[CCF-GAIR 2020]聯邦學習下的數據價值與模型安全-楊強
文章首發於 https://yu-feng.top/archives/6/,轉載請複製此條。
寫在前面
很高興有機會去到了現場參加CCF-GAIR 2020 全球人工智慧和機器人峯會,
先簡單貼下介紹,8月7日-8月9日,2020年全球人工智慧和機器人峯會(簡稱「CCF-GAIR 2020」)在深圳舉辦!CCF-GAIR由中國計算機學會(CCF)主辦,香港中文大學(深圳)、雷鋒網聯合承辦,鵬城實驗室、深圳市人工智慧與機器人研究院協辦,以「AI新基建 產業新機遇」爲大會主題,致力打造國內人工智慧和機器人領域規模最大、規格最高、跨界最廣的學術、工業和投資領域盛會。
峯會網站入口:https://gair.leiphone.com/gair/gair2020
主要參加了 前沿語音技術專場、機器人前沿專場、AI金融專場、聯邦學習與大數據隱私專場。雖然此次會議部分有線上直播,但是現場給自己留下了更加深刻的感受與體會。我目前是網路空間安全的一名碩士研究生,也通過會議瞭解學習到一些前沿知識和風向,對自己未來發展有一定的指導作用。爲了更好地學習,也特地將自己所瞭解所學習到的一些東西分享出來,供大家參考學習。同時十分希望同在研究學習的朋友多多交流,留下您的寶貴意見和建議那就更好了!
另外做一個說明,總結不會完全重述演講者的講話,會挑一些自己覺得重點的點進行闡述(參照部分標識出來),僅代表個人淺見,也歡迎留言討論你的想法。如果想看全文或視訊,請將本文拉到最下方見參考文獻。
楊強教授:聯邦學習下的數據價值與模型安全

演講大咖簡介
楊強:微衆銀行首席人工智慧官,IJCAI首位華人理事會主席
演講概述
演講中,楊強教授介紹了聯邦學習的關鍵技術以及應用案例,並進一步介紹了最新開展的聯邦學習和遷移學習的結合研究以及接下來的重點研究方向。
楊強教授表示,我們建立的 AI 離不開人,保護人的隱私是當下AI 發展中特別重要的一點,這也是從政府到個人、企業以及社會的要求;另外,AI也要保護模型的安全,防止惡意或非惡意的攻擊;最後,AI 需要人類夥伴的理解,如何實現聯邦學習系統的透明性和可解釋性,也是研究者接下來需要重點研究的方向。
總結(正文看重點標註部分)
- AI離不開人,保護人的隱私是當下AI發展特別重要的一點,也是政府、個人、社會以及企業的要求
- AI也要保護模型的安全,如上述例子,若差分隱私用的不好,可能會暴露原始數據
- AI需要人類夥伴的理解, 如何實現聯邦學習系統的透明性和可解釋性, 也是需要研究的方向
研究方向概述
- 如何應對對抗攻擊?機器學習過程中有哪些可攻擊的點?
- 第一種,他可以通過跟你的互動來推斷你的數據隱私,這個叫推斷訓練數據的隱私;
- 第二種,通過跟你合作建模,影響你的模型效果,而這個影響朝着他們希望的方向行進;
- 第三種,在測試數據裡加入一些小的改動,改變模型對測試數據的判斷。
- 隱私攻擊:
- 防禦攻擊(HE、MPC、DP)
- 深度泄露攻擊(DP中噪聲的適當新增)——防禦(安全和效率高之間的最佳平衡點)
- 聯邦學習和自動化機器學習的結合
- 對於學生來說,將演算法與聯邦學習相結合是一個很好的研究題目。不管是To C還是To B,既可以採用橫向聯邦也可以採用縱向聯邦。 尋找課題研究的一種思路:在機器學習演算法中找到與聯邦學習結合的點進行研究.
正文
FL 背景
楊教授首先講了聯邦學習的背景,AI的力量來自大數據,但是面臨的實際問題往往只有小數據。
舉例:1)一個是法律,一個是金融,一個是醫療,這些跟國計民生和大產業都相關。
2)香港科技大學的老師們,他們網上課程的學生受衆是萬級的,那能不能用他們的問答數據做一個對話系統?我帶着這個問題訪問了好幾位老師,結果他們的回答都是:沒有數據。他們的數據十分有限,也沒有標註,完全沒辦法採用人工智慧對話機器人的思路和方法來做對話系統。
楊教授以此展開開始了 聯邦學習下的數據價值與模型安全的主題演講。在平常聽到的人工智慧主戰場,比如無人車、智慧手機、Pad、筆記型電腦等,每一臺裝置數據都是有限的,只有把這些數據匯聚雲端才能 纔能形成大數據。但匯聚雲端會帶來隱私問題,泄露隱私問題如Facebook事件等等這些,繼而政府部分關注並實施法律法規,如 GDPR、2020年7月的中國《數據安全法》草案。再者,數據上傳雲端容易發生泄露,因此推動聯邦學習的發展。
FL:數據不動模型動,數據可用不可見
核心:數據不動模型動,(插句題外話,這場會議中的PPT我曾經在前幾個月的演講中見過,可以在youtube或者B站找到,還有上午的AI金融專場,所以至少看了3遍)
數據不動模型動,是指模型在不同機構之間、端和雲之間進行溝通交流。產生的效果 則是 數據可用不可見,不可見指的是 雙方都不能看見對方的數據,即數據和模型都保留在本地,建模的過程也保證了數據的安全。
「羊吃草」的例子:
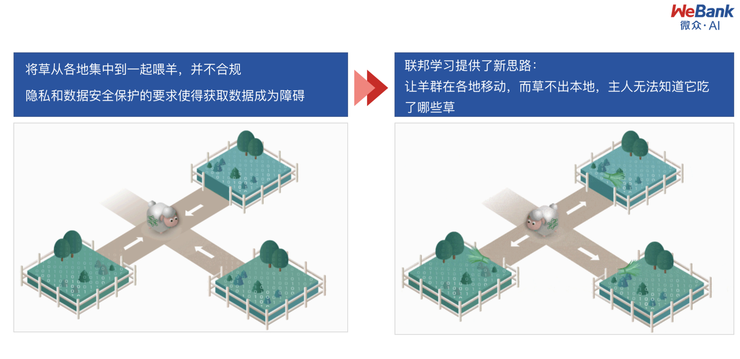
把羊比擬成一個模型,把草比作數據。傳統的做法是把草運到羊的位置,這樣的話這個數據就需要出本地,而聯邦學習的做法是領着這隻羊存取不同的草所在的地方,這樣草就不用出本地,羊還是可以長大。
橫向聯邦學習:按樣本分割(橫向切割數據)
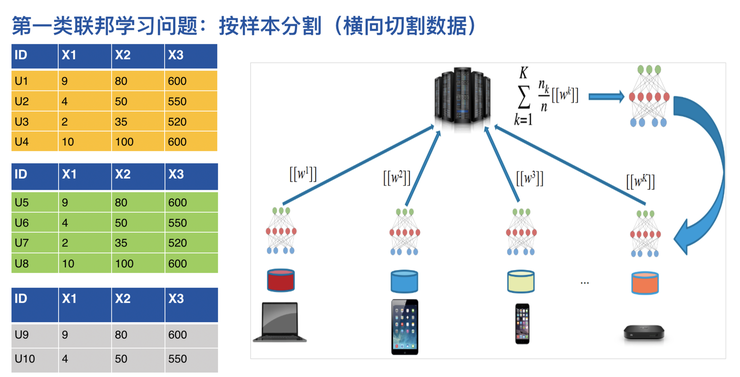
業界有多種不同的聯邦學習模式,一種模式是谷歌提出的橫向聯邦,或者叫做按照樣本切割的聯邦學習。
如果我們把所有聚合好的數據想象成一個大的數據集,這個數據集橫過來的每一行是一個樣本,是一個使用者的所有數據,縱過來的每一列則是特徵,比如使用者的年份、身份等等。橫向聯邦,就是把這個數據的一部分樣本寄存在某個終端,如上右圖所示。這些樣本加起來是一個完整的數據集,但我們現在沒辦法在物理或實際現實世界中達到這個目的。
谷歌的做法是:首先在每一個本地建模,建的模型是圖裏的「w」,對模型加密以後,把加密後的模型在雲端進行整合。
FL關鍵技術——加密/解密

這個過程的目的是不讓參數泄露,因此關鍵技術是加密和解密的技術,現在有各種各樣的可以使用的加密技術,它們都在不同程度有保密性。比方說最嚴格的同態加密,它的特點是穿透性,其進行的數學多項運算可以穿透包對內部數據進行同樣的運算,而運作執行者可以不看內容。
縱向聯邦學習(特徵不同,樣本重疊)
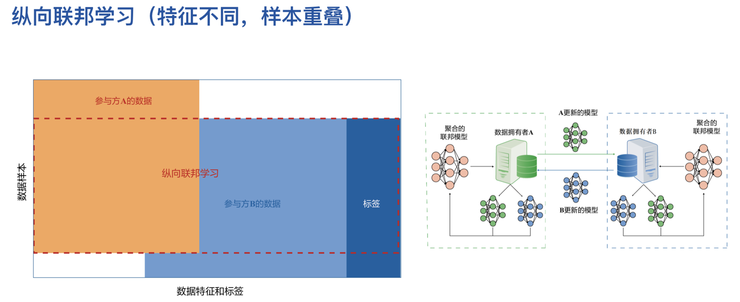
可以用在縱向聯邦模型上。按照特徵來分,一個機構可以有這樣的使用者特徵,另一個機構可以有那樣的使用者特徵;一個醫院可以有病人的胸腔檢測,另一個醫院可以有病人的核酸檢測,當他們合作以後,就希望得到全面的使用者檢測模型。而這個模型可以通過上右圖呈現的方式,在兩個機構之間傳播和溝通,整個傳播和溝通過程也是在加密的情況下用分佈式的機器學習來進行的。
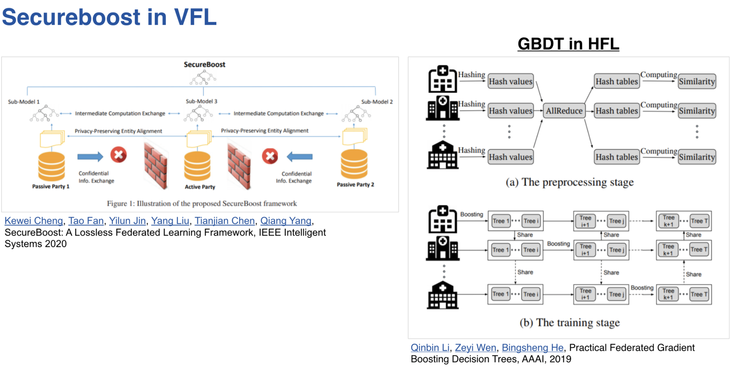
Secureboost in VFL
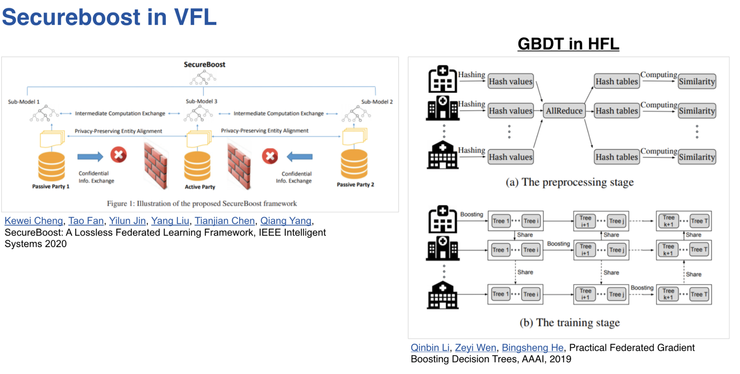
這種做法也可以適配到人工智慧演算法上,左邊的圖表示的是在縱向的情況下採用SecureBoost演算法,右邊的圖表示在橫向聯邦基礎上也可以實現SecureBoost演算法,這是機器學習聯邦化的例子。
*對於學生來說,將演算法與聯邦學習相結合是一個很好的研究題目。 不管是To C還是To B,既可以採用橫向聯邦也可以採用縱向聯邦。 *
尋找課題研究的一種思路:在機器學習演算法中找到與聯邦學習結合的點進行研究.
FL應用案例
縱向聯邦推薦:系統架構

第一個案例是推薦系統,這是現在很多應用的核心,比如電影推薦、書籍推薦,比如新聞和短視訊推薦,這些系統的特點是數據越多越好,我們叫做矩陣數據。也就是說,這個矩陣的縱向是不同使用者,橫向是不同特徵(即產品)。做推薦的時候,矩陣越密越好,因爲矩陣的密度決定了推薦的個性化效果。如果要實現這個推薦系統,讓兩方合作,同時又不在物理上將雙方的數據進行傳播,就需要用到聯邦推薦的架構,具體來說,就是讓雙方交換一些共有子矩陣,在加密的前提下實現聯邦推薦的效果。這種方法也可以應用在廣告的推薦上。
應用:基於聯邦學習的企業貸款風控模型
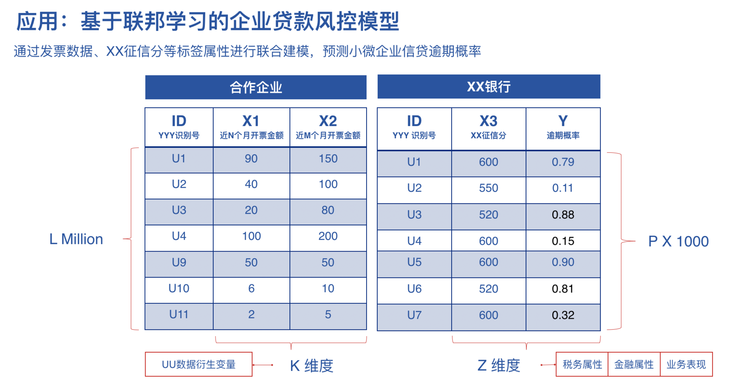
第二個例子是基於聯邦學習的企業貸款風控模型。金融界特別關心建立一個好的風控模型。在這個案例中,由一家銀行和一家票據公司對同一批使用者進行聯合建模,在建模的過程中就可以復傳數據。
對於縱向聯邦而言特別重要的一點是,有一方需要有關鍵的標註數據,比如銀行有關鍵的逾期率數據,但缺乏使用者行爲數據,而使用者行爲數據可以由合作的票據方來提供,最終實現效果也是非常明顯的。
目前在聯邦學習實踐中,已經有幾十家銀行和非銀行合作的案例了,這些案例都證明聯邦學習方法可以大幅降低壞賬率。
第三個例子,多個保險公司之間進行橫向聯邦,在保險公司和網際網路之間還可以進行縱向聯邦。也就是說在同樣型別客戶的機構之間,可以進行橫向聯邦;而在擁有不同特徵客戶的機構之間可以進行縱向聯邦,也可以進行拓撲聯邦。
聯邦學習用於計算機視覺
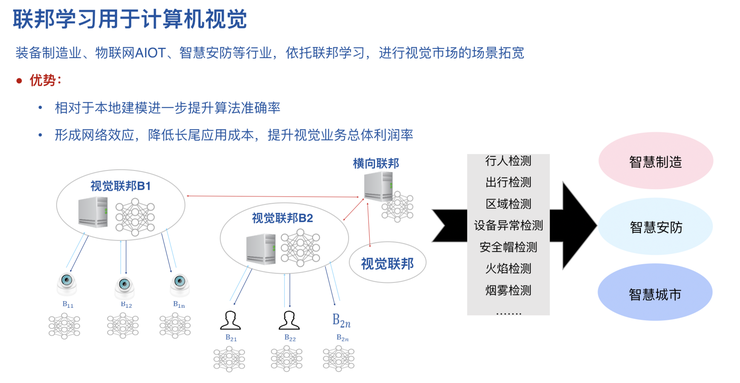
聯邦學習在計算機視覺領域也有應用案例。AI 視覺公司之間如果進行橫向聯邦,他們可以把模型的準確率大幅提高。
語音識別引擎-微衆AI基於「聯邦對抗學習」的解決方案
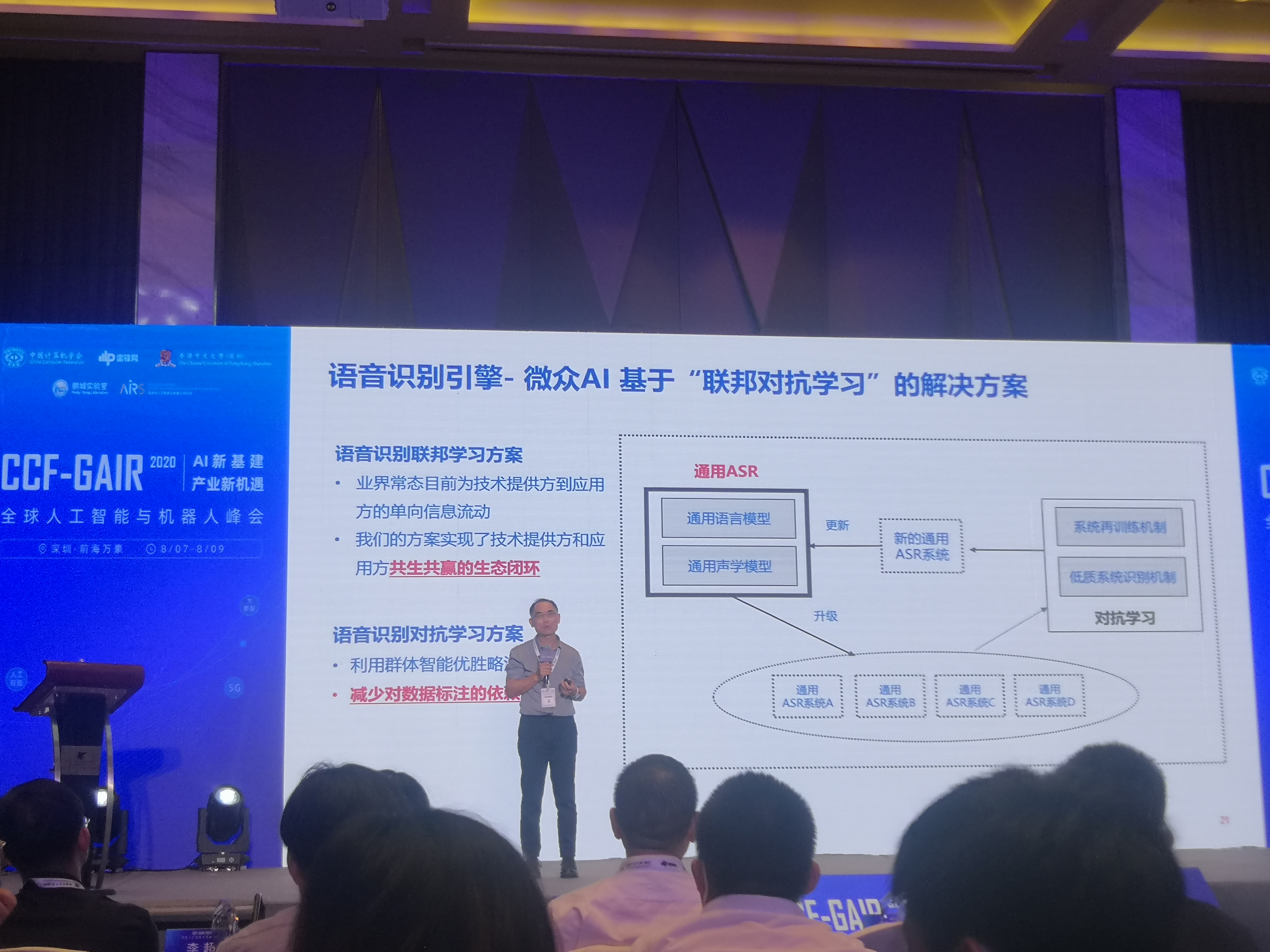
視覺以外,人工智慧的另一個重要戰場是語音識別ASR,這一領域也有採用聯邦學習的需求。比方說我們在一個客服中心收集了很多錄音,在另一個客服中心也收集了很多錄音,那能不能把這兩批錄音結合起來變成更大的數據集?很顯然,這會暴露使用者隱私,不過現在我們可以用聯邦學習建立一個更好的語音識別模型,目前微衆人工智慧部門也實現這一方案。
Federated Learning in IoT

聯邦學習在 IoT 領域也得到了應用,比如還利用聯邦學習進行倉庫的倉儲量預測,比如當有些貨品缺乏時,系統就可以提早提出預警。
聯邦學習技術加速大數據合作生態構建

總結來說,這一階段我們做了各種各樣的嘗試,以證明聯邦學習可以在企業,尤其是可以在不同企業之間廣泛使用,現在這一點也得到了很好的印證,接下來的專場,大家也會聽到不同講者 闡述聯邦學習在他們各自領域中的應用。
Federated Health Code: Defending COVID 19 with privacy

我特別要提到的一個應用——健康碼,這是我們最新的一個嘗試。大家掃健康碼進入會場的時候,掃的時候可能都會有一個擔心,健康碼記錄了你到過什麼地方,有沒有去過現在疫情比較緊急的地方。其實更準確的健康碼,應該能記錄到你有沒有近距離接觸過一些新冠病人,但這就要對你的軌跡數據進行非常細緻的調查以及你和其他人的軌跡的交叉計算。這或多或少會讓我們擔心自己的軌跡數據隱私會不會暴露給一些不認識的人,比方說雲端計算公司。我們現在把聯邦學習和應用結合起來,形成了新的方案,叫做聯邦健康碼,它計算出來的最後結果只有你自身所擁有的那臺手機才知道,其他的人都只知道片面資訊,而不知道全面資訊。
聯邦學習和遷移學習的結合研究
聯邦學習在應用中往往存在一個現象,即每一個數據擁有方所持有的數據,也許和別人的分佈是不一樣的,也許和別人的表達也是不一樣的。比方說一個攝像頭中可能看到更多的是男性,另一個攝像頭看到的更多的是女性,這樣的分佈是不一樣的。在這種狀況下建模,對機器學習來說是有困難的,因爲機器學習要求數據遵從統一分佈,並且表達也是類似的,而不能一部分數據是影象,而另一部分數據是文字。這種異構的數據在現實中經常發生,所以有必要來做聯邦學習和遷移學習的結合。
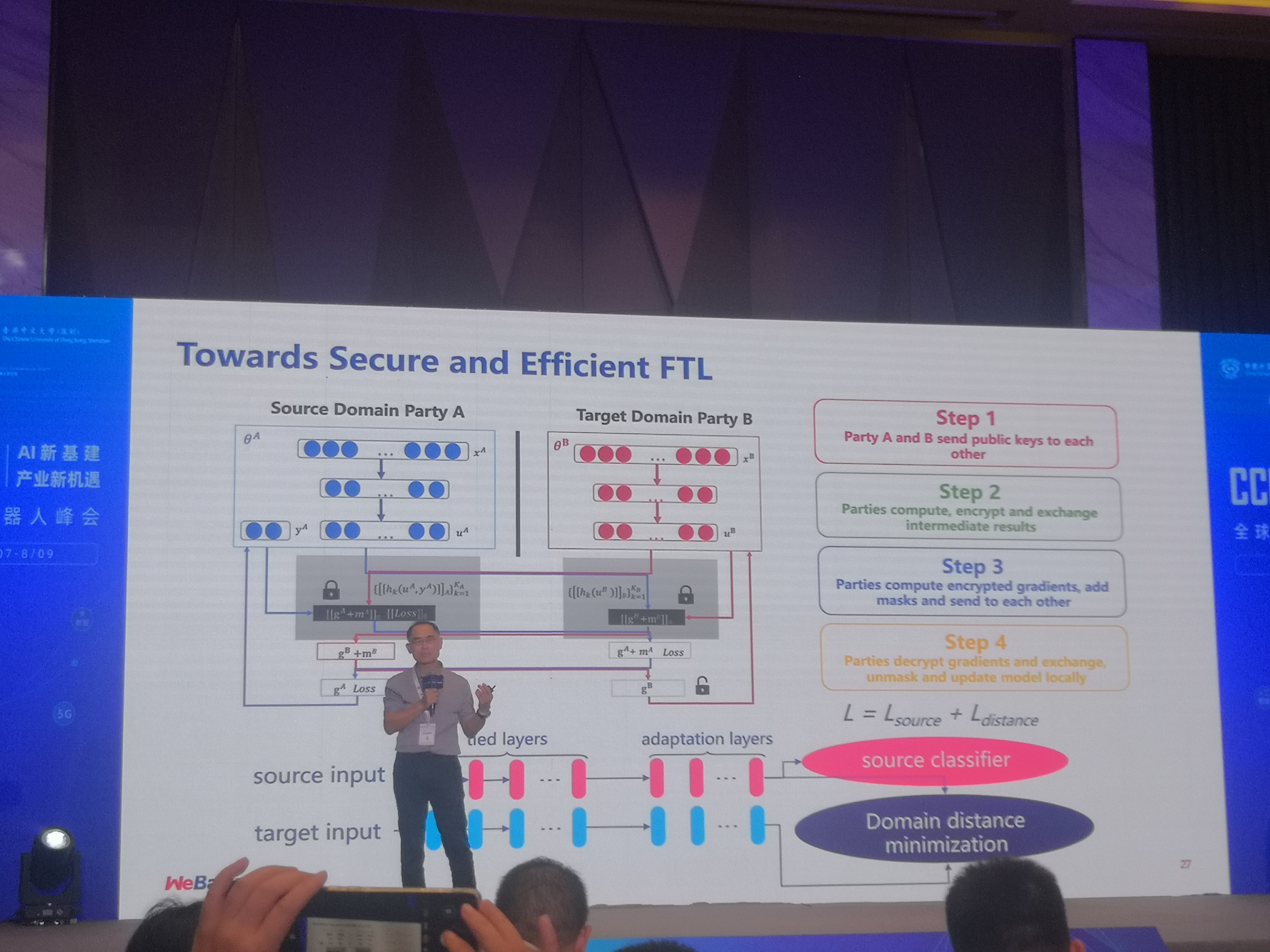
這種結合可以體現在各個層面,以深度學習爲例,左邊的圖展示的是兩個神經網路,藍色的神經網路有很多數據標籤,所以可以建一個很好的神經網路模型,但是紅色的神經網路卻缺乏這樣的數據,我們考慮將藍色神經網路的數據遷移到紅色的神經網路中。過去,遷移學習是不考慮隱私的,模型和數據都可以被物理運到紅色神經網路進行知識遷移。現在有了隱私顧慮,是不是可以用聯邦學習達到遷移學習的效果?答案是可以。
在兩邊溝通的過程中,除了隱私加密以外,還要進行一項遷移學習的運算,保證兩邊數據的分佈和兩邊數據的表達都是相同的。要達到這一點,雙方首先要把各自方的模型和數據遷移到一個共同的子空間,這個遷移過程可以通過某種數學運算進行,比如和函數,效果相當於我們把神經網路的某些層遷移到了新的場景下。

這個工作中需要經過多番遷移和對比,所以效率很低。最近我們又提出了一個加速演算法,使得每一方原生的數據計算儘量多,跨合作方的計算儘量少,以聯邦塊的方式進行梯度互動,結果證明效果非常好。
隨機森林也可以採用這個方法實現遷移學習和聯邦學習的結合。

最近我們在推一個聯邦視覺的公共數據集,歡迎學校的學生來參與比賽。我在很多場合都說過,我們在共同推動IEEE標準,比如塗威威等人都在共同推動。現在,微衆銀行開源的FATE也變成了國際上知名的聯邦學習開源軟體。
聯邦學習接下來的重點研究方向
第一方向,是如何應對對抗攻擊。假設在聯合建模的過程中有壞人蔘與,或者說這個人並不那麼壞,但是他很好奇,時不時要探測合作方數據隱私,這種情況怎麼防止?我們要看機器學習的過程中有哪些可攻擊點。
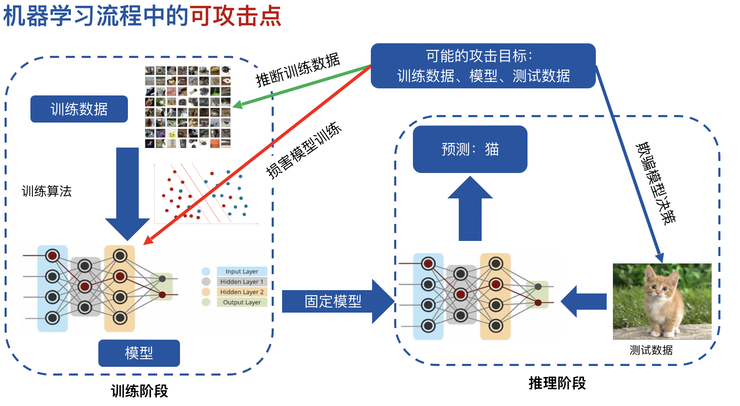
第一種,他可以通過跟你的互動來推斷你的數據隱私,這個叫推斷訓練數據的隱私;
第二種,通過跟你合作建模,影響你的模型效果,而這個影響朝着他們希望的方向行進;
第三種,在測試數據裡加入一些小的改動,改變模型對測試數據的判斷。
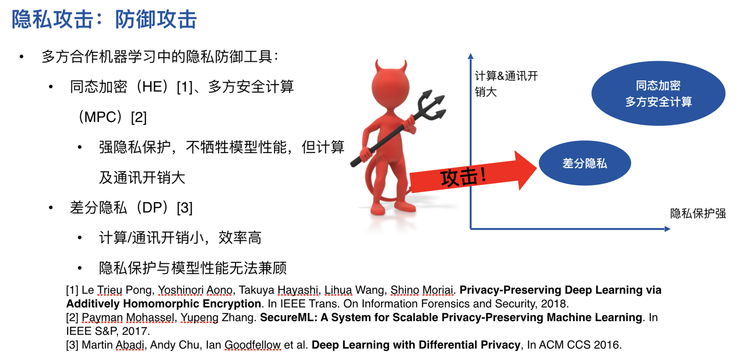
另外我們一不小心也有可能讓參與方學到你數據裡的隱私,這也是一種隱私攻擊。如果我們用很嚴格的同態加密或者多方安全計算來進行,往往就不會發生這種情況。但是在大規模的工業應用中,我們往往沒辦法用完整的原始同態加密和多方安全計算保證安全。相反,我們往往會往模型加一些噪音,在完全安全和完全不安全之間選擇一箇中間點,差分隱私往往是中間點,具體做法是在數據和模型當中加入一些噪音,使對方沒辦法完全區分某一個人或者某一個樣本是不是在你的數據裡。
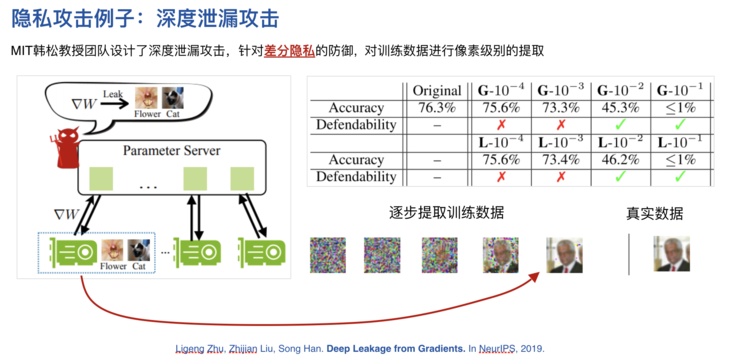
但是這是有一定概率的,有可能對方還是能猜出來你的數據內容。去年年底MIT的韓松教授團隊發表了一篇論文,他們證明如果差分隱私應用得不好,有可能讓參與方通過對梯度的積累猜出來數據的原始形狀和原始的隱私資訊。實驗證明,如果你加更多的噪音,會導致聯邦學習的效果下降,準確率會變差;而加的噪音少了,效果變好了,安全性卻又大爲降低,所以這個方法其實是一把雙刃劍。
ps:加噪聲需要根據實際效果判斷

最近我們引入了一個新的方法,讓每一個參與方不直接和對方溝通,具體來說,就是讓參與方在建模的時候建立自己的映象,在跟別人溝通時,防火牆會把他們對隱私的好奇心擋住,這樣就能夠在安全和效率高的兩個極端找到一個最佳的平衡點。

聯邦學習和自動化機器學習的結合研究,是另一個方向,第四範式的塗威威是這方面的專家。
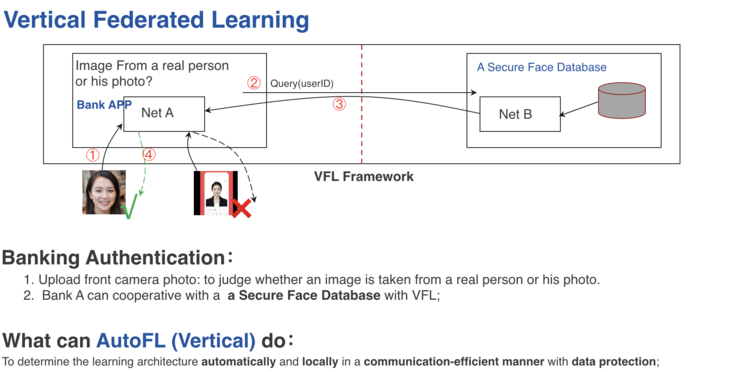
縱向聯邦中,我們都希望兩邊都快速建立起一個神經網路。而神經網路的結構和搜尋空間是非常大的,過去我們需要一個人做手工調參,但現在可以通過一些加密手段梯讓度和損失函數值進行溝通,促進雙邊都自動尋找最優網路結構,如圖上所示的兩個系統一樣,可以進行有機結合,最後獲得的效果就會非常好。上圖的大概思想是,我們建立網路形狀拓撲的同時,也可以讓他們交換一定量的網路數據、梯度和損失函數,當能夠自動化建模的過程,實現的效果非常好。
參考文獻
- [1] https://www.leiphone.com/news/202008/hBACeSbAY8PIOcbh.html
- [2] https://gair.leiphone.com/gair/gair2020
最後附一張與楊強教授的合影~

歡迎交流,靜候你的留言~
--fzhiy.更新與2020年8月12日15點29分
文中部分參照了相關文獻或者其他資料,如有侵權請郵件[[email protected]]聯繫站長,感謝!
若有 參照或轉載 本文的請貼原文鏈接: https://yu-feng.top/archives/6/
本文由部落格羣發一文多發等運營工具平臺 OpenWrite 發佈