備戰秋招——演算法與數據結構(14)
1. 使用「反向代理伺服器」的優點是什麼?
(1)提高存取速度
由於目標主機返回的數據會存在代理伺服器的硬碟中,因此下一次客戶再存取相同的站 點數據時,會直接從代理伺服器的硬碟中讀取,起到了快取的作用,尤其對於熱門站點 能明顯提高請求速度。
(2)防火牆作用
由於所有的客戶機請求都必須通過代理伺服器存取遠端站點,因此可在代理伺服器上設 限,過濾某些不安全資訊。
(3)通過代理伺服器存取不能存取的目標站點
網際網路上有許多開發的代理伺服器,客戶機可存取受限時,可通過不受限的代理伺服器 存取目標站點,通俗說,我們使用的翻牆瀏覽器就是利用了代理伺服器,可直接存取外 網。
2. 右值參照和move語意
1.move語意
最原始的左值和右值定義可以追溯到C語言時代,左值是可以出現在賦值符的左邊 和右邊,然而右值只能出現在賦值符的右邊。在C++裡,這種方法作爲初步判斷左 值或右值還是可以的,但不只是那麼準確了。你要說C++中的右值到底是什麼,這 真的很難給出一個確切的定義。你可以對某個值進行取地址運算,如果不能得到地 址,那麼可以認爲這是個右值。例如:
int& foo();
foo() = 3; //ok, foo() is an lvalue
int bar();
int a = bar(); // ok, bar() is an rvalue
爲什麼要move語意呢?它可以讓你寫出更高效的程式碼。看下面 下麪程式碼:
string foo();
string name("jack");
name = foo();
第三句賦值會呼叫string的賦值操作符函數,發生了以下事情:
1.首先要銷燬name的字串吧
2.把foo()返回的臨時字串拷貝到name吧
3.最後還要銷燬foo()返回的臨時字串吧
這就顯得很不高效,在C++11之前,你要些的高效點,可以是swap交換資源。C++11 的move語意就是要做這事,這時過載move賦值操作符
string& string::operator=(string&& rhs);
move語意不僅僅用於右值,也用於左值。標準庫提供了std::move方法,將左值 轉換 成右值。因此,對於swap函數,我們可以這樣實現:
template<class T>
void swap(T& a, T& b)
{
T temp(std::move(a));
a = std::move(b);
b = std::move(temp);
}
2.右值參照
爲了支援移動操作,c++新標準引入了一種新的參照型別—右值參照。所謂右值引 用就是必須系結到右值的參照。我們通過&&而不是&來獲得右值參照。如我們將要 看到的,右值參照有一個重要的性質—只能系結到一個將要銷燬的物件。因此,我 們可以自由地將一個右值參照的資源「移動」到另一個物件中。
一般而言,一個左值表達式表示的是一個物件的身份,而一個右值表達式表示的是 物件的值。
舉例說明:
int i=42;
int &r=i; //正確,r參照i
int &&rr=i //錯誤,不能將一個右值參照系結到一個左值上
int &r2=i*42; //錯誤,i*42是一個右值
const int &r3=i*42; //正確,我們可以將一個const的參照系結到一個右值上
int &&r2=i*42; //正確,將rr2系結到乘法結果上
1.左值持久,右值短暫
左值有持久的狀態,而右值要麼是字面值常數,要麼是表達式求值過程中建立的臨 時物件。
由於右值參照只能系結到臨時物件,我們得知
1.所參照的物件將要被銷燬
2.該物件沒有其他使用者
這兩個特徵意味着:使用右值參照的程式碼可以自由地接管所參照的物件的資源。
3. kafka的生產者和消費者的理解
生產者:
Producer將訊息發佈到指定的Topic中,同時Producer也能決定將此訊息歸屬於哪個 partition;比如基於"round-robin"方式或者通過其他的一些演算法等.
消費者:
本質上kafka只支援Topic.每個consumer屬於一個consumer group;反過來說,每個 group中可以有多個consumer.發送到Topic的訊息,只會被訂閱此Topic的每個group 中的一個consumer消費.
如果所有的consumer都具有相同的group,這種情況和queue模式很像;訊息將會在 consumers之間負載均衡.
如果所有的consumer都具有不同的group,那這就是"發佈-訂閱";訊息將會廣播給所有 的消費者.
在kafka中,一個partition中的訊息只會被group中的一個consumer消費;每個group 中consumer訊息消費互相獨立;我們可以認爲一個group是一個"訂閱"者,一個Topic 中的每個partions,只會被一個"訂閱者"中的一個consumer消費,不過一個consumer 可以消費多個partitions中的訊息.kafka只能保證一個partition中的訊息被某個 consumer消費時,訊息是順序的.事實上,從Topic角度來說,訊息仍不是有序的.
4. kafka三種消費語意與保證精準消費
- 消費語意的介紹
at last once:至少消費一次(對一條訊息有可能多次消費,有可能會造成重複消費數 據)
原因:Proudcer產生數據的時候,已經寫入在broker中,但是由於broker的網 絡異常,沒有返回ACK,這時Producer,認爲數據沒有寫入成功,此時producer會再次 寫入,相當於一條數據,被寫入了多次。
at most once:最多消費一次,對於訊息,有可能消費一次,有可能一次也消費不了
原因:producer在產生數據的時候,有可能寫數據的時候不成功,此時broker就 跳過這個訊息,那麼這條數據就會丟失,導致consumer無法消費。
exactly once:有且僅有一次。這種情況是我們所需要的,也就是精準消費一次。
2.kafka中消費語意的場景
at last once:可以先讀取數據,處理數據,最後記錄offset,當然如果在記錄offset 之前就crash,新的consumer會重複的來消費這條數據,導致了」最少一次「
at most once:可以先讀取數據,然後記錄offset,最後在處理數據,這個方式,就 有可能在offset後,還沒有及時的處理數據,就crash了,導致了新的consumer繼續 從這個offset處理,那麼剛剛還沒來得及處理的數據,就永遠不會被處理,導致了」 最多消費一次「
exactly once:可以通過將提交分成兩個階段來解決:儲存了offset後提交一次,消 息處理成功後,再提交一次。
3.kafka中如何實現精準寫入數據?
A:Producer 端寫入數據的時候保證冪等性操作:
冪等性:對於同一個數據無論操作多少次都只寫入一條數據,如果重複寫入,則執 行不成功
B:broker寫入數據的時候,保證原子性操作, 要麼寫入成功,要麼寫入失敗。(不成 功不斷進行重試) - kafka中partition的工作原理?
Kafka叢集partition replication預設自動分配分析
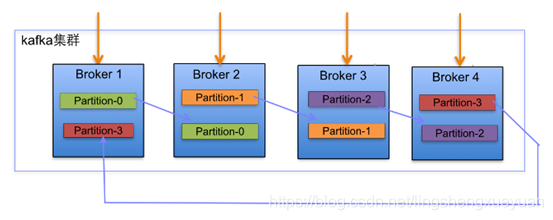
下面 下麪以Kafka叢集中4個Broker舉例,建立1個topic包含4個Partition,2 Replication;數據Producer流動如圖所示:
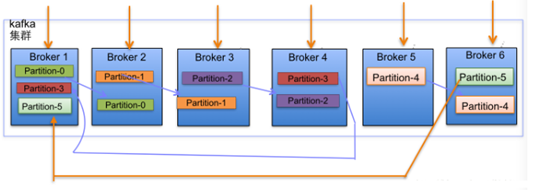
當叢集中新增2節點,Partition增加到6個時分佈情況如下:
副本分配邏輯規則如下:
在Kafka叢集中,每個Broker都有均等分配Partition的Leader機會。
上述圖Broker Partition中,箭頭指向爲副本,以Partition-0爲例:broker1中 parition-0爲Leader,Broker2中Partition-0爲副本。
上述圖種每個Broker(按照BrokerId有序)依次分配主Partition,下一個Broker爲副 本,如此回圈迭代分配,多副本都遵循此規則。
副本分配演算法如下:
將所有N Broker和待分配的i個Partition排序.
將第i個Partition分配到第(i mod n)個Broker上.
將第i個Partition的第j個副本分配到第((i + j) mod n)個Broker上.
另外需要完整版一線網際網路大廠面試題以及關於c++ Linux後臺伺服器開發的一些知識點分享:Linux,Nginx,MySQL,Redis,P2P,K8S,Docker,TCP/IP,協程,DPDK,webrtc,音視訊等等視訊。
vx關注零聲學院公衆號領取!
