DANet核心內容翻譯
2020-08-12 14:45:49
雙注意力機制 機製:
位置注意力模組:使用自監督機制 機製捕獲特徵對映任意兩個位置之間的空間依賴。對於特定位置的特徵,通過加權求和聚合所有位置的特徵來更新,權重由相應兩個位置之間的特徵相似性決定。任意兩個具有相似特徵的位置可以互相提升,不管距離多遠。
通道注意力模組。:捕獲任意兩個通道間的依賴,對所有通道對映加權求和來更新每個通道對映
ResNet把特徵圖縮小到原來的1/8,之後進行如下處理:
- 生成空間注意力矩陣,其爲特徵的任意兩個畫素之間的空間關係建模
- 注意力矩陣和原始特徵相乘。
- 將如上矩陣相乘的結果矩陣與原始特徵上的元素相加,來獲取反映長範圍上下文的最終表徵
對於通道注意力模組,與空間注意力相似,只是第一步在通道維計算通道注意力矩陣
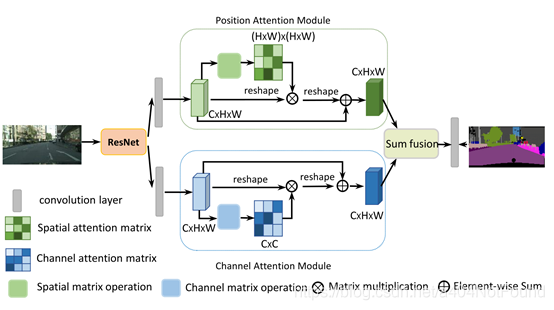
3.2位置注意力模組:
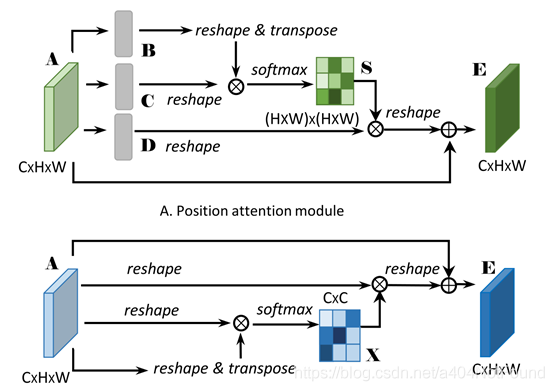
給定區域性特徵A(CxHxW),我們首先將其放入一個折積層來生成兩個新特徵對映B和C(B和C的形狀爲CxHxW),接着把他們變形爲CxN,其中N=HxW,它是畫素數量。然後我們在C的轉置和B之間使用矩陣相乘,再應用softmax層來計算空間注意力對映S(NxN)
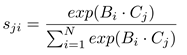
其中sji衡量了第i個位置對第j個位置的影響。兩個位置的特徵表示越相似,它們之間的相關性就越強。
同時,我們將特徵A放入折積層來生成新特徵對映D(CxHxW)並變形爲CxN。接着在D和轉置後的S使用矩陣相乘,並將結果變形爲CxHxW。最終,我們通過放縮參數α乘它,並與A元素級相加來獲取最終輸出E(CxHxW)如下:
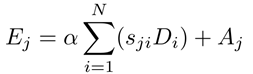
其中α以0初始化並逐漸學習來分配更多權重。可以由上式推導出每個位置的結果特徵E爲貫穿所有位置的特徵和原始特徵的加權求和。因此,它具有全域性上下文視野並根據空間注意力矩陣選擇性地聚合上下文。相似語意特徵實現了相互增益,增強了類間緊湊型和語意一致性。
3.3通道注意力模組
每個高層次特徵的通道對映可以視作特定類別的響應,不同語意響應相互關聯。通過探索通道對映間的相互依賴,我們可以強調相互依賴的特徵對映並提升特定語意的特徵表示。因此,我們建立了一個通道注意力模組來顯式地對通道間的相互依賴關係建模。
通道注意力模組的結構如圖所示。與位置注意力模組不同的是,我們直接從原始特徵A(CxHxW)計算通道注意力對映X(CxC)。特別地,我們將A變形成(CxN),接着將A與A的轉置使用矩陣乘法。最終我們使用softmax曾來獲取通道注意力對映X(CxC):
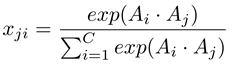
其中xji衡量了第i個通道對第j個通道的影響。而且,我們對X的轉置和A使用矩陣乘法並將結果變形成CxHxW。然後我們使用放縮參數β乘結果並與A逐元素相加獲得最終輸出E(CxHxW)
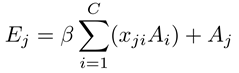
其中β從0逐漸學得權重。上式表明每個通道的最終特徵是所有通道特徵和原始特徵的加權求和,它對特徵對映間大範圍語意依賴建模。它幫助提升特徵可辨性。
程式碼網址https://github.com/junfu1115/DANet
encoding/models/danet.py
class DANet(BaseNet):
def __init__(self, nclass, backbone, aux=False, se_loss=False, norm_layer=nn.BatchNorm2d, **kwargs):
super(DANet, self).__init__(nclass, backbone, aux, se_loss, norm_layer=norm_layer, **kwargs)
self.head = DANetHead(2048, nclass, norm_layer)
def forward(self, x):
imsize = x.size()[2:]
_, _, c3, c4 = self.base_forward(x)
x = self.head(c4)
x = list(x)
x[0] = upsample(x[0], imsize, **self._up_kwargs)
x[1] = upsample(x[1], imsize, **self._up_kwargs)
x[2] = upsample(x[2], imsize, **self._up_kwargs)
outputs = [x[0]]
outputs.append(x[1])
outputs.append(x[2])
return tuple(outputs)
class DANetHead(nn.Module):
def __init__(self, in_channels, out_channels, norm_layer):
super(DANetHead, self).__init__()
inter_channels = in_channels // 4
self.conv5a = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv5c = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.sa = PAM_Module(inter_channels)
self.sc = CAM_Module(inter_channels)
self.conv51 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv52 = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels),
nn.ReLU())
self.conv6 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv7 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
self.conv8 = nn.Sequential(nn.Dropout2d(0.1, False), nn.Conv2d(inter_channels, out_channels, 1))
def forward(self, x):
feat1 = self.conv5a(x)
sa_feat = self.sa(feat1)
sa_conv = self.conv51(sa_feat)
sa_output = self.conv6(sa_conv)
feat2 = self.conv5c(x)
sc_feat = self.sc(feat2)
sc_conv = self.conv52(sc_feat)
sc_output = self.conv7(sc_conv)
feat_sum = sa_conv+sc_conv
sasc_output = self.conv8(feat_sum)
output = [sasc_output]
output.append(sa_output)
output.append(sc_output)
return tuple(output)
encoding/nn/attention.py
class PAM_Module(Module):
""" Position attention module"""
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
energy = torch.bmm(proj_query, proj_key)
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
class CAM_Module(Module):
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
energy = torch.bmm(proj_query, proj_key)
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
attention = self.softmax(energy_new)
proj_value = x.view(m_batchsize, C, -1)
out = torch.bmm(attention, proj_value)
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out