深度學習之影象處理與分析
2020-08-12 14:21:29
深度學習之影象處理與分析
目錄
- 人工智慧和深度學習概論
- 影象基礎
- 深度學習基礎
- 深度學習的基本數學
- 理解的人工神經網路
人工智慧和深度學習概論
中國的AI
- 2017年7月,國務院發佈白皮書,使中國到2030年成爲全球AI領導者,行業價值1500億美元
- 到2030年投資70億美元,其中包括在北京的一個研究園的20億美元
- 全球AI資金佔主導地位48%,而美國在2017年爲38%
- 中國的AI公司總數爲23%,而美國2017年爲42%
AI與ML與DL
- Artificial intelligence(人工智慧)
- 使人類通常執行的智力任務自動化的努力
- Machine Learning(機器學習)
- 使系統無需進行顯式程式設計即可自動從數據進行改進
- Deep Learning(深度學習)
- 機器學習的特定子領域
- 側重於學習越來越有意義的表示形式的連續層
人工神經網路
- 最初於1950年代進行調查,始於1980年代
- 不是真正的大腦模型
- 受到神經生物學研究的寬鬆啓發
深度學習的深度如何?
- 深度學習是人工神經網路的重塑,具有兩層以上
- 「深入」並不是指通過這種方法獲得的更深刻的理解
- 它代表連續表示層的想法
深度學習框架
我們的深度學習技術堆疊

GPU和CUDA
- GPU(Graphics Processing Unit):
- 數百個更簡單的內核
- 數千個併發的硬體執行緒
- 最大化浮點吞吐量
- CUDA(Compute Unified Device Architecture)
- 並行程式設計模型,可通過利用GPU顯着提高計算效能
- cuDNN(CUDA深度神經網路庫)
- GPU加速的神經網路原語庫
- 它爲以下方面提供了高度優化的實現:折積,池化,規範化和啓用層
設定深度學習環境
- 安裝Anaconda3-5.2.0
- 安裝DL框架
- $ conda install -c conda-forge tensorflow
- $ conda install -c conda-forge keras
- 啓動Jupyter Server
- $ jupyter notebook
影象處理基礎
畫素
- 畫素是影象的原始構建塊。 每個影象都包含一組畫素
- 畫素被認爲是在影象中給定位置出現的光的「顏色」或「強度」
- 圖片的解析度爲1024x768,即1024畫素
- 寬768畫素高
灰度與顏色
- 在灰度影象中,每個畫素的標量值爲0到255之間,其中零對應於黑色,而255爲白色。 0到255之間的值是變化的灰色陰影
- RGB顏色空間中的畫素由三個值的列表表示:紅色代表一個值,綠色代表一個值,藍色代表另一個值
- 通過執行均值減法或縮放對輸入影象進行預處理,這是將影象轉換爲浮點數據型別所必需的
影象表示
- 我們可以將RGB影象概念化,該影象由寬度W和高度H的三個獨立矩陣組成,每個RGB分量一個
- RGB影象中的給定畫素是[0; 255]範圍內的三個整數的列表:紅色代表一個值,綠色代表第二個值,藍色代表最終值
- RGB影象可以以形狀(高度,寬度,深度)儲存在3D NumPy多維陣列中。
影象分類
- 影象分類是從一組預定義的類別中爲影象分配標籤的任務
- 假設計算機看到的只是一個很大的畫素矩陣,那麼如何以計算機可以理解的過程來表示影象
- 應用特徵提取以獲取輸入影象,應用演算法並獲得量化內容的特徵向量
- 我們的目標是應用深度學習演算法來發現影象集閤中的潛在模式,從而使我們能夠正確分類演算法尚未遇到的影象
深度學習基礎
數據處理
- 向量化
- 將原始數據轉換爲張量
- 正常化
- 所有特徵值均在同一範圍內,標準偏差爲1,平均值爲0
- 特徵工程
- 通過在建模之前將人類知識應用於數據來使演算法更好地工作
什麼是模型
- 在訓練數據集上訓練ML演算法時生成的函數
- 例如。 找出w和b的值,因此f(x)= wx + b緊密匹配數據點。
[外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-KEdBb6Nv-1597210412880)(https://i.loli.net/2020/05/07/oXVkl8pgTrnY7Wi.png)]
模型重量
- 模型權重=參數=內核
- 從訓練數據中學到的模型的可學習部分
- 學習開始之前,這些參數的值會隨機初始化
- 然後調整爲具有最佳輸出的值
- 模型超參數:
- 在實際優化模型參數之前手動設定變數
- 例如 學習率,批次大小,時代等
Optimizer(優化器)
- 通過動態調整學習率來確定如何更新網路權重
- 熱門優化器:
- SGD(隨機梯度下降)
- RMSProp(均方根傳播)
- 動量•Adam(自適應矩估計)
Loss Function(損失函數)
- 也稱爲誤差函數或成本函數
- 通過彙總整個數據集的誤差並求平均值來量化模型預測與地面真實程度的接近程度
- 查詢權重組合以最小化損失函數
- 廣泛使用的損失函數
- 交叉熵(對數損失)
- 均方誤差(MSE)
- 均值絕對誤差(MAE)
Weight Updates
[外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-UpOvuY6A-1597210412883)(https://i.loli.net/2020/05/07/qmlv7QHCiSKobep.png)]
學習率
- 控制我們在損耗梯度方面調整網路權重的程度
- 係數,用於衡量模型在損失函數中權重的大小
- 它確定演算法的下一步要使用多少梯度。
[外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-Ryrd3gqv-1597210412885)(https://i.loli.net/2020/05/07/CU1of9DQE3uV2BK.png)]
指標
- 研究人員使用度量標準來在每個時期後根據驗證集判斷模型的效能
- 分類指標
- 準確性
- 精確
- 召回
- 迴歸指標:
- 平均絕對誤差
- 均方誤差
深度學習的基本數學
- 線性代數:矩陣運算
- 微積分:微分,梯度下降
- 統計: 概率
Tensors(張量)
- 張量:
- 數值數據的容器
- 多維陣列
- 機器學習的基本數據結構
- ![外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-SFdTG8am-1597210412886)(https://i.loli.net/2020/05/07/M5WD6VopYdcA1Cn.png)]
Tensor Operations(張量運算)
- Element-wise product
- 將一個元素的每個元素與另一個元素的每個元素相乘
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-54v30Na0-1597210412886)(https://i.loli.net/2020/05/07/tZTvgy97UlQEPYM.png)]
Broadcasting(廣播)
- 廣播較小的張量以匹配較大的張量的形狀
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-y6mHyvKl-1597210412887)(https://i.loli.net/2020/05/07/JsVWmC6F1MUfwvz.png)]
Dot Product Example(點積的例子)
- 第一個矩陣的列數必須等於第二個矩陣的行數
- A(m, n) x B(n, k) = C(m, k)
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-KN1Bjpbd-1597210412888)(https://i.loli.net/2020/05/07/iCMNqAKEa4oWvw9.png)]
Derivative vs. Gradient (導數與梯度)
- 導數測量標量值的函數的「變化率」
- 梯度是張量的導數,導數的多維泛化
- 在一個變數的函數上定義了導數,而梯度爲 用於幾個變數的函數。
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-zx4OP1Q4-1597210412889)(https://i.loli.net/2020/05/07/lN9d4X8iocervjS.png)]
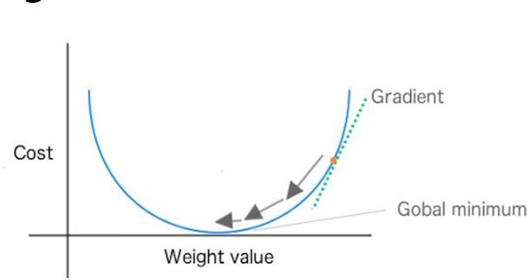
梯度下降
- 梯度下降法是找到一個函數的區域性最小值
- 成本函數告訴我們離全域性最小值有多遠
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-qvipg5E4-1597210412890)(https://i.loli.net/2020/05/07/nCdI9TKVL4Beqa6.png)]
人工神經網路
- 許多簡單的單元在沒有集中控制單元的情況下並行工作
- ANN由輸入/輸出層和隱藏層組成
- 每層中的單元都完全連線到前饋神經網路中相鄰層中的所有單元。
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-r2nCHWKU-1597210412891)(https://i.loli.net/2020/05/07/PYur1zgbXMdjGiy.png)]D:\App\hugo\XiaoHe\content\post\F5A4DEA36C00496FB8D89212EC7BF2D7)
神經元
- 神經元是人工神經網路的數學功能和基本處理元素
- 人工神經網路中的每個神經元都會對其所有輸入進行加權求和,新增一個恆定的偏差,然後通過非線性啓用函數提供結果
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-c0MFuQhH-1597210412891)(https://i.loli.net/2020/05/07/ELqThBntlwxpGIk.png)]
層數
- 一層是一個數據處理模組,使用張量作爲輸入和輸出張量。
- 隱藏層是網路外部無法觀察到的層
- 大多數層具有權重,而有些則沒有權重
- 每個層具有不同數量的單位
連線權重和偏差
- 放大輸入信號並抑制網路單元噪聲的係數。
- 通過減小某些權重,另一些權重較大,可以使某些功能有意義,並最小化其他功能,從而瞭解哪些結果有用。
- 偏差爲標量值 輸入,以確保無論信號強度如何,每層至少啓用幾個單位
- 本質上,ANN旨在優化權重和偏差以最小化誤差
Activation Functions(啓用函數)
- 當一個非零值從一個單元傳遞到另一個單元時,該值被啓用
- 啓用功能將輸入,權重和偏差的組合從一層轉換到下一層
- 將非線性引入網路的建模功能
流行的Activation Functions
- Sigmoid
- Tanh
- ReLU
- Leaky ReLU
- Softmax
- SoftPlus
案例研究:手寫數位分類
- LeCun等在1980年代組裝的MNIST數據集
- 70,000個具有28 x 28畫素正方形的樣本影象
- 多類分類問題
輸入層
- 使用28 x 28 = 784畫素作爲前饋網路輸入層中的輸入向量
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-wPL7Nakh-1597210412892)(https://i.loli.net/2020/05/07/FLEKIyp97jWSxbh.png)]
Sigmoid Functions
- 邏輯函數,可通過將任意值轉換爲[0,1]來預測輸出的可能性
- 每次梯度信號流過S型門時,其幅值始終最多減少0.25
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-YIryynqj-1597210412892)(https://i.loli.net/2020/05/07/oVthPfwcCbv6Lsn.png)]
Softmax Functions
- Softmax返回互斥輸出類上的概率分佈
- 結果向量清楚地顯示了max元素,該元素接近1,並保持順序
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-4nF3sYG9-1597210412893)(https://i.loli.net/2020/05/07/EpV5rWyBjdRqYl6.png)]
輸出層
- 在輸出層上使用Softmax將輸出轉換爲類似概率的值

Classification Loss Function(分類損失函數)
- 分類交叉熵衡量了多分類模型的效能
- [外連圖片轉存失敗,源站可能有防盜鏈機制 機製,建議將圖片儲存下來直接上傳(img-Iz0yNKa0-1597210412894)(https://i.loli.net/2020/05/07/BekEvlgd5ZhHLTR.png)]
- 在以上範例中,Y’是真實目標,而Y是模型的預測輸出。 輸出層由Sigmoid啓用
SGD, Batch and Epoch
- 隨機梯度下降(SGD),用於計算梯度並更新每個單個訓練樣本上的權重矩陣
- SGD使計算速度更快,而使用整個數據集會使向量化效率降低。
- 而不是對整個數據集或單個樣本計算梯度, 我們通常在mini-batch(16,32,64)上評估梯度,然後更新權重矩陣
- Epoch是所有訓練樣本的一個前向通過加一個向後通過