預訓練BERT學習筆記
預訓練BERT學習筆記
文章目錄
一、概述
BERT(Bidirectional Encoder Representations from Transformers)作爲Word2Vec的替代者,在NLP領域的11個方向大幅重新整理了精度,其主要特點以下幾點:
- 使用了Transformer作爲演算法的主要框架,Trabsformer能更徹底的捕捉語句中的雙向關係;
- 使用了Mask Language Model(MLM)和Next Sentence Prediction(NSP)的多工訓練目標;
- 使用更強大的機器訓練更大規模的數據,並且Google開源了BERT模型,使用者可以直接使用BERT作爲Word2Vec的轉換矩陣並高效的將其應用到自己的任務中。
BERT的本質上是通過在海量的語料的基礎上執行自監督學習方法爲單詞學習一個好的特徵表示,可以直接使用BERT的特徵表示作爲該任務的詞嵌入特徵。ERT提供的是一個供其它任務遷移學習的模型,該模型可以根據任務微調或者固定之後作爲特徵提取器。
二、Transformer框架
Transformer使用了Attention機制 機製,將序列中的任意兩個位置之間的距離是縮小爲一個常數;它不是類似RNN的順序結構,因此具有更好的並行性,符合現有的GPU框架。
2.1 總體結構
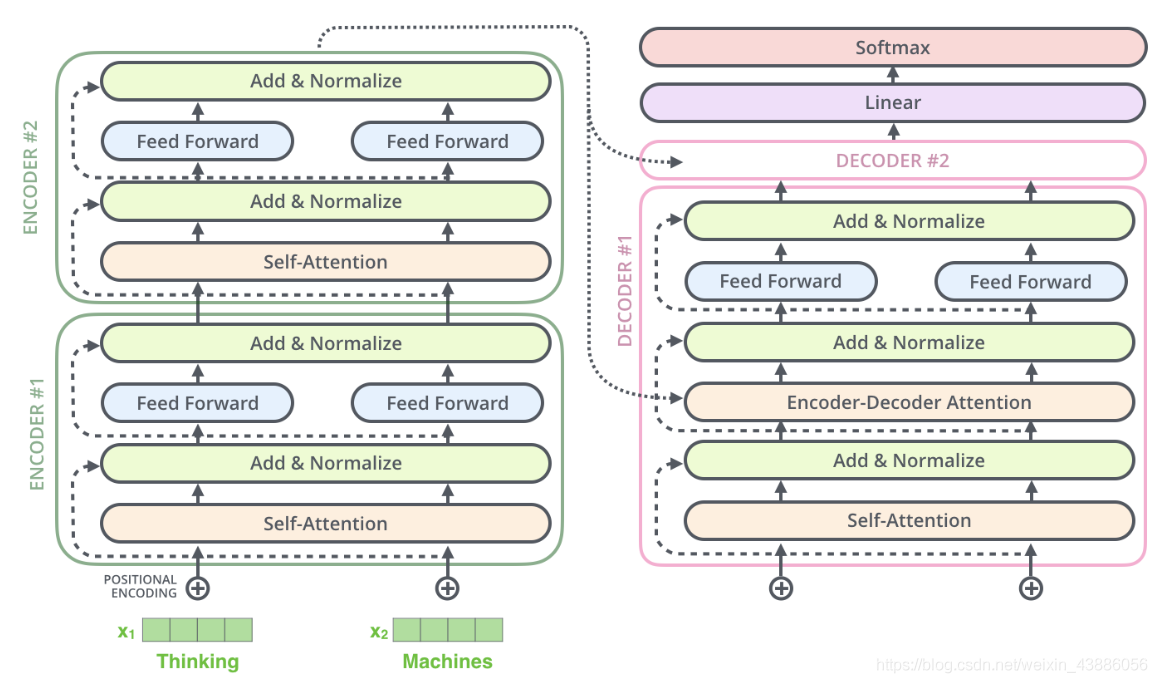
Transformer的本質上是一個Encoder-Decoder的結構:
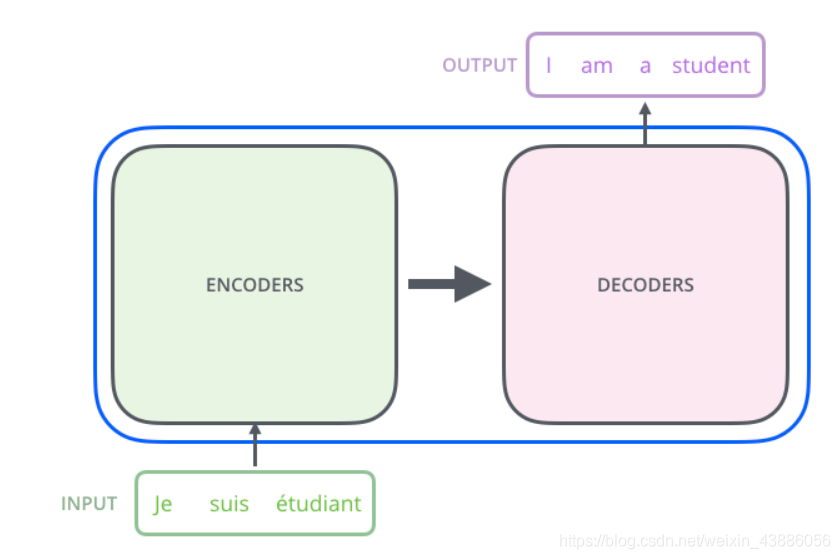
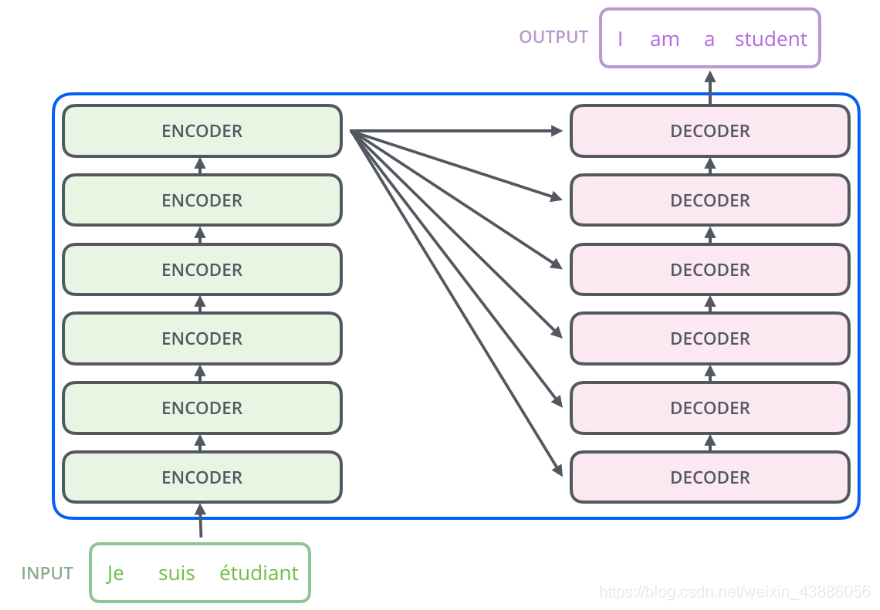
其編碼器由6個編碼block組成,同樣解碼器是6個解碼block組成。與所有的生成模型相同的是,編碼器的輸出會作爲解碼器的輸入,如下圖所示:
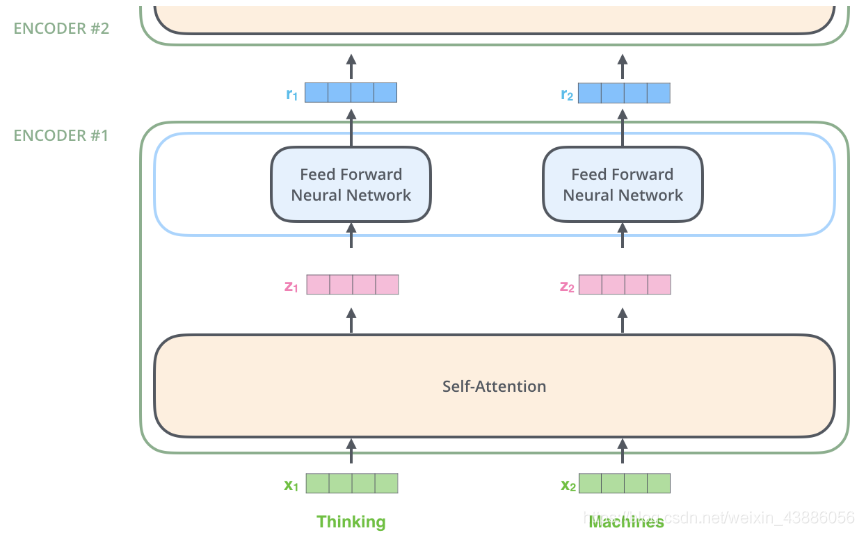
在Transformer的encoder中,數據首先會經self-attention模組得到一個加權之後的特徵向量,即:
得到之後,被送到encoder的下一個模組,Feed Forward Neural Network。這個全連線有兩層,第一層的啓用函數是ReLU,第二層是一個線性啓用函數,可以表示爲:
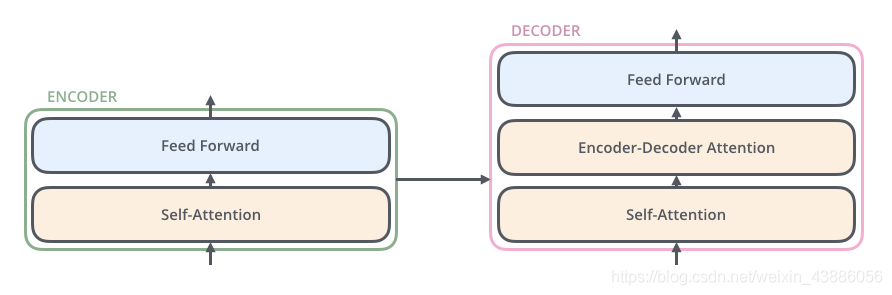
Decoder的結構與Encoder相比多了一個Encoder-Decoder Attention,兩個Attention分別用於計算輸入和輸出的權值:
- Self-Attention:當前翻譯和已經翻譯的前文之間的關係;
- Encoder-Decnoder Attention:當前翻譯和編碼的特徵向量之間的關係。
Encoder和Decoder的結構下圖所示:
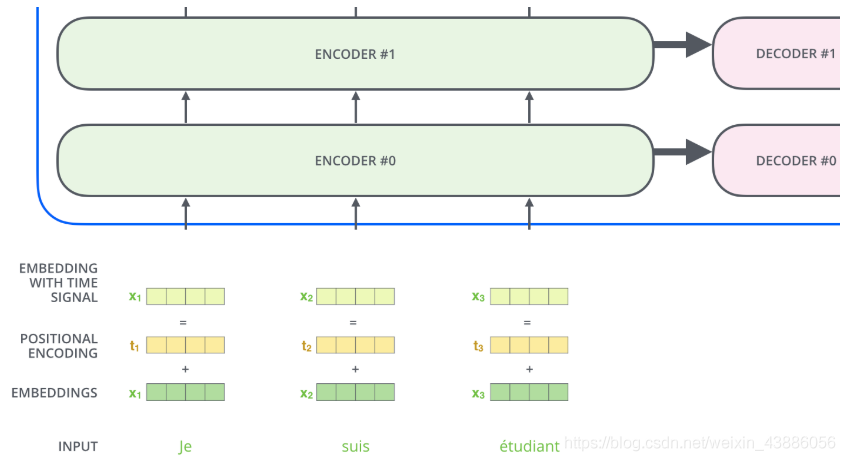
2.2 輸入編碼
首先通過Word2Vec等詞嵌入方法將輸入語料轉化成特徵向量,在最底層的block中,將直接作爲Transformer的輸入,而在其他層中,輸入則是上一個block的輸出。
2.3 Self-Attention
Self-Attention是Transformer最核心的內容,其內容是爲輸入向量的每個單詞學習一個權重,例如在下面 下麪的例子中我們判斷it代指的內容,
The animal didn’t cross the street because it was too tired.
通過加權之後可以得到類似下圖的加權情況:
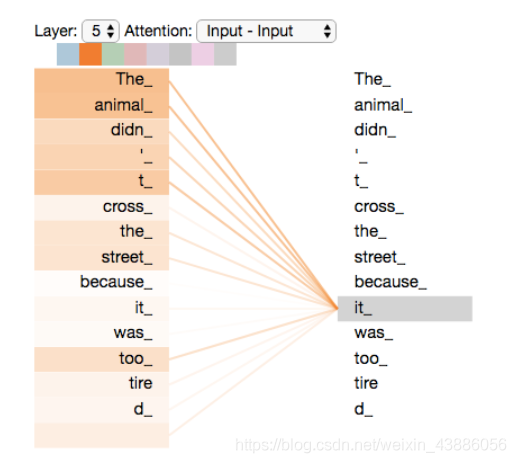
在self-attention中,每個單詞有3個不同的向量,它們分別是Query向量(),Key向量()和Value向量(),長度均是64。它們是通過3個不同的權值矩陣由嵌入向量乘以三個不同的權值矩陣,,得到,其中三個矩陣的尺寸均爲。
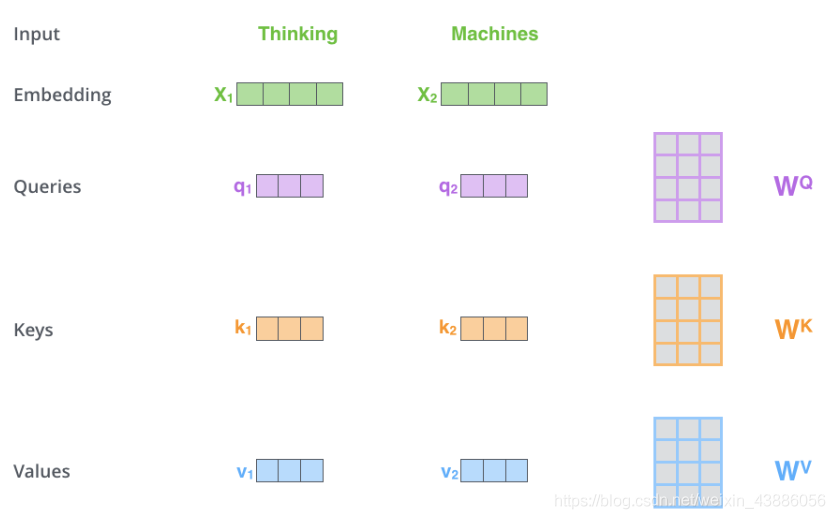
Attention的計算方法可以分成7步:
- 1.將輸入單詞轉化成嵌入向量;
- 2.根據嵌入向量得到,, 三個向量;
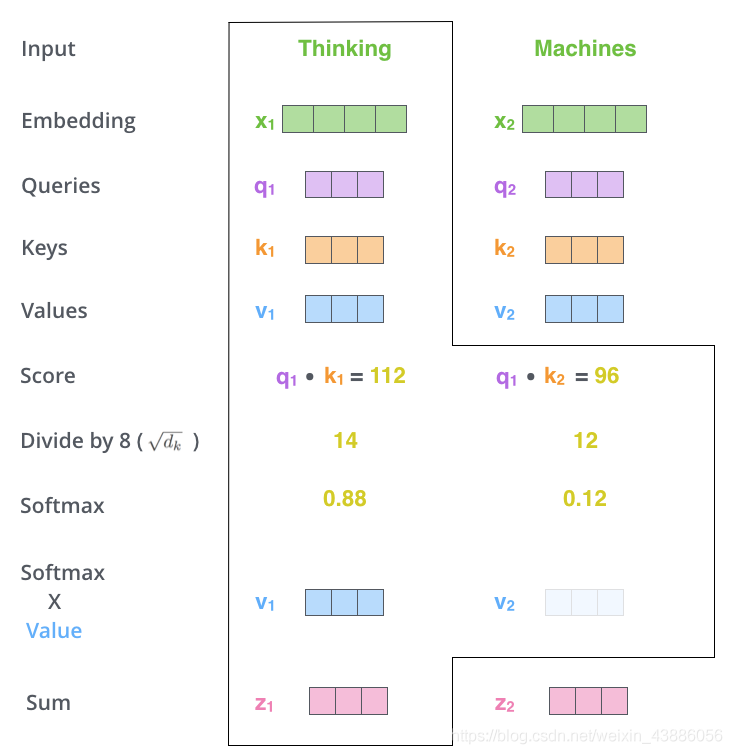
- 3.爲每個向量計算一個score: ;
- 4.爲了梯度的穩定,Transformer使用了score歸一化,即除以;
- 5.對score施以softmax啓用函數;
- 6.softmax點乘Value值 ,得到加權的每個輸入向量的評分;
- 7.相加之後得到最終的輸出結果 :。
具體過程如下圖所示:
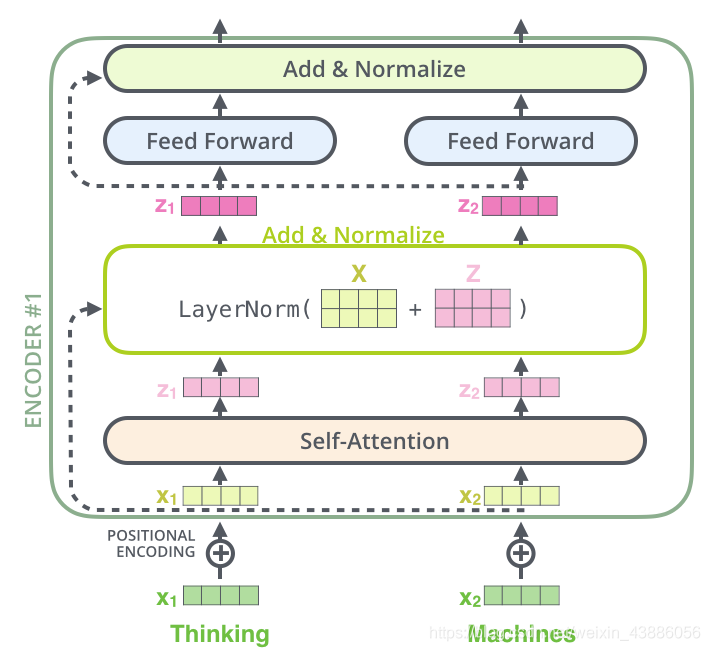
在self-attention中最後一點是其採用了殘差網路中的short-cut結構,目的是解決深度學習中的退化問題,得到的最終結果如圖。
2.3 Multi-Head Attention
Multi-Head Attention相當於h個不同的self-attention的整合。Multi-Head Attention的輸出分成3步:
- 將數據分別輸入到h個self-attention中,得到h個加權後的特徵矩陣。
- 將h個橫向拼成一個大的特徵矩陣;
- 特徵矩陣與權重矩陣相乘後得到輸出。
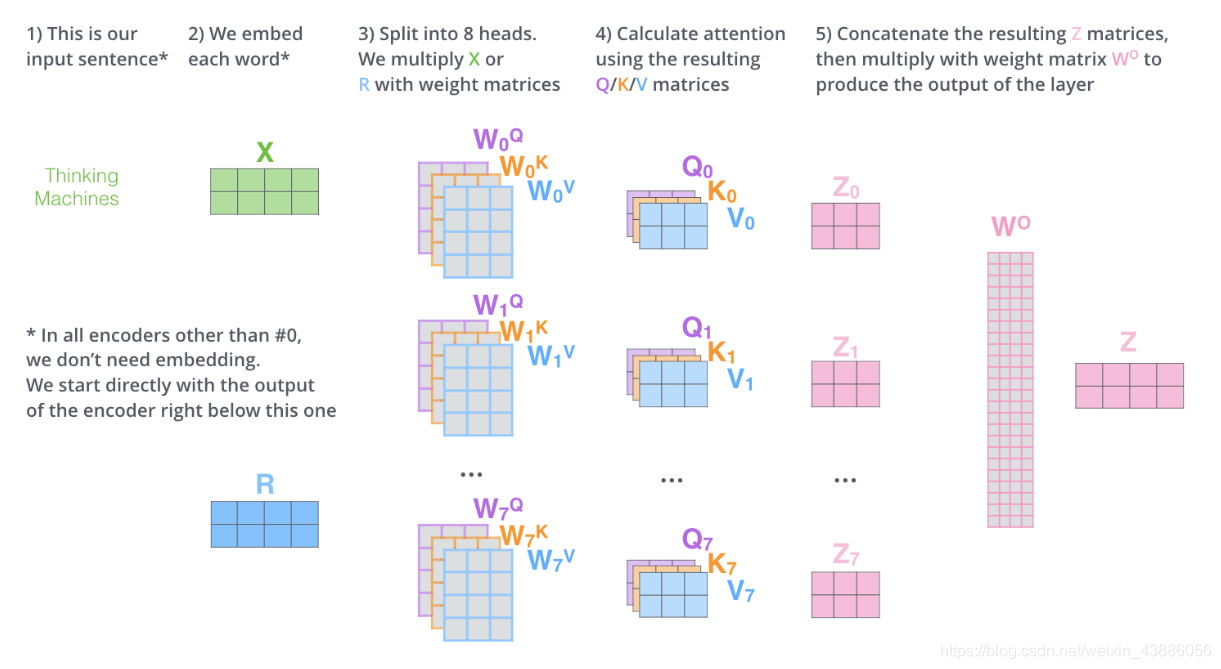
和self-attention一樣,multi-head attention也使用了short-cut機制 機製。
2.4 Encoder-Decoder Attention
在解碼器中,Transformer block比編碼器中多了個encoder-cecoder attention。在encoder-decoder attention中,來自與解碼器的上一個輸出,和則來自於編碼器的輸出。
由於在機器翻譯中,解碼過程是一個順序操作的過程,也就是當解碼第 個特徵向量時,只能看到第 及其之前的解碼結果,論這種情況下的multi-head attention被視爲masked multi-head attention。
2.5 損失層
解碼器解碼之後,解碼的特徵向量經過一層啓用函數爲softmax的全連線層之後得到反映每個單詞概率的輸出向量。此時可以通過CTC等損失函數訓練模型。一個完整可訓練的網路結構是encoder和decoder的堆疊(各 個,),完整的Transformer的結構如下:
2.6 位置編碼
爲了解決捕捉順序序列的問題,編碼詞向量時引入了位置編碼(Position Embedding)的特徵。即位置編碼會在詞向量中加入了單詞的位置資訊,從而Transformer能區分不同位置的單詞。
常見的位置編碼模式有:根據數據學習;自己設計編碼規則。huggingface採用了第二種方式。位置編碼是一個長度爲的特徵向量,這樣便於和詞向量進行單位加的操作。
其具體的編碼規則如下:
其中,表示單詞的位置,表示單詞的維度
三、BERT介紹
論文資訊:2018年10月,谷歌,NAACL
論文地址 https://arxiv.org/pdf/1810.04805.pdf
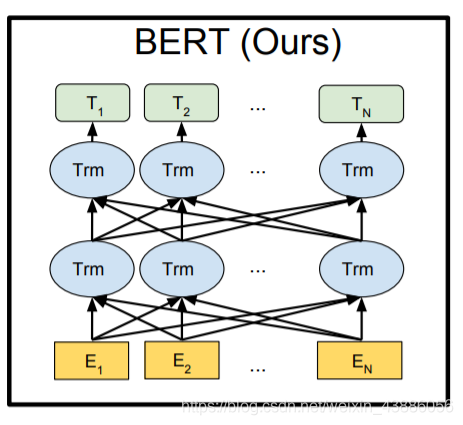
BERT全稱爲「Bidirectional Encoder Representations from Transformers」。它是一個基於Transformer結構的雙向編碼器。其結構可以簡單理解爲Transformer的encoder部分。如下圖所示:
BERT提供了簡單和複雜兩個模型,對應的超參數分別如下:
- : L=12,H=768,A=12,參數總量110M;
- : L=24,H=1024,A=16,參數總量340M;
在上面的超參數中,L表示網路的層數(即Transformer blocks的數量),A表示Multi-Head Attention中self-Attention的數量,filter的尺寸是4H。
BERT主要分爲三層,embedding層、encoder層、prediction層。
3.1 Embedding層
Embedding層是BERT的輸入層,其輸入的編碼向量(長度512)是3個嵌入特徵的單位和:
- Token Embedding:將單詞劃分成一組有限的公共子詞單元,能在單詞的有效性和字元的靈活性之間取得一個折中的平衡。比如‘playing’被拆分成了‘play’和‘ing’;
- Position Embedding:將單詞的位置資訊編碼成特徵向量,在向模型中引入單詞位置關係;
- Segment Embedding:用於區分兩個句子,例如B是否是A的下文(對話場景,問答場景等)。對於句子對,第一個句子的特徵值是0,第二個句子的特徵值是1。
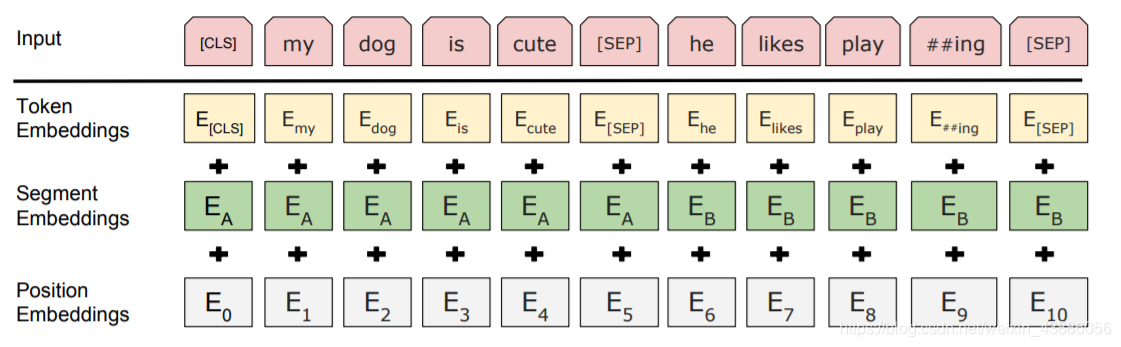
[CLS]表示該特徵用於分類模型,對非分類模型,該符合可以省去。[SEP]表示分句符號,用於斷開輸入語料中的兩個句子。
3.2 Encoder層
Encoder層則和Transformer encoder基本相同,主要完成兩個自監督任務,即MLM和NSP。
3.2.1 Masked Language Model
Masked Language Model(MLM)是指在訓練的時候隨機從輸入語料上mask掉一些單詞,然後通過的上下文預測該單詞,該任務像完形填空。
在BERT的實驗中,15%的WordPiece Token會被隨機Mask掉。在訓練模型時,一個句子會被多次傳遞到模型中用於參數學習,但是並不是每次都mask掉這些單詞,而是在確定要mask掉的單詞之後,80%的時候會直接替換爲[mask],10%的時候將其替換爲其它任意單詞,10%的時候會保留原始Token。
因爲如果句子中的某個Token 100%都會被mask掉,那麼在fine-tuning的時候模型就會有一些沒有見過的單詞。加入隨機Token的原因是因爲Transformer要保持對每個輸入token的分佈式表徵,否則模型就會記住這個[mask]與原單詞相同。而因爲一個單詞被隨機替換掉的概率只有,負面影響可以忽略不計的。另外由於每次只預測15%的單詞,因此模型收斂的比較慢。
3.2.2 Next Sentence Prediction
Next Sentence Prediction(NSP)的任務是判斷句子B是否是句子A的下文。如果是的話輸出’IsNext’,否則輸出’NotNext’。訓練數據的生成方式是從平行語料中隨機抽取的連續兩句話,其中50%保留抽取的兩句話,它們符合IsNext關係,另外50%的第二句話隨機從語料中提取,符合NotNext。這個關係儲存在[CLS]符號中。
3.3 prediction層
Prediction層採用線性全連線並做softmax歸一化。在不同的下遊任務使用中,可以把bert理解爲一個特徵抽取encoder,根據下遊任務靈活使用。BERT應用的四個場景:
- 語句對分類,如語句相似度任務,語句蘊含判斷等
- 單語句分類,如情感分類
- QA任務,如閱讀理解,將question和document構建爲語句對,輸出start和end的位置即可
- 序列標註,如NER,從每個位置得到類別即可。
對於NSP任務來說,其條件概率表示爲,其中是BERT輸出中的[CLS]符號,是可學習的權值矩陣。對於其它任務來說,可以根據BERT的輸出資訊作出對應的預測,在BERT的基礎上再新增一個輸出層便可以完成對特定任務的微調。
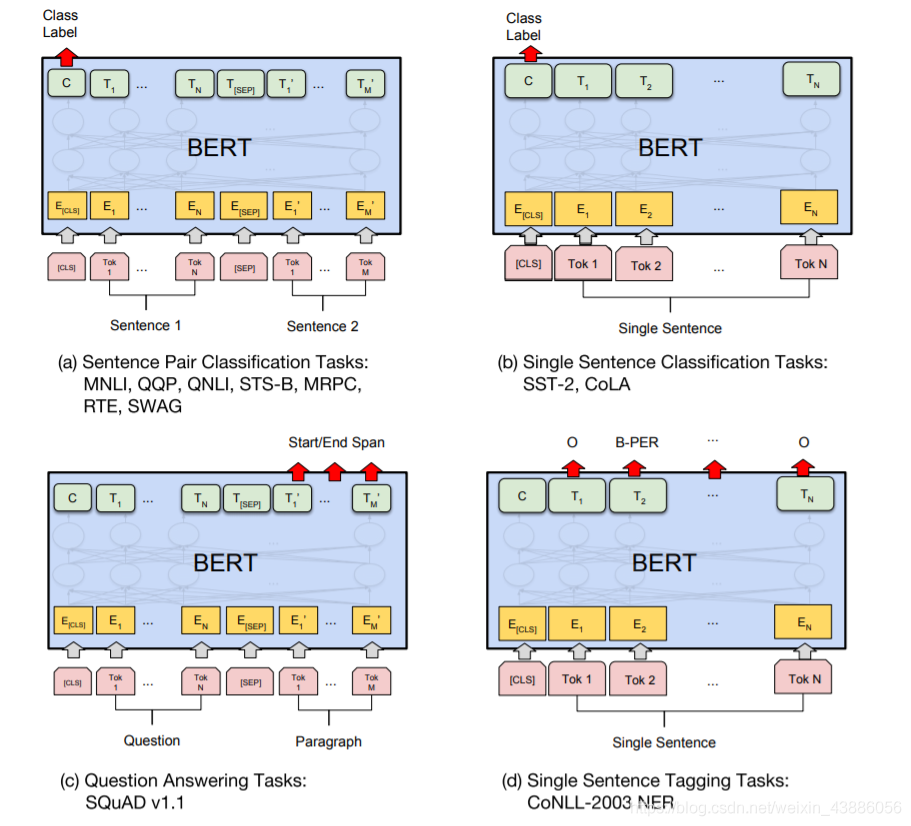
其中Tok表示不同的Token,表示嵌入向量,表示第個Token在經過BERT處理之後得到的特徵向量。
微調的任務包括:
- 1.基於句子對的分類
- MNLI:給定一個前提(Premise),根據這個前提去推斷假設(Hypothesis)與前提的關係。該任務的關係分爲三種,蘊含關係(Entailment)、矛盾關係(Contradiction)以及中立關係(Neutral)。
- QQP:基於Quora,判斷 Quora 上的兩個問題句是否表示的是一樣的意思。
- QNLI:用於判斷文字是否包含問題的答案,類似於我們做閱讀理解定位問題所在的段落。
- STS-B:預測兩個句子的相似性,包括5個級別。
- MRPC:判斷兩個句子是否是等價的。
- RTE:類似於MNLI,但是隻是對蘊含關係的二分類判斷。
- SWAG:從四個句子中選擇爲可能爲前句下文的那個。
- 2.基於單個句子的分類
- SST-2:電影評價的情感分析。
- CoLA:句子語意判斷,是否是可接受的(Acceptable)。
- 3.問答任務
- SQuAD v1.1:給定一個句子(通常是一個問題)和一段描述文字,輸出這個問題的答案,類似於做閱讀理解的簡答題。
- 4.命名實體識別
- CoNLL-2003 NER:判斷一個句子中的單詞是不是Person,Organization,Location,Miscellaneous或者other(無命名實體)。
四、原始碼分析
分析的原始碼爲基於PyTorch的HuggingFace Transformer。原始碼地址:https://github.com/huggingface/transformers。入口類爲BertModel。
4.1 入口和總體架構
使用bert進行下遊任務fine-tune時,通常先構造一個BertModel,然後由它從輸入語句中提取特徵,得到輸出。
class BertModel(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.config = config
self.embeddings = BertEmbeddings(config) # embedding向量輸入層
self.encoder = BertEncoder(config) # encoder編碼層
self.pooler = BertPooler(config) # pooler輸出層,CLS輸出
self.init_weights()
# 獲取embedding層的word_embedding,
def get_input_embeddings(self):
return self.embeddings.word_embeddings
# 利用別的數據來初始化word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
構造方法主要有以下三點:
- 讀取設定config,包括vocab_size、num_attention_heads、num_hidden_layers等參數,一般在組態檔bert_config.json中
- 構造embedding、encoder、pooler三個物件,分別對應embedding層、encoder層、prediction層。
- 利用pretrain model初始化weights,進行多頭剪枝prune_heads等。
從輸入語句提取特徵,並得到輸出,程式碼如下
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
··· # 預處理
# embedding層,包括word_embedding, position_embedding, token_type_embedding
embedding_output = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
# encoder層,得到每個位置的編碼、所有中間隱層、所有中間attention分佈
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
# CLS位置編碼向量
pooled_output = self.pooler(sequence_output)
if not return_dict:
# 返回每個位置編碼、CLS位置編碼、所有中間隱層、所有中間attention分佈等。
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
在上述從輸入語句中抽取特徵的過程中,有以下行爲:
- embedding層,對input_ids、position_ids、token_type_ids進行embedding
- encoder層,embedding後的結果,經過多層Transformer encoder,得到輸出。每一層encoder結構基本相同,均包括multi-head self-attention和feed-forward,並經過layer-norm和殘差連線
- pooler層,對CLS位置進行線性全連線,將它作爲整個sequence的輸出。
最終返回4個結果:
- sequence_output:每個位置的編碼輸出,每個位置對應一個向量
- pooled_output: CLS位置編碼輸出,經過了一層Linear和activation。一般用CLS來代表整個語句
- hidden_states:所有中間層的隱層,這個需要在config中開啓,纔會儲存下來
- attentions: 所有中間層的attention分佈,這個也需要在config中開啓,纔會儲存。
4.2 Embedding層
class BertEmbeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# layerNorm歸一化和dropout。layerNorm對歸一化做一個線性連線,故有訓練參數
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
# 獲取input_shape, [batch, seq_length]
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
# position_ids預設按照字的順利進行編碼,不足補0
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
# token_type_ids預設全0
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
# 通過embedding_lookup查表,將ids向量化
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
# 最終embedding爲三者直接相加,權值包含在embedding本身訓練參數中
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
# 歸一化和dropout後,得到最終輸入向量
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
Embedding層的具體行爲包括:
- 從三個embedding表中,通過id查詢到對應向量。三個embedding表爲word_embeddings,position_embeddings,token_type_embeddings。均是在train階段訓練得到。
- 三個embedding向量直接相加,得到總embedding。
- 對總embedding進行歸一化和dropout。
4.3 Encoder層
class BertEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=False,
output_hidden_states=False,
return_dict=False,
):
all_hidden_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
# 遍歷所有layer。bert中每個layer結構相同
for i, layer_module in enumerate(self.layer):
# 儲存每層hidden_state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if getattr(self.config, "gradient_checkpointing", False):
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, output_attentions)
return custom_forward
# 執行每層self-attention和feed-forward計算。得到隱層輸出
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(layer_module),
hidden_states,
attention_mask,
head_mask[i],
encoder_hidden_states,
encoder_attention_mask,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
head_mask[i],
encoder_hidden_states,
encoder_attention_mask,
output_attentions,
)
hidden_states = layer_outputs[0]
# 儲存每層attention分佈,預設不儲存
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
# 儲存最後一層
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
)
Encoder由多個結構相同的子層BertLayer組成,遍歷所有的子層,執行每層的self-attention和feed-forward計算,並儲存每層的hidden_state和attention分佈。
4.3.1 BertLayer子層
class BertLayer(nn.Module):
def __init__(self, config):
super().__init__()
# multi-head self attention層
self.attention = BertAttention(config)
self.is_decoder = config.is_decoder
if self.is_decoder:
# 對於decoder,cross-attention和self-attention共用一個函數
self.crossattention = BertAttention(config)
# 兩層feed-forward全連線,然後殘差並layerNorm輸出
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=False,
):
# self-attention:attention_mask 和 head_mask
self_attention_outputs = self.attention(
hidden_states, attention_mask, head_mask, output_attentions=output_attentions,
)
# hidden state隱層輸出
attention_output = self_attention_outputs[0]
# attention分佈
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
# decoder在self-attention結束後進行soft-attention
if self.is_decoder and encoder_hidden_states is not None:
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:] # add cross attentions if we output attention weights
# feed-forward和layerNorm歸一化
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
# 輸出hidden_state隱層和attention分佈
outputs = (layer_output,) + outputs
return outputs
BertLayer實現的功能包括:
- multi-head self-attention, 支援attention_mask和head_mask
- 如果作decoder的話,self-attention結束後進行一層cross-attention,將encoder資訊和decoder資訊產生互動
- feed-forward全連線和layerNorm歸一化。
4.3.2 BertAttention注意力計算
class BertAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = BertSelfAttention(config)
self.output = BertSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
# 對每層多頭進行裁剪,直接對權重矩陣剪枝
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# q,k,v和全連線上,加入mask
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=False,
):
# self-attention計算
self_outputs = self.self(
hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, output_attentions,
)
# 殘差連線和歸一化
attention_output = self.output(self_outputs[0], hidden_states)
# 輸出歸一化後隱層,和attention概率分佈
outputs = (attention_output,) + self_outputs[1:]
return outputs
BertAttention主要包括:self-attention計算和歸一化殘差連線。
4.3.3 BertIntermediate全連線
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
# 全連線,[hidden_size, intermediate_size]
hidden_states = self.dense(hidden_states)
# 非線性啓用,如glue,relu。bert預設使用glue
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
該模組主要進行全連線和非線性啓用。
4.3.4 BertOutput輸出
class BertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
# 全連線, [intermediate_size, hidden_size]
hidden_states = self.dense(hidden_states)
# dropout
hidden_states = self.dropout(hidden_states)
# 歸一化和殘差連線
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
輸出層也比較簡單經過一層全連線、dropout、layerNorm歸一化和殘差連線,得到輸出隱層。
4.4 Pooler層輸出
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# CLS位置輸出
first_token_tensor = hidden_states[:, 0]
# 全連線 + tanh啓用
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
Pooler層對CLS位置向量,進行全連線和tanh啓用,從而得到輸出向量。CLS位置向量一般用來代表整個sequence。
五、Transformers庫使用
Transformers庫中有通用模型和指定特殊任務的模型兩類。根據任務的需要,可以選擇沒有爲指定任務finetune的模型transformers.BertModel,也可以選擇爲指定任務之後的模型如transformers.BertForSequenceClassification。一共有6個指定的任務型別:
- transformers.BertForMaskedLM:語言模型;
- transformers.BertForNextSentencePrediction:判斷下一句話是否與上一句有關;
- transformers.BertForSequenceClassification:序列分類如 GLUE;
- transformers.BertForMultipleChoice:文字分類;
- transformers.BertForTokenClassification:token 分類如 NER,
- transformers.BertForQuestionAnswering;問答。
5.1 分詞 transformers.BertTokenizer
所有的tokenizer都繼承自transformers.PreTrainedTokenizer基礎類別
- tokenizer.tokenize():分詞;
- tokenizer.encode():將文字分詞後編碼爲包含對應id的列表;
- tokenizer.encode_plus():將文字分詞後建立一個包含對應id,token型別及是否遮蓋的詞典;
- tokenizer.convert_ids_to_tokens():將id轉化爲token;
- tokenizer.convert_tokens_to_ids():將token轉化爲id;
- tokenizer.decode(token_ids):將id解碼。
tokenizer = BertTokenizer.from_pretrained(r"E:\Machine Learning\bert-mul-cased")
sequence = "The program was wonderful and there were no empty seats."
print("sequence:",sequence)
print("tokenize:",tokenizer.tokenize(sequence))
ids = tokenizer.encode(sequence)
print("encode:",tokenizer.encode(sequence))
print("encode_plus:",tokenizer.encode_plus(sequence))
token = tokenizer.convert_ids_to_tokens(ids)
print("convert_ids_to_tokens:",tokenizer.convert_ids_to_tokens(ids))
print("convert_tokens_to_ids:",tokenizer.convert_tokens_to_ids(token))
print("decode:",tokenizer.decode(ids))

5.2 利用Bert進行完形填空
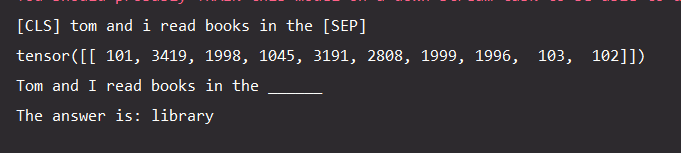
通過BertForMaskedLM,在文字中嵌入[MASK]標記,通過模型對上下文的預測,推斷出該位置的單詞。
tokenizer = BertTokenizer.from_pretrained(r"E:\Machine Learning\bert-base-uncased")
model = BertForMaskedLM.from_pretrained(r"E:\Machine Learning\bert-base-uncased")
text = "Tom and I read books in the"
indexed_tokens = tokenizer.encode(text)
temp = tokenizer.decode(indexed_tokens)
tokenized_text = tokenizer.tokenize(temp)
tokenized_text[-1] = '[MASK]' # 構造空缺 in the _____
tokenized_text.append('[SEP]')
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 在PyTorch張量中轉換indexed_tokens
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
#將模型設定爲evaluation模式,關閉DropOut模組
model.eval()
# 預測所有的tokens
with torch.no_grad():
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
predictions = outputs[0]
# 得到預測的單詞
predicted_index = torch.argmax(predictions[0, 8]).item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
# 輸出結果
print("Tom and I read books in the ______")
print("The answer is:",predicted_token)
5.3 判斷文字相似度
利用BertForSequenceClassification判斷兩個sequence的相似度,即是否符合上下文的概率。
sequence_0 = "I watched an acrobatic show at the Shanghai Great World amphitheater"
sequence_1 = "Tom went to Beijing by plane."
sequence_2 = "The program was wonderful and there were no empty seats"
paraphrase = tokenizer.encode_plus(sequence_0, sequence_2, return_tensors="pt")
not_paraphrase = tokenizer.encode_plus(sequence_0, sequence_1, return_tensors="pt")
paraphrase_classification_logits = model(**paraphrase)[0]
not_paraphrase_classification_logits = model(**not_paraphrase)[0]
paraphrase_results = torch.softmax(paraphrase_classification_logits, dim=1).tolist()[0]
not_paraphrase_results = torch.softmax(not_paraphrase_classification_logits, dim=1).tolist()[0]
print("s1與s3應該是上下文")
for i in range(len(classes)):
print(classes[i], ':', paraphrase_results[i])
print("s1與s2應該不是上下文")
for i in range(len(classes)):
print(classes[i], ':', not_paraphrase_results[i])

六、總結
-
BERT的優點:
- Transformer的設計最大的帶來效能提升的關鍵是將任意兩個單詞的距離是1,有效解決NLP中棘手的長期依賴問題;
- 演算法的並行性非常好,符合目前的硬體(GPU)環境。
-
BERT的缺點:
- BERT使模型喪失了捕捉區域性特徵的能力
- Transformer失去了位置資訊,而加入位置向量並沒有改變Transformer結構上的固有缺陷。