c++伺服器開發
2020-08-12 16:05:12
本文章主要針對c/c++初學者、初中級開發者和意在轉型c++伺服器研發的同學們,對基礎知識和進階路線做了詳細的介紹。
文章目錄
- c/c++伺服器開發
- <注>:在恰當的場合使用恰當的特性
c/c++伺服器開發
c語言
宏定義
touch tmp
cpp -dM ./tmp
cpp -dM ./dummy.hxx | less # 檢視全部系統宏
- 1
- 2
- 3
斷言
- C/C++程式設計師可以把assert看成一個在任何系統狀態下都可以安全使用的無害測試手段,assert(斷言)不是函數,而是宏。
- 如果正確使用了斷言assert,則若程式在assert處終止了,並不是說含有該assert的函數有錯誤,而是呼叫者出錯了,assert在偵錯的時候可以幫助我們找到發生錯誤的原因。
例如:assert(p != NULL);
- 1
- 建議:在編寫函數時,要進行反覆 反復的考察,並且自問:「我打算做哪些假定?」,可能會隱藏的錯誤,當進行放錯誤設計時,如果「不可能發生」的事情的確發生了,則要使用斷言進行報警。
位元組對齊
c++語言
c++初級
c++中/高階——c++標準庫
- ios:抽象基礎類別
- istream:通用輸入流和其他輸入流的基礎類別
- ostream:通用輸出流和其他輸出流的基礎類別
- iostream:通用輸入輸出流和其他輸入輸出流的基礎類別
- ifstream:輸入檔案流類
- ofstream:輸出檔案流類
- fstream:輸入輸出檔案流類
- istrstream:輸入字串流類
- ostrstream:輸出字串流類
- strstream:輸入輸出字串流類
- 數據結構
- vector: 每個元素在記憶體上是連續的,支援高效遍歷、尾端插入和刪除;
(1)特點:
- 動態陣列,在堆中分配記憶體,即使大小減小,記憶體也不會釋放;如果新值 > 當前大小,會再分配記憶體;
- 記憶體的動態增長,首地址不變;
- 地址連續的順序序列;
- 能夠感知記憶體分配器的(Allocator-aware):
vector使用一個記憶體分配器物件來動態的處理儲存需求;
- 1
- 2
- 3
- 4
- 5
- 6
- list: 元素地址不連續,具有雙鏈表結構,支援高效的隨機插入/刪除;
(1)特點:
- 線性雙向鏈表結構,有若幹節點,每個節點包括一個資訊塊、一個前驅指針和一個後繼指針;
- 不支援[]操作符和at()函數;
- 相對於vector,佔用更多記憶體;(因爲每個節點至少包含2個指針)
- 1
- 2
- 3
- 4
- map: 關聯容器,提供一對一的數據處理能力;
(1)特點:
- map內部自建一顆紅黑樹(一種非嚴格意義上的平衡二元樹)
這棵樹具有對數據自動排序的功能,所以在map內部所有的數據都是有序的;
- 根據key值快速查詢記錄,查詢的複雜度基本是log(n),例如:
如果有1000個記錄,最多查詢10次;
如果有1000000個記錄,最多查詢20次;
- 1
- 2
- 3
- 4
- 5
- 6
- 佇列:
(1)queue: 是一個容器適配器型別
- 特點:
a.佇列是一個容器適配器型別,被設計成用來執行FIFO(先進先出)場景;
- 佇列在多執行緒中的應用:
a.生產——消費模型,實現解耦;
(2)dequeue: 每個元素在記憶體上是連續的,支援高效遍歷、首/尾端插入和刪除;
- 雙端佇列的數據被表示爲一個分段陣列,容器中的元素分段存放在一個大小固定的陣列中;
- 容器需要維護一個存放這些陣列首地址的索引陣列;
- 特點:
a.首地址的索引陣列地址連續,雙端佇列本質上每一段的地址不連續;
(3)priority_queue:優先佇列
- 具有佇列的所有特性,包括基本操作,在這基礎上,增加了一個內部的排序,本質是一個堆實現的(預設是大頂堆)
- 特點:
a.佇列中的最大元素總是位於首部(出隊時,是將當前佇列中最大的元素出隊)
b.元素的比較規則預設按照元素值由大到小排序(可以過載'<'來重新定義比較規則)
c.在預設的優先佇列中,優先順序高的先出隊(在預設的int型中,先出隊的爲最大的數)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 概念:
(1)函數物件:
- 首先,是一個物件:即某個類的範例;
- 其次,函數物件的行爲和函數一致:即可以像呼叫函數一樣來使用函數物件(參數傳遞、返回值等),這種方式是通過過載類的'()'操作符實現的;
(2)過載'()'操作符的類,它的物件叫做「函數物件」,即它是類似於函數的物件(可以像函數一樣呼叫),稱爲「仿函數」;
<注>:函數物件(仿函數)是一個類,不是一個函數;
(3)術語:
- 一元仿函數:過載'()'操作符有一個參數;
- 二元仿函數:過載'()'操作符有兩個參數;
- 一元謂詞: 返回值是bool型別的函數物件或普通函數,有一個參數;
- ...
(4)STL內建的函數物件 #include <functional>
- 算數類函數物件:
- 關係運算類:
- 邏輯運算類:
<注>:用這些類的物件當做函數使用時,用法與函數完全相同;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
函數物件的作用和應用場景
- 迭代器(iterator):是一種抽象的設計理念,通過迭代器可以在不瞭解容器內部原理的情況下遍歷容器;
- 抽象思想的經典應用:迭代器作爲容器(vector、list等)與STL演算法的「粘黏劑」,只要容器提供迭代器的介面,同一套演算法程式碼可以利用在完全不同的容器中;
- 實現:
(1)內部構成 :
- 提供一個遍歷容器內部所有元素的介面,因此內部必須儲存一個與容器相關聯的指針;
- 過載常用的運算子來方便遍歷(其中最重要的是'*'、'->'和'++');
-
- 1
- 2
- 3
- 4
c++精通(c++11/14/17新特性)
- c++空指針
- c的NULL與c++的nullptr:
(1)區別:
- NULL在c++中,被明確定義爲整數0;
- NULL在c中,被定義成 ((void*)0);(即:NULL實際上是一個void*指針);
(2)特點:
- nullptr用於標識空指針,是std::nullptr_t型別的(constexpr)變數;
- nullptr可以轉換成任何指針型別和bool型別;(主要爲了相容普通指針可以作爲條件判斷語句的寫法)
- nullptr不能被轉換爲整數;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- constexpr修飾的是編譯時期的常數;
- const與constexpr的區別:
(1)const爲執行時常數,constexpr爲編譯時常數(與#define作用相同);
const和constexpr修飾的都是read-only的值,但:
- constexpr在程式執行前已經得到了具體的值;
- const在程式執行過程中,得到的具體值;
- 1
- 2
- 3
- 4
- constexpr常數表達式的要求:
並非所有的函數都有資格成爲常數表達式函數,具體要求如下:
(1)函數體只有單一的return返回語句;
(2)函數必須有返回值(即,不能爲void函數);
(3)在使用前必須已有定義;
(4)return返回語句表達式中不能使用非常數表達式的函數、全域性數據,並且必須是一個常數表達式;
- 1
- 2
- 3
- 4
- 5
- constexpr的優勢:
(1)是一種很強的約束,更好的保證程式的正確語意不被破壞;
(2)編譯器可以在編譯時對constexpr的程式碼進行非常大的優化,比如:將用到constexpr表達式都直接替換成最終結果;
(3)相比宏定義來說,沒有額外開銷,但更安全可靠;
- 1
- 2
- 3
- c++98 auto:(極少使用)
- c++11 auto:
(1)特點:
- auto可以在宣告變數的時候,根據變數初始值型別,自動推斷匹配的型別;
類似的關鍵字還有decltype;
可以使用typeid(i).name()獲得變數的型別;
- auto的自動型別推斷髮生在編譯時期,所以使用auto並不會造成程式執行時的效率問題;
(2)用途:
- 用於代替冗長複雜、變數使用範圍專一的變數宣告;
- 在定義模板函數時,用於宣告以來模板參數的變數型別;
- 用於模板函數依賴於模板參數的返回值
<注>:第二點和第三點是因爲模板參數的型別是可變的,無法在函數內部形成統一的變數型別;
(3)注意事項:
- auto變數必須在定義時初始化,這點類似與const;
- 定義在一個auto序列的變數,必須始終推導成同一型別;
- 如果初始化表達式是參照,則去除參照語意;
- 如果初始化表達式爲const或volatile(或者兩者兼有),則去除const/volatile語意;
- 如果auto關鍵字帶上&號,則不去除const語意;
- 初始化表達式爲陣列時,auto關鍵字推導型別爲指針;
- 若表達式爲陣列且auto帶上&號,則推導型別爲陣列型別;
- 函數參數或模板參數不能被宣告爲auto;(c++11錯誤,c++14可以使用auto參數)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 與auto關鍵字一樣,用於進行編譯時型別推導,它與auto的區別是:
- decltype的型別推導不像auto一樣是從變數宣告的初始化表達式獲得變數的型別,而是總是以一個普通表達式作爲參數,返回該表達式的型別;
- decltype不會對錶達式進行求值;
- 1
- 2
- decltype使用方法:
- 推導出表達式型別;
int i = 4;
decltype(i) a; // 推導結果爲int,宣告a變數的型別爲int;
- 與using/typedef合用,用於定義型別;
using size_t = decltype(sizeof(0)); // sizeof(a)的返回值爲size型別
- 重用匿名型別;
struct {
int d;
double b;
}anon_s;
decltype(anon_s) as; // 定義了一個上面匿名的結構體;
- 泛型程式設計中結合auto,用於追蹤函數的返回值型別;(decltype的最大用途)
template<typename _Tx, typename _Ty>
auto multiply(_Tx x, _Ty y)->decltype(_Tx*_Ty) {
return x*y;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- decltype推導的四條規則:
(1)如果e是一個沒有帶括號的標記符表達式或者類成員存取表達式,那麼decltype(e)就是e所命名的實體的型別;
此外,如果e是一個被過載的函數,則會導致編譯錯誤;
(2)否則,假設e的型別是T,如果e是一個將亡值,那麼decltype(e)爲T&&;
(3)否則,假設e的型別是T,如果e是一個左值,那麼decltype(e)爲T&;
(4)否則,假設e的型別是T,則decltype(e)爲T;
- 1
- 2
- 3
- 4
- 5
- string、array和所有的STL容器,都可以被新的區間迭代方式迭代;
- 如果想讓自己的數據結構使用區間迭代語法,則需要:
- 這個數據結構必須要有begin()和end()方法,成員方法和獨立函數都可以,這兩個方法分別返回開始和結束的迭代器;
- 迭代器支援'*'操作符、'!='操作符、'++'方法(字首形式、成員函數和獨立函數都可);
實現這5個函數,就可以有一個支援區間迭代的數據結構。
begin()和end()可以是非成員函數,甚至可以適配現有的數據結構,而不用實現STL風格的迭代器。
因此,需要做的就是建立自己的支援*、前++和!=的嗲帶起,並定義好自己的being()和end();
- 1
- 2
- 3
- 4
- 5
- 區間迭代可以與STL中的for_each有着同樣的效能;
- 模板函數的預設模板參數;
- 外部模板:是c++11中一個關於模板效能上的改進;
- lambda表達式本質上就是過載了()運算子的類,稱爲「functor」,即行爲像函數的類。因此,lambda表達式物件其實就是一個匿名的functor;
- 說明:
(1)構成:
- 一個標準的lambda表達式包括:
捕獲列表:捕獲外部變數列表;
值捕獲、參照捕獲和外部捕獲;
參數列表:形參列表;
mutable指示符:用來說明是否可以修改捕獲變數;
exception:異常設定;
尾置返回型別(->返回型別):返回型別;
函數體:函數體
[capture list](params list) mutable exception->return type {function body};
- 根據反彙編分析,lambda表達式中的程式碼是在一個單獨的函數中執行的,這個函數在呼叫時建立了自己的棧幀,而捕獲的變數在其他的棧幀中(雖然通過ebp可以進行棧幀回溯,但顯然是一種不合理的做法)。
(2)注意:
- 如果lambda表達式中忽略括號和形參列表,則相當於指定的函數沒有入參;
- lambda表達式中不能指定參數的預設值;
- 如果忽略返回值型別,則由編譯器做自動型別推斷;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 捕獲列表:由於lambda表達式在某函數內定義的,因此會希望其能使用函數內部的區域性變數,這時可以使用「捕獲列表」
- 值捕獲:
值捕獲和參數傳遞中的值傳遞類似,被捕獲的變數的值,在lambda表達式建立時通過值拷貝的方式傳入,因此隨後對該變數的修改不會影響lambda表達式中的值;
<注>:不能在lambda表達式中修改捕獲變數的值;
- 參照捕獲:
使用參照捕獲一個外部變數,需要在捕獲列表變數前面加上一個參照說明符&;
- 外部捕獲(隱式捕獲):
我們可以讓編譯器根據函數體中的程式碼來推斷需要捕獲哪些變數;
隱式捕獲有兩種方式:
[=]:表示以值捕獲的方式捕獲外部變數;
[&]:表示以參照捕獲的方式捕獲外部變數;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 說明:
c++11 std::function是一種通用、多型的函數封裝,它的範例可以對任何可以呼叫的目標實體進行儲存、複製和呼叫;
它也是對c++中現有的可呼叫實體的一種型別安全的包裝(相對來說,函數指針的呼叫不是型別安全的);
std::function是函數的容器,可以更加方便的將函數、函數指針作爲物件進行處理;
- 1
- 2
- 3
- 右值參照
- 左值和右值的區分標準:能否獲取地址:
- 左值:可以獲取地址的表達式,它能出現在賦值語句的左邊,對該表達式進行賦值;
但是修飾符const的出現,使得可以宣告如下識別符號,它可以獲取地址,但是沒辦法對其賦值:
const int& i = 10;
- 右值表示無法獲取地址的物件,有常數值、函數返回值、lambda表達式等;無法獲取地址,但不代表其不可改變,當定義了右值的右值參照時,就可以改變右值;
- 1
- 2
- 3
- 4
- c++11增加了右值參照,右值參照關聯到右值時,右值被儲存到特定位置,右值參照指向該特定位置:
即: 右值雖然無法獲取地址,但是右值參照是可以獲取地址的,該地址表示臨時物件的儲存位置:(臨時變數會參照關聯到右值時,右值被儲存到特定位置)
int && iii = 10;
- 1
- 2
- 右值參照和移動語意:
(1)說明:
- 在舊的c++中,出現了很多不必要的拷貝,因爲在某些情況下,物件拷貝完成後就銷燬了;
- c++11新標準,引入了移動操作,減少了很多複製操作,而右值參照正式爲了支援移動操作爲引入的新的參照型別;
(2)std::move()函數:
- 根據右值參照的語法規則,不能將右值參照系結到一個左值上,c++11引入右值參照,並且提供了std::move()函數,用來獲得系結到左值上的右值參照(即:爲右值參照系結到左值提供了可能)
- 該函數需要:#include <utility>
int &&iii = std::move(ii);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 右值參照的作用:
減少拷貝構造,賦值過載過程記憶體開闢拷貝的次數,提高執行速度;
- 1
- array:
- forward_list:
- unordered_map:
- unordered_set:
- unordered_multimap:
- unordered_multiset:
- tuple(元組):
- 理解智慧指針:
作用:方便管理堆記憶體;
三個層次:
- 較淺層面:
智慧指針利用一種叫「RAII」(資源獲取即初始化)的技術,對普遍的指針進行封裝,這使得智慧指針實質是一個物件,行爲表現卻像一個指針;
- 智慧指針的作用,是防止忘記呼叫delete釋放記憶體和程式異常的進入catch塊忘記釋放記憶體。另外指針的釋放時機也是非常有考究的,多次釋放同一個指針會造成程式崩潰,這些都可以通過智慧指針來避免;
- 智慧指針還有一個作用,是把值語意轉換成參照語意;
- 1
- 2
- 3
- 4
- 5
- 6
- 智慧指針的分類:c++11新特性,需要包含標頭檔案memory,有shared_ptr、unique_ptr和weak_ptr;
- shared_ptr:
a.特點:多個指針指向相同的物件;
b.shared_ptr內部使用參照計數,每一個shared_ptr的拷貝都指向相同的記憶體;
每使用一次,內部的參照計數加1,;每解構一次,內部的參照計數減1;
當計數爲0時,自動釋放記憶體;後來指向的物件參照計數加1,指向後來的物件;
c.拷貝和賦值:拷貝使得物件的參照計數加1,賦值使得原來物件的參照計數減1;
d.可以使用get()函數獲取原始指針;
e.陷阱:避免回圈參照:
shared_ptr的一個最大的陷阱就是回圈參照;
回圈參照會導致堆記憶體無法正確釋放,導致記憶體泄露(看weak_ptr);
- unique_ptr:
a.特點:唯一的擁有其所指物件,同一時刻只能有一個unique_ptr指向給定物件(禁止拷貝語意,只有移動語意來實現);
b.相比於原始指針unique_ptr用於其RAII的特性,使得在出現異常的情況下,動態資源能得到釋放;
c.unique_ptr指針本身的生命週期:從unique_ptr指針建立時開始,直到離開作用域;
離開作用域時,若其指向物件,則將其所指向的物件銷燬(預設使用delete操作符,使用者可以指定其他操作)。
d.unique_ptr指針與其所指物件的關係:
在智慧指針生命週期內,可以改變智慧指針所指物件,如:建立智慧指針時通過建構函式指定、通過reset方法重新指定、通過release方法釋放所有權、通過移動語意跳脫所有權;
- weak_ptr:
a.特點:是爲了配合shared_ptr而引入的一種智慧指針,因爲它不具有普通指針的行爲:
沒有過載operator*和->;
b.weak_ptr最大的作用在於:協助shared_ptr工作,像旁觀者那樣觀測資源的使用情況;
c.weak_ptr可以從一個shared_ptr或者另一個weak_ptr物件構造,獲得資源的觀測權(weak_ptr是shared_ptr的友元類(friend));
d.weak_ptr沒有共用資源,它的構造不會引起指針參照計數的增加;
e.使用weak_ptr的成員函數:
use_count()可以觀測資源的參照計數;
expired()的功能等價於use_count()==0,但是更快,表示被觀測的資源(即:shared_ptr管理的資源)已經不存在;
lock():weak_ptr重要的成員函數,它從被觀測的shared_ptr獲得一個可用的shared_ptr物件,從而操作資源。
但當expired()==true時,lock()函數將返回一個儲存空指針的shared_ptr;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 回圈參照問題:案例
- 所有的智慧指針都會過載->和*操作符;
- 對標準庫的擴充:
- std::thread
- std::mutex/std::unique_lock
- std::future/std::packaged_task
- std::condition_variable
- 1
- 2
- 3
- 4
多執行緒和執行緒池
進程和執行緒
- 進程是操作系統分配儲存資源的最小單元;
- 執行緒是程式執行、cpu排程的最小單元;
- 進程和執行緒
執行緒池原理:
I/O原理
socket網路程式設計
- c/c++網路程式設計,基本使用的是linux系統函數實現
linux系統函數
- 伺服器啓動流程:
- socket(): 建立一個socket,並設定地址描述、socket型別和協定;
- bind(): 系結socket,並設定系結的ip和埠;(伺服器一般設定爲INADDR_ANY)
- listen(): 設定監聽套介面,並設定監聽佇列的大小;
- accept(): 接受連線,並設定用戶端地址結構;
- read(): 接收數據,並設定接收快取區和大小;
- write(): 發送數據,並設定發送快取區和大小;
- 1
- 2
- 3
- 4
- 5
- 6
- 設定已建立socket的屬性:
setsockopt():
(1)用於任意型別、任意狀態套介面的設定。j儘管在不同協定層上存在選項,但本函數僅定義了最高的"高介面"層次上的選項。
(2)應用舉例:
- 設定呼叫close(socket)後,仍可繼續重用該socket。呼叫close(socket)一般不會立即關閉socket,而經歷TIME_WAIT的過程。
BOOL bReuseaddr = TRUE;
setsockopt( s, SOL_SOCKET, SO_REUSEADDR, ( const char* )&bReuseaddr, sizeof( BOOL ) );
- 如果要已經處於連線狀態的soket在呼叫closesocket()後強制關閉,不經歷TIME_WAIT的過程:
BOOL bDontLinger = FALSE;
setsockopt( s, SOL_SOCKET, SO_DONTLINGER, ( const char* )&bDontLinger, sizeof( BOOL ) );
- 在send(),recv()過程中有時由於網路狀況等原因,收發不能預期進行,可以設定收發時限:
int nNetTimeout = 1000; //1秒
//發送時限
setsockopt( socket, SOL_SOCKET, SO_SNDTIMEO, ( char * )&nNetTimeout, sizeof( int ) );
//接收時限
setsockopt( socket, SOL_SOCKET, SO_RCVTIMEO, ( char * )&nNetTimeout, sizeof( int ) );
- 在send()的時候,返回的是實際發送出去的位元組(同步)或發送到socket緩衝區的位元組(非同步);系統預設的狀態發送和接收一次爲8688位元組(約爲8.5K);在實際的過程中如果發送或是接收的數據量比較大,可以設定socket緩衝區,避免send(),recv()不斷的回圈收發:
// 接收緩衝區
int nRecvBufLen = 32 * 1024; //設定爲32K
setsockopt( s, SOL_SOCKET, SO_RCVBUF, ( const char* )&nRecvBufLen, sizeof( int ) );
//發送緩衝區
int nSendBufLen = 32*1024; //設定爲32K
setsockopt( s, SOL_SOCKET, SO_SNDBUF, ( const char* )&nSendBufLen, sizeof( int ) );
- 在發送數據的時,不執行由系統緩衝區到socket緩衝區的拷貝,以提高程式的效能:
int nZero = 0;
setsockopt( socket, SOL_SOCKET, SO_SNDBUF, ( char * )&nZero, sizeof( nZero ) );
- 在接收數據時,不執行將socket緩衝區的內容拷貝到系統緩衝區:
int nZero = 0;
setsockopt( s, SOL_SOCKET, SO_RCVBUF, ( char * )&nZero, sizeof( int ) );
- 一般在發送UDP數據報的時候,希望該socket發送的數據具有廣播特性:
BOOL bBroadcast = TRUE;
setsockopt( s, SOL_SOCKET, SO_BROADCAST, ( const char* )&bBroadcast, sizeof( BOOL ) );
- 在client連線伺服器過程中,如果處於非阻塞模式下的socket在connect()的過程中可以設定connect()延時,直到accpet()被呼叫(此設定只有在非阻塞的過程中有顯著的作用,在阻塞的函數呼叫中作用不大)
BOOL bConditionalAccept = TRUE;
setsockopt(s, SOL_SOCKET, SO_CONDITIONAL_ACCEPT, (const char*)&bConditionalAccept, sizeof( BOOL ) );
- 如果在發送數據的過程中send()沒有完成,還有數據沒發送,而呼叫了close(socket),以前一般採取的措施是shutdown(s,SD_BOTH),但是數據將會丟失。某些具體程式要求待未發送完的數據發送出去後再關閉socket,可通過設定讓程式滿足要求:
struct linger {
u_short l_onoff;
u_short l_linger;
};
struct linger m_sLinger;
m_sLinger.l_onoff = 1; //在呼叫close(socket)時還有數據未發送完,允許等待
// 若m_sLinger.l_onoff=0;則呼叫closesocket()後強制關閉
m_sLinger.l_linger = 5; //設定等待時間爲5秒
setsockopt( s, SOL_SOCKET, SO_LINGER, (const char*)&m_sLinger, sizeof(struct linger));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
多路I/O複用
- 同步和非同步: 描述的是」使用者執行緒「和」內核「的互動方式;
同步:指使用者執行緒發起I/O請求後,需要」等待「或」輪詢「內核I/O操作完成後才能 纔能繼續執行;
非同步:指使用者執行緒發起I/O請求後,仍可繼續執行,當內核I/O操作完成後會通知使用者執行緒,或呼叫使用者執行緒註冊的回撥函數;
- 1
- 2
- 阻塞和非阻塞: 描述的是」使用者執行緒「呼叫」內核I/O「操作的方式
阻塞:指I/O操作需要徹底完成後才能 纔能返回到使用者空間;
非阻塞:指I/O操作被呼叫後立即返回給使用者一個狀態值,無需等待I/O操作徹底完成;
- 1
- 2
- 同步阻塞I/O: 傳統I/O模型;
(1)特點:
- 使用者執行緒在內核進行I/O操作時被阻塞;
- 屬於請求應答式
(2)缺點:
- 使用者需要等待read將socket中的數據讀取到buffer後,才繼續處理接收的數據;
- 整個I/O請求過程中,使用者執行緒是被阻塞的,這導致使用者在發起I/O請求時,不能做任何事情,對cpu的資源利用率不夠;
- 1
- 2
- 3
- 4
- 5
- 6
- 同步非阻塞I/O: 預設建立的socket都是阻塞的,非阻塞I/O要求socket被設定成NONBLOCK;
(1)特點:
- 是在同步阻塞I/O基礎上,將socket設定爲NONBLOCK,這樣使用者執行緒可以在發起I/O請求後立即返回;
- 使用者執行緒發起I/O請求時立即返回,但並未讀取到任何數據,使用者執行緒需要不斷的發起I/O請求,直到數據到達後,才能 纔能真正讀取到數據,繼續執行;
(2)缺點:
- 使用者需要不斷的呼叫read,嘗試讀取socket中的數據;
- 整個I/O請求的過程中,雖然使用者執行緒每次發起I/O請求後可以立即返回,但是爲了等到數據,仍需要不斷的輪詢、重複請求,消耗了大量的cpu資源;
(3)一般很少直接使用這種模型,而是在其他I/O模型中使用非阻塞I/O這一特性;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- I/O多路複用:經典的Reactor設計模式,也被稱作「非同步阻塞I/O」,代表爲linux的epoll;
(1)特點:
- I/O多路複用是建立在內核提供的多路分離函數select()基礎之上;
- 使用select()函數可以避免同步非阻塞I/O模型中輪詢等待的問題;
- select函數與同步阻塞模型沒有太大區別,甚至新增了監視socket,以及呼叫select()函數的額外操作,效率更差;
但是,使用select()以後最大的優勢,就是使用者可以在一個執行緒內同時處理多個socket的I/O請求;
使用者可以註冊多個socket,然後不斷的呼叫select()讀取被啓用的socket,即:
可以達到在同一個執行緒內同時處理多個I/O請求的目的;
而在同步阻塞模型中,必須通過多執行緒方式才能 纔能達到這個目的;
(2)缺點:
- 雖然上述方式允許單執行緒內處理多個I/O請求,但是每個I/O請求過程還是阻塞的(在select()函數上阻塞),平均時間甚至比同步阻塞I/O模型還要長;
(3)如果使用者執行緒只註冊自己感興趣的socket或I/O請求,然後去做自己的事,等到數據到來時再進行處理,則可以提高CPU的利用率;
I/O多路複用模型使用了Reactor設計模式實現了這一機制 機製;
(4)Reactor設計模式:
通過Reactor的方式,可以將使用者執行緒輪詢I/O操作狀態的工作統一交給handle_events事件回圈進行處理;
使用者執行緒註冊事件處理器之後,可以繼續執行其他的工作(非同步過程),而Reactor執行緒負責呼叫內核的select()函數檢查socket狀態,當有socket被啓用時,則通知相應的使用者執行緒(或執行使用者執行緒的回撥函數),執行handle_event進行數據讀取、處理等工作;
(5)由於select()函數是阻塞的,因此多路I/O複用也被稱爲」非同步阻塞I/O模型「;(這裏的阻塞,指的是select()函數執行時執行緒被阻塞,而不是指socket)
(6)I/O多路複用是最常使用的I/O模型,但是其非同步程度還不夠」徹底「,因爲它使用會阻塞執行緒的select()系統呼叫,因此I/O多路複用只是非同步阻塞I/O,而不是真正的非同步I/O;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 非同步I/O: 經典的Proactor設計模式,也被稱作」非同步非阻塞I/O「;
真正的非同步I/O需要操作系統更強的支援;
(1)特點:
- 在I/O多路複用模型中,事件回圈將檔案控制代碼的狀態事件通知給使用者執行緒,由使用者執行緒自行讀取、處理數據;
而在非同步I/O模型中,當使用者執行緒收到通知時,數據已經被內核讀取完畢,並放在了使用者執行緒指定的緩衝區內,內核在I/O完成後通知使用者執行緒直接使用即可;
非同步I/O模型使用了Proactor設計模式實現了這一機制 機製;
(2)Proactor與Reactor的區別:
- Proactor和Reactor在結構上比較相似,不過在使用者使用方式上差別較大;
- Reactor模式中,使用者執行緒通過向Reactor物件註冊感興趣的事件監聽,然後事件觸發時呼叫事件處理常式;
- Proactor模式中,使用者執行緒間asyncchronousOperation(讀/寫等)、Proactor以及操作完成時的CompletionHandler註冊到asyncchronousOperationProcessor;
asyncchronousOperationProcessor使用Facade模式,提供了一組非同步操作API(讀/寫等)供使用者使用;
當使用者執行緒呼叫非同步API後,便繼續執行自己的任務;asyncchronousOperationProcessor會開啓獨立的內核執行緒執行非同步操作,實現真正的非同步;
當非同步I/O操作完成時,asyncchronousOperationProcessor將使用者執行緒與asyncchronousOperation一起註冊的Proactor和CompletionHandler取出,然後將ComletionHandler與I/O操作的結果數據一起轉發給Proactor,Proactor負責回撥每一個非同步操作事件完成處理常式handle_event;
- 雖然Proactor模式中每個非同步操作都可以系結一個Proactor物件,但是在一般系統中,Proactor實現爲Singleton模式,以便於集中化分發操作完成事件;
(3)相比I/O多路複用模型,非同步I/O並不很常用,不少高效能併發服務程式使用」I/O多路複用買模型+多執行緒任務處理「的架構基本可以滿足需求;
並且,目前操作系統對非同步I/O的支援並非特別完善,更多的採用I/O多路複用模型」模擬「(例如:boost::asio)非同步I/O的方式(I/O事件觸發時,不直接通知使用者執行緒,而是將數據讀寫完畢後,放到使用者指定的緩衝區中;)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- I/O多路複用:
I/O多路複用(又被稱爲「事件驅動」):
操作系統提供了一個功能,當某個socket可讀或可寫的時候,會發出一個通知。這樣當配合非阻塞的socket使用時,只有當系統通知了哪個描述符fd可讀了,才執行read操作,可以保證每次read都能讀到有效的數據,而不做僅僅返回-1和errno的無用功;
寫操作類似,操作系統通過select/poll/epoll等系統呼叫來實現,這些函數都可以同時監控多個描述符fd的讀寫就緒狀態;
這樣,多個描述符fd的I/O操作都能在一個執行緒內併發交替的完成,即:I/O多路複用;
這裏的「複用」指的是複用同一個執行緒。
- 1
- 2
- 3
- 4
- 5
- select:
select模型的原理、優點和缺點
(1)特點:
select系統呼叫的目的是:在一段指定時間內,監聽使用者感興趣的描述符fd上可讀、可寫和異常事件;
poll和select,都可以阻塞式的、同時探測一組支援非阻塞的IO裝置,直到某一個裝置觸發了事件或超過了指定的等待事件————即:他們的職責不是做I/O,而二十幫助呼叫者找到當前就緒的裝置;
(2)select優點:
- select是windows socket中最常見的模型,可以等待多個通訊端;
(3)select缺點:
- 每次呼叫select,都需要把fd集合,從使用者態拷貝到內核態,在拷貝大量fd時開銷很大;
- 同時每次呼叫select,都需要在內核遍歷傳遞進來的所有fd,在遍歷大量fd時開銷很大;
- select支援的檔案描述符數量小,預設只有1024;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
<核心>:epoll作爲select的linux的替代品,解決了selectfd_set的限制。效能優於select。
(1)特點:
epoll是linux下I/O多路複用介面select/poll的增強版本,它能顯著減少程式在大量併發連線中,只有少量活躍的情況下,系統CPU的利用率,原因如下:
a. 它不會複用檔案描述符fd集合來傳遞結果,而迫使開發者每次等待事件之前都必須重新準備要監聽的檔案描述符fd集合;
b. 在獲取事件時,它無須遍歷整個被監聽的描述符fd集合,而是隻要遍歷那些被內核I/O事件非同步喚醒而加入Ready佇列的描述符fd集合就行;
epoll除了提供select/poll的I/O事件的Level Triggered(電平觸發)外,還提供了Edge Triggered(邊沿觸發),這就使得使用者空間程式有可能快取I/O狀態,減少epoll_wait/epoll_pwait的呼叫,提高應用程式效率;
(2)epoll優點:
- 支援一個進程開啓大量的socket描述符;
- I/O效率不隨fd數目增加而線性下降;
- 內核微調;
(3)工作模式:epoll有2中工作方式:LT和ET;
- LT(預設工作方式):
同時支援block和non-block socket;
這種做法,內核告訴使用者執行緒檔案描述符fd是否就緒,然後執行緒可以對這個就緒的fd進行I/O操作;
如果不做任何操作,內核還會繼續通知。(只要有數據就不停的通知, 直到沒有數據了就不再通知了)
因此,這種模式程式設計出錯的可能性要小;
傳統的select/poll都是基於此;
- ET(高速工作方式):
只支援non-block socket;
這種做法,當描述符從未就緒變爲就緒時,內核通過epoll告訴使用者執行緒,然後它會假設執行緒知道檔案描述符已經就緒,並不會再爲那個檔案描述符發送更多的就緒通知,直到執行緒做了某些操作導致那個檔案描述符不再爲就緒狀態(比如:在發送、接收或接收請求、發送接收的數據少於一定量時,導致了一個EWOULDBLOCK錯誤);
但是,如果一直不對這個fd做I/O操作(從而導致它再次變成未就緒),內核不會發送更多的通知(only once);
不過在TCP協定中,ET模式的加速效果仍需要更多的benchmark(基準)確認;
(4)epoll介面:
epoll的介面非常簡單,共有三個函數:
- int epoll_create(int size);
建立一個epoll控制代碼,會佔用一個fd值,linux下檢視/proc/進程id/fd/,是能夠看到對應的fd的;
return: int epfd;
所以在使用完epoll後,必須呼叫close()關閉,否則可能導致fd被耗盡;
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll的事件註冊函數,它不同於select():
select是在監聽事件時告訴內核要監聽什麼型別的事件;
epoll是先註冊要監聽的事件型別;
- int epoll_wait(int epfd, struct epoll_event *event, int maxevents, int timeout);
等待事件的產生,類似於select()呼叫;
(5)epoll框架的使用方式:
前提:包含標頭檔案 #include <sys/epoll.h>
a. 通過epoll_create(int maxfds)來建立一個epoll控制代碼,maxfds爲epoll所支援的最大控制代碼數;
這個函數會返回一個新的epoll控制代碼,之後的所有操作都將通過這個控制代碼來進行;
在用完之後,需要呼叫close()來關閉這個epoll控制代碼;
b. 在使用者程式的網路主回圈中,每一幀的呼叫epoll_wait()來查詢所有的網路介面,看哪一個可讀,哪一個可寫;
基本的語法爲:nfds = epoll_wait(kdpfd, events, max_events, -1)
其中:
- kdpfd: 用epoll_create()建立後的控制代碼;
- events: 是一個epoll_event*的指針,當epoll_wait()函數操作成功後,events裏面將儲存所有的讀寫事件;
- max_events:是當前需要監聽的所有socket控制代碼數;
- timeout:是epoll_wait的超時,爲0時馬上返回,這裏-1表示一直等待,直到有事件返回;
一般情況下,如果網路主回圈是單獨的執行緒,可以用-1來等待,這樣可以保證效率;
如果主邏輯與網路主回圈是同一個執行緒的話,則可以用0來保證主回圈的效率;
c. epoll_wait()返回之後應該是一個回圈,遍歷所有的事件;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
數據庫
(1)主要區別:
- 儲存方式:
sql數據存在特定結構的表中;
nosql則更加靈活和可延伸,儲存方式可以是JSON文件、雜湊表或其他方式;
- 表/數據集合的數據關係:
sql中,必須定義好表和欄位結構後才能 纔能新增數據,例如:
主鍵(primary key)、索引(index)、觸發器(trigger)、儲存過程等;
nosql中,數據可以在任何時候、任何地方新增,不需要先定義表;
nosql也可以在數據集中建立索引,如:
MongoDB中,會在數據集合建立後,自動建立唯一值_id欄位,這樣就可以在數據集建立後增加索引;
<注>: 該區別表明,nosql更適合初始化數據還不明確或未定義的專案中;
- 外部數據儲存:
sql中,如果需要增加外部關聯數據,規範化做法是在原表中增加一個外來鍵,關聯外部數據表;
nosql中,除了這種規範化的外部數據表做法外,還可以用非規範化方式把外部數據直接放到原數據集中,以提高查詢效率;(缺點是:更新審覈人數據時很麻煩)
- JOIN查詢:
sql中,可以用JOIN錶鏈接方式,將多個關係數據表中的數據,用一條簡單的指令執行;
nosql暫未提供類似JOIN的查詢方式,所以大部分nosql使用非規範化的方式儲存數據;
- 數據耦合性:
sql不允許刪除已經被使用的外部數據;(強耦合)
nosql沒有這種強耦合的概念,可以隨時刪除任何數據;
- 事務:
sql中,如果多張表數據需要同批次被更新,即:要麼都成功,要麼都失敗。可以在所有指令完成後,再統一提交事務;
nosql中沒有事務這個概念,每一個數據集的操作都是「原子級」的;
- 查詢效能:
在相同水平的系統設計下,因爲nosql中省略了類似JOIN查詢的小號,所以理論上效能是優於sql的;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
sql
(1)介紹:
- mysql數據庫引擎取決於mysql在安裝時是如何被編譯的;
- 數據庫引擎是用於儲存、處理和保護數據的核心服務。利用數據庫引擎可控制存取許可權並快速處理事務,從而滿足大多數需要處理大量數據的應用程式的要求。
- 使用數據庫引擎建立用於聯機事務處理或聯機分析處理數據的關係型數據庫,包括:
建立用於儲存數據的表和用於檢視、管理和保護數據安全的數據庫物件(如:索引、檢視和儲存過程)
(2)分類:
- ISAM:
- MyISAM(非聚集索引):
是mysql的ISAM擴充套件格式和預設的數據庫引擎;
MyISAM強調快速讀取操作,在web開發中所進行的大量數據操作都是讀取操作,所以,大多數虛擬機器提供商和INTERNET平臺提供商只允許使用MyISAM格式;
- HEAP:
允許只駐留在記憶體裡的臨時表格,駐留在記憶體裡讓HEAP要比ISAM和MyISAM要塊;
- InnoDB(聚集索引):
InnoDB和BEARKLEYDB(BDB)都是造就mysql靈活性的技術的直接產品,即:MYSQL++ API;
InnoDB和BDB包括了對事務處理和外來鍵的支援,這兩點都是ISAM和MyISAM都沒有的;
(3)聚集索引和非聚集索引:
- 聚集索引:
實體地址連續存放的索引,在取區間的時候,查詢速度非常快;
但是插入速度慢;
- 非聚集索引:物理位置使用鏈表來進行儲存;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
對mysql優化,是一個綜合性的技術,主要包括:
- 表的設計合理化(符合3NF);
- 新增適當的索引(index); // 有4種:普通索引、主鍵索引、唯一索引unique、全文索引;
- 分表技術:水平分割、垂直分割;
- 讀寫分離;
- 儲存過程:模組化程式設計,提高存取速度;
- 對mysql設定優化:(例如:設定最大併發數my.ini、調整快取大小);
- mysql伺服器硬體升級;
- 定期清除不必要的數據,定時進行碎片整理(MyISAM);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
nosql
- 特點:物件導向或集合
- redis詳解
- redis
- redis底層數據結構
- redis叢集功能列舉:
(1)開啓允許區域網存取:
(2)開啓/關閉主從關係:
(3)哨兵功能:
涉及到「分佈式選舉」;
- 1
- 2
- 3
- 4
網路程式設計
tcp協定棧
- 位碼即TCP標誌位,有6種:
- ACK(acknowledgement):確認
- PSH(push):傳送
- FIN(finish):結束
- RST(reset):重置
- URG(urgent):緊急
- SYN(synchoronous):建立聯機
- Sequence Number:順序號碼
- Acknowledge Number:確認號碼
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
web伺服器開發
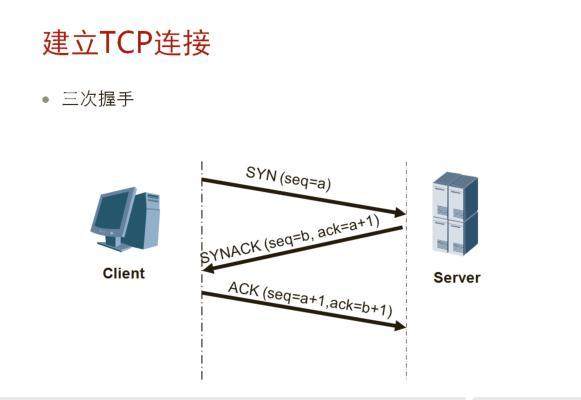
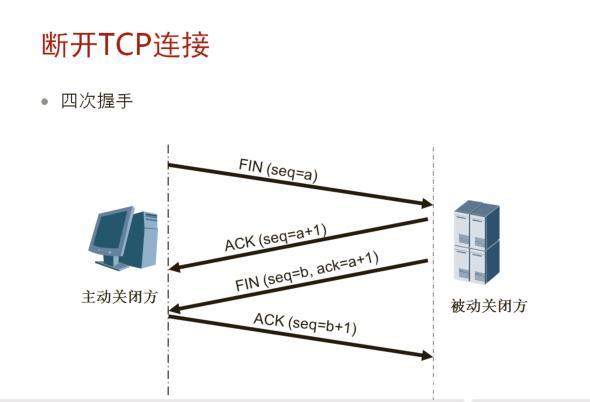
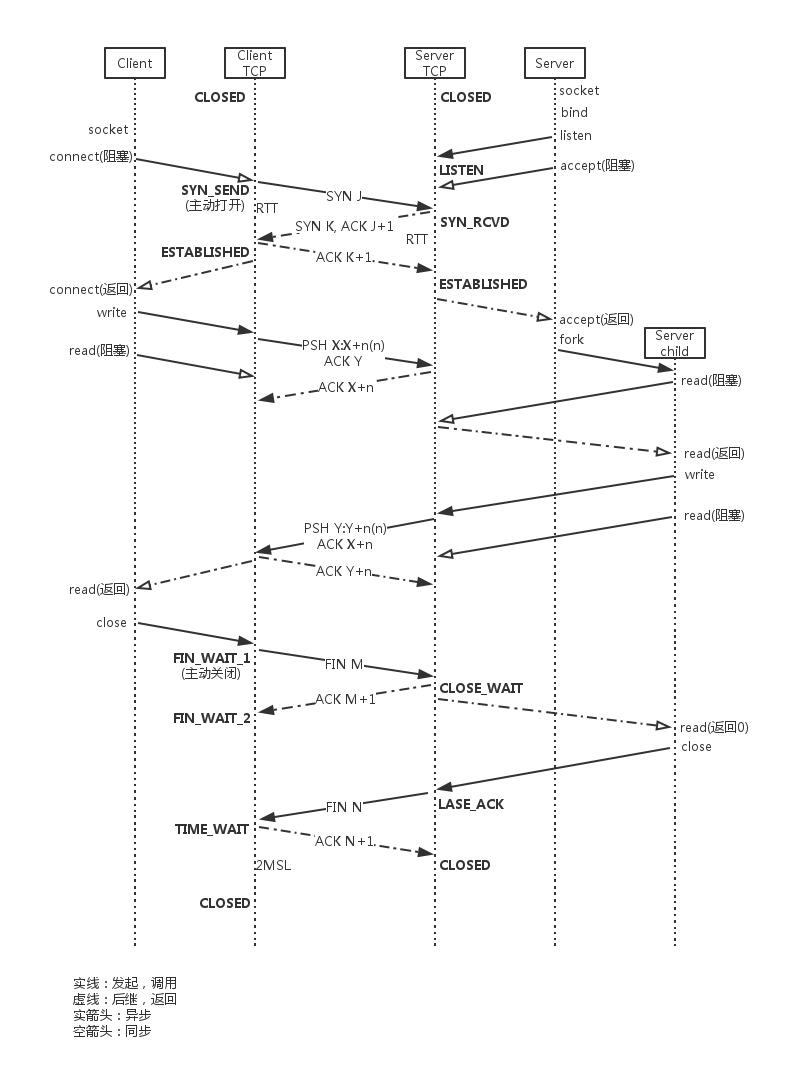
(1)正常開啓:
- 初始時,Client和Server的TCP狀態都是CLOSED;
- S端首先socket、bind、listen,listen後,S tcp狀態會變成LISTEN,執行被動開啓
- S端呼叫accept,阻塞等待tcp有連線完成;
- C端socket、connect,connect會阻塞到tcp的三次握手完成;
- 在C tcp發送第一個SYN報文時,C tcp狀態變爲SYN_SEND,爲主動開啓一方;
- S tcp收到C tcp的SYN後,狀態由LISTEN變爲SYN_RCVD,並執行發送回覆 回復(SYN K, ACK J+1);
- C tcp收到回覆 回復時,狀態變爲ESTABLISHED(數據傳輸狀態),並回復確認(ACK K+1)
然後connect()函數返回,這時用戶端的tcp連線建立完畢,可以向該socket收發數據
- S tcp收到3次握手的最後一個確認後,狀態變爲ESTABLISHED,至此,S端的accept返回,返回已連線的socket(區分socket返回的監聽通訊端);
(2)正常關閉:
- C呼叫close,C tcp向S tcp發送FIN報文,狀態變爲FIN_WAIT_1,主動關閉;
- S tcp收到FIN後,狀態變爲CLOSE_WAIT,並回復確認,此爲被動關閉。
若此時S端正在阻塞read此通訊端,read將返回0;
- S端呼叫close()或退出進程,使S tcp向C tcp發送FIN,S tcp狀態變爲LASK_ACK;
- C tcp收到S tcp發送的FIN後,狀態變爲TIME_WAIT,並對此FIN發送確認;
在等待 2×MSL 後,狀態變爲CLOSED,在此期間內,所有此socket pair的報文被丟棄(新建的、舊的);
- S tcp收到最後的ACK後,狀態變爲CLOSED;
(3)異常情況:
- accept返回前連線終止
- S端進程終止
- SIGPIPE信號
- S主機崩潰
- S主機崩潰後重新啓動
- S主機關機
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
開源庫
常用設計模式
建立型模式(重點)
結構型模式
行爲模式
Chain of Responsibility職責鏈模式(重點)
- 感謝@njczy2010、@jiayayao、@慢慢爬的小蝸牛、@yofer張耀琦、@Rayen0715、@番茄汁汁、@wxquare、@天空101、@艾露米婭娜、@A_carat_tear、@LeechanXBlog、@han_cui、@jaycekon、@yx0628、@wllenyj、@qing101hua的部落格文章