Python 使用總結
設定類
設定jupyter notebook
設定遠端存取
1.生成組態檔
執行–》輸入一下程式碼
$jupyter notebook --generate-config
#會在home目錄下生成一個組態檔夾,.jupyter
2.使用ipython生成密文
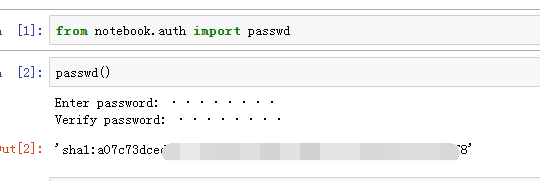
from notebook.auth import passwd
password()
Enter password:###輸入密碼
Verify password:###再次輸入密碼
3.找到/jupyter_notebook_config.py檔案

4.修改設定
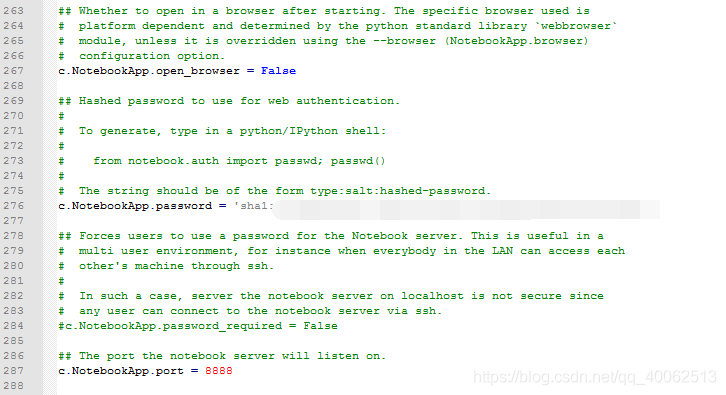
c.NotebookApp.ip='*'
c.NotebookApp.password = u'sha:ce...剛纔複製的那個密文'
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888 #隨便指定一個埠

爬蟲類
關於selenium與webdriver
參照的庫
import selenium
from selenium import webdriver
參照webdriver是模擬一個瀏覽器,不管是IE,Chrome,Fixfox都需要本機安裝的瀏覽器對應的驅動器,
谷歌瀏覽器要求下載的驅動器與本機安裝的谷歌瀏覽器版本一致
IE驅動器最好下載32位元的
IE瀏覽器驅動器下載地址
谷歌瀏覽器驅動器下載地址1
谷歌瀏覽器驅動器下載地址2
可以將.exe檔案放在python的安裝目錄下
注:裝python環境時,已經將python的安裝目錄新增到系統環境變數Path下面 下麪了
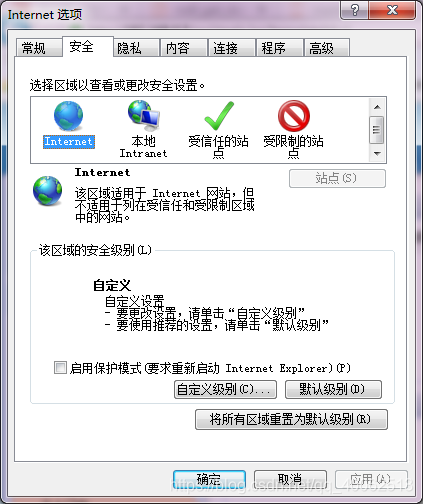
IE瀏覽器注意事項
IE瀏覽器中的保護模式必須設定爲一致,例如,都設定爲不啓用保護模式
設定地址:IE—》設定—》Internet選項—》安全
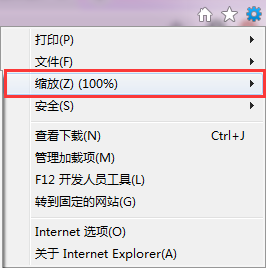
ie瀏覽器的縮放改爲100%
地址:IE–》設定–》縮放
範例化瀏覽器
###IE
driver = webdriver.Ie("IEDriverserver.exe")
###如果已經把.exe檔案放入python安裝檔案下
driver = webdriver.Ie()
###Chrome
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])###此選項可以禁用顯示 "DevTools on ws..."
driver=webdriver.Chrome(executable_path="chromedriver.exe",chrome_options=options)
webdriver常用的方法
driver.get("http://www.baidu.com")#開啓百度網頁
driver.refresh()###重新整理當前標籤頁
driver.close()##關閉當前標籤頁
driver.exit()###退出所有瀏覽器
driver.quit()###關閉瀏覽器全部標籤頁
webdriver.find_element_by_id("te").send_keys("test")#查詢id=te的文字方塊並輸入值"test"
driver.find_element_by_xpath("").send_keys("")#使用xpath查詢元素
xpath詳解
XPath,全稱 XML Path Language,即 XML 路徑語言,它是一門在 XML 文件中查詢資訊的語言。最初是用來搜尋 XML 文件的,但同樣適用於 HTML 文件的搜尋。所以在做爬蟲時完全可以使用 XPath 做相應的資訊抽取。
Xpath官方文件
W3sc教學
首先要安裝lxml :
pip install lxml
常用規則
| 表達式 | 描述 |
|---|---|
| 節點名稱 | 選擇所有此節點下的內容,例如:div |
| / | right-aligned 選擇當前節點下的內容,例如:/div |
| // | 選擇當前節點下的內容,本質與/相同,例如://div |
| . | 選取當前節點,例如:./div |
| … | 選取當前節點的父節點 |
| @ | 選取屬性,例如://div[@id=「a」],選取所有名稱爲div的節點下屬性id的值爲a的內容 |
| * | 選擇所有值,例如://div/*,選擇div下的所有值 |
運算子
| 運算子 | 描述 | 範例 | 返回值 |
|---|---|---|---|
| | | 計算兩個節點集 | //book|//cd | 返回所有擁有 book 和 cd 元素的節點集 |
| + | 加法 | 6 + 4 | 10 |
| - | 減法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等於 | price=9.80 | 如果 price 是 9.80,則返回 true。如果 price 是 9.90,則返回 false。 |
| != | 不等於 | price!=9.80 | 如果 price 是 9.90,則返回 true。如果 price 是 9.80,則返回 false。 |
| < | 小於 | price<9.80 | 如果 price 是 9.00,則返回 true。如果 price 是 9.90,則返回 false。 |
| <= | 小於或等於 | price<=9.80 | 如果 price 是 9.00,則返回 true。如果 price 是 9.90,則返回 false。 |
| > | 大於 | price>9.80 | 如果 price 是 9.90,則返回 true。如果 price 是 9.80,則返回 false。 |
| >= | 大於或等於 | price>=9.80 | 如果 price 是 9.90,則返回 true。如果 price 是 9.70,則返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,則返回 true。如果 price 是 9.50,則返回 false。 |
| and | 與 | price>9.00 and price<9.90 | 如果 price 是 9.80,則返回 true。如果 price 是 8.50,則返回 false。 |
| mod | 計算除法的餘數 | 5 mod 2 | 1 |
driver.find_element_by_id("in").click() #查詢id=te的按鈕並點選
driver.switch_to.parent_frame()#回到最開始的框架結構
driver.page_source ###獲取當前頁面內容
driver.get_cookies()###獲取當前頁面的cookie值
BeautifulSoup
from bs4 import BeautifulSoup
BeautifulSoup(driver.page_source, 'html.parser')
BeautifulSoup是一個模組,該模組用於格式化Html或者XML字串
官方文件
'''
<a name="test" class="c" id="a3"> 測試 </a>
'''
soup.get_text()###獲取所有文字內容,返回,測試
soup.a.string ###返回,測試
soup.a ###得到所有<a>標籤的內容,返回<a name="test" class="c" > 測試 </a>
soup.a.name###得到<a>標籤的name屬性,返回,test
soup.a["class"]###得到<a>標籤的class屬性,返回,C
soup.find(id="a3")###得到id=a3的內容,返回,<a name="test" class="c" id="a3"> 測試 </a>
soup.find_all('a')###得到所有標籤爲a的內容
Requests
requests庫是一個常用的用於http請求的模組,它使用python語言編寫,可以方便的對網頁進行爬取,是學習python爬蟲的較好的http請求模組。
官方文件
安裝
pip install requests
使用
###自定義一個headers,具體以爬取網站爲準
headers ={
"Accept":"application/json, text/javascript",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
#"Content-Type":"application/x-www-form-urlencoded",
#"Content-Type":"application/json",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cookie":"cookie值來自於要爬取網站的規則或者使用driver.get_cookies()獲取"
}
GET請求
requests.get("請求地址",verify = False,headers=headers,allow_redirects=False)
POST請求
post_param={'key':'value'}##json字串/請求參數
requests.post("請求地址",data=post_param,verify = False,headers=headers, allow_redirects=False)
allow_redirects 重定向請求
預設情況下,除了 HEAD, Requests 會自動處理所有重定向。
可以使用響應物件的 history 方法來追蹤重定向。
Response.history 是一個 Response 物件的列表,爲了完成請求而建立了這些物件。這個物件列表按照從最老到最近的請求進行排序。
如果你使用的是GET、OPTIONS、POST、PUT、PATCH 或者 DELETE,那麼你可以通過 allow_redirects 參數禁用重定向處理:
requests.post("請求地址", allow_redirects=False)
如果你使用了 HEAD,你也可以啓用重定向:
requests.head("請求地址",allow_redirects=True)
verfiy
爲了避免ssl認證,可以將verify=False, 但是這麼設定會帶來一個問題,日誌中會有大量的warning資訊, 如:
requests.post("請求地址",data=post_param,verify = False,headers=headers, allow_redirects=False)
如果想把這些報錯資訊去掉,只需要在請求的地方加上requests.packages.urllib3.disable_warnings()
響應狀態碼
r = requests.get('http://httpbin.org/get')
r.status_code
### 返回:200
1xx(臨時響應)
2xx (成功)
3xx (重定向)
4xx(請求錯誤)
5xx(伺服器錯誤)
| 程式碼 | 說明 |
|---|---|
| 100 | (繼續) 請求者應當繼續提出請求。 伺服器返回此代碼表示已收到請求的第一部分,正在等待其餘部分。 |
| 101 | (切換協定) 請求者已要求伺服器切換協定,伺服器已確認並準備切換。 |
| 200 | (成功) 伺服器已成功處理了請求。 通常,這表示伺服器提供了請求的網頁。 |
| 201 | (已建立) 請求成功並且伺服器建立了新的資源。 |
| 202 | (已接受) 伺服器已接受請求,但尚未處理。 |
| 203 | (非授權資訊) 伺服器已成功處理了請求,但返回的資訊可能來自另一來源。 |
| 204 | (無內容) 伺服器成功處理了請求,但沒有返回任何內容。 |
| 205 | (重置內容) 伺服器成功處理了請求,但沒有返回任何內容。 |
| 206 | (部分內容) 伺服器成功處理了部分 GET 請求。 |
| 207 | (多狀態)代表之後的訊息體將是一個XML訊息,並且可能依照之前子請求數量的不同,包含一系列獨立的響應程式碼。 |
| 208 | (已報告)DAV系結的成員已經在(多狀態)響應之前的部分被列舉,且未被再次包含。 |
| 226 | (IM Used)伺服器已經滿足了對資源的請求,對實體請求的一個或多個實體操作的結果表示。 |
| 300 | (多種選擇) 針對請求,伺服器可執行多種操作。 伺服器可根據請求者 (user agent) 選擇一項操作,或提供操作列表供請求者選擇。 |
| 301 | (永久移動) 請求的網頁已永久移動到新位置。 伺服器返回此響應(對 GET 或 HEAD 請求的響應)時,會自動將請求者轉到新位置。 |
| 302 | (臨時移動) 伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以後的請求。 |
| 303 | (檢視其他位置) 請求者應當對不同的位置使用單獨的 GET 請求來檢索響應時,伺服器返回此程式碼。 |
| 304 | (未修改) 自從上次請求後,請求的網頁未修改過。 伺服器返回此響應時,不會返回網頁內容。 |
| 305 | (使用代理) 請求者只能使用代理存取請求的網頁。 如果伺服器返回此響應,還表示請求者應使用代理。 |
| 307 | (臨時重定向) 伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以後的請求。 |
| 308 | (請求重複)請求和所有將來的請求應該使用另一個URI重複。 307和308重複302和301的行爲,但不允許HTTP方法更改。 例如,將表單提交給永久重定向的資源可能會順利進行。 |
| 400 | (錯誤請求) 伺服器不理解請求的語法。 |
| 401 | (未授權) 請求要求身份驗證。 對於需要登錄的網頁,伺服器可能返回此響應。 |
| 403 | (禁止) 伺服器拒絕請求。 |
| 404 | (未找到) 伺服器找不到請求的網頁。 |
| 405 | (方法禁用) 禁用請求中指定的方法。 |
| 406 | (不接受) 無法使用請求的內容特性響應請求的網頁。 |
| 407 | (需要代理授權) 此狀態程式碼與 401(未授權)類似,但指定請求者應當授權使用代理。 |
| 408 | (請求超時) 伺服器等候請求時發生超時。 |
| 409 | (衝突) 伺服器在完成請求時發生衝突。 伺服器必須在響應中包含有關衝突的資訊。 |
| 410 | (已刪除) 如果請求的資源已永久刪除,伺服器就會返回此響應。 |
| 411 | (需要有效長度) 伺服器不接受不含有效內容長度檔頭欄位的請求。 |
| 412 | (未滿足前提條件) 伺服器未滿足請求者在請求中設定的其中一個前提條件。 |
| 413 | (請求實體過大) 伺服器無法處理請求,因爲請求實體過大,超出伺服器的處理能力。 |
| 414 | (請求的 URI 過長) 請求的 URI(通常爲網址)過長,伺服器無法處理。 |
| 415 | (不支援的媒體型別) 請求的格式不受請求頁面的支援。 |
| 416 | (請求範圍不符合要求) 如果頁面無法提供請求的範圍,則伺服器會返回此狀態程式碼。 |
| 417 | (未滿足期望值) 伺服器未滿足」期望」請求檔頭欄位的要求。 |
| 418 | (彩蛋)本操作碼是在1998年作爲IETF的傳統愚人節笑話, 在RFC 2324超文字咖啡壺控制協定’中定義的,並不需要在真實的HTTP伺服器中定義。當一個控製茶壺的HTCPCP收到BREW或POST指令要求其煮咖啡時應當回傳此錯誤。這個HTTP狀態碼在某些網站(包括Google.com)與專案(如Node.js、ASP.NET和Go語言)中用作彩蛋 |
| 420 | (特定限速)Twitter Search與Trends API在用戶端被限速的情況下返回。 |
| 421 | (無法響應)該請求針對的是無法產生響應的伺服器(例如因爲連線重用)。 |
| 422 | (語意錯誤)請求格式正確,但是由於含有語意錯誤,無法響應 |
| 423 | (鎖定)當前資源被鎖定。 |
| 424 | (依賴請求失敗)由於之前的某個請求發生的錯誤,導致當前請求失敗,例如PROPPATCH。 |
| 425 | (無序連線)在WebDAV Advanced Collections Protocol中定義,但Web Distributed Authoring and Versioning (WebDAV) Ordered Collections Protocol中並不存在 |
| 426 | (請求升級)用戶端應當切換到TLS/1.0,並在HTTP/1.1 Upgrade header中給出。 |
| 428 | (先決條件缺失)原伺服器要求該請求滿足一定條件。這是爲了防止「‘未更新’問題,即用戶端讀取(GET)一個資源的狀態,更改它,並將它寫(PUT)回伺服器,但這期間第三方已經在伺服器上更改了該資源的狀態,因此導致了衝突。」 |
| 429 | (請求數量過多)使用者在給定的時間內發送了太多的請求。旨在用於網路限速。 |
| 431 | (請求頭某一個或者多個欄位過大)伺服器不願處理請求,因爲一個或多個頭欄位過大。 |
| 444 | (無響應)Nginx上HTTP伺服器擴充套件。伺服器不向用戶端返回任何資訊,並關閉連線(有助於阻止惡意軟體)。 |
| 450 | (被Windows家長控制系統阻止)這是一個由Windows家庭控制(Microsoft)HTTP阻止的450狀態程式碼的範例,用於資訊和測試。 |
| 451 | (由於法律原因無法使用)主條目:HTTP 451 該存取因法律的要求而被拒絕,由IETF在2015覈準後新增加。 |
| 494 | (請求頭過大)在錯誤程式碼431提出之前Nginx上使用的擴充套件HTTP程式碼。 |
| 500 | (伺服器內部錯誤) 伺服器遇到錯誤,無法完成請求。 |
| 501 | (尚未實施) 伺服器不具備完成請求的功能。 例如,伺服器無法識別請求方法時可能會返回此程式碼。 |
| 502 | (錯誤閘道器) 伺服器作爲閘道器或代理,從上遊伺服器收到無效響應。 |
| 503 | (服務不可用) 伺服器目前無法使用(由於超載或停機維護)。 通常,這只是暫時狀態。 |
| 504 | (閘道器超時) 伺服器作爲閘道器或代理,但是沒有及時從上遊伺服器收到請求。 |
| 505 | (HTTP 版本不受支援) 伺服器不支援請求中所用的 HTTP 協定版本。 |
| 506 | (代表伺服器存在內部設定錯誤)由《透明內容協商協定》(RFC 2295)擴充套件,代表伺服器存在內部設定錯誤,[64]被請求的協商變元資源被設定爲在透明內容協商中使用自己,因此在一個協商處理中不是一個合適的重點。 |
| 507 | (儲存空間不足)伺服器無法儲存完成請求所必須的內容。這個狀況被認爲是臨時的。 |
| 508 | (死回圈)伺服器在處理請求時陷入死回圈。 (可代替 208狀態碼) |
| 510 | (獲取資源所需要的策略並沒有沒滿足)獲取資源所需要的策略並沒有被滿足。 |
| 511 | (要求網路認證)用戶端需要進行身份驗證才能 纔能獲得網路存取許可權,旨在限制使用者羣存取特定網路。(例如連線WiFi熱點時的強制網路門戶) |
返回內容
Requests 會自動解碼來自伺服器的內容。大多數 unicode 字元集都能被無縫地解碼。
請求發出後,Requests 會基於 HTTP 頭部對響應的編碼作出有根據的推測。當你存取 r.text 之時,Requests 會使用其推測的文字編碼。你可以找出 Requests 使用了什麼編碼,並且能夠使用 r.encoding 屬性來改變它:
>>> r.encoding
'utf-8'
>>> r.encoding = 'ISO-8859-1'
二進制響應內容
可以用於下載圖片
r.content()
####如果建立圖片
from PIL import Image
from io import BytesIO
i = Image.open(BytesIO(r.content))
JSON響應內容
用於得到json字元
Requests 中也有一個內建的 JSON 解碼器,助你處理 JSON 數據:
r.json()
原始響應內容
r.raw()
r.raw.read(10)###讀取值
###如果要下載檔案,請設定stream=true,並且使用get方法
r = requests.get('https://api.github.com/events', stream=True)
####下載
with open("檔案儲存位置", "wb") as f:
for chunk in r.iter_content(1024000):
#print (chunk)
if chunk:
f.write(chunk)
Pandas
Pandas 是基於 BSD 許可的開源支援庫,爲 Python 提供了高效能、易使用的數據結構與數據分析工具。
Pandas中文文件
DataFrame
1、DataFrame是一種數據框結構,相當於是一個矩陣形式,單元格可以存放數值、字串等,這和excel表很像;
2、DataFrame是有 行(index)和 列(columns)可以設定的;
from pandas import DataFrame
建立
####方式一
df=pd.DataFrame()
df.columns=[u'col1',u'col2',u'col3']
### 方式二,list物件
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d)
### 方式三,字典物件
d=['a','b','c']
df=pd.DataFrame(data=[d],columns=(['col1','col2','col3']))
修改
####修改列名
df=df.rename(columns={'原列名':'新列名'})
###重置索引
df=df.reindex(axis='index')
###追加列,並設定預設值
df=df.assign(l="value")
刪除
df=df.drop("列名")
df=df.drop([列的索引值])
篩選
####排除列1爲空的情況
df=df[~df[u'列1'].isnull()]
####得到日期2020-08-12的銷售收入與銷售數量
sale,count = df.loc[(df.tdate=='2020-08-12'),(u'銷售收入',u'銷售數量')].sum()
####選取門店編號在1001,1002中的門店編號,門店名稱列
df[['門店編號','門店名稱']][df['門店編號'].isin(['1001','1002'])]
#####篩選期初數量大於0或者當前數量大於0的數據
df[(df['期初數量']>0) | df['當前數量']>0]
合併,連線
#######複製,合併,追加
frame_body=[]
order_details=[]
order_detail_body=df()
frame_body.append(order_details.copy())###追加
order_detail_body = pd.concat(frame_body)####合併
######左、右、內、全連線,類似於SQL中的LEFT JOIN、RIGHT JOIN、OUTER JOIN、INNER JOIN
pd.merge(dfA, dfB,how='left', on=['dfA與dfB相同的列'])
pd.merge(dfA, dfB,how='left', left_on=['dfA列'],right_on=['dfB列'])
pd.merge(dfA, dfB,how='right', on=['dfA與dfB相同的列'])
pd.merge(dfA, dfB,how='outer', on=['dfA與dfB相同的列'])
pd.merge(dfA, dfB,how='inner', on=['dfA與dfB相同的列'])
pd.merge方法
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=(’_x’, ‘_y’), copy=True, indicator=False,
validate=None)
參數如下:
| 參數 | 值 |
|---|---|
| left | 拼接的左側DataFrame物件 |
| right | 拼接的右側DataFrame物件 |
| on | 要加入的列或索引級別名稱。 必須在左側和右側DataFrame物件中找到。 如果未傳遞且left_index和right_index爲False,則DataFrame中的列的交集將被推斷爲連線鍵。 |
| left_on | 左側DataFrame中的列或索引級別用作鍵。 可以是列名,索引級名稱,也可以是長度等於DataFrame長度的陣列。 |
| right_on | 左側DataFrame中的列或索引級別用作鍵。 可以是列名,索引級名稱,也可以是長度等於DataFrame長度的陣列。 |
| left_index | 如果爲True,則使用左側DataFrame中的索引(行標籤)作爲其連線鍵。 對於具有MultiIndex(分層)的DataFrame,級別數必須與右側DataFrame中的連線鍵數相匹配。 |
| right_index | 與left_index功能相似。 |
| how | One of ‘left’, ‘right’, ‘outer’, ‘inner’. 預設inner。inner是取交集,outer取並集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的話,left中出現的A會和right中出現的買一個A進行匹配拼接,如果沒有是B,在right中沒有匹配到,則會丟失。'outer’取並集,出現的A會進行一一匹配,沒有同時出現的會將缺失的部分新增缺失值。 |
| sort | 按字典順序通過連線鍵對結果DataFrame進行排序。 預設爲True,設定爲False將在很多情況下顯着提高效能。 |
| suffixes | 用於重疊列的字串後綴元組。 預設爲(‘x’,’ y’)。 |
| copy | 始終從傳遞的DataFrame物件複製數據(預設爲True),即使不需要重建索引也是如此。 |
| indicator | 將一列新增到名爲_merge的輸出DataFrame,其中包含有關每行源的資訊。 _merge是分類型別,並且對於其合併鍵僅出現在「左」DataFrame中的觀察值,取得值爲left_only,對於其合併鍵僅出現在「右」DataFrame中的觀察值爲right_only,並且如果在兩者中都找到觀察點的合併鍵,則爲left_only。 |
JSON
####將JSON字串轉換爲pandas物件
pandas.read_json()
pandas.json_normalize()####將半結構化JSON數據規範化爲一個平面表。
data = [{'id': 1, 'name': {'first': 'Coleen', 'last': 'Volk'}},
{'name': {'given': 'Mose', 'family': 'Regner'}},
{'id': 2, 'name': 'Faye Raker'}]
pandas.json_normalize(data)
# id name name.family name.first name.given name.last
#0 1.0 NaN NaN Coleen NaN Volk
#1 NaN NaN Regner NaN Mose NaN
#2 2.0 Faye Raker NaN NaN NaN NaN
json.loads()與json.dumps()
import json
json.loads()###將json格式的數據轉換爲字典
json.dumps()###將字典轉換爲json格式的數據
pandas.read
pandas.read_sql()
從數據庫查詢數據並返回DataFrame型別值
與read_sql_table和read_sql_query相同
pandas.read_sql(
sql,
con,
index_col=None,
coerce_float=True,
params=None,
parse_dates=None,
columns=None,
chunksize=None)
| 參數 | 描述 |
|---|---|
| sql | 數據查詢sql語句,例如:select * from test |
| con | 數據庫連線物件 |
| index_col | 索引列 |
| coerce_float | 將數位形式的字串直接以float型讀入 |
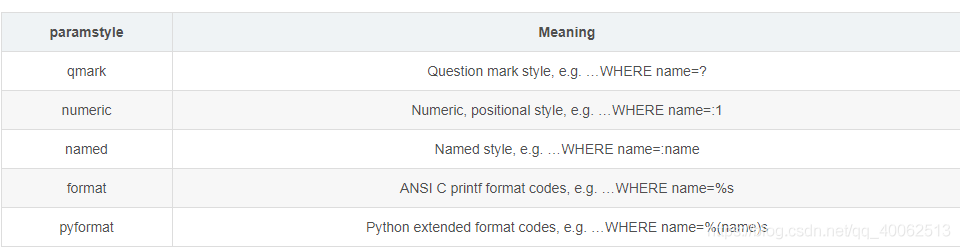
| params | 使用list 或者 dict或者tuple傳遞值,傳遞給執行方法的參數列表。用於傳遞參數的語法取決於數據庫驅動程式。檢視數據庫驅動程式文件,以瞭解PEP 249的paramstyle中所描述的五種語法樣式中的哪一種受支援。例如。對於psycopg2,使用%(name)s,因此請使用params = {‘name’:‘value’}。 |
| parse_dates | 某一列日期型字串轉換爲datetime型數據,與pd.to_datetime函數功能類似。可以直接提供需要轉換的列名以預設的日期形式轉換,也可以用字典的格式提供列名和轉換的日期格式,比如{column_name: format string}(format string:"%Y:%m:%H:%M:%S") |
| columns | 選取返回的列 |
| chunksize | 如果提供了一個整數值,那麼就會返回一個generator,每次輸出的行數就是提供的值的大小。 |
PEP 249的paramstyle:
建立數據庫連線
import sqlalchemy
import pyodbc
from sqlalchemy.types import *
from sqlalchemy import create_engine
engine=sqlalchemy.create_engine(
'數據庫型別+數據庫驅動名稱://使用者名稱:口令@機器地址:埠號/數據庫名',###"mssql+pyodbc://使用者名稱:密碼@數據源名稱"此語句爲連線SQLServer數據庫
echo=True, # 設定爲True,則輸出sql語句
pool_size=5, # 數據庫連線池初始化的容量
max_overflow=10, # 連線池最大溢位容量,該容量+初始容量=最大容量。超出會堵塞等待,等待時間爲timeout參數值預設30
pool_recycle=7200 # 重連週期
)
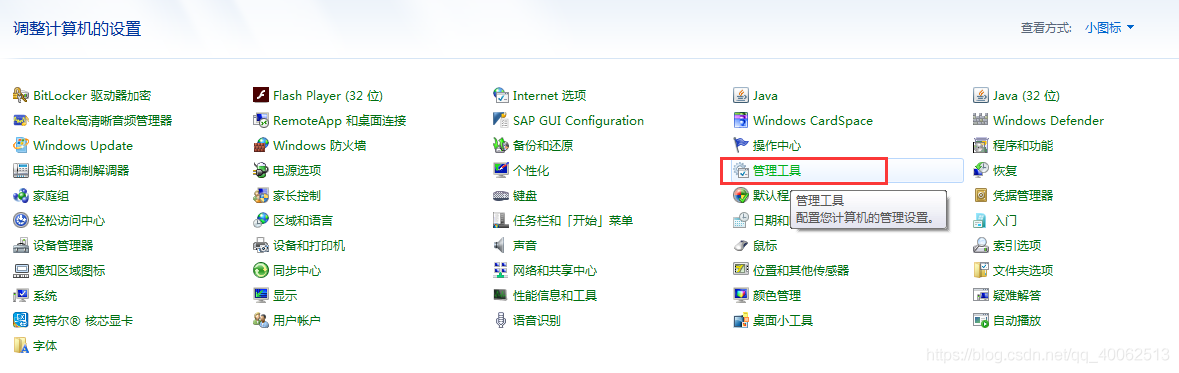
設定數據源
1.執行–》control.exe–》管理工具
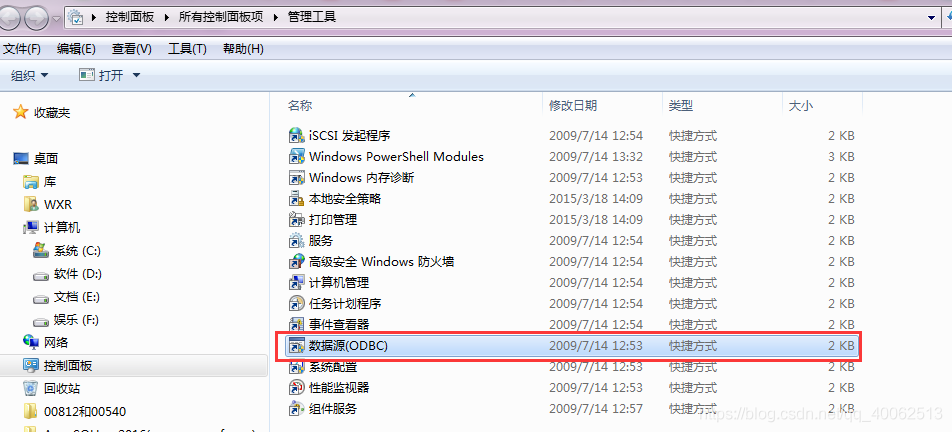
2.選擇數據源—》系統DSN–>新增–>SQL Server
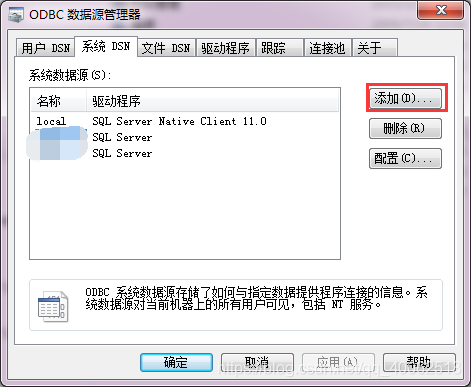
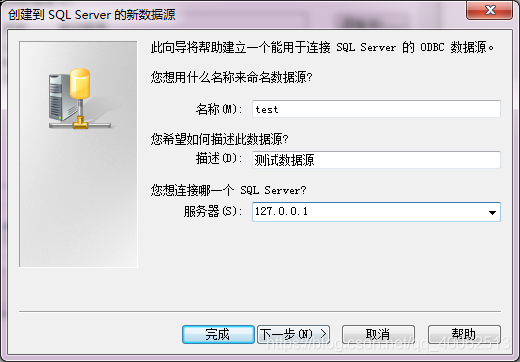
3.輸入名稱,描述,伺服器地址
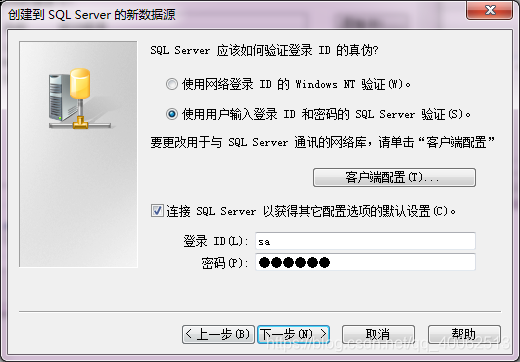
4.輸入數據庫登錄名和密碼
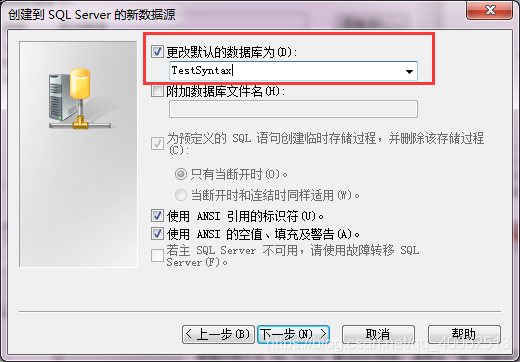
5.更改預設的數據庫
6.完成
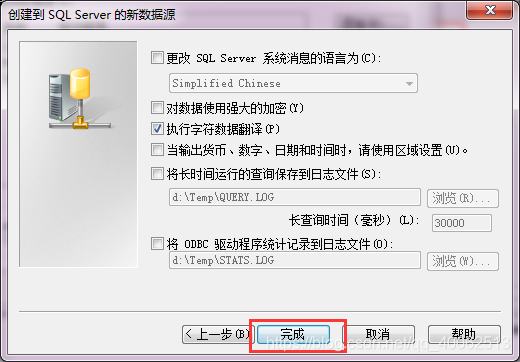
7.測試連線
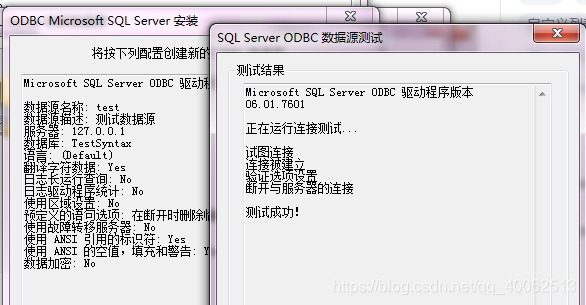
8.設定成功!!!
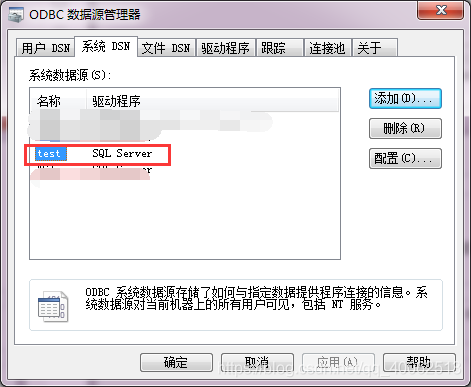
更新中…