Python學習報告(二)
Python爬蟲實戰
文章目錄
一、寫在前面
在學習了一天的Python基礎語法之後,本着「學中幹,幹中學」的思想,我開始了菜雞的爬蟲生活
爬蟲網站
感謝圖吧給我這次練手機會
https://poi.mapbar.com/beijing/
選擇圖吧的原因如下:
- 沒有反爬機制 機製
- 整體結構清晰統一,可重複爬取
- 賈老師要求的(嘿嘿)
目的&思路
目的:獲取北京市旅遊、酒店、交通等類別的具體資訊及商家個人頁鏈接
思路:先從北京市頁面爬取各個類別下的所有的分類名和鏈接,然後回圈存取每一類,爬取所有商家資訊,最後整合成json格式檔案(jl也可)
工具:Requests獲取數據,lxml分析數據
依賴庫
- lxml
- requests
- json
二、具體流程
各大版塊分類抓取
抓取方法請看Xpath定位
url = "https://poi.mapbar.com/beijing/"
response = requests.get(url)
txt = response.text
html = etree.HTML(txt)
result = html.xpath('//div[@class="isortRow"]/h3/text()')
result2 = list(filter(lambda x:x!='\r\n\t\t\t\t',result))
with open('./各大板塊.txt','w',encoding='utf-8') as fp:
for i in result2:
fp.write(i)
先是從總的網頁讀取每一個板塊的名稱,因爲讀取出來的文字帶有’\r\n\t\t\t’,於是利用filter過濾一下
這裏有個問題,就是沒有文字的僅是’\r\n\t\t\t’的內容被過濾了,但是文字+’\r\n\t\t\t’的怎麼也處理不了,嘗試了replace無果,於是手動改了,這也是爲什麼最後程式碼會有本地讀取的原因(是我太菜了)
各個版塊下具體分類名及鏈接地址抓取
for i in range(0,10):
urlresult = html.xpath('/html/body/div[2]/div[3]/div['+str(i+1)+']/a/@href')
nameresult = html.xpath('/html/body/div[2]/div[3]/div['+str(i+1)+']/a/text()')
因爲網站分爲兩個div存放的位置,於是我具體讀取的時候就分成兩塊讀:0-10與0-8
網站資訊抓取
接下來就根據每一個具體類別和鏈接,一遍一遍爬就好了
#以讀取超市爲例
url = "https://poi.mapbar.com/beijing/520"
response = requests.get(url)
txt = response.text
html = etree.HTML(txt)
result1 = html.xpath('//div[@class="sortC"]/dl/dd/a/text()')
result2 = html.xpath('//div[@class="sortC"]/dl/dd/a/@href')
資訊儲存
爲了方便閱讀,用了json格式存放,如果需要瞭解更多可以看下方心得體會
with open('./標準化.json', 'a', encoding='utf-8') as fp:
json.dump({'板塊名稱': list5[i + 10*m],
'具體分類': nameresult[j],
'鏈接地址': urlresult[j],
'名稱': result1,
'相關鏈接': result2},
fp,ensure_ascii=False)
fp.write('\n')
三、心得體會
xpath定位
這裏要講一下xpath地址的抓取,因爲沒有什麼基礎,只要想要那個元素,但是不知道如何定位就是一個很大的問題
進入目標網站-右鍵-檢查
你就可以看到裏面的元素,然後根據選中的範圍一層一層的找到你想要的元素
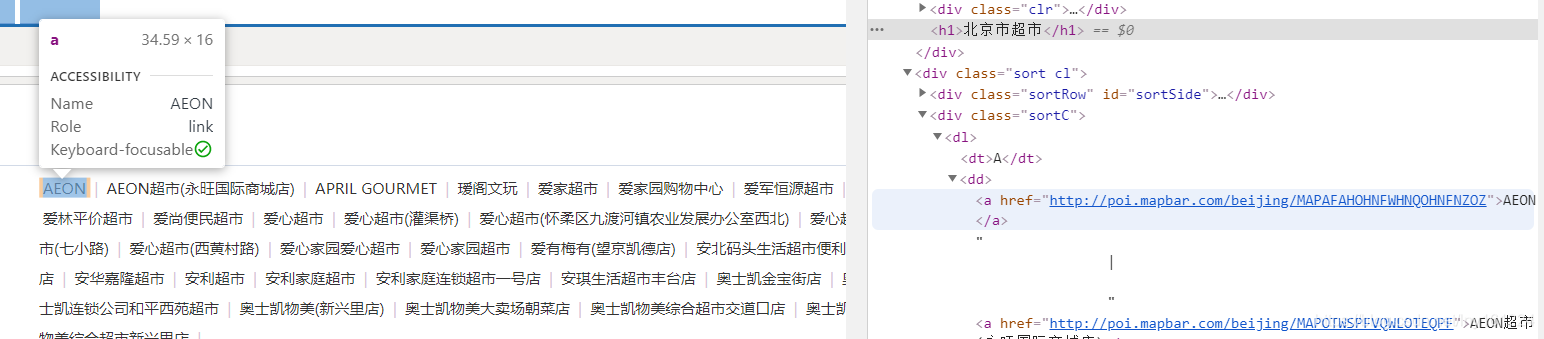
目標元素位置-右鍵-copy-xpath
這樣做你可以獲得它的絕對路徑,但是一般來說我們用不着那麼清晰
這個時候就要知道xpath好用的一點
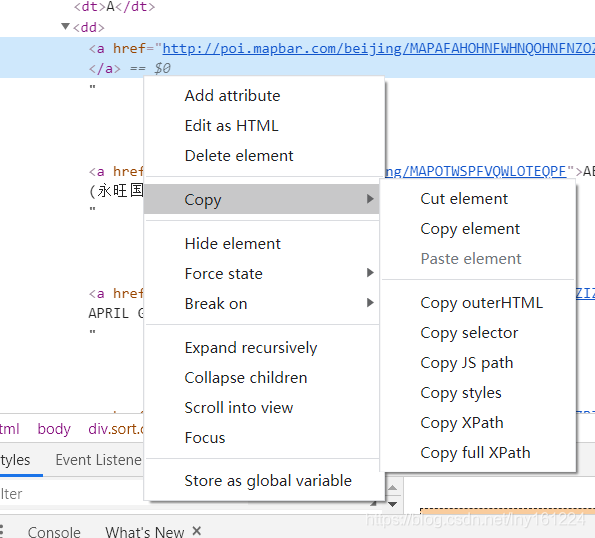
先給出Xpath的表示式
| 表達式 | 描述 |
|---|---|
| / | 從根節點選取 |
| // | 從匹配選擇的當前節點選擇文件中的節點,而不考慮它們的位置 |
| . | 選取當前節點 |
| … | 選取當前節點的父節點 |
| @ | 選取屬性。 |
我們可以看到超市裏面第一個AEON的元素有<div class=「sortC」>
我們就可以根據這個進行定位
result1 = html.xpath('//div[@class="sortC"]/dl/dd/a/text()')
result2 = html.xpath('//div[@class="sortC"]/dl/dd/a/@href')
雖然最後的標籤是a,但是a是一個物件,想要獲取它的文字資訊,一定要用a/text(),如果是獲取他的超鏈接地址用a/@href
動態分頁處理
在爬蟲的時候,發現了一個問題,如下:

(公司企業-其他公司企業)
本來想着用xpath去定位,結果發現是一個JS動態生成的。在賈老師的幫助下知道了分頁的機制 機製:
- 如果存取的是無分頁的網站,鏈接顯示爲:https://poi.mapbar.com/beijing/xxx/
- 如果存取的是動態分頁的網站,鏈接顯示爲:
https://poi.mapbar.com/beijing/xxx_1/
根據分頁不同更改數位即可 - 實際上存取https://poi.mapbar.com/beijing/xxx_1/ 實際就是在存取無分頁情況下的https://poi.mapbar.com/beijing/xxx/
於是對於每一個鏈接的存取,都改成xxx_1的存取方式,在存取成功後,嘗試性存取xxx_2,如果存取成功,則繼續讀取寫入該類別;如果返回404就放棄,開始存取下一個類別
url = url[:len(url)-1]+"_1/"
t=1
while True:
url = url[:len(url)-2]+str(t)+"/"
response = requests.get(url)
if requests.get(url).status_code==404:
break
存取限制
因爲爬取的數據量較大(最後合格的文件是60MB),本身存取請求次數較多,並且加上測試動態分頁的情況,存取次數又會加倍,很容易被目標網站限(dang)制(chang)訪(zhua)問(huo)
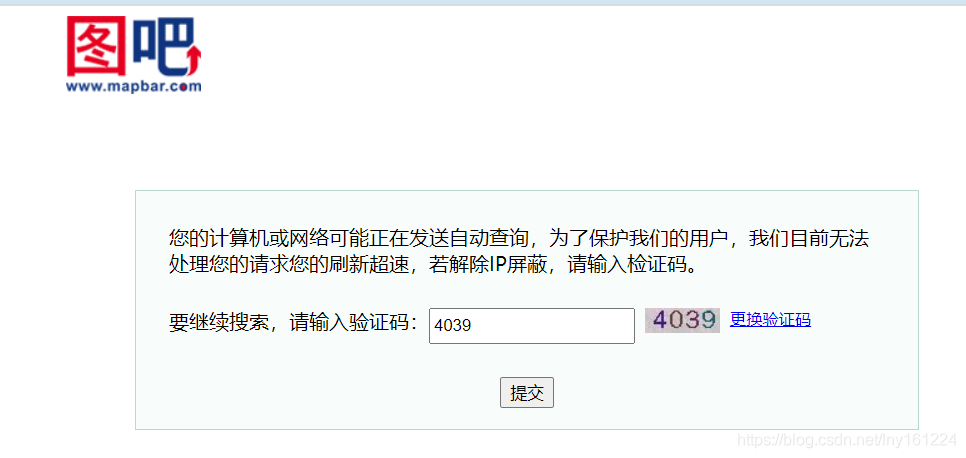
我先嚐試了time.sleep,在測試0.3s,0.5s,1s都失敗之後,我選擇了分成兩塊爬取。本來想着中間sleep十分鐘就可以了,結果繼續被限制…
最後我將整個爬蟲分成兩個板塊,不設定sleep,兩次爬蟲中間間隔3小時,get√
json儲存格式
原本存放json的程式碼是這樣的:
with open('./標準化.json', 'a', encoding='utf-8') as fp:
json.dump({'板塊名稱': list5[i + 10*m],
'具體分類': nameresult[j],
'鏈接地址': urlresult[j],
'名稱': result1,
'相關鏈接': result2}, fp)
結果發現有亂碼,並且難以閱讀
於是變成了這樣
with open('./標準化.json', 'a', encoding='utf-8') as fp:
json.dump({'板塊名稱': list5[i + 10*m],
'具體分類': nameresult[j],
'鏈接地址': urlresult[j],
'名稱': result1,
'相關鏈接': result2},
fp,ensure_ascii=False)
fp.write('\n')
寫入的每一行代表一個具體的設施資訊,利用ensure_ascii=False來解決了問題