軟體工程管理-第六章軟體專案成本計劃
-
程式碼行估演算法:與具體的程式語言有關、分解足夠詳細、有一定的數據。優點:程式碼是所有軟件開發專案都有的「產品」,而且很容易計算程式碼行數。缺點:對程式碼行沒有公認的可接受的標準定義;程式碼行數量依賴於所用的程式語言和個人的程式設計風格;在專案早期,需求不穩定、設計不成熟、實現不確定的情況下很難準確地估算程式碼量;程式碼行強調編碼的工作量,只是專案實現階段的一部分。
-
功能點估演算法:與實現的語言和技術沒有關係,用系統的功能數量來測量其規模,通過評估、加權、量化得出功能點。功能點公式:FP=UFC*TCF UFC:未調整功能點計數 TCF:技術複雜度因子
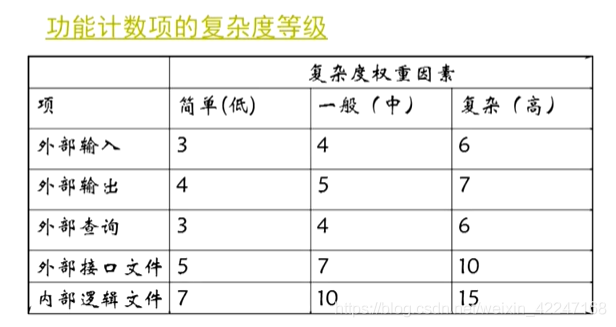
外部輸入:給軟體提供面嚮應用的數據的項(如螢幕、表單、對話方塊、控制元件、檔案等);在這個過程中,數據穿越外部邊界進入到系統內部。
外部輸出:向使用者提供(經過處理的)面嚮應用的資訊,例如,報表和出錯資訊等。
外部查詢:是一個輸入引出一個即時的簡單輸出,沒有處理過程。
外部介面檔案:使用者可以識別的一組邏輯相關數據,這組數據智慧被參照。用這些介面把資訊傳遞給另一個系統。
內部邏輯檔案:使用者可以識別的一組邏輯相關的數據,而且完全存在於應用的邊界之內,並且通過外部輸入維護,是邏輯主檔案的數目。
UFC未調整功能點計數
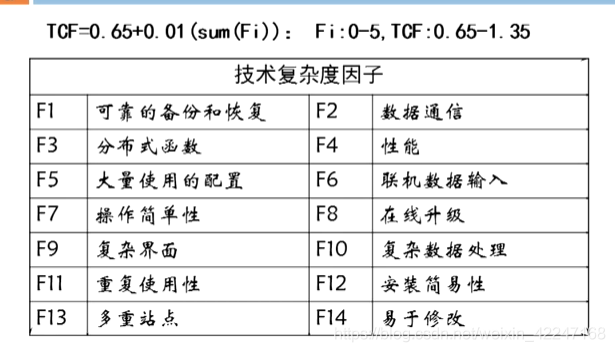
TFC計數複雜度因子:相加後乘以0.01+0.65
tcf 最大爲1.35,最小爲0.65
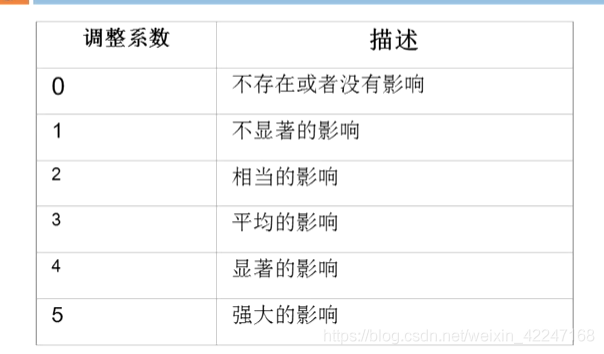
fi 0-5
-
用例點估演算法
計算未調整的角色的權值UAW;計算未調整的用例的權值UUCW;計算未調整的用例點;計算技術和環境因子TEF;計算調整的用例點UCP;計算工作量(man-hours)。 -
類比(自頂向下)估演算法
定義:估算人員根據以往的完成類似專案所消耗的總成本(或工作量),來推算將要開發的軟體的總成本(或工作量);是一種自上而下的估算形式。
使用情況:有類似的歷史專案數據;資訊不足的時候。 -
自下而上估演算法
定義:
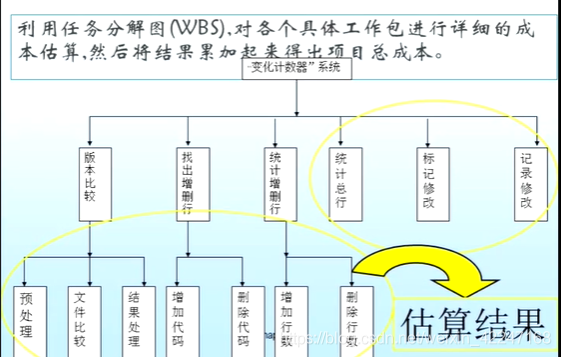
特點:相對比較準確,他的準確度來源於每個任務的估算情況;花費時間。 -
參數估演算法
定義:通過專案數據,得出迴歸模型;通過參數模型估算成本的方法。
使用條件:具有良好的專案數據爲基礎;存在成熟的專案估算模型。
特點:比較簡單,而且也比較準確;如果模型選擇不當或者數據不準 不準,也會導致偏差。
參數模型整體公式:E=a+b*S^c
E:以人月表示的工作量:經驗導出的係數 abc:經驗導出的係數 S:主要的輸入參數(通常是LOC、FP等)
Walston-Felix模型:E=5.2*(KLOC)^0.91,KLOC是原始碼行數,E是工作量(以PM計)
D=4.1*(KLOC)^0.36,D是專案持續時間(以月計)
S=0.54E^0.6,S是人員需要量(以人計)
DOC=49(KLOC)1.01,DOC是文件數量(以頁計)
COCOMO:結構化成本模型;是目前應用最廣泛的參數型軟體成本估計模型。
基本原理:

E=aX(KLOC)^b
E:工作量; KLOC:是交付的程式碼行; a,b:依賴於專案自然屬性的係數
-
專家估演算法:
基本概念:組織者確定專家,這些專家互相不見面;組織者給每位專家一份規格說明;
專家以無記名對該軟體給出3各規模的估算值:最小ai,最大bi,最可能mi。組織者計算美味專家的Ei=(ai+4mi+bi)/6;如果各個專家的估算差異超出規定的範圍。則重複上述過程;最終可以獲得一個多數專家共識的軟體規模:E=E1+E2+…En/n(n:表示n個專家) -
敏捷估演算法:
敏捷估算絲路:高層估算:採用輕量級、快速生成;短期估算:進行詳細的估算。
story point :故事點,用來度量實現一個Story需要付出的工作量的相對估算。
Fibonacci七個等級:
