Redis學習筆記
NoSQL = Not Only SQL 「不僅僅是SQL」 非關係型的數據庫
大數據時代的3V :海量Volume 多樣Variety 實時Velocity
網際網路需求的3高 :高併發 高可擴 高效能
四種類型的數據庫
傳統ACID :A(Atomicity) 原子性 C(Consistency) 一致性 I(Isolation)獨立性 D(Durability) 永續性
分佈式數據庫中的CAP特性 :C(Consistency) 強一致性 A(Availability) 可用性 P(Partition tolerance) 分割區容錯性
CAP理論在分佈式儲存系統中,最多隻能實現上面的兩點 . 由於當前的網路硬體肯定會出現延遲丟包等問題, 所以 分割區容忍性是必須要實現的
CA 傳統Oracle數據庫
AP 大多數網站架構的選擇
CP Redis 、 Mongodb
注意:分佈式架構的時候必須做出取捨。一致性和可用性之間取一個平衡。多餘大多數web應用,其實並不需要強一致性。因此犧牲C換取P,這是目前分佈式數據庫產品的方向
Redis : REmote DIctionary Server(遠端字典伺服器)
Redis 特點 :
1 . Redis支援數據的持久化, 可以將記憶體中的數據保持在磁碟中, 重新啓動的時候可以再次載入進行使用
2 . Redis不僅僅支援簡單的key-value型別的數據 , 同事還提供list, set, zset, hash等數據結構的儲存
3 . Redis支援數據的備份, 即master-slave模式的數據備份
Redis Linux版安裝
- 下載獲得 redis-版本號.tar.gz , 將它放在linux目錄 /opt 下
- /opt 目錄下, 解壓命令 : tar -zxvf redis-版本號.tar.gz
- 解壓完成出現對應的 redis-版本號 資料夾
- 進入目錄 : cd redis-版本號
- 在 redis-版本號 目錄下執行 make 命令
- 如果 make 完成後繼續執行 make install
- 檢視預設安裝目錄 : usr/local/bin( 命令 : ls -l )
Redis-benchmark : 效能測試工具 , 可以在自己本子執行, 看看自己本子效能如何 ( 服務啓動後執行 )
Redis-check-aof : 修復有問題的AOF檔案, rdb和aof 是持久化
Redis-check-dump : 修復有問題的dump.rdb檔案
Redis-cli :用戶端 , 操作入口
Redis-sentinel : redis叢集使用
Redis-server : Redis伺服器啓動命令 - 啓動
修改redis.conf檔案將裏面的daemonize no 改成 yes, 讓服務在後臺啓動
將預設的redis.conf拷貝到自己定義好的一個路徑下, 比如 /myconf
啓動 : ( 命令: redis-server /目錄/redis.conf --------兩個命令------- redis-cli )
連通測試 : (命令: ping 獲得 PONG即爲成功 )
/usr/local/bin 目錄下執行redis-server , 執行拷貝出存放了自定義conf檔案目錄下的redis.conf - 關閉
單範例關閉: ( 命令: redis-cli shutdown )
多範例關閉, 指定埠關閉 ( 命令: redis-cli -p 6379 shutdown )
Redis啓動後雜項基礎知識講解
單進程
單進程模型來處理用戶端的請求. 對讀寫等事件的響應是通過對epoll函數的包裝來做到的. Redis的實際處理速度完全依靠主進程的執行效率
Epoll是Linux內核爲處理大批次檔案描述符而作了改進的epoll, 是Linux下多路複用IO介面select/poll的增強版本, 它能顯著提高程式在大量併發連線中只有少量活躍的情況下的系統CPU利用率
預設16個數據庫, 類似陣列下標從零開始, 初始預設使用零號庫
( 命令: SELECT 指定連線的數據庫id)
Dbsize 檢視當前數據庫的key的數量
Flushdb : 清空當前庫
Flushall : 通殺所有庫
統一密碼管理, 16個庫都是同樣密碼, 要麼都OK要麼一個也連線不上
Redis 索引都是從零開始
預設埠是6379
Redis數據型別
五大數據型別**
String (字串)
string 是redis最基本的型別, 你可以理解成與Memcached一模一樣的型別, 一個key對應一個value
string型別是二進制安全的. 意思是redis的string可以包含任何數據. 比如jpg圖片或者序列化的物件
string型別是Redis最基本的數據型別, 一個redis中字串value最多可以是512M
Hash (雜湊, 類似java裡的Map)
Redis hash 是一個鍵值對集合。
Redis hash是一個string型別的field和value的對映表,hash特別適合用於儲存物件。
類似Java裏面的Map<String,Object>
List (列表)
Redis 列表是簡單的字串列表,按照插入順序排序。你可以新增一個元素導列表的頭部(左邊)或者尾部(右邊)。
它的底層實際是個鏈表
Set (集合)
Redis的Set是string型別的無序集合。它是通過HashTable實現實現的
Zset (sorted set : 有序集合)
Redis zset 和 set 一樣也是string型別元素的集合,且不允許重複的成員。
不同的是每個元素都會關聯一個double型別的分數。
redis正是通過分數來爲集閤中的成員進行從小到大的排序。
zset的成員是唯一的,但分數(score)卻可以重複。
Http://redisdoc.com 獲取redis常見數據型別操作命令
鍵(key) 常用指令
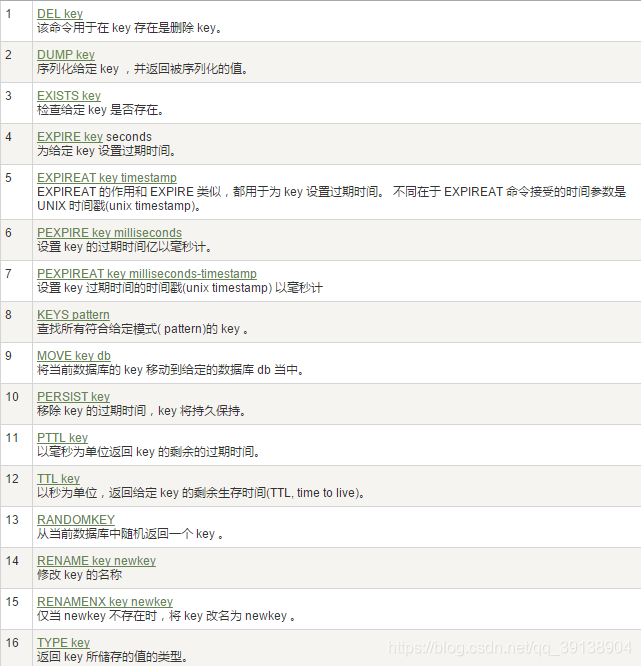
案列:
- keys *
- exists key的名字 ----> 判斷某個key是否存在
- move key db ----> 當前庫就沒有了,被移除了
- expire key 秒鐘 ----> 爲給定的key設定過期時間
- ttl key ----> 檢視還有多少秒過期, -1 表示永不過期, -2 表示已過期
- type key ----> 檢視你的key是什麼型別
字串(String)
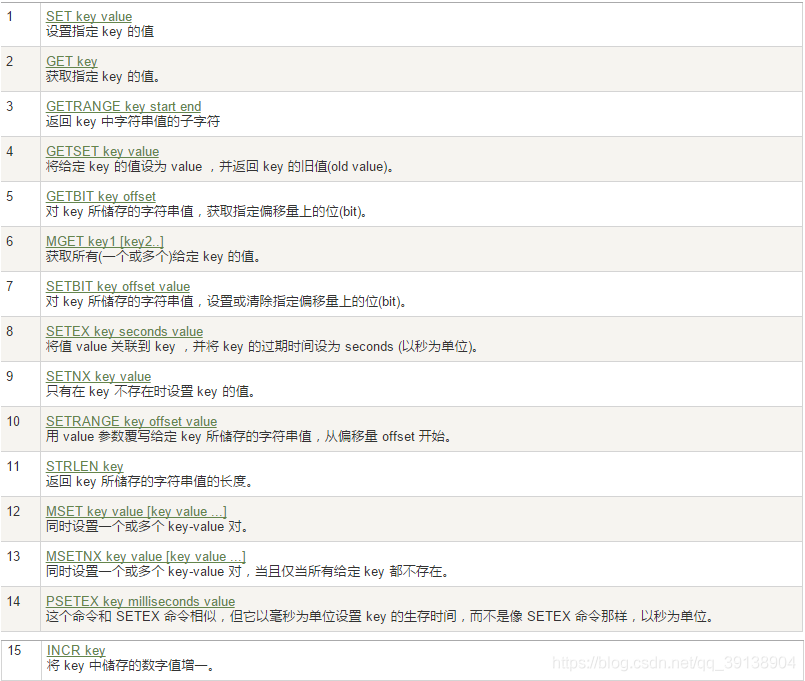

案例 :
- set/get/del/append/strlen
- Incr/decr/incrby/decrby ---- 一定要是數位才能 纔能進行加減
- getrange/setrange
getrange : 獲取指定區間範圍內的值, 類似 between…and 的關係 從 0到-1 表示全部
例 : set key1 abcd1234
GETRANGE key1 0 -1 ------> 「abcd1234」
GETRANGE key1 0 2 -------> 「abc」
setrange : 設定指定區間範圍內的值, 格式是setrange
例 : SETRANGE key1 1 xxx -----> 8
get key1 ------> axxx1234 - setex(set with expire)鍵秒值/setnx(set if not exist)
setex : 設定帶過期時間的key , 動態設定
setex 鍵 秒值 真實值 -----> setex k1 15 hello ---- 15秒後過期, 過期後即獲取不到
setnx : 只有在key不存在時設定key的值 ----> 如果存在key值,則設定不成功 - mset/mget/msetnx
mset : 同時設定一個或多個key-value -----> mset key1 aa key2 bb key3 cc
mget : 獲取所有(一個或多個)給定key的值 ----> mget key1 key2 key3
msetnx : 同時設定一個或多個 key-value , 當且僅當所有給定 key 都不存在 -----> msetnx k1 aa k2 bb ---- k1 , k2 都不存在,才能 纔能設定成功 - getset ( 先get再set )
將給定的key的值設爲value , 並返回key的舊值(old value) —> getset k1 bb ---- 返回 aa
列表( List )
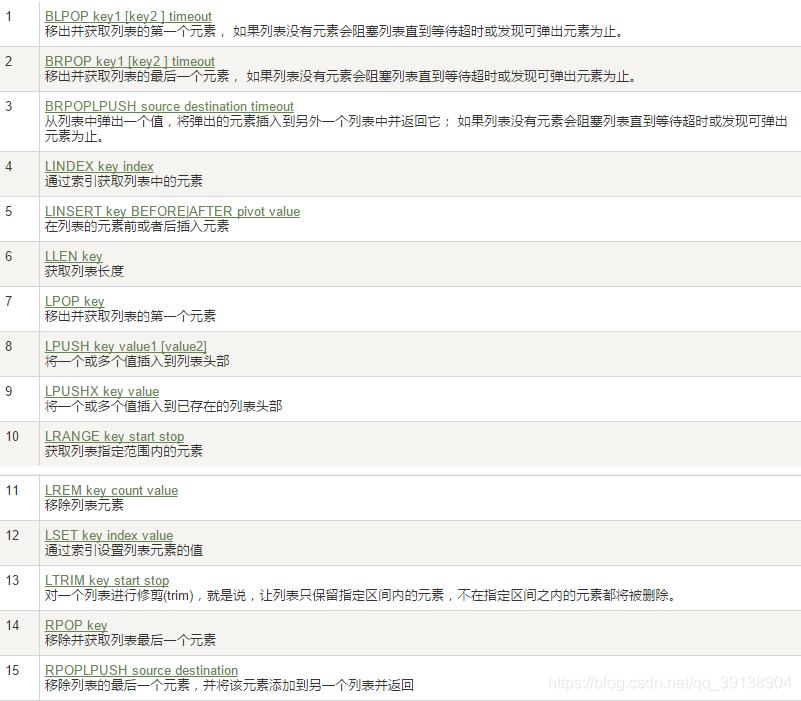

案例 :
- lpush/rpush/lrange
- lpop/rpop
lpop list1 ----> 移除並獲取列表的第一個元素,
rpop list1 ----> 移除並獲取列表最後一個元素 - lindex , 按照索引下標獲得元素(從上到下)
通過索引獲取列表中的元素
lindex key index ----> lindex list1 3 — 獲取list1索引爲3的值 - llen
- lrem key 刪除N個value
從left往right刪除N個值等於value的元素, 返回的值爲實際刪除的數量
lrem list1 0 值 ----> 表示刪除全部給定的值. 零個就是全部值
LREM list1 2 v1 -----> 從left往right刪除2個值等於v1的元素, 返回的值爲實際刪除的數量 - ltrim key 開始index 結束index , 擷取指定範圍的值後再賦值給key
ltrim : 擷取指定索引區間的元素, 格式是ltrim list的key 起始索引 結束索引
LRANGE list1 0 -1 ----> 9 8 7 6 5 4 3 2 1 0
LIRIM list1 3 5 ----> ok
LRANGE list1 0 -1 -----> 6 5 4\ - rpoplpush 源列表 目的列表
移除列表的最後一個元素,並將該元素新增到另一個列表並返回
RPOPLPUSH list2 list3 ----> 返回移動的那個元素, 即list2最後一個元素, 新增到list3第一個元素 - lset key index value
lset list3 2 aa ----> OK 將aa value值插入到list3索引爲2的地方 - linsert key before/after 值1 值2 ----> 在list某個已有值的前後再新增具體值
LINSERT list3 before 3 aa ----> 在 value爲3 的值前面新增 aa , 返回list長度值
總結:
它是一個字串鏈表,left、right都可以插入新增;
如果鍵不存在,建立新的鏈表;
如果鍵已存在,新增內容;
如果值全移除,對應的鍵也就消失了。
鏈表的操作無論是頭和尾效率都極高,但假如是對中間元素進行操作,效率就很慘淡了。
集合(Set)

案例:
- sadd/smembers/sismember
sadd set1 v1 ----> 返回1 , 如果已存在v1,則返回0
sadd set1 v2 v3 v4 v5 ----> 返回4
smembers set1 ----> v2 v4 v3 v1 v5 , 返回值是無序的 - scard , 獲取集合裏面的元素個數
scard set1 ----> 返回 5 , 集合裡有5個元素 - srem key value 刪除集閤中元素
SREM set1 v1 ----> 返回刪除元素個數 - srandmember key 某個整數(隨機出幾個數)
從set集合裏面隨機取出2個
如果超過最大數量就全部取出
如果寫的值是負數, 比如 -3 , 表示需要取出3個, 但是可能會有重複值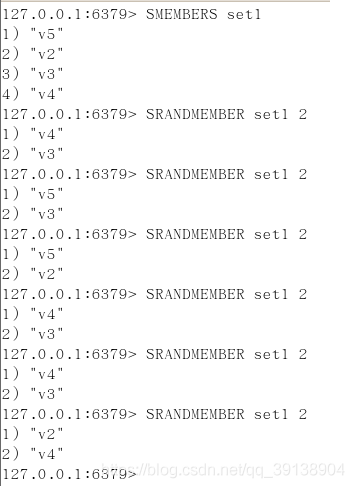
- spop key 隨機出棧
- smove key1 key2 在key1裡某個值 ---- 作用 : 將key1裡的某個值賦給key2
- 數學集合類
差集 : sdiff ----- 在第一個set裏面而不在後面任何一個set裏面的項
交集 : sinter
並集 : sunion
雜湊(Hash) — KV模式不變 , 但V是一個鍵值對

案例 :
- hset/hget/hmset/hmget/hgetall/hdel
hset hash1 k4 v4
hget hash1 k4 --------> v4
hmset hash2 id 11 name lisi age 24 ----> ok
hmget hash2 id name age ----> 11 lisi 24
hgetall hash1 ----> k1 v1 k2 v2 k3 v3 k4 v4
hdel hash1 k1 k2 ----> 2 , 刪除了 k1 k2的鍵值 - hlen
- hexists key key 在key裏面的某個值的key
- hkeys/hvals
hkeys hash2 -----> id name age
hvals hash2 -----> 11 lisi 24 - hincrby/hincrbyfloat
hset hash2 k1 77
hget hash2 k1 ------> 77
hincrby hash2 k1 3 -----> 80
hincrbyfloat hash2 k1 2.7 ------> 82.7 - hsetnx value中的鍵不存在賦值, value中的鍵存在了無效
hsetnx hash3 k1 44 -----> 1
hsetnx hash3 k1 45 -----> 0
有序集合Zset(sorted set)
注 : 在set基礎上, 加一個score值, 之前set是k1 v1 v2 v3, 現在zset是k1 score1 v1 score2 v2
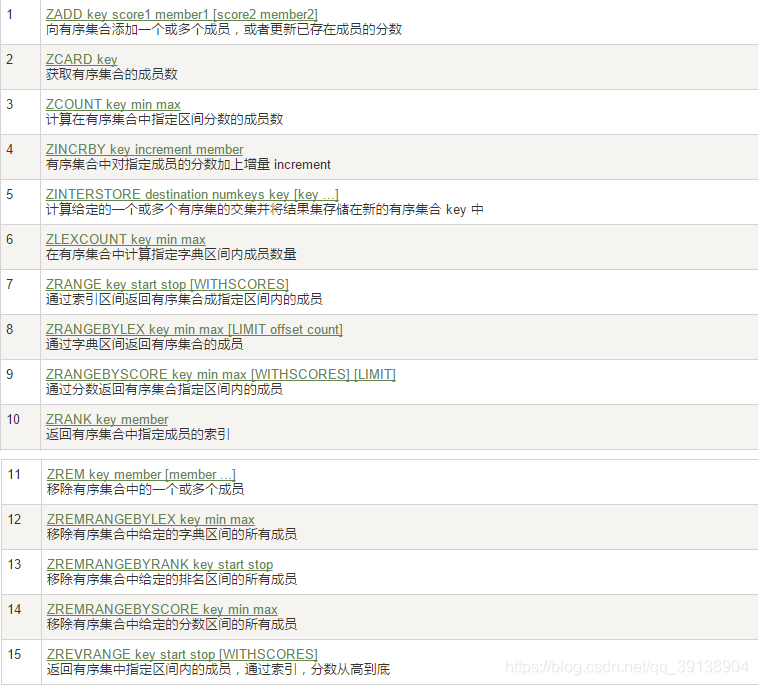

案例:
- zadd/zrange
zadd zset1 60 v1 70 v2 80 v3 90 v4 ----> 4 — 如果存在了,則返回0
zrange zset1 0 -1 -----> v1 v2 v3 v4
zrange zset1 0 -1 withscores -----> v1 60 v2 70 v3 80 v4 90 - zrangebyscore key 開始score 結束score ----- withscores | ( : 表示不包括 | limit : 返回限制
zrangebyscore zset1 60 90 -----> v1 v2 v3 v4
zrangebyscore zset1 60 90 withscores -----> v1 60 v2 70 v3 80 v4 90
zrangebyscore zset1 (60 90 withscores -----> v2 70 v3 80 v4 90
zrangebyscore zset1 60 (90 withscores -----> v1 60 v2 70 v3 80
zrangebyscore zset1 60 +inf withscores -----> v1 60 v2 70 v3 80 v4 90
zrangebyscore zset1 (60 +inf withscores -----> v1 60 v2 70 v3 80 v4 90
zrangebyscore zset1 60 +inf withscores limit 0 2 -----> v1 60 v2 70
zrangebyscore zset1 60 +inf withscores limit 1 3 -----> v2 70 v3 80 v4 90 - zrem key 某score下對應的value值, 作用是刪除元素
zrem key score某個對應的值, 可以是多個值
zrem zset2 v2 —> 刪除v2 和 對應score - zcard/zcount key score區間/zrank key values值, 作用是獲得下標值/zscore key 對應值, 獲得分數
zcard : 獲取集閤中元素個數
zcount : 獲取分數區間內元素個數
zcount key : 開始分數區間 結束分數區間
zrank : 獲取value在zset中的下標位置
zscore : 按照值獲得對應的分數 - zrevrank key values值, 作用是逆序獲得下標值
- zrevrange
- zrevrangebyscore key 結束score 開始score
解析組態檔 redis.conf
地址 : /目錄/redis-版本號下面 下麪, 解壓包後的資料夾下
Units單位 : 設定大小單位, 開頭定義了一些基本的度量單位, 只支援bytes, 不支援bit , 對大小寫不敏感
INCLUEDS : 和我們的strusts2組態檔類似, 可以通過includes包含, redis.conf可以作爲總閘, 包含其他
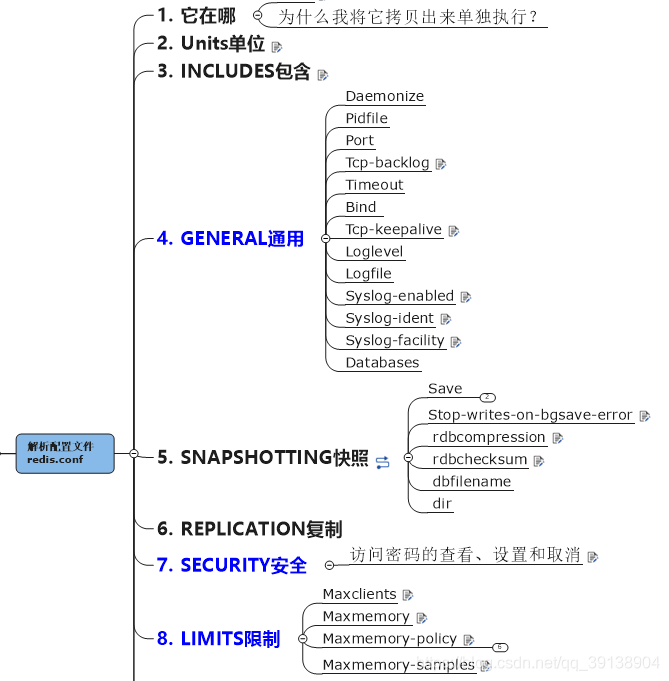
參數說明
redis.conf 設定項說明如下:
-
Redis預設不是以守護行程的方式執行,可以通過該設定項修改,使用yes啓用守護行程
daemonize no -
當Redis以守護行程方式執行時,Redis預設會把pid寫入/var/run/redis.pid檔案,可以通過pidfile指定 — pidfile /var/run/redis.pid
-
指定Redis監聽埠,預設埠爲6379,作者在自己的一篇博文中解釋了爲什麼選用6379作爲預設埠,因爲6379在手機按鍵上MERZ對應的號碼,而MERZ取自意大利歌女Alessia Merz的名字 — port 6379
-
系結的主機地址 — bind 127.0.0.1
5.當 用戶端閒置多長時間後關閉連線,如果指定爲0,表示關閉該功能 — timeout 300 -
指定日誌記錄級別,Redis總共支援四個級別:debug、verbose、notice、warning,預設爲verbose — loglevel verbose
-
日誌記錄方式,預設爲標準輸出,如果設定Redis爲守護行程方式執行,而這裏又設定爲日誌記錄方式爲標準輸出,則日誌將會發送給/dev/null — logfile stdout
-
設定數據庫的數量,預設數據庫爲0,可以使用SELECT 命令在連線上指定數據庫id
databases 16 -
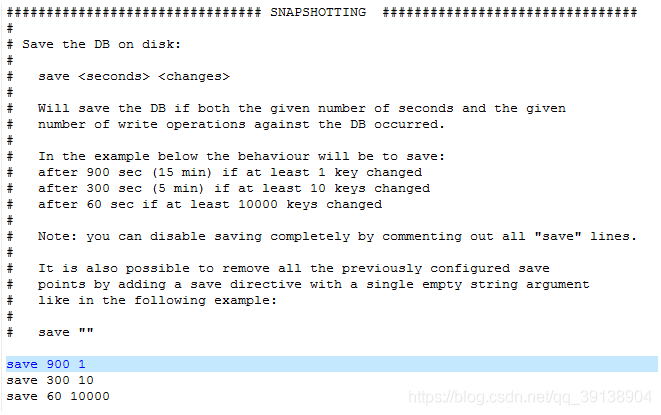
指定在多長時間內,有多少次更新操作,就將數據同步到數據檔案,可以多個條件配合
save
Redis預設組態檔中提供了三個條件:
save 900 1
save 300 10
save 60 10000
分別表示900秒(15分鐘)內有1個更改,300秒(5分鐘)內有10個更改以及60秒內有10000個更改。 -
指定儲存至本地數據庫時是否壓縮數據,預設爲yes,Redis採用LZF壓縮,如果爲了節省CPU時間,可以關閉該選項,但會導致數據庫檔案變的巨大
rdbcompression yes -
指定本地數據庫檔名,預設值爲dump.rdb
dbfilename dump.rdb -
指定本地數據庫存放目錄
dir ./ -
設定當本機爲slav服務時,設定master服務的IP地址及埠,在Redis啓動時,它會自動從master進行數據同步
slaveof -
當master服務設定了密碼保護時,slav服務連線master的密碼
masterauth -
設定Redis連線密碼,如果設定了連線密碼,用戶端在連線Redis時需要通過AUTH 命令提供密碼,預設關閉
requirepass foobared -
設定同一時間最大用戶端連線數,預設無限制,Redis可以同時開啓的用戶端連線數爲Redis進程可以開啓的最大檔案描述符數,如果設定 maxclients 0,表示不作限制。當用戶端連線數到達限制時,Redis會關閉新的連線並向用戶端返回max number of clients reached錯誤資訊
maxclients 128 -
指定Redis最大記憶體限制,Redis在啓動時會把數據載入到記憶體中,達到最大記憶體後,Redis會先嚐試清除已到期或即將到期的Key,當此方法處理 後,仍然到達最大記憶體設定,將無法再進行寫入操作,但仍然可以進行讀取操作。Redis新的vm機制 機製,會把Key存放記憶體,Value會存放在swap區
maxmemory -
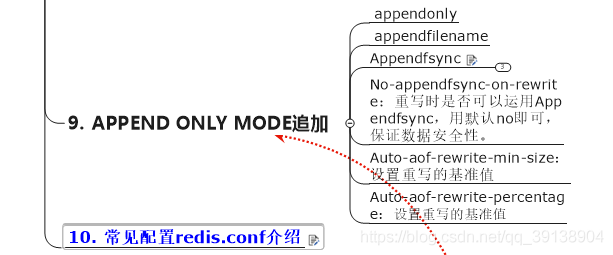
指定是否在每次更新操作後進行日誌記錄,Redis在預設情況下是非同步的把數據寫入磁碟,如果不開啓,可能會在斷電時導致一段時間內的數據丟失。因爲 redis本身同步數據檔案是按上面save條件來同步的,所以有的數據會在一段時間內只存在於記憶體中。預設爲no
appendonly no -
指定更新日誌檔名,預設爲appendonly.aof
appendfilename appendonly.aof -
指定更新日誌條件,共有3個可選值:
no:表示等操作系統進行數據快取同步到磁碟(快)
always:表示每次更新操作後手動呼叫fsync()將數據寫到磁碟(慢,安全)
everysec:表示每秒同步一次(折衷,預設值)
appendfsync everysec -
指定是否啓用虛擬記憶體機制 機製,預設值爲no,簡單的介紹一下,VM機制 機製將數據分頁存放,由Redis將存取量較少的頁即冷數據swap到磁碟上,存取多的頁面由磁碟自動換出到記憶體中(在後面的文章我會仔細分析Redis的VM機制 機製)
vm-enabled no -
虛擬記憶體檔案路徑,預設值爲/tmp/redis.swap,不可多個Redis範例共用
vm-swap-file /tmp/redis.swap -
將所有大於vm-max-memory的數據存入虛擬記憶體,無論vm-max-memory設定多小,所有索引數據都是記憶體儲存的(Redis的索引數據 就是keys),也就是說,當vm-max-memory設定爲0的時候,其實是所有value都存在於磁碟。預設值爲0
vm-max-memory 0 -
Redis swap檔案分成了很多的page,一個物件可以儲存在多個page上面,但一個page上不能被多個物件共用,vm-page-size是要根據儲存的 數據大小來設定的,作者建議如果儲存很多小物件,page大小最好設定爲32或者64bytes;如果儲存很大大物件,則可以使用更大的page,如果不 確定,就使用預設值
vm-page-size 32 -
設定swap檔案中的page數量,由於頁表(一種表示頁面空閒或使用的bitmap)是在放在記憶體中的,,在磁碟上每8個pages將消耗1byte的記憶體。
vm-pages 134217728 -
設定存取swap檔案的執行緒數,最好不要超過機器的核數,如果設定爲0,那麼所有對swap檔案的操作都是序列的,可能會造成比較長時間的延遲。預設值爲4
vm-max-threads 4 -
設定在向用戶端應答時,是否把較小的包合併爲一個包發送,預設爲開啓
glueoutputbuf yes -
指定在超過一定的數量或者最大的元素超過某一臨界值時,採用一種特殊的雜湊演算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512 -
指定是否啓用重置雜湊,預設爲開啓(後面在介紹Redis的雜湊演算法時具體介紹)
activerehashing yes -
指定包含其它的組態檔,可以在同一主機上多個Redis範例之間使用同一份組態檔,而同時各個範例又擁有自己的特定組態檔
include /path/to/local.conf
Redis持久化
RDB 和 AOF
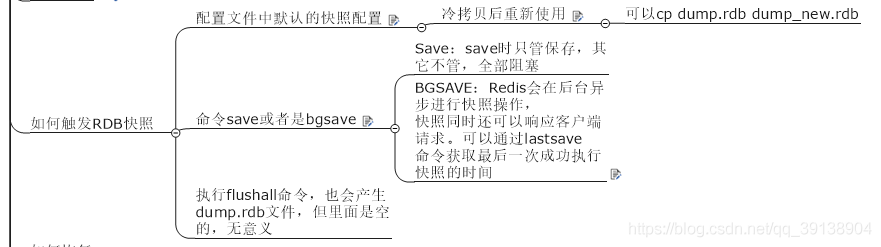
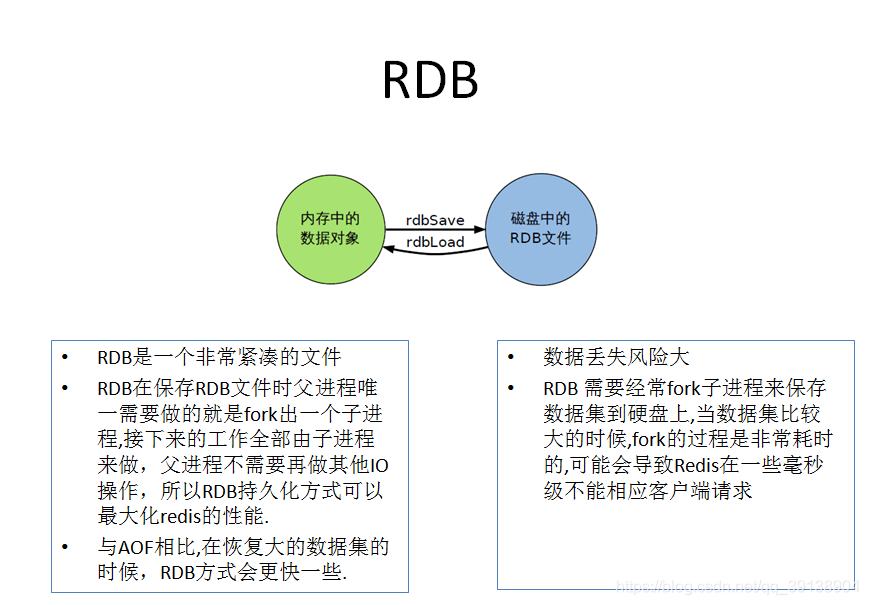
rdb :在指定的時間間隔內將記憶體中的數據集快照寫入磁碟, 也就是行話講的Snapshot快照,它恢復時是將快照檔案直接讀到記憶體裡.
Redis會單獨建立(fork) 一個子進程來進行持久化,會先將數據寫入到一個臨時檔案中,待持久化過程都結束了,再用這個臨時檔案替換上次持久化好的檔案。整個過程中,主進程是不進行任何IO操作的,這就確保了極高的效能. 如果需要進行大規模數據的恢復,且對於數據恢復的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺點是最後一次持久化後的數據可能丟失。
Fork的作用是複製一個與當前進程一樣的進程。新進程的所有數據(變數、環境變數、程式計數器等) 數值都和原進程一-致,但是是一個全新的進程,並作爲原進程的子進程
Rdb 儲存的是 dump.rdb 檔案
設定位置 :

AOF

AOF儲存的檔案是appendonly.aof檔案


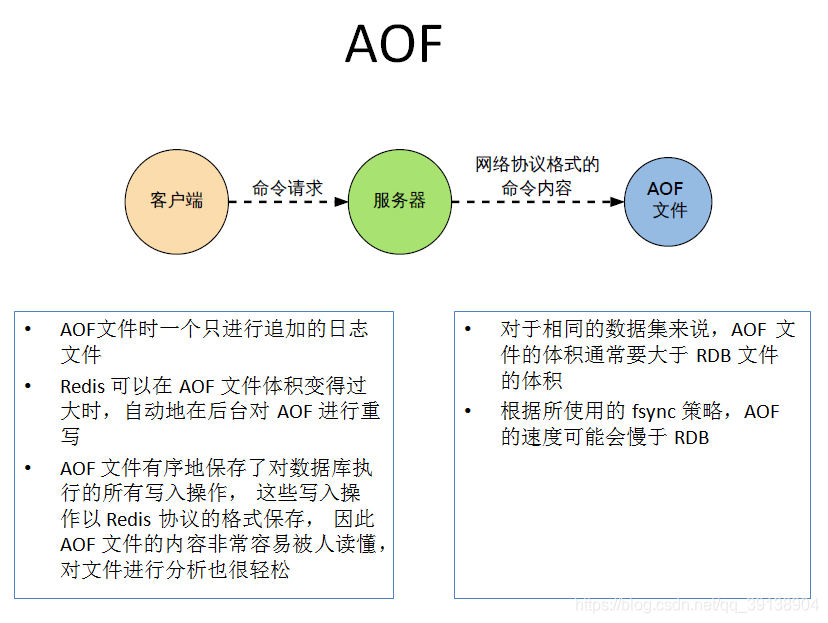
總結

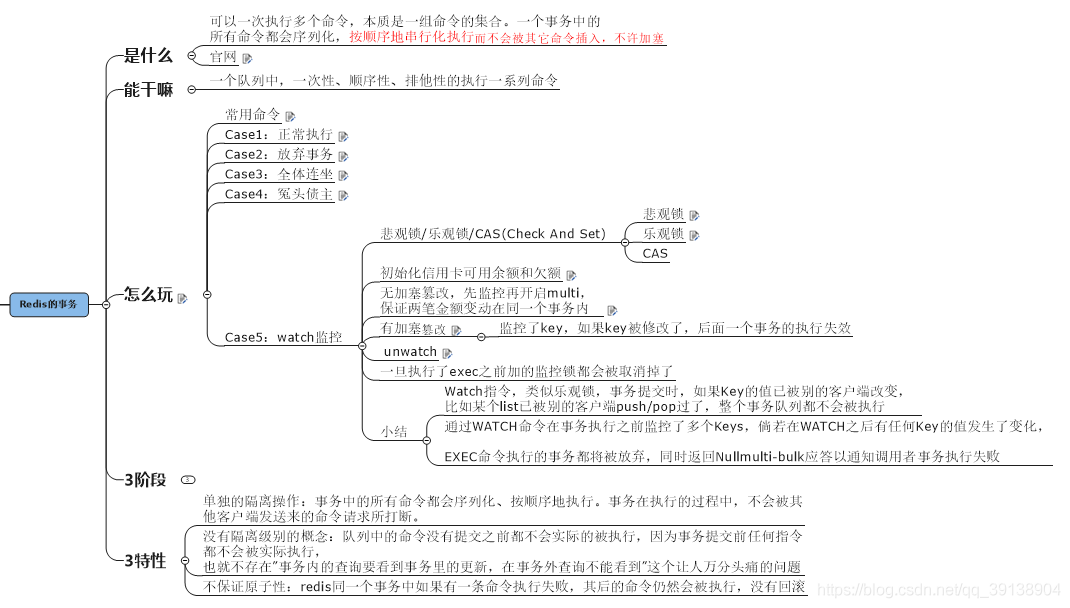
Redis 事務
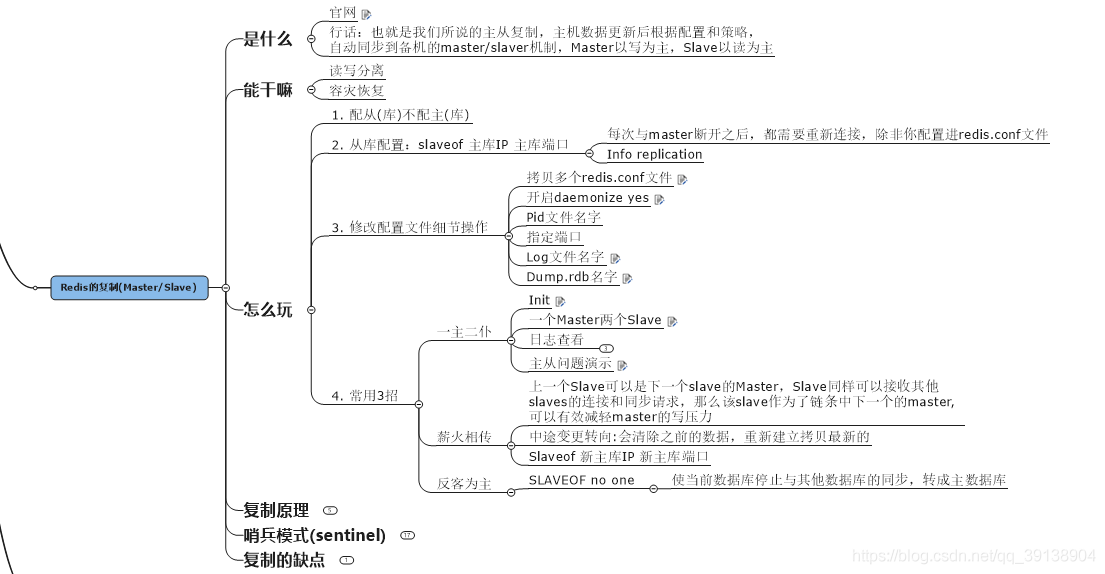
Redis 主從複製
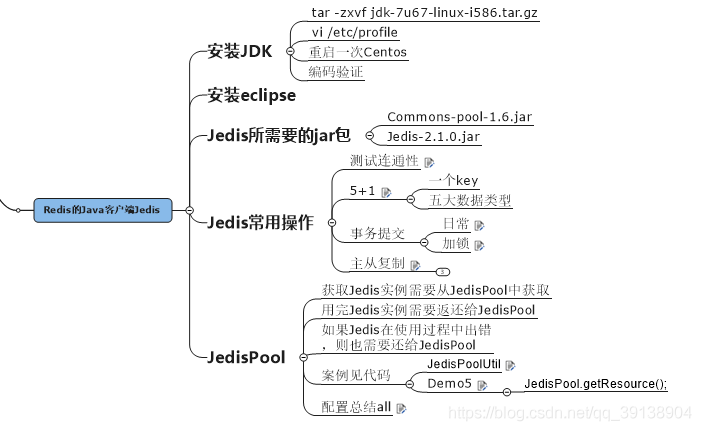
Redis的java用戶端Jedis