如何在生產環境mysql刪除億萬級數據解並且不影響數據庫主從延遲的解決方案
目錄
分場景1、被刪除的數據很小小到只會引起10分鐘內的主從延遲-不建議
分場景2、被刪除的數據不小,但是如果直接delete一定會引起15分鐘以上的主從延遲
最終對於生產mysql的日誌清理策略的best practice
自動監控mysql主從延遲報警shell指令碼-behind_master.sh
使用CentOS的crontab設定監控指令碼每5s執行一次寫法
自動發送告警資訊到企業微信介面(aldi-cupidmq)的python指令碼
前言
本方案適合:無關業務的「日誌數據」,但往往日誌數據是最最佔用我們的整體系統效能的,因此對這樣的日誌,我們是需要進行定期清理的。
如果你要說:業務數據也需要那麼我告訴你,業務數據肯定用的是本方案中的場景2中的分場景2模式(只有這一條路),但是業務數據會暴發到你連本方案都無法覆蓋的那一天的(很快的,如我上一家公司:幾千萬的會員生成業務流水),那麼當本方案都失效時怎麼辦?
答案就是:垂直折分,hash一致演算法,sharding sphere就要用上了,對於這一塊涉及到的面太龐大了因此我需要寫一段時間,當我寫完也會分享給到大家。
開始進入正文:
如果你是單機,如果你是自己在家玩。你的數據庫裡有億級數據,你來一條:
delete from user_behavior_logs;
然後你慢慢等個幾小時,等到你的mysql暴了、硬碟被燒了都沒事。
如果你在公司的生產環境,特別是在具有主從複製、1主多從甚至多主多從的環境下,你來一條delete命令,你知道會發生什麼事嗎?
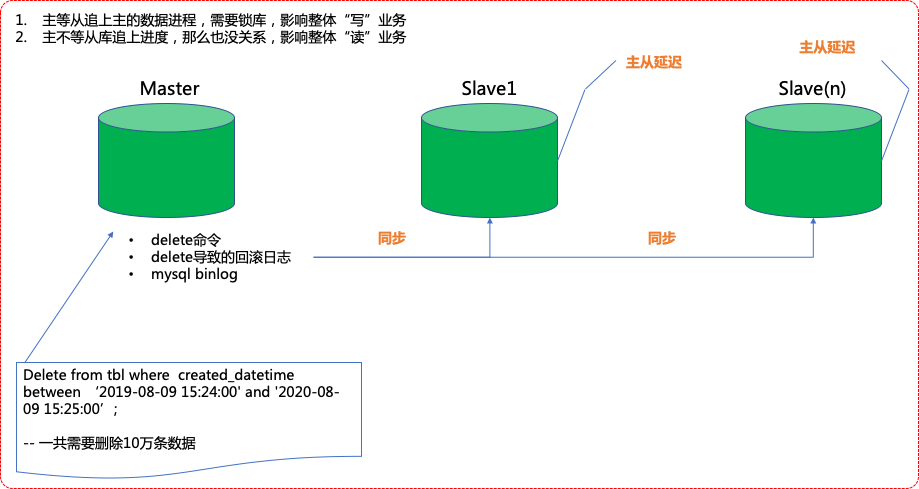
爲什麼在生產上主從環境情況下mySQL特別容易卡死
它的原理其實是:mysql上的delete語句首先會同步到各個從庫上,delete語句會產生redo日誌也會同步在各個從庫上,然後是mysql本身數據的binlog也在同步。三條操作*總mysql庫量*你刪除的數據量產生的:
- 網路io
- CPU消耗
- 磁碟讀寫
- 等等等其它
導致了上面的「主從延遲」這樣的一個問題。
當發生主從延遲時其實是不用怕的,當生產環境讀寫操作頻繁,總會發生一定概率的主從延遲。偶爾在大促季,一天發生個1-2次並且只要在主從延遲發生時,從庫可以在5-10分鐘內追平主庫就不構成任何影響。
但是,如果發生了主從延遲,這個從延尺不斷的在加大時間,超過了20分鐘,30分鐘,往40、60分鐘走時,此時的整個db羣就是:讀業務全部受影響,因爲從還沒執行完自己的任務還要去追主,但是主上不斷的在寫進大量的數據。一般爲了讓從能夠追上主,你就必須「鎖主庫」。
我們都知道,在生產環境下是不能鎖主庫的,一鎖,所有的訂單或者相關的「寫操作」都沒法提交了。
那麼就有人說了:讓從慢慢追主吧。
但是,些時你的整體網站是讀寫分離的,從庫追不平主庫,整體的讀業務又受影響。
這個痛苦啊,此時就會發生著名的「主從延遲土撥鼠之日」,這是一個悖論,即:
眼看着數據庫裡的日誌越來越多、佔用的磁碟越來越大、影響了日常的正常報表、運維工作,再不刪,整體業務要嚴重受到影響。但是呢,當你要去刪,就又出現了嚴重的主從延遲,一樣影響業務。咽不下去也吐不出,活活被憋死!
不要去怪設計不要去怪開發我們devops靠自己
「一千個觀衆眼中有一千個哈姆雷特」--《殺死比爾說的-哦,不是,是莎士比亞》

可是,我們在生產db上刪除記錄並且又能不影響主從同步的話就只有「一種」方法,我們在說任何方法前先來一個感性的認識,即我們先用「人類」可以懂的語言來描述一下這件事到底該怎麼做。它其實可以分爲兩個場景來做,每個場景有不同的做法:
場景一、當要被刪除的數據量遠大於保留的數據量的場景下的做法
場景二、當要被刪除的數據量遠小於保留的數據量的場景下的做法
下面 下麪,就讓我們來展開這兩個場景吧。
場景一、當要被刪除的數據量遠大於保留的數據量的場景下的做法
假設我們實際要執行的是下面 下麪這樣的一條sql:
delete from user_behavior_logs where created_datetime between '2016-08-10 17:20:00' and '2019-12-31 17:20:00';
這涉及到在生產的主庫上:
刪除:1700萬條記錄
實際需要保留的數據:30萬條,條件: between '2020-01-01 17:20:00' and '2020-08-10 17:20:00',30萬條數據。
那麼我們的做法爲:
1) 照着要被刪除的table名建立一個完全一模一樣名字帶tmp_字首的table名
2)選取要保留的數據 into tmp_table
3)rename table 原來的table名 to deleted_原來的table名
4)rename table tmp_table to 原來的table名
5)drop table deleted_原來的table名
它化成具體的操作就是以下這麼幾條sql(create table語句省略,因爲這個太簡單了)
insert into tmp_user_behavior_logs
(
ak,gu,ln,st,os,
ss,ip,bruser_behavior_logs,lan,fv,ifj,ifc,brs,cp,pn,pl,chn,sv,ev,et,pt,prn,created_datetime
)
select
ak,gu,ln,st,os,
ss,ip,bruser_behavior_logs,lan,fv,ifj,ifc,brs,cp,pn,pl,chn,sv,ev,et,pt,prn,now()
from user_behavior_logs where created_datetime between '2020-01-01 17:20:00' and '2020-08-10 17:20:00';
rename table user_behavior_logs to deleted_user_behavior_logs;
rename table tmp_user_behavior_logs to user_behavior_logs;
drop table deleted_user_behavior_logs;
操作涉及數據量及環境
爛機器環境下的執行情況
以上的操作位於:base 1000萬條記錄,同時使用壓力測試工具不斷的往數據庫中以每5秒進5000條數據的速度插入新數據,master slaver主從情況下,在4c cpu, 8gb ram,非ssd磁碟執行情況:
對於insert into ...select from...語句涉及到30萬數據量的情況下,執行時間爲:16s,執行期間有報主從同步,主從同步一開始值有點高爲70s,這個報警持續了5分鐘左右即消失;
對於rename與drop語句執行只用了1s,執行過程無任何主從同步報警;
結論
就算主從報警,爲完全可接受範圍內。
好機器環境下的執行情況
以上的操作位於:base 1000萬條記錄,同時使用壓力測試工具不斷的往數據庫中以每5秒進5000條數據的速度插入新數據,master slaver主從情況下,在64c cpu, 256gb ram,ssd磁碟執行情況:
對於insert into ...select from...語句涉及到30萬數據量的情況下,執行時間爲:1.3s,執行期間,有報主從同步,主從同步一開始值爲5s,這個報警持續了15s就消失了;
對於rename與drop語句執行只用了1s,執行過程無任何主從同步報警;
結論
就算主從報警也可以忽略不計。
場景二、當要被刪除的數據量遠小於保留的數據量的場景下的做法
分場景1、被刪除的數據很小小到只會引起10分鐘內的主從延遲-不建議
第1步:確定要被刪除的id範圍;
第2步:使用儲存過程,分成小批次刪除,每次刪除的量不要超過(delete+where條件)萬條。刪除後停一下,再刪下一批,全程最好有監控報警隨時看着
操作涉及數據量及環境
爛機器環境下的執行情況
以上的操作位於:base 2.1億條記錄,總共:460gb,同時使用壓力測試工具不斷的往數據庫中以每5秒進5000條數據的速度插入新數據,master slaver主從情況下,在4c cpu, 8gb ram,非ssd磁碟執行情況:
對於delete from user_behavior_logs where id between 1 and 5000; 每隔30秒我做一次這樣的delete操作。
實際操作時間爲:3.7s,主從延遲報警持續了:59s即告結束。
結論
就算主從報警,爲完全可接受範圍內。
好機器環境下的執行情況
以上的操作位於:base 1000萬條記錄,每5秒進5000條數據,master slaver主從情況下,在64c cpu, 256gb ram,ssd磁碟執行情況:
對於delete from user_behavior_logs where id between 1 and 5000; 每隔30秒我做一次這樣的delete操作。
實際操作時間爲:1s,主從延遲報警持續了:8s即告結束。
結論
就算主從報警,爲完全可接受範圍內。每次刪除需要少數據量,頻率不能太高,每次刪完當中需要有一個30-60秒的間隔以讓從儘量追上主庫。
分場景2、被刪除的數據不小,但是如果直接delete一定會引起15分鐘以上的主從延遲
假設我們實際要執行的是下面 下麪這樣的一條sql:
delete from user_behavior_logs where created_datetime between '2020-04-07 09:00:00' and '2020-08-07 14:00:00';
這涉及到在生產的主庫上:
刪除:170萬條記錄
實際需要保留的數據:9000w條記錄,條件爲created_datetime between '2020-04-07 09:00:00' and '2020-08-07 14:00:00';
那麼我們的做法爲:
第一步:mysqldump成一個檔案;
第二步:把dump出去的檔案匯入到一個新的表中去
第三步:使用分場景2中的rename手法來
注意:這個手法只有在非業務時間段即一般在零晨去做這個事情,mysqldump回新表時,會造成不小的主從延遲,來看一下本人的實際操作情況。
爛機器環境下的執行情況
以上的操作位於:base 1億條記錄,總共:140gb,同時使用壓力測試工具不斷的往數據庫中以每5秒進5000條數據的速度插入新數據,master slaver主從情況下,在4c cpu, 8gb ram,非ssd磁碟執行情況:
對於delete from user_behavior_logs where created_datetime between '2020-04-07 09:00:00' and '2020-08-07 14:00:00'; 要刪除的數據多達:170w條,需要保留的有9900w條。
用mysqldump導出和恢復9900w條記錄總計用了:6小時,造成了嚴重的主從同步,最後不得不鎖主庫,再用mysqldump追平從庫,最後造成整個操作沒法完成。
結論
該操作確實很耗時,在一般機器上很難模擬,也驗證了,這種操作很耗資源。
好機器環境下的執行情況
以上的操作位於:base 1億條記錄,總共:140gb,同時使用壓力測試工具不斷的往數據庫中以每5秒進5000條數據的速度插入新數據,master slaver主從情況下,在64c cpu, 256gb ram,ssd磁碟執行情況:
對於delete from user_behavior_logs where created_datetime between '2020-04-07 09:00:00' and '2020-08-07 14:00:00'; 要刪除的數據多達:170w條,需要保留的有9000w條。
用mysqldump導出和恢復9900w條記錄總計用了:3小時,從庫每3分鐘報一次主從同步,連續了3小時直到mysqldump把9900w條記錄匯入了新表才告終目。而後續的rename表名和drop都是秒級,期間無任務報警。
結論
這種手法,只有在非營業時間去做,並且這點時間是完全可以忍受的,但是這種需求只應該每半年或者季度發生一次。
最終對於生產mysql的日誌清理策略的best practice
- 策略一、如果需要刪除的數據很多,多到比如說需要刪除相當於原表數據內的50%,並且這個總量超過10個gb的話,都必須在非業務時間,有足夠的空餘時間(8小時內)才能 纔能去做這樣的操作,操作前必須建立1v1數據庫驗證這個手法可以在8小時內完成,然後纔可以去正式生產上做操作。並且這種操作視業務量,一般6個月或者最頻繁3個月一次足以了;
- 策略二、如果需要刪除的數據遠大於需要保留的數據,比如說需要保留的數據不過百萬來條,10個gb以內,完全可以使用場景一中的「5步曲」去做這個操作;
- 場景2中的分場景1,不建議原因有兩點:1)你根本無法控制自動指令碼的跑delete語句的準確率,特別是生產環境,你能確保定時觸發的delete語句每次都刪除的數據量是你規定的嗎?2)如果在高併發環境下,爲了確保被自動觸發的delete語句永遠是安全的你就必須去控制這個delete語句的數據範圍,一般會控制在很少值,那麼就是你刪除的速度遠遠跟不上進入的數據,你的分小段delete清理日誌手段或者在一開始業務量小的情況下有一定的效果,但是如果業務一旦爆增這種「涓涓溪流」的行爲是毫無任何意義的;
- 無論採取的是策略一還是策略二,絕對不可以設成「自動指令碼」,必須全程人爲幹涉和監控。就算用的是策略二、半年這麼幸苦一晚上也是值得的;
附錄
自動監控mysql主從延遲報警shell指令碼-behind_master.sh
#!/bin/bash
#desc:指令碼
#通過從庫監控Seconds_Behind_Master的值監控延遲情況。
#該值爲null或着超過告警閾值會報錯.
#本腳還通過mysql命令執行情況判定mysql服務可用狀態。
#author:hahaxiao_mk
#date:2018/04/27
#source ~/.bash_profile
#source ~/.bashrc
#----Seconds_Behind_Master的值
v_sbm='NULL'
#----檢測域值,單位s
v_threshold=1
#----機器標示
v_machine_mark=ymkmysql
MYSQL_HOME=/usr/local/mysql
#-----發送告警資訊函數
function f_send_msg()
{
echo "準備發送主從遲告警:${1} ${2}" >> /home/appadmin/behind_master.log
python /home/appadmin/send_alert_msg.py ${1}$2 101 1
#呼叫alert告警${v_java_home_bin}/java -jar /opt/config/inf/alarm.jar 1 $1 $2
}
#-----判定mysql服務狀態
starttime=$(date +%Y-%m-%d\ %H:%M:%S)
v_mysql_status=`mysql -uroot -phaha -P3306 -h10.0.0.1 -e "show slave status\G"|grep Seconds_Behind_Master`
echo "開發庫10.0.0.1於 ${starttime} -> 主從延遲目前爲:${v_mysql_status}" >> /home/appadmin/behind_master.log
if [ $? -eq 1 ]
then
v_err_msg="mysql is not available! "
# f_send_msg ${v_mobile} ${v_err_msg}
echo ${v_err_msg}
f_send_msg ${v_err_msg}
exit
fi
#------判定延遲情況
v_sbm=`echo ${v_mysql_status}|awk -F ":" '{print $2}'`
if [ "${v_sbm}" = " NULL" ]
then
v_err_msg="開發庫10.0.0.1於 ${starttime} -> 發生主從延遲爲: ${v_sbm}!"
# f_send_msg ${v_mobile} ${v_err_msg}
#echo ${v_err_msg}
f_send_msg ${v_err_msg}
elif [ ${v_sbm} -gt ${v_threshold} ]
then
v_err_msg="開發庫10.0.0.1發生主從延遲${v_sbm}s!"
echo ${v_err_msg} >> /home/appadmin/behind_master.log
#f_send_msg ${v_mobile} ${v_err_msg}
#echo ${v_err_msg}
f_send_msg ${v_err_msg}
fi
使用CentOS的crontab設定監控指令碼每5s執行一次寫法
crontab -e
然後把下面 下麪這一陀複製進去吧(crontab的最小條件爲分鐘,因此要做成秒必須化解成以下的語句,這是一個實用技巧
* * * * * sh /home/appadmin/behind_master.sh
* * * * * sleep 5; sh /home/appadmin/behind_master.sh
* * * * * sleep 10; sh /home/appadmin/behind_master.sh
* * * * * sleep 15; sh /home/appadmin/behind_master.sh
* * * * * sleep 20; sh /home/appadmin/behind_master.sh
* * * * * sleep 25; sh /home/appadmin/behind_master.sh
* * * * * sleep 30; sh /home/appadmin/behind_master.sh
* * * * * sleep 35; sh /home/appadmin/behind_master.sh
* * * * * sleep 40; sh /home/appadmin/behind_master.sh
* * * * * sleep 45; sh /home/appadmin/behind_master.sh
* * * * * sleep 50; sh /home/appadmin/behind_master.sh
自動發送告警資訊到企業微信介面(aldi-cupidmq)的python指令碼
#!/usr/bin/python
import re
import requests
import time
import json
import sys
url='http://localhost:9081/alertservice/sendMsg'
if (len(sys.argv)>1):
inputedmsg=sys.argv[1]
msgtype=sys.argv[2]
modelId=sys.argv[3]
print('input message->'+inputedmsg+' input msgtype->'+msgtype+' modelId->'+modelId)
currentTime=time.strftime('%Y/%m/%d %H:%M:%S',time.localtime(time.time()))
print 'current time is ', currentTime
if(msgtype=='101'):
wechatmsg='Issue happened on ' +currentTime +':\n'+ inputedmsg
wechatcontent={"modelId": modelId, "content": wechatmsg}
wechatheaders = {"content-type": "application/json; charset=UTF-8", "type": "101"}
req = requests.post(url, data=json.dumps(wechatcontent),headers=wechatheaders)
print(req.text)
elif(msgtype=='102'):
print('send mail msg')
else:
print('inputed msgtype required 101|102')
else:
print('inputed msg can not be null')
企業微信收到主從延遲後的展示效果
