SpringBoot2.x系列教學63--SpringBoot整合訊息佇列之RabbitMQ詳解
一. RabbitMQ 簡介
1. RabbitMQ 背景
RabbitMQ起源於金融系統,主要用於分佈式系統的內部各子系統之間的數據儲存轉發,這是系統解耦方面的一種運用.
2. RabbitMQ 概述
RabbitMQ是一種基於erlang語言開發的流行的開源訊息中介軟體,或者說是一個訊息佇列系統.它是對AMQP協定的實現,支援多種用戶端,可以對來自用戶端的非同步訊息進行儲存轉發,在易用性、擴充套件性、高可用性等方面表現不俗.
趣味定義: 兔子行動非常迅速而且繁殖起來也非常瘋狂,用Rabbit來命名這個分佈式軟體,呼應了RabbitMQ的主要任務是處理海量的資訊.
3. RabbitMQ 的優點
- 基於 ErLang 語言開發具有高可用高併發的優點,適合叢集伺服器;
- 健壯、穩定、易用、跨平臺、支援多種語言、文件齊全;
- 有訊息確認機制 機製和持久化機制 機製,可靠性高;
- 開源.
4. 爲什麼選擇RabbitMQ
現在市面上有很多MQ可以選擇,比如ActiveMQ、ZeroMQ、Appche Qpid,Kafka,RocketMQ等,那問題來了爲什麼要選擇RabbitMQ?
- 除了Qpid,RabbitMQ是唯一一個實現了AMQP標準的訊息伺服器;
- 可靠性:RabbitMQ支援持久化,保證了訊息的穩定性;
- 高併發: RabbitMQ使用了Erlang作爲開發語言,Erlang是爲電話交換機開發的語言,天生自帶高併發和高可用的光環;
- 叢集部署簡單:正是因爲Erlang使得RabbitMQ叢集部署變的超級簡單;
- 社羣活躍度高:根據網上資料來看,RabbitMQ也是首選.
5. RabbitMQ 應用場景
- 解耦: 在單體應用通常可以使用記憶體佇列,如Java的
BlockingQueue來進行不同模組間的資訊傳遞.而將單體應用拆分爲分佈式系統之後,可以通過RabbitMQ這種進程間佇列來在各子系統之間進行訊息傳遞,從而達到解耦的作用; - 流量削峯: RabbitMQ還可以被用在高併發系統當中的流量削峯,即將請求流量數據臨時存放到RabbitMQ當中,從而避免大量的請求流量直接達到後臺服務,把後臺服務沖垮 衝垮.通過使用RabbitMQ來存放這些請求流量,後臺服務從RabbitMQ中消費數據,從而達到流量削峯的目的.
- 訊息通訊: 除了系統解耦和流量削峯外,RabbitMQ也常用於訊息通訊,即可以用於實現IM聊天系統.
6. RabbitMQ 基本工作流程

訊息的生產者把要發送的訊息放入到訊息佇列中,訊息的接收端可以根據RabbitMQ設定的轉發機制 機製接收伺服器端發來的訊息.RabbitMQ依據指定的轉發規則進行訊息的轉發、緩衝和持久化操作,主要用在多伺服器間或單伺服器的子系統間進行通訊,RabbitMQ是分佈式系統的標準設定.
7. RabbitMQ的核心思想

RabbitMQ中訊息傳遞模型的核心思想是生產者永遠不會將任何訊息直接發送到佇列.
實際上,生產者通常甚至不知道訊息是否會被傳遞到任何佇列.而且生產者只能向交換機發送訊息.
交換是一件非常簡單的事情.一方面,它接收來自生產者的訊息;另一方面將它們推播到佇列.交換機必須確切知道如何處理它收到的訊息---它應該附加到特定佇列嗎?它應該附加到許多佇列嗎?或者它應該被丟棄嗎?
二. RabbitMQ 核心概念
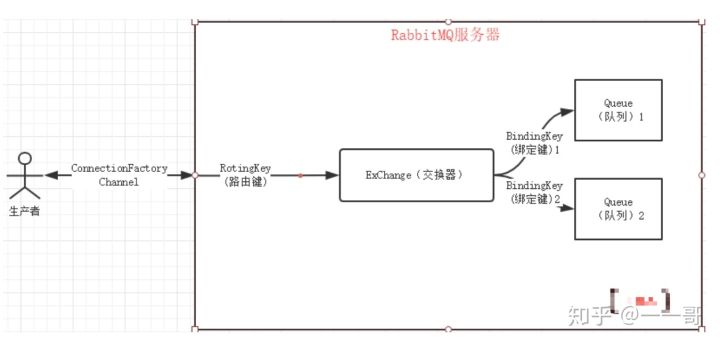
1. 生產者和消費者
- Producer: 訊息的生產者,用於發佈訊息;
- Consumer: 訊息的消費者,用於從佇列中獲取訊息.消費者只需關注佇列即可,不需要關注交換機和路由鍵.消費者可以通過
basicConsume(訂閱模式可以從佇列中一直持續的自動的接收訊息)或者basicGet(先訂閱訊息,然後獲取單條訊息,再然後取消訂閱,也就是說basicGet一次只能獲取一條訊息,如果還想再獲取下一條還要再次呼叫basicGet)來從佇列中獲取訊息.
2. RabbitMQ broker 伺服器
RabbitMQ broker: 官方定義"RabbitMQ isn’t a food truck, it’s a delivery service",指明RabbitMQ是一種傳輸服務.
3. ExChange 交換機
Exchange: 生產者會將訊息發送到交換機,然後交換機通過路由策略(規則)將訊息路由到匹配的佇列中去. ExchangeType決定了Exchange路由訊息的行爲,在RabbitMQ中,ExchangeType有direct、Fanout、Topic和Header 4種.
Exchange 類似於數據通訊網路中的交換機,提供訊息路由策略.
在RabbitMQ 中,Producer 不是通過通道直接將訊息發送給 Queue,而是先發送給 ExChange. 一個 ExChange 可以和多個 Queue 進行系結,Producer 在傳遞訊息的時候,會傳遞一個 ROUTING_KEY, ExChange 會根據這個 ROUTING_KEY 按照特定的路由演算法,將訊息路由給指定的 Message Queue.與 Queue 一樣, ExChange 也可設定爲持久化,臨時或者自動刪除.
4. Binding 系結
所謂系結就是將一個特定的 ExChange 和一個特定的 Queue 系結起來,所以Binding不是一個概念,而是一種操作.RabbitMQ中通過系結,以路由鍵作爲橋樑將Exchange與Queue關聯起來(Exchange—>Routing Key—>Queue),這樣RabbitMQ就知道如何正確地將訊息路由到指定的佇列了,通過queueBind()方法將Exchange、Routing Key、Queue系結起來.ExChange 和 Queue 的系結可以是多對多的關係.
5. Binding Key 系結鍵
Binding Key: 它表示的是Exchange與Message Queue是通過binding key進行系結聯繫的,這個關係是固定的.初始化的時候,我們就會建立該佇列.
6. Routing Key 路由鍵
Routing Key: 它是一個String值,用於定義路由規則.生產者在將訊息發送給Exchange的時候,一般會指定一個routing key,來指定這個訊息的路由規則.在佇列系結的時候需要指定路由鍵,在生產者發佈訊息的時候需要指定路由鍵,當訊息的路由鍵和佇列系結的路由鍵匹配時,訊息就會發送到該佇列.
7. Message Queue 訊息佇列
用於儲存訊息的容器,可以看成一個有序的陣列,生產者生產的訊息會發送到交換機中,最終交換機將訊息儲存到某個或某些佇列中.佇列可被消費者訂閱,消費者從訂閱的佇列中獲取訊息.
- Message Queue: 訊息佇列,我們發送給RabbitMQ的訊息最後都會到達各種queue,並且儲存在其中(如果路由找不到相應的queue則數據會丟失),等待消費者來取.
- 訊息佇列提供了 FIFO 的處理機制 機製,具有快取訊息的能力.在RabbitMQ 中,佇列訊息可以設定爲持久化,臨時或者自動刪除.
- 設定爲持久化的佇列,Queue 中的訊息會在 Server 本地硬碟儲存一份,防止系統 Crash,數據丟失;
- 設定爲臨時的佇列,Queue 中的數據在系統重新啓動之後就會丟失;
- 設定爲自動刪除的佇列,當沒有使用者連線到 Server,佇列中的數據會被自動刪除.
8. Virtual Host 虛擬主機
每一個RabbitMQ伺服器都能建立多個虛擬訊息伺服器,我們稱之爲虛擬主機.每一個vhost本質上是一個mini版的RabbitMQ伺服器,擁有自己的交換機、佇列、系結等,擁有自己的許可權機制 機製.vhost相對於RabbitMQ就像虛擬機器之於物理機一樣.他們通過在各個範例間提供邏輯上的分離,允許不同的應用程式安全保密的執行數據,這很有用,它既能將同一個Rabbit的衆多客戶區分開來,又可以避免佇列和交換器的命名衝突.RabbitMQ提供了開箱即用的預設的虛擬主機「/」,如果不需要多個vhost可以直接使用這個預設的vhost,通過使用預設的guest使用者名稱和guest密碼來存取預設的vhost.
vhost之間是相互獨立的,這避免了各種命名的衝突,就像App中的沙盒的概念一樣,每個沙盒是相互獨立的,且只能存取自己的沙盒,以保證非法存取別的沙盒帶來的安全隱患.
三. ExChange 的 4 種類型

1. 直接交換器(direct,預設)
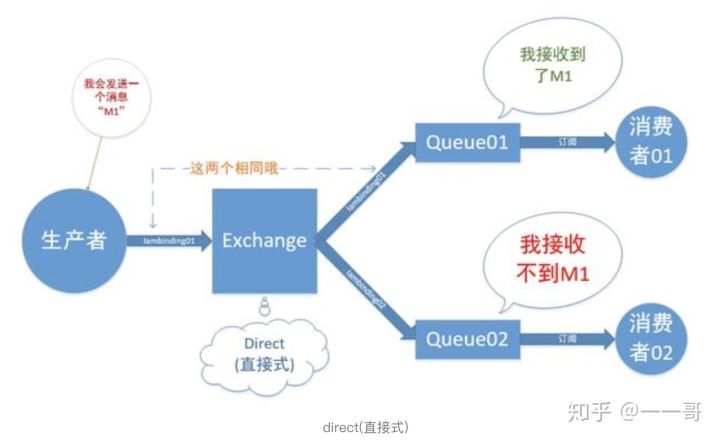
直接交換器direct(預設):工作方式類似於單播,Binding_Key和Routing_Key相同才能 纔能收到訊息,ExChange會將訊息發送給 Binding_Key和ROUTING_KEY相匹配的Queue.

有一個需要注意的地方:如果找不到指定的exchange,就會報錯.但routing key找不到的話,不會報錯,這條訊息會直接丟失,所以此處要小心.
2. 廣播式交換器(fanout)

廣播式交換器(fanout):不管訊息的 ROUTING_KEY 是什麼,ExChange 都會將訊息轉發給所有系結的 Queue(無視 key,所有的 queue都能收到訊息).
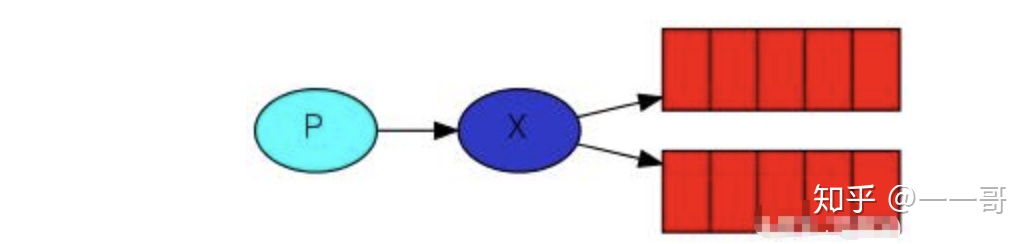
Fanout 扇出,顧名思義,就是像風扇吹麪粉一樣,吹得到處都是.如果使用fanout型別的exchange,那麼routing key就不起作用了.因爲凡是系結到這個exchange的queue,都會收到訊息.
3.主題交換器(topic)
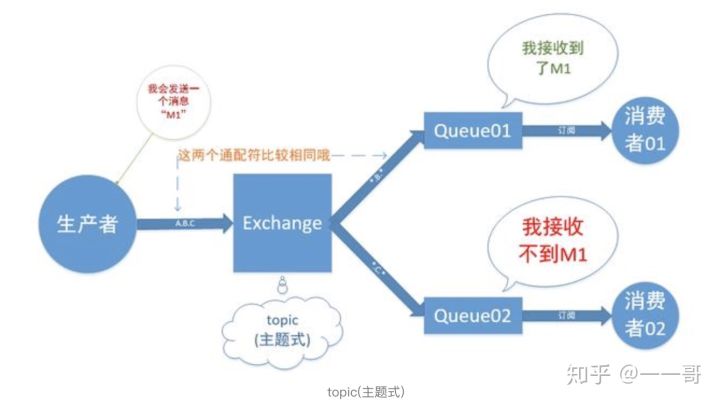
主題交換器(topic):工作方式類似於組播,採用模糊匹配,ExChange 會將訊息轉發給與 ROUTING_KEY 匹配模式相同的所有佇列(Binding Key和Routing Key都是被點"."分個開的多個"單詞").比如,ROUTING_KEY 爲 user.stock 的 Message 會轉發給系結匹配模式爲* .stock,user.stock, * . * 和 #.user.stock.# 的佇列(* 表是匹配一個任意單詞,# 表示匹配 0 個或多個單詞).

- direct是將訊息放到exchange系結的一個queue裡(一對一);
- fanout是將訊息放到exchange系結的所有queue裡(一對所有);
- topic型別的exchange可以實現(一對部分)把訊息放到exchange系結的一部分queue裡,或者多個routing key可以路由到一個queue裡.
topic應用場景:
列印不同級別的錯誤日誌.
例如,我們的系統出錯後會根據不同的錯誤級別生成error_levelX.log日誌,我們在後台首先要把所有的error儲存在一個總的queue(系結了一個*.error的路由鍵)裡,然後再按level分別存放在不同的queue.
routing key系結如下圖:

4. headers交換機
headers:訊息體的 header 匹配,無視 key.headers型別不是基於訊息的路由鍵來進行匹配的,而是基於訊息的headers屬性的鍵值對來進行匹配的.首先交換器和佇列之間基於一個鍵值對來建立起系結對映關係,當交換器接收到訊息時,分析該訊息的headers屬性的鍵值對是否與這個建立交換器和佇列系結關係的鍵值對完全匹配,是則投遞到該佇列.由於這種方式效能較低,故基本不會使用.
四. RabbitMQ 訊息傳遞流程
- 1️⃣.用戶端連線到訊息佇列伺服器,開啓一個 Channel;
- 2️⃣.用戶端宣告一個 ExChange,並設定相關屬性;
- 3️⃣.用戶端宣告一個 Queue,並設定相關屬性;
- 4️⃣.用戶端使用 Routing Key,在 ExChange 和 Queue 之間建立好系結關係;
- 5️⃣.用戶端投遞訊息到 ExChange;
- 6️⃣.ExChange 接收到訊息後,就根據訊息的 key 和已經設定的 binding,進行訊息路由,將訊息投遞到一個或多個佇列裡.
五. RabbitMQ 核心設計
RabbitMQ是基於AMQP協定的一個訊息佇列中介軟體,主要用於分佈式系統當中不同系統之間的訊息傳遞,所以在覈心設計層面也是圍繞AMQP協定來展開的.如下爲RabbitMQ的核心架構示意圖:
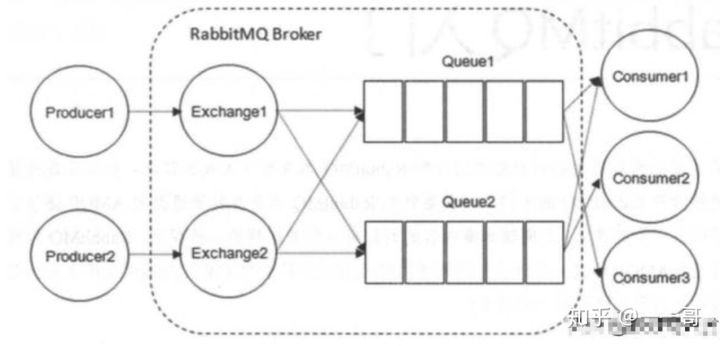
1. 虛擬主機vhost與許可權
1.1 虛擬主機
虛擬主機vhost也被稱爲多租戶,主要用於實現不同業務系統之間的訊息佇列的隔離.也就是說只部署一個RabbitMQ伺服器端,但是可以設定多個虛擬主機給多個不同的業務系統使用,這些虛擬主機對應的訊息佇列內部的數據是相互隔離的.所以多個虛擬主機也類似於同一棟公寓樓裏面的多個租戶,每個租戶都在自己家裏生活,而不會去其他租戶家裏過日子.
虛擬主機的概念相當於Java應用程式的名稱空間namespace,不同虛擬主機內部可以包含相同名字的佇列.
RabbitMQ伺服器包含一個預設的虛擬主機,即「/」.如果需要建立其他的虛擬主機,可以在RabbitMQ控制檯執行如下命令:
比如通過rabbitmqctl add_vhost命令新增一個新的「test_host」虛擬主機.
1.2 使用者與許可權
一個RabbitMQ伺服器端可以包含多個虛擬主機,而這多個虛擬主機通常是對應多個不同的業務.所以爲了保證不同業務不相互影響,則RabbitMQ中定義了使用者和許可權的概念.
在RabbitMQ中,許可權控制是以虛擬主機vhost爲單位的,即當建立一個使用者時,該使用者需要被授予對一個或者多個虛擬主機進行操作的許可權,而操作的物件主要包括交換器,佇列和系結關係等,如新增,刪除交換器、佇列等操作.
建立使用者和設定許可權的相關命令主要在rabbitmqctl定義,RabbitMQ預設包含一個guest使用者,密碼也是guest,該使用者的角色爲管理員:
2. 連線Connection與通道Channel
- 在高併發系統設計當中,需要儘量減少伺服器的連線數,因爲每個連線都需要佔用伺服器的一個檔案控制代碼,而伺服器的檔案控制代碼數量是有限的,具體可以通過
ulimit命令檢視. - 所以爲了減少連線的數量,AMQP協定抽象了通道Channel的概念,一個用戶端與RabbitMQ伺服器之間只建立一個TCP連線,但是用戶端可以建立多個Channel,這多個Channel公用這個TCP連線來進行與伺服器端之間的數據傳輸.即Channel是建立在這個TCP連線之上的虛擬連線,就相當於每個Channel都是一個獨立的TCP連線一樣.爲了保證數據的安全性,RabbitMQ的設計爲每個不同Channel範例都分配一個唯一的ID.故這個真實的TCP連線發送和接收到數據時,可以根據這個唯一的ID來確定這個數據屬於哪個Channel.
- 使用Channel的場景通常是爲在用戶端中的每個執行緒使用一個獨立的Channel範例來進行數據傳輸,這樣就實現了不同線程之間的隔離.不過由於所有執行緒都共用一個TCP連線進行數據傳輸,如果傳輸的數據量小則問題不大,如果需要進行大數據量傳輸,則該TCP連線的頻寬就會成爲效能瓶頸,所以此時需要考慮使用多個TCP連線.
3. RabbitMQ伺服器Broker
在AMQP協定中,訊息佇列伺服器稱爲Broker.在Broker中接收生產者的產生的訊息,然後將該訊息放入到對應的訊息佇列中,最後再將訊息分發給這個訊息佇列對應的消費者.所以Broker內部通常包含數據交換器Exchanger,佇列Queue兩大元件和需要實現這兩大元件之間的系結.
3.1 交換器Exchanger
在RabbitMQ的設計當中,交換器主要用於分析生產者傳遞過來的訊息,根據訊息的路由資訊,即路由鍵route key,和自身維護的和佇列Queue的系結資訊來將將訊息放到對應的佇列中,或者如果沒有匹配的佇列,則丟棄該訊息或者扔回給生產者。
3.2 交換器型別
在RabbitMQ的交換器設計當中,交換器主要包含四種類型,分別爲fanout,direct,topic和headers.
3.3 佇列Queue與系結Binding
- 在RabbitMQ的設計當中,佇列Queue是進行數據存放的地方,即交換器Exchanger其實只是一個對映關係而已,不會實際佔用RabbitMQ伺服器的資源.而佇列Queue由於在消費者消費訊息之前,需要臨時存放生產者傳遞過來的訊息,故需要佔用伺服器的記憶體和磁碟資源.
- 預設情況下,RabbitMQ的數據是存放在記憶體中的,當消費者消費了佇列的訊息併發回了ACK確認時,RabbitMQ伺服器纔會將記憶體中的數據,即佇列Queue中的數據,標記爲刪除,並在之後某個時刻進行實際刪除.
- 不過RabbitMQ也會使用磁碟來存放訊息:
第一種場景是記憶體不夠用時,RabbitMQ伺服器會將記憶體中的數據臨時換出到磁碟中存放,之後當記憶體充足或者消費者需要消費時,再換回記憶體;
第二種場景是佇列Queue和生產者發送過來的訊息都是持久化型別的.其中佇列Queue持久化需要在建立該佇列時指定,而訊息的持久化爲通過設定訊息的deliveryMode屬性爲2來提示RabbitMQ伺服器持久化這條訊息到磁碟. - 如果RabbitMQ伺服器採用叢集部署,但是沒有開啓映象佇列,則訊息也是隻存放在一個佇列中的,這種情況下叢集的目的主要是在不同的機器節點部署不同的佇列Queue,從而來解決單機效能瓶頸,而不是解決數據的高可靠性.如果開啓了映象佇列,則是基於Master-Slave的模式,將佇列的數據複製到叢集其他節點的佇列中存放,從而實現數據高可用和高可靠.
4. 生產者
生產者主要負責投遞訊息到RabbitMQ伺服器broker.首先建立一個與broker的TCP連線,然後建立一個或者多個虛擬連線的Channel通道,在Channel中指定需要投遞的交換器,訊息的路由鍵和訊息內容,最後呼叫publish方法發佈到這個交換器.
4.1 路由鍵Route key
生產者需要指定訊息的路由鍵route key,路由鍵通常與broker的交換器和佇列之間的系結鍵binding key對應,然後結合交換器的型別,路由鍵和系結鍵來決定投遞給哪個佇列.如果沒有可以投遞的佇列,則丟失訊息或者返回訊息給生產者.
4.2 訊息確認機制 機製
訊息確認機制 機製主要用於保證生產者投遞的訊息成功到達RabbitMQ伺服器.具體爲成功到達RabbitMQ伺服器的交換器,如果此交換器沒有匹配的佇列,則也會丟失該訊息.
如果要保證數據成功到達佇列,則可以結合Java API的mandatory參數,即如果沒有匹配的佇列可投遞,則返回該訊息給生產者,有生產者設定回撥來處理,或者轉發給備份佇列來處理.
5. 消費者
消費者用於消費佇列中的訊息,與生產者類似,消費者也是作爲RabbitMQ伺服器的一個用戶端.即首先建立一個TCP連線,然後建立channel作爲消費者,從而實現不同channel對應不同隊列消費者.
在數據消費層面,RabbitMQ伺服器會將同一個佇列數據以輪詢的負載均衡方式分發給消費這個佇列的多個消費者,每個訊息預設只會給到其中一個消費者.
5.1 推模式和拉模式
消費者消費佇列中的數據可以基於推、拉兩種模式.其中推模式爲當RabbitMQ伺服器中的佇列有數據時,主動推播給消費者的channel;而拉模式則是消費者channel主動發起獲取數據的請求,每發起一次則獲取一次數據,不發起則不會獲取數據.如果在一個while死回圈中輪詢,則相當於推模式,不過這種方式很耗費資源,通常使用推模式代替.
5.2 訊息確認ACK與佇列的訊息刪除
在RabbitMQ的設計當中,RabbitMQ伺服器是不會主動刪除佇列中的訊息的,而是需要等到消費這條訊息的消費者發送ACK確認時纔會將佇列的這條訊息刪除.
注意:
RabbitMQ伺服器在等待消費者的ACK確認過程中,是沒有超時的概唸的.
如果該消費者的連線還存在且沒有回傳ACK,則這條訊息一直保留在該佇列中.如果該消費者連線斷了且沒有回傳ACK,則RabbitMQ伺服器將該訊息發送給另外一個消費者.
消費者確認可以使用自動確認和手動確認.其中自動確認會存在消費者還沒處理就崩潰的情況,此時出現數據丟失,是「至多一次」的場景;如果手動確認,存在處理完還沒提交ACK,則消費者崩潰,此時RabbitMQ會重複投遞給其他消費者,故是「至少一次」的場景,存在消費重複.
所以RabbitMQ在數據重複性和數據丟失方面,提供的是「至少一次」和「至多一次」的保證,不提供「恰好一次」的保證,即會存在重複訊息和丟失訊息.
5.3 訊息拒絕與重入隊
當消費者接收到RabbitMQ伺服器發送過來的訊息時,可以選擇拒絕這條訊息.消費者拒絕的時候,可以告訴RabbitMQ伺服器是否將該訊息重新入隊,如果是,則RabbitMQ伺服器會將該訊息重新投遞給其他消費者,否則丟棄這條訊息。