java 正則表達式
java 正則表達式
1、正則表達式:regular expression搜尋模式可以是簡單字元,固定字串或包含描述模式的特殊字元的複雜表達式的任何內容
由正則表達式定義的 pattern 可以同時匹配一個或多個,或者一個都沒匹配到正則表達式可用於搜尋,編輯和操作文字 使用正則表達式分析或修改文字的過程稱爲:正則表達式應用於文字/字串 由正則表達式定義的模式從左到右應用於文字。一旦源字元在匹配中被使用,就不能重複使用。
例如,正則表達式aba將僅可以匹配ababababa兩次(aba_aba__)
2、正則表達式的範例及描述:
| 正則表達式 | 描述 |
|---|---|
| this is text | 匹配字串 「this is text」 |
| this\s+is\s+text | 注意字串中的 \s+。 匹配單詞 「this」 後面的 \s+ 可以匹配多個空格,之後匹配 is 字串,再之後 \s+ 匹配多個空格然後再跟上 text 字串。 可以匹配這個範例:this is text |
| ^\d+(.\d+)? | ^ 定義了以什麼開始 \d+ 匹配一個或多個數字 ? 設定括號內的選項是可選的 . 匹配 「.」 可以匹配的範例:」5」, 「1.5」 和 「2.21」。 |
3、正則表達式規則
3.1、常見匹配符號
| 正則表達式 | 描述 |
|---|---|
. |
匹配任何字元 |
^ |
匹配輸入字串開始的位置。如果設定了 RegExp 物件的 Multiline 屬性,^ 還會與」\n」或」\r」之後的位置匹配。。 |
$ |
匹配輸入字串結尾的位置。如果設定了 RegExp 物件的 Multiline 屬性,$ 還會與」\n」或」\r」之前的位置匹配。。 |
[abc] |
集定義,可以匹配字母A或B或C。例如,」[abc]」匹配」jian」中的」a」。。 |
[abc][vz] |
集定義,可以匹配或B或C,接着爲v或z。 |
[^abc] |
向字元集。匹配未包含的任何字元。例如,」[^abc]」匹配」plain」中」p」,」l」,」i」,」n」。 |
[a-d1-7] |
範圍:從1到7 a和d和數位之間的匹配信,但不能匹配D1。 |
X|Z |
查詢X或Z |
XZ |
發現X直接跟着Z. |
3.2、元字元
下面 下麪的元字元有一個預先定義的含義,使某些共同的pattern更易於使用,例如 \d 代替 [0…9]。
| 正則表達式 | 描述 |
|---|---|
\d |
數位字元匹配。等效於 [0-9]。] |
\D |
非數位字元匹配。等效於 [^0-9]。 |
\s |
匹配任何空白字元,包括空格、製表符、換頁符等。與 [ \f\n\r\t\v] 等效。 |
\S |
匹配任何非空白字元。與 [^ \f\n\r\t\v] 等效。 |
\w |
垂直製表符匹配。與 \x0b 和 \cK 等效。 |
\W |
匹配任何字類字元,包括下劃線。與」[A-Za-z0-9_]」等效。 |
\S |
匹配任何非空白字元。與 [^ \f\n\r\t\v] 等效。 |
\b |
匹配一個單詞邊界,單詞字元是 [a-zA-Z0-9_] |
3.3、量化
量詞定義如何經常可以發生的元素。{}的符號?,*,+,並定義正則表達式的數量
| 正則表達式 | 描述 | 例子 |
|---|---|---|
* |
出現零次或更多次,等效於{0,} ,例如,jia* 匹配」ji」和」jian」{0,} |
X*X *0個或多個字母X,。*找到任何字元序列 |
+ |
發生一次或多次,是{1,}的縮寫 {1,} |
X+ - 找到一個或幾個字母X |
? |
沒有發生次或一次,?是{0,1}的縮寫。 |
X? 未找到或只有一個字母X |
{X} |
非負整數。正好匹配 X 次。例如,」o{2}」與」Bob」中的」o」不匹配,但與」food」中的兩個」o」匹配。 | \d{3}搜尋三位數位,.{10}對於長度爲10的任何字元序列。 |
{X,Y} |
X和Y之間發生, | \d{1,4}``\d出現至少一次,並最多出現四個。 |
*? |
?後一個量詞使其成爲一個不貪婪的量詞。它試圖找到最小的匹配。。 |
3.4、捕獲組
捕獲組是把多個字元當一個單獨單元進行處理的方法,它通過對括號內的字元分組來建立。
例如,正則表達式 (dog) 建立了單一分組,組裏包含」d」,」o」,和」g」。
捕獲組是通過從左至右計算其開括號來編號。例如,在表達式((A)(B(C))),有四個這樣的組:
- ((A)(B©))
- (A)
- (B©)
- ©
以通過呼叫 matcher 物件的 groupCount 方法來檢視錶達式有多少個分組。groupCount 方法返回一個 int 值,表示matcher物件當前有多個捕獲組。
還有一個特殊的組(group(0)),它總是代表整個表達式。該組不包括在 groupCount 的返回值中。
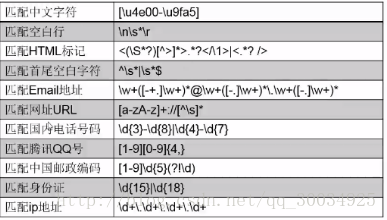
常用的正則匹配
4、Pattern與Matcher
建立一個定義正則表達式的Pattern物件。此Pattern物件允許您爲給定的字串建立Matcher物件。這個Matcher物件然後允許你對String進行正則表達式操作。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexTestPatternMatcher {
public static final String EXAMPLE_TEST = 「This is my small example string which I’m going to use for pattern matching.」;
public static void main(String[] args) {
Pattern pattern = Pattern.compile("\\w+");
// 如果忽略大小寫敏感度,
// 可以使用這個語句:
// Pattern pattern = Pattern.compile("\\s+", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(EXAMPLE_TEST);
// 檢查所有的結果
while (matcher.find()) {
System.out.print("Start index: " + matcher.start());
System.out.print(" End index: " + matcher.end() + " ");
System.out.println(matcher.group());
}
// 現在建立一個新的pattern和Matcher 以用索引標签替換空格s
Pattern replace = Pattern.compile("\\s+");
Matcher matcher2 = replace.matcher(EXAMPLE_TEST);
System.out.println(matcher2.replaceAll("\t"));
}}
5、正則表達式範例
5.1、建立一個鏈接檢查器允許從網頁中提取所有有效的鏈接。它不考慮以「javascript:」或「mailto:」開頭的鏈接。
public class LinkGetter {
private Pattern htmltag;
private Pattern link;
public LinkGetter() {
htmltag = Pattern.compile("<a\\b[^>]*href=\"[^>]*>(.*?)</a>");
link = Pattern.compile("href=\"[^>]*\">");
}
public List<String> getLinks(String url) {
List<String> links = new ArrayList<String>();
try {
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(new URL(url).openStream()));
String s;
StringBuilder builder = new StringBuilder();
while ((s = bufferedReader.readLine()) != null) {
builder.append(s);
}
Matcher tagmatch = htmltag.matcher(builder.toString());
while (tagmatch.find()) {
Matcher matcher = link.matcher(tagmatch.group());
matcher.find();
String link = matcher.group().replaceFirst("href=\"", "")
.replaceFirst("\">", "")
.replaceFirst("\"[\\s]?target=\"[a-zA-Z_0-9]*", "");
if (valid(link)) {
links.add(makeAbsolute(url, link));
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return links;
}
private boolean valid(String s) {
if (s.matches("javascript:.*|mailto:.*")) {
return false;
}
return true;
}
private String makeAbsolute(String url, String link) {
if (link.matches("http://.*")) {
return link;
}
if (link.matches("/.*") && url.matches(".*$[^/]")) {
return url + "/" + link;
}
if (link.matches("[^/].*") && url.matches(".*[^/]")) {
return url + "/" + link;
}
if (link.matches("/.*") && url.matches(".*[/]")) {
return url + link;
}
if (link.matches("/.*") && url.matches(".*[^/]")) {
return url + link;
}
throw new RuntimeException("Cannot make the link absolute. Url: " + url
+ " Link " + link);
}}
5.2、找到重複的單詞
以下正則表達式匹配重複的單詞。
\b(\w+)\s+\1\b1
\ b是一個字邊界,\ 1參照了第一個組的捕獲匹配,即第一個字。 (?! - in)\ b(\ w +)\ 1 \ b如果不以「-in」開頭,則會找到重複的單詞。 提示:新增(?s)以跨多行搜尋
5.3、尋找從新行開始的元素
以下正則表達式允許您找到「標題」單詞,以防其在新行中開始。
(\n\s*)title5.4、從一個給定的字串中找到想要的字串
public class RegexTest {
public static void main( String args[] ){
// 按指定模式在字串查詢
String line = "My name is Jianguotang。I am a Android programmer.I am 21 years old";
String pattern = "(\\D*)(\\d+)(.*)";
// 建立 Pattern 物件
Pattern r = Pattern.compile(pattern);
// 現在建立 matcher 物件
Matcher m = r.matcher(line);
if (m.find( )) {
System.out.println("Found value: " + m.group(0) );
System.out.println("Found value: " + m.group(1) );
System.out.println("Found value: " + m.group(2) );
System.out.println("Found value: " + m.group(3) );
} else {
System.out.println("NO MATCH");
}
}}
6、斷言