史上最全的C++面試寶典(合集)
參考:https://www.runoob.com/cplusplus/cpp-tutorial.html
本教學旨在提取最精煉、實用的C++面試知識點,供讀者快速學習及本人查閱複習所用。
目錄
第一章 C++基本語法
C++ 程式可以定義爲物件的集合,這些物件通過呼叫彼此的方法進行互動。
- 物件 - 物件具有狀態和行爲。例如:一隻狗的狀態 - 顏色、名稱、品種,行爲 - 搖動、叫喚、吃。
- 類 - 類可以定義爲描述物件行爲/狀態的模板,物件是類的範例。
- 方法 - 從基本上說,一個方法表示一種行爲。一個類可以包含多個方法。可以在方法中寫入邏輯、操作數據等動作。
- 即時變數 - 每個物件都有其獨特的即時變數。
1.1 C++程式結構
下面 下麪給出一段基礎的C++程式:
#include <iostream>
using namespace std;
// main() 是程式開始執行的地方
int main()
{
cout << "Hello World" << endl; // 輸出 Hello World
return 0;
}
這段程式主要結構如下:
- C++ 語言定義了一些標頭檔案,這些標頭檔案包含了程式中必需的或有用的資訊。上面這段程式中,包含了標頭檔案 <iostream>
- using namespace std; 告訴編譯器使用 std 名稱空間。
- int main() 是主函數,程式從這裏開始執行。
1.2 名稱空間
- 名稱空間這個概念可作爲附加資訊來區分不同庫中相同名稱的函數、類、變數等。
- 使用了名稱空間即定義了上下文,本質上,名稱空間就是定義了一個範圍。
1.2.1 定義名稱空間
下面 下麪通過一個範例來展示如何定義名稱空間並使用名稱空間中的函數等。
#include <iostream>
using namespace std;
// 第一個名稱空間
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二個名稱空間
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 呼叫第一個名稱空間中的函數
first_space::func();
// 呼叫第二個名稱空間中的函數
second_space::func();
return 0;
}
1.2.2 using指令
可以使用 using namespace xxxx指令,這樣在使用名稱空間時就可以不用在前面加上名稱空間的名稱。這個指令會告訴編譯器,後續的程式碼將使用指定的名稱空間中的名稱。
1.3 前處理器
前處理器是一些指令,指示編譯器在實際編譯之前所需完成的預處理。所有的前處理器指令都是以井號(#)開頭,只有空格字元可以出現在預處理指令之前。預處理指令不是 C++ 語句,所以它們不會以分號(;)結尾。
1.3.1 #define預處理
#define 預處理指令用於建立符號常數。該符號常數通常稱爲宏,指令的一般形式是:
#define macro-name replacement-text
//例如
#define PI 3.14159
可以使用 #define 來定義一個帶有參數的參數宏,如下所示:
#include <iostream>
using namespace std;
#define MIN(a,b) (a<b ? a : b)
int main ()
{
int i, j;
i = 100;
j = 30;
cout <<"較小的值爲:" << MIN(i, j) << endl;
return 0;
}
1.3.2 條件編譯
有幾個指令可以用來有選擇地對部分程式原始碼進行編譯。這個過程被稱爲條件編譯。
條件前處理器的結構與 if 選擇結構很像。請看下面 下麪這段前處理器的程式碼:
#ifndef NULL
#define NULL 0
#endif
例如,要實現只在偵錯時進行編譯,可以使用一個宏來實現,如下所示:
#ifdef DEBUG
cerr <<"Variable x = " << x << endl;
#endif
使用 #if 0 語句可以註釋掉程式的一部分,如下所示:
#if 0
不進行編譯的程式碼
#endif
下面 下麪給出一個範例:
#include <iostream>
using namespace std;
#define DEBUG
#define MIN(a,b) (((a)<(b)) ? a : b)
int main ()
{
int i, j;
i = 100;
j = 30;
#ifdef DEBUG
cerr <<"Trace: Inside main function" << endl;
#endif
#if 0
/* 這是註釋部分 */
cout << MKSTR(HELLO C++) << endl;
#endif
cout <<"The minimum is " << MIN(i, j) << endl;
#ifdef DEBUG
cerr <<"Trace: Coming out of main function" << endl;
#endif
return 0;
}
當上面的程式碼被編譯和執行時,它會產生下列結果:
Trace: Inside main function
The minimum is 30
Trace: Coming out of main function
1.4 相關面試題
Q:C++和C的區別
A:設計思想上:
- C++是物件導向的語言,而C是程序導向的結構化程式語言
語法上:
- C++具有封裝、繼承和多型三種特性
- C++相比C,增加多許多型別安全的功能,比如強制型別轉換
- C++支援範式程式設計,比如模板類、函數模板等
Q:include標頭檔案雙引號」」和尖括號<>的區別
A:編譯器預處理階段查詢標頭檔案的路徑不一樣:
- 對於使用尖括號包含的標頭檔案,編譯器從標準庫路徑開始搜尋
- 對於使用雙引號包含的標頭檔案,編譯器從使用者的工作路徑開始搜尋
Q:標頭檔案的作用是什麼?
A:
- 通過標頭檔案來呼叫庫功能。
- 標頭檔案能加強型別安全檢查。
Q:在標頭檔案中進行類的宣告,在對應的實現檔案中進行類的定義有什麼意義?
A:這樣可以提高編譯效率,因爲分開的話,這個類只需要編譯一次生成對應的目標檔案,以後在其他地方用到這個類時,編譯器查詢到了標頭檔案和目標檔案,就不會再次編譯這個類,從而大大提高了效率。
Q:C++原始檔從文字到可執行檔案經歷的過程
A:對於C++原始檔,從文字到可執行檔案一般需要四個過程:
- 預編譯階段:對原始碼檔案中檔案包含關係(標頭檔案)、預編譯語句(宏定義)進行分析和替換,生成預編譯檔案
- 編譯階段:將經過預處理後的預編譯檔案轉換成特定彙編程式碼,生成彙編檔案
- 彙編階段:將編譯階段生成的彙編檔案轉化成機器碼,生成可重定位目標檔案
- 鏈接階段:將多個目標檔案及所需要的庫鏈接成最終的可執行目標檔案
Q:靜態鏈接與動態鏈接
A:靜態鏈接是在編譯期間完成的。
- 靜態鏈接浪費空間 ,這是由於多進程情況下,每個進程都要儲存靜態鏈接函數的副本。
- 更新困難 ,當鏈接的衆多目標檔案中有一個改變後,整個程式都要重新鏈接才能 纔能使用新的版本。
- 靜態鏈接執行效率高。
動態鏈接的進行則是在程式執行時鏈接。
- 動態鏈接當系統多次使用同一個目標檔案時,只需要載入一次即可,節省記憶體空間。
- 程式升級變得容易,當升級某個共用模組時,只需要簡單的將舊目標檔案替換掉,程式下次執行時,新版目標檔案會被自動裝載到記憶體並鏈接起來,即完成升級。
Q:C++11有哪些新特性
A:
- auto關鍵字:編譯器可以根據初始值自動推導出型別,但是不能用於函數傳參以及陣列型別的推導;
- nullptr關鍵字:nullptr是一種特殊型別的字面值,它可以被轉換成任意其它的指針型別;而NULL一般被宏定義爲0,在遇到過載時可能會出現問題。
- 智慧指針:C++11新增了std::shared_ptr、std::weak_ptr等型別的智慧指針,用於解決記憶體管理的問題。
- 初始化列表:使用初始化列表來對類進行初始化
- 右值參照:基於右值參照可以實現移動語意和完美轉發,消除兩個物件互動時不必要的物件拷貝,節省運算儲存資源,提高效率
- atomic原子操作用於多執行緒資源互斥操作
- 新增STL容器array以及tuple
Q:assert()是什麼
A:斷言是宏,而非函數。assert 宏的原型定義在 <assert.h>(C)、<cassert>(C++)中,其作用是如果它的條件返回錯誤,則終止程式執行。可以通過定義 NDEBUG 來關閉 assert,但是需要在原始碼的開頭,include <assert.h> 之前。
#define NDEBUG // 加上這行,則 assert 不可用 #include <assert.h> assert( p != NULL ); // assert 不可用
Q:C++是不是型別安全的?
A:不是,因爲兩個不同類型的指針之間可以強制轉換(用reinterpret cast)。
Q:系統會自動開啓和關閉的3個標準的檔案是?
A:
- 標準輸入----鍵盤---stdin
- 標準輸出----顯示器---stdout
- 標準出錯輸出----顯示器---stder
第二章 C++數據操作
2.1 數據型別
2.1.1 基本型別
C++有7種基本的數據型別:
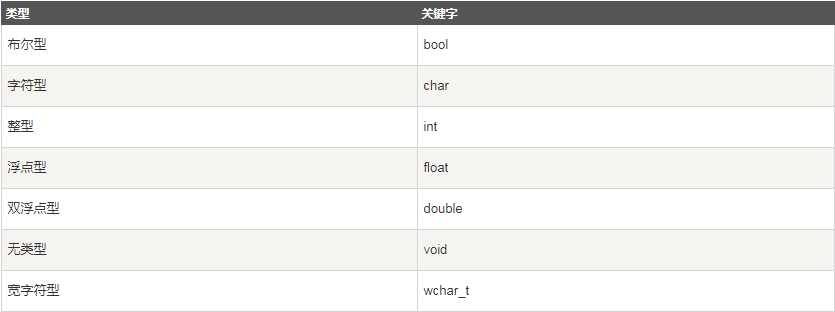
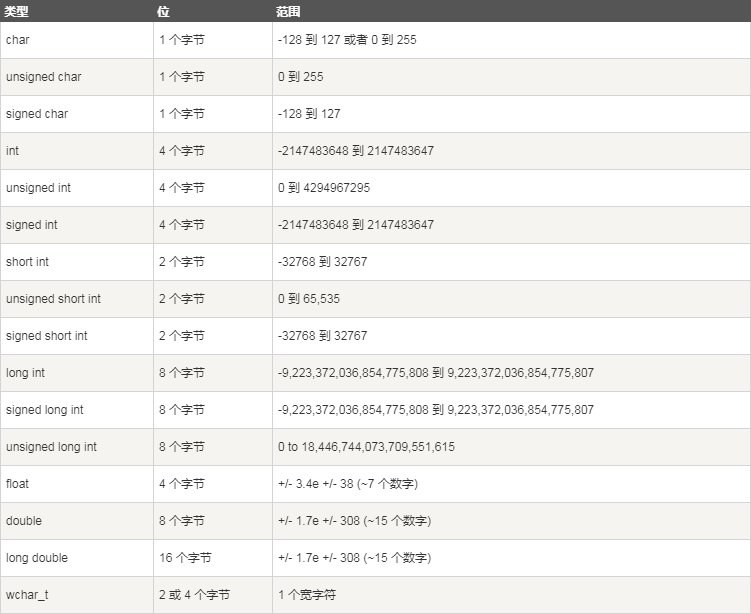
可以使用signed,unsigned,short,long去修飾這些基本型別:
2.1.2 typedef
可以使用 typedef 爲一個已有的型別取一個新的名字。例如:
//typedef type newname;
typedef int feet;
feet distance
typedef struct Student {
int age;
} S;
S student;
2.2 變數
2.2.1 變數定義
//type variable_name = value;
extern int d = 3, f = 5; // d 和 f 的宣告
int d = 3, f = 5; // 定義並初始化 d 和 f
byte z = 22; // 定義並初始化 z
char x = 'x'; // 變數 x 的值爲 'x'
2.2.2 變數宣告
可以使用extern關鍵字在任意地方宣告一個變數。
// 變數宣告
extern int a, b;
extern float f;
int main ()
{
// 變數定義
int a, b;
float f;
return 0;
}
同樣的,函數宣告是,提供一個函數名即可,而函數的實際定義則可以在任何地方進行。
// 函數宣告
int func();
int main()
{
// 函數呼叫
int i = func();
}
// 函數定義
int func()
{
return 0;
}
2.2.3 變數作用域
- 在函數或一個程式碼塊內部宣告的變數,稱爲區域性變數。
- 在函數參數的定義中宣告的變數,稱爲形式參數。
- 在所有函數外部宣告的變數,稱爲全域性變數。
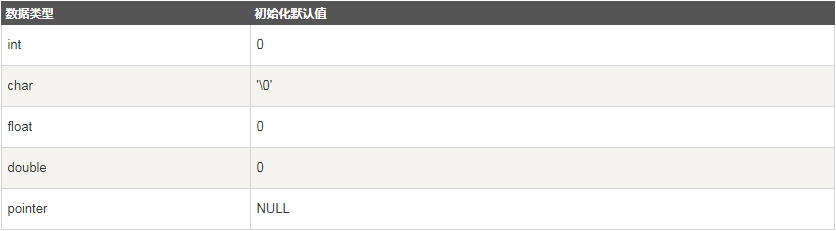
注:當區域性變數被定義時,系統不會對其初始化,您必須自行對其初始化。定義全域性變數時,系統會自動初始化爲下列值:
2.3 常數
常數是固定值,在程式執行期間不會改變。這些固定的值,又叫做字面量。
2.3.1 define前處理器
下面 下麪是使用 #define 前處理器定義常數的形式:
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
2.3.2 const關鍵字
可以使用 const 字首宣告指定型別的常數,const型別的物件在程式執行期間不能被修改。如下所示:
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
2.4 型別限定符
2.4.1 volatile
volatile 用來修飾變數,表明某個變數的值可能會隨時被外部改變,因此使用 volatile 告訴編譯器不應對這樣的物件進行優化(沒有被 volatile 修飾的變數,可能由於編譯器的優化,從 CPU 暫存器中取值;而被volatile修飾的變數,它不能被快取到暫存器,每次存取需要到記憶體中重新讀取)。
volatile int n = 10;
2.4.2 restrict
由 restrict 修飾的指針是唯一一種存取它所指向的物件的方式。
2.5 儲存類
儲存類定義 C++ 程式中變數/函數的範圍(可見性)和生命週期。
2.5.1 auto儲存類
auto 關鍵字用於兩種情況:宣告變數時根據初始化表達式自動推斷該變數的型別、宣告函數時函數返回值的佔位符。
2.5.2 static儲存類
static 儲存類指示編譯器在程式的生命週期內保持區域性變數的存在,而不需要在每次它進入和離開作用域時進行建立和銷燬。
- 使用 static 修飾區域性變數可以在函數呼叫之間保持區域性變數的值。
- 當 static 修飾全域性變數時,會使變數的作用域限制在宣告它的檔案內。
- 在 C++ 中,當 static 用在類數據成員上時,會導致僅有一個該成員的副本被類的所有物件共用。
2.5.3 extern儲存類
extern 儲存類用於提供一個全域性變數的參照,全域性變數對所有的程式檔案都是可見的。通常用於當有兩個或多個檔案共用相同的全域性變數或函數的時候。
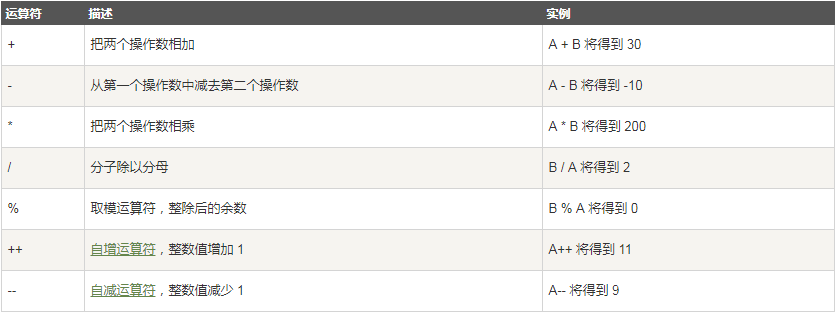
2.6 運算子
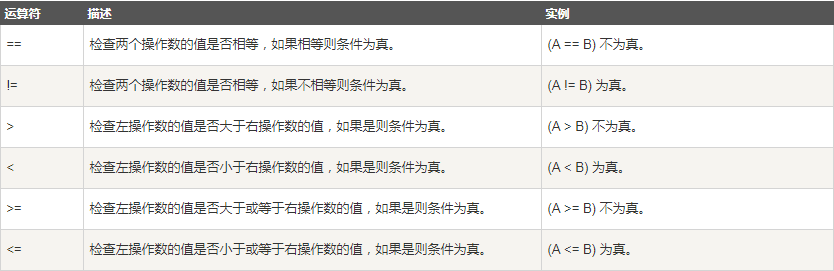
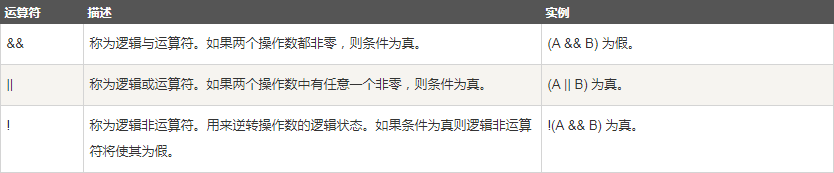
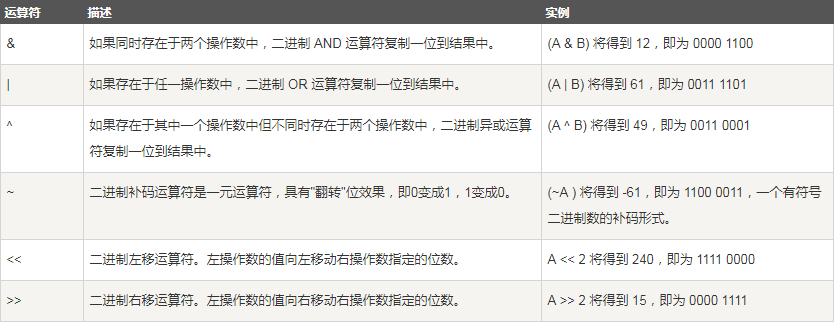
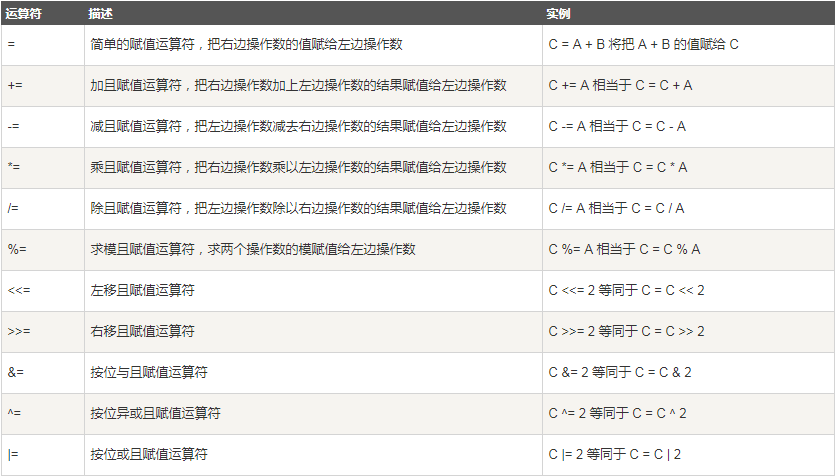

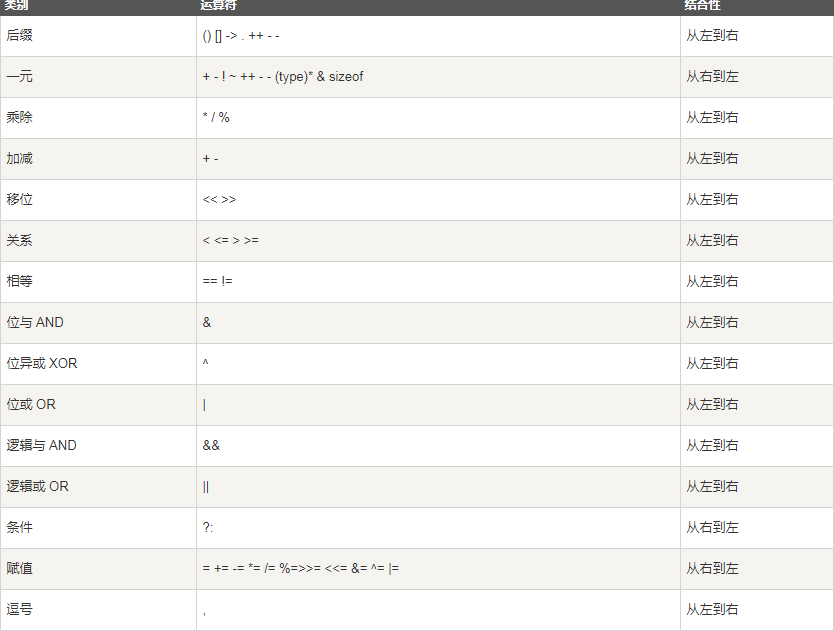
2.7 相關面試題
Q:const的作用
A:
- 修飾變數,說明該變數不可以被修改
- 修飾指針,即常數指針和指針常數
- 常數參照,經常用於形參型別,既避免了拷貝,又避免了函數對值的修改
- 修飾類的成員函數,說明該成員函數內不能修改成員變數
// 類 class A { private: const int a; // 常物件成員,只能在初始化列表賦值 public: // 建構函式 A() : a(0) { }; A(int x) : a(x) { }; // 初始化列表 // const可用於對過載函數的區分 int getValue(); // 普通成員函數 int getValue() const; // 常成員函數,不得修改類中的任何數據成員的值 }; void function() { // 物件 A b; // 普通物件,可以呼叫全部成員函數、更新常成員變數 const A a; // 常物件,只能呼叫常成員函數 const A *p = &a; // 常指針 const A &q = a; // 常參照 // 指針 char greeting[] = "Hello"; char* p1 = greeting; // 指針變數,指向字元陣列變數 const char* p2 = greeting; // 常數指針即常指針,指針指向的地址可以改變,但是所存的內容不能變 char const* p2 = greeting; // 與const char* p2 等價 char* const p3 = greeting; // 指針常數,指針是一個常數,即指針指向的地址不能改變,但是指針所存的內容可以改變 const char* const p4 = greeting; // 指向常數的常指針,指針和指針所存的內容都不能改變,本質是一個常數 } // 函數 void function1(const int Var); // 傳遞過來的參數在函數內不可變 void function2(const char* Var); // 參數爲常數指針即指針所指的內容爲常數不能變,指針指向的地址可以改變 void function3(char* const Var); // 參數爲指針常數 void function4(const int& Var); // 參數爲常數參照,在函數內部不會被進行修改,同時參數不會被複制一遍,提高了效率 // 函數返回值 const int function5(); // 返回一個常數 const int* function6(); // 返回一個指向常數的指針變數即常數指針,使用:const int *p = function6(); int* const function7(); // 返回一個指向變數的常指針即指針常數,使用:int* const p = function7();
Q:說明define和const在語法和含義上有什麼不同?
A:
- #define是C語法中定義符號變數的方法,符號常數只是用來表達一個值,在編譯階段符號就被值替換了,它沒有型別;
- const是C++語法中定義常變數的方法,常變數具有變數特性,它具有型別,記憶體中存在以它命名的儲存單元,可以用sizeof測出長度。
Q:static關鍵字的作用
A:靜態變數在程式執行之前就建立,在程式執行的整個週期都存在。可以歸類爲如下五種:
- 區域性靜態變數:作用域僅在定義它的函數體或語句塊內,該變數的記憶體只被分配一次,因此其值在下次函數被呼叫時仍維持上次的值;
- 全域性靜態變數:作用域僅在定義它的檔案內,該變數也被分配在靜態儲存區內,在整個程式執行期間一直存在;
- 靜態函數:在函數返回型別前加static,函數就定義爲靜態函數。靜態函數只是在宣告他的檔案當中可見,不能被其他檔案所用;
- 類的靜態成員:在類中,靜態成員屬於整個類所擁有,對類的所有物件只有一份拷貝,因此可以實現多個物件之間的數據共用,並且使用靜態數據成員還不會破壞隱藏的原則,即保證了安全性;
- 類的靜態函數:在類中,靜態成員函數不接收this指針,因而只能存取類的static成員變數,如果靜態成員函數中要參照非靜態成員時,可通過物件來參照。(呼叫靜態成員函數使用如下格式:<類名>::<靜態成員函數名>(<參數表>);)
Q:請你來說一下C++裡是怎麼定義常數的?常數存放在記憶體的哪個位置?
A:常數在C++裡使用const關鍵字定義,常數定義必須初始化。對於區域性物件,常數存放在棧區;對於全域性物件,編譯期一般不分配記憶體,放在符號表中以提高存取效率;對於字面值常數,存放在常數儲存區。
Q:sizeof()和strlen()
A:sizeof是運算子,能獲得保證能容納實現所建立的最大物件的位元組大小:
- sizeof 對陣列,得到整個陣列所佔空間大小;
- sizeof 對指針,得到指針本身所佔空間大小(4個位元組);
- 當一個類A中沒有生命任何成員變數與成員函數,這時sizeof(A)的值是1。
strlen()是函數,可以計算字串的長度,直到遇到結束符NULL才結束,返回的長度大小不包含NULL。
Q:C++ 位元組對齊
A:定義:位元組按照一定的規律在空間上排列。現代計算機中記憶體空間都是按照byte劃分的,從理論上講似乎對任何型別的變數的存取可以從任何地址開始,但實際情況是在存取特定型別變數的時候經常在特定的記憶體地址存取,這就需要各種型別數據按照一定的規則在空間上排列,而不是順序的一個接一個的排放,這就是對齊。
使用原因:不同硬體平臺對儲存空間的處理上存在很大的不同。某些平臺對特定型別的數據只能從特定地址開始存取,而不允許其在記憶體中任意存放;同時,如果不按照平臺要求對存放數據進行對齊,會帶來存取效率上的損失。
Q:強制型別轉換運算子
A:static_cast
- 特點:靜態轉換,編譯時執行。
- 應用場合:主要用於C++中內建的基本數據型別之間的轉換,同一個繼承體系中型別的轉換,任意型別與空指針型別void* 之間的轉換,但是沒有執行時型別檢查(RTTI)來保證轉換的安全性。
const_cast
- 特點:去常轉換,編譯時執行。
- 應用場合: const_cast可以用於修改型別的const或volatile屬性,去除指向常數物件的指針或參照的常數性。
reinterpret_cast:
- 特點:重解釋型別轉換,編譯時執行。
- 應用場合: 可以用於任意型別的指針之間的轉換,對轉換的結果不做任何保證。
dynamic_cast:
- 特點:動態型別轉換,執行時執行。
- 應用場合:只能用於存在虛擬函式的父子關係的強制型別轉換,只能轉指針或參照。對於指針,轉換失敗則返回nullptr,對於參照,轉換失敗會拋出異常
Q:請你說說你瞭解的RTTI
A:
定義:RTTI(Run Time Type Identification)即通過執行時型別識別,程式能夠使用基礎類別的指針或參照來檢查着這些指針或參照所指的物件的實際派生型別。
RTTI機制 機製產生原因:C++是一種靜態型別語言,其數據型別是在編譯期就確定的,不能在執行時更改。然而由於物件導向程式設計中多型性的要求,C++中的指針或參照本身的型別,可能與它實際代表(指向或參照)的型別並不一致。有時我們需要將一個多型指針轉換爲其實際指向物件的型別,就需要知道執行時的型別資訊,這就產生了執行時型別識別的要求。
C++中有兩個函數用於執行時型別識別,分別是dynamic_cast和typeid,具體如下:
- typeid函數返回一個對type_info類物件的參照,可以通過該類的成員函數獲得指針和參照所指的實際型別;
- dynamic_cast操作符,將基礎類別型別的指針或參照安全地轉換爲其派生類型別的指針或參照。
Q:explicit(顯式)關鍵字
A:
- explicit 修飾建構函式時,可以防止隱式轉換和複製初始化,必須顯式初始化
- explicit 修飾轉換函數時,可以防止隱式轉換,但按語境轉換 除外
struct B { explicit B(int) {} explicit operator bool() const { return true; } }; int main() { B b1(1); // OK:直接初始化 B b2 = 1; // 錯誤:被 explicit 修飾建構函式的物件不可以複製初始化 B b3{ 1 }; // OK:直接列表初始化 B b4 = { 1 }; // 錯誤:被 explicit 修飾建構函式的物件不可以複製列表初始化 B b5 = (B)1; // OK:允許 static_cast 的顯式轉換 doB(1); // 錯誤:被 explicit 修飾建構函式的物件不可以從 int 到 B 的隱式轉換 if (b1); // OK:被 explicit 修飾轉換函數 B::operator bool() 的物件可以從 B 到 bool 的按語境轉換 bool b6(b1); // OK:被 explicit 修飾轉換函數 B::operator bool() 的物件可以從 B 到 bool 的按語境轉換 bool b7 = b1; // 錯誤:被 explicit 修飾轉換函數 B::operator bool() 的物件不可以隱式轉換 bool b8 = static_cast<bool>(b1); // OK:static_cast 進行直接初始化 return 0; }
Q::: 範圍解析運算子
A:該運算子可分爲如下三類:
- 全域性作用域符(::name):用於型別名稱(類、類成員、成員函數、變數等)前,表示作用域爲全域性名稱空間
- 類作用域符(class::name):用於表示指定型別的作用域範圍是具體某個類的
- 名稱空間作用域符(namespace::name):用於表示指定型別的作用域範圍是具體某個名稱空間的
第三章 指針和參照
3.1 指針
3.1.1 指針定義
指針是一個變數,其值爲另一個變數的記憶體地址。指針變數宣告的一般形式爲:
type *var-name;
int *ip; /* 一個整型的指針 */
所有指針的值的實際數據型別,不管是整型、浮點型、字元型,還是其他的數據型別,都是一樣的,都是一個代表記憶體地址的長的十六進制數。不同數據型別的指針之間唯一的不同是,指針所指向的變數或常數的數據型別不同。
3.1.2 指針的使用
使用指針時會頻繁進行以下幾個操作:定義一個指針變數、把變數地址賦值給指針、存取指針變數中可用地址的值。這些是通過使用一元運算子 * 來返回位於運算元所指定地址的變數的值。
#include <iostream>
using namespace std;
int main ()
{
int var = 20; // 實際變數的宣告
int *ip; // 指針變數的宣告
ip = &var; // 在指針變數中儲存 var 的地址
cout << "Value of var variable: ";
cout << var << endl;
// 輸出在指針變數中儲存的地址
cout << "Address stored in ip variable: ";
cout << ip << endl;
// 存取指針中地址的值
cout << "Value of *ip variable: ";
cout << *ip << endl;
return 0;
}
其結果爲:
Value of var variable: 20
Address stored in ip variable: 0xbfc601ac
Value of *ip variable: 20
3.1.3 常用指針操作
//空指針
int *ptr = NULL;
cout << "ptr 的值是 " << ptr ; //結果是:ptr 的值是 0
//指針遞增
int var[3] = {10, 100, 200};
ptr = var; //陣列的變數名代表指向第一個元素的指針
ptr++;
//指向指針的指針
int var;
int *ptr;
int **pptr;
var = 3000;
// 獲取 var 的地址
ptr = &var;
// 使用運算子 & 獲取 ptr 的地址
pptr = &ptr;
3.2 參照
參照變數是一個別名,也就是說,它是某個已存在變數的另一個名字。一旦把參照初始化爲某個變數,就可以使用該參照名稱或變數名稱來指向變數。參照很容易與指針混淆,它們之間有三個主要的不同:
- 不存在空參照。參照必須連線到一塊合法的記憶體。
- 一旦參照被初始化爲一個物件,就不能被指向到另一個物件。指針可以在任何時候指向到另一個物件。
- 參照必須在建立時被初始化。指針可以在任何時間被初始化。
// 宣告簡單的變數
int i;
double d;
// 宣告參照變數
int& r = i;
double& s = d;
3.3 相關面試題
Q:C/C++ 中指針和參照的區別?
A:
- 指針有自己的一塊空間,而參照只是一個別名;
- 指針可以被初始化爲NULL,而參照必須被初始化;
- 指針在使用中可以指向其它物件,但是參照只能是一個物件的參照,不能被改變;
- 指針可以有多級指針(**p),而參照只有一級;
Q:指針函數和函數指針?
A:
- 指針函數本質上是一個函數,函數的返回值是一個指針;
- 函數指針本質上是一個指針,C++在編譯時,每一個函數都有一個入口地址,該入口地址就是函數指針所指向的地址,有了函數指針後,就可用該指針變數呼叫函數。
char * fun(char * p) {…} // 指針函數fun char * (*pf)(char * p); // 函數指針pf pf = fun; // 函數指針pf指向函數fun pf(p); // 通過函數指針pf呼叫函數fun
Q:在什麼時候需要使用「常參照」?
A:如果既要利用參照提高程式的效率,又要保護傳遞給函數的數據不在函數中被改變,就應使用常參照。
Q:C++中的四個智慧指針: shared_ptr、unique_ptr、weak_ptr、auto_ptr
A:智慧指針出現的原因:智慧指針的作用就是用來管理一個指針,將普通的指針封裝成一個棧物件,當棧物件的生命週期結束之後,會自動呼叫解構函式釋放掉申請的記憶體空間,從而防止記憶體泄露。(https://www.cnblogs.com/WindSun/p/11444429.html)
- shared_ptr實現共用式擁有概念。多個智慧指針指向相同對象,該物件和其相關資源會在最後一個參照被銷燬時被釋放。
- unique_ptr實現獨佔式擁有概念,保證同一時間內只有一個智慧指針可以指向該物件。
- weak_ptr 是一種共用但不擁有物件的智慧指針, 它指向一個 shared_ptr 管理的物件。進行該物件的記憶體管理的是那個強參照的 shared_ptr,weak_ptr只是提供了對管理物件的一個存取手段,它的構造和解構不會引起參照計數的增加或減少。weak_ptr 設計的目的是爲協助 shared_ptr工作的,用來解決shared_ptr相互參照時的死鎖問題。注意的是我們不能通過weak_ptr直接存取物件的方法,以通過呼叫lock函數來獲得shared_ptr,再通過shared_ptr去呼叫物件的方法。
- auto_ptr採用所有權模式,C++11中已經拋棄。
Q:shared_ptr的底層實現
A:
template <typename T> class smart_ptrs { public: smart_ptrs(T*); //用普通指針初始化智慧指針 smart_ptrs(smart_ptrs&); // 拷貝構造 T* operator->(); //自定義指針運算子 T& operator*(); //自定義解除參照運算子 smart_ptrs& operator=(smart_ptrs&); //自定義賦值運算子 ~smart_ptrs(); //自定義解構函式 private: int *count; //參照計數 T *p; //智慧指針底層保管的指針 }; //建構函式 template <typename T> smart_ptrs<T>::smart_ptrs(T *p): count(new int(1)), p(p) {} //對普通指針進行拷貝,同時參照計數器加1,因爲需要對參數進行修改,所以沒有將參數宣告爲const template <typename T> smart_ptrs<T>::smart_ptrs(smart_ptrs &sp): count(&(++*sp.count)), p(sp.p) {} //指針運算子 template <typename T> T* smart_ptrs<T>::operator->() {return p;} //定義解除參照運算子 template <typename T> T& smart_ptrs<T>::operator*() {return *p;} //定義賦值運算子,左邊的指針計數減1,右邊指針計數加1,當左邊指針計數爲0時,釋放記憶體: template <typename T> smart_ptrs<T>& smart_ptrs<T>::operator=(smart_ptrs& sp) { ++*sp.count; if (--*count == 0) { //自我賦值同樣能保持正確 delete count; delete p; } this->p = sp.p; this->count = sp.count; return *this; } // 定義解構函式: template <typename T> smart_ptrs<T>::~smart_ptrs() { if (--*count == 0) { delete count; delete p; } }
Q:野指針
A:野指針就是指向一個已銷燬或者存取受限記憶體區域的指針。產生野指針通常是因爲幾種疏忽:
- 指針變數未被初始化;
- 指針釋放後未置空;
- 指針操作超越變數作用域(例如變數被釋放了,指針還是指向它)。
Q:什麼時候會發生段錯誤?
A:段錯誤通常發生在存取非法記憶體地址的時候,具體來說分爲以下幾種情況:
- 使用了野指針
- 試圖修改字串常數的內容
- 陣列越界導致棧溢位Q:什麼是右值參照,跟左值又有什麼區別?
A:左值:能對錶達式取地址的具名物件/變數等。一般指表達式結束後依然存在的持久物件。
右值:不能對錶達式取地址的字面量、函數返回值、匿名函數或匿名物件。一般指表達式結束就不再存在的臨時物件。
右值參照和左值參照的區別在於:
- 通過&獲得左值參照,左值參照只能系結左值。
- 通過&&獲得右值參照,右值參照只能系結右值,基於右值參照可以實現移動語意和完美轉發,右值參照的好處是減少右值作爲參數傳遞時的複製開銷,提高效率。
Q:什麼是std::move()以及什麼時候使用它?
A:std::move()是C ++標準庫中用於轉換爲右值參照的函數。當需要在其他地方「傳輸」物件的內容時使用std :: move,物件可以在不進行復制的情況下獲取臨時物件的內容,避免不必要的深拷貝。
Q:C++類別的內部可以定義參照數據成員嗎?
A:可以,必須通過成員函數初始化列表初始化
class MyClass { public: MyClass(int &i): a(1), b(i){ // 建構函式初始化列表中是初始化工作 // 在這裏做的是賦值而非初始化工作 } private: const int a; int &b; // 參照數據成員b,必須通過列表初始化! };
第四章 函數——C++的程式設計模組
4.1 函數的定義與宣告
4.1.1 函數定義
return_type function_name( parameter list )
{
body of the function
}
// 範例:函數返回兩個數中較大的那個數
int max(int num1, int num2)
{
// 區域性變數宣告
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
4.1.2 函數宣告
return_type function_name( parameter list );
//範例
int max(int num1, int num2);
//在函數宣告中,參數的名稱並不重要,只有參數的型別是必需的,因此下面 下麪也是有效的宣告:
int max(int, int);
注:當你在一個原始檔中定義函數且在另一個檔案中呼叫函數時,函數宣告是必需的。在這種情況下,您應該在呼叫函數的檔案頂部宣告函數。
4.1.3 函數參數
如果函數要使用參數,則必須宣告接受參數值的變數。這些變數稱爲函數的形式參數。形式參數就像函數內的其他區域性變數,在進入函數時被建立,退出函數時被銷燬。當呼叫函數時,有多種向函數傳遞參數的方式:
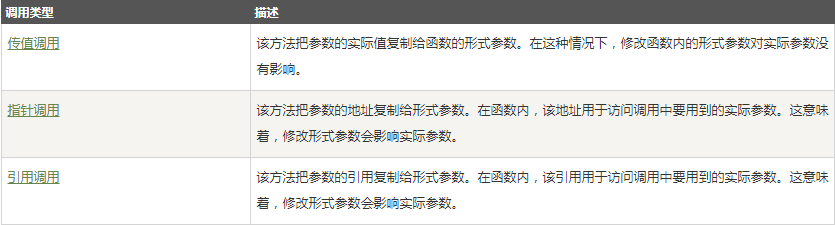
1、傳值呼叫
預設情況下,C++ 使用傳值呼叫來傳遞參數。
2、指針呼叫
把參數的地址複製給形參
#include <iostream>
using namespace std;
// 函數定義
void swap(int *x, int *y)
{
int temp;
temp = *x; /* 儲存地址 x 的值 */
*x = *y; /* 把 y 賦值給 x */
*y = temp; /* 把 x 賦值給 y */
return;
}
int main ()
{
// 區域性變數宣告
int a = 100;
int b = 200;
cout << "交換前,a 的值:" << a << endl;
cout << "交換前,b 的值:" << b << endl;
/* 呼叫函數來交換值
* &a 表示指向 a 的指針,即變數 a 的地址
* &b 表示指向 b 的指針,即變數 b 的地址
*/
swap(&a, &b);
cout << "交換後,a 的值:" << a << endl;
cout << "交換後,b 的值:" << b << endl;
return 0;
}
其中,&a、&b是指變數的地址,swap函數的形參*x、*y中的*是指從x、y的地址取值(即實參爲地址,形參通過指針參照)。
3、參照呼叫
#include <iostream>
using namespace std;
// 函數定義
void swap(int &x, int &y)
{
int temp;
temp = x; /* 儲存地址 x 的值 */
x = y; /* 把 y 賦值給 x */
y = temp; /* 把 x 賦值給 y */
return;
}
int main ()
{
// 區域性變數宣告
int a = 100;
int b = 200;
cout << "交換前,a 的值:" << a << endl;
cout << "交換前,b 的值:" << b << endl;
/* 呼叫函數來交換值 */
swap(a, b);
cout << "交換後,a 的值:" << a << endl;
cout << "交換後,b 的值:" << b << endl;
return 0;
}
實參爲變數,形參通過加&參照實參變數(區別於傳值參照)
4、參數預設值
int sum(int a, int b=20)
{
int result;
result = a + b;
return (result);
}
//呼叫的時候可以不傳入b
sum(a);
4.2 行內函式
當函數被宣告爲行內函式之後,編譯器會將其內聯展開,而不是按通常的函數呼叫機制 機製進行呼叫。引入行內函式的目的是爲了解決程式中函數呼叫的效率問題,程式在編譯器編譯的時候,編譯器將程式中出現的行內函式的呼叫表達式用行內函式的函數體進行替換,而對於其他的函數,都是在執行時候才被替代。這其實就是個空間代價換時間的節省。所以行內函式一般都是10行以下的小函數,如果想把一個函數定義爲行內函式,則需要在函數名前面放置關鍵字 inline,在呼叫函數之前需要對函數進行定義。

注:在類中定義的成員函數全部預設爲行內函式,在類中宣告,但在類外定義的爲普通函數。
4.3 過載
4.3.1 過載函數
C++ 允許在同一個作用域內宣告幾個功能類似的同名函數,但是這些同名函數的形式參數(指參數的個數、型別或者順序)必須不同。不能僅通過返回型別的不同來過載函數。
呼叫一個過載函數或過載運算子時,編譯器通過把您所使用的參數型別與定義中的參數型別進行比較,決定選用最合適的定義。選擇最合適的過載函數或過載運算子的過程,稱爲過載決策。
#include <iostream>
using namespace std;
class printData
{
public:
void print(int i) {
cout << "整數爲: " << i << endl;
}
void print(double f) {
cout << "浮點數爲: " << f << endl;
}
void print(char c[]) {
cout << "字串爲: " << c << endl;
}
};
int main(void)
{
printData pd;
// 輸出整數
pd.print(5);
// 輸出浮點數
pd.print(500.263);
// 輸出字串
char c[] = "Hello C++";
pd.print(c);
return 0;
}
4.3.2 過載運算子
過載的運算子是帶有特殊名稱的函數,函數名是由關鍵字 operator 和其後要過載的運算子符號構成的。與其他函數一樣,過載運算子有一個返回型別和一個參數列表,例如:
#include <iostream>
using namespace std;
class Box
{
public:
double getVolume(void)
{
return length * breadth * height;
}
void setLength( double len )
{
length = len;
}
void setBreadth( double bre )
{
breadth = bre;
}
void setHeight( double hei )
{
height = hei;
}
// 過載 + 運算子,用於把兩個 Box 物件相加
Box operator+(const Box& b)
{
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
double length; // 長度
double breadth; // 寬度
double height; // 高度
};
// 程式的主函數
int main( )
{
Box Box1; // 宣告 Box1,型別爲 Box
Box Box2; // 宣告 Box2,型別爲 Box
Box Box3; // 宣告 Box3,型別爲 Box
double volume = 0.0; // 把體積儲存在該變數中
// Box1 詳述
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// Box2 詳述
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// Box1 的體積
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl;
// Box2 的體積
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl;
// 把兩個物件相加,得到 Box3
Box3 = Box1 + Box2;
// Box3 的體積
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl;
return 0;
}
4.3.3 可過載與不可過載運算子


4.4 模板
模板是泛型程式設計的基礎,泛型程式設計即以一種獨立於任何特定型別的方式編寫程式碼。
4.4.1 函數模板
模板函數定義的一般形式如下所示:
template <class type>
ret-type func-name(parameter list)
{
// 函數的主體
}
範例如下:
#include <iostream>
#include <string>
using namespace std;
//使用const&可節省傳遞時間,同時保證值不被改變
template <typename T>
inline T const& Max (T const& a, T const& b)
{
return a < b ? b:a;
}
int main ()
{
int i = 39;
int j = 20;
cout << "Max(i, j): " << Max(i, j) << endl;
double f1 = 13.5;
double f2 = 20.7;
cout << "Max(f1, f2): " << Max(f1, f2) << endl;
string s1 = "Hello";
string s2 = "World";
cout << "Max(s1, s2): " << Max(s1, s2) << endl;
return 0;
}
4.4.2 類別範本
泛型類宣告的一般形式如下所示:
template <class type>
class class-name {
//類的主體
}
範例如下:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>
using namespace std;
template <class T>
class Stack {
private:
vector<T> elems; // 元素
public:
void push(T const&); // 入棧
void pop(); // 出棧
T top() const; // 返回棧頂元素
bool empty() const{ // 如果爲空則返回真。
return elems.empty();
}
};
template <class T>
void Stack<T>::push (T const& elem)
{
// 追加傳入元素的副本
elems.push_back(elem);
}
template <class T>
void Stack<T>::pop ()
{
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// 刪除最後一個元素
elems.pop_back();
}
template <class T>
T Stack<T>::top () const
{
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// 返回最後一個元素的副本
return elems.back();
}
int main()
{
try {
Stack<int> intStack; // int 型別的棧
Stack<string> stringStack; // string 型別的棧
// 操作 int 型別的棧
intStack.push(7);
cout << intStack.top() <<endl;
// 操作 string 型別的棧
stringStack.push("hello");
cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
}
catch (exception const& ex) {
cerr << "Exception: " << ex.what() <<endl;
return -1;
}
}
4.5 相關面試題
Q:C語言是怎麼進行函數呼叫的?
A:每一個函數呼叫都會分配函數棧,在棧內進行函數執行過程。呼叫前,先把返回地址壓棧,然後把當前函數的esp指針壓棧。
Q:函數參數壓棧方式爲什麼是從右到左的?
A:因爲C++支援可變函數參數。C程式棧底爲高地址,棧頂爲低地址,函數最左邊確定的參數在棧上的位置必須是確定的,否則意味着已經確定的參數是不能定位和找到的,這樣式無法保證函數正確執行的。
Q:C++如何處理返回值
A:生成一個臨時變數存入記憶體單元,呼叫程式存取該記憶體單元,獲得返回值。
Q:fork,wait,exec函數的作用
A:
- fork函數可以建立一個和當前映像一樣的子進程,這個函數會返回兩個值:從子進程返回0,從父進程返回子進程的PID;
- 呼叫了wait函數的父進程會發生阻塞,直到有子進程狀態改變(執行成功返回0,錯誤返回-1);
- exec函數可以讓子進程執行與父進程不同的程式,即讓子進程執行另一個程式(exec執行成功則子進程從新的程式開始執行,無返回值,執行失敗返回-1)。
Q:inline行內函式是什麼?
A:當一個函數被宣告爲行內函式之後,在編譯階段,編譯器會用行內函式的函數體取替換程式中出現的行內函式呼叫表達式,而其他的函數都是在執行時才被替換,這其實就是用空間換時間,提高了函數呼叫的效率。同時,行內函式具有幾個特點:
- 行內函式中不可以出現回圈、遞回或開關操作;
- 行內函式的定義必須出現在行內函式的第一次呼叫前;
- 類的成員函數(除了虛擬函式)會自動隱式的當成行內函式。
Q:行內函式的優缺點
A:優點:
- 行內函式在被呼叫處進行程式碼展開,省去了參數壓棧、棧幀開闢與回收,結果返回等操作,從而提高程式執行速度;
- 行內函式相比宏函數來說,在程式碼展開時,會做安全檢查或自動型別轉換,而宏定義則不會;
- 在類中宣告同時定義的成員函數,自動轉化爲行內函式,因此行內函式可以存取類的成員變數,宏定義則不能;
- 行內函式在執行時可偵錯,而宏定義不可以。
缺點:
- 程式碼膨脹,消耗了更多的記憶體空間;
- inline 函數無法隨着函數庫升級而升級。inline函數的改變需要重新編譯,不像 non-inline 可以直接鏈接;
- 行內函式其實是不可控的,它只是對編譯器的建議,是否對函數內聯,決定權在於編譯器。
Q:虛擬函式可以是行內函式嗎?
A:虛擬函式可以是行內函式,但是當虛擬函式表現多型性的時候不能內聯。
Q:函數過載、重寫、隱藏和模板
A:
- 過載:在同一作用域中,兩個函數名相同,但是參數列表不同(個數、型別、順序),返回值型別沒有要求;
- 重寫:子類繼承了父類別,父類別中的函數是虛擬函式,在子類中重新定義了這個虛擬函式,這種情況是重寫;
- 隱藏:派生類中函數與基礎類別中的函數同名,但是這個函數在基礎類別中並沒有被定義爲虛擬函式,此時基礎類別的函數會被隱藏;
- 模板:模板函數是一個通用函數,函數的型別和形參不直接指定而用虛擬型別來代表,只適用於參數個數相同而型別不同的函數。
Q:建構函式和解構函式能不能被過載?
A:建構函式可以被過載,解構函式不可以被過載。因爲建構函式可以有多個且可以帶參數, 而解構函式只能有一個,且不能帶參數。
Q:拷貝建構函式和賦值運算子過載的區別?
A:
- 拷貝建構函式是函數,賦值運算子是運算子的過載;
- 拷貝建構函式會生成新的類物件,賦值運算子不會;
- 拷貝建構函式是用一個已存在的物件去構造一個不存在的物件;而賦值運算子過載函數是用一個存在的物件去給另一個已存在並初始化過的物件進行賦值。
Q:類別範本是什麼?
A:類別範本是對一批僅數據成員型別不同的類的抽象,用於解決多個功能相同、數據型別不同的類需要重複定義的問題。在建立類時候使用template及任意型別識別符號T,之後在建立類物件時,會指定實際的型別,這樣纔會是一個實際的物件。
Q:select、poll和epoll的區別、原理、效能、限制
A:select,poll,epoll都是I/O多路複用技術的具體實現。I/O多路複用就是在單個執行緒中,通過記錄並跟蹤每個I/O流的狀態,來同時管理多個I/O流,一旦某個I/O流已經就緒,就能夠通知程式進行相應的讀寫操作,以此提高伺服器的吞吐能力。這種機制 機製的優勢不是在於對單個連線能處理得更快,而是在於能處理更多的連線,也就是多路網路連線複用一個I/O執行緒。
select
select是第一個實現I/O複用概唸的函數。它用一個結構體fd_set讓內核監聽多個檔案描述符。fd_set(檔案描述符集合)本質上就是一個數組,當呼叫select函數後,就會去裏面輪詢查詢看是否有描述符被置位,也就是有需要被處理的I/O事件。
select函數主要存在三個問題:
- 內建陣列的形式使得select支援的最大檔案描述符受限於FD_SIZE;
- 每次呼叫select前都要重新初始化描述符集,將fd從使用者態拷貝到內核態,每次呼叫select後,都需要將fd從內核態拷貝到使用者態;
- 每次呼叫select後都要去輪詢排查所有檔案描述符,這在檔案描述符個數很多的時候,效率很低。
poll
poll可以理解爲一個加強版的select。它通過一個可變長度的陣列解決了select檔案描述符受限的問題。陣列中元素是結構體pollfd,這個結構體儲存了描述符的資訊,每增加一個檔案描述符就向陣列中加入一個結構體。同時,結構體只需要拷貝一次到內核態,解決了select重複初始化的問題。但是,它仍然存在輪詢排查效率低的問題。
epoll
輪詢排查所有檔案描述符的效率不高,使伺服器併發能力受限。因此,epoll採用只返回狀態發生變化的檔案描述符,便解決了輪尋的瓶頸。
第五章 結構體、類與物件
5.1 結構體
5.1.1 定義結構
struct 語句定義了一個包含多個成員的新的數據型別,struct 語句的格式如下:
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
在結構定義的末尾,最後一個分號之前,可以指定一個或多個結構變數,這是可選的。上面是宣告一個結構體型別 Books,變數爲 book。
5.1.2 存取結構成員
爲了存取結構的成員,我們使用成員存取運算子(.)。
Books Book1; // 定義結構體型別 Books 的變數 Book1
// Book1 詳述
strcpy( Book1.title, "C++ 教學");
strcpy( Book1.author, "Runoob");
strcpy( Book1.subject, "程式語言");
Book1.book_id = 12345;
5.1.3 結構作爲函數參數
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books book );
// 宣告一個結構體型別 Books
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main( )
{
Books Book1; // 定義結構體型別 Books 的變數 Book1
Books Book2; // 定義結構體型別 Books 的變數 Book2
// Book1 詳述
strcpy( Book1.title, "C++ 教學");
strcpy( Book1.author, "Runoob");
strcpy( Book1.subject, "程式語言");
Book1.book_id = 12345;
// Book2 詳述
strcpy( Book2.title, "CSS 教學");
strcpy( Book2.author, "Runoob");
strcpy( Book2.subject, "前端技術");
Book2.book_id = 12346;
// 輸出 Book1 資訊
printBook( Book1 );
// 輸出 Book2 資訊
printBook( Book2 );
return 0;
}
void printBook( struct Books book )
{
cout << "書標題 : " << book.title <<endl;
cout << "書作者 : " << book.author <<endl;
cout << "書類目 : " << book.subject <<endl;
cout << "書 ID : " << book.book_id <<endl;
}
5.1.4 指向結構的指針
定義指向結構的指針,方式與定義指向其他型別變數的指針相似。爲了使用指向該結構的指針存取結構的成員,必須使用 -> 運算子,如下所示:
struct Books *struct_pointer;
struct_pointer = &Book1;
struct_pointer->title;
5.2 類和物件
5.2.1 類的定義
class Box
{
public:
double length; // 盒子的長度
double breadth; // 盒子的寬度
double height; // 盒子的高度
double getVolume(void);// 返回體積
};
5.2.2 類的宣告
Box box1;
Box box2 = Box(parameters);
Box box3(parameters);
Box* box4 = new Box(parameters);
5.2.3 存取類的成員
box1.length = 5.0;
cout << box1.length << endl;
5.2.4 類成員函數
成員函數可以定義在類定義內部,或者單獨使用範圍解析運算子 :: 來定義。
class Box
{
public:
double length; // 長度
double breadth; // 寬度
double height; // 高度
double getVolume(void)
{
return length * breadth * height;
}
};
//您也可以在類的外部使用範圍解析運算子 :: 定義該函數
double Box::getVolume(void)
{
return length * breadth * height;
}
//呼叫成員函數同樣是在物件上使用點運算子(.)
Box myBox; // 建立一個物件
myBox.getVolume(); // 呼叫該物件的成員函數
5.2.5 類存取修飾符
數據封裝是物件導向程式設計的一個重要特點,它防止函數直接存取類的內部成員。類成員的存取限制是通過在類主體內部對各個區域標記 public、private、protected 來指定的。關鍵字 public、private、protected 稱爲存取修飾符。
class Base {
public:
// 公有成員
protected:
// 受保護成員
private:
// 私有成員
};
- 公有成員在程式中類的外部是可存取的。
- 私有成員變數或函數在類的外部是不可存取的,甚至是不可檢視的。只有類和友元函數可以存取私有成員。如果沒有使用任何存取修飾符,類的成員將被假定爲私有成員
- 保護成員變數或函數與私有成員十分相似,但有一點不同,保護成員在派生類(即子類)中是可存取的。
5.2.6 類的特殊函數
1)建構函式
類別建構函式是類的一種特殊的成員函數,它會在每次建立類的新物件時執行。建構函式的名稱與類的名稱是完全相同的,並且不會返回任何型別,也不會返回 void。
2)解構函式
類的解構函式是類的一種特殊成員函數,它會在每次刪除所物件時執行。解構函式的名稱與類的名稱是完全相同的,只是在前面加了個波浪號(~)作爲字首,它不會返回任何值,也不能帶有任何參數。解構函式有助於在跳出程式(比如關閉檔案、釋放記憶體等)前釋放資源。
class Line
{
public:
void setLength( double len );
double getLength( void );
Line(); // 這是建構函式
Line(double len); // 這是帶參數的建構函式
~Line(); // 這是解構函式宣告
private:
double length;
};
// 成員函數定義,包括建構函式
Line::Line(void)
{
cout << "Object is being created" << endl;
}
Line::Line( double len)
{
cout << "Object is being created, length = " << len << endl;
length = len;
}
Line::~Line(void)
{
cout << "Object is being deleted" << endl;
delete ptr;
}
3)拷貝建構函式
拷貝建構函式是一種特殊的建構函式,通常用於:通過使用另一個同類型的物件來初始化新建立的物件。
class Line
{
public:
int getLength( void );
Line( int len ); // 簡單的建構函式
Line( const Line &obj); // 拷貝建構函式
~Line(); // 解構函式
private:
int *ptr;
};
Line::Line(const Line &obj)
{
cout << "呼叫拷貝建構函式併爲指針 ptr 分配記憶體" << endl;
ptr = new int;
*ptr = *obj.ptr; // 拷貝值
}
4)友元函數
類的友元函數是定義在類外部,但有權存取類的所有私有(private)成員和保護(protected)成員。儘管友元函數的原型有在類的定義中出現過,但是友元函數並不是成員函數。
class Box
{
double width;
public:
friend void printWidth( Box box );
void setWidth( double wid );
};
// 請注意:printWidth() 不是任何類的成員函數
void printWidth( Box box )
{
/* 因爲 printWidth() 是 Box 的友元,它可以直接存取該類的任何成員 */
cout << "Width of box : " << box.width <<endl;
}
5.2.7 this指針
在 C++ 中,每一個物件都能通過 this 指針來存取自己的地址。this 指針是所有成員函數的隱含參數。因此,在成員函數內部,它可以用來指向呼叫物件。
class Box{
public:
Box(){;}
~Box(){;}
Box* get_address() //得到this的地址
{
return this;
}
double Volume()
{
return length * breadth * height;
}
int compare(Box box)
{
//指針通過->存取類成員,物件通過.存取類成員
return this->Volume() > box.Volume();
}
};
注:友元函數沒有 this 指針,因爲友元不是類的成員。只有成員函數纔有 this 指針。
5.2.8 指向類的指針
int main(void)
{
Box Box1(3.3, 1.2, 1.5); // Declare box1
Box Box2(8.5, 6.0, 2.0); // Declare box2
Box *ptrBox; // Declare pointer to a class.
// 其中ptrBox爲地址,*表示從其地址取值
// 儲存第一個物件的地址
ptrBox = &Box1;
// 現在嘗試使用成員存取運算子來存取成員
cout << "Volume of Box1: " << ptrBox->Volume() << endl;
// 儲存第二個物件的地址
ptrBox = &Box2;
// 現在嘗試使用成員存取運算子來存取成員
cout << "Volume of Box2: " << ptrBox->Volume() << endl;
return 0;
}
5.2.9 類的靜態成員
我們可以使用 static 關鍵字來把類成員定義爲靜態的。靜態成員在類的所有物件中是共用的,當我們宣告類的成員爲靜態時,這意味着無論建立多少個類的物件,靜態成員都只有一個副本。
注:如果不存在其他的初始化語句,在建立第一個物件時,所有的靜態數據都會被初始化爲零。我們不能把靜態成員的初始化放置在類的定義中,但是可以在類的外部通過使用範圍解析運算子 :: 來重新宣告靜態變數從而對它進行初始化
class Box
{
public:
static int objectCount;
// 建構函式定義
Box(double l=2.0, double b=2.0, double h=2.0)
{
cout <<"Constructor called." << endl;
length = l;
breadth = b;
height = h;
// 每次建立物件時增加 1
objectCount++;
}
double Volume()
{
return length * breadth * height;
}
private:
double length; // 長度
double breadth; // 寬度
double height; // 高度
};
// 初始化類 Box 的靜態成員
int Box::objectCount = 1;
如果把函數成員宣告爲靜態的,就可以把函數與類的任何特定物件獨立開來。靜態成員函數即使在類物件不存在的情況下也能被呼叫,靜態函數只要使用類名加範圍解析運算子 :: 就可以存取。

5.3 數據抽象與封裝
5.3.1 定義
數據抽象是一種僅向使用者暴露介面而把具體的實現細節隱藏起來的機制 機製,是一種依賴於介面實現分離的設計技術。
數據封裝是一種把數據和操作數據的函數捆綁在一起的機制 機製。
#include <iostream>
using namespace std;
class Adder{
public:
// 建構函式
Adder(int i = 0)
{
total = i;
}
// 對外的介面
void addNum(int number)
{
total += number;
}
// 對外的介面
int getTotal()
{
return total;
};
private:
// 對外隱藏的數據
int total;
};
int main( )
{
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}
上面的類把數位相加,並返回總和。公有成員 addNum 和 getTotal 是對外的介面,使用者需要知道它們以便使用類。私有成員 total 是使用者不需要瞭解的,但又是類能正常工作所必需的。
數據抽象的好處
- 類的內部受到保護,不會因無意的使用者級錯誤導致物件狀態受損。
- 類實現可能隨着時間的推移而發生變化,數據抽象可以更好的取應對不斷變化的需求。
設計策略
- 通常情況下,我們都會設定類成員狀態爲私有(private),除非我們真的需要將其暴露,這樣才能 纔能保證良好的封裝性。抽象把程式碼分離爲介面和實現。所以在設計元件時,必須保持介面獨立於實現,這樣,如果改變底層實現,介面也將保持不變。在這種情況下,不管任何程式使用介面,介面都不會受到影響,只需要將最新的實現重新編譯即可。
5.3.2 介面
介面描述了類的行爲和功能,而不需要完成類的特定實現。如果類中至少有一個函數被宣告爲純虛擬函式,則這個類就是抽象類。
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
// pure virtual function
virtual int area() = 0;
};
設計抽象類(通常稱爲 ABC)的目的,是爲了給其他類提供一個可以繼承的適當的基礎類別。抽象類不能被用於範例化物件,它只能作爲介面使用。因此,如果一個 ABC 的子類需要被範例化,則必須實現每個虛擬函式,如果沒有在派生類中重寫純虛擬函式,就嘗試範例化該類的物件,會導致編譯錯誤。可用於範例化物件的類被稱爲具體類。
5.4 繼承
繼承代表了 is a 關係。例如,哺乳動物是動物,狗是哺乳動物,因此,狗是動物,等等。一個類可以派生自多個類,這意味着,它可以從多個基礎類別繼承數據和函數。類派生列表以一個或多個基礎類別命名,形式如下:
class derived-class: access-specifier base-class
//例如
#include <iostream>
using namespace std;
// 基礎類別 Shape
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// 基礎類別 PaintCost
class PaintCost
{
public:
int getCost(int area)
{
return area * 70;
}
};
// 派生類
class Rectangle: public Shape, public PaintCost
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// 輸出物件的面積
cout << "Total area: " << Rect.getArea() << endl;
// 輸出總花費
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}
派生類可以存取基礎類別中所有的非私有成員,同時,一個派生類繼承了所有的基礎類別方法,但下列情況除外:
- 基礎類別的建構函式、解構函式和拷貝建構函式。
- 基礎類別的過載運算子。
- 基礎類別的友元函數。
5.5 多型
5.5.1 虛擬函式
虛擬函式是在基礎類別中使用關鍵字 virtual 宣告的函數。在派生類中重新定義基礎類別中定義的虛擬函式時,會告訴編譯器不要靜態鏈接到該函數。我們想要的是在程式中任意點可以根據所呼叫的物件型別來選擇呼叫的函數,這種操作被稱爲動態鏈接,或後期系結。
C++ 多型意味着呼叫成員函數時,會根據呼叫函數的物件的型別來執行不同的函數,例如:
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape{
public:
Rectangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape{
public:
Triangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// 程式的主函數
int main( )
{
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// 儲存矩形的地址
shape = &rec;
// 呼叫矩形的求面積函數 area
shape->area(); //Rectangle class area
// 儲存三角形的地址
shape = &tri;
// 呼叫三角形的求面積函數 area
shape->area(); //Triangle class area
return 0;
}
注意:若在基礎類別中不能對虛擬函式給出有意義的實現,這個時候就會用到純虛擬函式,在函數參數後直接加 = 0 告訴編譯器,函數沒有主體,這種虛擬函式即是純虛擬函式。
5.6 相關面試題
Q:C++中struct和class的區別
A:struct 更適合看成是一個數據結構的實現體,class 更適合看成是一個物件的實現體。它們最本質的一個區別就是:struct 存取許可權預設是 public 的,class 預設是 private 的。
Q:解構函式是否需要是虛擬函式?
A:只有當一個類需要當作父類別時,纔將它的解構函式設定爲虛擬函式。
- 將可能會被繼承的父類別的解構函式設定爲虛擬函式,可以保證當我們new一個子類,然後使用基礎類別指針指向該子類物件,釋放基礎類別指針時可以釋放掉子類的空間,防止記憶體漏失;
- C++預設的解構函式不是虛擬函式,着是因爲虛擬函式需要額外的虛擬函式表和虛表指針,佔用額外的記憶體。而對於不會被繼承的類來說,其解構函式如果是虛擬函式,就會浪費記憶體。
Q:C++中解構函式的特點
A:
- 當物件結束其生命週期,如物件所在的函數已呼叫完畢時,系統會自動執行解構函式;
- 解構函式名與類名相同,只是在函數名前面加一個位取反符~,只能有一個解構函式,不能過載;
- 如果使用者沒有編寫解構函式,編譯系統會自動生成一個預設的解構函式;
- 如果一個類中有指針,且在使用的過程中動態的申請了記憶體,那麼最好顯式構造解構函式,在銷燬類之前釋放掉申請的記憶體空間,避免記憶體漏失;
- 類解構順序:1)派生類本身的解構函式;2)物件成員解構函式;3)基礎類別解構函式。
Q:靜態函數和虛擬函式的區別
A:
- 靜態函數在編譯的時候就已經確定執行時機,虛擬函式在執行的時候動態系結。
- 虛擬函式因爲用了虛擬函式表機制 機製,呼叫的時候會增加一次記憶體開銷。
Q:必須使用成員初始化列表的場合
A:初始化列表的好處:少了一次呼叫預設建構函式的過程,提高了效率。
有些場合必須要用初始化列表:
- 常數成員,因爲常數只能初始化不能賦值,所以必須放在初始化列表裏面
- 參照型別,參照必須在定義的時候初始化,並且不能重新賦值,所以也要寫在初始化列表裏面
- 沒有預設建構函式的類型別,因爲使用初始化列表可以不必呼叫預設建構函式來初始化
Q:物件導向三大特徵
A:
- 封裝:把數據和操作系結在一起封裝成抽象的類,僅向使用者暴露介面,而對其隱藏具體實現,以此避免外界幹擾和不確定性存取;
- 繼承:讓某種型別物件獲得另一個型別物件的屬性和方法,提高了程式碼的可維護性;
- 多型:讓同一事物體現出不同事物的狀態,提高了程式碼的擴充套件性。
Q:C++ 多型分類及實現
A:
- 過載多型(Ad-hoc Polymorphism,編譯期):函數過載、運算子過載(靜態多型)
- 子型別多型(Subtype Polymorphism,執行期):虛擬函式(動態多型)
- 參數多型(Parametric Polymorphism,編譯期):類別範本、函數模板
- 強制多型(Coercion Polymorphism,編譯期/執行期):基本型別轉換、自定義型別轉換
Q:是不是一個父類別寫了一個virtual 函數,如果子類重寫它的函數不加virtual ,也能實現多型?
A:virtual修飾符會被隱形繼承,因此可加可不加,子類覆蓋它的函數不加virtual,也能實現多型。
Q:虛表指針、虛擬函式指針和虛擬函式表
A:
- 虛表指針:在含有虛擬函式的類的物件中,指向虛擬函式表的指針,在執行時確定。
- 虛擬函式指針:指向虛擬函式的地址的指針。
- 虛擬函式表:在程式只讀數據段,存放虛擬函式指針,如果派生類實現了基礎類別的某個虛擬函式,則在虛擬函式表中覆蓋原本基礎類別的那個虛擬函式指針,在編譯時根據類的宣告建立。
Q:簡單描述虛繼承與虛基礎類別?
A:定義:在C++中,在定義公共基礎類別A的派生類B、C...的時候,如果在繼承方式前使用關鍵字virtual對繼承方式限定,這樣的繼承方式就是虛擬繼承,公共基礎類別A成爲虛基礎類別。這樣,在具有公共基礎類別的、使用了虛擬繼承方式的多個派生類B、C...的公共派生類D中,該基礎類別A的成員就只有一份拷貝。
作用:一個類有多個基礎類別,這樣的繼承關係稱爲多繼承。在多繼承的情況下,如果不同基礎類別的成員名稱相同,匹配度相同, 則會造成二義性。爲了避免多繼承產生的二義性,在這種機制 機製下,不論虛基礎類別在繼承體系中出現了多少次,在派生類中都只包含一份虛基礎類別的成員。
Q:抽象類、介面類、聚合類
A:
- 抽象類:含有純虛擬函式的類
- 介面類:僅含有純虛擬函式的抽象類
- 聚合類:使用者可以直接存取其成員,並且具有特殊的初始化語法形式。滿足如下特點:1)所有成員都是 public;2)沒有定義任何建構函式;3)沒有類內初始化;4)沒有基礎類別,也沒有 virtual 函數
Q:如何定義一個只能在堆上(棧上)生成物件的類?
A:
- 只能在堆上
- 方法: 將解構函式設定爲私有
- 原因:C++ 是靜態系結語言,編譯器管理棧上物件的生命週期,編譯器在爲類物件分配棧空間時,會先檢查類的解構函式的存取性。若解構函式不可存取,則不能在棧上建立物件。
- 只能在棧上
- 方法:將 new 和 delete 過載爲私有
- 原因: 在堆上生成物件,使用 new 關鍵詞操作,其過程分爲兩階段:第一階段,使用 new 在堆上尋找可用記憶體,分配給物件;第二階段,呼叫建構函式生成物件。將 new 操作設定爲私有,那麼第一階段就無法完成,就不能夠在堆上生成物件。
Q:建構函式是否可以用private修飾,如果可以,會有什麼效果?
A:如果一個類別建構函式只有一個且爲private:
- 可以編譯通過;
- 如果類的內部沒有專門建立範例的程式碼,則是無法建立任何範例的;
- 如果類的內部有專門建立範例的程式碼,則只能建立一個或多個範例(根據類內部宣告的成員物件個數來定);
- private 建構函式如果參數 爲void(無參),則子類無法編譯。
Q:子類的指針能否轉換爲父類別的指針?父類別指針能否存取子類成員?
A:首先要明確,當一個父類別指針指向子類物件時是安全的,但只能存取從父類別繼承的成員;然而當一個子類指針指向父類別物件時,因爲可能呼叫父類別不存在的方法,所以是不安全的,會爆語法錯誤。
- 當自己的類指針指向自己類的物件時,無論呼叫的是虛擬函式還是實函數,其呼叫的都是自己的;
- 當指向父類別物件的父類別指針被強制轉換成子類指針時,也就是子類指針指向父類別物件,此時,子類指針呼叫函數時,只有非重寫函數是自己的,虛擬函式是父類別的;
- 當指向子類物件的子類指針被強制轉換成父類別指針時,也就是父類別指針指向子類物件,此時,父類別指針呼叫的虛擬函式都是子類的,而非虛擬函式都是自己的。
Q:this 指針
A:this 指針是一個隱含於每一個非靜態成員函數中的特殊指針,它指向呼叫該成員函數的物件的首地址。
- 當對一個物件呼叫成員函數時,編譯程式先將物件的地址賦給 this 指針,然後呼叫成員函數,每次成員函數存取數據成員時,都隱式使用 this 指針。
- this 指針被隱含地宣告爲: ClassName *const this,這意味着不能給 this 指針賦值。
- this 並是個右值,所以不能取 this 的地址。
Q:delete this
A:
- 類的成員函數中可以呼叫delete this,但是在釋放後,物件後續呼叫的方法不能再用到this指針;
- delete this釋放了類物件的記憶體空間,但是記憶體空間卻並不是馬上被回收到系統中,此時其中的值是不確定的;
- delete的本質是爲將被釋放的記憶體呼叫一個或多個解構函式,如果在類的解構函式中呼叫delete this,會陷入無限遞回,造成棧溢位。
Q:一個空類class中有什麼?
A:建構函式、拷貝建構函式、解構函式、賦值運算子過載、取地址操作符過載、被const修飾的取地址操作符過載
Q:C++計算一個類的sizeof
A:
- 一個空的類sizeof返回1,因爲一個空類也要範例化,所謂類的範例化就是在記憶體中分配一塊地址;
- 類內的普通成員函數不參與sizeof的統計,因爲sizeof是針對範例的,而普通成員函數,是針對類體的;
- 一個類如果含有虛擬函式,則這個類中有一個指向虛擬函式表的指針,佔4個位元組;
- 靜態成員不影響類的大小,被編譯器放在程式的數據段中;
- 普通繼承的類sizeof,會得到基礎類別的大小加上派生類自身成員的大小;
- 當存在虛擬繼承時,派生類中會有一個指向虛基礎類別表的指針。所以其大小應爲普通繼承的大小,再加上虛基礎類別表的指針大小。
Q:建構函式和解構函式能被繼承嗎?
A:不能。建構函式和解構函式是用來處理物件的建立和解構的,它們只知道對在它們的特殊層次的物件做什麼。
Q:建構函式能不能是虛擬函式?
A:不能。虛擬函式對應一個虛擬函式表,可是這個虛擬函式表儲存在物件的記憶體空間的。問題就在於,如果建構函式是虛的,就需要通過 虛擬函式表來呼叫,可是物件還沒有範例化,也就是記憶體空間還沒有,就不會有虛擬函式表。
Q:建構函式和解構函式能不能被過載 ?
A:建構函式可以被過載,解構函式不可以被過載。因爲建構函式可以有多個且可以帶參數, 而解構函式只能有一個,且不能帶參數。
Q:建構函式呼叫順序,解構函式呢?
A:基礎類別的建構函式——成員類物件的建構函式——派生類別建構函式;解構函式相反。
Q:建構函式和解構函式呼叫時機?
A:
- 全域性範圍中的物件:建構函式在所有函數呼叫之前執行,在主函數執行完呼叫解構函式。
- 區域性自動物件:建立物件時呼叫建構函式,函數結束時呼叫解構函式。
- 動態分配的物件:建立物件時呼叫建構函式,呼叫釋放時呼叫解構函式。
- 靜態區域性變數物件:建立物件時呼叫建構函式,在主函數結束時呼叫解構函式。
Q:拷貝建構函式中深拷貝和淺拷貝區別?
A:
- 深拷貝會先申請一塊和拷貝數據一樣大的記憶體空間,然後將數據逐位元組拷貝過去,拷貝後兩個指針指向不同的兩個記憶體空間;
- 淺拷貝僅是拷貝指針地址,拷貝後兩個指針指向同一個記憶體空間。
當淺拷貝時,如果原來的物件呼叫解構函式釋放掉指針所指向的數據,則會產生空懸指針,因爲所指向的記憶體空間已經被釋放了。
Q:拷貝建構函式在什麼時候會被呼叫?
A:
- 當用類的一個物件去初始化該類的另一個物件(或參照)時系統自動呼叫拷貝建構函式實現拷貝賦值;
- 若函數的形參爲類物件,呼叫函數時,實參賦值給形參,系統自動呼叫拷貝建構函式;
- 當函數的返回值是類物件時,系統自動呼叫拷貝建構函式;
- 需要產生一個臨時類物件時。
Q:什麼時候必須重寫拷貝建構函式?
A:當建構函式涉及到動態記憶體分配時,要自己寫拷貝建構函式,並且要深拷貝。
Q:什麼是常物件?
A:常物件是指在任何場合都不能對其成員的值進行修改的物件。
Q:程序導向程式設計和麪向物件程式設計的區別
A:程序導向:就是分析出解決問題所需要的步驟,然後用函數把這些步驟一步一步實現。
物件導向:物件導向是一種對現實世界理解和抽象的方法,強調的是通過將需求要素轉化爲物件進行問題處理的一種思想。
Q:爲什麼行內函式,建構函式,靜態成員函數不能爲virtual函數?
A:
行內函式
行內函式是在編譯時期展開,而虛擬函式的特性是執行時才動態聯編,所以兩者矛盾,不能定義行內函式爲虛擬函式。建構函式
建構函式用來建立一個新的物件,而虛擬函式的執行是建立在物件的基礎上,在建構函式執行時,物件尚未形成,所以不能將建構函式定義爲虛擬函式。靜態成員函數
靜態成員函數屬於一個類而非某一物件,沒有this指針,它無法進行物件的判別。友元函數
C++不支援友元函數的繼承,對於沒有繼承性的函數沒有虛擬函式。
Q:如何定義和實現一個類的成員函數爲回撥函數?
A:所謂的回撥函數,就是預先在系統的對函數進行註冊,讓系統知道這個函數的存在,以後,當某個事件發生時,再呼叫這個函數對事件進行響應。
定義一個類的成員函數時在該函數前加CALLBACK即將其定義爲回撥函數,函數的實現和普通成員函數沒有區別。
第六章 動態記憶體
C++ 程式中的記憶體分爲兩個部分:
- 棧:在函數內部宣告的所有變數都將佔用棧記憶體。
- 堆:這是程式中未使用的記憶體,在程式執行時可用於動態分配記憶體。
6.1 new和delete運算子
在 C++ 中,可以使用特殊的運算子爲給定型別的變數在執行時分配堆內的記憶體,這會返回所分配的空間地址。這種運算子即 new 運算子。如果不再需要動態分配的記憶體空間,可以使用 delete 運算子,刪除之前由 new 運算子分配的記憶體。
#include <iostream>
using namespace std;
int main ()
{
double* pvalue = NULL; // 初始化爲 null 的指針
pvalue = new double; // 爲變數請求記憶體
*pvalue = 29494.99; // 在分配的地址儲存值
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // 釋放記憶體
return 0;
}
6.2 動態記憶體分配
6.2.1 陣列的動態記憶體分配
假設我們要爲一個字元陣列(一個有 20 個字元的字串)分配記憶體,我們可以使用上面範例中的語法來爲陣列動態地分配記憶體:
char* pvalue = NULL; // 初始化爲 null 的指針
pvalue = new char[20]; // 爲變數請求記憶體
要刪除我們剛纔建立的陣列,語句如下:
delete [] pvalue; // 刪除 pvalue 所指向的陣列
二維陣列範例:
#include <iostream>
using namespace std;
int main()
{
int **p;
int i,j; //p[4][8]
//開始分配4行8列的二維數據
p = new int *[4];
for(i=0;i<4;i++){
p[i]=new int [8];
}
for(i=0; i<4; i++){
for(j=0; j<8; j++){
p[i][j] = j*i;
}
}
//列印數據
for(i=0; i<4; i++){
for(j=0; j<8; j++)
{
if(j==0) cout<<endl;
cout<<p[i][j]<<"\t";
}
}
//開始釋放申請的堆
for(i=0; i<4; i++){
delete [] p[i];
}
delete [] p;
return 0;
}
6.2.2 物件的動態記憶體分配
物件與簡單的數據型別沒有什麼不同:
#include <iostream>
using namespace std;
class Box
{
public:
Box() {
cout << "呼叫建構函式!" <<endl;
}
~Box() {
cout << "呼叫解構函式!" <<endl;
}
};
int main( )
{
Box* myBoxArray = new Box[4];
delete [] myBoxArray; // 刪除陣列
return 0;
}
如果要爲一個包含四個 Box 物件的陣列分配記憶體,建構函式將被呼叫 4 次,同樣地,當刪除這些物件時,解構函式也將被呼叫相同的次數。
6.3 相關面試題
Q:new/delete具體步驟
A:使用new操作符來分配物件記憶體時會經歷三個步驟:
- 第一步:呼叫operator new 函數分配一塊足夠大的,原始的,未命名的記憶體空間以便儲存特定型別的物件。
- 第二步:編譯器執行相應的建構函式以構造物件,併爲其傳入初值。
- 第三部:物件構造完成後,返回一個指向該物件的指針。
使用delete操作符來釋放物件記憶體時會經歷兩個步驟:
- 第一步:呼叫物件的解構函式。
- 第二步:編譯器呼叫operator delete函數釋放記憶體空間。
Q:new/delete與malloc/free的區別是什麼?
A:
- malloc/free是C語言的標準庫函數, new/delete是C++的運算子。它們都可用於申請動態記憶體和釋放記憶體;
- malloc/free不會去自動呼叫構造和解構函式,對於基本數據型別的物件而言,光用malloc/free無法滿足動態物件的要求;
- malloc/free需要指定分配記憶體的大小,而new/delete會自動計算所需記憶體大小;
- new返回的是指定物件的指針,而malloc返回的是void*,因此malloc的返回值一般都需要進行強制型別轉換。
Q:C++記憶體管理
A:在C++中,虛擬記憶體分爲程式碼段、數據段、BSS段、堆區、棧區以及檔案對映區六部分。
- 程式碼段:包括只讀儲存區和文字區,其中只讀儲存區儲存字串常數,文字區儲存程序的機器程式碼。
- 數據段:儲存程序中已初始化的全域性變數和靜態變數
- BSS段:儲存未初始化的全域性變數和靜態變數(區域性+全域性),以及所有被初始化爲0的全域性變數和靜態變數。
- 堆區:呼叫new/malloc函數時在堆區動態分配記憶體,同時需要呼叫delete/free來手動釋放申請的記憶體。
- 對映區:儲存動態鏈接庫以及呼叫mmap函數進行的檔案對映
- 棧區:使用棧空間儲存函數的返回地址、參數、區域性變數、返回值
Q:記憶體的分配方式
A:記憶體分配方式有三種:
- 靜態儲存區,是在程式編譯時就已經分配好的,在整個執行期間都存在,如全域性變數、常數。
- 棧上分配,函數內的區域性變數就是從這分配的,但分配的記憶體容易有限。
- 堆上分配,也稱動態分配,如我們用new,malloc分配記憶體,用delete,free來釋放的記憶體。
Q:簡單介紹記憶體池?
A:記憶體池是一種記憶體分配方式。通常我們習慣直接使用new、malloc申請記憶體,這樣做的缺點在於所申請記憶體塊的大小不定,當頻繁使用時會造成大量的記憶體碎片並進而降低效能。記憶體池則是在真正使用記憶體之前,預先申請分配一定數量、大小相等(一般情況下)的記憶體塊留作備用。當有新的記憶體需求時,就從記憶體池中分出一部分記憶體塊,若記憶體塊不夠再繼續申請新的記憶體。這樣做的一個顯著優點是,使得記憶體分配效率得到提升。
Q:簡單描述記憶體漏失?
A:記憶體漏失一般是指堆記憶體的泄漏,也就是程式在執行過程中動態申請的記憶體空間不再使用後沒有及時釋放,導致那塊記憶體不能被再次使用。
Q:C++中的不安全是什麼概念?
A:C++中的不安全包括兩種:一是程式得不到正確的結果,二是發生不可預知的錯誤(佔用了不該用的記憶體空間)。可能會發生如下問題:
- 最嚴重的:記憶體漏失,程式崩潰;
- 一般嚴重的:發生一些邏輯錯誤,且不便於偵錯;
- 較輕的:丟失部分數據,就像強制轉換一樣。
Q:記憶體中的堆與棧有什麼區別?
A:
- 申請方式:棧由系統自動分配和管理,堆由程式設計師手動分配和管理。
- 效率:棧由系統分配,計算機底層對棧提供了一系列支援:分配專門的暫存器儲存棧的地址,壓棧和入棧有專門的指令執行,因此,其速度快,不會有記憶體碎片;堆由程式設計師分配,堆是由C/C++函數庫提供的,機制 機製複雜,需要一些列分配記憶體、合併記憶體和釋放記憶體的演算法,因此效率較低,可能由於操作不當產生記憶體碎片。
- 擴充套件方向:棧從高地址向低地址進行擴充套件,堆由低地址向高地址進行擴充套件。
- 程式區域性變數是使用的棧空間,new/malloc動態申請的記憶體是堆空間;同時,函數呼叫時會進行形參和返回值的壓棧出棧,也是用的棧空間。
第七章 C++ STL(標準模板庫)
STL(Standard Template Library),即標準模板庫,是一個具有工業強度的,高效的C++程式庫。STL中包括六大元件:容器、迭代器、演算法、仿函數、迭代適配器、空間設定器。
7.1 容器
STL中的常用容器包括:序列式容器(vector、deque、list)、關聯式容器(map、set)、容器適配器(queue、stack)。
7.1.1 序列式容器
1)vector
vector是一種動態陣列,在記憶體中具有連續的儲存空間,支援快速隨機存取。由於具有連續的儲存空間,所以在插入和刪除操作方面,效率比較慢。其常用操作如下:
//需要包含標頭檔案
#include <vector>
//1.定義和初始化
vector<int> vec1; //預設初始化,vec1爲空
vector<int> vec2(vec1); //使用vec1初始化vec2
vector<int> vec3(vec1.begin(),vec1.end());//使用vec1初始化vec2
vector<int> vec4(10); //10個值爲0的元素
vector<int> vec5(10,4); //10個值爲4的元素
//2.常用操作方法
//2.1 新增函數
vec1.push_back(100); //尾部新增元素
vec1.insert(vec1.end(),5,3); //從vec1.back位置插入5個值爲3的元素
//2.2 刪除函數
vec1.pop_back(); //刪除末尾元素
vec1.erase(vec1.begin(),vec1.begin()+2); //刪除vec1[0]-vec1[2]之間的元素,不包括vec1[2]其他元素前移
vec1.clear(); //清空元素,元素在記憶體中並未消失,通常使用swap()來清空
vector<int>().swap(V); //利用swap函數和臨時物件交換記憶體,交換以後,臨時物件消失,釋放記憶體。
//2.3 遍歷函數
vec1[0]; //取得第一個元素
vec1.at(int pos); //返回pos位置元素的參照
vec1.front(); //返回首元素的參照
vec1.back(); //返回尾元素的參照
vector<int>::iterator begin= vec1.begin(); //返迴向量頭指針,指向第一個元素
vector<int>::iterator end= vec1.end(); //返迴向量尾指針,指向向量最後一個元素的下一個位置
vector<int>::iterator rbegin= vec1.rbegin(); //反向迭代器,指向最後一個元素
vector<int>::iterator rend= vec1.rend(); //反向迭代器,指向第一個元素之前的位置
//2.4 判斷函數
bool isEmpty = vec1.empty(); //判斷是否爲空
//2.5 大小函數
int size = vec1.size(); //元素個數
vec1.capacity(); //返回容器當前能夠容納的元素個數
vec1.max_size(); //返回容器最大的可能儲存的元素個數
//2.6 改動函數
vec1.assign(int n,const T& x); //賦n個值爲x的元素到vec1中,這會清除掉vec1中以前的內容。
vec1.assign(const_iterator first,const_iterator last); //當前向量中[first,last)中元素設定成迭代器所指向量的元素,這會清除掉vec1中以前的內容。
2)deque
所謂的deque是」double ended queue」的縮寫,雙向佇列不論在尾部或頭部插入元素,都十分迅速。而在中間插入元素則會比較費時,因爲必須移動中間其他的元素。
#include <deque> // 標頭檔案
//1.宣告和初始化
deque<type> deq; // 宣告一個元素型別爲type的雙端佇列que
deque<type> deq(size); // 宣告一個型別爲type、含有size個預設值初始化元素的的雙端佇列que
deque<type> deq(size, value); // 宣告一個元素型別爲type、含有size個value元素的雙端佇列que
deque<type> deq(mydeque); // deq是mydeque的一個副本
deque<type> deq(first, last); // 使用迭代器first、last範圍內的元素初始化deq
//2.常用成員函數
deq[index]; //用來存取雙向佇列中單個的元素。
deq.at(index); //用來存取雙向佇列中單個的元素。
deq.front(); //返回第一個元素的參照。
deq.back(); //返回最後一個元素的參照。
deq.push_front(x); //把元素x插入到雙向佇列的頭部。
deq.pop_front(); //彈出雙向佇列的第一個元素。
deq.push_back(x); //把元素x插入到雙向佇列的尾部。
deq.pop_back(); //彈出雙向佇列的最後一個元素。
3)list
list是STL實現的雙向鏈表,與vector相比, 它允許快速的插入和刪除,但是隨機存取卻比較慢。
#include <list>
//1.定義和初始化
list<int>lst1; //建立空list
list<int> lst2(5); //建立含有5個元素的list
list<int>lst3(3,2); //建立含有3個元素值爲2的list
list<int>lst4(lst2); //使用lst2初始化lst4
list<int>lst5(lst2.begin(),lst2.end()); //同lst4
//2.常用操作函數
lst1.assign(lst2.begin(),lst2.end()); //給list賦值爲lst2
lst1.back(); //返回最後一個元素
lst1.begin(); //返回指向第一個元素的迭代器
lst1.clear(); //刪除所有元素
lst1.empty(); //如果list是空的則返回true
lst1.end(); //返回末尾的迭代器
lst1.erase(); //刪除一個元素
lst1.front(); //返回第一個元素
lst1.insert(); //插入一個元素到list中
lst1.max_size(); //返回list能容納的最大元素數量
lst1.merge(); //合併兩個list
lst1.pop_back(); //刪除最後一個元素
lst1.pop_front(); //刪除第一個元素
lst1.push_back(); //在list的末尾新增一個元素
lst1.push_front(); //在list的頭部新增一個元素
lst1.rbegin(); //返回指向第一個元素的逆向迭代器
lst1.remove(); //從list刪除元素
lst1.remove_if(); //按指定條件刪除元素
lst1.rend(); //指向list末尾的逆向迭代器
lst1.resize(); //改變list的大小
lst1.reverse(); //把list的元素倒轉
lst1.size(); //返回list中的元素個數
lst1.sort(); //給list排序
lst1.splice(); //合併兩個list
lst1.swap(); //交換兩個list
lst1.unique(); //刪除list中相鄰重複的元素
7.1.2 關聯式容器
1)map
map是STL的一個關聯容器,它是一種鍵值對容器,裏面的數據都是成對出現的,可在我們處理一對一數據的時候,在程式設計上提供快速通道。map內部自建一顆紅黑樹(一種非嚴格意義上的平衡二元樹),這顆樹具有對數據自動排序的功能,所以在map內部所有的數據都是有序的。
#include <map>
//1.定義與初始化
map<int, string> ID_Name;
// 使用{}賦值是從c++11開始的,因此編譯器版本過低時會報錯,如visual studio 2012
map<int, string> ID_Name = {{ 2015, "Jim" },{ 2016, "Tom" },{ 2017, "Bob"}};
//2.基本操作函數
count() //返回指定元素出現的次數
find() //查詢一個元素
get_allocator() //返回map的設定器
key_comp() //返回比較元素key的函數
lower_bound() //返回鍵值>=給定元素的第一個位置
upper_bound() //返回鍵值>給定元素的第一個位置
value_comp() //返回比較元素value的函數
map<int,string>::iterator iter_map = map1.begin();//取得迭代器首地址
int key = iter_map->first; //取得key
string value = iter_map->second; //取得value
2)set
set的含義是集合,它是一個有序的容器,裏面的元素都是排序好的支援插入、刪除、查詢等操作,就像一個集合一樣,所有的操作都是嚴格在logn時間內完成,效率非常高,使用方法類似list。
7.2 相關面試題
Q:六大元件介紹
A:容器:數據結構,用來存放數據
演算法:常用演算法
迭代器:容器和演算法之間的膠合劑,「範型指針」
仿函數:一種過載了operator()的類,使得這個類的使用看上去像一個函數
設定器:爲容器分配並管理記憶體
適配器:修改其他元件介面
Q:STL常用的容器有哪些以及各自的特點是什麼?
A:
- vector:底層數據結構爲陣列 ,支援快速隨機存取。
- list:底層數據結構爲雙向鏈表,支援快速增刪。
- deque:底層數據結構爲一箇中央控制器和多個緩衝區,支援首尾(中間不能)快速增刪,也支援隨機存取。
- stack:底層一般用deque/list實現,封閉頭部即可,不用vector的原因應該是容量大小有限制,擴容耗時。
- queue:底層一般用deque/list實現,封閉頭部即可,不用vector的原因應該是容量大小有限制,擴容耗時。
- priority_queue:的底層數據結構一般爲vector爲底層容器,堆heap爲處理規則來管理底層容器實現。
- set:底層數據結構爲紅黑樹,有序,不重複。
- multiset:底層數據結構爲紅黑樹,有序,可重複。
- map:底層數據結構爲紅黑樹,有序,不重複。
- multimap:底層數據結構爲紅黑樹,有序,可重複。
- unordered_set:底層數據結構爲hash表,無序,不重複。
- unordered_multiset:底層數據結構爲hash表,無序,可重複 。
- unordered_map :底層數據結構爲hash表,無序,不重複。
- unordered_multimap:底層數據結構爲hash表,無序,可重複。
Q:說說 vector 和 list 的區別
A:
- vector底層實現是陣列,所以在記憶體中是連續存放的,隨機讀取效率高,但插入、刪除效率低;list底層實現是雙向鏈表,所以在記憶體中是任意存放的,插入、刪除效率高,但存取元素效率低。
- vector在中間節點進行插入、刪除會導致記憶體拷貝,而list不會。
- vector一次性分配好記憶體,不夠時才進行2倍擴容;list每次插入新節點都會進行記憶體申請。
Q:vector擴容原理
A:以原記憶體空間大小的兩倍設定一份新的記憶體空間,並將原空間數據拷貝過來進行初始化。
Q:map 和 set 有什麼區別
A:
- map中的元素是鍵值對;Set僅是關鍵字的簡單集合;
- set的迭代器是const的,不允許修改元素的值;map允許修改value,但不允許修改key;
- map支援用關鍵字作下標操作,set不支援下標操作。
Q:map和unordered_map的區別
A:
- map: map內部實現了一個紅黑樹,紅黑樹的每一個節點都代表着map的一個元素,因此所有元素都是有序的,對其進行查詢、插入、刪除得效率都是O(log n);但是,因爲每個結點都需要額外儲存數據,所以空間佔用率比較高。
- unordered_map: unordered_map內部實現了一個雜湊表,因此內部元素是無序的,對其進行查詢、插入、刪除得效率都是O(1);但是建立雜湊表比較費時。
Q:STL 中迭代器的作用,有指針爲何還要迭代器
A:
- Iterator(迭代器)模式又稱Cursor(遊標)模式,用於提供一種方法順序存取一個聚合物件中各個元素, 而又不需暴露該物件的內部表示。
- 迭代器不是指針,是類別範本,表現的像指針。他只是模擬了指針的一些功能,通過過載了指針的一些操作符,->、*、++、--等,相當於一種智慧指針。
- 迭代器產生原因:Iterator採用的是物件導向的思想,把不同集合類的存取邏輯抽象出來,使得不用暴露集合內部的結構而達到回圈遍歷集合的效果。
第八章 例外處理
C++ 例外處理涉及到三個關鍵字:try、catch、throw。
- throw: 當問題出現時,程式會拋出一個異常。這是通過使用 throw 關鍵字來完成的。
- catch: 在想要處理問題的地方,通過例外處理程式捕獲異常。catch 關鍵字用於捕獲異常。
- try: try 塊中放置可能拋出異常的程式碼,try 塊中的程式碼被稱爲保護程式碼。它後面通常跟着一個或多個 catch 塊。
8.1 拋出異常
可以使用 throw 語句在程式碼塊中的任何地方拋出異常。throw 語句的運算元可以是任意的表達式,表達式的結果的型別決定了拋出的異常的型別。
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
8.2 捕獲異常
try
{
// 保護程式碼
}catch( ExceptionName e1 )
{
// catch 塊
}catch( ExceptionName e2 )
{
// catch 塊
}catch( ExceptionName eN )
{
// catch 塊
}
上面的程式碼會捕獲一個型別爲 ExceptionName 的異常。如果想讓 catch 塊能夠處理 try 塊拋出的任何型別的異常,則必須在異常宣告的括號內使用省略號 ...,例如:
try
{
// 保護程式碼
}catch(...)
{
// 能處理任何異常的程式碼
}
8.3 C++標準的異常
C++ 提供了一系列標準的異常,定義在 <exception> 中,我們可以在程式中使用這些標準的異常。
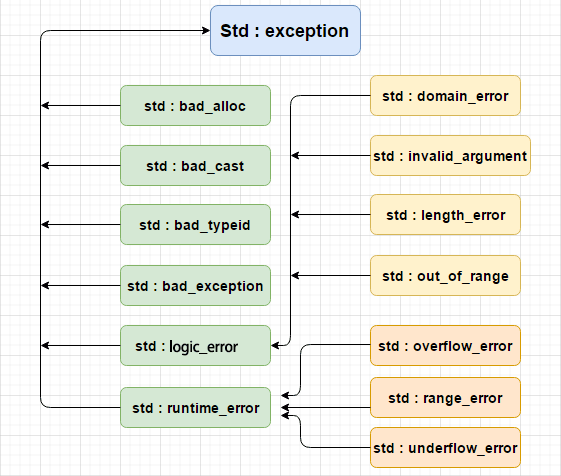
8.4 定義新的異常
可以通過繼承和過載 exception 類來定義新的異常。
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception
{
const char * what () const throw ()
{
return "C++ Exception";
}
};
int main()
{
try
{
throw MyException();
}
catch(MyException& e)
{
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
}
catch(std::exception& e)
{
//其他的錯誤
}
}
第九章 多執行緒
多執行緒是多工處理的一種特殊形式,一般情況下,有基於進程和基於執行緒的兩種型別的多工處理方式。
- 基於進程的多工處理是程式的併發執行。
- 基於執行緒的多工處理是同一程式的片段的併發執行。
9.1 基本概念
9.1.1 進程與執行緒
進程是資源分配和排程的一個獨立單位;而執行緒是進程的一個實體,是CPU排程和分配的基本單位。
同一個進程中的多個執行緒的記憶體資源是共用的,各執行緒都可以改變進程中的變數。因此在執行多執行緒運算的時候要注意執行順序。
9.1.2 並行與併發
並行(parallellism)指的是多個任務在同一時刻同時在執行。
併發(concurrency)是指在一個時間段內,多個任務交替進行。雖然看起來像在同時執行,但其實是交替的。
9.2 C++執行緒管理
- C++11的標準庫中提供了多執行緒庫,使用時需要#include <thread>標頭檔案,該標頭檔案主要包含了對執行緒的管理類std::thread以及其他管理執行緒相關的類。
- 每個應用程式至少有一個進程,而每個進程至少有一個主執行緒,除了主執行緒外,在一個進程中還可以建立多個子執行緒。每個執行緒都需要一個入口函數,入口函數返回退出,該執行緒也會退出,主執行緒就是以main函數作爲入口函數的執行緒。
9.2.1 啓動執行緒
std::thread的建構函式需要的是可呼叫(callable)型別,除了函數外,還可以呼叫例如:lambda表達式、過載了()運算子的類的範例。
#include <iostream>
#include <thread>
using namespace std;
void output(int i)
{
cout << i << endl;
}
int main()
{
for (uint8_t i = 0; i < 4; i++)
{
//建立一個執行緒t,第一個參數爲呼叫的函數,第二個參數爲傳遞的參數
thread t(output, i);
//表示允許該執行緒在後台執行
t.detach();
}
return 0;
}
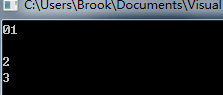
在多執行緒並行的條件下,其輸出結果不一定是順序呢的輸出1234,可能如下:
注意:
- 把函數物件傳入std::thread時,應傳入函數名稱(命名變數,如:output)而不加括號(臨時變數,如:output())。
- 當啓動一個執行緒後,一定要在該執行緒thread銷燬前,呼叫t.join()或者t.detach(),確定以何種方式等待執行緒執行結束:
- detach方式,啓動的執行緒自主在後台執行,當前的程式碼繼續往下執行,不等待新執行緒結束。
- join方式,等待關聯的執行緒完成,纔會繼續執行join()後的程式碼。
- 在以detach的方式執行執行緒時,要將執行緒存取的區域性數據複製到執行緒的空間(使用按值傳遞),一定要確保執行緒沒有使用區域性變數的參照或者指針,除非你能肯定該執行緒會在區域性作用域結束前執行結束。
9.2.2 向執行緒傳遞參數
向執行緒呼叫的函數只需要在構造thread的範例時,依次傳入即可。
thread t(output, arg1, arg2, arg3, ...);
9.2.3 呼叫類成員函數
class foo
{
public:
void bar1(int n)
{
cout<<"n = "<<n<<endl;
}
static void bar2(int n)
{
cout<<"static function is running"<<endl;
cout<<"n = "<<n<<endl;
}
};
int main()
{
foo f;
thread t1(&foo::bar1, &f, 5); //注意在呼叫非靜態類成員函數時,需要加上範例變數。
t1.join();
thread t2(&foo::bar2, 4);
t2.join();
}
9.2.4 轉移執行緒的所有權
thread是可移動的(movable)的,但不可複製的(copyable)。可以通過move來改變執行緒的所有權,靈活的決定執行緒在什麼時候join或者detach。
thread t1(f1);
thread t3(move(t1));
將執行緒從t1轉移給t3,這時候t1就不再擁有執行緒的所有權,呼叫t1.join或t1.detach會出現異常,要使用t3來管理執行緒。這也就意味着thread可以作爲函數的返回型別,或者作爲參數傳遞給函數,能夠更爲方便的管理執行緒。
9.2.5 執行緒標識的獲取
執行緒的標識型別爲std::thread::id,有兩種方式獲得到執行緒的id:
- 通過thread的範例呼叫get_id()直接獲取;
- 在當前執行緒上呼叫this_thread::get_id()獲取。
9.2.6 執行緒暫停
如果讓執行緒從外部暫停會引發很多併發問題,這也是爲什麼std::thread沒有直接提供pause函數的原因。如果執行緒在執行過程中,確實需要停頓,就可以用this_thread::sleep_for。
void threadCaller()
{
this_thread::sleep_for(chrono::seconds(3)); //此處執行緒停頓3秒。
cout<<"thread pause for 3 seconds"<<endl;
}
int main()
{
thread t(threadCaller);
t.join();
}
9.2.7 異常情況下等待執行緒完成
爲了避免主執行緒出現異常時將子執行緒終結,就要保證子執行緒在函數退出前完成,即在函數退出前呼叫join()。
方法一:異常捕獲
void func() {
thread t([]{
cout << "hello C++ 11" << endl;
});
try
{
do_something_else();
}
catch (...)
{
t.join();
throw;
}
t.join();
}
方法二:資源獲取即初始化(RAII)
class thread_guard
{
private:
thread &t;
public:
/*加入explicit防止隱式轉換,explicit僅可加在帶一個參數的構造方法上,如:Demo test; test = 12.2;
這樣的呼叫就相當於把12.2隱式轉換爲Demo型別,加入explicit就禁止了這種轉換。*/
explicit thread_guard(thread& _t) {
t = _t;
}
~thread_guard()
{
if (t.joinable())
t.join();
}
thread_guard(const thread_guard&) = delete; //刪除預設拷貝建構函式
thread_guard& operator=(const thread_guard&) = delete; //刪除預設賦值運算子
};
void func(){
thread t([]{
cout << "Hello thread" <<endl ;
});
thread_guard guard(t);
}
無論是何種情況,當函數退出時,物件guard呼叫其解構函式銷燬,從而能夠保證join一定會被呼叫。
9.3 執行緒的同步與互斥
執行緒之間通訊的兩個基本問題是互斥和同步:
- 執行緒同步是指執行緒之間所具有的一種制約關係,一個執行緒的執行依賴另一個執行緒的訊息,當它沒有得到另一個執行緒的訊息時應等待,直到訊息到達時才被喚醒。
- 執行緒互斥是指對於共用的操作系統資源,在各執行緒存取時的排它性。當有若幹個執行緒都要使用某一共用資源時,任何時刻最多隻允許一個執行緒去使用,其它要使用該資源的執行緒必須等待,直到佔用資源者釋放該資源。
執行緒互斥是一種特殊的執行緒同步。實際上,同步和互斥對應着執行緒間通訊發生的兩種情況:
- 當一個執行緒需要將某個任務已經完成的情況通知另外一個或多個執行緒時;
- 當有多個執行緒存取共用資源而不使資源被破壞時。
在WIN32中,同步機制 機製主要有以下幾種:
- 臨界區(Critical Section):通過對多執行緒的序列化來存取公共資源或一段程式碼,速度快,適合控制數據存取。
- 事件(Event):用來通知執行緒有一些事件已發生,從而啓動後繼任務的開始。
- 號志(Semaphore):爲控制一個具備有限數量使用者資源而設計。
- 互斥量(Mutex):爲協調一起對一個共用資源的單獨存取而設計的。
9.3.1 臨界區
臨界區(Critical Section)是一段獨佔對某些共用資源存取的程式碼,在任意時刻只允許一個執行緒對共用資源進行存取。如果有多個執行緒試圖同時存取臨界區,那麼在有一個執行緒進入後其他所有試圖存取此臨界區的執行緒將被掛起,並一直持續到進入臨界區的執行緒離開。臨界區在被釋放後,其他執行緒可以繼續搶佔,並以此達到用原子方式操作共用資源的目的。
臨界區在使用時以CRITICAL_SECTION結構物件保護共用資源,並分別用EnterCriticalSection()和LeaveCriticalSection()函數去標識和釋放一個臨界區。所用到的CRITICAL_SECTION結構物件必須經過InitializeCriticalSection()的初始化後才能 纔能使用,而且必須確保所有執行緒中的任何試圖存取此共用資源的程式碼都處在此臨界區的保護之下。否則臨界區將不會起到應有的作用,共用資源依然有被破壞的可能。
#include "stdafx.h"
#include<windows.h>
#include<iostream>
using namespace std;
int number = 1; //定義全域性變數
CRITICAL_SECTION Critical; //定義臨界區控制代碼
unsigned long __stdcall ThreadProc1(void* lp)
{
while (number < 100)
{
EnterCriticalSection(&Critical);
cout << "thread 1 :"<<number << endl;
++number;
_sleep(100);
LeaveCriticalSection(&Critical);
}
return 0;
}
unsigned long __stdcall ThreadProc2(void* lp)
{
while (number < 100)
{
EnterCriticalSection(&Critical);
cout << "thread 2 :"<<number << endl;
++number;
_sleep(100);
LeaveCriticalSection(&Critical);
}
return 0;
}
int main()
{
InitializeCriticalSection(&Critical); //初始化臨界區物件
CreateThread(NULL, 0, ThreadProc1, NULL, 0, NULL);
CreateThread(NULL, 0, ThreadProc2, NULL, 0, NULL);
Sleep(10*1000);
system("pause");
return 0;
}
9.3.2 事件
事件物件能夠通過通知操作的方式來保持執行緒的同步,並且能夠實現不同進程中的執行緒同步操作。事件可以處於激發狀態(signaled or true)或未激發狀態(unsignal or false)。根據狀態變遷方式的不同,事件可分爲兩類:
- 手動設定:這種物件只可能用程式手動設定,在需要該事件或者事件發生時,採用SetEvent及ResetEvent來進行設定。
- 自動恢復:一旦事件發生並被處理後,自動恢復到沒有事件狀態,不需要再次設定。
使用」事件」機制 機製應注意以下事項:
- 如果跨進程存取事件,必須對事件命名,在對事件命名的時候,要注意不要與系統名稱空間中的其它全域性命名物件衝突;
- 事件是否要自動恢復;
- 事件的初始狀態設定。
#include "stdafx.h"
#include<windows.h>
#include<iostream>
using namespace std;
int number = 1; //定義全域性變數
HANDLE hEvent; //定義事件控制代碼
unsigned long __stdcall ThreadProc1(void* lp)
{
while (number < 100)
{
WaitForSingleObject(hEvent, INFINITE); //等待物件爲有信號狀態
cout << "thread 1 :"<<number << endl;
++number;
_sleep(100);
SetEvent(hEvent);
}
return 0;
}
unsigned long __stdcall ThreadProc2(void* lp)
{
while (number < 100)
{
WaitForSingleObject(hEvent, INFINITE); //等待物件爲有信號狀態
cout << "thread 2 :"<<number << endl;
++number;
_sleep(100);
SetEvent(hEvent);
}
return 0;
}
int main()
{
CreateThread(NULL, 0, ThreadProc1, NULL, 0, NULL);
CreateThread(NULL, 0, ThreadProc2, NULL, 0, NULL);
hEvent = CreateEvent(NULL, FALSE, TRUE, "event");
Sleep(10*1000);
system("pause");
return 0;
}
由於event物件屬於內核物件,故進程B可以呼叫OpenEvent函數通過物件的名字獲得進程A中event物件的控制代碼,然後將這個控制代碼用於ResetEvent、SetEvent和WaitForMultipleObjects等函數中。此法可以實現一個進程的執行緒控制另一進程中執行緒的執行,例如:
HANDLE hEvent=OpenEvent(EVENT_ALL_ACCESS,true,"MyEvent");
ResetEvent(hEvent);
9.3.3 號志
號志物件對執行緒的同步方式和前面幾種方法不同,信號允許多個執行緒同時使用共用資源,但是需要限制在同一時刻存取此資源的最大執行緒數目。
用CreateSemaphore()建立號志時即要同時指出允許的最大資源計數和當前可用資源計數。一般是將當前可用資源計數設定爲最大資源計數,每增加一個執行緒對共用資源的存取,當前可用資源計數就會減1,只要當前可用資源計數是大於0的,就能夠發出號志信號。但是當前可用計數減小到0時則說明當前佔用資源的執行緒數已達到了所允許的最大數目,不能在允許其他執行緒的進入,此時的號志信號將無法發出。執行緒在處理完共用資源後,應在離開的同時通過ReleaseSemaphore()函數將當前可用資源計數加1。在任何時候當前可用資源計數決不可能大於最大資源計數。
號志包含的幾個操作原語:
- CreateSemaphore() 建立一個號志
- OpenSemaphore() 開啓一個號志
- ReleaseSemaphore() 釋放號志
- WaitForSingleObject() 等待號志
#include "stdafx.h"
#include<windows.h>
#include<iostream>
using namespace std;
int number = 1; //定義全域性變數
HANDLE hSemaphore; //定義號志控制代碼
unsigned long __stdcall ThreadProc1(void* lp)
{
long count;
while (number < 100)
{
WaitForSingleObject(hSemaphore, INFINITE); //等待號志爲有信號狀態
cout << "thread 1 :"<<number << endl;
++number;
_sleep(100);
ReleaseSemaphore(hSemaphore, 1, &count);
}
return 0;
}
unsigned long __stdcall ThreadProc2(void* lp)
{
long count;
while (number < 100)
{
WaitForSingleObject(hSemaphore, INFINITE); //等待號志爲有信號狀態
cout << "thread 2 :"<<number << endl;
++number;
_sleep(100);
ReleaseSemaphore(hSemaphore, 1, &count);
}
return 0;
}
int main()
{
hSemaphore = CreateSemaphore(NULL, 1, 100, "sema");
CreateThread(NULL, 0, ThreadProc1, NULL, 0, NULL);
CreateThread(NULL, 0, ThreadProc2, NULL, 0, NULL);
Sleep(10*1000);
system("pause");
return 0;
}
9.3.4 互斥量
採用互斥物件機制 機製。 只有擁有互斥物件的執行緒纔有存取公共資源的許可權,因爲互斥物件只有一個,所以能保證公共資源不會同時被多個執行緒存取。互斥不僅能實現同一應用程式的公共資源安全共用,還能實現不同應用程式的公共資源安全共用。
互斥量包含的幾個操作原語:
- CreateMutex() 建立一個互斥量
- OpenMutex() 開啓一個互斥量
- ReleaseMutex() 釋放互斥量
- WaitForMultipleObjects() 等待互斥量物件
#include "stdafx.h"
#include<windows.h>
#include<iostream>
using namespace std;
int number = 1; //定義全域性變數
HANDLE hMutex; //定義互斥物件控制代碼
unsigned long __stdcall ThreadProc1(void* lp)
{
while (number < 100)
{
WaitForSingleObject(hMutex, INFINITE);
cout << "thread 1 :"<<number << endl;
++number;
_sleep(100);
ReleaseMutex(hMutex);
}
return 0;
}
unsigned long __stdcall ThreadProc2(void* lp)
{
while (number < 100)
{
WaitForSingleObject(hMutex, INFINITE);
cout << "thread 2 :"<<number << endl;
++number;
_sleep(100);
ReleaseMutex(hMutex);
}
return 0;
}
int main()
{
hMutex = CreateMutex(NULL, false, "mutex"); //建立互斥物件
CreateThread(NULL, 0, ThreadProc1, NULL, 0, NULL);
CreateThread(NULL, 0, ThreadProc2, NULL, 0, NULL);
Sleep(10*1000);
system("pause");
return 0;
}
9.4 C++中的幾種鎖
在9.3.4中我們講到了互斥量,其中CreateMutex等是Win32 api函數,而本節要介紹的std :: mutex來自C++標準庫。
在C++11中執行緒之間的鎖有:互斥鎖、條件鎖、自旋鎖、讀寫鎖、遞回鎖。
9.4.1 互斥鎖
互斥鎖是一種簡單的加鎖的方法來控制對共用資源的存取。
通過std::mutex可以方便的對臨界區域加鎖,std::mutex類定義於mutex標頭檔案,是用於保護共用數據避免從多個執行緒同時存取的同步原語,它提供了lock、try_lock、unlock等幾個介面。使用方法如下:
std::mutex mtx;
mtx.lock()
do_something...; //共用的數據
mtx.unlock();
mutex的lock和unlock必須成對呼叫,lock之後忘記呼叫unlock將是非常嚴重的錯誤,再次lock時會造成死鎖。
此時可以使用類別範本std::lock_guard,通過RAII機制 機製在其作用域內佔有mutex,當程式流程離開建立lock_guard物件的作用域時,lock_guard物件被自動銷燬並釋放mutex。lock_guard構造時還可以傳入一個參數adopt_lock或者defer_lock。adopt_lock表示是一個已經鎖上了鎖,defer_lock表示之後會上鎖的鎖。
std::mutex mtx;
std::lock_guard<std::mutex> guard(mtx);
do_something...; //共用的數據
lock_guard類最大的缺點也是簡單,沒有給程式設計師提供足夠的靈活度,因此C++11定義了另一個unique_guard類。這個類和lock_guard類似,也很方便執行緒對互斥量上鎖,但它提供了更好的上鎖和解鎖控制,允許延遲鎖定、鎖定的有時限嘗試、遞回鎖定、所有權轉移和與條件變數一同使用。
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::unique_lock
#include <vector>
std::mutex mtx; // mutex for critical section
std::once_flag flag;
void print_block (int n, char c) {
//unique_lock有多組建構函式, 這裏std::defer_lock不設定鎖狀態
std::unique_lock<std::mutex> my_lock (mtx, std::defer_lock);
//嘗試加鎖, 如果加鎖成功則執行
//(適合定時執行一個job的場景, 一個執行緒執行就可以, 可以用更新時間戳輔助)
if(my_lock.try_lock()){
for (int i=0; i<n; ++i)
std::cout << c;
std::cout << '\n';
}
}
void run_one(int &n){
std::call_once(flag, [&n]{n=n+1;}); //只執行一次, 適合延遲載入; 多執行緒static變數情況
}
int main () {
std::vector<std::thread> ver;
int num = 0;
for (auto i = 0; i < 10; ++i){
ver.emplace_back(print_block,50,'*');
ver.emplace_back(run_one, std::ref(num));
}
for (auto &t : ver){
t.join();
}
std::cout << num << std::endl;
return 0;
}
unique_lock比lock_guard使用更加靈活,功能更加強大,但使用unique_lock需要付出更多的時間、效能成本。
9.4.2 條件鎖
條件鎖就是所謂的條件變數,當某一執行緒滿足某個條件時,可以使用條件變數令該程式處於阻塞狀態;一旦該條件狀態發生變化,就以「號志」的方式喚醒一個因爲該條件而被阻塞的執行緒。
最爲常見就是線上程池中,起初沒有任務時任務佇列爲空,此時執行緒池中的執行緒因爲「任務佇列爲空」這個條件處於阻塞狀態。一旦有任務進來,就會以號志的方式喚醒一個執行緒來處理這個任務。
- 標頭檔案:<condition_variable>
- 型別:std::condition_variable(只與std::mutex一起工作)、std::condition_variable_any(可與符合類似互斥元的最低標準的任何東西一起工作)。
std::deque<int> q;
std::mutex mu;
std::condition_variable cond;
void function_1() //生產者
{
int count = 10;
while (count > 0)
{
std::unique_lock<std::mutex> locker(mu);
q.push_front(count);
locker.unlock();
cond.notify_one(); // Notify one waiting thread, if there is one.
std::this_thread::sleep_for(std::chrono::seconds(1));
count--;
}
}
void function_2() //消費者
{
int data = 0;
while (data != 1)
{
std::unique_lock<std::mutex> locker(mu);
while (q.empty())
cond.wait(locker); // Unlock mu and wait to be notified
data = q.back();
q.pop_back();
locker.unlock();
std::cout << "t2 got a value from t1: " << data << std::endl;
}
}
int main()
{
std::thread t1(function_1);
std::thread t2(function_2);
t1.join();
t2.join();
return 0;
}
上面是一個生產者-消費者模型,軟體開啓後,消費者執行緒進入回圈,在回圈裡獲取鎖,如果消費品佇列爲空則wait,wait會自動釋放鎖;此時消費者已經沒有鎖了,在生產者執行緒裡,獲取鎖,然後往消費品佇列生產產品,釋放鎖,然後notify告知消費者退出wait,消費者重新獲取鎖,然後從佇列裡取消費品。
9.4.3 自旋鎖
當發生阻塞時,互斥鎖會讓CPU去處理其他的任務,而自旋鎖則會讓CPU一直不斷回圈請求獲取這個鎖。由此可見「自旋鎖」是比較耗費CPU的。在C++中我們可以通過原子操作實現自旋鎖:
//使用std::atomic_flag的自旋鎖互斥實現
class spinlock_mutex{
private:
std::atomic_flag flag;
public:
spinlock_mutex():flag(ATOMIC_FLAG_INIT) {}
void lock()
{
while(flag.test_and_set(std::memory_order_acquire));
}
void unlock()
{
flag.clear(std::memory_order_release);
}
}
9.4.4 讀寫鎖
說到讀寫鎖我們可以藉助於「讀者-寫者」問題進行理解。
計算機中某些數據被多個進程共用,對數據庫的操作有兩種:一種是讀操作,就是從數據庫中讀取數據不會修改數據庫中內容;另一種就是寫操作,寫操作會修改數據庫中存放的數據。因此可以得到我們允許在數據庫上同時執行多個「讀」操作,但是某一時刻只能在數據庫上有一個「寫」操作來更新數據。這就是一個簡單的讀者-寫者模型。
標頭檔案:boost/thread/shared_mutex.cpp
型別:boost::shared_lock、boost::shared_mutex
shared_mutex比一般的mutex多了函數lock_shared() / unlock_shared(),允許多個(讀者)執行緒同時加鎖和解鎖;而shared_lock則相當於共用版的lock_guard。對於shared_mutex使用lock_guard或unique_lock就可以達到寫者執行緒獨佔鎖的目的。
讀寫鎖的特點:
- 如果一個執行緒用讀鎖鎖定了臨界區,那麼其他執行緒也可以用讀鎖來進入臨界區,這樣可以有多個執行緒並行操作。這個時候如果再用寫鎖加鎖就會發生阻塞。寫鎖請求阻塞後,後面繼續有讀鎖來請求時,這些後來的讀鎖都將會被阻塞。這樣避免讀鎖長期佔有資源,防止寫鎖飢餓。
- 如果一個執行緒用寫鎖鎖住了臨界區,那麼其他執行緒無論是讀鎖還是寫鎖都會發生阻塞。
9.4.5 遞回鎖
遞回鎖又稱可重入鎖,在同一個執行緒在不解鎖的情況下,可以多次獲取鎖定同一個遞回鎖,而且不會產生死鎖。遞回鎖用起來固然簡單,但往往會隱藏某些程式碼問題。比如呼叫函數和被呼叫函數以爲自己拿到了鎖,都在修改同一個物件,這時就很容易出現問題。
9.5 C++中的原子操作
9.5.1 atomic模版函數
爲了避免多個執行緒同時修改全域性變數,C++11除了提供互斥量mutex這種方法以外,還提供了atomic模版函數。使用atomic可以避免使用鎖,而且更加底層,比mutex效率更高。
#include <thread>
#include <iostream>
#include <vector>
#include <atomic>
using namespace std;
void func(int& counter)
{
for (int i = 0; i < 100000; ++i)
{
++counter;
}
}
int main()
{
//atomic<int> counter(0);
atomic_int counter(0); //新建一個整型原子counter,將counter初始化爲0
//int counter = 0;
vector<thread> threads;
for (int i = 0; i < 10; ++i)
{
threads.push_back(thread(func, ref(counter)));
}
for (auto& current_thread : threads)
{
current_thread.join();
}
cout << "Result = " << counter << '\n';
return 0;
}
爲了避免多個執行緒同時修改了counter這個數導致出現錯誤,只需要把counter的原來的int型,改爲atomic_int型就可以了,非常方便,也不需要用到鎖。
9.5.2 std::atomic_flag
std::atomic_flag是一個原子型的布爾變數,只有兩個操作:
1)test_and_set,如果atomic_flag 物件已經被設定了,就返回True,如果未被設定,就設定之然後返回False
2)clear,把atomic_flag物件清掉
注意這個所謂atomic_flag物件其實就是當前的執行緒。如果當前的執行緒被設定成原子型,那麼等價於上鎖的操作,對變數擁有唯一的修改權。呼叫clear就是類似於解鎖。
下面 下麪先看一個簡單的例子,main() 函數中建立了 10 個執行緒進行計數,率先完成計數任務的執行緒輸出自己的 ID,後續完成計數任務的執行緒不會輸出自身 ID:
#include <iostream> // std::cout
#include <atomic> // std::atomic, std::atomic_flag, ATOMIC_FLAG_INIT
#include <thread> // std::thread, std::this_thread::yield
#include <vector> // std::vector
std::atomic<bool> ready(false); // can be checked without being set
std::atomic_flag winner = ATOMIC_FLAG_INIT; // always set when checked
void count1m(int id)
{
while (!ready) {
std::this_thread::yield();
} // 等待主執行緒中設定 ready 爲 true.
for (int i = 0; i < 1000000; ++i) {
} // 計數.
// 如果某個執行緒率先執行完上面的計數過程,則輸出自己的 ID.
// 此後其他執行緒執行 test_and_set 是 if 語句判斷爲 false,
// 因此不會輸出自身 ID.
if (!winner.test_and_set()) {
std::cout << "thread #" << id << " won!\n";
}
};
int main()
{
std::vector<std::thread> threads;
std::cout << "spawning 10 threads that count to 1 million...\n";
for (int i = 1; i <= 10; ++i)
threads.push_back(std::thread(count1m, i));
ready = true;
for (auto & th:threads)
th.join();
return 0;
}
再來一個例子:
#include <iostream>
#include <atomic>
#include <vector>
#include <thread>
#include <sstream>
std::atomic_flag lock = ATOMIC_FLAG_INIT; //初始化原子flag
std::stringstream stream;
void append_number(int x)
{
while(lock.test_and_set()); //如果原子flag未設定,那麼返回False,就繼續後面的程式碼。否則一直返回True,就一直停留在這個回圈。
stream<<"thread#" <<x<<'\n';
lock.clear(); //去除flag的物件
}
int main()
{
std::vector<std::thread> threads;
for(int i=0;i<10;i++)
threads.push_back(std::thread(append_number, i));
for(auto& th:threads)
th.join();
std::cout<<stream.str()<<'\n';
}
9.6 相關面試題
Q:C++怎麼保證執行緒安全
A:
Q:悲觀鎖和樂觀鎖
A:悲觀鎖:悲觀鎖是就是悲觀思想,即認爲讀少寫多,遇到併發寫的可能性高,每次去拿數據的時候都認爲別人會修改,所以每次在讀寫數據的時候都會上鎖,這樣別人想讀寫這個數據就會 block 直到拿到鎖。
樂觀鎖:樂觀鎖是一種樂觀思想,即認爲讀多寫少,遇到併發寫的可能性低,每次去拿數據的時候都認爲別人不會修改,所以不會上鎖,但是在更新的時候會判斷一下在此期間別人有沒有去更新這個數據,採取在寫時先讀出當前版本號,然後加鎖操作(比較跟上一次的版本號,如果一樣則更新),如果失敗則要重複【讀 - 比較 - 寫】的操作。
Q:什麼是死鎖
A:所謂死鎖是指多個執行緒因競爭資源而造成的一種僵局(互相等待),若無外力作用,這些進程都將無法向前推進。
Q:死鎖形成的必要條件
A:
產生死鎖必須同時滿足以下四個條件,只要其中任一條件不成立,死鎖就不會發生:
- 互斥條件:進程要求對所分配的資源(如印表機)進行排他性控制,即在一段時間內某 資源僅爲一個進程所佔有。此時若有其他進程請求該資源,則請求進程只能等待。
- 不剝奪條件:進程所獲得的資源在未使用完畢之前,不能被其他進程強行奪走,即只能 由獲得該資源的進程自己來釋放(只能是主動釋放)。
- 請求和保持條件:進程已經保持了至少一個資源,但又提出了新的資源請求,而該資源 已被其他進程佔有,此時請求進程被阻塞,但對自己已獲得的資源保持不放。
- 回圈等待條件:存在一種進程資源的回圈等待鏈,鏈中每一個進程已獲得的資源同時被 鏈中下一個進程所請求。即存在一個處於等待狀態的進程集合 {Pl, P2, …, pn},其中 Pi 等 待的資源被 P (i+1) 佔有(i=0, 1, …, n-1),Pn 等待的資源被 P0 佔有
Q:什麼是活鎖
A:活鎖和死鎖在表現上是一樣的兩個執行緒都沒有任何進展,但是區別在於:死鎖,兩個執行緒都處於阻塞狀態,而活鎖並不會阻塞,而是一直嘗試去獲取需要的鎖,不斷的 try,這種情況下執行緒並沒有阻塞所以是活的狀態,我們檢視執行緒的狀態也會發現執行緒是正常的,但重要的是整個程式卻不能繼續執行了,一直在做無用功。
Q:公平鎖與非公平鎖
A:公平鎖:是指多個執行緒在等待同一個鎖時,必須按照申請鎖的先後順序來一次獲得鎖。
非公平鎖:理解了公平鎖,非公平鎖就很好理解了,它無非就是不用排隊,當餐廳裡的人出來後將鑰匙往地上一扔,誰搶到算誰的。