java面試文章
文章目錄
- 一、Java 基礎
- 1.JDK 和 JRE 有什麼區別?
- 2. == 和 equals 的區別是什麼?
- 3.兩個物件的 hashCode()相同,則 equals()也一定爲 true,對嗎?
- 4.final 在 java 中有什麼作用?
- 5.java 中的 Math.round(-1.5) 等於多少?
- 6.String 屬於基礎的數據型別嗎?
- 7.java 中操作字串都有哪些類?它們之間有什麼區別?
- 8.String str="i"與 String str=new String(「i」)一樣嗎?
- 9.如何將字串反轉?
- 10.String 類的常用方法都有那些?
- 11.抽象類必須要有抽象方法嗎?
- 12.普通類和抽象類有哪些區別?
- 13.抽象類能使用 final 修飾嗎?
- 14.介面和抽象類有什麼區別?
- 15.java 中 IO 流分爲幾種?
- 16.BIO、NIO、AIO 有什麼區別?
- 17.Files的常用方法都有哪些?
- 二、容器
- 18.java 容器都有哪些?
- 19.Collection 和 Collections 有什麼區別?
- 20.List、Set、Map 之間的區別是什麼?
- 21.HashMap 和 Hashtable 有什麼區別?
- 22.如何決定使用 HashMap 還是 TreeMap?
- 23.說一下 HashMap 的實現原理?
- 24.說一下 HashSet 的實現原理?
- 25.ArrayList 和 LinkedList 的區別是什麼?
- 26.如何實現陣列和 List 之間的轉換?
- 27.ArrayList 和 Vector 的區別是什麼?
- 28.Array 和 ArrayList 有何區別?
- 29.在 Queue 中 poll()和 remove()有什麼區別?
- 30.哪些集合類是執行緒安全的?
- 31.迭代器 Iterator 是什麼?
- 32.Iterator 怎麼使用?有什麼特點?
- 33.Iterator 和 ListIterator 有什麼區別?
- 34.怎麼確保一個集合不能被修改?
- 附:阿裡騰訊校招Java面試題總結及答案
- 三、多執行緒
- 35.並行和併發有什麼區別?
- 36.執行緒和進程的區別?
- 37.守護執行緒是什麼?
- 38.建立執行緒有哪幾種方式?
- 39.說一下 runnable 和 callable 有什麼區別?
- 40.執行緒有哪些狀態?
- 41.sleep() 和 wait() 有什麼區別?
- 42.notify()和 notifyAll()有什麼區別?
- 43.執行緒的 run()和 start()有什麼區別?
- 44.建立執行緒池有哪幾種方式?
- 45.執行緒池都有哪些狀態?
- 46.執行緒池中 submit()和 execute()方法有什麼區別?
- 47.在 java 程式中怎麼保證多執行緒的執行安全?
- 48.多執行緒鎖的升級原理是什麼?
- 49.什麼是死鎖?
- 50.怎麼防止死鎖?
- 51.ThreadLocal 是什麼?有哪些使用場景?
- 52.說一下 synchronized 底層實現原理?
- 53.synchronized 和 volatile 的區別是什麼?
- 54.synchronized 和 Lock 有什麼區別?
- 55.synchronized 和 ReentrantLock 區別是什麼?
- 56.說一下 atomic 的原理?
- 四、反射
- 五、物件拷貝
- 六、Java Web
- 七、異常
- 八、網路
- 九、設計模式
- 十、Spring / Spring MVC
- 十一、Spring Boot / Spring Cloud
- 十二、Hibernate
- 113.爲什麼要使用 hibernate?
- 114.什麼是 ORM 框架?
- 115.hibernate 中如何在控制檯檢視列印的 sql 語句?
- 116.hibernate 有幾種查詢方式?
- 117.hibernate 實體類可以被定義爲 final 嗎?
- 118.在 hibernate 中使用 Integer 和 int 做對映有什麼區別?
- 119.hibernate 是如何工作的?
- 120.get()和 load()的區別?
- 121.說一下 hibernate 的快取機制 機製?
- 122.hibernate 物件有哪些狀態?
- 123.在 hibernate 中 getCurrentSession 和 openSession 的區別是什麼?
- 124.hibernate 實體類必須要有無參建構函式嗎?爲什麼?
- 十三、Mybatis
- 十四、RabbitMQ
- 135.rabbitmq 的使用場景有哪些?
- 136.rabbitmq 有哪些重要的角色?
- 137.rabbitmq 有哪些重要的元件?
- 138.rabbitmq 中 vhost 的作用是什麼?
- 139.rabbitmq 的訊息是怎麼發送的?
- 140.rabbitmq 怎麼保證訊息的穩定性?
- 141.rabbitmq 怎麼避免訊息丟失?
- 142.要保證訊息持久化成功的條件有哪些?
- 143.rabbitmq 持久化有什麼缺點?
- 144.rabbitmq 有幾種廣播型別?
- 145.rabbitmq 怎麼實現延遲訊息佇列?
- 146.rabbitmq 叢集有什麼用?
- 147.rabbitmq 節點的型別有哪些?
- 148.rabbitmq 叢集搭建需要注意哪些問題?
- 149.rabbitmq 每個節點是其他節點的完整拷貝嗎?爲什麼?
- 150.rabbitmq 叢集中唯一一個磁碟節點崩潰了會發生什麼情況?
- 151.rabbitmq 對叢集節點停止順序有要求嗎?
- 十五、Kafka
- 十六、Zookeeper
- 十七、MySQL
- 164.數據庫的三範式是什麼?
- 165.一張自增表裏面總共有 7 條數據,刪除了最後 2 條數據,重新啓動 mysql 數據庫,又插入了一條數據,此時 id 是幾?
- 166.如何獲取當前數據庫版本?
- 167.說一下 ACID 是什麼?
- 168.char 和 varchar 的區別是什麼?
- 169.float 和 double 的區別是什麼?
- 170.mysql 的內連線、左連線、右連線有什麼區別?
- 171.mysql 索引是怎麼實現的?
- 172.怎麼驗證 mysql 的索引是否滿足需求?
- 173.說一下數據庫的事務隔離?
- 174.說一下 mysql 常用的引擎?
- 175.說一下 mysql 的行鎖和表鎖?
- 176.說一下樂觀鎖和悲觀鎖?
- 177.mysql 問題排查都有哪些手段?
- 178.如何做 mysql 的效能優化?
- 十八、Redis
- 179.redis 是什麼?都有哪些使用場景?
- 180.redis 有哪些功能?
- 181.redis 和 memecache 有什麼區別?
- 182.redis 爲什麼是單執行緒的?
- 183.什麼是快取穿透?怎麼解決?
- 184.redis 支援的數據型別有哪些?
- 185.redis 支援的 java 用戶端都有哪些?
- 186.jedis 和 redisson 有哪些區別?
- 187.怎麼保證快取和數據庫數據的一致性?
- 188.redis 持久化有幾種方式?
- 189.redis 怎麼實現分佈式鎖?
- 190.redis 分佈式鎖有什麼缺陷?
- 191.redis 如何做記憶體優化?
- 192.redis 淘汰策略有哪些?
- 193.redis 常見的效能問題有哪些?該如何解決?
- 十九、JVM
溫馨提示
程式羊十分重視文章文字的排版(好的排版可以既改變一個讀者的心情,又可以爲讀者帶來視覺上的衝突),尤其是針對這些很長的閱讀類文章,所以本人花了好幾天的時間排版了文章和標註重要提示,希望能給你一個好的閱讀感覺。
適宜閱讀人羣
- 需要面試的初/中/高階 Java 程式設計師
- 想要查漏補缺的人
- 想要不斷完善和擴充自己 Java 技術棧的人
- Java 面試官
閱讀建議
本文會按技能模組劃分文章段落,每個模組裡的內容,從易到難依次進行排序,各模組之間不存在互相關聯的關係,讀者可選擇文章順序閱讀或者跳躍式閱讀。
包含的模組
本文分爲十九個模組,分別是: Java 基礎、容器、多執行緒、反射、物件拷貝、Java Web 、異常、網路、設計模式、Spring/Spring MVC、Spring Boot/Spring Cloud、Hibernate、MyBatis、RabbitMQ、Kafka、Zookeeper、MySQL、Redis、JVM ,如下圖所示:
一、Java 基礎
1.JDK 和 JRE 有什麼區別?
- JDK:Java Development Kit 的簡稱,Java 開發工具包,提供了 Java 的開發環境和執行環境。
- JRE:Java Runtime Environment 的簡稱,Java 執行環境,爲 Java 的執行提供了所需環境。
具體來說 JDK 其實包含了 JRE,同時還包含了編譯 Java 原始碼的編譯器 Javac,還包含了很多 Java 程式偵錯和分析的工具。簡單來說:如果你需要執行 Java 程式,只需安裝 JRE 就可以了,如果你需要編寫 Java 程式,需要安裝 JDK。
2. == 和 equals 的區別是什麼?
==解讀:
對於基本型別和參照型別 == 的作用效果是不同的,如下所示:
- 基本型別:比較的是值是否相同;
- 參照型別:比較的是參照是否相同;
程式碼範例:
String x = "string";
String y = 「string」;
String z = new String(「string」);
System.out.println(x==y); // true
System.out.println(x==z); // false
System.out.println(x.equals(y)); // true
System.out.println(x.equals(z)); // true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
程式碼解讀:
因爲 x 和 y 指向的是同一個參照,所以 == 也是 true,而 new String()方法則重寫開闢了記憶體空間,所以 == 結果爲 false,而 equals 比較的一直是值,所以結果都爲 true。
equals 解讀:
equals 本質上就是 ==,只不過 String 和 Integer 等重寫了 equals 方法,把它變成了值比較。看下面 下麪的程式碼就明白了。
首先來看預設情況下 equals 比較一個有相同值的物件,程式碼如下:
class Cat { public Cat(String name) { this.name = name; }<span class="token keyword">private</span> String name<span class="token punctuation">;</span> <span class="token keyword">public</span> String <span class="token function">getName</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">return</span> name<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">void</span> <span class="token function">setName</span><span class="token punctuation">(</span>String name<span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">this</span><span class="token punctuation">.</span>name <span class="token operator">=</span> name<span class="token punctuation">;</span> <span class="token punctuation">}</span>
}
Cat c1 = new Cat(「張三」);
Cat c2 = new Cat(「張三」);
System.out.println(c1.equals(c2)); // false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
輸出結果出乎我們的意料,竟然是 false?這是怎麼回事,看了 equals 原始碼就知道了,原始碼如下:
public boolean equals(Object obj) {
return (this == obj);
}
- 1
- 2
- 3
原來 equals 本質上就是 ==。
那問題來了,兩個相同值的 String 物件,爲什麼返回的是 true?程式碼如下:
String s1 = new String("李四");
String s2 = new String("李四");
System.out.println(s1.equals(s2)); // true
- 1
- 2
- 3
同樣的,當我們進入 String 的 equals 方法,找到了答案,程式碼如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
原來是 String 重寫了 Object 的 equals 方法,把參照比較改成了值比較。
總結 :
== 對於基本型別來說是值比較,對於參照型別來說是比較的是參照;而 equals 預設情況下是參照比較,只是很多類重寫了 equals 方法,比如 String、Integer 等把它變成了值比較,所以一般情況下 equals 比較的是值是否相等。
3.兩個物件的 hashCode()相同,則 equals()也一定爲 true,對嗎?
不對,兩個物件的 hashCode()相同,equals()不一定 true。
程式碼範例:
String str1 = "通話";
String str2 = "重地";
System.out.println(String.format("str1:%d | str2:%d", str1.hashCode(),str2.hashCode()));
System.out.println(str1.equals(str2));
- 1
- 2
- 3
- 4
執行的結果:
str1:1179395 | str2:1179395
false
- 1
- 2
程式碼解讀:
很顯然「通話」和「重地」的 hashCode() 相同,然而 equals() 則爲 false,因爲在雜湊表中,hashCode()相等即兩個鍵值對的雜湊值相等,然而雜湊值相等,並不一定能得出鍵值對相等。
4.final 在 java 中有什麼作用?
- final 修飾的類叫最終類,該類不能被繼承。
- final 修飾的方法不能被重寫。
- final 修飾的變數叫常數,常數必須初始化,初始化之後值就不能被修改。
5.java 中的 Math.round(-1.5) 等於多少?
等於 -1。
解析:
因爲在數軸上取值時,中間值(0.5)向右取整,所以正 0.5 是往上取整,負 0.5 是直接捨棄。
6.String 屬於基礎的數據型別嗎?
String 不屬於基礎型別,基礎型別有 8 種:byte、boolean、char、short、int、float、long、double,而 String 屬於物件。
7.java 中操作字串都有哪些類?它們之間有什麼區別?
操作字串的類有:String、StringBuffer、StringBuilder。
-
String 和 StringBuffer、StringBuilder 的區別在於 String 宣告的是不可變的物件,每次操作都會生成新的 String 物件,然後將指針指向新的 String 物件,而 StringBuffer、StringBuilder 可以在原有物件的基礎上進行操作,所以在經常改變字串內容的情況下最好不要使用 String。
-
StringBuffer 和 StringBuilder 最大的區別在於,StringBuffer 是執行緒安全的,而 StringBuilder 是非執行緒安全的,但 StringBuilder 的效能卻高於 StringBuffer,所以在單執行緒環境下推薦使用 StringBuilder,多執行緒環境下推薦使用 StringBuffer。
8.String str="i"與 String str=new String(「i」)一樣嗎?
不一樣,因爲記憶體的分配方式不一樣。String str="i"的方式,java 虛擬機器會將其分配到常數池中;而 String str=new String(「i」) 則會被分到堆記憶體中。
9.如何將字串反轉?
使用 StringBuilder 或者 stringBuffer 的 reverse() 方法。
範例程式碼:
// StringBuffer reverse
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("abcdefg");
System.out.println(stringBuffer.reverse()); // gfedcba
// StringBuilder reverse
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("abcdefg");
System.out.println(stringBuilder.reverse()); // gfedcba
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
10.String 類的常用方法都有那些?
- indexOf():返回指定字元的索引。
- charAt():返回指定索引處的字元。
- replace():字串替換。
- trim():去除字串兩端空白。
- split():分割字串,返回一個分割後的字串陣列。
- getBytes():返回字串的 byte 型別陣列。
- length():返回字串長度。
- toLowerCase():將字串轉成小寫字母。
- toUpperCase():將字串轉成大寫字元。
- substring():擷取字串。
- equals():字串比較。
11.抽象類必須要有抽象方法嗎?
不需要,抽象類不一定非要有抽象方法。
範例程式碼:
abstract class Cat {
public static void sayHi() {
System.out.println("hi~");
}
}
- 1
- 2
- 3
- 4
- 5
上面程式碼,抽象類並沒有抽象方法但完全可以正常執行。
12.普通類和抽象類有哪些區別?
- 普通類不能包含抽象方法,抽象類可以包含抽象方法。
- 抽象類不能直接範例化,普通類可以直接範例化。
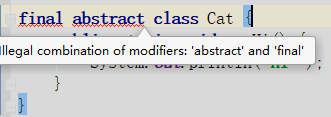
13.抽象類能使用 final 修飾嗎?
不能,定義抽象類就是讓其他類繼承的,如果定義爲 final 該類就不能被繼承,這樣彼此就會產生矛盾,所以 final 不能修飾抽象類,如下圖所示,編輯器也會提示錯誤資訊:
14.介面和抽象類有什麼區別?
- 實現:抽象類的子類使用 extends 來繼承;介面必須使用 implements 來實現介面。(即抽象類繼承(extends),介面實現(implements) )
- 建構函式:抽象類可以有建構函式;介面不能有。 (即抽象類中可以有不是抽象的方法,介面當中必須全是抽象方法(jdk1.8之前成立) )。
- main 方法:抽象類可以有 main 方法,並且我們能執行它;介面不能有 main 方法。
- 實現數量:類可以實現很多個介面;但是隻能繼承一個抽象類。 (即抽象類只能夠被單繼承,介面可以有多實現)
- 存取修飾符:介面中的方法預設使用 public 修飾;抽象類中的方法可以是任意存取修飾符。(即介面中變數全部預設是用public static final修飾的常數,抽象類中不限制 。)
- 修飾符不同,一個是abstract,一個是interface 。
15.java 中 IO 流分爲幾種?
- 按功能來分:輸入流(input)、輸出流(output)。
- 按型別來分:位元組流和字元流。
位元組流和字元流的區別是:位元組流按 8 位傳輸以位元組爲單位輸入輸出數據,字元流按 16 位傳輸以字元爲單位輸入輸出數據。
16.BIO、NIO、AIO 有什麼區別?
- BIO:Block IO 同步阻塞式 IO,就是我們平常使用的傳統 IO,它的特點是模式簡單使用方便,併發處理能力低。
- NIO:New IO 同步非阻塞 IO,是傳統 IO 的升級,用戶端和伺服器端通過 Channel(通道)通訊,實現了多路複用。
- AIO:Asynchronous IO 是 NIO 的升級,也叫 NIO2,實現了非同步非堵塞 IO ,非同步 IO 的操作基於事件和回撥機制 機製。
17.Files的常用方法都有哪些?
- Files.exists():檢測檔案路徑是否存在。
- Files.createFile():建立檔案。
- Files.createDirectory():建立資料夾。
- Files.delete():刪除一個檔案或目錄。
- Files.copy():複製檔案。
- Files.move():移動檔案。
- Files.size():檢視檔案個數。
- Files.read():讀取檔案。
- Files.write():寫入檔案。
二、容器
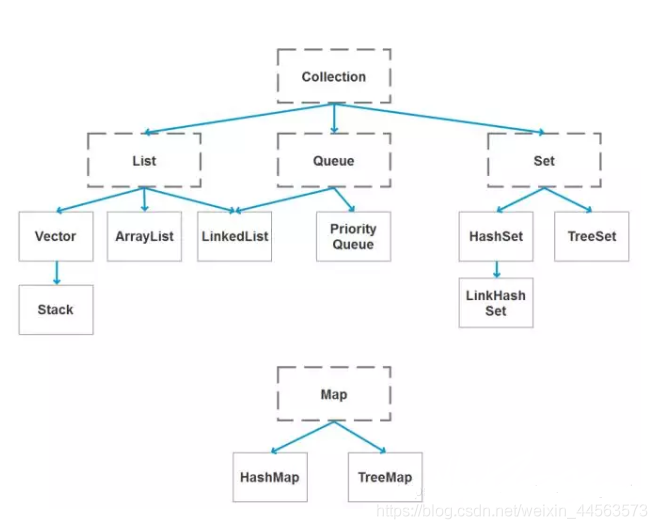
18.java 容器都有哪些?
Java 容器分爲 Collection 和 Map 兩大類,其下又有很多子類,如下所示:
19.Collection 和 Collections 有什麼區別?
java.util.Collection 是一個集合介面(集合類的一個頂級介面)。它提供了對集合物件進行基本操作的通用介面方法。Collection介面在Java 類庫中有很多具體的實現。Collection介面的意義是爲各種具體的集合提供了最大化的統一操作方式,其直接繼承介面有List與Set。
Collections則是集合類的一個工具類/幫助類,其中提供了一系列靜態方法,用於對集閤中元素進行排序、搜尋以及執行緒安全等各種操作。
第二種回答:
Collection 是一個集合介面,它提供了對集合物件進行基本操作的通用介面方法,所有集合都是它的子類,比如 List、Set 等。
Collections 是一個包裝類,包含了很多靜態方法,不能被範例化,就像一個工具類,比如提供的排序方法: Collections. sort(list)。
20.List、Set、Map 之間的區別是什麼?
List、Set、Map 的區別主要體現在兩個方面:元素是否有序、是否允許元素重複。三者之間的區別,如下表:
| 比較 | List | Set | Map |
|---|---|---|---|
| 繼承介面 | Collection | Collection | |
| 常見實現類 | AbstractList(其常用子類有ArrayList、LinkedList、Vector) | AbstractSet(其常用子類有HashSet、LinkedHashSet、TreeSet) | HashMap、HashTable |
| 常用方法 | add()、remove()、clear()、get()、contains()、size() | add()、remove()、clear()、contains()、size() | put()、get()、remove()、clear()、containsKey()、containsValue()、keySet()、values()、size() |
| 元素 | 可重複 | 不可重複(用equals()判斷) | 不可重複 |
| 順序 | 有序 | 無序(實際上由HashCode決定) | |
| 執行緒安全 | Vector執行緒安全 | HashTable執行緒安全 |
21.HashMap 和 Hashtable 有什麼區別?
- hashMap去掉了HashTable 的contains方法,但是加上了containsValue()和containsKey()方法。
- hashTable同步的,而HashMap是非同步的,效率上逼hashTable要高。
- hashMap允許空鍵值,而hashTable不允許。
第二種回答:
- 儲存:HashMap 執行 key 和 value 爲 null,而 Hashtable 不允許。
- 執行緒安全:Hashtable 是執行緒安全的,而 HashMap 是非執行緒安全的。
- 推薦使用:在 Hashtable 的類註釋可以看到,Hashtable 是保留類不建議使用,推薦在單執行緒環境下使用 HashMap 替代,如果需要多執行緒使用則用 ConcurrentHashMap 替代。
22.如何決定使用 HashMap 還是 TreeMap?
對於在Map中插入、刪除和定位元素這類操作,HashMap是最好的選擇。然而,假如你需要對一個有序的key集合進行遍歷,TreeMap是更好的選擇。基於你的collection的大小,也許向HashMap中新增元素會更快,將map換爲TreeMap進行有序key的遍歷。
23.說一下 HashMap 的實現原理?
HashMap概述:
HashMap是基於雜湊表的Map介面的非同步實現。此實現提供所有可選的對映操作,並允許使用null值和null鍵。此類不保證對映的順序,特別是它不保證該順序恆久不變。
HashMap的數據結構:
在java程式語言中,最基本的結構就是兩種,一個是陣列,另外一個是模擬指針(參照),所有的數據結構都可以用這兩個基本結構來構造的,HashMap也不例外。HashMap實際上是一個「鏈表雜湊」的數據結構,即陣列和鏈表的結合體。
當我們往Hashmap中put元素時,首先根據key的hashcode重新計算hash值,根絕hash值得到這個元素在陣列中的位置(下標);如果該陣列在該位置上已經存放了其他元素,那麼在這個位置上的元素將以鏈表的形式存放,新加入的放在鏈頭,最先加入的放入鏈尾;如果陣列中該位置沒有元素,就直接將該元素放到陣列的該位置上。
需要注意Jdk 1.8中對HashMap的實現做了優化,當鏈表中的節點數據超過八個之後,該鏈表會轉爲紅黑樹來提高查詢效率,從原來的O(n)到O(logn)。
第二種回答:
HashMap 基於 Hash 演算法實現的,我們通過 put(key,value)儲存,get(key)來獲取。當傳入 key 時,HashMap 會根據 key. hashCode() 計算出 hash 值,根據 hash 值將 value 儲存在 bucket 裡。當計算出的 hash 值相同時,我們稱之爲 hash 衝突,HashMap 的做法是用鏈表和紅黑樹儲存相同 hash 值的 value。當 hash 衝突的個數比較少時,使用鏈表否則使用紅黑樹。
24.說一下 HashSet 的實現原理?
- HashSet底層由HashMap實現
- HashSet的值存放於HashMap的key上
- HashMap的value統一爲PRESENT
第二種回答:
HashSet 是基於 HashMap 實現的,HashSet 底層使用 HashMap 來儲存所有元素,因此 HashSet 的實現比較簡單,相關 HashSet 的操作,基本上都是直接呼叫底層 HashMap 的相關方法來完成,HashSet 不允許重複的值。
25.ArrayList 和 LinkedList 的區別是什麼?
最明顯的區別是 ArrrayList底層的數據結構是陣列,支援隨機存取,而 LinkedList 的底層數據結構是雙向回圈鏈表,不支援隨機存取。使用下標存取一個元素,ArrayList 的時間複雜度是 O(1),而 LinkedList 是 O(n)。
第二種回答:
- 數據結構實現:ArrayList 是動態陣列的數據結構實現,而 LinkedList 是雙向鏈表的數據結構實現。
- 隨機存取效率:ArrayList 比 LinkedList 在隨機存取的時候效率要高,因爲 LinkedList 是線性的數據儲存方式,所以需要移動指針從前往後依次查詢。
- 增加和刪除效率:在非首尾的增加和刪除操作,LinkedList 要比 ArrayList 效率要高,因爲 ArrayList 增刪操作要影響陣列內的其他數據的下標。
綜合來說,在需要頻繁讀取集閤中的元素時,更推薦使用 ArrayList,而在插入和刪除操作較多時,更推薦使用 LinkedList。
26.如何實現陣列和 List 之間的轉換?
- List轉換成爲陣列:呼叫ArrayList的toArray方法。
- 陣列轉換成爲List:呼叫Arrays的asList(array) 方法。
程式碼範例:
// list to array
List<String> list = new ArrayList<String>();
list. add("張三");
list. add("李四");
list. toArray();
// array to list
String[] array = new String[]{"張三","李四"};
Arrays. asList(array);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
27.ArrayList 和 Vector 的區別是什麼?
- Vector是同步的,而ArrayList不是。然而,如果你尋求在迭代的時候對列表進行改變,你應該使用CopyOnWriteArrayList。
- ArrayList比Vector快,它因爲有同步,不會過載。
- ArrayList更加通用,因爲我們可以使用Collections工具類輕易地獲取同步列表和只讀列表。
第二種回答:
- 執行緒安全:Vector 使用了 Synchronized 來實現執行緒同步,是執行緒安全的,而 ArrayList 是非執行緒安全的。
- 效能:ArrayList 在效能方面要優於 Vector。
- 擴容:ArrayList 和 Vector 都會根據實際的需要動態的調整容量,只不過在 Vector 擴容每次會增加 1 倍,而 ArrayList 只會增加 50%。
28.Array 和 ArrayList 有何區別?
- Array可以容納(儲存)基本型別和物件,而ArrayList只能容納(儲存)物件。
- Array是指定大小後不可變的(即指定固定大小的),而ArrayList大小是可變的(即大小是自動擴充套件的)。
- Array沒有提供ArrayList那麼多功能,比如addAll、removeAll和iterator等方法只有 ArrayList 有。
29.在 Queue 中 poll()和 remove()有什麼區別?
poll() 和 remove() 都是從佇列中取出一個元素,但是 poll() 在獲取元素失敗的時候會返回空,但是 remove() 失敗的時候會拋出異常。
第二種回答:
- 相同點:都是返回第一個元素,並在佇列中刪除返回的物件。
- 不同點:如果沒有元素 poll()會返回 null,而 remove()會直接拋出 NoSuchElementException 異常。
程式碼範例:
Queue<String> queue = new LinkedList<String>();
queue. offer("string"); // add
System. out. println(queue. poll());
System. out. println(queue. remove());
System. out. println(queue. size());
- 1
- 2
- 3
- 4
- 5
30.哪些集合類是執行緒安全的?
- vector:就比arraylist多了個同步化機制 機製(執行緒安全),因爲效率較低,現在已經不太建議使用。在web應用中,特別是前臺頁面,往往效率(頁面響應速度)是優先考慮的。
- statck:堆疊類,先進後出。
- hashtable:就比hashmap多了個執行緒安全。
- enumeration:列舉,相當於迭代器。
第二種回答:
Vector、Hashtable、Stack 都是執行緒安全的,而像 HashMap 則是非執行緒安全的,不過在 JDK 1.5 之後隨着 Java. util. concurrent 併發包的出現,它們也有了自己對應的執行緒安全類,比如 HashMap 對應的執行緒安全類就是 ConcurrentHashMap。
31.迭代器 Iterator 是什麼?
迭代器是一種設計模式,它是一個物件,它可以遍歷並選擇序列中的物件,而開發人員不需要瞭解該序列的底層結構。迭代器通常被稱爲「輕量級」物件,因爲建立它的代價小。
第二種回答:
Iterator 介面提供遍歷任何 Collection 的介面。我們可以從一個 Collection 中使用迭代器方法來獲取迭代器範例。迭代器取代了 Java 集合框架中的 Enumeration,迭代器允許呼叫者在迭代過程中移除元素。
32.Iterator 怎麼使用?有什麼特點?
Java中的Iterator功能比較簡單,並且只能單向移動:
(1)使用方法iterator()要求容器返回一個Iterator。第一次呼叫Iterator的next()方法時,它返回序列的第一個元素。注意:iterator()方法是java.lang.Iterable介面,被Collection繼承。
(2)使用next()獲得序列中的下一個元素。
(3)使用hasNext()檢查序列中是否還有元素。
(4)使用remove()將迭代器新返回的元素刪除。
Iterator是Java迭代器最簡單的實現,爲List設計的ListIterator具有更多的功能,它可以從兩個方向遍歷List,也可以從List中插入和刪除元素。
第二種回答:
Iterator 使用程式碼如下:
List<String> list = new ArrayList<>();
Iterator<String> it = list. iterator();
while(it. hasNext()){
String obj = it. next();
System. out. println(obj);
}
- 1
- 2
- 3
- 4
- 5
- 6
Iterator 的特點是更加安全,因爲它可以確保,在當前遍歷的集合元素被更改的時候,就會拋出 ConcurrentModificationException 異常。
33.Iterator 和 ListIterator 有什麼區別?
- Iterator可用來遍歷Set和List集合,但是ListIterator只能用來遍歷List。
- Iterator對集合只能是前向遍歷(即單向遍歷),ListIterator既可以前向也可以後向(即雙向遍歷)。
- ListIterator實現了Iterator介面,幷包含其他的功能,比如:增加元素,替換元素,獲取前一個和後一個元素的索引,等等。
34.怎麼確保一個集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法來建立一個只讀集合,這樣改變集合的任何操作都會拋出 Java. lang. UnsupportedOperationException 異常。
範例程式碼如下:
List<String> list = new ArrayList<>();
list. add("x");
Collection<String> clist = Collections. unmodifiableCollection(list);
clist. add(「y」); // 執行時此行報錯
System. out. println(list. size());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
附:阿裡騰訊校招Java面試題總結及答案
1.HashMap的工作原理是什麼?
HashMap內部是通過一個數組實現的,只是這個陣列比較特殊,數組裏儲存的元素是一個Entry實體(jdk 8爲Node),這個Entry實體主要包含key、value以及一個指向自身的next指針。HashMap是基於hashing實現的,當我們進行put操作時,根據傳遞的key值得到它的hashcode,然後再用這個hashcode與陣列的長度進行模運算,得到一個int值,就是Entry要儲存在陣列的位置(下標);當通過get方法獲取指定key的值時,會根據這個key算出它的hash值(陣列下標),根據這個hash值獲取陣列下標對應的Entry,然後判斷Entry裡的key,hash值或者通過equals()比較是否與要查詢的相同,如果相同,返回value,否則的話,遍歷該鏈表(有可能就只有一個Entry,此時直接返回null),直到找到爲止,否則返回null。
HashMap之所以在每個陣列元素儲存的是一個鏈表,是爲了解決hash衝突問題,當兩個物件的hash值相等時,那麼一個位置肯定是放不下兩個值的,於是hashmap採用鏈表來解決這種衝突,hash值相等的兩個元素會形成一個鏈表。
2.HashMap與HashTable的區別是什麼?
(1)HashTable基於Dictionary類,而HashMap是基於AbstractMap。Dictionary是任何可將鍵對映到相應值的類的抽象父類別,而AbstractMap是基於Map介面的實現,它以最大限度地減少實現此介面所需的工作。
(2)HashMap的key和value都允許爲null,而Hashtable的key和value都不允許爲null。HashMap遇到key爲null的時候,呼叫putForNullKey方法進行處理,而對value沒有處理;Hashtable遇到null,直接返回NullPointerException。
(3)Hashtable是同步的,而HashMap是非同步的,但是我們也可以通過Collections.synchronizedMap(hashMap),使其實現同步。
3.CorrentHashMap的工作原理?
jdk 1.6版: ConcurrenHashMap可以說是HashMap的升級版,ConcurrentHashMap是執行緒安全的,但是與Hashtablea相比,實現執行緒安全的方式不同。Hashtable是通過對hash表結構進行鎖定,是阻塞式的,當一個執行緒佔有這個鎖時,其他執行緒必須阻塞等待其釋放鎖。ConcurrentHashMap是採用分離鎖的方式,它並沒有對整個hash表進行鎖定,而是區域性鎖定,也就是說當一個執行緒佔有這個區域性鎖時,不影響其他執行緒對hash表其他地方的存取。
具體實現: ConcurrentHashMap內部有一個Segment陣列, 該Segment物件可以充當鎖。Segment物件內部有一個HashEntry陣列,於是每個Segment可以守護若幹個桶(HashEntry),每個桶又有可能是一個HashEntry連線起來的鏈表,儲存發生碰撞的元素。
每個ConcurrentHashMap在預設併發級下會建立包含16個Segment物件的陣列,每個陣列有若幹個桶,當我們進行put方法時,通過hash方法對key進行計算,得到hash值,找到對應的segment,然後對該segment進行加鎖,然後呼叫segment的put方法進行儲存操作,此時其他執行緒就不能訪問當前的segment,但可以存取其他的segment物件,不會發生阻塞等待。
jdk 1.8版 在jdk 8中,ConcurrentHashMap不再使用Segment分離鎖,而是採用一種樂觀鎖CAS演算法來實現同步問題,但其底層還是「陣列+鏈表->紅黑樹」的實現。
4.遍歷一個List有哪些不同的方式?
List<String> strList = new ArrayList<>();
//for-each
for(String str:strList) {
System.out.print(str);
}
//use iterator 儘量使用這種 更安全(fail-fast)
Iterator<String> it = strList.iterator();
while(it.hasNext) {
System.out.printf(it.next());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.fail-fast與fail-safe有什麼區別?
Iterator的fail-fast屬性與當前的集合共同起作用,因此它不會受到集閤中任何改動的影響。Java.util包中的所有集合類都被設計爲fail->fast的,而java.util.concurrent中的集合類都爲fail-safe的。當檢測到正在遍歷的集合的結構被改變時,Fail-fast迭代器拋出ConcurrentModificationException,而fail-safe迭代器從不拋出ConcurrentModificationException。
6.Array和ArrayList有何區別?什麼時候更適合用Array?
- Array可以容納基本型別和物件,而ArrayList只能容納物件。
- Array是指定大小的,而ArrayList大小是不固定的(即ArrayList的大小是可以動態變化的。)
7.哪些集合類提供對元素的隨機存取?
- ArrayList、HashMap、TreeMap和HashTable類提供對元素的隨機存取。
8.HashSet的底層實現是什麼?
通過看原始碼知道HashSet的實現是依賴於HashMap的,HashSet的值都是儲存在HashMap中的。在HashSet的構造法中會初始化一個HashMap物件,HashSet不允許值重複,因此,HashSet的值是作爲HashMap的key儲存在HashMap中的,當儲存的值已經存在時返回false。
9.LinkedHashMap的實現原理?
LinkedHashMap也是基於HashMap實現的,不同的是它定義了一個Entry header,這個header不是放在Table裡,它是額外獨立出來的。LinkedHashMap通過繼承hashMap中的Entry,並新增兩個屬性Entry before,after,和header結合起來組成一個雙向鏈表,來實現按插入順序或存取順序排序。LinkedHashMap定義了排序模式accessOrder,該屬性爲boolean型變數,對於存取順序,爲true;對於插入順序,則爲false。一般情況下,不必指定排序模式,其迭代順序即爲預設爲插入順序。
10.LinkedList和ArrayList的區別是什麼?
- ArrayList是基於陣列實現,LinkedList是基於鏈表實現
- ArrayList在查詢時速度快,LinkedList在插入與刪除時更具優勢
三、多執行緒
35.並行和併發有什麼區別?
- 並行是指兩個或者多個事件在同一時刻發生;而併發是指兩個或多個事件在同一時間間隔發生。
- 並行是在不同實體上的多個事件,併發是在同一實體上的多個事件。
- 在一臺處理器上「同時」處理多個任務,在多臺處理器上同時處理多個任務。如hadoop分佈式叢集。
所以併發程式設計的目標是充分的利用處理器的每一個核,以達到最高的處理效能。
第二種回答:
- 並行:多個處理器或多核處理器同時處理多個任務。
- 併發:多個任務在同一個 CPU 核上,按細分的時間片輪流(交替)執行,從邏輯上來看那些任務是同時執行。
如下圖:
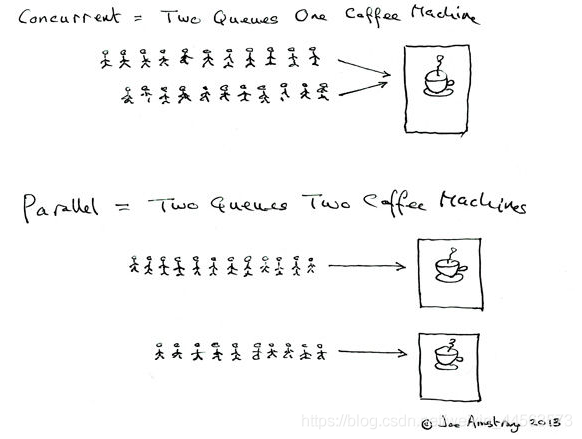
通俗來說:
- 併發 = 兩個佇列和一臺咖啡機。
- 並行 = 兩個佇列和兩臺咖啡機。
36.執行緒和進程的區別?
簡而言之,進程是程式執行和資源分配的基本單位,一個程式至少有一個進程,一個進程至少有一個執行緒。進程在執行過程中擁有獨立的記憶體單元,而多個執行緒共用記憶體資源,減少切換次數,從而效率更高。執行緒是進程的一個實體,是cpu排程和分派的基本單位,是比程式更小的能獨立執行的基本單位。同一進程中的多個執行緒之間可以併發執行。
第二種回答:
一個程式下至少有一個進程,一個進程下至少有一個執行緒,一個進程下也可以有多個執行緒來增加程式的執行速度。
37.守護執行緒是什麼?
- 守護執行緒(即daemon thread),是個服務執行緒,準確地來說就是服務其他的執行緒。
第二種回答:
守護執行緒是執行在後台的一種特殊進程。它獨立於控制終端並且週期性地執行某種任務或等待處理某些發生的事件。在 Java 中垃圾回收執行緒就是特殊的守護執行緒。
38.建立執行緒有哪幾種方式?
建立執行緒有三種方式:
- 繼承 Thread 重新 run 方法;
- 實現 Runnable 介面;
- 實現 Callable 介面。
詳細介紹:
①. 繼承Thread類建立執行緒類
- 定義Thread類的子類,並重寫該類的run方法,該run方法的方法體就代表了執行緒要完成的任務。因此把run()方法稱爲執行體。
- 建立Thread子類的範例,即建立了執行緒物件。
- 呼叫執行緒物件的start()方法來啓動該執行緒。
②. 通過Runnable介面建立執行緒類
- 定義runnable介面的實現類,並重寫該介面的run()方法,該run()方法的方法體同樣是該執行緒的執行緒執行體。
- 建立 Runnable實現類的範例,並依此範例作爲Thread的target來建立Thread物件,該Thread物件纔是真正的執行緒物件。
- 呼叫執行緒物件的start()方法來啓動該執行緒。
③. 通過Callable和Future建立執行緒
- 建立Callable介面的實現類,並實現call()方法,該call()方法將作爲執行緒執行體,並且有返回值。
- 建立Callable實現類的範例,使用FutureTask類來包裝Callable物件,該FutureTask物件封裝了該Callable物件的call()方法的返回值。
- 使用FutureTask物件作爲Thread物件的target建立並啓動新執行緒。
- 呼叫FutureTask物件的get()方法來獲得子執行緒執行結束後的返回值。
39.說一下 runnable 和 callable 有什麼區別?
- 有點深的問題了,也看出一個Java程式設計師學習知識的廣度。
- Runnable介面中的run()方法的返回值是void,它做的事情只是純粹地去執行run()方法中的程式碼而已;
- Callable介面中的call()方法是有返回值的,是一個泛型,和Future、FutureTask配合可以用來獲取非同步執行的結果。
第二種回答:
runnable 沒有返回值,callable 可以拿到有返回值,callable 可以看作是 runnable 的補充。
40.執行緒有哪些狀態?
執行緒通常都有五種狀態,建立、就緒、執行、阻塞和死亡。
- 建立狀態。在生成執行緒物件,並沒有呼叫該物件的start方法,這是執行緒處於建立狀態。
- 就緒狀態。當呼叫了執行緒物件的start方法之後,該執行緒就進入了就緒狀態,但是此時執行緒排程程式還沒有把該執行緒設定爲當前執行緒,此時處於就緒狀態。線上程執行之後,從等待或者睡眠中回來之後,也會處於就緒狀態。
- 執行狀態。執行緒排程程式將處於就緒狀態的執行緒設定爲當前執行緒,此時執行緒就進入了執行狀態,開始執行run函數當中的程式碼。
- 阻塞狀態。執行緒正在執行的時候,被暫停,通常是爲了等待某個時間的發生(比如說某項資源就緒)之後再繼續執行。sleep,suspend,wait等方法都可以導致執行緒阻塞。
- 死亡狀態。如果一個執行緒的run方法執行結束或者呼叫stop方法後,該執行緒就會死亡。對於已經死亡的執行緒,無法再使用start方法令其進入就緒
拓展:
關係圖如下:
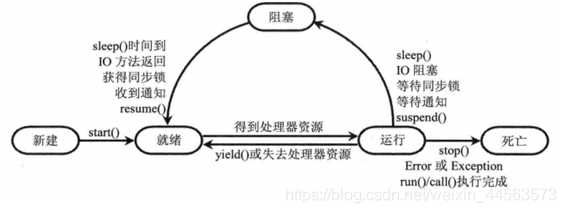
(1)執行緒 start 方法執行後,並不表示該執行緒執行了,而是進入就緒狀態,意思是隨時準備執行,但是真正何時執行,是由操作系統決定的,程式碼並不能控制,
(2)同樣的,從執行狀態的執行緒,也可能由於失去了 CPU 資源,回到就緒狀態,也是由操作系統決定的。這一步中,也可以由程式主動失去 CPU 資源,只需呼叫 yield 方法。
(3)執行緒執行完畢,或者執行了一半異常了,或者主動呼叫執行緒的 stop 方法,那麼就進入死亡。死亡的執行緒不可逆轉。
(4)下面 下麪幾個行爲,會引起執行緒阻塞。
- 主動呼叫 sleep 方法。時間到了會進入就緒狀態
- 主動呼叫 suspend 方法。主動呼叫 resume 方法,會進入就緒狀態
- 呼叫了阻塞式 IO 方法。呼叫完成後,會進入就緒狀態。
- 試圖獲取鎖。成功的獲取鎖之後,會進入就緒狀態。
- 執行緒在等待某個通知。其它執行緒發出通知後,會進入就緒狀態
第二種回答:
執行緒的狀態:
- NEW 尚未啓動
- RUNNABLE 正在執行中
- BLOCKED 阻塞的(被同步鎖或者IO鎖阻塞)
- WAITING 永久等待狀態
- TIMED_WAITING 等待指定的時間重新被喚醒的狀態
- TERMINATED 執行完成
41.sleep() 和 wait() 有什麼區別?
-
sleep():方法是執行緒類(Thread)的靜態方法,讓呼叫執行緒進入睡眠狀態,讓出執行機會給其他執行緒,等到休眠時間結束後,執行緒進入就緒狀態和其他執行緒一起競爭cpu的執行時間。因爲sleep() 是static靜態的方法,他不能改變物件的機鎖,當一個synchronized塊中呼叫了sleep() 方法,執行緒雖然進入休眠,但是物件的機鎖沒有被釋放,其他執行緒依然無法存取這個物件。
-
wait():wait()是Object類的方法,當一個執行緒執行到wait方法時,它就進入到一個和該物件相關的等待池,同時釋放物件的機鎖,使得其他執行緒能夠存取,可以通過notify,notifyAll方法來喚醒等待的執行緒
第二種回答:
- 類的不同:sleep() 來自 Thread,wait() 來自 Object。
- 釋放鎖:sleep() 不釋放鎖;wait() 釋放鎖。
- 用法不同:sleep() 時間到會自動恢復;wait() 可以使用 notify()/notifyAll()直接喚醒。
42.notify()和 notifyAll()有什麼區別?
- 如果執行緒呼叫了物件的 wait()方法,那麼執行緒便會處於該物件的等待池中,等待池中的執行緒不會去競爭該物件的鎖。
- 當有執行緒呼叫了物件的 notifyAll()方法(喚醒所有 wait 執行緒)或 notify()方法(只隨機喚醒一個 wait 執行緒),被喚醒的的執行緒便會進入該物件的鎖池中,鎖池中的執行緒會去競爭該物件鎖。也就是說,呼叫了notify後只要一個執行緒會由等待池進入鎖池,而notifyAll會將該物件等待池內的所有執行緒移動到鎖池中,等待鎖競爭。
- 優先順序高的執行緒競爭到物件鎖的概率大,假若某執行緒沒有競爭到該物件鎖,它還會留在鎖池中,唯有執行緒再次呼叫 wait()方法,它纔會重新回到等待池中。而競爭到物件鎖的執行緒則繼續往下執行,直到執行完了 synchronized 程式碼塊,它會釋放掉該物件鎖,這時鎖池中的執行緒會繼續競爭該物件鎖。
第二種回答:
notifyAll()會喚醒所有的執行緒,notify()之後喚醒一個執行緒。notifyAll() 呼叫後,會將全部執行緒由等待池移到鎖池,然後參與鎖的競爭,競爭成功則繼續執行,如果不成功則留在鎖池等待鎖被釋放後再次參與競爭。而 notify()只會喚醒一個執行緒,具體喚醒哪一個執行緒由虛擬機器控制。
43.執行緒的 run()和 start()有什麼區別?
每個執行緒都是通過某個特定Thread物件所對應的方法run()來完成其操作的,方法run()稱爲執行緒體。通過呼叫Thread類的start()方法來啓動一個執行緒。
-
start()方法來啓動一個執行緒,真正實現了多執行緒執行。這時無需等待run方法體程式碼執行完畢,可以直接繼續執行下面 下麪的程式碼; 這時此執行緒是處於就緒狀態, 並沒有執行。 然後通過此Thread類呼叫方法run()來完成其執行狀態, 這裏方法run()稱爲執行緒體,它包含了要執行的這個執行緒的內容, Run方法執行結束, 此執行緒終止。然後CPU再排程其它執行緒。
-
run()方法是在本執行緒裡的,只是執行緒裡的一個函數,而不是多執行緒的。 如果直接呼叫run(),其實就相當於是呼叫了一個普通函數而已,直接待用run()方法必須等待run()方法執行完畢才能 纔能執行下面 下麪的程式碼,所以執行路徑還是隻有一條,根本就沒有執行緒的特徵,所以在多執行緒執行時要使用start()方法而不是run()方法。
第二種回答:
start() 方法用於啓動執行緒,run() 方法用於執行執行緒的執行時程式碼。run() 可以重複呼叫,而 start() 只能呼叫一次。
44.建立執行緒池有哪幾種方式?
①. newFixedThreadPool(int nThreads)
建立一個固定長度的執行緒池,每當提交一個任務就建立一個執行緒,直到達到執行緒池的最大數量,這時執行緒規模將不再變化,當執行緒發生未預期的錯誤而結束時,執行緒池會補充一個新的執行緒。
②. newCachedThreadPool()
建立一個可快取的執行緒池,如果執行緒池的規模超過了處理需求,將自動回收空閒執行緒,而當需求增加時,則可以自動新增新執行緒,執行緒池的規模不存在任何限制。
③. newSingleThreadExecutor()
這是一個單執行緒的Executor,它建立單個工作執行緒來執行任務,如果這個執行緒異常結束,會建立一個新的來替代它;它的特點是能確保依照任務在佇列中的順序來序列執行。
④. newScheduledThreadPool(int corePoolSize)
建立了一個固定長度的執行緒池,而且以延遲或定時的方式來執行任務,類似於Timer。
第二種回答:
執行緒池建立有七種方式,最核心的是最後一種:
-
newSingleThreadExecutor():它的特點在於工作執行緒數目被限製爲 1,操作一個無界的工作佇列,所以它保證了所有任務的都是被順序執行,最多會有一個任務處於活動狀態,並且不允許使用者改動執行緒池範例,因此可以避免其改變執行緒數目;
-
newCachedThreadPool():它是一種用來處理大量短時間工作任務的執行緒池,具有幾個鮮明特點:它會試圖快取執行緒並重用,當無快取執行緒可用時,就會建立新的工作執行緒;如果執行緒閒置的時間超過 60 秒,則被終止並移出快取;長時間閒置時,這種執行緒池,不會消耗什麼資源。其內部使用 SynchronousQueue 作爲工作佇列;
-
newFixedThreadPool(int nThreads):重用指定數目(nThreads)的執行緒,其背後使用的是無界的工作佇列,任何時候最多有 nThreads 個工作執行緒是活動的。這意味着,如果任務數量超過了活動佇列數目,將在工作佇列中等待空閒執行緒出現;如果有工作執行緒退出,將會有新的工作執行緒被建立,以補足指定的數目 nThreads;
-
newSingleThreadScheduledExecutor():建立單執行緒池,返回 ScheduledExecutorService,可以進行定時或週期性的工作排程;
-
newScheduledThreadPool(int corePoolSize):和newSingleThreadScheduledExecutor()類似,建立的是個 ScheduledExecutorService,可以進行定時或週期性的工作排程,區別在於單一工作執行緒還是多個工作執行緒;
-
newWorkStealingPool(int parallelism):這是一個經常被人忽略的執行緒池,Java 8 才加入這個建立方法,其內部會構建ForkJoinPool,利用Work-Stealing演算法,並行地處理任務,不保證處理順序;
-
ThreadPoolExecutor():是最原始的執行緒池建立,上面1-3建立方式都是對ThreadPoolExecutor的封裝。
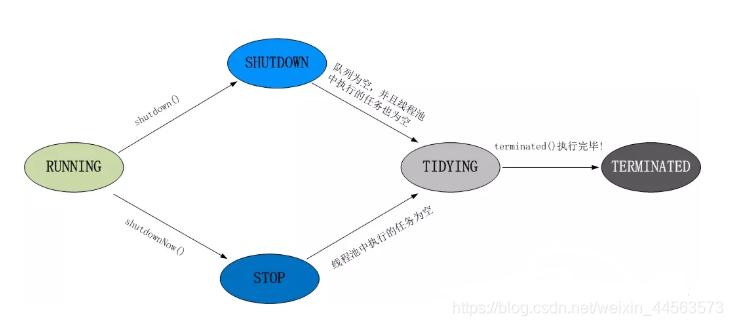
45.執行緒池都有哪些狀態?
- 執行緒池有5種狀態:Running、ShutDown、Stop、Tidying、Terminated。
第二種回答:
- RUNNING:這是最正常的狀態,接受新的任務,處理等待佇列中的任務。
- SHUTDOWN:不接受新的任務提交,但是會繼續處理等待佇列中的任務。
- STOP:不接受新的任務提交,不再處理等待佇列中的任務,中斷正在執行任務的執行緒。
- TIDYING:所有的任務都銷燬了,workCount 爲 0,執行緒池的狀態在轉換爲 TIDYING 狀態時,會執行勾點方法 terminated()。
- TERMINATED:terminated()方法結束後,執行緒池的狀態就會變成這個。
執行緒池各個狀態切換框架圖:
46.執行緒池中 submit()和 execute()方法有什麼區別?
- 接收的參數不一樣
- submit有返回值,而execute沒有
- submit方便Exception處理
第二種回答:
- execute():只能執行 Runnable 型別的任務。
- submit():可以執行 Runnable 和 Callable 型別的任務。
47.在 java 程式中怎麼保證多執行緒的執行安全?
執行緒安全在三個方面體現:
- 原子性:提供互斥存取,同一時刻只能有一個執行緒對數據進行操作,(atomic,synchronized);
- 可見性:一個執行緒對主記憶體的修改可以及時地被其他執行緒看到,(synchronized,volatile);
- 有序性:一個執行緒觀察其他執行緒中的指令執行順序,由於指令重排序,該觀察結果一般雜亂無序,(happens-before原則)。
第二種回答:
- 方法一:使用安全類,比如 Java. util. concurrent 下的類。
- 方法二:使用自動鎖 synchronized。
- 方法三:使用手動鎖 Lock。
手動鎖 Java 範例程式碼如下:
Lock lock = new ReentrantLock();
lock. lock();
try {
System. out. println("獲得鎖");
} catch (Exception e) {
// TODO: handle exception
} finally {
System. out. println("釋放鎖");
lock. unlock();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
48.多執行緒鎖的升級原理是什麼?
在Java中,鎖共有4種狀態,級別從低到高依次爲:無狀態鎖,偏向鎖,輕量級鎖和重量級鎖狀態,這幾個狀態會隨着競爭情況逐漸升級。鎖可以升級但不能降級。
鎖升級的圖示過程:
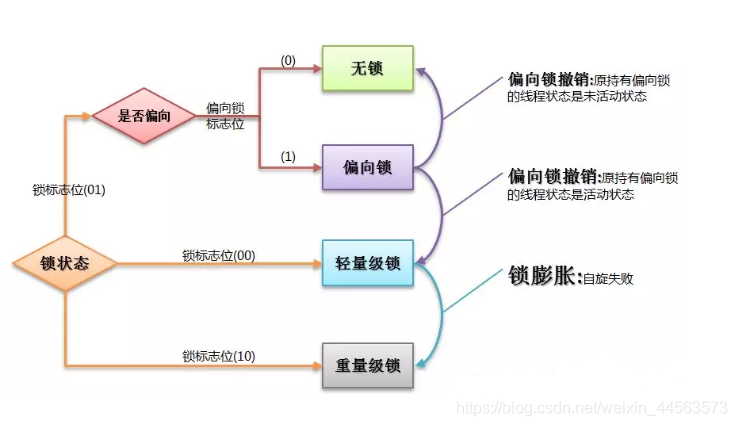
拓展:
多執行緒中 synchronized 鎖升級的原理是什麼?
synchronized 鎖升級原理:在鎖物件的物件頭裏面有一個 threadid 欄位,在第一次存取的時候 threadid 爲空,jvm 讓其持有偏向鎖,並將 threadid 設定爲其執行緒 id,再次進入的時候會先判斷 threadid 是否與其執行緒 id 一致,如果一致則可以直接使用此物件,如果不一致,則升級偏向鎖爲輕量級鎖,通過自旋回圈一定次數來獲取鎖,執行一定次數之後,如果還沒有正常獲取到要使用的物件,此時就會把鎖從輕量級升級爲重量級鎖,此過程就構成了 synchronized 鎖的升級。
鎖的升級的目的:鎖升級是爲了減低了鎖帶來的效能消耗。在 Java 6 之後優化 synchronized 的實現方式,使用了偏向鎖升級爲輕量級鎖再升級到重量級鎖的方式,從而減低了鎖帶來的效能消耗。
49.什麼是死鎖?
死鎖是指兩個或兩個以上的進程在執行過程中,由於競爭資源或者由於彼此通訊而造成的一種阻塞的現象,若無外力作用,它們都將無法推進下去。此時稱系統處於死鎖狀態或系統產生了死鎖,這些永遠在互相等待的進程稱爲死鎖進程。是操作系統層面的一個錯誤,是進程死鎖的簡稱,最早在 1965 年由 Dijkstra 在研究銀行家演算法時提出的,它是計算機操作系統乃至整個併發程式設計領域最難處理的問題之一。
第二種回答:
當執行緒 A 持有獨佔鎖a,並嘗試去獲取獨佔鎖 b 的同時,執行緒 B 持有獨佔鎖 b,並嘗試獲取獨佔鎖 a 的情況下,就會發生 AB 兩個執行緒由於互相持有對方需要的鎖,而發生的阻塞現象,我們稱爲死鎖。
50.怎麼防止死鎖?
死鎖的四個必要條件:
- 互斥條件:進程對所分配到的資源不允許其他進程進行存取,若其他進程存取該資源,只能等待,直至佔有該資源的進程使用完成後釋放該資源
- 請求和保持條件:進程獲得一定的資源之後,又對其他資源發出請求,但是該資源可能被其他進程佔有,此事請求阻塞,但又對自己獲得的資源保持不放
- 不可剝奪條件:是指進程已獲得的資源,在未完成使用之前,不可被剝奪,只能在使用完後自己釋放
- 環路等待條件:是指進程發生死鎖後,若幹進程之間形成一種頭尾相接的回圈等待資源關係
這四個條件是死鎖的必要條件,只要系統發生死鎖,這些條件必然成立,而只要上述條件之一不滿足,就不會發生死鎖。
理解了死鎖的原因,尤其是產生死鎖的四個必要條件,就可以最大可能地避免、預防和解除死鎖。
所以,在系統設計、進程排程等方面注意如何不讓這四個必要條件成立,如何確定資源的合理分配演算法,避免進程永久佔據系統資源。
此外,也要防止進程在處於等待狀態的情況下佔用資源。因此,對資源的分配要給予合理的規劃。
第二種回答:
- 儘量使用 tryLock(long timeout, TimeUnit unit)的方法(ReentrantLock、ReentrantReadWriteLock),設定超時時間,超時可以退出防止死鎖。
- 儘量使用 Java. util. concurrent 併發類代替自己手寫鎖。
- 儘量降低鎖的使用粒度,儘量不要幾個功能用同一把鎖。
- 儘量減少同步的程式碼塊。
51.ThreadLocal 是什麼?有哪些使用場景?
執行緒區域性變數是侷限於執行緒內部的變數,屬於執行緒自身所有,不在多個執行緒間共用。Java提供ThreadLocal類來支援執行緒區域性變數,是一種實現執行緒安全的方式。但是在管理環境下(如 web 伺服器)使用執行緒區域性變數的時候要特別小心,在這種情況下,工作執行緒的生命週期比任何應用變數的生命週期都要長。任何執行緒區域性變數一旦在工作完成後沒有釋放,Java 應用就存在記憶體泄露的風險。
第二種回答:
ThreadLocal 爲每個使用該變數的執行緒提供獨立的變數副本,所以每一個執行緒都可以獨立地改變自己的副本,而不會影響其它執行緒所對應的副本。
ThreadLocal 的經典使用場景是數據庫連線和 session 管理等。
52.說一下 synchronized 底層實現原理?
synchronized可以保證方法或者程式碼塊在執行時,同一時刻只有一個方法可以進入到臨界區,同時它還可以保證共用變數的記憶體可見性。
Java中每一個物件都可以作爲鎖,這是synchronized實現同步的基礎:
- 普通同步方法,鎖是當前範例物件
- 靜態同步方法,鎖是當前類的class物件
- 同步方法塊,鎖是括號裏面的物件
第二種回答:
synchronized 是由一對 monitorenter/monitorexit 指令實現的,monitor 物件是同步的基本實現單元。在 Java 6 之前,monitor 的實現完全是依靠操作系統內部的互斥鎖,因爲需要進行使用者態到內核態的切換,所以同步操作是一個無差別的重量級操作,效能也很低。但在 Java 6 的時候,Java 虛擬機器 對此進行了大刀闊斧地改進,提供了三種不同的 monitor 實現,也就是常說的三種不同的鎖:偏向鎖(Biased Locking)、輕量級鎖和重量級鎖,大大改進了其效能。
53.synchronized 和 volatile 的區別是什麼?
- volatile本質是在告訴jvm當前變數在暫存器(工作記憶體)中的值是不確定的,需要從主記憶體中讀取; synchronized則是鎖定當前變數,只有當前執行緒可以存取該變數,其他執行緒被阻塞住。
- volatile僅能使用在變數級別(是變數修飾符);synchronized則可以使用在變數、方法、和類級別的(是修飾類、方法、程式碼段)。
- volatile僅能實現變數的修改可見性,不能保證原子性;而synchronized則可以保證變數的修改可見性和原子性。
- volatile不會造成執行緒的阻塞;synchronized可能會造成執行緒的阻塞。
- volatile標記的變數不會被編譯器優化;synchronized標記的變數可以被編譯器優化。
54.synchronized 和 Lock 有什麼區別?
- 首先synchronized是java內建關鍵字,在jvm層面,Lock是個java類;
- synchronized無法判斷是否獲取鎖的狀態,Lock可以判斷是否獲取到鎖;
- synchronized會自動釋放鎖(a 執行緒執行完同步程式碼會釋放鎖 ;b 執行緒執行過程中發生異常會釋放鎖),Lock需在finally中手工釋放鎖(unlock()方法釋放鎖),否則容易造成執行緒死鎖;
- 用synchronized關鍵字的兩個執行緒1和執行緒2,如果當前執行緒1獲得鎖,執行緒2執行緒等待。如果執行緒1阻塞,執行緒2則會一直等待下去,而Lock鎖就不一定會等待下去,如果嘗試獲取不到鎖,執行緒可以不用一直等待就結束了;
- synchronized的鎖可重入、不可中斷、非公平,而Lock鎖可重入、可判斷、可公平(兩者皆可);
- Lock鎖適合大量同步的程式碼的同步問題,synchronized鎖適合程式碼少量的同步問題。
第二種回答:
- synchronized 可以給類、方法、程式碼塊加鎖;而 lock 只能給程式碼塊加鎖。
- synchronized 不需要手動獲取鎖和釋放鎖,使用簡單,發生異常會自動釋放鎖,不會造成死鎖;而 lock 需要自己加鎖和釋放鎖,如果使用不當沒有 unLock()去釋放鎖就會造成死鎖。
- 通過 Lock 可以知道有沒有成功獲取鎖,而 synchronized 卻無法辦到。
55.synchronized 和 ReentrantLock 區別是什麼?
synchronized是和if、else、for、while一樣的關鍵字,ReentrantLock是類,這是二者的本質區別。既然ReentrantLock是類,那麼它就提供了比synchronized更多更靈活的特性,可以被繼承、可以有方法、可以有各種各樣的類變數,ReentrantLock比synchronized的擴充套件性體現在幾點上:
- ReentrantLock可以對獲取鎖的等待時間進行設定,這樣就避免了死鎖
- ReentrantLock可以獲取各種鎖的資訊
- ReentrantLock可以靈活地實現多路通知
另外,二者的鎖機制 機製其實也是不一樣的:ReentrantLock藉助Unsafe 類的CAS操作來對鎖狀態(state)進行控制和獲取,synchronized操作的應該是物件頭中mark word。
第二種回答:
synchronized 早期的實現比較低效,對比 ReentrantLock,大多數場景效能都相差較大,但是在 Java 6 中對 synchronized 進行了非常多的改進。
主要區別如下:
- ReentrantLock 使用起來比較靈活,但是必須有釋放鎖的配合動作;
- ReentrantLock 必須手動獲取與釋放鎖,而 synchronized 不需要手動釋放和開啓鎖;
- ReentrantLock 只適用於程式碼塊鎖,而 synchronized 可用於修飾方法、程式碼塊等。
56.說一下 atomic 的原理?
Atomic包中的類基本的特性就是在多執行緒環境下,當有多個執行緒同時對單個(包括基本型別及參照型別)變數進行操作時,具有排他性,即當多個執行緒同時對該變數的值進行更新時,僅有一個執行緒能成功,而未成功的執行緒可以向自旋鎖一樣,繼續嘗試,一直等到執行成功。
Atomic系列的類中的核心方法都會呼叫unsafe類中的幾個本地方法。我們需要先知道一個東西就是Unsafe類,全名爲:sun.misc.Unsafe,這個類包含了大量的對C程式碼的操作,包括很多直接記憶體分配以及原子操作的呼叫,而它之所以標記爲非安全的,是告訴你這個裏面大量的方法呼叫都會存在安全隱患,需要小心使用,否則會導致嚴重的後果,例如在通過unsafe分配記憶體的時候,如果自己指定某些區域可能會導致一些類似C++一樣的指針越界到其他進程的問題。
第二種回答:
atomic 主要利用 CAS (Compare And Wwap) 和 volatile 和 native 方法來保證原子操作,從而避免 synchronized 的高開銷,執行效率大爲提升。
四、反射
57.什麼是反射?
- 反射主要是指程式可以存取、檢測和修改它本身狀態或行爲的一種能力
Java反射:
在Java執行時環境中,對於任意一個類,能否知道這個類有哪些屬性和方法?對於任意一個物件,能否呼叫它的任意一個方法。
Java反射機制 機製主要提供了以下功能:
- 在執行時判斷任意一個物件所屬的類。
- 在執行時構造任意一個類的物件。
- 在執行時判斷任意一個類所具有的成員變數和方法。
- 在執行時呼叫任意一個物件的方法。
第二種回答:
反射是在執行狀態中,對於任意一個類,都能夠知道這個類的所有屬性和方法;對於任意一個物件,都能夠呼叫它的任意一個方法和屬性;這種動態獲取的資訊以及動態呼叫物件的方法的功能稱爲 Java 語言的反射機制 機製。
58.什麼是 java 序列化?什麼情況下需要序列化?
簡單說就是爲了儲存在記憶體中的各種物件的狀態(也就是範例變數,不是方法),並且可以把儲存的物件狀態再讀出來。雖然你可以用你自己的各種各樣的方法來儲存object states,但是Java給你提供一種應該比你自己好的儲存物件狀態的機制 機製,那就是序列化。
什麼情況下需要序列化:
- (1)當你想把的記憶體中的物件狀態儲存到一個檔案中或者數據庫中時候;
- (2)當你想用通訊端在網路上傳送物件的時候;
- (3)當你想通過RMI(遠端方法呼叫)傳輸物件的時候;
59.動態代理是什麼?有哪些應用?
動態代理:
當想要給實現了某個介面的類中的方法,加一些額外的處理。比如說加日誌,加事務等。可以給這個類建立一個代理,故名思議就是建立一個新的類,這個類不僅包含原來類方法的功能,而且還在原來的基礎上新增了額外處理的新類。這個代理類並不是定義好的,是動態生成的。具有解耦意義,靈活,擴充套件性強。
動代理的應用:
- Spring的AOP
- 加事務
- 加許可權
- 加日誌
第二種回答:
- 動態代理是執行時動態生成代理類。
- 動態代理的應用有 spring aop、hibernate 數據查詢、測試框架的後端 mock、rpc,Java註解物件獲取等。
60.怎麼實現動態代理?
首先必須定義一個介面,還要有一個InvocationHandler(將實現介面的類的物件傳遞給它)處理類。再有一個工具類Proxy(習慣性將其稱爲代理類,因爲呼叫他的newInstance()可以產生代理物件,其實他只是一個產生代理物件的工具類)。利用到InvocationHandler,拼接代理類原始碼,將其編譯生成代理類的二進制碼,利用載入器載入,並將其範例化產生代理物件,最後返回。
第二種回答:
JDK 原生動態代理和 cglib 動態代理。JDK 原生動態代理是基於介面實現的,而 cglib 是基於繼承當前類的子類實現的。
五、物件拷貝
61.爲什麼要使用克隆?
想對一個物件進行處理,又想保留原有的數據進行接下來的操作,就需要克隆了,Java語言中克隆針對的是類的範例。
第二種回答:
克隆的物件可能包含一些已經修改過的屬性,而 new 出來的物件的屬性都還是初始化時候的值,所以當需要一個新的物件來儲存當前物件的「狀態」就靠克隆方法了。
62.如何實現物件克隆?
有兩種方式:
- 實現Cloneable介面並重寫Object類中的clone()方法;
- 實現Serializable介面,通過物件的序列化和反序列化實現克隆,可以實現真正的深度克隆,程式碼如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class MyUtil {
<span class="token keyword">private</span> <span class="token function">MyUtil</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">throw</span> <span class="token keyword">new</span> <span class="token class-name">AssertionError</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token annotation punctuation">@SuppressWarnings</span><span class="token punctuation">(</span><span class="token string">"unchecked"</span><span class="token punctuation">)</span>
<span class="token keyword">public</span> <span class="token keyword">static</span> <span class="token operator"><</span>T <span class="token keyword">extends</span> <span class="token class-name">Serializable</span><span class="token operator">></span> T <span class="token function">clone</span><span class="token punctuation">(</span>T obj<span class="token punctuation">)</span> <span class="token keyword">throws</span> Exception <span class="token punctuation">{</span>
ByteArrayOutputStream bout <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">ByteArrayOutputStream</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
ObjectOutputStream oos <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">ObjectOutputStream</span><span class="token punctuation">(</span>bout<span class="token punctuation">)</span><span class="token punctuation">;</span>
oos<span class="token punctuation">.</span><span class="token function">writeObject</span><span class="token punctuation">(</span>obj<span class="token punctuation">)</span><span class="token punctuation">;</span>
ByteArrayInputStream bin <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">ByteArrayInputStream</span><span class="token punctuation">(</span>bout<span class="token punctuation">.</span><span class="token function">toByteArray</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
ObjectInputStream ois <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">ObjectInputStream</span><span class="token punctuation">(</span>bin<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">return</span> <span class="token punctuation">(</span>T<span class="token punctuation">)</span> ois<span class="token punctuation">.</span><span class="token function">readObject</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token comment">// 說明:呼叫ByteArrayInputStream或ByteArrayOutputStream物件的close方法沒有任何意義</span>
<span class="token comment">// 這兩個基於記憶體的流只要垃圾回收器清理物件就能夠釋放資源,這一點不同於對外部資源(如檔案流)的釋放</span>
<span class="token punctuation">}</span>
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
下面 下麪是測試程式碼:
import java.io.Serializable;
/**
- 人類
- @author nnngu
*/
class Person implements Serializable {
private static final long serialVersionUID = -9102017020286042305L;
<span class="token keyword">private</span> String name<span class="token punctuation">;</span> <span class="token comment">// 姓名</span>
<span class="token keyword">private</span> <span class="token keyword">int</span> age<span class="token punctuation">;</span> <span class="token comment">// 年齡</span>
<span class="token keyword">private</span> Car car<span class="token punctuation">;</span> <span class="token comment">// 座駕</span>
<span class="token keyword">public</span> <span class="token function">Person</span><span class="token punctuation">(</span>String name<span class="token punctuation">,</span> <span class="token keyword">int</span> age<span class="token punctuation">,</span> Car car<span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">this</span><span class="token punctuation">.</span>name <span class="token operator">=</span> name<span class="token punctuation">;</span>
<span class="token keyword">this</span><span class="token punctuation">.</span>age <span class="token operator">=</span> age<span class="token punctuation">;</span>
<span class="token keyword">this</span><span class="token punctuation">.</span>car <span class="token operator">=</span> car<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">public</span> String <span class="token function">getName</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">return</span> name<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">public</span> <span class="token keyword">void</span> <span class="token function">setName</span><span class="token punctuation">(</span>String name<span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">this</span><span class="token punctuation">.</span>name <span class="token operator">=</span> name<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">public</span> <span class="token keyword">int</span> <span class="token function">getAge</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">return</span> age<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">public</span> <span class="token keyword">void</span> <span class="token function">setAge</span><span class="token punctuation">(</span><span class="token keyword">int</span> age<span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">this</span><span class="token punctuation">.</span>age <span class="token operator">=</span> age<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">public</span> Car <span class="token function">getCar</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">return</span> car<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token keyword">public</span> <span class="token keyword">void</span> <span class="token function">setCar</span><span class="token punctuation">(</span>Car car<span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">this</span><span class="token punctuation">.</span>car <span class="token operator">=</span> car<span class="token punctuation">;</span>
<span class="token punctuation">}</span>
<span class="token annotation punctuation">@Override</span>
<span class="token keyword">public</span> String <span class="token function">toString</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span>
<span class="token keyword">return</span> <span class="token string">"Person [name="</span> <span class="token operator">+</span> name <span class="token operator">+</span> <span class="token string">", age="</span> <span class="token operator">+</span> age <span class="token operator">+</span> <span class="token string">", car="</span> <span class="token operator">+</span> car <span class="token operator">+</span> <span class="token string">"]"</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
/** * 小汽車類 * @author nnngu * */ class Car implements Serializable { private static final long serialVersionUID = -5713945027627603702L;<span class="token keyword">private</span> String brand<span class="token punctuation">;</span> <span class="token comment">// 品牌</span> <span class="token keyword">private</span> <span class="token keyword">int</span> maxSpeed<span class="token punctuation">;</span> <span class="token comment">// 最高時速</span> <span class="token keyword">public</span> <span class="token function">Car</span><span class="token punctuation">(</span>String brand<span class="token punctuation">,</span> <span class="token keyword">int</span> maxSpeed<span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">this</span><span class="token punctuation">.</span>brand <span class="token operator">=</span> brand<span class="token punctuation">;</span> <span class="token keyword">this</span><span class="token punctuation">.</span>maxSpeed <span class="token operator">=</span> maxSpeed<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> String <span class="token function">getBrand</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">return</span> brand<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">void</span> <span class="token function">setBrand</span><span class="token punctuation">(</span>String brand<span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">this</span><span class="token punctuation">.</span>brand <span class="token operator">=</span> brand<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">int</span> <span class="token function">getMaxSpeed</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">return</span> maxSpeed<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">void</span> <span class="token function">setMaxSpeed</span><span class="token punctuation">(</span><span class="token keyword">int</span> maxSpeed<span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">this</span><span class="token punctuation">.</span>maxSpeed <span class="token operator">=</span> maxSpeed<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token annotation punctuation">@Override</span> <span class="token keyword">public</span> String <span class="token function">toString</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">return</span> <span class="token string">"Car [brand="</span> <span class="token operator">+</span> brand <span class="token operator">+</span> <span class="token string">", maxSpeed="</span> <span class="token operator">+</span> maxSpeed <span class="token operator">+</span> <span class="token string">"]"</span><span class="token punctuation">;</span> <span class="token punctuation">}</span>
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
class CloneTest {
public static void main(String[] args) {
try {
Person p1 = new Person("郭靖", 33, new Car("Benz", 300));
Person p2 = MyUtil.clone(p1); // 深度克隆
p2.getCar().setBrand("BYD");
// 修改克隆的Person物件p2關聯的汽車物件的品牌屬性
// 原來的Person物件p1關聯的汽車不會受到任何影響
// 因爲在克隆Person物件時其關聯的汽車物件也被克隆了
System.out.println(p1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意:
基於序列化和反序列化實現的克隆不僅僅是深度克隆,更重要的是通過泛型限定,可以檢查出要克隆的物件是否支援序列化,這項檢查是編譯器完成的,不是在執行時拋出異常,這種是方案明顯優於使用Object類的clone方法克隆物件。讓問題在編譯的時候暴露出來總是好過把問題留到執行時。
63.深拷貝和淺拷貝區別是什麼?
- 淺拷貝只是複製了物件的參照地址,兩個物件指向同一個記憶體地址,所以修改其中任意的值,另一個值都會隨之變化,這就是淺拷貝(例:assign())
- 深拷貝是將物件及值複製過來,兩個物件修改其中任意的值另一個值不會改變,這就是深拷貝(例:JSON.parse()和JSON.stringify(),但是此方法無法複製函數型別)
第二種回答:
- 淺克隆:當物件被複制時只複製它本身和其中包含的值型別的成員變數,而參照型別的成員物件並沒有複製。
- 深克隆:除了物件本身被複制外,物件所包含的所有成員變數也將複製。
六、Java Web
64.jsp 和 servlet 有什麼區別?
- jsp經編譯後就變成了servlet。(jsp的本質就是servlet,JVM只能識別java的類,不能識別jsp的程式碼,Web容器將jsp的程式碼編譯成JVM能夠識別的java類)
- jsp更擅長表現於頁面顯示,servlet更擅長於邏輯控制。
- servlet中沒有內建物件,jsp中的內建物件都是必須通過HttpServletRequest物件,HttpServletResponse物件以及HttpServlet物件得到。
- jsp是servlet的一種簡化,使用Jsp只需要完成程式設計師需要輸出到用戶端的內容,jsp中的Java指令碼如何鑲嵌到一個類中,由jsp容器完成。而servlet則是個完整的Java類,這個類的Service方法用於生成對用戶端的響應。
第二種回答:
JSP 是 servlet 技術的擴充套件,本質上就是 servlet 的簡易方式。servlet 和 JSP 最主要的不同點在於,servlet 的應用邏輯是在 Java 檔案中,並且完全從表示層中的 html 裡分離開來,而 JSP 的情況是 Java 和 html 可以組合成一個擴充套件名爲 JSP 的檔案。JSP 側重於檢視,servlet 主要用於控制邏輯。
65.jsp 有哪些內建物件?作用分別是什麼?
JSP有9個內建物件:
- request:封裝用戶端的請求,其中包含來自GET或POST請求的參數;
- response:封裝伺服器對用戶端的響應;
- pageContext:通過該物件可以獲取其他物件;
- session:封裝使用者對談的物件;
- application:封裝伺服器執行環境的物件;
- out:輸出伺服器響應的輸出流物件;
- config:Web應用的設定物件;
- page:JSP頁面本身(相當於Java程式中的this);
- exception:封裝頁面拋出異常的物件。
66.說一下 jsp 的 4 種作用域?
jsp中的四種作用域包括page、request、session和application,具體來說:
- page代表與一個頁面相關的物件和屬性。
- request代表與Web客戶機發出的一個請求相關的物件和屬性。一個請求可能跨越多個頁面,涉及多個Web元件;需要在頁面顯示的臨時數據可以置於此作用域。
- session代表與某個使用者與伺服器建立的一次對談相關的物件和屬性。跟某個使用者相關的數據應該放在使用者自己的session中。
- application代表與整個Web應用程式相關的物件和屬性,它實質上是跨越整個Web應用程式,包括多個頁面、請求和對談的一個全域性作用域。
67.session 和 cookie 有什麼區別?
由於HTTP協定是無狀態的協定,所以伺服器端需要記錄使用者的狀態時,就需要用某種機制 機製來識具體的使用者,這個機制 機製就是Session.典型的場景比如購物車,當你點選下單按鈕時,由於HTTP協定無狀態,所以並不知道是哪個使用者操作的,所以伺服器端要爲特定的使用者建立了特定的Session,用用於標識這個使用者,並且跟蹤使用者,這樣才知道購物車裏面有幾本書。這個Session是儲存在伺服器端的,有一個唯一標識。在伺服器端儲存Session的方法很多,記憶體、數據庫、檔案都有。叢集的時候也要考慮Session的轉移,在大型的網站,一般會有專門的Session伺服器叢集,用來儲存使用者對談,這個時候 Session 資訊都是放在記憶體的,使用一些快取服務比如Memcached之類的來放 Session。
思考一下伺服器端如何識別特定的客戶?這個時候Cookie就登場了。每次HTTP請求的時候,用戶端都會發送相應的Cookie資訊到伺服器端。實際上大多數的應用都是用 Cookie 來實現Session跟蹤的,第一次建立Session的時候,伺服器端會在HTTP協定中告訴用戶端,需要在 Cookie 裏面記錄一個Session ID,以後每次請求把這個對談ID發送到伺服器,我就知道你是誰了。有人問,如果用戶端的瀏覽器禁用了 Cookie 怎麼辦?一般這種情況下,會使用一種叫做URL重寫的技術來進行對談跟蹤,即每次HTTP互動,URL後面都會被附加上一個諸如 sid=xxxxx 這樣的參數,伺服器端據此來識別使用者。
Cookie其實還可以用在一些方便使用者的場景下,設想你某次登陸過一個網站,下次登錄的時候不想再次輸入賬號了,怎麼辦?這個資訊可以寫到Cookie裏面,存取網站的時候,網站頁面的指令碼可以讀取這個資訊,就自動幫你把使用者名稱給填了,能夠方便一下使用者。這也是Cookie名稱的由來,給使用者的一點甜頭。所以,總結一下:Session是在伺服器端儲存的一個數據結構,用來跟蹤使用者的狀態,這個數據可以儲存在叢集、數據庫、檔案中;Cookie是用戶端儲存使用者資訊的一種機制 機製,用來記錄使用者的一些資訊,也是實現Session的一種方式。
第二種回答:
- 儲存位置不同:session 儲存在伺服器端;cookie 儲存在瀏覽器端。
- 安全性不同:cookie 安全性一般,在瀏覽器儲存,可以被僞造和修改。
- 容量和個數限制:cookie 有容量限制,每個站點下的 cookie 也有個數限制。
- 儲存的多樣性:session 可以儲存在 Redis 中、數據庫中、應用程式中;而 cookie 只能儲存在瀏覽器中。
68.說一下 session 的工作原理?
其實session是一個存在伺服器上的類似於一個雜湊表格的檔案。裏面存有我們需要的資訊,在我們需要用的時候可以從裏面取出來。類似於一個大號的map吧,裏面的鍵儲存的是使用者的sessionid,使用者向伺服器發送請求的時候會帶上這個sessionid。這時就可以從中取出對應的值了。
第二種回答:
session 的工作原理是用戶端登錄完成之後,伺服器會建立對應的 session,session 建立完之後,會把 session 的 id 發送給用戶端,用戶端再儲存到瀏覽器中。這樣用戶端每次存取伺服器時,都會帶着 sessionid,伺服器拿到 sessionid 之後,在記憶體找到與之對應的 session 這樣就可以正常工作了。
69.如果用戶端禁止 cookie 能實現 session 還能用嗎?
Cookie與 Session,一般認爲是兩個獨立的東西,Session採用的是在伺服器端保持狀態的方案,而Cookie採用的是在用戶端保持狀態的方案。但爲什麼禁用Cookie就不能得到Session呢?因爲Session是用Session ID來確定當前對話所對應的伺服器Session,而Session ID是通過Cookie來傳遞的,禁用Cookie相當於失去了Session ID,也就得不到Session了。
假定使用者關閉Cookie的情況下使用Session,其實現途徑有以下幾種:
- 設定php.ini組態檔中的「session.use_trans_sid = 1」,或者編譯時開啓打開了「–enable-trans-sid」選項,讓PHP自動跨頁傳遞Session ID。
- 手動通過URL傳值、隱藏表單傳遞Session ID。
- 用檔案、數據庫等形式儲存Session ID,在跨頁過程中手動呼叫。
第二種回答:
可以用,session 只是依賴 cookie 儲存 sessionid,如果 cookie 被禁用了,可以使用 url 中新增 sessionid 的方式保證 session 能正常使用。
70.spring mvc 和 struts 的區別是什麼?
攔截機制 機製的不同
Struts2是類級別的攔截,每次請求就會建立一個Action,和Spring整合時Struts2的ActionBean注入作用域是原型模式prototype,然後通過setter,getter吧request數據注入到屬性。Struts2中,一個Action對應一個request,response上下文,在接收參數時,可以通過屬性接收,這說明屬性參數是讓多個方法共用的。Struts2中Action的一個方法可以對應一個url,而其類屬性卻被所有方法共用,這也就無法用註解或其他方式標識其所屬方法了,只能設計爲多例。
SpringMVC是方法級別的攔截,一個方法對應一個Request上下文,所以方法直接基本上是獨立的,獨享request,response數據。而每個方法同時又何一個url對應,參數的傳遞是直接注入到方法中的,是方法所獨有的。處理結果通過ModeMap返回給框架。在Spring整合時,SpringMVC的Controller Bean預設單例模式Singleton,所以預設對所有的請求,只會建立一個Controller,有應爲沒有共用的屬性,所以是執行緒安全的,如果要改變預設的作用域,需要新增@Scope註解修改。
Struts2有自己的攔截Interceptor機制 機製,SpringMVC這是用的是獨立的Aop方式,這樣導致Struts2的組態檔量還是比SpringMVC大。
底層框架的不同
Struts2採用Filter(StrutsPrepareAndExecuteFilter)實現,SpringMVC(DispatcherServlet)則採用Servlet實現。Filter在容器啓動之後即初始化;服務停止以後墜毁,晚於Servlet。Servlet在是在呼叫時初始化,先於Filter呼叫,服務停止後銷燬。
效能方面
Struts2是類級別的攔截,每次請求對應範例一個新的Action,需要載入所有的屬性值注入,SpringMVC實現了零設定,由於SpringMVC基於方法的攔截,有載入一次單例模式bean注入。所以,SpringMVC開發效率和效能高於Struts2。
設定方面
spring MVC和Spring是無縫的。從這個專案的管理和安全上也比Struts2高。
第二種回答:
- 攔截級別:struts2 是類級別的攔截;spring mvc 是方法級別的攔截。
- 數據獨立性:spring mvc 的方法之間基本上獨立的,獨享 request 和 response 數據,請求數據通過參數獲取,處理結果通過 ModelMap 交回給框架,方法之間不共用變數;而 struts2 雖然方法之間也是獨立的,但其所有 action 變數是共用的,這不會影響程式執行,卻給我們編碼和讀程式時帶來了一定的麻煩。
- 攔截機制 機製:struts2 有以自己的 interceptor 機制 機製,spring mvc 用的是獨立的 aop 方式,這樣導致struts2 的組態檔量比 spring mvc 大。
- 對 ajax 的支援:spring mvc 整合了ajax,所有 ajax 使用很方便,只需要一個註解 @ResponseBody 就可以實現了;而 struts2 一般需要安裝外掛或者自己寫程式碼才行。
71.如何避免 sql 注入?
- 使用預處理 PreparedStatement(簡單又有效的方法)
- 使用正則表達式過濾傳入的參數(或字元中的特殊字元)
- 字串過濾
- JSP中呼叫該函數檢查是否包函非法字元
- JSP頁面判斷程式碼
72.什麼是 XSS 攻擊,如何避免?
XSS攻擊又稱CSS,全稱Cross Site Script (跨站指令碼攻擊),其原理是攻擊者向有XSS漏洞的網站中輸入惡意的 HTML 程式碼,當使用者瀏覽該網站時,這段 HTML 程式碼會自動執行,從而達到攻擊的目的。XSS 攻擊類似於 SQL 注入攻擊,SQL隱碼攻擊中以SQL語句作爲使用者輸入,從而達到查詢/修改/刪除數據的目的,而在xss攻擊中,通過插入惡意指令碼,實現對使用者遊覽器的控制,獲取使用者的一些資訊。 XSS是 Web 程式中常見的漏洞,XSS 屬於被動式且用於用戶端的攻擊方式。
XSS防範的總體思路是:對輸入(和URL參數)進行過濾,對輸出進行編碼。
第二種回答:
XSS 攻擊:即跨站指令碼攻擊,它是 Web 程式中常見的漏洞。原理是攻擊者往 Web 頁面裡插入惡意的指令碼程式碼(css 程式碼、Javascript 程式碼等),當使用者瀏覽該頁面時,嵌入其中的指令碼程式碼會被執行,從而達到惡意攻擊使用者的目的,如盜取使用者 cookie、破壞頁面結構、重定向到其他網站等。
預防 XSS 的核心是必須對輸入的數據做過濾處理。
73.什麼是 CSRF 攻擊,如何避免?
CSRF(Cross-site request forgery)也被稱爲 one-click attack或者 session riding,中文全稱是叫跨站請求僞造。一般來說,攻擊者通過僞造使用者的瀏覽器的請求,向存取一個使用者自己曾經認證存取過的網站發送出去,使目標網站接收並誤以爲是使用者的真實操作而去執行命令。常用於盜取賬號、轉賬、發送虛假訊息等。攻擊者利用網站對請求的驗證漏洞而實現這樣的攻擊行爲,網站能夠確認請求來源於使用者的瀏覽器,卻不能驗證請求是否源於使用者的真實意願下的操作行爲。
如何避免:
- 驗證 HTTP Referer 欄位
HTTP頭中的Referer欄位記錄了該 HTTP 請求的來源地址。在通常情況下,存取一個安全受限頁面的請求來自於同一個網站,而如果駭客要對其實施 CSRF
攻擊,他一般只能在他自己的網站構造請求。因此,可以通過驗證Referer值來防禦CSRF 攻擊。
- 使用驗證碼
關鍵操作頁面加上驗證碼,後臺收到請求後通過判斷驗證碼可以防禦CSRF。但這種方法對使用者不太友好。
- 在請求地址中新增token並驗證
CSRF 攻擊之所以能夠成功,是因爲駭客可以完全僞造使用者的請求,該請求中所有的使用者驗證資訊都是存在於cookie中,因此駭客可以在不知道這些驗證資訊的情況下直接利用使用者自己的cookie 來通過安全驗證。要抵禦 CSRF,關鍵在於在請求中放入駭客所不能僞造的資訊,並且該資訊不存在於 cookie 之中。可以在 HTTP 請求中以參數的形式加入一個隨機產生的 token,並在伺服器端建立一個攔截器來驗證這個 token,如果請求中沒有token或者 token 內容不正確,則認爲可能是 CSRF 攻擊而拒絕該請求。這種方法要比檢查 Referer 要安全一些,token 可以在使用者登陸後產生並放於session之中,然後在每次請求時把token 從 session 中拿出,與請求中的 token 進行比對,但這種方法的難點在於如何把 token 以參數的形式加入請求。
對於 GET 請求,token 將附在請求地址之後,這樣 URL 就變成 http://url?csrftoken=tokenvalue。
而對於 POST 請求來說,要在 form 的最後加上 ,這樣就把token以參數的形式加入請求了。
- 在HTTP 頭中自定義屬性並驗證
這種方法也是使用 token 並進行驗證,和上一種方法不同的是,這裏並不是把 token 以參數的形式置於 HTTP 請求之中,而是把它放到 HTTP 頭中自定義的屬性裡。通過 XMLHttpRequest 這個類,可以一次性給所有該類請求加上 csrftoken 這個 HTTP 頭屬性,並把 token 值放入其中。這樣解決了上種方法在請求中加入 token 的不便,同時,通過 XMLHttpRequest 請求的地址不會被記錄到瀏覽器的位址列,也不用擔心 token 會透過 Referer 泄露到其他網站中去。
第二種回答:
CSRF:Cross-Site Request Forgery(中文:跨站請求僞造),可以理解爲攻擊者盜用了你的身份,以你的名義發送惡意請求,比如:以你名義發送郵件、發訊息、購買商品,虛擬貨幣轉賬等。
防禦手段:
- 驗證請求來源地址;
- 關鍵操作新增驗證碼;
- 在請求地址新增 token 並驗證。
七、異常
74.throw 和 throws 的區別?
throws是用來宣告一個方法可能拋出的所有異常資訊,throws是將異常宣告但是不處理,而是將異常往上傳,誰呼叫我就交給誰處理。而throw則是指拋出的一個具體的異常型別。
第二種回答:
- throw:是真實拋出一個異常。
- throws:是宣告可能會拋出一個異常。
75.final、finally、finalize 有什麼區別?
- final可以修飾類、變數、方法,修飾類表示該類不能被繼承、修飾方法表示該方法不能被重寫、修飾變數表示該變數是一個常數不能被重新賦值。
- finally一般作用在try-catch程式碼塊中,在處理異常的時候,通常我們將一定要執行的程式碼方法finally程式碼塊中,表示不管是否出現異常,該程式碼塊都會執行,一般用來存放一些關閉資源的程式碼。
- finalize是一個方法,屬於Object類的一個方法,而Object類是所有類的父類別,該方法一般由垃圾回收器來呼叫,當我們呼叫System的gc()方法的時候,由垃圾回收器呼叫finalize(),回收垃圾。
第二種回答:
- final:是修飾符,如果修飾類,此類不能被繼承;如果修飾方法和變數,則表示此方法和此變數不能在被改變,只能使用。
- finally:是 try{} catch{} finally{} 最後一部分,表示不論發生任何情況都會執行,finally 部分可以省略,但如果 finally 部分存在,則一定會執行 finally 裏面的程式碼。
- finalize: 是 Object 類的一個方法,在垃圾收集器執行的時候會呼叫被回收物件的此方法。
76.try-catch-finally 中哪個部分可以省略?
答:catch 可以省略
原因:
更爲嚴格的說法其實是:try只適合處理執行時異常,try+catch適合處理執行時異常+普通異常。也就是說,如果你只用try去處理普通異常卻不加以catch處理,編譯是通不過的,因爲編譯器硬性規定,普通異常如果選擇捕獲,則必須用catch顯示宣告以便進一步處理。而執行時異常在編譯時沒有如此規定,所以catch可以省略,你加上catch編譯器也覺得無可厚非。
理論上,編譯器看任何程式碼都不順眼,都覺得可能有潛在的問題,所以你即使對所有程式碼加上try,程式碼在執行期時也只不過是在正常執行的基礎上加一層皮。但是你一旦對一段程式碼加上try,就等於顯示地承諾編譯器,對這段程式碼可能拋出的異常進行捕獲而非向上拋出處理。如果是普通異常,編譯器要求必須用catch捕獲以便進一步處理;如果執行時異常,捕獲然後丟棄並且+finally掃尾處理,或者加上catch捕獲以便進一步處理。
至於加上finally,則是在不管有沒捕獲異常,都要進行的「掃尾」處理。
第二種回答:
try-catch-finally 其中 catch 和 finally 都可以被省略,但是不能同時省略,也就是說有 try 的時候,必須後面跟一個 catch 或者 finally。
77.try-catch-finally 中,如果 catch 中 return 了,finally 還會執行嗎?
答:會執行,在 return 前執行。
程式碼範例1:
/* * java面試題--如果catch裏面有return語句,finally裏面的程式碼還會執行嗎? */ public class FinallyDemo2 { public static void main(String[] args) { System.out.println(getInt()); }<span class="token keyword">public</span> <span class="token keyword">static</span> <span class="token keyword">int</span> <span class="token function">getInt</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">int</span> a <span class="token operator">=</span> <span class="token number">10</span><span class="token punctuation">;</span> <span class="token keyword">try</span> <span class="token punctuation">{</span> System<span class="token punctuation">.</span>out<span class="token punctuation">.</span><span class="token function">println</span><span class="token punctuation">(</span>a <span class="token operator">/</span> <span class="token number">0</span><span class="token punctuation">)</span><span class="token punctuation">;</span> a <span class="token operator">=</span> <span class="token number">20</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">catch</span> <span class="token punctuation">(</span><span class="token class-name">ArithmeticException</span> e<span class="token punctuation">)</span> <span class="token punctuation">{</span> a <span class="token operator">=</span> <span class="token number">30</span><span class="token punctuation">;</span> <span class="token keyword">return</span> a<span class="token punctuation">;</span> <span class="token comment">/* * return a 在程式執行到這一步的時候,這裏不是return a 而是 return 30;這個返迴路徑就形成了 * 但是呢,它發現後面還有finally,所以繼續執行finally的內容,a=40 * 再次回到以前的路徑,繼續走return 30,形成返迴路徑之後,這裏的a就不是a變數了,而是常數30 */</span> <span class="token punctuation">}</span> <span class="token keyword">finally</span> <span class="token punctuation">{</span> a <span class="token operator">=</span> <span class="token number">40</span><span class="token punctuation">;</span> <span class="token punctuation">}</span>
// return a;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
執行結果:
30
- 1
程式碼範例2:
package com.java_02;
/*
-
java面試題–如果catch裏面有return語句,finally裏面的程式碼還會執行嗎?
*/
public class FinallyDemo2 {
public static void main(String[] args) {
System.out.println(getInt());
}public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a 在程式執行到這一步的時候,這裏不是return a 而是 return 30;這個返迴路徑就形成了
* 但是呢,它發現後面還有finally,所以繼續執行finally的內容,a=40
* 再次回到以前的路徑,繼續走return 30,形成返迴路徑之後,這裏的a就不是a變數了,而是常數30
*/
} finally {
a = 40;
return a; //如果這樣,就又重新形成了一條返迴路徑,由於只能通過1個return返回,所以這裏直接返回40
}
// return a;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
執行結果:
40
- 1
第二種回答:
finally 一定會執行,即使是 catch 中 return 了,catch 中的 return 會等 finally 中的程式碼執行完之後,纔會執行。
78.常見的異常類有哪些?
- NullPointerException:當應用程式試圖存取空物件時,則拋出該異常。
- SQLException:提供關於數據庫存取錯誤或其他錯誤資訊的異常。
- IndexOutOfBoundsException:指示某排序索引(例如對陣列、字串或向量的排序)超出範圍時拋出。
- NumberFormatException:當應用程式試圖將字串轉換成一種數值型別,但該字串不能轉換爲適當格式時,拋出該異常。
- FileNotFoundException:當試圖開啓指定路徑名錶示的檔案失敗時,拋出此異常。
- IOException:當發生某種I/O異常時,拋出此異常。此類是失敗或中斷的I/O操作生成的異常的通用類。
- ClassCastException:當試圖將物件強制轉換爲不是範例的子類時,拋出該異常。
- ArrayStoreException:試圖將錯誤型別的物件儲存到一個物件陣列時拋出的異常。
- IllegalArgumentException:拋出的異常表明向方法傳遞了一個不合法或不正確的參數。
- ArithmeticException:當出現異常的運算條件時,拋出此異常。例如,一個整數「除以零」時,拋出此類的一個範例。
- NegativeArraySizeException:如果應用程式試圖建立大小爲負的陣列,則拋出該異常。
- NoSuchMethodException:無法找到某一特定方法時,拋出該異常。
- SecurityException:由安全管理器拋出的異常,指示存在安全侵犯。
- UnsupportedOperationException:當不支援請求的操作時,拋出該異常。
- RuntimeExceptionRuntimeException:是那些可能在Java虛擬機器正常執行期間拋出的異常的超類。
第二種回答:
- NullPointerException 空指針異常
- ClassNotFoundException 指定類不存在
- NumberFormatException 字串轉換爲數位異常
- IndexOutOfBoundsException 陣列下標越界異常
- ClassCastException 數據型別轉換異常
- FileNotFoundException 檔案未找到異常
- NoSuchMethodException 方法不存在異常
- IOException IO 異常
- SocketException Socket 異常
八、網路
79.http 響應碼 301 和 302 代表的是什麼?有什麼區別?
答:301,302 都是HTTP狀態的編碼,都代表着某個URL發生了轉移。
區別:
- 301 redirect: 301 代表永久性轉移(Permanently Moved)。
- 302 redirect: 302 代表暫時性轉移(Temporarily Moved )。
第二種回答:
- 301:永久重定向。
- 302:暫時重定向。
它們的區別是,301 對搜尋引擎優化(SEO)更加有利;302 有被提示爲網路攔截的風險。
80.forward 和 redirect 的區別?
Forward和Redirect代表了兩種請求轉發方式:直接轉發和間接轉發。
-
直接轉發方式(Forward),用戶端和瀏覽器只發出一次請求,Servlet、HTML、JSP或其它資訊資源,由第二個資訊資源響應該請求,在請求物件request中,儲存的物件對於每個資訊資源是共用的。
-
間接轉發方式(Redirect)實際是兩次HTTP請求,伺服器端在響應第一次請求的時候,讓瀏覽器再向另外一個URL發出請求,從而達到轉發的目的。
舉個通俗的例子:
- 直接轉發就相當於:「A找B借錢,B說沒有,B去找C借,借到借不到都會把訊息傳遞給A」;
- 間接轉發就相當於:「A找B借錢,B說沒有,讓A去找C借」。
第二種回答:
forward 是轉發 和 redirect 是重定向:
- 位址列 url 顯示:foward url 不會發生改變,redirect url 會發生改變;
- 數據共用:forward 可以共用 request 裡的數據,redirect 不能共用;
- 效率:forward 比 redirect 效率高。
81.簡述 tcp 和 udp的區別?
- TCP面向連接(如打電話要先撥號建立連線);UDP是無連線的,即發送數據之前不需要建立連線。
- TCP提供可靠的服務。也就是說,通過TCP連線傳送的數據,無差錯,不丟失,不重複,且按序到達;UDP盡最大努力交付,即不保證可靠交付。
- TCP通過校驗和,重傳控制,序號標識,滑動視窗、確認應答實現可靠傳輸。如丟包時的重發控制,還可以對次序亂掉的分包進行順序控制。
- UDP具有較好的實時性,工作效率比TCP高,適用於對高速傳輸和實時性有較高的通訊或廣播通訊。
每一條TCP連線只能是點到點的;UDP支援一對一,一對多,多對一和多對多的互動通訊。 - TCP對系統資源要求較多,UDP對系統資源要求較少。
第二種回答:
tcp 和 udp 是 OSI 模型中的運輸層中的協定。tcp 提供可靠的通訊傳輸,而 udp 則常被用於讓廣播和細節控制交給應用的通訊傳輸。
兩者的區別大致如下:
- tcp 面向連接,udp 面向非連線即發送數據前不需要建立鏈接;
- tcp 提供可靠的服務(數據傳輸),udp 無法保證;
- tcp 面向位元組流,udp 面向報文;
- tcp 數據傳輸慢,udp 數據傳輸快;
82.tcp 爲什麼要三次握手,兩次不行嗎?爲什麼?
爲了實現可靠數據傳輸, TCP 協定的通訊雙方, 都必須維護一個序列號, 以標識發送出去的數據包中, 哪些是已經被對方收到的。 三次握手的過程即是通訊雙方相互告知序列號起始值, 並確認對方已經收到了序列號起始值的必經步驟。
如果只是兩次握手, 至多隻有連線發起方的起始序列號能被確認, 另一方選擇的序列號則得不到確認。
第二種回答:
如果採用兩次握手,那麼只要伺服器發出確認數據包就會建立連線,但由於用戶端此時並未響應伺服器端的請求,那此時伺服器端就會一直在等待用戶端,這樣伺服器端就白白浪費了一定的資源。若採用三次握手,伺服器端沒有收到來自用戶端的再此確認,則就會知道用戶端並沒有要求建立請求,就不會浪費伺服器的資源。
83.說一下 tcp 粘包是怎麼產生的?
①. 發送方產生粘包
採用TCP協定傳輸數據的用戶端與伺服器經常是保持一個長連線的狀態(一次連線發一次數據不存在粘包),雙方在連線不斷開的情況下,可以一直傳輸數據;但當發送的數據包過於的小時,那麼TCP協定預設的會啓用Nagle演算法,將這些較小的數據包進行合併發送(緩衝區數據發送是一個堆壓的過程);這個合併過程就是在發送緩衝區中進行的,也就是說數據發送出來它已經是粘包的狀態了。
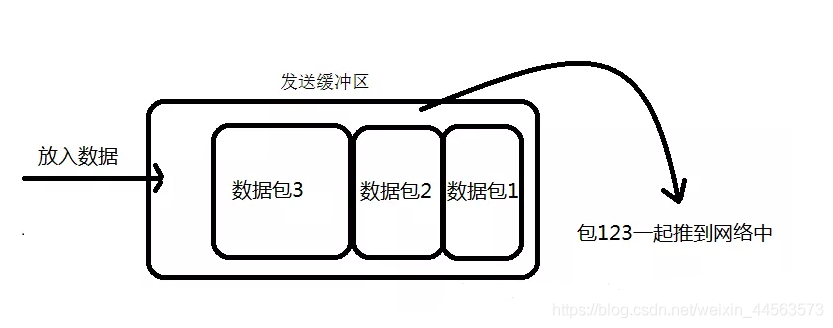
②. 接收方產生粘包
接收方採用TCP協定接收數據時的過程是這樣的:數據到底接收方,從網路模型的下方傳遞至傳輸層,傳輸層的TCP協定處理是將其放置接收緩衝區,然後由應用層來主動獲取(C語言用recv、read等函數);這時會出現一個問題,就是我們在程式中呼叫的讀取數據函數不能及時的把緩衝區中的數據拿出來,而下一個數據又到來並有一部分放入的緩衝區末尾,等我們讀取數據時就是一個粘包。(放數據的速度 > 應用層拿數據速度)
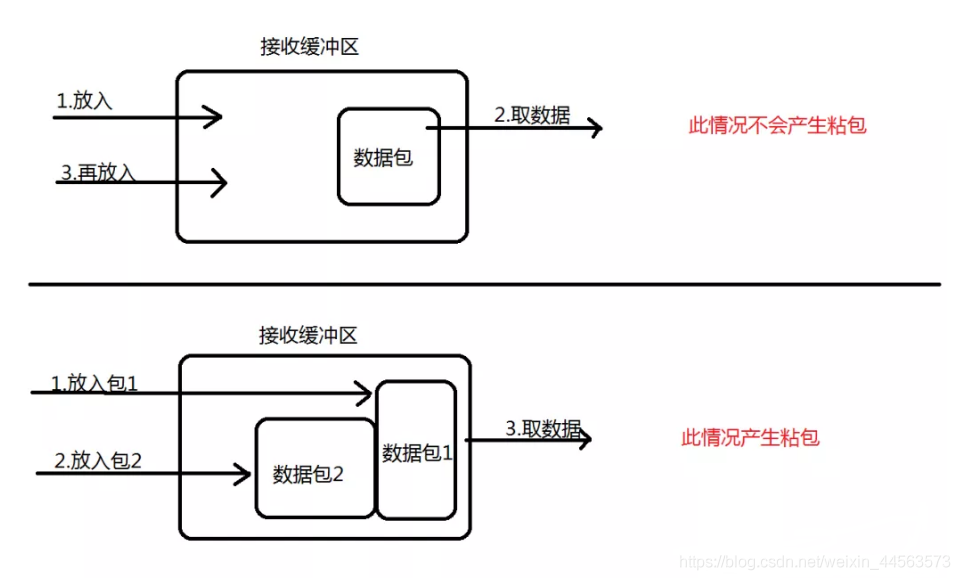
第二種回答:
tcp 粘包可能發生在發送端或者接收端,分別來看兩端各種產生粘包的原因:
- 發送端粘包:發送端需要等緩衝區滿才發送出去,造成粘包;
- 接收方粘包:接收方不及時接收緩衝區的包,造成多個包接收。
84.OSI 的七層模型都有哪些?
- 應用層:網路服務與終端使用者的一個介面。
- 表示層:數據的表示、安全、壓縮。
- 對談層:建立、管理、終止對談。
- 傳輸層:定義傳輸數據的協定埠號,以及流控和差錯校驗。
- 網路層:進行邏輯地址定址,實現不同網路之間的路徑選擇。
- 數據鏈路層:建立邏輯連線、進行硬體地址定址、差錯校驗等功能。
- 物理層:建立、維護、斷開物理連線。
第二種回答:
- 物理層:利用傳輸媒介爲數據鏈路層提供物理連線,實現位元流的透明傳輸。
- 數據鏈路層:負責建立和管理節點間的鏈路。
- 網路層:通過路由選擇演算法,爲報文或分組通過通訊子網選擇最適當的路徑。
- 傳輸層:向使用者提供可靠的端到端的差錯和流量控制,保證報文的正確傳輸。
- 對談層:向兩個實體的表示層提供建立和使用連線的方法。
- 表示層:處理使用者資訊的表示問題,如編碼、數據格式轉換和加密解密等。
- 應用層:直接向使用者提供服務,完成使用者希望在網路上完成的各種工作。
85.get 和 post 請求有哪些區別?
- get在瀏覽器回退時是無害的,而post會再次提交請求。
- get產生的URL地址可以被Bookmark,而post不可以。
- get請求會被瀏覽器主動cache(快取),而post不會,除非手動設定。
- get請求只能進行url編碼,而post支援多種編碼方式。
- get請求參數會被完整保留在瀏覽器歷史記錄裡,而post 中的參數不會被保留。
- get請求在URL中傳送的參數是有長度限制的,而post沒有。
- 參數的數據型別,get只接受ASCII字元,而post沒有限制。
- get比post更不安全,因爲參數直接暴露在URL上,所以不能用來傳遞敏感資訊。(即post 參數傳輸更安全,get 的參數會明文限制在 url 上,post 不會。)
- get參數通過URL傳遞,post放在Request body中。
86.如何實現跨域?
方式一:圖片ping或script標籤跨域
- 圖片ping常用於跟蹤使用者點選頁面或動態廣告曝光次數。
- script標籤可以得到從其他來源數據,這也是JSONP依賴的根據。
方式二:JSONP跨域
JSONP(JSON with Padding)是數據格式JSON的一種「使用模式」,可以讓網頁從別的網域要數據。根據 XmlHttpRequest 物件受到同源策略的影響,而利用
- 只能使用Get請求
- 不能註冊success、error等事件監聽函數,不能很容易的確定JSONP請求是否失敗
- JSONP是從其他域中載入程式碼執行,容易受到跨站請求僞造的攻擊,其安全性無法確保
方式三:CORS
Cross-Origin Resource Sharing(CORS)跨域資源共用是一份瀏覽器技術的規範,提供了 Web 服務從不同域傳來沙盒指令碼的方法,以避開瀏覽器的同源策略,確保安全的跨域數據傳輸。現代瀏覽器使用CORS在API容器如XMLHttpRequest來減少HTTP請求的風險來源。與 JSONP 不同,CORS 除了 GET 要求方法以外也支援其他的 HTTP 要求。伺服器一般需要增加如下響應頭的一種或幾種:
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
- 1
- 2
- 3
- 4
跨域請求預設不會攜帶Cookie資訊,如果需要攜帶,請設定下述參數:
"Access-Control-Allow-Credentials": true
// Ajax設定
"withCredentials": true
- 1
- 2
- 3
方式四:window.name+iframe
window.name通過在iframe(一般動態建立i)中載入跨域HTML檔案來起作用。然後,HTML檔案將傳遞給請求者的字串內容賦值給window.name。然後,請求者可以檢索window.name值作爲響應。
- iframe標籤的跨域能力;
- indow.name屬性值在文件重新整理後依舊存在的能力(且最大允許2M左右)。
每個iframe都有包裹它的window,而這個window是top window的子視窗。contentWindow屬性返回元素的Window物件。你可以使用這個Window物件來存取iframe的文件及其內部DOM。
<!--
下述用埠
10000表示:domainA
10001表示:domainB
-->
<!– localhost:10000 –>
<script>
var iframe = document.createElement(‘iframe’);
iframe.style.display = ‘none’; // 隱藏
var state = 0; // 防止頁面無限重新整理
iframe.onload = function() {
if(state = 1) {
console.log(JSON.parse(iframe.contentWindow.name));
// 清除建立的iframe
iframe.contentWindow.document.write(’’);
iframe.contentWindow.close();
document.body.removeChild(iframe);
} else if(state = 0) {
state = 1;
// 載入完成,指向當前域,防止錯誤(proxy.html爲空白頁面)
// Blocked a frame with origin 「http://localhost:10000」 from accessing a cross-origin frame.
iframe.contentWindow.location = ‘http://localhost:10000/proxy.html’;
}
};
iframe.src = ‘http://localhost:10001’;
document.body.appendChild(iframe);
</script>
<!– localhost:10001 –>
<!DOCTYPE html>
...
<script>
window.name = JSON.stringify({a: 1, b: 2});
</script>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
方式五:window.postMessage()
HTML5新特性,可以用來向其他所有的 window 物件發送訊息。需要注意的是我們必須要保證所有的指令碼執行完才發送 MessageEvent,如果在函數執行的過程中呼叫了它,就會讓後面的函數超時無法執行。
下述程式碼實現了跨域儲存localStorage
<!--
下述用埠
10000表示:domainA
10001表示:domainB
-->
<!– localhost:10000 –>
<iframe src=「http://localhost:10001/msg.html」 name=「myPostMessage」 style=「display:none;」>
</iframe>
<script>
function main() {
LSsetItem(‘test’, 'Test: ’ + new Date());
LSgetItem(‘test’, function(value) {
console.log('value: ’ + value);
});
LSremoveItem(‘test’);
}
var callbacks = {};
window.addEventListener(‘message’, function(event) {
if (event.source = frames[‘myPostMessage’]) {
console.log(event)
var data = /^#localStorage#(\d+)(null)?#([\S\s]*)/.exec(event.data);
if (data) {
if (callbacks[data[1]]) {
callbacks[data[1]](data[2] = ‘null’ ? null : data[3]);
}
delete callbacks[data[1]];
}
}
}, false);
var domain = ‘*’;
// 增加
function LSsetItem(key, value) {
var obj = {
setItem: key,
value: value
};
frames[‘myPostMessage’].postMessage(JSON.stringify(obj), domain);
}
// 獲取
function LSgetItem(key, callback) {
var identifier = new Date().getTime();
var obj = {
identifier: identifier,
getItem: key
};
callbacks[identifier] = callback;
frames[‘myPostMessage’].postMessage(JSON.stringify(obj), domain);
}
// 刪除
function LSremoveItem(key) {
var obj = {
removeItem: key
};
frames[‘myPostMessage’].postMessage(JSON.stringify(obj), domain);
}
</script>
<!– localhost:10001 –>
<script>
window.addEventListener(‘message’, function(event) {
console.log(‘Receiver debugging’, event);
if (event.origin ‘http://localhost:10000’) {
var data = JSON.parse(event.data);
if (‘setItem’ in data) {
localStorage.setItem(data.setItem, data.value);
} else if (‘getItem’ in data) {
var gotItem = localStorage.getItem(data.getItem);
event.source.postMessage(
‘#localStorage#’ + data.identifier +
(gotItem = null ? ‘null#’ : ‘#’ + gotItem),
event.origin
);
} else if (‘removeItem’ in data) {
localStorage.removeItem(data.removeItem);
}
}
}, false);
</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
注意Safari一下,會報錯:
Blocked a frame with origin 「http://localhost:10001」 from
accessing a frame with origin 「http://localhost:10000「.
Protocols, domains, and ports must match.
- 1
- 2
- 3
避免該錯誤,可以在Safari瀏覽器中勾選開發選單==>停用跨域限制。或者只能使用伺服器端轉存的方式實現,因爲Safari瀏覽器預設只支援CORS跨域請求。
方式六:修改document.domain跨子域
前提條件:這兩個域名必須屬於同一個基礎域名!而且所用的協定,埠都要一致,否則無法利用document.domain進行跨域,所以只能跨子域
在根域範圍內,允許把domain屬性的值設定爲它的上一級域。例如,在」aaa.xxx.com」域內,可以把domain設定爲 「xxx.com」 但不能設定爲 「xxx.org」 或者」com」。
現在存在兩個域名aaa.xxx.com和bbb.xxx.com。在aaa下嵌入bbb的頁面,
由於其document.name不一致,無法在aaa下操作bbb的js。
可以在aaa和bbb下通過js將document.name = 'xxx.com';
設定一致,來達到互相存取的作用。
- 1
- 2
- 3
- 4
方式七:WebSocket
WebSocket protocol 是HTML5一種新的協定。它實現了瀏覽器與伺服器全雙工通訊,同時允許跨域通訊,是server push技術的一種很棒的實現。相關文章,請檢視:WebSocket、WebSocket-SockJS
需要注意:
WebSocket物件不支援DOM 2級事件偵聽器,必須使用DOM 0級語法分別定義各個事件。
方式八:代理
同源策略是針對瀏覽器端進行的限制,可以通過伺服器端來解決該問題。
DomainA用戶端(瀏覽器) ==> DomainA伺服器 ==> DomainB伺服器 ==> DomainA用戶端(瀏覽器)
第二種回答:
實現跨域有以下幾種方案:
- 伺服器端執行跨域 設定 CORS 等於 *;
- 在單個介面使用註解 @CrossOrigin 執行跨域;
- 使用 jsonp 跨域;
87.說一下 JSONP 實現原理?
jsonp 即 json+padding,動態建立script標籤,利用script標籤的src屬性可以獲取任何域下的js指令碼,通過這個特性(也可以說漏洞),伺服器端不在返貨json格式,而是返回一段呼叫某個函數的js程式碼,在src中進行了呼叫,這樣實現了跨域。
第二種回答:
jsonp:JSON with Padding,它是利用script標籤的 src 連線可以存取不同源的特性,載入遠端返回的「JS 函數」來執行的。
九、設計模式
88.說一下你熟悉的設計模式?
- 單例模式:保證被建立一次,節省系統開銷。
- 工廠模式(簡單工廠、抽象工廠):解耦程式碼。
- 觀察者模式:定義了物件之間的一對多的依賴,這樣一來,當一個物件改變時,它的所有的依賴者都會收到通知並自動更新。
- 外觀模式:提供一個統一的介面,用來存取子系統中的一羣介面,外觀定義了一個高層的介面,讓子系統更容易使用。
- 模版方法模式:定義了一個演算法的骨架,而將一些步驟延遲到子類中,模版方法使得子類可以在不改變演算法結構的情況下,重新定義演算法的步驟。
- 狀態模式:允許物件在內部狀態改變時改變它的行爲,物件看起來好像修改了它的類。
89.簡單工廠和抽象工廠有什麼區別?
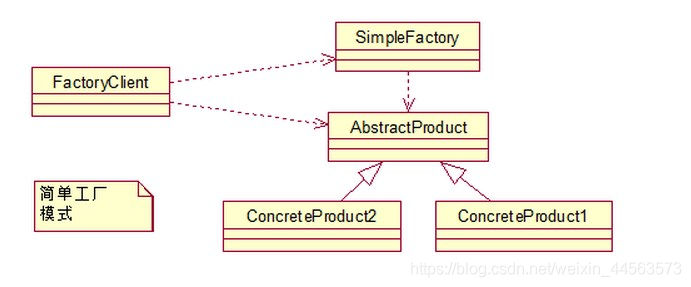
簡單工廠模式:
這個模式本身很簡單而且使用在業務較簡單的情況下。一般用於小專案或者具體產品很少擴充套件的情況(這樣工廠類纔不用經常更改)。
它由三種角色組成:
- 工廠類角色:這是本模式的核心,含有一定的商業邏輯和判斷邏輯,根據邏輯不同,產生具體的工廠產品。如例子中的Driver類。
- 抽象產品角色:它一般是具體產品繼承的父類別或者實現的介面。由介面或者抽象類來實現。如例中的Car介面。
- 具體產品角色:工廠類所建立的物件就是此角色的範例。在java中由一個具體類實現,如例子中的Benz、Bmw類。
來用類圖來清晰的表示下的它們之間的關係:
抽象工廠模式:
先來認識下什麼是產品族: 位於不同產品等級結構中,功能相關聯的產品組成的家族。
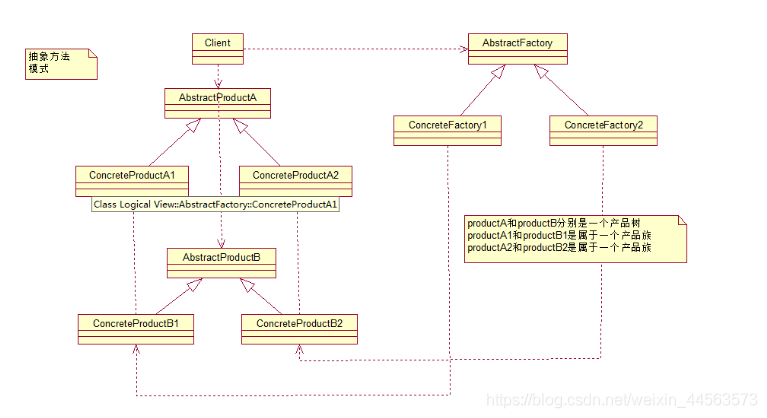
它和工廠方法模式的區別就在於需要建立物件的複雜程度上。而且抽象工廠模式是三個裏面最爲抽象、最具一般性的。抽象工廠模式的用意爲:給用戶端提供一個介面,可以建立多個產品族中的產品物件。
而且使用抽象工廠模式還要滿足一下條件:
- 系統中有多個產品族,而系統一次只可能消費其中一族產品
- 同屬於同一個產品族的產品以其使用。
來看看抽象工廠模式的各個角色(和工廠方法的如出一轍):
- 抽象工廠角色: 這是工廠方法模式的核心,它與應用程式無關。是具體工廠角色必須實現的介面或者必須繼承的父類別。在java中它由抽象類或者介面來實現。
- 具體工廠角色:它含有和具體業務邏輯有關的程式碼。由應用程式呼叫以建立對應的具體產品的物件。在java中它由具體的類來實現。
- 抽象產品角色:它是具體產品繼承的父類別或者是實現的介面。在java中一般有抽象類或者介面來實現。
- 具體產品角色:具體工廠角色所建立的物件就是此角色的範例。在java中由具體的類來實現。
第二種回答:
- 簡單工廠:用來生產同一等級結構中的任意產品,對於增加新的產品,無能爲力。
- 工廠方法:用來生產同一等級結構中的固定產品,支援增加任意產品。
- 抽象工廠:用來生產不同產品族的全部產品,對於增加新的產品,無能爲力;支援增加產品族。
十、Spring / Spring MVC
90.爲什麼要使用 spring?
1.簡介
- 目的:解決企業應用開發的複雜性
- 功能:使用基本的JavaBean代替EJB,並提供了更多的企業應用功能
- 範圍:任何Java應用
簡單來說,Spring是一個輕量級的控制反轉(IoC)和麪向切面(AOP)的容器框架。
2.輕量
從大小與開銷兩方面而言Spring都是輕量的。完整的Spring框架可以在一個大小隻有1MB多的JAR檔案裡發佈。並且Spring所需的處理開銷也是微不足道的。此外,Spring是非侵入式的:典型地,Spring應用中的物件不依賴於Spring的特定類。
3.控制反轉
Spring通過一種稱作控制反轉(IoC)的技術促進了松耦合。當應用了IoC,一個物件依賴的其它物件會通過被動的方式傳遞進來,而不是這個物件自己建立或者查詢依賴物件。你可以認爲IoC與JNDI相反——不是物件從容器中查詢依賴,而是容器在物件初始化時不等物件請求就主動將依賴傳遞給它。
4.面向切面
Spring提供了面向切面程式設計的豐富支援,允許通過分離應用的業務邏輯與系統級服務(例如審計(auditing)和事務(transaction)管理)進行內聚性的開發。應用物件只實現它們應該做的——完成業務邏輯——僅此而已。它們並不負責(甚至是意識)其它的系統級關注點,例如日誌或事務支援。
5.容器
Spring包含並管理應用物件的設定和生命週期,在這個意義上它是一種容器,你可以設定你的每個bean如何被建立——基於一個可設定原型(prototype),你的bean可以建立一個單獨的範例或者每次需要時都生成一個新的範例——以及它們是如何相互關聯的。然而,Spring不應該被混同於傳統的重量級的EJB容器,它們經常是龐大與笨重的,難以使用。
6.框架
- Spring可以將簡單的元件設定、組合成爲複雜的應用。在Spring中,應用物件被宣告式地組合,典型地是在一個XML檔案裡。
- Spring也提供了很多基礎功能(事務管理、持久化框架整合等等),將應用邏輯的開發留給了你。
所有Spring的這些特徵使你能夠編寫更乾淨、更可管理、並且更易於測試的程式碼。它們也爲Spring中的各種模組提供了基礎支援。
第二種回答:
- spring 提供 ioc 技術,容器會幫你管理依賴的物件,從而不需要自己建立和管理依賴物件了,更輕鬆的實現了程式的解耦。
- spring 提供了事務支援,使得事務操作變的更加方便。
- spring 提供了面向切片程式設計,這樣可以更方便的處理某一類的問題。
- 更方便的框架整合,spring 可以很方便的整合其他框架,比如 MyBatis、hibernate 等。
91.解釋一下什麼是 aop?
AOP(Aspect-Oriented Programming,面向切面程式設計),可以說是OOP(Object-Oriented Programing,物件導向程式設計)的補充和完善。OOP引入封裝、繼承和多型性等概念來建立一種物件層次結構,用以模擬公共行爲的一個集合。當我們需要爲分散的物件引入公共行爲的時候,OOP則顯得無能爲力。也就是說,OOP允許你定義從上到下的關係,但並不適合定義從左到右的關係。例如日誌功能。日誌程式碼往往水平地散佈在所有物件層次中,而與它所散佈到的物件的核心功能毫無關係。對於其他型別的程式碼,如安全性、例外處理和透明的持續性也是如此。這種散佈在各處的無關的程式碼被稱爲橫切(cross-cutting)程式碼,在OOP設計中,它導致了大量程式碼的重複,而不利於各個模組的重用。
而AOP技術則恰恰相反,它利用一種稱爲「橫切」的技術,剖解開封裝的物件內部,並將那些影響了多個類的公共行爲封裝到一個可重用模組,並將其名爲「Aspect」,即切面。所謂「切面」,簡單地說,就是將那些與業務無關,卻爲業務模組所共同調用的邏輯或責任封裝起來,便於減少系統的重複程式碼,降低模組間的耦合度,並有利於未來的可操作性和可維護性。AOP代表的是一個橫向的關係,如果說「物件」是一個空心的圓柱體,其中封裝的是物件的屬性和行爲;那麼面向切面程式設計的方法,就彷彿一把利刃,將這些空心圓柱體剖開,以獲得其內部的訊息。而剖開的切面,也就是所謂的「切面」了。然後它又以巧奪天功的妙手將這些剖開的切面復原,不留痕跡。
使用「橫切」技術,AOP把軟件系統分爲兩個部分:核心關注點和橫切關注點。業務處理的主要流程是核心關注點,與之關係不大的部分是橫切關注點。橫切關注點的一個特點是,他們經常發生在覈心關注點的多處,而各處都基本相似。比如許可權認證、日誌、事務處理。Aop 的作用在於分離系統中的各種關注點,將核心關注點和橫切關注點分離開來。正如Avanade公司的高階方案構架師Adam Magee所說,AOP的核心思想就是「將應用程式中的商業邏輯同對其提供支援的通用服務進行分離。」
第二種回答:
- aop 是面向切面程式設計,通過預編譯方式和執行期動態代理實現程式功能的統一維護的一種技術。
- 簡單來說就是統一處理某一「切面」(類)的問題的程式設計思想,比如統一處理日誌、異常等。
92.解釋一下什麼是 ioc?
IOC是Inversion of Control的縮寫,多數書籍翻譯成「控制反轉」。
1996年,Michael Mattson在一篇有關探討物件導向框架的文章中,首先提出了IOC 這個概念。對於物件導向設計及程式設計的基本思想,前面我們已經講了很多了,不再贅述,簡單來說就是把複雜系統分解成相互合作的物件,這些物件類通過封裝以後,內部實現對外部是透明的,從而降低瞭解決問題的複雜度,而且可以靈活地被重用和擴充套件。
IOC理論提出的觀點大體是這樣的:藉助於「第三方」實現具有依賴關係的物件之間的解耦。如下圖:
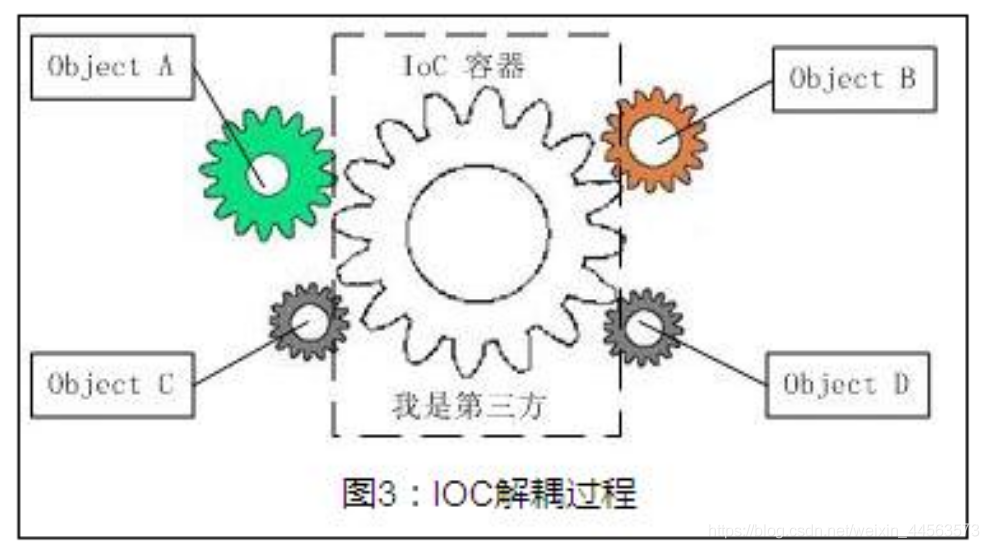
大家看到了吧,由於引進了中間位置的「第三方」,也就是IOC容器,使得A、B、C、D這4個物件沒有了耦合關係,齒輪之間的傳動全部依靠「第三方」了,全部物件的控制權全部上繳給「第三方」IOC容器,所以,IOC容器成了整個系統的關鍵核心,它起到了一種類似「粘合劑」的作用,把系統中的所有物件粘合在一起發揮作用,如果沒有這個「粘合劑」,物件與物件之間會彼此失去聯繫,這就是有人把IOC容器比喻成「粘合劑」的由來。
我們再來做個試驗:把上圖中間的IOC容器拿掉,然後再來看看這套系統:
我們現在看到的畫面,就是我們要實現整個系統所需要完成的全部內容。這時候,A、B、C、D這4個物件之間已經沒有了耦合關係,彼此毫無聯繫,這樣的話,當你在實現A的時候,根本無須再去考慮B、C和D了,物件之間的依賴關係已經降低到了最低程度。所以,如果真能實現IOC容器,對於系統開發而言,這將是一件多麼美好的事情,參與開發的每一成員只要實現自己的類就可以了,跟別人沒有任何關係!
我們再來看看,控制反轉(IOC)到底爲什麼要起這麼個名字?我們來對比一下:
軟件系統在沒有引入IOC容器之前,如圖1所示,物件A依賴於物件B,那麼物件A在初始化或者執行到某一點的時候,自己必須主動去建立物件B或者使用已經建立的物件B。無論是建立還是使用物件B,控制權都在自己手上。
軟件系統在引入IOC容器之後,這種情形就完全改變了,如圖3所示,由於IOC容器的加入,物件A與物件B之間失去了直接聯繫,所以,當物件A執行到需要物件B的時候,IOC容器會主動建立一個物件B注入到物件A需要的地方。
通過前後的對比,我們不難看出來:物件A獲得依賴物件B的過程,由主動行爲變爲了被動行爲,控制權顛倒過來了,這就是「控制反轉」這個名稱的由來。
第二種回答:
ioc:Inversionof Control(中文:控制反轉)是 spring 的核心,對於 spring 框架來說,就是由 spring 來負責控制物件的生命週期和物件間的關係。
簡單來說,控制指的是當前物件對內部成員的控制權;控制反轉指的是,這種控制權不由當前物件管理了,由其他(類,第三方容器)來管理。
93.spring 有哪些主要模組?
Spring框架至今已整合了20多個模組。這些模組主要被分如下圖所示的核心容器、數據存取/整合,、Web、AOP(面向切面程式設計)、工具、訊息和測試模組。
第二種回答:
- spring core:框架的最基礎部分,提供 ioc 和依賴注入特性。
- spring context:構建於 core 封裝包基礎上的 context 封裝包,提供了一種框架式的物件存取方法。
- spring dao:Data Access Object 提供了JDBC的抽象層。
- spring aop:提供了面向切面的程式設計實現,讓你可以自定義攔截器、切點等。
- spring Web:提供了針對 Web 開發的整合特性,例如檔案上傳,利用 servlet listeners 進行 ioc 容器初始化和針對 Web 的 ApplicationContext。
- spring Web mvc:spring 中的 mvc 封裝包提供了 Web 應用的 Model-View-Controller(MVC)的實現。
94.spring 常用的注入方式有哪些?
Spring通過DI(依賴注入)實現IOC(控制反轉),常用的注入方式主要有三種:
- 構造方法注入
- setter注入
- 基於註解的注入
95.spring 中的 bean 是執行緒安全的嗎?
Spring容器中的Bean是否執行緒安全,容器本身並沒有提供Bean的執行緒安全策略,因此可以說spring容器中的Bean本身不具備執行緒安全的特性,但是具體還是要結合具體scope的Bean去研究。
第二種回答:
spring 中的 bean 預設是單例模式,spring 框架並沒有對單例 bean 進行多執行緒的封裝處理。
實際上大部分時候 spring bean 無狀態的(比如 dao 類),所有某種程度上來說 bean 也是安全的,但如果 bean 有狀態的話(比如 view model 物件),那就要開發者自己去保證執行緒安全了,最簡單的就是改變 bean 的作用域,把「singleton」變更爲「prototype」,這樣請求 bean 相當於 new Bean()了,所以就可以保證執行緒安全了。
- 有狀態就是有數據儲存功能。
- 無狀態就是不會儲存數據。
96.spring 支援幾種 bean 的作用域?
當通過spring容器建立一個Bean範例時,不僅可以完成Bean範例的範例化,還可以爲Bean指定特定的作用域。Spring支援如下5種作用域:
- singleton:單例模式,在整個Spring IoC容器中,使用singleton定義的Bean將只有一個範例
- prototype:原型模式,每次通過容器的getBean方法獲取prototype定義的Bean時,都將產生一個新的Bean範例
- request:對於每次HTTP請求,使用request定義的Bean都將產生一個新範例,即每次HTTP請求將會產生不同的Bean範例。只有在Web應用中使用Spring時,該作用域纔有效
- session:對於每次HTTP Session,使用session定義的Bean豆漿產生一個新範例。同樣只有在Web應用中使用Spring時,該作用域纔有效
- globalsession:每個全域性的HTTP Session,使用session定義的Bean都將產生一個新範例。典型情況下,僅在使用portlet context的時候有效。同樣只有在Web應用中使用Spring時,該作用域纔有效
其中比較常用的是singleton和prototype兩種作用域。對於singleton作用域的Bean,每次請求該Bean都將獲得相同的範例。容器負責跟蹤Bean範例的狀態,負責維護Bean範例的生命週期行爲;如果一個Bean被設定成prototype作用域,程式每次請求該id的Bean,Spring都會新建一個Bean範例,然後返回給程式。在這種情況下,Spring容器僅僅使用new 關鍵字建立Bean範例,一旦建立成功,容器不在跟蹤範例,也不會維護Bean範例的狀態。
如果不指定Bean的作用域,Spring預設使用singleton作用域。Java在建立Java範例時,需要進行記憶體申請;銷燬範例時,需要完成垃圾回收,這些工作都會導致系統開銷的增加。因此,prototype作用域Bean的建立、銷燬代價比較大。而singleton作用域的Bean範例一旦建立成功,可以重複使用。因此,除非必要,否則儘量避免將Bean被設定成prototype作用域。
第二種回答:
spring 支援 5 種作用域,如下:
- singleton:spring ioc 容器中只存在一個 bean 範例,bean 以單例模式存在,是系統預設值;
- prototype:每次從容器呼叫 bean 時都會建立一個新的範例,既每次 getBean()相當於執行 new Bean()操作;
Web 環境下的作用域:
- request:每次 http 請求都會建立一個 bean;
- session:同一個 http session 共用一個 bean 範例;
- global-session:用於 portlet 容器,因爲每個 portlet 有單獨的 session,globalsession 提供一個全域性性的 http session。
注意:
使用 prototype 作用域需要慎重的思考,因爲頻繁建立和銷燬 bean 會帶來很大的效能開銷。
97.spring 自動裝配 bean 有哪些方式?
Spring容器負責建立應用程式中的bean同時通過ID來協調這些物件之間的關係。作爲開發人員,我們需要告訴Spring要建立哪些bean並且如何將其裝配到一起。
spring中bean裝配有兩種方式:
- 隱式的bean發現機制 機製和自動裝配
- 在java程式碼或者XML中進行顯示設定
當然這些方式也可以配合使用。
第二種回答:
- no:預設值,表示沒有自動裝配,應使用顯式 bean 參照進行裝配。
- byName:它根據 bean 的名稱注入物件依賴項。
- byType:它根據型別注入物件依賴項。
- 建構函式:通過建構函式來注入依賴項,需要設定大量的參數。
- autodetect:容器首先通過建構函式使用 autowire 裝配,如果不能,則通過 byType 自動裝配。
98.spring 事務實現方式有哪些?
- 程式設計式事務管理對基於 POJO 的應用來說是唯一選擇。我們需要在程式碼中呼叫beginTransaction()、commit()、rollback()等事務管理相關的方法,這就是程式設計式事務管理。
- 基於 TransactionProxyFactoryBean 的宣告式事務管理
- 基於 @Transactional 的宣告式事務管理
- 基於 Aspectj AOP 設定事務
第二種回答:
- 宣告式事務:宣告式事務也有兩種實現方式,基於 xml 組態檔的方式和註解方式(在類上新增 @Transaction 註解)。
- 編碼方式:提供編碼的形式管理和維護事務。
99.說一下 spring 的事務隔離?
事務隔離級別指的是一個事務對數據的修改與另一個並行的事務的隔離程度,當多個事務同時存取相同數據時,如果沒有採取必要的隔離機制 機製,就可能發生以下問題:
- 髒讀:一個事務讀到另一個事務未提交的更新數據。
- 幻讀:例如第一個事務對一個表中的數據進行了修改,比如這種修改涉及到表中的「全部數據行」。同時,第二個事務也修改這個表中的數據,這種修改是向表中插入「一行新數據」。那麼,以後就會發生操作第一個事務的使用者發現表中還存在沒有修改的數據行,就好象發生了幻覺一樣。
- 不可重複讀:比方說在同一個事務中先後 先後執行兩條一模一樣的select語句,期間在此次事務中沒有執行過任何DDL語句,但先後 先後得到的結果不一致,這就是不可重複讀。
第二種回答:
spring 有五大隔離級別,預設值爲 ISOLATION_DEFAULT(使用數據庫的設定),其他四個隔離級別和數據庫的隔離級別一致:
- ISOLATION_DEFAULT:用底層數據庫的設定隔離級別,數據庫設定的是什麼我就用什麼;
- ISOLATIONREADUNCOMMITTED:未提交讀,最低隔離級別、事務未提交前,就可被其他事務讀取(會出現幻讀、髒讀、不可重複讀);
- ISOLATIONREADCOMMITTED:提交讀,一個事務提交後才能 纔能被其他事務讀取到(會造成幻讀、不可重複讀),SQL server 的預設級別;
- ISOLATIONREPEATABLEREAD:可重複讀,保證多次讀取同一個數據時,其值都和事務開始時候的內容是一致,禁止讀取到別的事務未提交的數據(會造成幻讀),MySQL 的預設級別;
- ISOLATION_SERIALIZABLE:序列化,代價最高最可靠的隔離級別,該隔離級別能防止髒讀、不可重複讀、幻讀。
髒讀 :
表示一個事務能夠讀取另一個事務中還未提交的數據。比如,某個事務嘗試插入記錄 A,此時該事務還未提交,然後另一個事務嘗試讀取到了記錄 A。
不可重複讀 :
是指在一個事務內,多次讀同一數據。
幻讀 :
指同一個事務內多次查詢返回的結果集不一樣。比如同一個事務 A 第一次查詢時候有 n 條記錄,但是第二次同等條件下查詢卻有 n+1 條記錄,這就好像產生了幻覺。發生幻讀的原因也是另外一個事務新增或者刪除或者修改了第一個事務結果集裏面的數據,同一個記錄的數據內容被修改了,所有數據行的記錄就變多或者變少了。
100.說一下 spring mvc 執行流程?
Spring MVC執行流程圖:
流程描述:
-
使用者向伺服器發送請求,請求被Spring 前端控制Servelt DispatcherServlet捕獲;
-
DispatcherServlet對請求URL進行解析,得到請求資源識別符號(URI)。然後根據該URI,呼叫HandlerMapping獲得該Handler設定的所有相關的物件(包括Handler物件以及Handler物件對應的攔截器),最後以HandlerExecutionChain物件的形式返回;
-
DispatcherServlet 根據獲得的Handler,選擇一個合適的HandlerAdapter;(附註:如果成功獲得HandlerAdapter後,此時將開始執行攔截器的preHandler(…)方法)
-
提取Request中的模型數據,填充Handler入參,開始執行Handler(Controller)。 在填充Handler的入參過程中,根據你的設定,Spring將幫你做一些額外的工作:
(1)HttpMessageConveter: 將請求訊息(如Json、xml等數據)轉換成一個物件,將物件轉換爲指定的響應資訊
(2)數據轉換:對請求訊息進行數據轉換。如String轉換成Integer、Double等
(3)數據根式化:對請求訊息進行數據格式化。 如將字串轉換成格式化數位或格式化日期等
(4)數據驗證: 驗證數據的有效性(長度、格式等),驗證結果儲存到BindingResult或Error中 -
Handler執行完成後,向DispatcherServlet 返回一個ModelAndView物件;
-
根據返回的ModelAndView,選擇一個適合的ViewResolver(必須是已經註冊到Spring容器中的ViewResolver)返回給DispatcherServlet ;
-
ViewResolver 結合Model和View,來渲染檢視;
-
將渲染結果返回給用戶端。
第二種回答:
- spring mvc 先將請求發送給 DispatcherServlet。
- DispatcherServlet 查詢一個或多個 HandlerMapping,找到處理請求的 Controller。
- DispatcherServlet 再把請求提交到對應的 Controller。
- Controller 進行業務邏輯處理後,會返回一個ModelAndView。
- Dispathcher 查詢一個或多個 ViewResolver 檢視解析器,找到 ModelAndView 物件指定的檢視物件。
- 檢視物件負責渲染返回給用戶端。
101.spring mvc 有哪些元件?
Spring MVC的核心元件:
- DispatcherServlet:中央控制器,把請求給轉發到具體的控制類
- Controller:具體處理請求的控制器
- HandlerMapping:對映處理器,負責對映中央處理器轉發給controller時的對映策略
- ModelAndView:服務層返回的數據和檢視層的封裝類
- ViewResolver:檢視解析器,解析具體的檢視
- Interceptors :攔截器,負責攔截我們定義的請求然後做處理工作
第二種回答:
- 前置控制器 DispatcherServlet。
- 對映控制器 HandlerMapping。
- 處理器 Controller。
- 模型和檢視 ModelAndView。
- 檢視解析器 ViewResolver。
102.@RequestMapping 的作用是什麼?
RequestMapping是一個用來處理請求地址對映的註解,可用於類或方法上。用於類上,表示類中的所有響應請求的方法都是以該地址作爲父路徑。
RequestMapping註解有六個屬性,下面 下麪我們把她分成三類進行說明。
value, method:
- value:指定請求的實際地址,指定的地址可以是URI Template 模式(後面將會說明);
- method:指定請求的method型別, GET、POST、PUT、DELETE等;
consumes,produces
- consumes:指定處理請求的提交內容型別(Content-Type),例如application/json, text/html;
- produces:指定返回的內容型別,僅當request請求頭中的(Accept)型別中包含該指定型別才返回;
params,headers
- arams: 指定request中必須包含某些參數值是,才讓該方法處理。
- headers:指定request中必須包含某些指定的header值,才能 纔能讓該方法處理請求。
第二種回答:
將 http 請求對映到相應的類/方法上。
103.@Autowired 的作用是什麼?
- 首先要知道另一個東西,default-autowire,它是在xml檔案中進行設定的,可以設定爲byName、byType、constructor和autodetect;比如byName,不用顯式的在bean中寫出依賴的物件,它會自動的匹配其它bean中id名與本bean的set**相同的,並自動裝載。
- @Autowired是用在JavaBean中的註解,通過byType形式,用來給指定的欄位或方法注入所需的外部資源。
- 兩者的功能是一樣的,就是能減少或者消除屬性或構造器參數的設定,只是設定地方不一樣而已。
- autowire四種模式的區別:
| 模式 | 說明 |
|---|---|
| no | 根據屬性名自動裝配。此選項將檢查容器並根據名字查詢與屬性完全一致的bean,並將其與屬性自動裝配。例如,在bean定義中將autowire設定爲by name ,而該bean包含master屬性(同時提供setMaster(…)方法) ,,Spring就會查詢名爲master的bean定義,並用它來裝配給master屬性。 |
| byType | 如果容器中存在一個與指定屬性型別相同的bean ,那麼將與該屬性自動裝配。如果存在多個該型別的bean ,那麼將會拋出異常,並指出不能使用byType方式進行自動裝配。若沒有找到相匹配的bean ,則什麼事都不發生,屬性也不會被設定。如果你不希望這樣,那麼可以通過設定dependency-check="objects"讓Spring拋出異常。 |
| constructor | 與byType的方式類似,不同之處在於它應用於構造器參數。如果在容器中沒有找到與構造器參數型別一致的bean ,那麼將會拋出異常。 |
| autodetect | 通過bean類的自省機制 機製( introspection )來決定是使用constructor還是byType方式進行自動裝配。如果發現預設的構造器,那麼將使用byType方式。 |
-
先看一下bean範例化和@Autowired裝配過程:
(1)一切都是從bean工廠的getBean方法開始的,一旦該方法呼叫總會返回一個bean範例,無論當前是否存在,不存在就範例化一個並裝配,否則直接返回。(Spring MVC是在什麼時候開始執行bean的範例化過程的呢?其實就在元件掃描完成之後)
(2)範例化和裝配過程中會多次遞回呼叫getBean方法來解決類之間的依賴。
(3)Spring幾乎考慮了所有可能性,所以方法特別複雜但完整有條理。
(4)@Autowired最終是根據型別來查詢和裝配元素的,但是我們設定了後會影響最終的型別匹配查詢。因爲在前面有根據BeanDefinition的autowire型別設定PropertyValue值得一步,其中會有新範例的建立和註冊。就是那個autowireByName方法。 -
下面 下麪通過@Autowired來說明一下用法
-
Setter 方法中的 @Autowired
你可以在 JavaBean中的 setter 方法中使用 @Autowired 註解。當 Spring遇到一個在 setter 方法中使用的 @Autowired 註解,它會在方法中執行 byType 自動裝配。
這裏是 TextEditor.java 檔案的內容:
package com.tutorialspoint;
import org.springframework.beans.factory.annotation.Autowired;
public class TextEditor {
private SpellChecker spellChecker;
@Autowired
public void setSpellChecker( SpellChecker spellChecker ){
this.spellChecker = spellChecker;
}
public SpellChecker getSpellChecker( ) {
return spellChecker;
}
public void spellCheck() {
spellChecker.checkSpelling();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
下面 下麪是另一個依賴的類檔案 SpellChecker.java 的內容:
package com.tutorialspoint;
public class SpellChecker {
public SpellChecker(){
System.out.println("Inside SpellChecker constructor." );
}
public void checkSpelling(){
System.out.println("Inside checkSpelling." );
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
下面 下麪是 MainApp.java 檔案的內容:
package com.tutorialspoint;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class MainApp {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("Beans.xml");
TextEditor te = (TextEditor) context.getBean("textEditor");
te.spellCheck();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
下面 下麪是組態檔 Beans.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns=「http://www.springframework.org/schema/beans」
xmlns:xsi=「http://www.w3.org/2001/XMLSchema-instance」
xmlns:context=「http://www.springframework.org/schema/context」
xsi:schemaLocation=「http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd」>
<context:annotation-config/>
<!– Definition for textEditor bean without constructor-arg –>
<bean id=「textEditor」 class=「com.tutorialspoint.TextEditor」>
</bean>
<!– Definition for spellChecker bean –>
<bean id=「spellChecker」 class=「com.tutorialspoint.SpellChecker」>
</bean>
</beans>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
一旦你已經完成的建立了原始檔和 bean 組態檔,讓我們執行一下應用程式。如果你的應用程式一切都正常的話,這將會輸出以下訊息:
Inside SpellChecker constructor.
Inside checkSpelling.
- 1
- 2
- 屬性中的 @Autowired
你可以在屬性中使用 @Autowired 註解來除去 setter 方法。當時使用爲自動連線屬性傳遞的時候,Spring 會將這些傳遞過來的值或者參照自動分配給那些屬性。所以利用在屬性中 @Autowired 的用法,你的 TextEditor.java 檔案將變成如下所示:
package com.tutorialspoint;
import org.springframework.beans.factory.annotation.Autowired;
public class TextEditor {
@Autowired
private SpellChecker spellChecker;
public TextEditor() {
System.out.println("Inside TextEditor constructor." );
}
public SpellChecker getSpellChecker( ){
return spellChecker;
}
public void spellCheck(){
spellChecker.checkSpelling();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
下面 下麪是組態檔 Beans.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns=「http://www.springframework.org/schema/beans」
xmlns:xsi=「http://www.w3.org/2001/XMLSchema-instance」
xmlns:context=「http://www.springframework.org/schema/context」
xsi:schemaLocation=「http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd」>
<context:annotation-config/>
<!– Definition for textEditor bean –>
<bean id=「textEditor」 class=「com.tutorialspoint.TextEditor」>
</bean>
<!– Definition for spellChecker bean –>
<bean id=「spellChecker」 class=「com.tutorialspoint.SpellChecker」>
</bean>
</beans>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
一旦你在原始檔和 bean 組態檔中完成了上面兩處改變,讓我們執行一下應用程式。如果你的應用程式一切都正常的話,這將會輸出以下訊息:
Inside TextEditor constructor.
Inside SpellChecker constructor.
Inside checkSpelling.
- 1
- 2
- 3
- 建構函式中的 @Autowired
你也可以在建構函式中使用 @Autowired。一個建構函式 @Autowired 說明當建立 bean 時,即使在 XML 檔案中沒有使用元素設定 bean ,建構函式也會被自動連線。讓我們檢查一下下面 下麪的範例。
這裏是 TextEditor.java 檔案的內容:
package com.tutorialspoint;
import org.springframework.beans.factory.annotation.Autowired;
public class TextEditor {
private SpellChecker spellChecker;
@Autowired
public TextEditor(SpellChecker spellChecker){
System.out.println("Inside TextEditor constructor." );
this.spellChecker = spellChecker;
}
public void spellCheck(){
spellChecker.checkSpelling();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下面 下麪是組態檔 Beans.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns=「http://www.springframework.org/schema/beans」
xmlns:xsi=「http://www.w3.org/2001/XMLSchema-instance」
xmlns:context=「http://www.springframework.org/schema/context」
xsi:schemaLocation=「http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd」>
<context:annotation-config/>
<!– Definition for textEditor bean without constructor-arg –>
<bean id=「textEditor」 class=「com.tutorialspoint.TextEditor」>
</bean>
<!– Definition for spellChecker bean –>
<bean id=「spellChecker」 class=「com.tutorialspoint.SpellChecker」>
</bean>
</beans>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
一旦你在原始檔和 bean 組態檔中完成了上面兩處改變,讓我們執行一下應用程式。如果你的應用程式一切都正常的話,這將會輸出以下訊息:
Inside TextEditor constructor.
Inside SpellChecker constructor.
Inside checkSpelling.
- 1
- 2
- 3
- @Autowired 的(required=false)選項
預設情況下,@Autowired 註解意味着依賴是必須的,它類似於 @Required 註解,然而,你可以使用 @Autowired 的 (required=false) 選項關閉預設行爲。
即使你不爲 age 屬性傳遞任何參數,下面 下麪的範例也會成功執行,但是對於 name 屬性則需要一個參數。你可以自己嘗試一下這個範例,因爲除了只有 Student.java 檔案被修改以外,它和 @Required 註解範例是相似的。
package com.tutorialspoint;
import org.springframework.beans.factory.annotation.Autowired;
public class Student {
private Integer age;
private String name;
@Autowired(required=false)
public void setAge(Integer age) {
this.age = age;
}
public Integer getAge() {
return age;
}
@Autowired
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
第二種回答:
@Autowired 它可以對類成員變數、方法及建構函式進行標註,完成自動裝配的工作,通過@Autowired 的使用來消除 set/get 方法。
十一、Spring Boot / Spring Cloud
104.什麼是 spring boot?
在Spring框架這個大家族中,產生了很多衍生框架,比如 Spring、SpringMvc框架等,Spring的核心內容在於控制反轉(IOC)和依賴注入(DI),所謂控制反轉並非是一種技術,而是一種思想,在操作方面是指在spring組態檔中建立,依賴注入即爲由spring容器爲應用程式的某個物件提供資源,比如 參照物件、常數數據等。
SpringBoot是一個框架,一種全新的程式設計規範,他的產生簡化了框架的使用,所謂簡化是指簡化了Spring衆多框架中所需的大量且繁瑣的組態檔,所以 SpringBoot是一個服務於框架的框架,服務範圍是簡化組態檔。
第二種回答:
spring boot 是爲 spring 服務的,是用來簡化新 spring 應用的初始搭建以及開發過程的。
105.爲什麼要用 spring boot?
- Spring Boot使編碼變簡單
- Spring Boot使設定變簡單
- Spring Boot使部署變簡單
- Spring Boot使監控變簡單
- 彌補Spring的不足
第二種回答:
- 設定簡單
- 獨立執行
- 自動裝配
- 無程式碼生成和 xml 設定
- 提供應用監控
- 易上手
- 提升開發效率
106.spring boot 核心組態檔是什麼?
Spring Boot提供了兩種常用的組態檔:
- properties檔案
- yml檔案
第二種回答:
spring boot 核心的兩個組態檔:
- bootstrap (. yml 或者 . properties):boostrap 由父 ApplicationContext 載入的,比 applicaton 優先載入,且 boostrap 裏面的屬性不能被覆蓋;
- application (. yml 或者 . properties):用於 spring boot 專案的自動化設定。
107.spring boot 組態檔有哪幾種類型?它們有什麼區別?
Spring Boot提供了兩種常用的組態檔,分別是properties檔案和yml檔案。相對於properties檔案而言,yml檔案更年輕,也有很多的坑。可謂成也蕭何敗蕭何,yml通過空格來確定層級關係,使組態檔結構跟清晰,但也會因爲微不足道的空格而破壞了層級關係。
第二種回答:
組態檔有 . properties 格式和 . yml 格式,它們主要的區別是書法風格不同。
. properties 設定如下:
spring. RabbitMQ. port=5672
- 1
. yml 設定如下:
spring:
RabbitMQ:
port: 5672
- 1
- 2
- 3
. yml 格式不支援 @PropertySource 註解匯入。
108.spring boot 有哪些方式可以實現熱部署?
SpringBoot熱部署實現有兩種方式:
①. 使用spring loaded
在專案中新增如下程式碼:
<build>
<plugins>
<plugin>
<!-- springBoot編譯外掛-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<dependencies>
<!-- spring熱部署 -->
<!-- 該依賴在此處下載不下來,可以放置在build標籤外部下載完成後再貼上進plugin中 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>springloaded</artifactId>
<version>1.2.6.RELEASE</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
新增完畢後需要使用mvn指令執行:
首先找到IDEA中的Edit configurations ,然後進行如下操作:(點選左上角的"+",然後選擇maven將出現右側面板,在紅色框處輸入如圖所示指令,你可以爲該指令命名(此處命名爲MvnSpringBootRun))
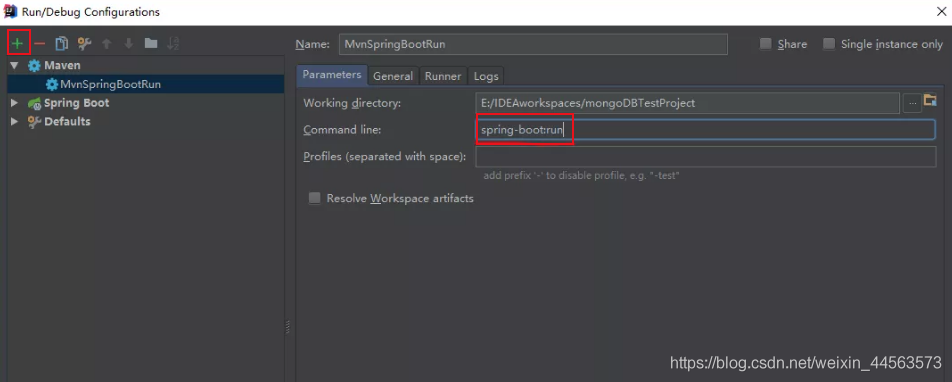
點選儲存將會在IDEA專案執行部位出現,點選綠色箭頭執行即可
②. 使用spring-boot-devtools==
在專案的pom檔案中新增依賴:
<!--熱部署jar-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency>
- 1
- 2
- 3
- 4
- 5
然後:使用 shift+ctrl+alt+"/" (IDEA中的快捷鍵) 選擇"Registry" 然後勾選 compiler.automake.allow.when.app.running。
第二種回答:
- 使用 devtools 啓動熱部署,新增 devtools 庫,在組態檔中把 spring. devtools. restart. enabled 設定爲 true;
- 使用 Intellij Idea 編輯器,勾上自動編譯或手動重新編譯。
109.jpa 和 hibernate 有什麼區別?
- JPA Java Persistence API,是Java EE 5的標準ORM介面,也是ejb3規範的一部分。
- Hibernate,當今很流行的ORM框架,是JPA的一個實現,但是其功能是JPA的超集。
- JPA和Hibernate之間的關係,可以簡單的理解爲JPA是標準介面,Hibernate是實現。那麼Hibernate是如何實現與JPA的這種關係的呢。Hibernate主要是通過三個元件來實現的,及hibernate-annotation、hibernate-entitymanager和hibernate-core。
- hibernate-annotation是Hibernate支援annotation方式設定的基礎,它包括了標準的JPA annotation以及Hibernate自身特殊功能的annotation。
- hibernate-core是Hibernate的核心實現,提供了Hibernate所有的核心功能。
- hibernate-entitymanager實現了標準的JPA,可以把它看成hibernate-core和JPA之間的適配器,它並不直接提供ORM的功能,而是對hibernate-core進行封裝,使得Hibernate符合JPA的規範。
第二種回答:
- jpa 全稱 Java Persistence API,是 Java 持久化介面規範,hibernate 屬於 jpa 的具體實現。
110.什麼是 spring cloud?
從字面理解,Spring Cloud 就是致力於分佈式系統、雲服務的框架。
Spring Cloud 是整個 Spring 家族中新的成員,是最近雲服務火爆的必然產物。
Spring Cloud 爲開發人員提供了快速構建分佈式系統中一些常見模式的工具,例如:
- 設定管理
- 服務註冊與發現
- 斷路器
- 智慧路由
- 服務間呼叫
- 負載均衡
- 微代理
- 控制匯流排
- 一次性令牌
- 全域性鎖
- 領導選舉
- 分佈式對談
- 叢集狀態
- 分佈式訊息
- ……
使用 Spring Cloud 開發人員可以開箱即用的實現這些模式的服務和應用程式。這些服務可以任何環境下執行,包括分佈式環境,也包括開發人員自己的筆記型電腦以及各種託管平臺。
第二種回答:
spring cloud 是一系列框架的有序集合。它利用 spring boot 的開發便利性巧妙地簡化了分佈式系統基礎設施的開發,如服務發現註冊、設定中心、訊息匯流排、負載均衡、斷路器、數據監控等,都可以用 spring boot 的開發風格做到一鍵啓動和部署。
111.spring cloud 斷路器的作用是什麼?
在Spring Cloud中使用了Hystrix 來實現斷路器的功能,斷路器可以防止一個應用程式多次試圖執行一個操作,即很可能失敗,允許它繼續而不等待故障恢復或者浪費 CPU 週期,而它確定該故障是持久的。斷路器模式也使應用程式能夠檢測故障是否已經解決,如果問題似乎已經得到糾正,應用程式可以嘗試呼叫操作。
斷路器增加了穩定性和靈活性,以一個系統,提供穩定性,而系統從故障中恢復,並儘量減少此故障的對效能的影響。它可以幫助快速地拒絕對一個操作,即很可能失敗,而不是等待操作超時(或者不返回)的請求,以保持系統的響應時間。如果斷路器提高每次改變狀態的時間的事件,該資訊可以被用來監測由斷路器保護系統的部件的健康狀況,或以提醒管理員當斷路器跳閘,以在開啓狀態。
第二種回答:
在分佈式架構中,斷路器模式的作用也是類似的,當某個服務單元發生故障(類似用電器發生短路)之後,通過斷路器的故障監控(類似熔斷保險絲),向呼叫方返回一個錯誤響應,而不是長時間的等待。這樣就不會使得執行緒因呼叫故障服務被長時間佔用不釋放,避免了故障在分佈式系統中的蔓延。
112.spring cloud 的核心元件有哪些?
①. 服務發現——Netflix Eureka
一個RESTful服務,用來定位執行在AWS地區(Region)中的中間層服務。由兩個元件組成:Eureka伺服器和Eureka用戶端。Eureka伺服器用作服務註冊伺服器。Eureka用戶端是一個java用戶端,用來簡化與伺服器的互動、作爲輪詢負載均衡器,並提供服務的故障切換支援。Netflix在其生產環境中使用的是另外的用戶端,它提供基於流量、資源利用率以及出錯狀態的加權負載均衡。
②. 客服端負載均衡——Netflix Ribbon
Ribbon,主要提供客戶側的軟體負載均衡演算法。Ribbon用戶端元件提供一系列完善的設定選項,比如連線超時、重試、重試演算法等。Ribbon內建可插拔、可定製的負載均衡元件。
③. 斷路器——Netflix Hystrix
斷路器可以防止一個應用程式多次試圖執行一個操作,即很可能失敗,允許它繼續而不等待故障恢復或者浪費 CPU 週期,而它確定該故障是持久的。斷路器模式也使應用程式能夠檢測故障是否已經解決。如果問題似乎已經得到糾正,應用程式可以嘗試呼叫操作。
④. 服務閘道器——Netflix Zuul
類似nginx,反向代理的功能,不過netflix自己增加了一些配合其他元件的特性。
⑤. 分佈式設定——Spring Cloud Config
這個還是靜態的,得配合Spring Cloud Bus實現動態的設定更新。
第二種回答:
- Eureka:服務註冊於發現。
- Feign:基於動態代理機制 機製,根據註解和選擇的機器,拼接請求 url 地址,發起請求。
- Ribbon:實現負載均衡,從一個服務的多臺機器中選擇一臺。
- Hystrix:提供執行緒池,不同的服務走不同的執行緒池,實現了不同服務呼叫的隔離,避免了服務雪崩的問題。
- Zuul:閘道器管理,由 Zuul 閘道器轉發請求給對應的服務。