10 #設定過期時間
(integer) 1
127.0.0.1:6379> ttl age #檢視還有多久過期
(integer) 7
127.0.0.1:6379> type name #檢視型別
string
Redis是單執行緒的
Redis是基於記憶體的操作,CPU不是Redis的瓶頸,Redis的瓶頸最有可能是機器記憶體的大小或者網路頻寬。既然單執行緒容易實現,而且CPU不會成爲瓶頸,那就順理成章地採用單執行緒的方案了。
Redis爲什麼那麼快?
-
完全基於記憶體
-
數據結構簡單
-
採用單執行緒,避免了多執行緒中不必要的上下文切換和競爭條件,也不用考慮鎖的問題
-
使用多路IO複用模型,非阻塞的
多路I/O複用模型是利用 select、poll、epoll 可以同時監察多個流的 I/O 事件的能力,在空閒的時候,會把當前執行緒阻塞掉,當有一個或多個流有 I/O 事件時,就從阻塞態中喚醒,於是程式就會輪詢一遍所有的流(epoll 是隻輪詢那些真正發出了事件的流),並且只依次順序的處理就緒的流,這種做法就避免了大量的無用操作。 -
Redis自己構建了VM,不用耗費時間去呼叫系統函數
3、五大數據型別
1、 String型別
# 拼接、獲取長度
127.0.0.1:6379> set key1 v1
OK
127.0.0.1:6379> get key1
"v1"
127.0.0.1:6379> append key1 hello # 追加字串 (如果key1不存在,就相當於set命令)
(integer) 7
127.0.0.1:6379> get key1
"v1hello"
127.0.0.1:6379> strlen key1 #字串長度
(integer) 7
127.0.0.1:6379> append key1 ,world
(integer) 13
127.0.0.1:6379> strlen key1
(integer) 13
127.0.0.1:6379> get key1
"v1hello,world"
############################################################################
# 增加、減少
127.0.0.1:6379> set views 0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views #自增+1
(integer) 1
127.0.0.1:6379> incr views
(integer) 2
127.0.0.1:6379> get views
"2"
127.0.0.1:6379> decr views #自減1
(integer) 1
127.0.0.1:6379> get views
"1"
127.0.0.1:6379> incrby views 10 #增加 10
(integer) 11
127.0.0.1:6379> decrby views 5 #減少 10
(integer) 6
#############################################################################
# 獲取指定範圍range
127.0.0.1:6379> set key hello,world
OK
127.0.0.1:6379> get key
"hello,world"
127.0.0.1:6379> getrange key 0 3 #獲取指定範圍的字串 [0,1,2,3] 是閉區間
"hell"
127.0.0.1:6379> get key
"hello,world"
127.0.0.1:6379> getrange key 0 -1 # 獲取全部的字串
"hello,world"
# 替換指定範圍 replace
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> setrange key2 1 xx #替換指定位置的字串
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
#############################################################################
#setex (set expire) 設定過期時間
#setnx (set if not exist) 不存在再設定
127.0.0.1:6379> setex key3 30 hello #設定key3的值爲hello 30s過期
OK
127.0.0.1:6379> ttl key3
(integer) 26
127.0.0.1:6379> get key3
"hello"
127.0.0.1:6379> setnx mykey redis #如果mykey不存在,建立mykey
(integer) 1
127.0.0.1:6379> keys *
1) "mykey"
2) "key2"
3) "key"
127.0.0.1:6379> setnx mykey mongoDB #如果mykey存在, 建立失敗
(integer) 0
127.0.0.1:6379> get mykey
"redis"
#################################################################################
#批次設定值、批次獲取值
#mset mget
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # 同時設定多個值
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k2"
3) "k3"
127.0.0.1:6379> mget k1 k2 k3 # 同時獲取多個值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 #原子性的命令 因爲k1存在,所以k4也會建立失敗
(integer) 0
#################################################################################
# 物件
127.0.0.1:6379> set user:1 {name:zhangsan,age:30} # 將一個使用者的資訊設定成json字串儲存
OK
127.0.0.1:6379> get user:1
"{name:zhangsan,age:30}"
127.0.0.1:6379>
127.0.0.1:6379> mset user:1:name zhangsan user:1:age 30 #批次設定user:1的屬性值
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "zhangsan"
2) "30"
################################################################################
#getset
127.0.0.1:6379> getset db redis # 如果不存在值 則返回nil 並設定新的值
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongoDb #如果存在值 則返回原來的值 並設定新的值
"redis"
127.0.0.1:6379> get db
"mongoDb"
2、List
java中的棧、佇列、阻塞佇列 都可以通過redis的list型別實現。
所有的list命令都是以 l 開頭的
#lpush lrange
127.0.0.1:6379> lpush list one # 在列表頭部 插入一個值 類似於棧
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1 #取值
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> lrange list 0 1
1) "three"
2) "two"
#################################################################
#rpush
127.0.0.1:6379> rpush list zero # 再尾部插入一個值
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "zero"
127.0.0.1:6379>
####################################################################
#lpop
#rpop
127.0.0.1:6379> lpop list #移除list中的第一個元素
"three"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "zero"
127.0.0.1:6379> rpop list #移除list中的最後一個元素
"zero"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
################################################################
#lindex
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> lindex list 1 # 獲取list中的值 下標從0開始
"one"
127.0.0.1:6379> lindex list 0
"two"
########################################################################
# llen
127.0.0.1:6379> lpush list one
(integer) 1
127.0.0.1:6379> lpush list two three
(integer) 3
127.0.0.1:6379> llen list # list的長度
(integer) 3
###########################################################################
#移除具體的值 lrem
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "three"
3) "two"
4) "one"
127.0.0.1:6379> lrem list 1 one # 移除list中指定數量的指定值
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "three"
3) "two"
127.0.0.1:6379> lrem list 1 three
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "three"
3) "two"
127.0.0.1:6379> lrem list 2 three
(integer) 2
127.0.0.1:6379> lrange list 0 -1
1) "two"
###########################################################################
#ltrim 擷取
127.0.0.1:6379> rpush list hello1
(integer) 1
127.0.0.1:6379> rpush list hello2 hello3
(integer) 3
127.0.0.1:6379> lrange list 0 -1
1) "hello1"
2) "hello2"
3) "hello3"
127.0.0.1:6379> lpush list hello
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "hello"
2) "hello1"
3) "hello2"
4) "hello3"
127.0.0.1:6379> ltrim list 1 2 # 通過下標擷取指定的長度,這個list會被改變,只剩下擷取的元素
OK
127.0.0.1:6379> lrange list 0 -1
1) "hello1"
2) "hello2"
###########################################################################
# rpoplpush 移除列表的最後一個元素並將這個元素移動到新的列表中
127.0.0.1:6379> rpush mylist hello hello1 hello2
(integer) 3
127.0.0.1:6379>
127.0.0.1:6379> rpoplpush mylist mylist2 # 移除列表的最後一個元素並將這個元素移動到新的列表中
"hello2"
127.0.0.1:6379>
127.0.0.1:6379> lrange mylist 0 -1 # 檢視舊列表中的元素
1) "hello"
2) "hello1"
127.0.0.1:6379> lrange mylist2 0 -1 #檢視新列表的元素
1) "hello2"
###########################################################################
#lset 將列表中指定下標的值替換 如果不存再這個下標 會報錯
127.0.0.1:6379> lrange list 0 -1
1) "sss"
127.0.0.1:6379> lset list 0 aaa
OK
127.0.0.1:6379> lrange list 0 -1
1) "aaa"
###########################################################################
#linsert 將某個具體的value插入列表中某個元素的前面或者後面
127.0.0.1:6379> rpush list hello world
(integer) 2
127.0.0.1:6379> lrange list 0 -1
1) "hello"
2) "world"
127.0.0.1:6379> linsert list before world other # 前邊
(integer) 3
127.0.0.1:6379>
127.0.0.1:6379> lrange list 0 -1
1) "hello"
2) "other"
3) "world"
127.0.0.1:6379> linsert list after world ! # 後邊
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "hello"
2) "other"
3) "world"
4) "!"
3、Set
set中的值是不能重複的
#存值 取值 檢視值是否存在
127.0.0.1:6379> sadd myset hello
(integer) 1
127.0.0.1:6379> sadd myset zzp
(integer) 1
127.0.0.1:6379> sadd myset love you
(integer) 2
127.0.0.1:6379> smembers myset
1) "hello"
2) "love"
3) "zzp"
4) "you"
127.0.0.1:6379> sismember myset hellp
(integer) 0
127.0.0.1:6379> sismember myset hello
(integer) 1
################################################################################
# 大小
127.0.0.1:6379> scard myset
(integer) 4
# 移除
127.0.0.1:6379> srem myset you
(integer) 1
127.0.0.1:6379> smembers myset
1) "hello"
2) "love"
3) "zzp"
################################################################################
# srandmember 隨機抽選出一個元素
127.0.0.1:6379> smembers myset
1) "hello"
2) "love"
3) "zzp"
127.0.0.1:6379> srandmember myset
"hello"
127.0.0.1:6379> srandmember myset
"hello"
127.0.0.1:6379> srandmember myset
"zzp"
################################################################################
# spop 隨機刪除元素
127.0.0.1:6379> smembers myset
1) "hello"
2) "love"
3) "zzp"
127.0.0.1:6379> spop myset
"hello"
127.0.0.1:6379> spop myset
"zzp"
127.0.0.1:6379> smembers myset
1) "love"
################################################################################
# smove 將一個指定的值,移動到另外一個set中
127.0.0.1:6379> sadd myset hello world zzp
(integer) 3
127.0.0.1:6379> sadd myset2 set2
(integer) 1
127.0.0.1:6379> smove myset myset2 zzp
(integer) 1
127.0.0.1:6379>
127.0.0.1:6379> smembers myset
1) "hello"
2) "world"
127.0.0.1:6379> smembers myset2
1) "set2"
2) "zzp"
################################################################################
# 共同關注(交集)
# 微博中 把A使用者的關注凡在set中,B使用者的關注放在set中,就可以通過這個命令拿到共同關注
# 二度好友 (推薦博主) 也是把朋友關注的博主,推薦給你
# 數位集合類:
- 差集 sdiff
- 交集 sinter
- 並集 sunion
127.0.0.1:6379> sadd key1 a b c
(integer) 4
127.0.0.1:6379> sadd key2 c d e
(integer) 3
127.0.0.1:6379> smembers key1
1) "b"
2) "c"
3) "a"
127.0.0.1:6379> smembers key2
1) "c"
2) "e"
3) "d"
127.0.0.1:6379> sdiff key1 key2
1) "b"
2) "a"
127.0.0.1:6379> sinter key1 key2
1) "c"
127.0.0.1:6379> sunion key1 key2
1) "b"
2) "c"
3) "e"
4) "a"
5) "d"
127.0.0.1:6379>
4、Hash
map集合 key - 也就是說值是一個value
# hset hget hmset hmget hgetall hdel
127.0.0.1:6379> hset myhash field1 zzp # set一個具體的key-value
(integer) 1
127.0.0.1:6379> hget myhash field1 #獲取一個欄位值
"zzp"
127.0.0.1:6379> hmset myhash field1 hello field2 world #set多個key—value
OK
127.0.0.1:6379> hmget myhash field1 field2 #獲取多個欄位值
1) "hello"
2) "world"
127.0.0.1:6379>
127.0.0.1:6379> hgetall myhash #獲取全部的數據
1) "field1"
2) "hello"
3) "field2"
4) "world"
127.0.0.1:6379> hdel myhash field1
(integer) 1
127.0.0.1:6379> hgetall myhash #刪除hash指定的key欄位,對應的value也就消失了
1) "field2"
2) "world"
#################################################################################
#hlen 長度
127.0.0.1:6379> hmset myhash k1 v1 k2 v2
OK
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "world"
3) "k1"
4) "v1"
5) "k2"
6) "v2"
127.0.0.1:6379> hlen myhash
(integer) 3
####################################################################################
#hexists 判斷hash中的key是否存在
127.0.0.1:6379> hexists myhash k1
(integer) 1
127.0.0.1:6379> hexists myhash kk
(integer) 0
#################################################################################
# 獲取所有的欄位 hkeys
# 獲取所有的值 hvals
127.0.0.1:6379> hkeys myhash
1) "field2"
2) "k1"
3) "k2"
127.0.0.1:6379>
127.0.0.1:6379> hvals myhash
1) "world"
2) "v1"
3) "v2"
#################################################################################
# 增加 hincrby
# hsetnx
127.0.0.1:6379> hset myhash filed3 5
(integer) 1
127.0.0.1:6379> hincrby myhash filed3 1 # 加1
(integer) 6
127.0.0.1:6379>
127.0.0.1:6379> hincrby myhash filed3 -1 # 減1
(integer) 5
127.0.0.1:6379> hsetnx myhash k3 v3 #不存k3 建立成功
(integer) 1
127.0.0.1:6379> hsetnx myhash k3 v4 # 當k3存在的時候,建立失敗
(integer) 0
hash適合儲存一些經常變動的資訊,比如使用者資訊! hash更適合物件的儲存,string更加適合字串的儲存
127.0.0.1:6379> hset user1 name zzp
(integer) 1
127.0.0.1:6379> hget user1 name
"zzp"
5、Zset(有序集合)
在set的基礎上增加了一個值
set : k1 v1
zset: k1 score v1
# zadd 新增 zrange 檢視
127.0.0.1:6379> zadd myset 1 one
(integer) 1
127.0.0.1:6379> zadd myset 2 two
(integer) 1
127.0.0.1:6379> zadd myset 3 three 4 four
(integer) 2
127.0.0.1:6379> zrange myset 0 -1
1) "one"
2) "two"
3) "three"
4) "four"
###################################################################################
# 排序
# zrangebyscore 正序
# zrevrange 倒敘
127.0.0.1:6379> zadd salary 2500 xiaohong 5000 zhangsan 500 zzp # 新增三個值
(integer) 3
127.0.0.1:6379> zrangebyscore salary -inf inf # 排序 正序 -inf代表負無窮 info 正無窮大
1) "zzp"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379> zrangebyscore salary -inf +inf withscores # 顯示全部的排序 並且附帶成績
1) "zzp"
2) "500"
3) "xiaohong"
4) "2500"
5) "zhangsan"
6) "5000"
127.0.0.1:6379> zrangebyscore salary -inf 2500 withscores #顯示負無窮到2500範圍內的排序
1) "zzp"
2) "500"
3) "xiaohong"
4) "2500"
127.0.0.1:6379> zrevrange salary 0 -1 # 倒敘
1) "zhangsan"
2) "xiaohong"
3) "zzp"
####################################################################################
# zrem 移除元素
# zcard 大小
127.0.0.1:6379> zrange salary 0 -1
1) "zzp"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379>
127.0.0.1:6379> zrem salary xiaohong
(integer) 1
127.0.0.1:6379> zrange salary 0 -1
1) "zzp"
2) "zhangsan"
127.0.0.1:6379> zcard salary # 獲取集閤中的個數
(integer) 2
#################################################################################
# zcount 獲取指定區間中的個數
127.0.0.1:6379> zadd myset 1 hello 2 world 3 zzp
(integer) 3
127.0.0.1:6379> zrange myset 0 -1
1) "hello"
2) "world"
3) "zzp"
127.0.0.1:6379> zcount myset 1 3
(integer) 3
127.0.0.1:6379> zcount myset 1 2
(integer) 2
4、三種特殊數據型別
1、geospatial 地理位置
朋友的定位,附近的人,打車距離的計算。
Redis的Geo在Redis3.2版本就推出了! 這個功能可以推算地理位置的資訊,兩地之間的距離, 方圓幾裡的人。
http://www.jsons.cn/lngcode/ 這個網站可以查詢城市的經緯度
# 新增 geoadd
# 規則: 兩極是無法新增的 我們一般是會用java程式將下載的城市數據匯入到redis中
127.0.0.1:6379> geoadd china:city 108.94 34.26 xian
(integer) 0
# geopos 獲取城市的精度和緯度
127.0.0.1:6379> geopos china:city beijing
1) 1) "116.39999896287918"
2) "39.900000091670925"
127.0.0.1:6379> geopos china:city shanghai xian
1) 1) "121.47000163793564"
2) "31.229999039757836"
2) 1) "108.9399978518486"
2) "34.2599996441893"
# geodist 兩個位置的距離
127.0.0.1:6379> geodist china:city beijing xian # 單位m
"911340.9035"
127.0.0.1:6379> geodist china:city beijing xian km # 指定單位km
"911.3409"
# georadius 以給定的位置爲中心 找指定半徑內的其他位置
127.0.0.1:6379> georadius china:city 110 30 1000 km # 獲取(110,30)爲座標 半徑1000km的城市
1) "chongqing"
2) "xian"
3) "shenzhen"
4) "hangzhou"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> georadius china:city 110 30 500 km # 獲取(110,30)爲座標 半徑500km的城市
1) "chongqing"
2) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist # 顯示距離
1) 1) "chongqing"
2) "341.9374"
2) 1) "xian"
2) "484.2186"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord # 顯示座標
1) 1) "chongqing"
2) 1) "106.49999767541885"
2) "29.529999579006592"
2) 1) "xian"
2) 1) "108.9399978518486"
2) "34.2599996441893"
127.0.0.1:6379>
127.0.0.1:6379> georadius china:city 110 30 500 km withdist withcoord count 1 # 限制數量
1) 1) "chongqing"
2) "341.9374"
3) 1) "106.49999767541885"
2) "29.529999579006592"
# georadiusbymember 找出指定元素某一範圍的其他元素
127.0.0.1:6379> georadiusbymember china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> georadiusbymember china:city shanghai 400 km
1) "hangzhou"
2) "shanghai"
127.0.0.1:6379>
# geohash 將經緯度轉換爲一位的字串
127.0.0.1:6379> geohash china:city chongqing
1) "wm5xzrybty0"
GEO的底層是通過Zset實現的,我們也可以通過Zset命令來操作它
127.0.0.1:6379> type china:city # 檢視型別 驗證底層確實是zset
zset
127.0.0.1:6379> zrange china:city 0 -1 # 檢視城市
1) "chongqing"
2) "xian"
3) "shenzhen"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379> zrem china:city shenzhen #移除一個城市(geo沒有移除的命令,但可以用zset的命令移除)
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1
1) "chongqing"
2) "xian"
3) "hangzhou"
4) "shanghai"
5) "beijing"
2、hyperloglog
Redis2.8.9版本更新了Hyperloglog數據結構。
Redis Hyperloglog 是技術統計的演算法!
優點:佔用記憶體是固定的,2^64不同元素的基數,只需要佔用12Kb記憶體!
網頁的UV(存取頁面的使用者量)
傳統的方式,set儲存使用者的id,然後統計set中元素的數量作爲標準!大那是這種方式儲存了大量的使用者id,佔用了大量的記憶體,並且在實際的生產環境中,因爲使用者id會因爲分佈式的原因導致這個使用者id特別長,佔用的記憶體也會隨之上升。
這個時候可以考慮採用redis的 Hyperloglog技術。
但是hyperloglog會有**0.81%**的錯誤率!
# pfadd 新增 pfcount 計數 pfmerge 合併
127.0.0.1:6379> pfadd mykey a b c d e f g h i j k
(integer) 1
127.0.0.1:6379> pfcount mykey
(integer) 11
127.0.0.1:6379> pfadd mykey2 i j z x c v b n m
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 9
127.0.0.1:6379> pfmerge mykey3 mykey mykey2
OK
127.0.0.1:6379>
127.0.0.1:6379> pfcount mykey3
(integer) 16
3、 bitemaps
Bitmaps點陣圖,也是一種數據結構! 通過操作二進制位來進行記錄的。只有0和1兩種狀態。
測試: 記錄使用者一週的打卡記錄
# 記錄使用者每天的打卡情況
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 0
(integer) 0
# 獲取某天的打卡情況
127.0.0.1:6379> getbit sign 4
(integer) 1
127.0.0.1:6379> getbit sign 6
(integer) 0
# 統計打卡記錄 也就是值是1的數量
127.0.0.1:6379> bitcount sign
(integer) 3
5、 事務
Redis的本質是一組命令的集合。一個事務中的所有命令都會被序列化,在事務的執行過程中,會被順序執行。
Redis事務沒有隔離級別的概念
即不存在像mysql中的髒讀幻讀這些情況!
Redis的單條命令可以保證原子性,但是事務不保證原子性
Redis的事務:
- 開啓事務(multi)
- 命令
- 執行事務(exec)
正常執行事務
127.0.0.1:6379> multi # 開啓事務
OK
# 命令入隊
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
# 執行事務 這個事務纔會真正執行上邊的命令
127.0.0.1:6379> exec
1) OK
2) OK
3) "v2"
4) OK
放棄事務
127.0.0.1:6379> multi # 開啓事務
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> set k4 v4 # 新加一個k4 驗證是否成功取消
QUEUED
127.0.0.1:6379> discard # 放棄事務
OK
127.0.0.1:6379> get k4
(nil)
檢查異常: redis的命令有錯時,事務中的其他命令也不會執行
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> getset k1 # getset命令出錯
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec # 整個事務執行失敗
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379>
執行時異常: 如果事務中的命令存在語法性問題的時候,那麼其他命令可以正常執行,這個命令會拋出異常。所以redis的事務不是原子性的!
127.0.0.1:6379> set k1 v1 # 提前設定一個值
OK
127.0.0.1:6379> multi #開啓事務
OK
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> incr k1 # 執行一條會報錯的命令
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec # 執行 其他的命令都正常執行 這條命令失敗
1) OK
2) "v2"
3) (error) ERR value is not an integer or out of range
4) OK
監控! watch (實現樂觀鎖 面試常問的!!!)
悲觀鎖
悲觀的認爲什麼時候都會出問題,無論什麼時候都會加鎖!
樂觀鎖
樂觀的認爲什麼時候都不會出問題,所以不會上鎖!更新數據的時候去判斷一下,在此期間是否有人更改過這個數據:
獲取version,更新的時候比較version
正常執行成功
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money # 監視money物件
OK
127.0.0.1:6379> multi # 開啓事務
OK
127.0.0.1:6379> decrby money 20 # money-20
QUEUED
127.0.0.1:6379> incrby out 20 # out+20
QUEUED
127.0.0.1:6379> exec # 執行
1) (integer) 80
2) (integer) 20
測試多執行緒修改值,使用watch可以當作redis的樂觀鎖
127.0.0.1:6379> watch money # 監控money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 10
QUEUED
127.0.0.1:6379> incrby out 10
QUEUED
127.0.0.1:6379> exec # 執行執行這一步之前,另一個執行緒對money進行了修改 watch檢測到這個值變化,導致事 # 務執行失敗
(nil)
如果執行失敗,就去重新監控,在執行
127.0.0.1:6379> unwatch # 解鎖
OK
127.0.0.1:6379> watch money # 重新監控
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 10
QUEUED
127.0.0.1:6379> incrby out 10
QUEUED
127.0.0.1:6379> exec
1) (integer) 990
2) (integer) 30
6、Jedis
使用java來操作redis!
jedis是redis官方推薦使用的java連線開發工具!
1、 匯入依賴的包
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
2、 連線測試
- 連線數據庫
- 操作命令
- 斷開命令
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
String pong = jedis.ping();
System.out.println(pong);
}
輸出結果:
PONG
7、 Springboot整合redis
說明:在springboot2.x之後,原來使用的 jedis 被替換爲了 lettuce!
redis: 採用的是直連的方式,多個執行緒操作的話,是不安全的。如果想要避免這個問題,就要使用jedis pool連線池,但是這種連線池是屬於BIO執行緒阻塞的。
lettuce: 採用netty,範例在多個執行緒中共用,不存線上程不安全的問題。可以減少執行緒數量。(NIO)
原始碼分析:
@Bean
@ConditionalOnMissingBean(name = "redisTemplate") // 可以自定義template來替換預設的
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
//預設的Template沒有過多的設定,redis物件是需要序列化的
// 兩個泛型都是<Object, Object> 我們需要強制轉換成成<String, Object>
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean // 由於String型別是常用的型別,所以單獨爲開發者提出來的一個方法
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
整合測試!
1、 匯入依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、設定連線
spring.redis.host=127.0.0.1
spring.redis.port=6379
3、 程式碼測試
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
//opsxxxx 操作不同類的數據 (5大基本型別,3個特殊型別)
//opsForZSet opsForValue opsForHash
// 獲取連線物件
// RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
// connection.flushAll();
// connection.flushDb();
redisTemplate.opsForValue().set("mykey", "zzp");
Object value = redisTemplate.opsForValue().get("mykey");
System.out.println(value);
}
redis中,如果我們的物件沒有進行序列化,那麼儲存到redis中的中文是亂碼的!
那麼去看看原始碼中是如何解決這個問題的!!!
[外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-FFIFxEsz-1597226757678)(https://raw.githubusercontent.com/zengpeng-zhao/picgo/master/img/20200809114139.png?token=AQRROS4ZDVRFU64JYKO2QJK7F5YL4)]
原始碼中預設的序列化方式是jdk!
[外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-a0ZojR8b-1597226757679)(https://raw.githubusercontent.com/zengpeng-zhao/picgo/master/img/20200809114912.png?token=AQRROSYJH7ALLV6QDJST3U27F5ZHU)]
加入現在我們要在redis中儲存一個物件作爲值:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private String name;
private Integer age;
}
@Test
void test() throws JsonProcessingException {
User user = new User("小明", 18);
redisTemplate.opsForValue().set("user", user);
System.out.println(redisTemplate.opsForValue().get("user"));
}
執行上述程式:
org.springframework.data.redis.serializer.SerializationException: Cannot serialize; nested exception is org.springframework.core.serializer.support.SerializationFailedException: Failed to serialize object using DefaultSerializer;
nested exception is java.lang.IllegalArgumentException: DefaultSerializer requires a Serializable payload but received an object of type [com.zzp.pojo.User]
執行報錯了,報錯資訊提示我們需要在User型別實現序列化。
修改User類
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable { // 序列化
private String name;
private Integer age;
}
這個時候執行成功
User(name=小明, age=18)
但是這個時候我們通過redis-client檢視user因爲jdk序列化,變成了跳脫字串了!
127.0.0.1:6379> keys *
1) "\xac\xed\x00\x05t\x00\x04user"
我們使用的序列化方式不想用預設的jdk,這個時候就需要我們自定義Template了!
-
編寫自己的redisConfig
@Bean @SuppressWarnings("all") public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactoryredisConnectionFactory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(redisConnectionFactory); //Json序列化設定 Jackson2JsonRedisSerializer jackson = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson.setObjectMapper(om); //String序列化 StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // 對key進行string序列化 template.setKeySerializer(stringRedisSerializer); template.setHashKeySerializer(stringRedisSerializer); // value採用jackson序列化 template.setValueSerializer(jackson); template.setHashValueSerializer(jackson); template.afterPropertiesSet(); return template; } -
指定引入我們自定義的redisTemplate
@Autowired @Qualifier("redisTemplate") // 限定 private RedisTemplate redisTemplate; -
再次測試
127.0.0.1:6379> keys *
1) "user"
平常的開發中,我們都會將redis的操作進行封裝
package com.zzp.util;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
@Component
public class RedisUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 指定快取失效時間
* @param key
* @param time
* @return
*/
public boolean expire (String key, long time) {
try {
if(time > 0) {
redisTemplate.expire(key, time, TimeUnit.SECONDS);
}
return true;
}catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根據key, 獲取過期時間
* @param key 不能爲空
* @return 返回0 代表永久有效
*/
public long expireKey (String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}
/**
* 判斷key是否存在
* @param key
* @return
*/
public boolean hasKey (String key) {
try {
return redisTemplate.hasKey(key);
}catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 刪除快取
* @param key 可以傳一個或者多個值
*/
public void del (String... key) {
if(key != null && key.length > 0) {
if(key.length == 1) {
redisTemplate.delete(key[0]);
}else{
redisTemplate.delete(CollectionUtils.arrayToList(key));
}
}
}
// ==================String====================
/**
* 普通快取獲取
* @param key
* @return
*/
public Object get(String key) {
return redisTemplate.opsForValue().get(key);
}
public boolean set (String key, Object value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
}catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 普通快取放入並設定時間
* @param key 鍵
* @param value 值
* @param time 時間(秒) time要大於0 如果time小於等於0 將設定無限期
* @return true成功 false 失敗
*/
public boolean set(String key, Object value, long time) {
try {
if (time > 0) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
} else {
set(key, value);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 遞增
* @param key 鍵
* @param delta 要增加幾(大於0)
* @return
*/
public long incr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("遞增因子必須大於0");
}
return redisTemplate.opsForValue().increment(key, delta);
}
/**
* 遞減
* @param key 鍵
* @param delta 要減少幾(小於0)
* @return
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("遞減因子必須大於0");
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ================================Map=================================
/**
* HashGet
* @param key 鍵 不能爲null
* @param item 項 不能爲null
* @return 值
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* 獲取hashKey對應的所有鍵值
* @param key 鍵
* @return 對應的多個鍵值
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
* @param key 鍵
* @param map 對應多個鍵值
* @return true 成功 false 失敗
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* HashSet 並設定時間
* @param key 鍵
* @param map 對應多個鍵值
* @param time 時間(秒)
* @return true成功 false失敗
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一張hash表中放入數據,如果不存在將建立
* @param key 鍵
* @param item 項
* @param value 值
* @return true 成功 false失敗
*
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一張hash表中放入數據,如果不存在將建立
* @param key 鍵
* @param item 項
* @param value 值
* @param time 時間(秒) 注意:如果已存在的hash表有時間,這裏將會替換原有的時間
* @return true 成功 false失敗
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 刪除hash表中的值
* @param key 鍵 不能爲null
* @param item 項 可以使多個 不能爲null
*/
public void hdel(String key, Object... item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* 判斷hash表中是否有該項的值
* @param key 鍵 不能爲null
* @param item 項 不能爲null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash遞增 如果不存在,就會建立一個 並把新增後的值返回
*
* @param key 鍵
* @param item 項
* @param by 要增加幾(大於0)
* @return
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash遞減
*
* @param key 鍵
* @param item 項
* @param by 要減少記(小於0)
* @return
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// ============================set=============================
/**
* 根據key獲取Set中的所有值
*
* @param key 鍵
* @return
*/
public Set<Object> sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根據value從一個set中查詢,是否存在
*
* @param key 鍵
* @param value 值
* @return true 存在 false不存在
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將數據放入set快取
*
* @param key 鍵
* @param values 值 可以是多個
* @return 成功個數
* 325
*/
public long sSet(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 將set數據放入快取
*
* @param key 鍵
* @param time 時間(秒)
* @param values 值 可以是多個
* @return 成功個數
*/
public long sSetAndTime(String key, long time, Object... values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0)
expire(key, time);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 獲取set快取的長度
*
* @param key 鍵
* @return
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 移除值爲value的
*
* @param key 鍵
* @param values 值 可以是多個
* @return 移除的個數
*/
public long setRemove(String key, Object... values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// ===============================list=================================
/**
* 獲取list快取的內容
*
* @param key 鍵
* @param start 開始
* @param end 結束 0 到 -1代表所有值
* @return 391
*/
public List<Object> lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 獲取list快取的長度
*
* @param key 鍵
* @return
*/
public long lGetListSize(String key) {
try {
return redisTemplate.opsForList().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 通過索引 獲取list中的值
*
* @param key 鍵
* @param index 索引 index>=0時, 0 表頭,1 第二個元素,依次類推;index<0時,-1,表尾,-2倒數第二個元素,依次類推
* @return
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
* @param time 時間(秒)
* @return
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
* @param time 時間(秒)
* @return
*/
public boolean lSet(String key, Object value, long time) {
try {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
* @param time 時間(秒)
* @return
*/
public boolean lSet(String key, List<Object> value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 將list放入快取
*
* @param key 鍵
* @param value 值
* @param time 時間(秒)
* @return
*/
public boolean lSet(String key, List<Object> value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根據索引修改list中的某條數據
*
* @param key 鍵
* @param index 索引
* @param value 值
* @return
*/
public boolean lUpdateIndex(String key, long index, Object value) {
try {
redisTemplate.opsForList().set(key, index, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 移除N個值爲value
*
* @param key 鍵
* @param count 移除多少個
* @param value 值
* @return 移除的個數
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
}
8、Redis.config檔案
# NETWORK
bind 127.0.0.1 #系結ip
protected-mode yes #保護模式
port 6379 #埠號
#GENERAL
daemonize yes # 是否開啓後臺執行 預設爲no 我們要改爲yes
pidfile /var/run/redis_6379.pid #如果以後台方式執行,就需要指定一個pid檔案
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably) 生產環境一般用這個
# warning (only very important / critical messages are logged)
loglevel notice # 日誌級別
logfile "server_log.txt" # 日誌檔案的檔名
databases 16 # 數據庫的數量
# SNAPSHOTTING 快照
#持久化規則
save 900 1 # 900s內,只要有一個key進行了修改, 就進行持久化操作
save 300 10 # 300s內,只要有10個key進行了修改, 就進行持久化操作
save 60 10000 # 60s內,只要有10000個key進行了修改, 就進行持久化操作
stop-writes-on-bgsave-error yes # 持久化失敗 是否還需要重新工作
rdbcompression yes # 是否壓縮rdb檔案 如果開啓 會消耗cpu資源
rdbchecksum yes # 進行rdb檔案儲存的時候,是否進行校驗
dir ./ # rdb儲存目錄 當前位置
# SECURITY 安全設定
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get requirepass # 獲取密碼
1) "requirepass"
2) ""
127.0.0.1:6379> config set requirepass 123456 #設定密碼
OK
127.0.0.1:6379> config get requirepass # 需要登陸採用繼續使用
(error) NOAUTH Authentication required.
127.0.0.1:6379>
127.0.0.1:6379> auth 123456 # 登陸
OK
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"
127.0.0.1:6379>
# LIMITS 限制
maxclients 10000 # 設定用戶端的最大連線數
maxmemory <bytes> # 設定最大的記憶體容量
maxmemory-policy noeviction #記憶體到達上限後的處理策略
volatile-lru: 只對設定了過期時間的key就行lru
allkeys-lru: 刪除lru演算法的key
volatile-random: 隨機刪除即將過期的key
allkeys-random: 隨機刪除
volatile-ttl: 刪除即將過期的
noeviction: 永不過期
# LRU是Least Recently Used的縮寫,即最近最少使用
# APPEND ONLY MODE AOF設定
appendonly no # 預設是不開啓AOF模式 redis預設是rdb持久化的
appendfilename "appendonly.aof" #檔名稱
# appendfsync always #沒次修改都會持久化 速度比較慢
appendfsync everysec #每秒執行一次 可能會丟失這1s數據
# appendfsync no #不執行
9、持久化
Redis記憶體數據庫,如果不把記憶體中的數據儲存到磁碟中,那麼一旦服務進程退出,伺服器中的數據庫狀態也會消失,爲了避免這個問題,redis提供了持久化機制 機製。
9.1、RDB(Redis Database)
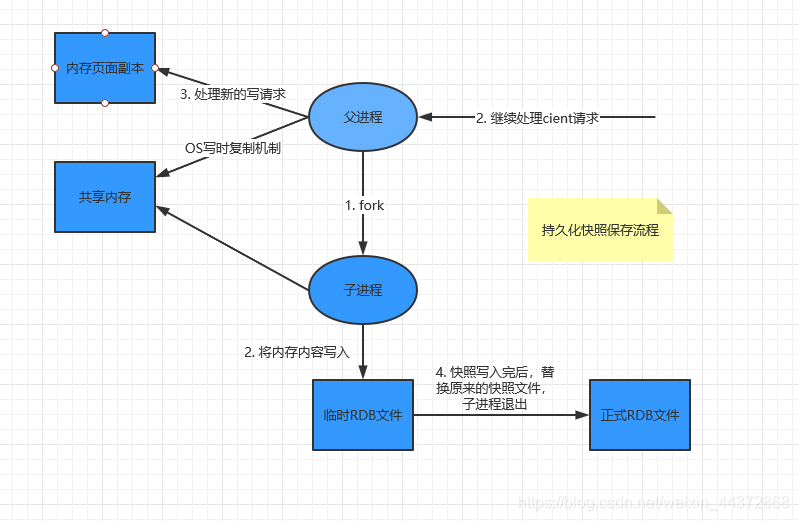
RDB(快照): 在指定的時間間隔內,將記憶體中的數據集持久化到磁碟中。它恢復時,是將檔案直接讀取到記憶體中。
RDB會單獨建立(fork)一個子進程來進行持久化,會將記憶體中的數據寫入到一個臨時檔案中,等到持久化過程結束後,纔會用這個臨時檔案替換原本的快照檔案。在這整個過程中,主進程是不進行任何I/O操作的,這就確保了極高的效能。 如果要進行大規模數據恢復,並對數據的完整性不是特別敏感,那麼RDB方式要比AOF方式更加的高效。
如何將RDB檔案恢復到記憶體中?
- 將rdb檔案放在redis的啓動目錄下,redis啓動的時候會自動檢查dump.rdb檔案,並進行恢復!
- 檢視需要存放rdb檔案的位置:
127.0.0.1:6379> config get dir
1) "dir"
2) "D:\\anzh\\Redis-x64-3.2.100"
優缺點:
優點:
適合大規模的數據恢復
效能相較於aof要高
缺點:
需要滿足一定的條件纔會出發持久化,如果redis在這段時間內意外宕機了,這部分數據就會丟失!
RDB每次在fork子進程來執行RDB快照數據檔案生成的時候,如果數據檔案特別大,可能會導致對用戶端提供的服務暫停數毫秒,或者甚至數秒。
9.2、AOF (Append Only File)
將我們的所有執行命令記錄下來(讀操作不記錄),這個過程只能追加檔案,不能改寫檔案。 如果要進行恢復數據的話, 就會把這個檔案中的命令全部重新執行一邊!
預設是不開啓的,需要手動開啓。
如果aof檔案出錯時(可能時人爲因素修改了這個檔案導致出錯),啓動redis是會失敗的。這個時候,redis爲我們提供了修復工具redis-check-aof。
redis-check-aof --fix appendonly.aof # 執行這個命令就可修復檔案,修復完成後重新啓動即可
優缺點:
優點:
1、 每一次修改都會記錄,檔案的完整性更好。預設是每秒同步一次(級別:always、no、everysec)
缺點:
1、 aof生成的數據檔案要比rdb大,恢復起來也很耗時。
2、 Aof的執行效率也要比Rdb慢。
RDB和AOF到底該如何選擇
(1)不要僅僅使用RDB,因爲那樣會導致你丟失很多數據
(2)也不要僅僅使用AOF,因爲那樣有兩個問題,第一,你通過AOF做冷備,沒有RDB做冷備,來的恢復速度更快; 第二,RDB每次簡單粗暴生成數據快照,更加健壯,可以避免AOF這種複雜的備份和恢復機制 機製的bug
(3)綜合使用AOF和RDB兩種持久化機制 機製,用AOF來保證數據不丟失,作爲數據恢復的第一選擇; 用RDB來做不同程度的冷備,在AOF檔案都丟失或損壞不可用的時候,還可以使用RDB來進行快速的數據恢復
10、 Redis 發佈訂閱
Redis 發佈訂閱(pub/sub)是一種訊息通訊模式:發送者(pub)發送訊息,訂閱者(sub)接收訊息。
Redis 用戶端可以訂閱任意數量的頻道。
下圖展示了頻道 channel1 , 以及訂閱這個頻道的三個用戶端 —— client2 、 client5 和 client1 之間的關係
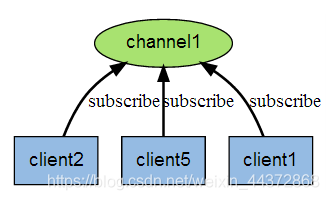
當有新訊息通過 PUBLISH 命令發送給頻道 channel1 時, 這個訊息就會被髮送給訂閱它的三個用戶端:
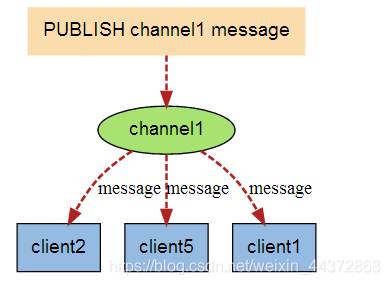
測試範例
# 發送者 publish channel message
127.0.0.1:6379> publish deyunshe "hello dajiahao"
(integer) 1
# 訂閱者 接受訊息 subscribe channel
127.0.0.1:6379> subscribe deyunshe
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "deyunshe"
3) (integer) 1
1) "message"
2) "deyunshe"
3) "hello dajiahao"
11、Redis主從複製
概念
主從複製:是指將一臺redis伺服器上的數據複製到其他幾臺redis伺服器上,這樣前者稱爲主節點(master/leader),後者稱爲從節點(slaver/follower);數據的複製是單向的,只能由主節點複製到從節點。Master以寫爲主,Slaver以讀爲主。
預設情況下,每一臺redis伺服器都是主節點;且一臺主節點可以有多臺從節點,但是一臺從節點只能有一個主節點。
主從複製的作用:
1、數據冗餘:主從複製實現了數據的熱備份,是持久化之外的一種數據冗餘
2、 故障恢復:當主節點出現問題,可以由從節點提供服務,實現故障的快速恢復。這是服務的冗餘
3、 負載均衡: 在主從複製的基礎上,配合讀寫分離,可以由主節點提供寫服務,從節點提供讀服務。尤其是在讀多寫少的場景中,通過多個節點分擔讀負載,可以大大提高redis伺服器的併發量。
4、 高可用的基石: 主從複製還是實現叢集和哨兵的基礎。
一般來說,一臺redis伺服器是不夠用的。
- 從結構上來說,單台服務的請求負載壓力很大,如果出現故障,將很難恢復
- 從容量上來說,單台伺服器的儲存容量有限
搭建主從複製
1、 在linux環境中拷貝幾份組態檔,修改埠號
2、 在從節點的組態檔中設定主節點資訊
slaveof 主節點ip 主節點埠號
masterauth <master-password> # 如果有密碼的話 需要設定密碼
3、 啓動設定好的主從伺服器
4、 驗證是否設定成功
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
思考
-
當主機斷開連線了?
主機斷開後,從機依舊連線到主機的,這個時候讀服務是正常的,只是寫服務失敗。當主機重新連線之後,寫服務恢復。
-
當一臺從機斷開連線?
這台伺服器停止提供讀服務,其他的從機和主機正常工作。當這台從機重新連線後,依舊正常提供讀服務。
複製原理
Slave啓動成功連線到父節點伺服器後,會發送一個sync同步命令
Master接收到請求後,啓動後臺的存檔進程,同時收集接收到的用於修改數據集的指令,在後台進程執行完畢後,master將傳送整個檔案到slave,完成一次完全同步。
- 全量複製: slave接收到數據檔案後,將其存檔並載入到記憶體中
- 增量複製: master將修改命令依次傳給slave,完成同步。
從機重新連線主機後,全量複製將會自動執行!
12、哨兵模式
當主伺服器宕機後,需要手動重新設定主節點,重新設定從節點,這樣會造成服務的一段時間不可用.
Redis在2.8開始提供了哨兵模式(Sentinel)來解決這個問題。它是一個獨立的進程,能夠監控主機是否故障(通過發送命令,等待伺服器響應來監控是否故障),如果故障了,根據投票數選舉一個從機出來成爲主機。
正常企業架構中,因爲單個哨兵也存在宕機的風險,所以哨兵也會設定成多個哨兵的模式。
哨兵的作用:
- 通過發送命令,等待伺服器響應來監控主從伺服器
- 如果master宕機,會選舉出來一個從機成爲master,並且通過發佈訂閱模式通知其他從伺服器,讓他們切換主機。
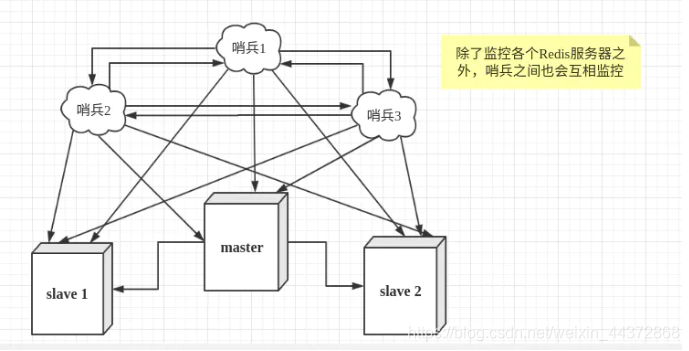
假設主伺服器宕機後,哨兵1先檢測到這個結果,系統並不會馬上進行failover過程,僅僅哨兵1認爲主伺服器不可用,這個被稱爲主觀下線。當其他的哨兵也檢測到這個伺服器不可用並且到達一定數量後,那麼哨兵之間就會進行一次投票,投票的結果由一個哨兵發起,進行failover(故障轉移)操作。切換成功後,就會通過發佈訂閱模式,讓各個哨兵把自己監控的從伺服器實現切換主機,這個過程稱爲客觀下線。這樣對於用戶端而言,一切都是透明的。
設定哨兵模式
1、 修改組態檔
在Redis安裝目錄下有一個sentinel.conf檔案,copy一份進行修改。
# 設定監聽的主伺服器,這裏sentinel monitor代表監控,mymaster代表伺服器的名稱,可以自定義,192.168.11.128代表監控的主伺服器,6379代表埠,2代表只有兩個或兩個以上的哨兵認爲主伺服器不可用的時候,纔會進行failover操作。
sentinel monitor mymaster 192.168.11.128 6379 2
# sentinel author-pass定義服務的密碼,mymaster是服務名稱,123456是Redis伺服器密碼
sentinel auth-pass mymaster 123456
2、 啓動
# 啓動哨兵進程
./redis-sentinel ../sentinel.conf
如果主機宕機了,那麼哨兵會從從機中選舉一個slave出來作爲主機。當我們將原來宕掉的主機重新啓動後,它會變成新主機的從機(朕的大清亡了!!!)。
13、快取涉及到的一些問題
13.1、 快取穿透
(沒數據導致的)
使用者想要查詢一個數據,redis中沒有找到,這個時候就會去關係型數據庫中查詢(MySql),如果我們的mysql中也沒有這個使用者的資訊,這個時候不會把這個使用者的空物件儲存到快取中(因爲快取中存了太多空物件,會影響我們的查詢效率)。
如果由使用者針對這個問題,通過JMeter等工具頻繁請求一個空物件,就可能給mysql造成很大的壓力。
> 解決方案:
布隆過濾器
13.2、 快取擊穿
(高併發的key由於過期導致)
一個熱點的key,在不停的扛着高併發的請求,當這個key過期的一瞬間,大量的請求直接請求到了數據庫。
解決方案:
設定熱點數據永不過期
加互斥鎖:使用分佈式鎖,保證同一個key只有一個執行緒就查詢後端服務,其他執行緒只需等待即可。
13.3、 快取雪崩
是指某一時間,快取集中過期。 (key的失效時間一致導致的或者是redis宕機)
解決方案
保證redis高可用,搭建redis叢集、異地多活
限流降級: 在快取失效後,通過加鎖或者佇列來控制讀數據庫寫快取的執行緒數量。比如一個key只允許一個執行緒查詢數據和寫快取,其他執行緒等待。
數據預熱: 在正式部署之前,先把可能的數據先預先存取一遍,把大量的請求方法存取數據放到快取裏邊。
14、 布隆過濾器
布隆過濾器的原理是,當一個元素被加入集合時,通過K個雜湊函數將這個元素對映成一個位數組中的K個點,把它們置爲1。檢索時,我們只要看看這些點是不是都是1就(大約)知道集閤中有沒有它了:如果這些點有任何一個0,則被檢元素一定不在;如果都是1,則被檢元素很可能在。這就是布隆過濾器的基本思想。
Bloom Filter跟單雜湊函數Bit-Map不同之處在於:Bloom Filter使用了k個雜湊函數,每個字串跟k個bit對應。從而降低了衝突的概率。
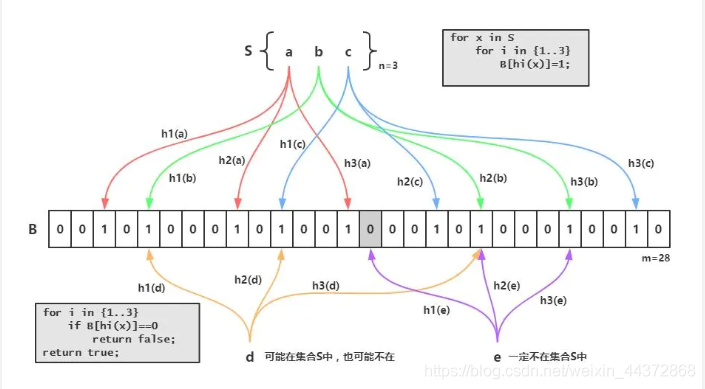
springboot中測試布隆過濾器
-
匯入依賴
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>23.0</version> </dependency>
2、 編寫測試類
package com.zzp.filter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class TestBloomFilter {
private static final int total = 1000000;
private static final BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
public static void main(String[] args) {
for (int i = 0; i < total; i++) {
bf.put(i);
}
for (int i = 0; i < total; i++) {
if(!bf.mightContain(i)) {
System.out.println(i + "是漏網之魚!"); // 沒有漏網的
}
}
int count = 0;
for(int j = total; j < total + 1000000; j++) {
if(bf.mightContain(j)){
count++;
}
}
System.out.println("錯誤數量: " + count); //錯誤數量: 30155 錯誤率是0.03左右
}
}
常見的面試題:https://blog.csdn.net/qq_35190492/article/details/102841400
相關的視訊講解,可以參考狂神說的B站視訊:
el monitor代表監控,mymaster代表伺服器的名稱,可以自定義,192.168.11.128代表監控的主伺服器,6379代表埠,2代表只有兩個或兩個以上的哨兵認爲主伺服器不可用的時候,纔會進行failover操作。
sentinel monitor mymaster 192.168.11.128 6379 2
sentinel author-pass定義服務的密碼,mymaster是服務名稱,123456是Redis伺服器密碼
sentinel auth-pass mymaster 123456
2、 啓動
```bash
# 啓動哨兵進程
./redis-sentinel ../sentinel.conf
如果主機宕機了,那麼哨兵會從從機中選舉一個slave出來作爲主機。當我們將原來宕掉的主機重新啓動後,它會變成新主機的從機(朕的大清亡了!!!)。
13、快取涉及到的一些問題
13.1、 快取穿透
(沒數據導致的)
使用者想要查詢一個數據,redis中沒有找到,這個時候就會去關係型數據庫中查詢(MySql),如果我們的mysql中也沒有這個使用者的資訊,這個時候不會把這個使用者的空物件儲存到快取中(因爲快取中存了太多空物件,會影響我們的查詢效率)。
如果由使用者針對這個問題,通過JMeter等工具頻繁請求一個空物件,就可能給mysql造成很大的壓力。
> 解決方案:
布隆過濾器
13.2、 快取擊穿
(高併發的key由於過期導致)
一個熱點的key,在不停的扛着高併發的請求,當這個key過期的一瞬間,大量的請求直接請求到了數據庫。
解決方案:
設定熱點數據永不過期
加互斥鎖:使用分佈式鎖,保證同一個key只有一個執行緒就查詢後端服務,其他執行緒只需等待即可。
13.3、 快取雪崩
是指某一時間,快取集中過期。 (key的失效時間一致導致的或者是redis宕機)
解決方案
保證redis高可用,搭建redis叢集、異地多活
限流降級: 在快取失效後,通過加鎖或者佇列來控制讀數據庫寫快取的執行緒數量。比如一個key只允許一個執行緒查詢數據和寫快取,其他執行緒等待。
數據預熱: 在正式部署之前,先把可能的數據先預先存取一遍,把大量的請求方法存取數據放到快取裏邊。
14、 布隆過濾器
布隆過濾器的原理是,當一個元素被加入集合時,通過K個雜湊函數將這個元素對映成一個位數組中的K個點,把它們置爲1。檢索時,我們只要看看這些點是不是都是1就(大約)知道集閤中有沒有它了:如果這些點有任何一個0,則被檢元素一定不在;如果都是1,則被檢元素很可能在。這就是布隆過濾器的基本思想。
Bloom Filter跟單雜湊函數Bit-Map不同之處在於:Bloom Filter使用了k個雜湊函數,每個字串跟k個bit對應。從而降低了衝突的概率。
[外連圖片轉存中…(img-k0c6cjTp-1597226757686)]
springboot中測試布隆過濾器
-
匯入依賴
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>23.0</version> </dependency>
2、 編寫測試類
package com.zzp.filter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class TestBloomFilter {
private static final int total = 1000000;
private static final BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
public static void main(String[] args) {
for (int i = 0; i < total; i++) {
bf.put(i);
}
for (int i = 0; i < total; i++) {
if(!bf.mightContain(i)) {
System.out.println(i + "是漏網之魚!"); // 沒有漏網的
}
}
int count = 0;
for(int j = total; j < total + 1000000; j++) {
if(bf.mightContain(j)){
count++;
}
}
System.out.println("錯誤數量: " + count); //錯誤數量: 30155 錯誤率是0.03左右
}
}
常見的面試題:https://blog.csdn.net/qq_35190492/article/details/102841400
相關的視訊講解,可以參考狂神說的B站視訊:
https://www.bilibili.com/video/BV1S54y1R7SB?p=1